











































 mathematics
mathematics economics
economicsSimilar presentations:










Парная линейная регрессия в экономике
1. Парная линейная регрессия
2.
С тех пор как экономика стала серьезной самостоятельной наукой,исследователи пытаются дать свое представление о возможных путях
экономического развития, спрогнозировать ту или иную ситуацию, предвидеть
будущие значения экономических показателей, указать инструменты
изменения ситуации в желательном направлении.
Поведение и значение любого экономического показателя зависят практически
от бесконечного количества факторов. Учесть все факторы нереально. Обычно
лишь ограниченное количество факторов действительно существенно
воздействуют на исследуемый экономический показатель. Доля влияния
остальных факторов столь незначительна, что их игнорирование не может
привести к существенным отклонениям в предполагаемом поведении
исследуемого объекта. Выделение и учет ограниченного числа реально
доминирующих факторов даёт основание для качественного анализа,
прогнозирования и управления ситуацией.
02.04.2013
Р. Мунипов
2
3.
Любая экономическая политика заключается в регулировании экономическихпеременных, и она должна базироваться на знании того, как эти переменные
связаны с другими переменными. В рыночной экономике нельзя
непосредственно регулировать темп инфляции, но на него можно
воздействовать средствами фискальной (бюджетно-налоговой) и монетарной
(кредитно-денежной) политики. А значит, должна быть изучена зависимость
между предложением денег и уровнем цен.
Инструментарием такого анализа являются методы статистики и
эконометрики, в частности регрессионного и корреляционного анализа.
Следует иметь в виду, что статистический анализ зависимостей сам по себе не
вскрывает существо причинных связей между явлениями, т.е. он не решает
вопроса, в силу каких причин одна переменная влияет на другую. Решение
такой задачи является результатом качественного (содержательного) изучения
связей, которое обязательно должно либо предшествовать статистическому
анализу, либо сопровождать его.
02.04.2013
Р. Мунипов
3
4.
В экономике чаще имеют не функциональные, а корреляционные, либостатистические, зависимости. Нахождение, оценка и анализ таких
зависимостей, построение формул зависимостей и оценка её параметров
являются одной из важнейших задач эконометрики.
Статистической называют зависимость, при которой изменение одной из
величин влечёт изменение распределения другой. В частности, статистическая
зависимость проявляется в том, что при изменении одной из величин
изменяется среднее значение другой. Такую статистическую зависимость
называют корреляционной.
Можно указать два варианта рассмотрения взаимосвязей между двумя
переменными X
и
Y. В первом случае обе переменные считаются
равноценными в том смысле, что они не подразделяются на первичную и
вторичную (независимую и зависимую) переменные. Основным в этом случае
является вопрос о наличии и силе взаимосвязи между этими переменными.
Например, между ценой товара и объемом спроса на него, между урожаем
картофеля и урожаем зерна, между интенсивностью движения транспорта и
числом аварий. При исследовании силы линейной зависимости между такими
переменными обращаются к корреляционному анализу, основной мерой
которого является коэффициент корреляции.
02.04.2013
Р. Мунипов
4
5.
Другой вариант рассмотрения взаимосвязей выделяет одну из величин какнезависимую (объясняющую), а другую как зависимую (объясняемую). В этом
случае изменение первой из них может служить причиной для изменения
другой. Например, рост дохода ведет к увеличению потребления; рост цены —
к снижению спроса; снижение процентной ставки увеличивает инвестиции;
увеличение обменного курса валюты сокращает объем чистого экспорта и т.д.
Однако такая зависимость не является однозначной в том смысле, что
каждому конкретному значению объясняющей переменной (набору
объясняющих переменных) может соответствовать не одно, а множество
значений из некоторой области. Или, каждому конкретному значению
объясняющей переменной (набору объясняющих переменных) соответствует
некоторое
вероятностное
распределение
зависимой
переменной
(рассматриваемой как СВ).
02.04.2013
Р. Мунипов
5
6.
Тогда анализируется, как объясняющая(ие) переменная(ые) влияет(ют) назависимую переменную «в среднем». Зависимость такого типа, выражаемая
соотношением
M Y x f ( x )
и называется функцией регрессии Y на X. При этом X называется
независимой (объясняющей) переменной (регрессором), Y — зависимой
(объясняемой) переменной. При рассмотрении зависимости двух СВ говорят о
парной регрессии.
Зависимость нескольких переменных, выражаемая функцией
M Y x1, x2 , , xm f ( x1, x2 , , xm )
называют множественной регрессией.
02.04.2013
Р. Мунипов
6
7.
Под регрессией понимается функциональная зависимость междуобъясняющими переменными и условным математическим ожиданием
(средним значением) зависимой переменной, которая строится с целью
предсказания (прогнозирования) этого среднего значения при фиксированных
значениях объясняющих переменных.
Так как реальные значения зависимой переменной не всегда совпадают с её
условными математическими ожиданиями, и могут быть различными при
одном и том же значении объясняющей переменной (наборе объясняющих
переменных), означает, что фактическая зависимость должна быть дополнена
некоторым слагаемым , которое, в сущности, является СВ и указывает на
стохастическую суть зависимости. Значит связи между зависимой и
объясняющей(ими) переменными должны выражаться соотношениями
M Y x f ( x )
M Y x1 , x2 ,
, xm f ( x1 , x2 ,
, xm )
называемыми регрессионными моделями (уравнениями).
02.04.2013
Р. Мунипов
7
8.
Определим причины предопределяющие присутствия в регрессионныхмоделях случайного фактора (отклонения). Среди таких причин выделим
наиболее существенные.
1. Невключение в модель всех объясняющих переменных.
Любая регрессионная (в частности, эконометрическая) модель является
упрощением реальной ситуации. Последняя всегда представляет собой
сложнейшее переплетение различных факторов, многие из которых в модели
не учитываются, что порождает отклонение реальных значений зависимой
переменной от ее модельных значений. Безусловно, перечислить все
объясняющие переменные здесь практически невозможно. Проблема еще и в
том, что никогда заранее не известно, какие факторы при создавшихся
условиях действительно являются определяющими, а какими можно
пренебречь. В ряде случаев учесть непосредственно какой-то фактор нельзя в
силу невозможности получения по нему статистических данных. Кроме того,
ряд факторов носит принципиально случайный характер (например, погода),
что добавляет неоднозначности при рассмотрении некоторых моделей
(например, модели сельскохозяйственной деятельности, прогнозирующие
объём урожая).
