




































































































































































 mathematics
mathematics programming
programming software
softwareSimilar presentations:










Методы обработки экспериментальных данных
1. Методы обработки экспериментальных данных
12. Введение
23. 1.1. Введение
Окружающий нас мир насыщен информацией…Ее НЕОБХОДИМО обрабатывать для принятия
управленческих решений.
Существует множество мат. пакетов: MatLab, Statistica,
Statgraphics…
НО ЕСТЬ проблема…. понимание и интерпретация
результатов!
НЕОБХОДИМО ЗНАТЬ И ПОНИМАТЬ КАК И ЧТО
ПРОИСХОДИТ ВНУТРИ МАТ. ПАКЕТОВ!
4. Области применения анализа экспериментальных данных
ФизикаХимия
Биология
Техника
Технологии
Гуманитарные науки
Прочая деятельность
5. 1.2. Основные этапы анализа данных
1. Планирование исбор данных
2. Предварительное
исследование
данных
4. Построение
моделей и проверка
гипотез
3. Оценка неизвестной
величины
6. 1.3. Структуры данных
Одномерные наборы данных (одна переменная) содержаттолько один признак, зарегистрированный для каждой
элементарной единицы.
Двумерные наборы данных содержат информацию о двух
признаках для каждого из объектов. В дополнение к обобщению
свойств каждой из этих двух переменных, рассматриваемых как
отдельные наборы одномерных данных,
Наборы многомерных данных содержат информацию о трех
или более признаках для каждого объекта. В дополнение к
обобщению
свойств
каждой
из
этих
переменных
(рассматриваемых как отдельные наборы одномерных данных)
и установлению зависимости между парами переменных (как
при анализе набора двумерных данных)
7. 1.3. Структуры данных
Количественные данныеДискретные
Непрерывные
Качественные данные
Порядковые
Номинальные
Временные ряды
8. 1.3. Структуры данных
Источники данныхПервичные
Планирование и сбор
данных
Маркетинговые
исследования
Вторичные
Поиск в
Internet
Социологические
опросы
Проведение
экспериментов
на производстве
Специальные
издания и
журналы
Покупка готовых
данных у
специализирующихся
компаний
9. 1.4. Что такое переменная?
Переменная (английский термин variable) — это то, что можноизмерять, контролировать или чем можно манипулировать в
исследованиях. Иными словами, переменная — это то, что
варьируется, изменяется, а не является постоянным (от
английского корня var).
ПРИМЕРЫ: анкетные данные, систолическое давление
пациентов, количество лейкоцитов в крови, цена акций, товаров,
услуг, потребление, инвестиции, доход, государственные закупки
товаров и услуг, инструмент государственного регулирования (в
экономике); рейтинг программ, доля зрителей, количество
посещений сайта (в рекламе); скорость, температура, объем,
масса в (физике) и т. д.
10. 1.4. Что такое переменная?
Так как значения переменных не постоянны, нужно научитьсяописывать их изменчивость.
Для этого
статистики.
придуманы
описательные
или
дескриптивные
Минимум и максимум — это минимальное и максимальное
значения переменной.
Среднее — сумма значений переменной, деленная на n (число
значений переменной).
Дисперсия и стандартное отклонение — наиболее часто
используемые меры изменчивости переменной. Дисперсия
меняется от нуля до бесконечности. Крайнее значение 0 означает
отсутствие изменчивости, когда значения переменной постоянны.
11. 1.4. Что такое переменная?
Медиана разбивает выборку на две равные части. Половина значенийпеременной лежит ниже медианы, половина — выше.
Медиана дает общее представление о том, где сосредоточены значения
переменной, иными словами, где находится ее центр. В некоторых
случаях, например при описании доходов населения, медиана более
удобна, чем среднее.
Мода представляет собой максимально часто встречающееся значение
переменной (иными словами, наиболее «модное" значение переменной),
например популярная передача на телевидении, модный цвет платья или
марка автомобиля и т. д.
А так же есть еще множество других статистик: квартили, коэффициент
асимметрии, эксцесс, коэффициент корреляции и др.
12. 1.5. Основные законы распределения случайных величин и их назначение
Законы распределения случайных величинслужат
математическими
моделями
для
реальных объектов и явлений, что позволяет в
некоторых случаях применять их для расчетов и
анализа ситуации.
13. 1.5. Основные законы распределения случайных величин и их назначение
Нормальное распределение особенно часто используется при анализе данных.Нормальное распределение дает хорошую модель для реальных явлений, в
которых:
1) имеется сильная тенденция данных группироваться вокруг центра;
2) положительные и отрицательные отклонения от центра равновероятны;
3) частота отклонений быстро падает, когда отклонения от центра становятся
большими.
f ( x)
1
e
2
( x m )2
2 2
14. 1.5. Основные законы распределения случайных величин и их назначение
Равномерноераспределение
полезно
при
описании
переменных, у которых каждое значение равновероятно,
иными
словами,
значения
переменной
равномерно
распределены в некоторой области.
