














































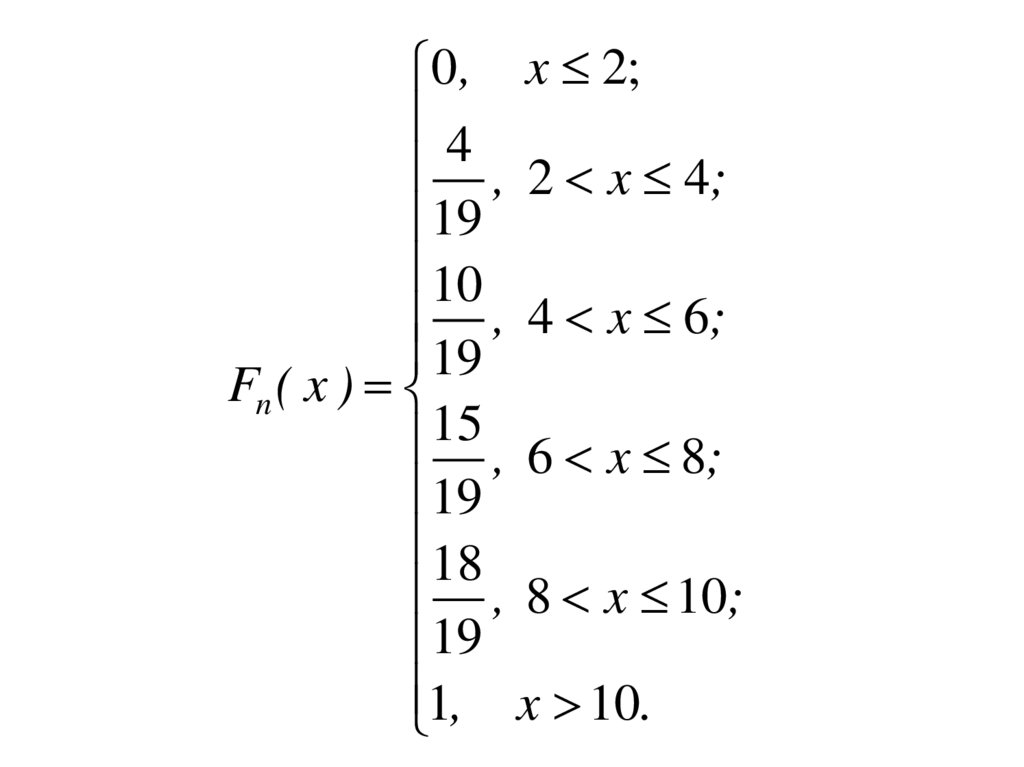






















 mathematics
mathematicsSimilar presentations:





")

")


Обработка выборки. Практическое занятие
1. Обработка выборки
Практическое занятие2. Генеральная совокупность
Генеральной совокупностьюназывается множество всех
мыслимых измерений
некоторой случайной
величины Х.
3. Генеральная совокупность
Генеральная совокупность Ханалогична случайной величине Х.
Это означает, что ГС обладает
законом распределения,
математическим ожиданием,
дисперсией, модой, медианой и т. д.
4. Генеральная совокупность
Генеральная совокупностьможет быть:
конечной и бесконечной;
дискретной и непрерывной.
5. Генеральная совокупность
Рост человека – бесповторнаябесконечная генеральная
совокупность.
Результат бросания игральной
кости 10000 раз – повторная
конечная генеральная
совокупность.
6. Выборка
Выборочной совокупностью иливыборкой называется некоторой
множество значений х1, х2, …, хn
генеральной совокупности Х,
предназначенное для
непосредственного исследования.
Количество элементов выборки n –
называется объемом выборки.
7. Выборка
Выборка бываетдискретной и непрерывной
повторной и бесповторной.
8. Выборка
Результат бросания игральнойкости 20 раз.
1, 3, 2, 2, 4, 1, 5, 3, 6, 1,
6, 5, 6, 5, 4, 3, 4, 2, 1, 3.
Повторная дискретная
объема n = 20.
выборка
9. Выборка
Результат измерения роста 20человек.