02.04.2013
Р. Мунипов
8
9.
2. Неправильный выбор функциональной формы модели.Из-за слабой изученности исследуемого процесса либо из-за его
переменчивости может быть неверно подобрана функция, его моделирующая.
Это, безусловно, скажется на отклонении модели от реальности, что отразится
на величине случайного члена.
3. Агрегирование переменных.
Во многих моделях рассматриваются зависимости между факторами, которые
сами представляют сложную комбинацию других, более простых переменных.
Например, при рассмотрении в качестве зависимой переменной совокупного
спроса проводится анализ зависимости, в которой объясняемая переменная
является сложной композицией индивидуальных спросов, оказывающих на
нее определённое влияние помимо факторов, учитываемых в модели. Это
может оказаться причиной отклонения реальных значений от модельных.
02.04.2013
Р. Мунипов
9
10.
4. Ошибки измерений.Какой бы качественной ни была модель, ошибки измерений переменных
отразятся на несоответствии модельных значений эмпирическим данным, что
также отразится на величине случайного члена.
5. Ограниченность статистических данных.
Зачастую строятся модели, выражаемые непрерывными функциями. Но для
этого используется набор данных, имеющих дискретную структуру. Это
несоответствие находит свое выражение в случайном отклонении.
6. Непредсказуемость человеческого фактора.
Эта причина может «испортить» самую качественную модель. Действительно,
при правильном выборе формы модели, скрупулезном подборе объясняющих
переменных все равно невозможно спрогнозировать поведение каждого
индивидуума.
02.04.2013
Р. Мунипов
10
11.
Решение эконометрической задачи построения качественного уравнениярегрессии, соответствующего эмпирическим данным и целям исследования,
является достаточно сложным и многоступенчатым процессом. Его можно
разбить на три этапа:
1. выбор формулы уравнения регрессии;
2. определение параметров выбранного уравнения;
3. анализ качества уравнения и поверка адекватности уравнения
эмпирическим данным, совершенствование уравнения.
Выбор формулы связи переменных называется спецификацией уравнения
регрессии. Задача определения параметров принятого при спецификации
уравнения называется параметризации (идентификацией), проверка качества
уравнения регрессии, её соответствия (репрезентативности) реальности
называется верификацией.
02.04.2013
Р. Мунипов
11
12.
Если функция регрессии линейна, то говорят о линейной регрессии. Модельлинейной регрессии (линейное уравнение) является наиболее
распространенным (и простым) видом зависимости между экономическими
переменными. Кроме того, построенное линейное уравнение может служить
начальной точкой эконометрического анализа.
Линейная регрессия (теоретическое линейное уравнение регрессии)
представляет собой линейную функцию между условным математическим
ожиданием M Y X xi зависимой переменной Y и одной объясняющей
переменной X ( xi — значения независимой переменной в i-ом наблюдении,
где i 1, n ),
M Y X xi 0 1xi
То, что каждое индивидуальное значение yi отличается от соответствующего
условного математического ожидания, в силу сказанного выше, необходимо
ввести случайное слагаемое i
M Y X xi 0 1xi i
Полученное соотношение называется теоретической линейной регрессионной
моделью; 0 и 1 — теоретическими параметрами (теоретическими
коэффициентами)
регрессии; i —Р. случайным
отклонением.
02.04.2013
Мунипов
12
13.
Следовательно, индивидуальные значения yi представляются в виде суммыдвух компонент — систематической ( 0 1 xi ) и случайной i .
Теоретическую линейную регрессионную модель будем представлять в виде
Y 0 1 X
Для определения значений теоретических коэффициентов регрессии
необходимо знать и использовать все значения переменных X и Y
генеральной совокупности, что практически невозможно.
Таким образом, задача линейного регрессионного анализа состоят в том,
чтобы по имеющимся статистическим данным xi , yi i 1,n для переменных X
и Y:
1. получить наилучшие оценки неизвестных параметров 0 и 1 ;
2. проверить статистические гипотезы о параметрах модели;
3. проверить, достаточно ли хорошо принятая модель согласуется со
статистическими данными (адекватность модели данным наблюдений).
02.04.2013
Р. Мунипов
13
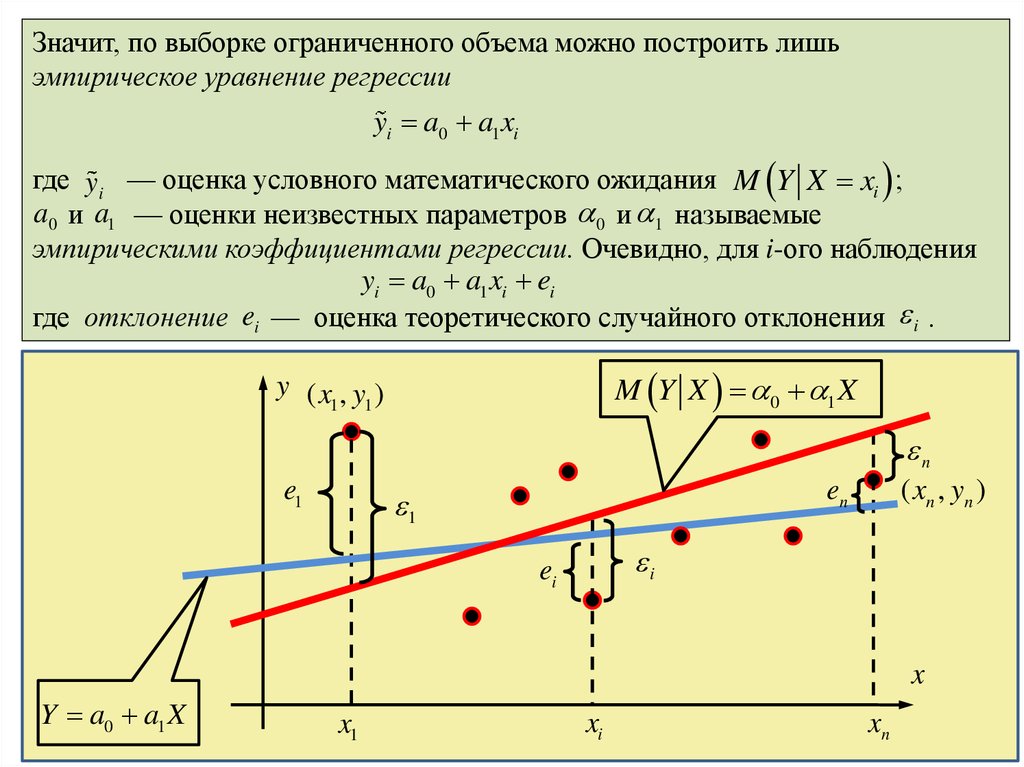
14.