1
, x [ , ]
f ( x)
0, x [ , ]
15. 1.5. Основные законы распределения случайных величин и их назначение
Экспоненциальное распределение. Имеют место события, которые на обыденномязыке можно назвать редкими. Если T – время между наступлениями редких
событий, происходящих в среднем с интенсивностью λ, то величина
имеет
экспоненциальное распределение с параметром λ (лямбда). Экспоненциальное
распределение часто используется для описания интервалов между
последовательными случайными событиями, например интервалов между
заходами на непопулярный сайт, так как эти посещения являются редкими
событиями.
f ( x ) e x , x 0
16. 1.5. Основные законы распределения случайных величин и их назначение
Распределение Лапласа, или, как его еще называют, двойногоэкспоненциального, используется, например, для описания распределения
ошибок в моделях регрессии.
1 x
f ( x ) e
, ( x )
2
17. 1.5. Основные законы распределения случайных величин и их назначение
Случайная величина h называется логарифмически нормальной, илилогнормальной, если ее натуральный логарифм (lnh) подчинен
нормальному закону распределения. Логнормальное распределение
используется, например, при моделировании таких переменных, как
доходы, возраст новобрачных или допустимое отклонение от стандарта
вредных веществ в продуктах питания. Итак, если величина x имеет
нормальное распределение, то величина y=ex имеет логнормальное
распределение.
1
f ( x)
e
2 x
(ln x ln a ) 2
2 2
18. 1.5. Основные законы распределения случайных величин и их назначение
Распределение Пуассона иногда называют распределением редкихсобытий. Примерами переменных, распределенных по закону Пуассона,
могут служить: число несчастных случаев, число дефектов в
производственном процессе и т д.
x
e
f ( x)
x!
19. 1.6. Краткий обзор современных программных средств для проведения анализа данных.
MATLAB – это высокопроизводительный язык для техническихрасчетов. Он включает в себя вычисления, визуализацию и
программирование в удобной среде, где задачи и решения
выражаются в форме, близкой к математической. Типичное
использование MATLAB – это:
• математические вычисления
• создание алгоритмов
• моделирование
• анализ данных, исследования и визуализация
• научная и инженерная графика
• разработка
интерфейса
приложений,
включая
создание
графического
20. 1.6. Краткий обзор современных программных средств для проведения анализа данных.
Mathcad – программное средство, среда для выполнения накомпьютере разнообразных математических и технических
расчетов, снабженная простым в освоении и в работе графическим
интерфейсом, которая предоставляет пользователю инструменты
для работы с формулами, числами, графиками и текстами.
В среде Mathcad доступны более сотни операторов и логических
функций, предназначенных для численного и символьного решения
математических задач различной сложности и применения этих
функций для анализа данных.
21. 1.6. Краткий обзор современных программных средств для проведения анализа данных.
STATISTICA – это универсальная интегрированная система,предназначенная для статистического анализа и визуализации
данных, управления базами данных и разработки пользовательских
приложений, содержащая широкий набор процедур анализа для
применения в научных исследованиях, технике, бизнесе, а также
специальные методы добычи данных.
С помощью реализованных в системе STATISTICA мощных языков
программирования, снабженных специальными средствами
поддержки, легко создаются законченные пользовательские
решения и встраиваются в различные другие приложения или
вычислительные среды.
22. 1.6. Краткий обзор современных программных средств для проведения анализа данных.
DeductorАналитическая платформа Deductor реализует практически все
современные подходы к анализу структурированной табличной
информации: хранилища данных (Data Warehouse), многомерный
анализ (OLAP), добыча данных (Data Mining), обнаружение знаний
в базах данных (Knowledge Discovery in Databases). Лучшим
способом изучить и понять целесообразность использования
современных технологий анализа - это испытать все на практике.
23. 1.6. Краткий обзор современных программных средств для проведения анализа данных.
STATGRAPHICS – это универсальный пакет для анализа и визуализацииданных. Отличительной особенностью пакета является наличие такого
инструмента как StatAdvisor, который помогает пользователям
интерпретировать полученные результаты, обеспечивает возможность
объединения в одном окне нескольких текстовых и графических подокон.
StatAdvisor дает пользователям понятные разъяснения полученных
результатов, определяет, являются ли эти результаты существенными, и
обращает особое внимание на любые возможные ошибки в анализе.
Пользователи получают немедленную интерпретацию результатов в
процедурах, доступных в как основной системе, так и в четырех
специальных модулях, поставляемых по выбору: Quality Control (контроль
качества), Experimental Design (планирование эксперимента), Time-Series
Analysis (анализ временных рядов) и Advanced Multivariate Method (анализ
вариаций).
24. Вопросы ?
2425. КЛАССИФИКАЦИЯ В РАСПОЗНАВАНИИ ОБРАЗОВ
2526. Схема системы распознавания
Система распознавания образов состоит из нескольких подсистем:Объект
Датчики
Формирователь
информативных
признаков
Обучающая выборка и решающее
правило
для
случая
двух
информативных признаков x1, x2 и
двух классов.
Классификатор
Решение
x2
(x , x ) 0
1
2
G1
( x , x ) 0
1
2
G2
(x , x ) 0
1
2
x1
27. Байесовская теория принятия решений при дискретных признаках
Одномерный вариантРассматриваем m классов (полную группу несовместных случайных событий) и
один дискретный информативный признак X.
По формуле Байеса вычисляем апостериорные вероятности для всех
рассматриваемых классов:
P( j | X xi )
p xi | j P ( j )
p xi
m
, pxi pxi |l P(l ) j 1, m
l 1
Выносим решение об истинности того класса (с номером ), для которого
апостериорная вероятность максимальная:
P( | X xi ) max P ( j | X xi ) , j 1, m
28. Байесовская теория принятия решений при дискретных признаках
Многомерный вариантДля простоты считаем, что имеются два информативных признака X и Y.
X принимает возможные значения x1,…,xn1, Y принимает возможные значения y1,
…,yn2.