176,5; 163,3; 173,4; 182,1; 152,3;
162,2; 200,0; 194,1; 154,4; 170,8;
160,0; 173,3; 167,6; 168,2; 166,1;
176,6; 175,9; 165,8;151,5; 178,6
Бесповторная непрерывная выборка
объема n = 20.
10. Выборка
Должна бытьрепрезентативной - каждый
элемент ГС имеет равную
вероятность попасть в
выборку.
11.
Крупномасштабный почтовый опрос престижного американскогожурнала «The Literary Digest», проведенный во время предвыборной
кампании 1936 года, занимает важное место в истории эмпирической
социологии. Исследование должно было определить, кого хотят видеть
американцы своим президентом: Франклина Д. Рузвельта, кандидата
от демократической партии, баллотировавшегося на второй срок, или
Элфа Лэндона, кандидата республиканской партии.
Итоги электорального опроса не оставляли никаких сомнений:
безоговорочную победу на предстоящих выборах одерживал
республиканец Лэндон, за которого собирались голосовать 55%
респондентов. Рузвельта поддержали участники опроса в количестве
только 41%.
Результат выборов стал полной неожиданностью для «The Literary
Digest»: действовавший президент Ф. Д. Рузвельт получил 61% голосов
избирателей, в то время как его соперник — 37%.
12.
Для составления списка респондентов были использованы телефонныекниги и регистрационные списки владельцев автомобилей каждого
территориального округа во всех сорока восьми штатах.
Самой распространенной точкой зрения на причину неудачи опроса
«The Digest» уже более семидесяти лет остается мнение о
некорректной процедуре составления выборки. Респонденты были
отобраны, главным образом, из обширной картотеки журнала, которую
владельцы создали с целью привлечения новых подписчиков. Как
телефон, так и автомобиль в тридцатых годах прошлого века
являлись определенным показателем уровня дохода. Таким образом,
необъективно большую долю в выборке представляли состоятельные
американцы. Учитывая, что во время выборов 1936 года существовала
тесная взаимосвязь между размером доходов и партийными
предпочтениями, результат можно было прогнозировать еще до
начала опроса. В то же время процедура исключала значительную
часть электората — бедняков, которые предположительно обеспечили
победу Рузвельта: многие сторонники президента не участвовали в
опросе только потому, что не имели автомобиля и телефона.
13. Суть выборочного метода
Суть выборочного методазаключается в том, что
по выборке делается вывод о
генеральной совокупности в
целом.
14. Выборочный метод является единственно возможным
1. Генеральная совокупностьбесконечна.
2. Объекты генеральной
совокупности уничтожаются
при измерении.
3. Измерения очень
дорогостоящи.
15. Упорядоченная выборка
Часто первым шагомобработки выборки
является ее упорядочение
по возрастанию. Во многих
источниках упорядоченная
выборка называется
ранжированным рядом.
16. Выборка
Выборка1 3 2 2 4 1 5 361
6 5 6 5 4 3 4 213
Упорядоченная выборка
17. Обработка дискретной выборки
Если выборка сделана измножества значений
дискретной случайной
величины, то она может
быть сгруппирована в
дискретный вариационный
ряд.
18. Варианты и частоты
Варианты хi - этонеповторяющиеся выборочные
значения.
Частота варианты n i - это
число, показывающее, сколько раз
варианта встречается в выборке.
Относительная частота
варианты
w i= n i / n.
19. Дискретный вариационный ряд
Дискретный вариационныйряд или просто вариационный
ряд – это соответствие между
вариантами хi их частотами ni ;
или вариантами хi и их
относительными частотами wi.
20. Дискретный вариационный ряд
xix1
x2
…
xk
ni
n1
n2
…
nk
21. Условие нормировки
kn
n
i
i 1
22. Дискретный вариационный ряд
xix1
x2
…
xk
wi
w1
w2
…
wk
23. Условие нормировки
kk
ni
w
i
i 1
i 1 n
k
1
1
ni n 1
n i 1
n
24. Выборка
Упорядоченная выборка1, 1, 1, 1, 2, 2, 2, 3, 3, 3,
3, 4, 4, 4, 5, 5, 5, 6, 6, 6.
xi
1
2
3
4
5
6
ni
4
3
4
3
3
3
wi
4/20 3/20 4/20 3/20 3/20 3/20
25. Интервальный ряд
Если выборка сделана измножества значений
непрерывной случайной
величины, то она может быть
сгруппирована в
интервальный
вариационный ряд.