Значит, по выборке ограниченного объема можно построить лишьэмпирическое уравнение регрессии
yi a0 a1 xi
где yi — оценка условного математического ожидания M Y X xi ;
a0 и a1 — оценки неизвестных параметров 0 и 1 называемые
эмпирическими коэффициентами регрессии. Очевидно, для i-ого наблюдения
yi a0 a1 xi ei
где отклонение ei — оценка теоретического случайного отклонения i .
M Y X 0 1 X
y (x , y )
1
1
e1
n
( xn , yn )
en
1
i
ei
x
Y a0 a1 X
02.04.2013
x1
Р. Мунипов
xi
xn
14
15.
В силу несовпадения статистической базы для генеральной совокупности ивыборки оценки a0 и a1 практически всегда отличаются от истинных
значений коэффициентов 0 и 1 , что влечёт несовпадение эмпирической и
теоретической линий регрессии.
Задача состоит в том, чтобы по конкретной выборке xi , yi i 1,n , найти
оценки a0 и a1 неизвестных параметров 0 и 1 так, чтобы построенная
линия регрессии являлась бы наилучшей в определенном смысле среди всех
других прямых. То есть, построенная прямая должна быть «ближайшей» к
точкам наблюдений по их совокупности. Очевидно, мерами качества
найденных оценок могут служить определенные композиции получаемых
отклонений ei i 1, n . В частности, минимум суммы квадратов отклонений
n
n
n
e = y y = y a
i 1
2
i
i 1
2
i
i
i 1
i
0
a1xi
2
Метод определения оценок коэффициентов из условия минимизации этой
суммы называется методом наименьших квадратов (МНК). Этот метод
оценки является наиболее простым с вычислительной точки зрения. Кроме
того, оценки коэффициентов регрессии, найденные МНК при определенных
предпосылках, обладают рядом оптимальных свойств.
02.04.2013
Р. Мунипов
15
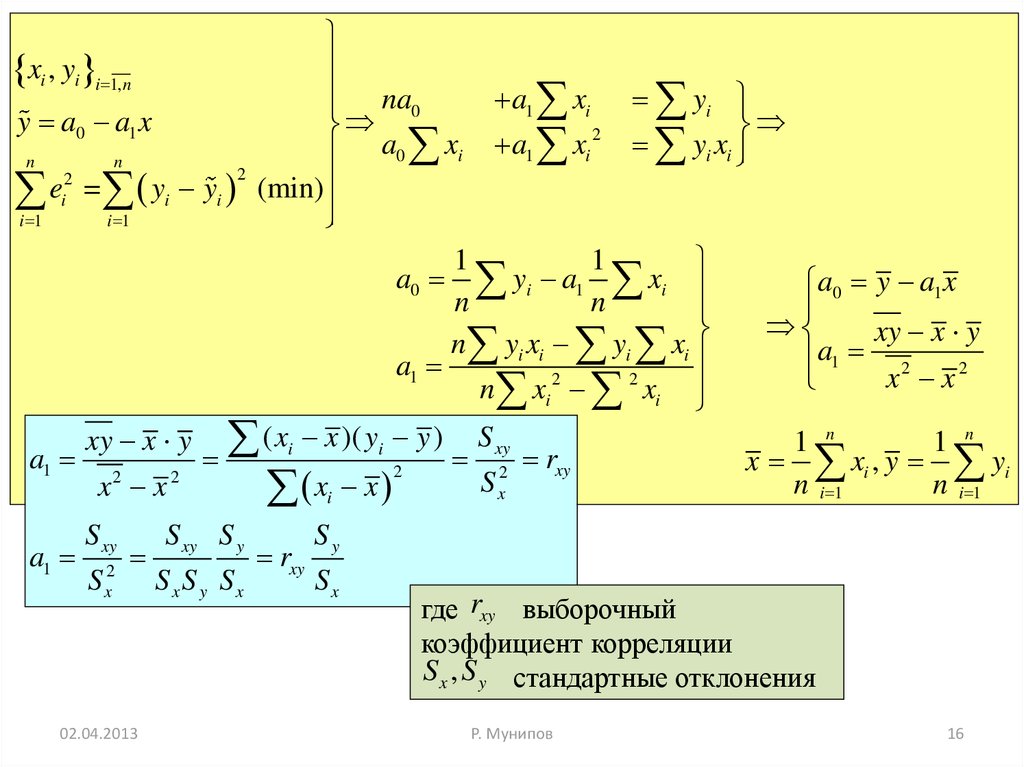
16.
xi , yi i 1,nna0
a1 xi yi
y a0 a1 x
2
a0 xi a1 xi yi xi
n
n
2
2
e
=
y
y
i i (min)
i
i 1
i 1
1
1
a0 yi a1 xi
a0 y a1 x
n
n
xy x y
n yi xi yi xi
a
1
2
2
a1
2
2
x
x
n xi xi
xy x y ( xi x )( yi y ) S xy
1 n
1 n
a1 2
2 rxy
x xi , y yi
2
2
Sx
n i 1
n i 1
x x
xi x
a1
S xy
S
2
x
02.04.2013
S xy S y
SxS y Sx
rxy
Sy
Sx
где rxy выборочный
коэффициент корреляции
S x , S y стандартные отклонения
Р. Мунипов
16
17.
Для полученных оценок МНК справедливо1.
2.
3.
4.
Оценки МНК являются функциями от выборки.
Оценки МНК являются точечными оценками теоретических
коэффициентов регрессии.
Согласно эмпирическая прямая регрессии обязательно проходит через
точку x , y .
Эмпирическое уравнение регрессии построено таким образом, что сумма
отклонений ei , а также среднее значение отклонений e равны нулю.
e e 0
i
5.
6.
Случайные отклонения не коррелированы с наблюдаемыми значениями
зависимой переменной Y.
Случайные отклонения ei не коррелированы с наблюдаемыми
значениями xi независимой переменной X.