По формуле Байеса вычисляем апостериорные вероятности для всех
рассматриваемых классов:
P (k | [( X xi )(Y y j )]) P (k | xi , y j )
p xi , y j | k P ( k )
m
pxi , y j |l P(l )
, k 1, m
l 1
Выносим решение об истинности того класса (с номером ), для которого
апостериорная вероятность максимальная:
P ( | xi , y j ) max P ( k | xi , y j ) , k 1, m
29. Байесовская теория принятия решений при дискретных признаках
Одномерный вариантX xi
1
Решающее
устройство
m
Многомерный вариант
X xi
Y yj
1
Решающее
устройство
m
30. Байесовская теория принятия решений при непрерывных признаках
f ( x | i ), i 1, 2,Одномерны вариант:
Апостериорные вероятности классов по формуле Байеса :
f ( x | i ) P (i )
P (i | x)
, i 1, 2
f ( x)
P ( j | x)
1
если
P(1| x )
0
G1
P( 2| x )
c
то принимается решение о 1-м классе, иначе о
2-м классе.
x
G2
P (1| x ) P (2| x )
31. Байесовская теория принятия решений при непрерывных признаках
Вероятность ошибки классификации при двух классах:Pîø1
f ( x | 1) P(1)dx
Pîø2
f ( x | 2) P( 2)dx
G1
G2
f ( x|1) P (1)
P
P
ош.2
G1
f ( x|2) P (2)
c
ош.1
x
G2
32. Идеи классификации
Случай 1. Известны полностью условные плотности распределения вероятности дляпризнаков:
f ( x | 1), , f ( x | m)
f ( x |i )
x2
f ( x|1)
f ( x|2)
G1
c
( x1 , x2 ) 0
( x1 , x2 ) 0
( x1 , x2 ) 0
x
G2
Одномерный случай
x1
Двумерный случай
33. Идеи классификации
Случай 2. Условные плотности распределения вероятности дляпризнаков известны не полностью, а с точностью до параметров:
1
2
f ( x , | 1), f ( x , | 2)
Неизвестные параметры θ1 и θ2 доопределяются с помощью одного из
методов математической статистики, например с помощью метода
максимального правдоподобия, на основе обучающей выборки.
Дальнейшая классификация проводится, как и в случае 1.
По обучающей выборке доопределяются и априорные вероятности:
P (1)
n1
n2
, P (2)
n1 n2
n1 n2
34. Идеи классификации
Случай 3. Условные плотности распределения вероятности неизвестны, ноизвестна обучающая выборка. Здесь возможны два варианта.
Вариант 1. Восстанавливается решающая функция.
Вариант 2. По обучающей выборке восстанавливаются условные плотности
35. Идеи классификации
Случай 4. Число классов неизвестно и нет обучающей выборки. Вернее, нетучителя, который мог бы измерения признаков разбить на группы, соответствующие
своим классам. Это самая сложная и распространенная на практике ситуация.
Приходится строить самообучающиеся системы классификации.
1) По
количеству
максимумов
определяем кол-во классов
2) Минимум позволяет разбить выборку
на две части – точка c0 (нулевое
приближение).
3) Далее
строится
процедура
последовательного (итерационного)
расчета порога c.
4) В итоге получаем случай 3.
36. Прямые методы восстановления решающей функции
1, если истинным является класс 1,yi
1, если истинным является класс 2.
y
1
(x)
x
-1
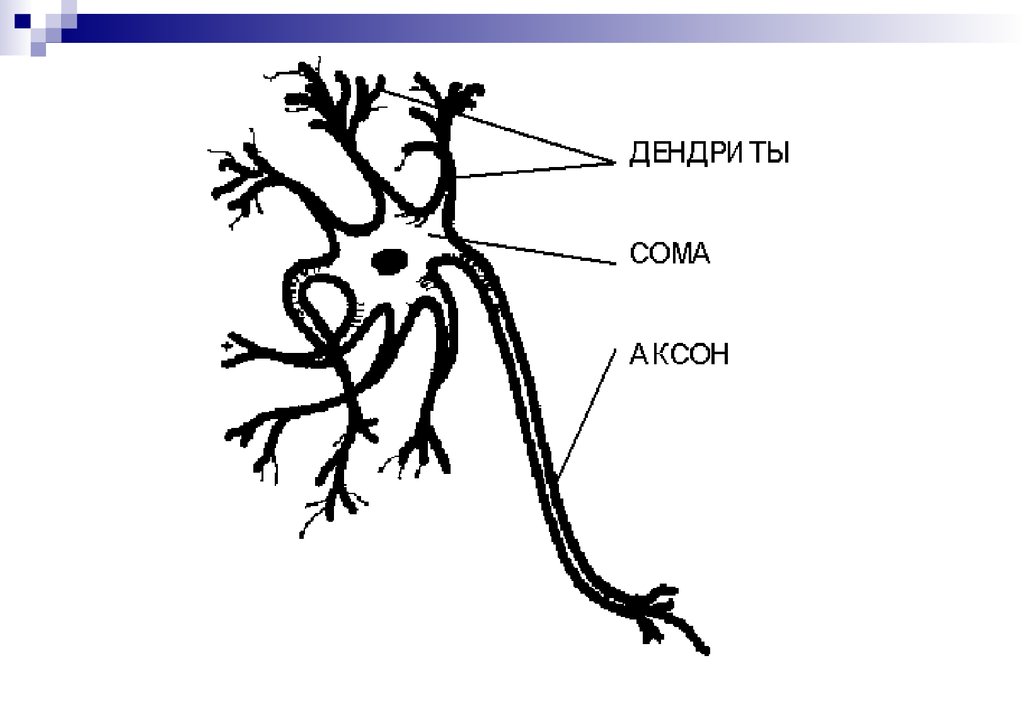
37. НЕЙРОННЫЕ СЕТИ: еще один подход к классификации
Идея взята из биологии:•Клетка - элементарный процессор, способный
к простейшей обработке информации
•Нейрон - элемент клеточной структуры мозга
•Нейрон осуществляет прием и передачу
информации в виде импульсов нервной
активности
•Природа импульсов - электрохимическая
38.