26. Интервальный ряд
Интервальный вариационныйряд или просто интервальный ряд
– это соответствие между
частичными интервалами
(интервалами группировки) [ai-1; аi)
и их частотами (или относительными частотами).
27. Интервальный ряд
Частота i-го интервалаni - это число, показывающее,
сколько раз значение выборки
встречается внутри данного
интервала [ai-1; аi).
28. Интервальный ряд
ai-1 – аi а0 – а1 …ni
n1
…
аk+1 – аk
nk
29. Выборка
Результат измерения роста 20человек.
176,5; 163,3; 173,4; 182,1; 152,3;
162,2; 201,0;194,1; 154,4; 170,8;
165,5; 173,3; 167,6; 168,2; 166,1;
176,6; 175,9; 165,8;151,5; 178,6
Бесповторная выборка объема n = 20.
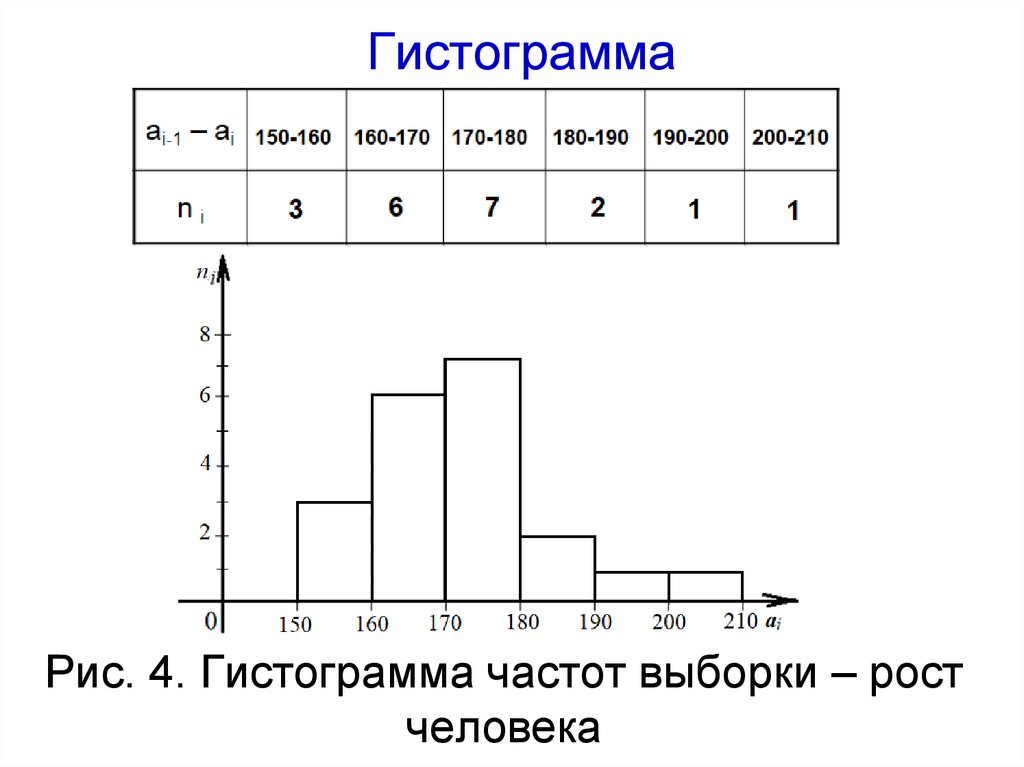
30. Интервальный ряд
176,5; 163,3; 173,4; 182,1; 152,3; 162,2;200,0;194,1; 154,4; 170,8; 160,0; 173,3; 167,6;
168,2; 166,1; 176,6; 175,9; 185,8;151,5; 178,6
ai-1 – аi
150-160
ni
3
6
7
wi
3/20
6/20
7/20
160-170 170-180
180-190
190-200
200-210
2
1
1
2/20
1/20
1/20
31. Накопленные частоты
Для сгруппированных выборок можноввести понятие накопленной частоты.