02.04.2013
Р. Мунипов
17
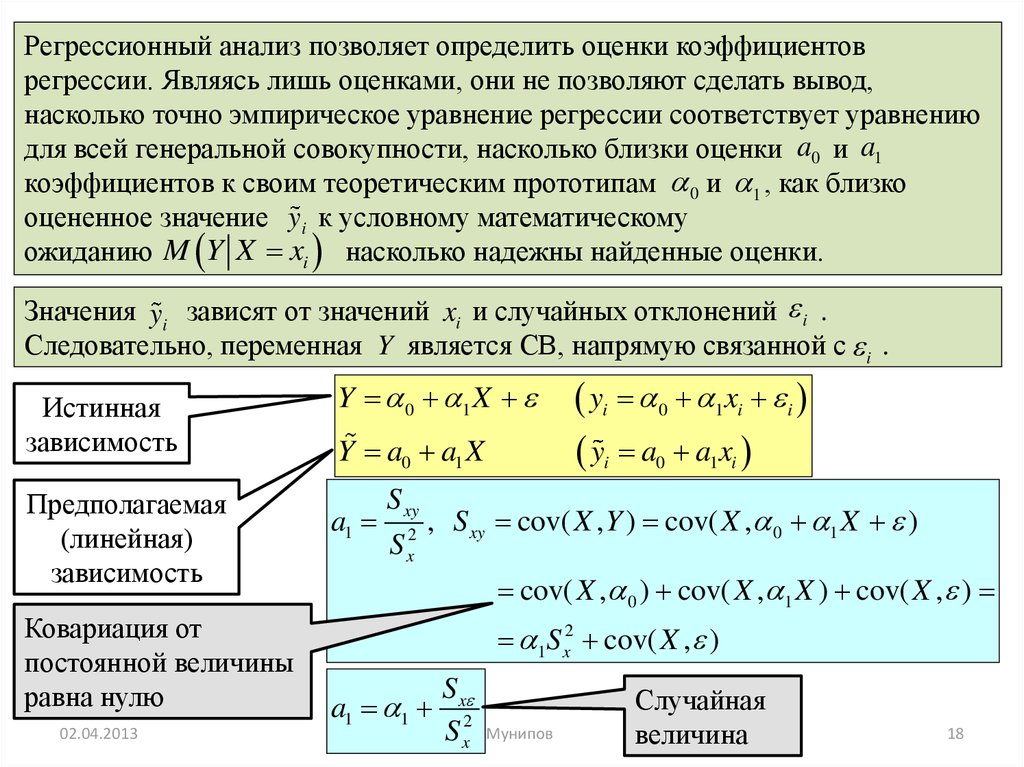
18.
Регрессионный анализ позволяет определить оценки коэффициентоврегрессии. Являясь лишь оценками, они не позволяют сделать вывод,
насколько точно эмпирическое уравнение регрессии соответствует уравнению
для всей генеральной совокупности, насколько близки оценки a0 и a1
коэффициентов к своим теоретическим прототипам 0 и 1 , как близко
оцененное значение yi к условному математическому
ожиданию M Y X xi насколько надежны найденные оценки.
Значения yi зависят от значений xi и случайных отклонений i .
Следовательно, переменная Y является СВ, напрямую связанной с i .
Истинная
зависимость
Предполагаемая
(линейная)
зависимость
Ковариация от
постоянной величины
равна нулю
02.04.2013
Y 0 1 X
Y a0 a1 X
a1
S xy
S
2
x
yi 0 1xi i
yi a0 a1xi
, S xy cov( X , Y ) cov( X , 0 1 X )
cov( X , 0 ) cov( X , 1 X ) cov( X , )
1S x2 cov( X , )
a1 1
S x
S x2Р. Мунипов
Случайная
величина
18
19.
Предпосылки МНК (условия Гаусса—Маркова)1. Математическое ожидание случайного отклонения i равно нулю: для
всех наблюдений M ( i ) 0 .
Данное условие означает, что случайное отклонение в среднем не оказывает
влияния на зависимую переменную. В каждом конкретном наблюдении
случайный член может быть либо положительным, либо отрицательным, но он
не должен иметь систематического смещения. Очевидно,
M ( i ) 0 M Y X xi 0 1xi
2. Дисперсия случайных отклонений постоянна: D( i ) D( j ) 2
для любых наблюдений i и j.
Данное условие подразумевает, что несмотря на то, что при каждом
конкретном наблюдении случайное отклонение может быть либо большим,
либо меньшим, но не должно быть некой причины, вызывающей большую
ошибку (отклонение).
Выполнимость данной предпосылки называется гомоскедастичностью
(постоянством дисперсии отклонений). Невыполнимость данной
предпосылки называется гетероскедастичностью (непостоянством
дисперсий отклонений).
2
Поскольку D( i ) M i M ( i ) M i2 , то данную предпосылку
можно переписать в форме: M i2 2 .
02.04.2013
Р. Мунипов
19
20.
Случайные отклонения i и j являются независимыми друг от другадля i j .
Выполнимость данной предпосылки предполагает, что отсутствует
систематическая связь между любыми случайными отклонениями.
Очевидно,
0, i j
i j cov( i , j ) 2
, i j
Если данное условие выполняется, то говорят об отсутствии автокорреляции.
С учетом выполнимости первой предпосылки получаем,
3.
0, i j
i j cov( i , j ) 2
, i j M ( i j ) 0
M ( i ) 0
Случайное отклонение должно быть независимо от объясняющих
переменных.
Это условие выполняется если объясняющие переменные не случайные.
Причём получаем
i xi cov( i , xi ) M i M ( i ) xi M ( xi ) M i xi M ( xi )
4.
02.04.2013
M ( i xi ) M ( i ) M ( xi )Р. Мунипов
0
20
21.
5.Модель регрессии является линейной относительно параметров.
Теорема Гаусса-Маркова. Если предпосылки 1— 5 выполнены, то оценки,
полученные по МНК, обладают следующими свойствами:
1. Оценки являются несмещенными, т.е. M (a0 ) 0 , M (a1 ) 1 . Это
вытекает из того, что M ( i ) 0 , и говорит об отсутствии систематической
ошибки в определении положения линии регрессии.
2. Оценки состоятельны, так как дисперсия оценок параметров при
возрастании числа наблюдений стремится к нулю:
D(a0 )
0, D(a1)
0
n
n
Т.е. при увеличении объема выборки надежность оценок увеличивается
( a0 наверняка близко к 0 , a1 — близко к 1 ).
3. Оценки эффективны, т.е. они имеют наименьшую дисперсию по сравнению
с любыми другими оценками данных параметров, линейными относительно
величин yi .
02.04.2013
Р. Мунипов
21
22.
В англоязычной литературе такие оценки называются BLUE (Best LinearUnbiased Estimators) — наилучшие линейные несмещенные оценки.
Если предпосылки 2 и 3 нарушены, т.е. дисперсия отклонений непостоянна и
(или) значения связаны друг с другом, то свойства несмещённости и
состоятельности сохраняются, но свойство эффективности — нет.