39. Интересные данные
Телоклетки имеет размер 3 - 100 микрон
Гигантский аксон кальмара имеет толщину 1 миллиметр и длину
несколько метров
Потенциал, превышающий 50 мВ изменяет проводимость
мембраны аксона
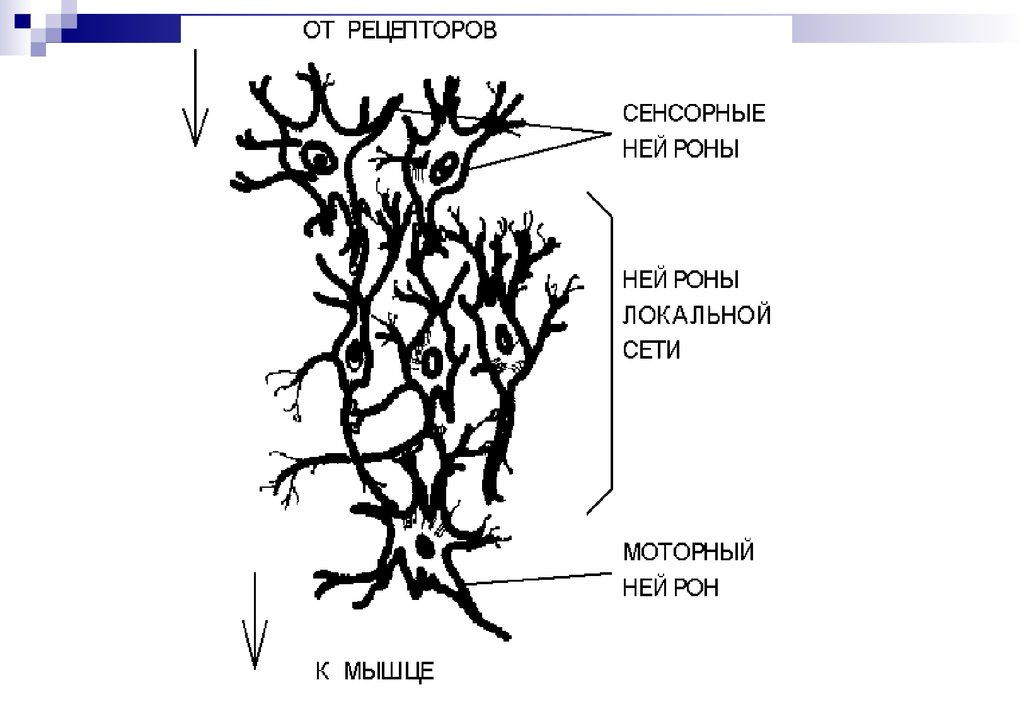
Общее число нейронов в ЦНС человека порядка
100.000.000.000
Каждая клетка связана в среднем с 10.000 других нейронов
Совокупность в объеме 1 мм*3 - независимая локальная сеть
40.
41. Персептроны
1 ( x)a1 a1 1 ( x)
j (x)
aj
M (x)
Преобразователи,
предикаты,
нейроны
aM
Усилители
( x, a ) Пороговое
устройство
sgn
Блок
обучения
1
1
42. Формальный нейрон
43. Нелинейное преобразование
Маккалок - ПиттсЛинейная
Сигмоидальная
44. Перцептрон Розенблата
Розенблат: нейронная сеть рассмотреннойархитектуры будет способна к воспроизведению любой
логической функции.
(неверное предположение)
45. Обучение сети
Обучить нейронную сеть это значит, сообщить ей,чего от нее добиваются.
Показав ребенку изображение буквы и получив
неверный ответ, ему сообщается тот, который
хотят получить.
Ребенок запоминает этот пример с верным
ответом и в его памяти происходят изменения в
нужном направлении.
46. Обучение перцептрона
Начальные значения весоввсех нейронов полагаются
случайными.
Сети предъявляется
входной образ x в
результате формируется
выходной образ.
47. STATISTICA Neural Networks
48. ВОПРОСЫ ?
4849. ПЛАНИРОВАНИЕ ЭКСПЕРИМЕНТА
4950. Что такое планирование эксперимента
u1Объект
um
y
Целью планирования эксперимента
является создание таких планов
вариации
входных
переменных,
которые обеспечивают более быстрое
и точное построение модели объекта.
Выход объекта состоит из неизвестного сигнала
(функции от входов) и центрированной помехи
y (u1 , , um ) h
51. Эксперименты в науке и промышленности
Экспериментальные методы широко используются как в науке,так и в промышленности, однако нередко с весьма
различными целями.
Обычно основная цель научного исследования состоит в том,
чтобы
показать
статистическую
значимость
эффекта
воздействия определенного фактора на изучаемую зависимую
переменную.
В условиях промышленного эксперимента основная цель
обычно заключается в извлечении максимального количества
объективной информации о влиянии изучаемых факторов на
производственный процесс с помощью наименьшего числа
дорогостоящих наблюдений.
52. Общие идеи
Обычно любая машина или станок, используемый напроизводстве, позволяет операторам изменять различные
настройки, влияя на качество производимого продукта.
Эксперименты позволяют инженеру, ответственному за
производство, улучшать настройки машины, а также
выяснить какие факторы вносят наиболее важный вклад в
качество продукции. Использование этой информации
позволяет
улучшить
настройки
системы,
достигнув
оптимального качества. Чтобы проиллюстрировать эти
рассуждения далее приводится несколько примеров.