С выполнимостью указанных предпосылок при построении классических
линейных регрессионных моделей делаются ещё предположения, такие
например, как:
• объясняющие переменные не являются СВ;
• случайные отклонения имеют нормальное распределение;
• число наблюдений существенно больше числа объясняющих переменных;
• отсутствуют ошибки спецификации;
• отсутствует совершенная мультиколлинеарность.
02.04.2013
Р. Мунипов
22
23.
В силу случайного отбора элементов в выборку случайными являются такжеоценки a0 и a1 коэффициентов 0 и 1 теоретического уравнения регрессии.
Их математические ожидания при выполнении предпосылок об отклонениях
равны соответственно M (a0 ) 0 , M (a1 ) 1 . При этом оценки тем
надежнее, чем меньше их разброс вокруг 0 и 1 , т.е. чем меньше
дисперсии D(a0 ) и D ( a1 ) оценок. Надежность получаемых оценок, связана с
дисперсией случайных отклонений i , и является дисперсией переменной Y
относительно линии регрессии (дисперсией Y, очищенной от влияния X ).
a1
( x x )( y y ) ( x x ) y ( x x ) y ( x x ) y
x x
x x x x x x
i
i
i
i
2
2
i
i
xi x
x x
i
2
yi ci yi
i
i
i
2
2
i
i
xi x
ci
2
xi x
обозначим
a0 y a1 x
02.04.2013
1
1
y
x
c
y
xc
i
i i
i yi d i yi ,
n
n
Р. Мунипов
1
d
xc
i
i
n
обозначим
23
24.
D(a1 ) D ci yi2
c
2
i
2
1
xi x
2
2
1
1
1
D(a0 ) D d i yi 2 d i2 2 ci x 2 2 2ci x ci2 x 2
n
n
n
1
1
2 n 2 2 x ci x 2 ci2
n
n
2
1
1
x
x
x
x
2
i
i
2 2 x
x
2
2
x x
n
n
xi x
i
1 ( xi x )
2 1
2
2 x
x
2
n
n
x
x
i
2
x
x
nx
i
2
2
02.04.2013
n xi x
2
( xi x ) 2 1 x 2
2 2
n x x 2
i
xi x
2
2
2
2
x
nx
2
x
x
nx
i
2 i
n xi x
Р. Мунипов
2
2
2
x
i
n xi x
24
2
25.
D(a1 ) 21
xi x
2
;
D
(
a
)
0
2
2
x
i
n xi x
2
Из полученных соотношений следует:
• Дисперсии параметров a0 и a1 прямо пропорциональны дисперсии
2
отклонения . Следовательно, чем больше фактор случайности, тем менее
точными будут оценки.
• Чем больше число наблюдений, тем меньше дисперсии оценок. Т.е. чем
большим числом данных мы располагаем, тем вероятнее получение более
точных оценок.
• Чем больше дисперсия (разброс значений ( xi x )2 ) объясняющей
переменной, тем меньше дисперсия оценок коэффициентов. Т.е, чем шире
область изменений объясняющей переменной, тем точнее будут оценки (тем
меньше доля случайности в их определении).
02.04.2013
Р. Мунипов
25
26.
Случайные отклонения i по выборке определены быть не могут, при анализенадежности оценок коэффициентов регрессии они заменяются
отклонениями ei yi a0 a1 xi значений yi переменной Y от оцененной
линии регрессии yi . Дисперсия случайных отклонений D( i ) 2
заменяется её несмещенной оценкой S 2
1
1
2
2
y
x
i n i 0 1 i
n
2
D( i ) S
1
1
2
2
S2
e
y
a
a
x
i 0 1 i D(a ) 2
i
n 2
n 2
1
D( i ) 2
Тогда
;
x x
x
n x x
2
i
D(a1 ) S
2
a1
D(a0 ) S
2
a0
02.04.2013
1
S2
xi x
S
2
2
;
2
i
i
x
2
i
n xi x
D ( a0 )
2
2
x 2 S a21
Р. Мунипов
26
2
27.
S2e
2
i
– необъясненная дисперсия (мера разброса зависимой
n 2
переменной вокруг линии регрессии), корень квадратный из необъясненной
дисперсии, т.е. S
2
e
i
, называется стандартной ошибкой оценки
n 2
(стандартной ошибкой регрессии).
Sa1
S2
и S a0
S 2 xi2
— стандартные отклонения
n xi x
случайных величин a1 и a0 называемые стандартными ошибками
x x
2
2
i
коэффициентов регрессии.
02.04.2013
Р. Мунипов
27
28.
Эмпирическое уравнение регрессии определяется на основе конечного числастатистических данных. Поэтому коэффициенты эмпирического уравнения
регрессии являются СВ, изменяющимися от выборки к выборке. При
проведении статистического анализа возникает необходимость сравнения
эмпирических коэффициентов регрессии a0 и a1 с некоторыми теоретически
ожидаемыми значениями 0 и 1 этих коэффициентов. Данный анализ
осуществляется по схеме статистической проверки гипотез.
Для проверки гипотезы H 0 : a1 1 , H1 : a1 1 используется статистика
t
a1 1
Sa1
которая при справедливости H 0 имеет распределение Стьюдента с числом
степеней свободы n 2 , где п — объем выборки. Следовательно, H 0
отклоняется на основании данного критерия, если
Tí àáë
a1 1
t
,n 2
Sa1
2
где — требуемый уровень значимости. При невыполнении этого
неравенства считается, что нет оснований для отклонения H 0 .
02.04.2013
Р. Мунипов
28
29.
Наиболее важной на начальном этапе статистического анализа построенноймодели является задача установления наличия линейной зависимости между Y
и X. Эта проблема может быть решена по схеме: H 0 : a1 0, H1 : a1 0
Гипотеза в такой постановке называется гипотезой о статистической
значимости коэффициента регрессии. При этом, если принимается H 0 , то
есть основания считать, что величина Y не зависит от X , в этом случае
говорят, что коэффициент a1 статистически незначим (он слишком близок к
нулю). При отклонении H 0 коэффициент a1 считается статистически
значимым, что указывает на наличие определенной линейной зависимости
между Y и X . В этом случае рассматривается двусторонняя критическая
область, так как важным является именно отличие от нуля коэффициента
регрессии, и он может быть как положительным, так и отрицательным.
02.04.2013
Р. Мунипов
29
30.
Поскольку полагается, что 1 0 , то значимость оцениваемого коэффициентарегрессии a1 проверяется с помощью анализа отношения его величины к его
стандартной ошибке S a1 .
t
a1
Sa1
Эта дробь имеет распределение Стьюдента с числом степеней
свободы n 2 , где п — число наблюдений, и называется t-статистикой.