53. Общие идеи
Пример 1: Производство красителей для ткани. Рассмотримэксперимент по производству некоторого красителя для ткани. В
этом случае качество производимой продукции описывается
насыщенностью, яркостью и стойкостью окрашенной ткани. Кроме
того, необходимо уточнить, что надо изменять для получения красок
различной
насыщенности,
яркости
для
удовлетворения
потребительского спроса. Другими словами, в этом эксперименте
нужно выявить факторы, наиболее заметно влияющие на яркость,
насыщенность и стойкость производимой краски. В примере
рассматривается 6 различных факторов, влияние которых
оценивается с помощью плана 2^6.
Результаты эксперимента показали, что имеется три наиболее
важных фактора: Полисульфидный индекс, Время и Температура.
Эту информацию теперь можно использовать для более тонкой
настройки аппаратуры, что бы улучшить качество красителя.
54. Общие идеи
Пример 2: Максимизация выхода химической реакции. Выходпродукта многих химических реакций зависит от времени и
температуры. К сожалению, эти функции не линейны и не
монотонны. Другими словами, нельзя сказать: “чем больше
продолжительность реакции, тем больше выход” и “чем выше
температура, тем больше выход”.
Формально
цель
эксперимента
заключается в том, чтобы найти
оптимальное
положение
на
поверхности выхода, образованной
двумя переменными: временем и
температурой.
55. Общие идеи
Пример 3: Улучшение поверхностной однородности припроизводстве кремниевых кристаллов. Производство надежных
микропроцессоров требует высоко отлаженного производственного
процесса. Отметим, что в данном примере одинаково, если не более
важно,
контролировать
как
изменчивость
некоторых
производственных характеристик, так и их средние значения.
Например, средняя толщина поверхностного слоя поликремниевой
подложки производственный процесс может быть отрегулирован
превосходно, однако, если изменчивость этого параметра велика, то
микрочипы будут недостаточно надежными. Не существует
теоретической модели, которые позволяла бы инженеру
предсказать, как эти факторы влияют на однородность поверхности
кристаллов. Следовательно, для оптимизации производственного
процесса нужно систематизировано проводить эксперименты на
различных уровнях факторов.
56. Что такое планирование эксперимента
AB
C
yi
1
–
–
–
y1
2
+
–
–
y2
3
–
+
–
y3
4
–
–
+
y4
n
Взвешивание трех тел по традиционной
схеме ("+" означает, что тело положено на
весы, "–" указывает на отсутствие тела на
весах).
2 ( вес А) 2 ( y2 y1 ) 2 2 ( y )
Взвешивание трех тел с использованием
планирования эксперимента.
2 ( вес А) 2
y1 y2 y3 y4 4 ( y )
2 ( y)
2
4
2
A
B
C
yi
1
–
–
–
y1
2
+
–
–
y2
3
–
+
–
y3
4
–
–
+
y4
n
Видно, что при новой схеме взвешивания дисперсия веса объектов
получается вдвое меньше, чем при традиционном методе взвешивания, хотя
в обоих случаях выполнялось по четыре опыта.
57. Построение линейной статической модели объекта
Считаем, что входами объекта являются u1,…,um, а выходом y.Уравнение линейной статической модели объекта имеет вид:
m
0
y 0 j (u j u j )
j 1
Необходимо на основе эксперимента (на основе
нескольких измерений входов и выхода объекта)
вычислить коэффициенты модели.
u2 2
1
u2
u20
4
u1
u1
u10
Экспериментальные точки для входных координат зададим в вершинах
гиперпрямоугольника.
Интервалы покачивания относительно базовой точки задаются
экспериментатором, и они определяют область изучения объекта.
u2
3
u1
58. Построение линейной статической модели объекта
С целью унификации процедур построения планов, исследования их свойств, расчетапараметров и исследования качества модели осуществляется переход от размерных
входных переменных u1,…,um к безразмерным x1,…,xm.
0
xj
uj uj
u j
u2 2
, j 1, m
Точки плана в вершинах прямоугольника в новых
координатах оказываются в вершинах квадрата с
единичными координатами. Центр плана переходит в
начало координат.
В итоге получается план:
1
u2
u20
4
u1
u1
u10
n
xo
x1
x2
yi
2
1
+
+
+
y1
1
2
+
–
+
yi
3
+
+
–
y3
4
+
–
–
y4
4
1
x2
1
1
1
u2
3
u1
3
x1
59. Построение линейной статической модели объекта
В новых безразмерных координатах x1,…,xm линейнаямодель также сохраняет линейный вид:
0 0 , j j u j , j 1, m
Параметры βi модели рассчитаем по
критерию наименьших квадратов :
m
y 0 j x j
0 0 , j
I
2
y
j 1
j
u j
n
m
i 1
j 1
, j 1, m
2
( yi 0 j x ji ) min
Предполагая, что измерения выхода некоррелированные и равноточные получаем
систему линейных алгебраических уравнений:
2
y
j
m
( xk , x j ) j
j 0
( x j , y) ( x j , y)
(xj, xj )
n
2
y ( xk ,
y ), k 0, 1, , m
n
n
i 1
i 1
( x k , x j ) x ki x ji , ( x k , y ) x ki yi
60. Крутое восхождение по поверхности отклика
В планировании эксперимента поверхностью отклика называют уравнение связивыхода объекта с его входами.
В 1951 году Бокс и Уилсон предложили использовать последовательный "шаговый"
метод движения к экстремуму выхода объекта.
Коэффициенты αi линейной модели
оценками составляющих градиента:
u2
являются
0
(u )
ai
; i 1, m
U i
Далее движение осуществляется по поверхности
отклика в направлении оценки градиента
u1
1 0
u u k
, где k - величина шага.
61. Полный факторный эксперимент
Полнымфакторным
экспериментом
называется
эксперимент,
в
котором
реализуются все возможные сочетания
уровней факторов. Если число факторов
равно m, а число уровней каждого фактора
равно p. то имеем полный факторный
эксперимент типа pm.
n
21
1
2
3
22
4
5
6
7
При построении линейной модели объекта
используется
полный
факторный
эксперимент
типа
2m.
Условия
эксперимента записываются в таблицы, в
которых строки соответствуют различным
опытам, а столбцы – значениям факторов.
Такие таблицы называются матрицами
планирования эксперимента.
23
8
9
10
11
2
4
12
13
14
15
16
x1
x2
x3
x4
yi
y1
y2
y3
y4
y5
y6
y7
y8
y9
y10
y11
y12
y13
y14
y15
y16
62. Полный факторный эксперимент
С использованием ортогонального плана первого порядкаможно определять не только коэффициенты βi, но и
коэффициенты βij перед факторами взаимодействия xixj (i≠j)
Например, при m=2 можно рассчитать и коэффициенты
модели:
y 0 1 x1 2 x2 12 x1 x2
n
x0
x1
x2
x1x2
yi
1
+
+
+
+
y1
2
+
–
+
–
y2
3
+
+
–
–
y3
4
+
–
–
+
y4
63. Дробные реплики
При большом числе входов объекта полный факторный эксперимент 2mсодержит большое число экспериментов. Можно этот план разбивать на блоки
(дробные реплики) с сохранением ортогональности плана. При этом по
меньшему числу точек определяются (также независимо друг от друга) все
коэффициенты линейной модели.
n
Чтобы получить дробную реплику, необходимо
за основу взять полный факторный эксперимент
(например 23) и в качестве новой переменной
взять один из столбцов (например x4),
соответствующий
фактору
взаимодействия
(например x4=x1x2). Для данного примера
дробная реплика обозначается как 24-1.
x1
x2
x3
X4=x1x2
1
+
+
+
+
2
–
+
+
–
3
+
–
+
–
4
–
–
+
+
5
+
+
–
–
6
–
+
–
+
7
+
–
–
+
8
–
–
–
–
Определяющий контраст (или определяющие контрасты, когда их несколько)
позволяет
установить
разрешающую
способность
дробной
реплики.
Разрешающая способность будет максимальной, если линейные эффекты будут
смешаны с эффектами взаимодействия наибольшего возможного порядка.
64. Насыщенные планы. Симплекс
Иногда исследователь ставит цель получения линейного уравнения моделипо планам, содержащим минимум точек (количество точек равно числу
коэффициентов). Такие планы называют насыщенными.
Ортогональный план проводится в вершинах правильного симплекса.
Правильным симплексом называется выпуклая правильная фигура в
многомерном пространстве, число вершин которой превышает размерность
этого пространства на единицу.
x1 x2
x1 x2 x3
x1
3a a
1 1 1
1 1 1
3a a
1
4
0
2a
1
1
1 1 1
x
1
0
1
x
x2
( 3a; a) ( 3a; a )
2
1 x
1
3 (0; 2a )
Эти планы центральные и ортогональные.
1 1
1
3
x1
3
2
x2
65. Насыщенные планы. Симплекс
Один из общих способов построения планов:x1
a1
a1
0
0
0
x2
a2
a2
2a2
0
0
x3
a3
a3
a3
3a3
0
xm
am
am
am
am
mam
66. Насыщенные планы. Планы Плаккета – Бермана
Плаккет и Берман в 1946 г. предложили способ построения насыщенных планов (сединичными координатами) при m=11, 19, 23, 27, 31, 35, 39, 43, 47, 51, 55, 59, 63, 67,
71, ... .
Задаются базовые строки. Каждая следующая строка матрицы планирования
образуется из исходной циклическим сдвигом вправо. Получается матрица размером
m x m. Последняя (m+1) -я строка матрицы планирования состоит из минус единиц.
Пример базисных строк:
Строка
m
n
11
12
++–+++–––+–
19
20
++––+++–+–+––––++–
23
24
+++++–+–++––++––+–+––––
31
32
––––+–+–+++–++–––+++++––++–+––+
35
36
–+–+++–––+++++–+++––+––––+–+–++––+–
67. Разбиение матрицы планирования на блоки
При проведении эксперимента выход объекта дрейфует. Если этотдрейф кусочно-постоянный, то его можно нейтрализовать, изменяя
порядок проведения эксперимента во времени. Для этого разбивают
матрицу планирования на блоки и последовательно реализуют (во
времени) эту матрицу: вначале один блок, затем другой и т. д.
В качестве примера рассмотрим ортогональный план 23 . Считаем, что
выход объекта имеет аддитивный дрейф на величину Δ1 (когда
проводятся эксперименты с номерами 1, 2, 3, 4) и на величину Δ2
(когда проводятся эксперименты № 5, 6, 7, 8). Этот дрейф приводит к
смещению на величину (4Δ1-4 Δ2)/8 параметра β3.
68. Разбиение матрицы планирования на блоки
Пример эксперимента в котором выход объекта дрейфует.n
x1
x2
x3
xдр=x1x2x3
1
+
+
+
+
y1=y1ист+Δ1
1
2
–
+
+
–
y2=y2ист+Δ1
2
3
+
–
+
–
y3=y3ист+Δ1
2
4
–
–
+
+
y4=y4ист+Δ1
1
5
+
+
–
–
y5=y5ист+Δ2
2
6
–
+
–
+
y6=y6ист+Δ2
1
7
+
–
–
+
y7=y7ист+Δ2
1
8
–
–
–
–
y8=y8ист+Δ2
2
yi
Номер блока
69. Разбиение матрицы планирования на блоки
Для устранения этого недостатка изменим порядок проведенияэксперимента, разбив план на 2 блока.
n
x1
x2
x3
xдр
1
+
+
+
+
y1=y1ист+Δ1
2
–
–
+
+
y2=y2ист+Δ1
3
–
+
–
+
y3=y3ист+Δ1
4
+
–
–
+
y4=y4ист+Δ1
5
–
+
+
–
y5=y5ист+Δ2
6
+
–
+
–
y6=y6ист+Δ2
7
+
+
–
–
y7=y7ист+Δ2
8
–
–
–
–
y8=y8ист+Δ2
yi
Номер блока
Блок 1
Блок 2
70. Обработка результатов эксперимента
1. Проверка однородности дисперсий. Если при реализации ортогональногоплана остается неизвестным, на самом ли деле дисперсии выходов (ошибок
измерения) одинаковы в каждой точке плана, то необходимо в каждой точке
плана осуществить несколько дополнительных измерений выхода, найти
оценку дисперсии (в каждой точке) и проверить гипотезу о равенстве
дисперсий.