Для t-статистики проверяется нулевая гипотеза о равенстве ее нулю.
Очевидно, t 0 равнозначно a1 0 , поскольку t пропорциональна a1 .
Фактически это свидетельствует об отсутствии линейной связи между X и Y .
По аналогичной схеме на основе t-статистики проверяется гипотеза о
статистической значимости коэффициента a0 :
t
a0
Sa0
Для парной регрессии более важным является анализ статистической
значимости коэффициента a1 , так как именно в нем скрыто влияние
объясняющей переменной X на зависимую переменную Y.
02.04.2013
Р. Мунипов
30
31.
При оценке значимости коэффициента линейной регрессии на начальномэтапе можно использовать следующее «грубое» правило.
Если стандартная ошибка коэффициента больше его модуля, t 1 , то
коэффициент не может быть признан значимым, так как доверительная
вероятность при двусторонней альтернативной гипотезе составит менее чем
0,7.
Если 1 t 2 , то найденная оценка может рассматриваться как
относительно (слабо) значимая. Доверительная вероятность в этом случае
лежит между значениями 0,7 и 0,95.
Если 2 t 3 , то это свидетельствует о значимой линейной связи между
X и Y . В этом случае доверительная вероятность колеблется от 0,95 до 0,99.
Наконец, если t 3 , то это гарантирует наличие линейной связи.
Вместе с тем, в каждом конкретном случае имеет значение число наблюдений,
чем их больше, тем надежнее при прочих равных условиях выводы о
значимости коэффициента. Однако для n > 10 предложенное «грубое»
правило практически всегда работает.
02.04.2013
Р. Мунипов
31
32.
Ранее для коэффициентов a0 и a1 получили:1
d
xc
i
i
n
a0 di yi ,
xi x
ci
a1 ci yi
2
xi x
Т.е, a0 и a1 являются линейными комбинациями yi , которые в свою очередь
также является линейной комбинацией i ,
yi M Y X xi 0 1xi i
(при этом считается, что 0 , 1 и xi — константы или неслучайные величины).
Тогда a0 и a1 через yi являются линейными функциями от i , имеющими
нормальное распределение. Значит, a0 и a1 также распределены нормально,
M (a1 ) 1 , D(a1 ) S
;
2
xi x
a1
2
2
a0
S xi
2
2 2
M (a0 ) 0 , D(a0 ) Sa0
x S a1
2
n xi x
2
a1
02.04.2013
S2
Р. Мунипов
N 1 , D(a1 )
N 0 , D(a0 )
32
33.
Статистикиta0
a0 0
a 1
, ta1 1
Sa0
Sa1
имеют распределение Стьюдента с числом степеней свободы n 2 . Для
определения 100(1 )% -го доверительного интервала с помощью
критических точек распределения Стьюдента по доверительной
вероятности 1 и числу степеней свободы v определяют критическое
значение t 2,n 2 , удовлетворяющее условию
P t t 1
,n 2
2
или
02.04.2013
a0 0
t 1
P ta0 t 1 P
,n 2
S
,n 2
a
2
0
2
a1 1
P ta1 t 1 P
t 1
,n 2
,n 2
2
S a1
2
Р. Мунипов
33
34.
a0 0P t
t 1 P a0 S a t
0 a0 S a0 t 1
0
,n 2
,
n
2
,
n
2
,n 2
Sa0
2
2
2
2
a1 1
P t
t 1 P a1 S a1 t ,n 2 1 a1 S a1t ,n 2 1
,n 2
,n 2
Sa1
2
2
2
2
S 2 xi2
S 2 xi2
P a0 t
0 a0 t
2
2
,n 2
,n 2
n
x
x
n
x
x
2
2
i
i
P a1 t
,n 2
2
S2
x x
i
2
1 a1 t
2
S2
,n 2
x x
i
2
1
1
Полученные соотношения для вероятностей определяют доверительные
интервалы
a0 S a0 t ,n 2 ; a0 S a0 t ,n 2
2
2
a1 S a1 t ,n 2 ; a1 S a1t ,n 2
2
2
которые
.
02.04.2013с надежностью (1 ) накрывают
Р. Мунипов определяемые параметры 0 и 34
1
35.
Одной из центральных задач эконометрического анализа являетсяпредсказание (прогнозирование) значений зависимой переменной при
определенных значениях объясняющих переменных. Очевидно, можно: либо
предсказать условное математическое ожидание зависимой переменной при
определенных значениях объясняющих переменных (предсказание среднего
значения), либо прогнозировать некоторое конкретное значение зависимой
переменной (предсказание конкретного значения).
Предсказание среднего значения. Пусть построено уравнение парной
регрессии yi a0 a1 xi , на основе которого необходимо предсказать условное
математическое ожидание M Y X x p переменной Y при X x p , которое
является оценкой y p . Естественным является вопрос, как сильно может
уклониться модельное среднее значение y p , рассчитанное по эмпирическому
уравнению регрессии, от соответствующего условного математического
ожидания. Это можно получить с помощью интервальных оценок,
построенных с заданной надежностью для любого конкретного значения
объясняющей переменной.
02.04.2013
Р. Мунипов
35
36.
Получено раннееYp a0 a1 x p
yi a0 a1 xi a0 di yi ,
a1 ci yi
Yp di x p ci yi
1
d
xc
i
i
n
Yp di yi ci yi x p
xi x
ci
2
xi x
Значит Yp является линейной комбинацией
нормальных СВ и имеет нормальное распределение.
D Y D a
M Yp M a0 a1 x p M (a0 ) M (a1 ) x p 0 1 x p
p
2
a
x
D
(
a
)
D
(
a
)
x
0
1 p
0
1
p 2 x p cov( a0 , a1 )
Поскольку,
D ( X Y ) D ( X ) D (Y ) 2cov( X , Y )
D (cX ) c 2 D ( X )
02.04.2013
cov( X , cY ) c cov( X , Y )
Р. Мунипов
36
37.
cov(a0 , a1 ) M a0 M (a0 ) a1 M (a1 )M a0 0 a1 1
2
2
2
x
M y xa1 ( yi x 1 ) a1 1 2
2
D Yp
x 2Получено
xp x
2
2 p
ранее2
xxi x a
x i x
xi x
M nxa
1
1
1
1
2
2
x
xM a1 1 a1
1 i 2 xx x 2
p
p
2
n
x
x
i 2
xM a1 1
2
2
2
1
2
x
x
nx
i
D(a1 ) 2 xx x 2 2 ;
2
xM a1 M (a12)
xp i xp
n
xi x
2
xD(a1 ) 2
x
2
2i
xi xD (a ) 2 2
0
2
2
x
2
xx
x
n
x
x
p
p
i
n
x xi 2x 2
2
2
2
2
2
xi x
x
n
nx
x
x
nx
2
i
i
x
x
x
p
2 1
2
n xi x
02.04.2013
Р. Мунипов
37
38.