Проверка однородности дисперсий производится с помощью различных
статистик. Простейшей из них является статистика Фишера, представляющая
собой отношение наибольшей из оценок к наименьшей:
2
max
F 2
min
Так же можно выполнить проверку с
использованием статистики Кочрена:
Gmax
n
2
2
max / j
j 1
71. Обработка результатов эксперимента
2. Проверка адекватности модели. Вычисляем остаточную сумму квадратов , делимее на число степеней свободы n-m-1 и получаем остаточную дисперсию (дисперсию
адекватности):
2
ад
n
1
2
(
y
y
i i)
n m 1 i 1
На основе дополнительного эксперимента объема n0 в одной из точек плана (например
в центре плана) строим оценку для дисперсии выхода объекта. Число степеней
свободы для оценки n0 -1. По статистике Фишера проверяем гипотезу о равенстве
дисперсий, которая совпадает с гипотезой об адекватности модели.
2 2
F ад / y
Если статистика не превосходит порогового значения, то принимается гипотеза об
адекватности модели. В противоположном случае эта гипотеза отвергается. Надо
заново строить модель, например, усложняя ее за счет введения дополнительных
факторов, либо отказываться от линейной модели и переходить к квадратичной модели.
72. Обработка результатов эксперимента
3. Проверка значимости коэффициентов заключается впроверке гипотезы H: bj = 0 для каждого j=1,…,m.
Вычисляется статистика Стьюдента:
j
t
y / n
Если |t|<c, где с – пороговое значения из таблицы Стьюдента, то
принимается гипотеза о том, что коэффициент модели βj
незначимо отличается от нуля. В этом случае данный член
модели можно опустить, но после этого упрощения модели ее
надо проверить на адекватность.
73. Обработка результатов эксперимента
4. Интерпретация модели. Производится качественное сопоставлениеповедения полученной модели с реальными процессами объекта. При
этом привлекается информация от экспертов (например технологов),
детально изучивших объект. Знак коэффициентов βj , линейной модели
показывает характер влияния входа объекта на выход. Знак "+"
свидетельствует о том, что с увеличением входа (фактора) растет
величина выхода объекта и наоборот. Величина коэффициентов βj –
количественная мера этого влияния.
Если характер связи между входами и выходом объекта на основе
построенной модели не соответствует реальным связям (на базе
информации от экспертов) в объекте, то такую модель надо поставить
под сомнение либо полностью отказаться от нее.
74. Ортогональное планирование второго порядка
Построение планов второго порядка – задача в математическом отношениизначительно более сложная, чем в случае построения планов первого
порядка. Модель второго порядка при m=3 имеет вид:
y 0 1 x1 2 x2 3 x3 12 x1 x2 23 x2 x3 13 x1 x3 11 x12 22 x22 33 x33
Для вычисления коэффициентов модели второго порядка необходимо
варьировать переменные не менее чем на трех уровнях. Это вызывает
необходимость постановки большого числа опытов. Полный факторный
эксперимент содержит 3m точек.
m
1
2
3
4
5
6
7
3m
3
9
27
81
243
729
2187
Композиционный план n0=1
5
9
15
25
43
77
143
75. Ортогональное планирование второго порядка
В 1951 году Бокс и Уилсон предложили составлять композиционные планы. Числоточек плана равно величине n=n1+2m+n0 . Здесь n1– число точек полного факторного
эксперимента или дробной реплики 2m – число парных точек, расположенных на осях
координат; n0 – число опытов в центре плана.
x2
*
*
x3
*
*
* x1
*
x2
*
*
*
*
x1
Точки на осях координат называют звездными
точками. Их количество равно удвоенному
числу факторов. Расстояние от центра плана
до звездной точки одинаково. Его обозначают
буквой α и называют звездным плечом.
Композиционные
планы
имеют
следующие
положительные
свойства:
1. Они могут быть получены в результате достройки планов первого порядка.
2. Дополнительные точки на осях координат и в центре плана не нарушают
ортогональности для столбцов, соответствующих факторам xj и эффектам
взаимодействия xixj .
76. Ортогональное планирование второго порядка
Пример композиционного плана:n
x0
x1
x2
1
+
+
2
+
3
xl
xl2
1 n 2
xli xl2 xl2
n i 1
x1x2
x12
x22
x1’
x2’
+
+
+
+
◊
◊
–
+
–
+
+
◊
◊
+
+
–
–
+
+
◊
◊
4
+
–
–
+
+
+
◊
◊
5
+
α
0
0
α2
0
Δ
□
6
+
-α
0
0
α2
0
Δ
□
7
+
0
α
0
0
α2
□
Δ
0 11 x1 22 x2 1 x1 2 x2 12 x1 x2 11 x1 22 x2
8
+
0
-α
0
0
α2
□
Δ
0 1 x1 2 x2 12 x1 x2 11 x1 22 x2
9
+
0
0
0
0
0
□
□
С учетом новых переменных xl’ получаем
следующее уравнение модели (для
случая m=2):
2
2
y 0 1 x1 2 x2 12 x1x2 11 ( x1 x1 ) 22 ( x2 x2 )
2
2
77. Ротатабельное планирование
Если эта дисперсия одинакова на равном удалении от центраплана, то такой план называется ротатабельным.