2x
x
1
p
2
D Yp 2
2
2
x
x
ei 1
n xi x
p
2
S Yp
2
n 2 n xi x
2
ei
2
2
S
n 2
Выборочная исправленная
дисперсия
02.04.2013
Р. Мунипов
38
39.
СтатистикаT (Yp )
Yp ( 0 1 x p )
S (Yp )
имеют распределение Стьюдента с числом степеней свободы n 2 . Для
определения 100(1 )% -го доверительного интервала с помощью
критических точек распределения Стьюдента по доверительной
вероятности 1 и числу степеней свободы v определяют критическое
значение t 2,n 2 , удовлетворяющее условию
P T (Yp ) t 1
,n 2
2
Yp ( 0 1 x p )
t 1
или P
,n 2
S
(
Y
)
p
2
После преобразований получим
P a0 a1 x p S (Yp )t
0 1 x p a0 a1 x p S (Yp )t 1
,n 2
,n 2
2
2
02.04.2013
Р. Мунипов
39
40.
Доверительный интервал для M Y X x p 0 1 x p имеет вид:2
2
x
x
e
i 1 p ;
a
a
x
t
2
0 1 p ,n 2 n 2 n
x
x
2
i
2
2
x xp
e
i 1
a0 a1 x p t
2
,n 2
n 2 n xi x
2
который с надежностью (1 ) накрывают прогнозируемое среднее значение,
условное математическое ожидание M Y X x p .
02.04.2013
Р. Мунипов
40
41.
Для проверки гипотезыH 0 : M (Y X x p ) y p
H1 : M (Y X x p ) y p
используется статистика:
T
M (Y X x p ) y p
2
x
x
e
1
p
2
n 2 n xi x
2
i
имеющая распределение Стьюдента с числом степеней свободы n 2 .
Поэтому H 0 отклоняется, если Tí àáë t
( — требуемый уровень
,n 2
2
значимости).
02.04.2013
Р. Мунипов
41
42.
Предсказание индивидуальных значений зависимой переменной. Иногда болееважно знать дисперсию Y, чем её средние значения (доверительные интервалы
для условных математических ожиданий). Что позволяет определить
допустимые границы для конкретного значения Y.
Пусть y0 есть некоторое возможное значение переменной Y при
определенном значении x p объясняющей переменной X. Предсказанное по
уравнению регрессии значение Y при X x p составляет y p . Если
рассматривать значение y0 как СВ Y0 , а y p — как СВ Yp ,то
имеют
нормальное
распределение
02.04.2013
Y0
Yp
N 0 1 x p , 2
2
x
x
1
p
N 0 1 x p , 2
2
n xi x
Р. Мунипов
42
43.
СВ Y0 и Yp являются независимыми, а следовательно, СВ U Y0 Yp имеетнормальное распределение
2
x
x
1
p
M (U ) 0, D(U ) 2
2
n xi x
Тогда статистика
U
SU
Y0 Yp
x xp
1
S 1
n xi x 2
2
,
S
2
e
i
n 2
имеет распределение Стьюдента с n 2 степенями свободы. Значит
Y0 Yp
P t
t 1
2
,n 2
2 ,n 2
2
x
x
p
1
S 1
2
n xi x
02.04.2013
Р. Мунипов
43
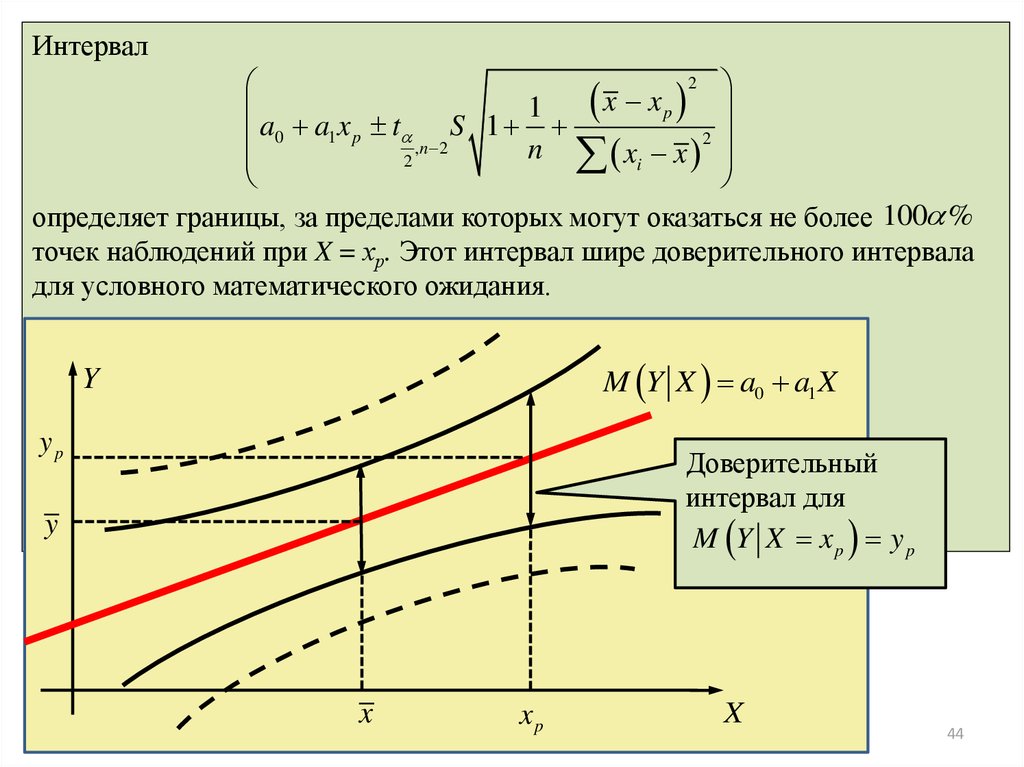
44.
Интервал2
x xp
1
a a x t
S 1
2
0 1 p ,n 2
n
x
x
2
i
определяет границы, за пределами которых могут оказаться не более 100 %
точек наблюдений при X = хр. Этот интервал шире доверительного интервала
для условного математического ожидания.
M Y X a0 a1 X
Y
yp
Доверительный
интервал для
M Y X xp yp
y
02.04.2013
x
x
p
Р. Мунипов
X
44
45.