Ортогональный план первого порядка является
ротатабельным.
Построение ротатабельного плана второго порядка из
симплексных планов:
x2
x1
78. Метод случайного баланса
Часто влияние факторов на выходную координату объекта имеет затухающийэкспоненциальный вид:
y
100 %
80 %
60 %
40 %
20 %
0
В 1956 году Сатерзвайт предложил метод
случайного баланса для отсеивания небольшого
числа значимых факторов на шумовом поле.
Метод базируется на постановке экспериментов
по плану, содержащему координаты точек,
выбранных случайным образом.
x1 x2 x3 x4 x5 x6 x7 x8 x9 x10
Построение матрицы планирования осуществляют следующим образом. Все
факторы разбивают на группы. Затем для каждой группы строят матрицы
планирования, беря за основу полный факторный эксперимент или дробные
реплики. План проведения эксперимента образуется путем случайного смешивания
строк соответствующих базовых планов (для групп факторов). Полученный план
реализуется на объекте, и результаты анализируются с помощью диаграмм
рассеяния.
79. Метод случайного баланса
yПример:
n
x1
x2
x1x2
y
y1
1
+
+
+
24
27
2
–
+
–
27
27
3
+
–
–
26
29
4
–
–
+
29
29
29
28
27
26
25
24
3
2
x1
0
x2 x1
x2
Каждая из диаграмм содержит точки, соответствующие результатам эксперимента.
Эти точки разбиты на две группы. Одна из них соответствует тем опытам, когда
исследуемый фактор находился на нижнем уровне, вторая – тем опытам, когда
фактор находился на верхнем уровне. Для каждой из групп находятся оценки
медианы и вычисляется их разность (из оценки медианы правой группы вычитается
оценка медианы левой).
Разность между оценками медиан количественно оценивает линейное влияние
фактора на выход объекта.
80. ВОПРОСЫ ?
8081. МЕТОДЫ НЕПАРАМЕТРИЧЕСКОЙ ОБРАБОТКИ ИНФОРМАЦИИ
8182. Оценивание функционалов
Необходимо по выборке x1,…,xn случайной величины X найти оценкуфункционала
∞
Φ= ∫ ϕ( x, f (x), )⋅ f ( x)dx
−∞
Рассмотрим некоторые примеры функционалов:
m xf ( x ) dx M { X } – математическое ожидание.
( x m ) 2 f ( x )dx M {( X m ) 2 } – дисперсия.
2
H ( X ) (log f ( x)) f ( x)dx – приведенная энтропия.
83. Оценивание функционалов
Схема построения оценки Фn следующая. Вначале строится оценка дляплотности вероятности fn(x), а затем она подставляется в функционал.
Основным свойством оценки Фn(x1,…,xn) является ее состоятельность. Оценка Фn
функционала Ф называется состоятельной, если:
p
n
lim P{| n | } 0
n
Требование состоятельности определяет практическую пригодность оценок, ибо в
противоположном случае (при несостоятельности оценок) увеличение объема
исходной выборки не будет приближать оценку к "истинной" величине. По этой
причине свойство состоятельности должно проверяться в первую очередь.
Оценка Фn параметра Ф называется несмещенной, если:
M { n }
Она является асимптотически несмещенной, если:
M { n } n
84. Простейшие оценки функции и плотности распределения вероятности
По упорядоченной независимой выборке x1,…,xn случайной величины Xпостроим оценку Fn(x) для функции распределения:
F ( x ) P{ X x}
m число исходов, благоприят ствующих событию { X x}
1 n
Fn ( x )
1( x xi )
n общее число опытов
n i 1
1, z 0,
1( z )
0, z 0.
где 1(z) – единичная функция:
Fn ( x )
1
0
1
n
1
n
1
n
x1
1
n
1
n
1
n
1
n
x2 x3 x4 xn 2 xn 1 xn
x
85. Простейшие оценки функции и плотности распределения вероятности
Так как плотность распределения f(x) связана с функцией распределения F(x)через линейный оператор дифференцирования :
f ( x)
dF ( x )
dx
Можно получить оценку для плотности распределения :
dFn ( x ) 1 n d
1 n
f n ( x)
1( x xi ) ( x xi )
dx
n i 1 dx
n i 1
Здесь δ(x-xi) – дельта-функция Дирака. Она имеет "игольчатый" ("гребенчатый") вид:
уходит до ∞ в точке xi , а при остальных значениях аргумента x равна нулю и обладает
свойствами:
1)
xi
( x x )dx 1
i
xi
- площадь под дельта функцией единичная.
селектирующее свойство дельта-функции позволяет
x
легко
выполнять
интегрирование.
Интеграл
2) ( x ) ( x xi )dx ( xi )
оказывается равным подынтегральному выражению,
x
стоящему перед дельта-функцией, в особой точке.
i
i
86. Простейшие оценки функции и плотности распределения вероятности
Первое свойство показывает, что, несмотря на экзотическое поведение дельтафункции, площадь под ней единичная.Второе селектирующее свойство дельта-функции позволяет легко выполнять
интегрирование. Интеграл оказывается равным подынтегральному выражению,
стоящему перед дельта-функцией, в особой точке.
f n ( x)
x1
x2
x3 x4 xn 2 xn 1
xn
x
Оценка плотности распределения является несмещенной, но несостоятельной. В явном
виде её использовать нельзя. Ею удобно пользоваться при вычислении оценок
моментов (математического ожидания, дисперсии и др.) для случайной величины или
для