Мерой качества уравнения регрессии (соответствия уравнения регрессиистатистическим данным) является коэффициент детерминации R2. В случае
парной регрессии коэффициент детерминации будет совпадать с квадратом
коэффициента корреляции. Коэффициент детерминации рассчитывается по
формуле
R2 1
e
2
i
( y y)
2
i
Уравнение линейной регрессии, построенное на основании эмпирических
(наблюдаемых) парных данных xi , yi i 1,n , имеет вид
y a0 a1 x
Наблюдаемые (реальные) значения yi , отличаются от модельных yi a0 a1 xi
на величину ei :
yi yi ei
Очевидно,
yi y ( yi y ) ( yi yi ) yi y ki ei
02.04.2013
Р. Мунипов
45
46.
Где ( yi y ) есть отклонение i –ого наблюдаемого значения от среднегозначения y зависимой переменной, ki – отклонение i –ого значения на
прямой регрессии от среднего значения зависимой переменной, ei есть
отклонение i –ого значения yi от расчётного (модельного) значения yi
определяемого регрессией.
y
y a0 a1 x
y
ki
yi
ei
yi
x
xi
02.04.2013
x
Р. Мунипов
46
47.
yi y ki eiyi y ( yi y ) ( yi yi ) ki yi y
e y y
i
i
i
2
2
2
(
y
y
)
(
y
y
)
(
y
y
)
i
i
i i 2 ( yi y )( yi yi )
( y y ) k e
2
i
2
i
2
i
2 ( yi y )ei
(y
i
y )ei yi ei y ei yi ei
( a0 a1 xi )ei
a0 ei a1 xi ei a1 xi ei 0
2
2
2
(
y
y
)
k
e
i
i i
Очевидно, ( yi y )2 — общая (полная) сумма квадратов может
интерпретироваться как мера общего разброса (рассеивания) переменной y
относительно y . ki2 ( yi y )2 — объясненная сумма квадратов,
интерпретируемая как мера разброса, объяснимого с помощью регрессии.
Сумма ei2 ( yi y )2 — остаточная (необъясненная) сумма квадратов,
являющаяся мерой остаточного, не объясненного уравнением регрессии
разброса (разброса точек вокруг линии регрессии).
02.04.2013
Р. Мунипов
47
48.
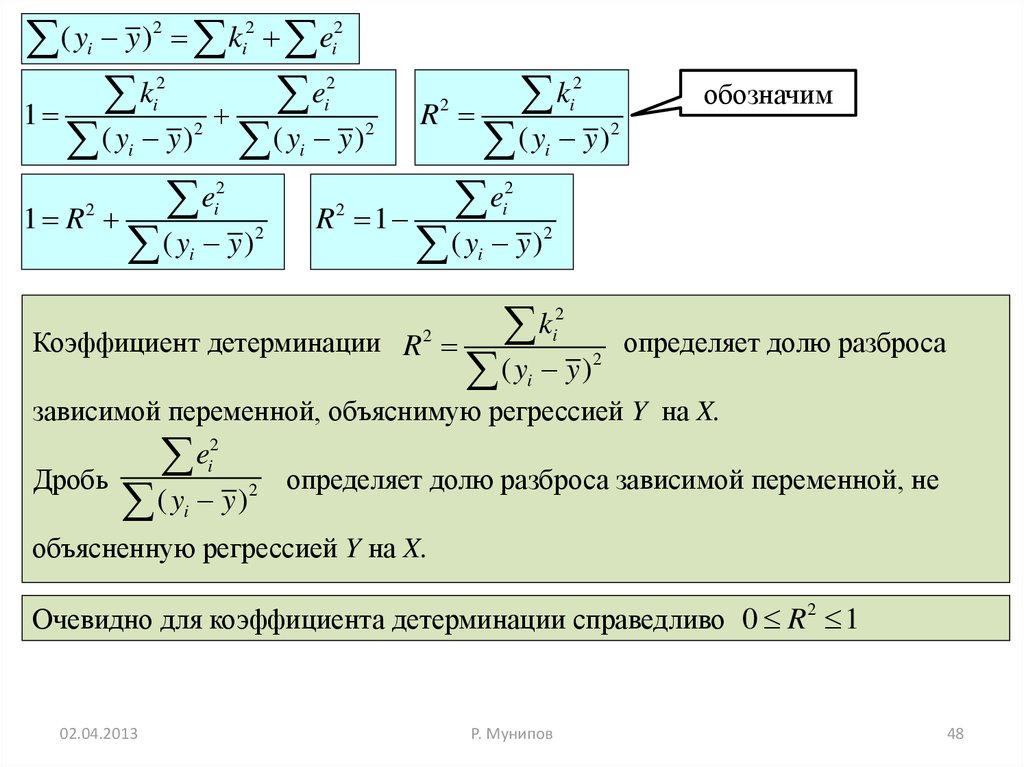
( y y ) k ek
e
k
1
R
( y y) ( y y)
( y y)
e
e
1 R
R 1
( y y)
( y y)
2
2
i
i
2
i
2
i
2
i
2
i
2
2
2
i
i
2
i
2
обозначим
2
i
2
i
2
2
2
i
i
Коэффициент детерминации R 2
k
2
i
( y y)
2
определяет долю разброса
i
зависимой переменной, объяснимую регрессией Y на X.
Дробь
e
2
i
( y y)
2
определяет долю разброса зависимой переменной, не
i
объясненную регрессией Y на X.
Очевидно для коэффициента детерминации справедливо 0 R 2 1
02.04.2013
Р. Мунипов
48
49.
Коэффициент детерминации R2 является мерой, позволяющей определить, вкакой степени найденная прямая регрессии дает лучший результат для
объяснения поведения зависимой переменной Y, чем горизонтальная
прямая Y y . Чем теснее линейная связь между X и Y, тем ближе
коэффициент детерминации к единице, чем слабее такая связь, тем R2 ближе
к нулю
R2
2
k
i
2
(
y
y
)
i
2
(
a
a
x
(
a
a
x
))
0 1i 0 1
( y y) ( y y)
( y y)
(a x a x )
(x x )
a
( y y)
( y y)
( x x )( y y ) ( x x )
( x x )( y y )
(x x ) ( y y) (x x ) ( y y)
2
2
i
i
i
2
1 i
1
2
i
2
1
2
2
i
i
2
i
i
i
i
i
2
i
i
2
i
2
i
2
( xi x )( yi y ) r 2
xy
2
2
( xi x ) ( yi y )
02.04.2013
2
2
2
2
Р. Мунипов
Коэффициент
детерминации равен
квадрату коэффициента
корреляции
49