Накопленной частотой
данной группы выборки
называется сумма групповых
частот с первой по частоту данной
группы. Обозначается – ni⁕
ni⁕ = n1+ n2+…+ ni
32. Накопленные частоты
Накопленной частотой i-ойварианты – называется
количество выборочных данных,
не превосходящих хi .
Накопленной частотой i-ого
интервала называется
количество выборочных данных,
лежащих от начала выборки до
конца этого интервала.
33. Накопленные частоты
Относительной накопленнойчастотой i-ой группы
выборки – называется число
wi
ni
n
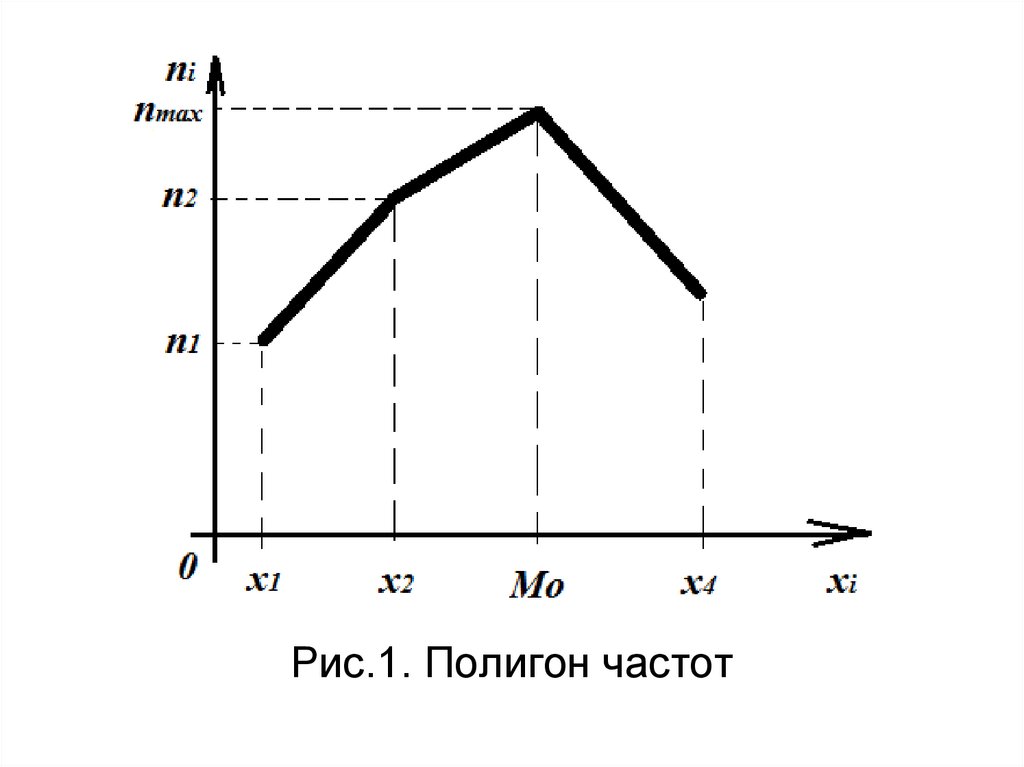
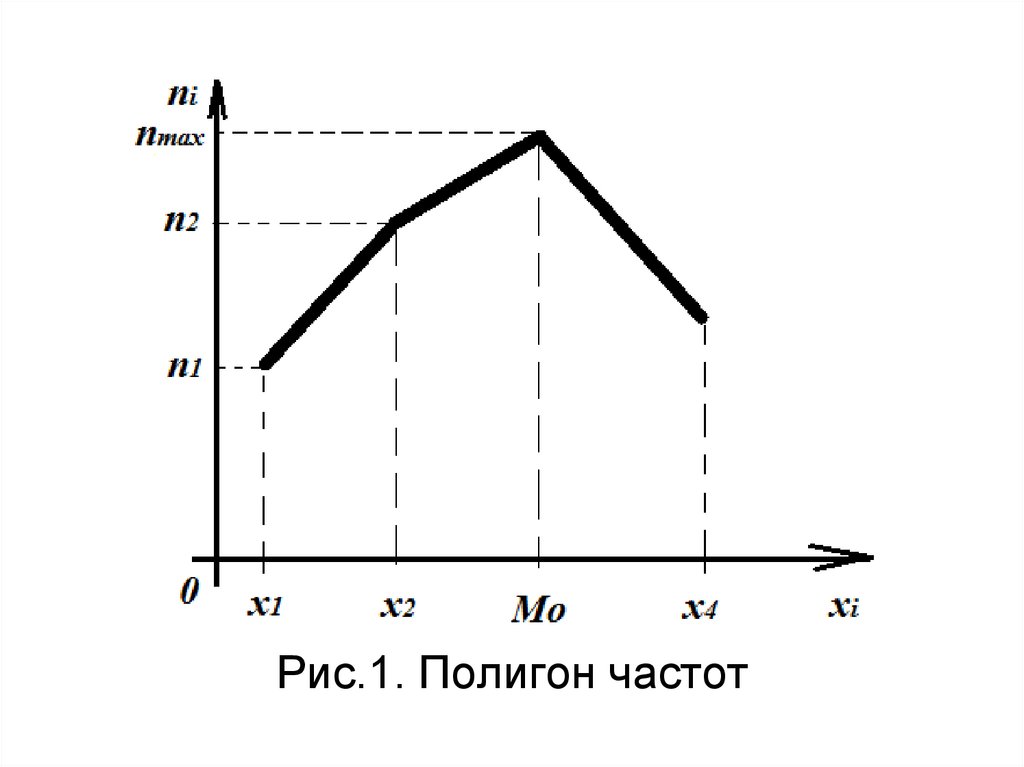
34. Графические представления выборки
Полигон частот – этоломаная линия с узлами в
точках (x i, n i) или (w i, n i).
.
По полигону можно найти моду
дискретного вариационного ряда.
35.
Рис.1. Полигон частот36. Полигон частот
Рис. 2. Полигон частот для дискретноговариационного ряда – число очков на кости
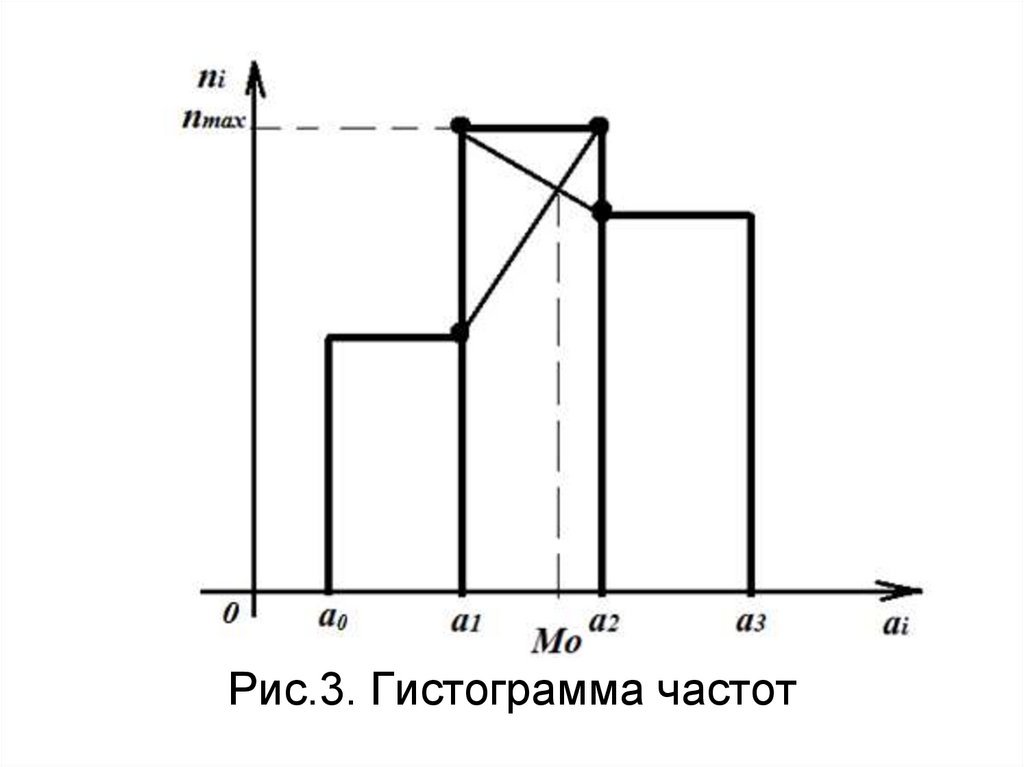
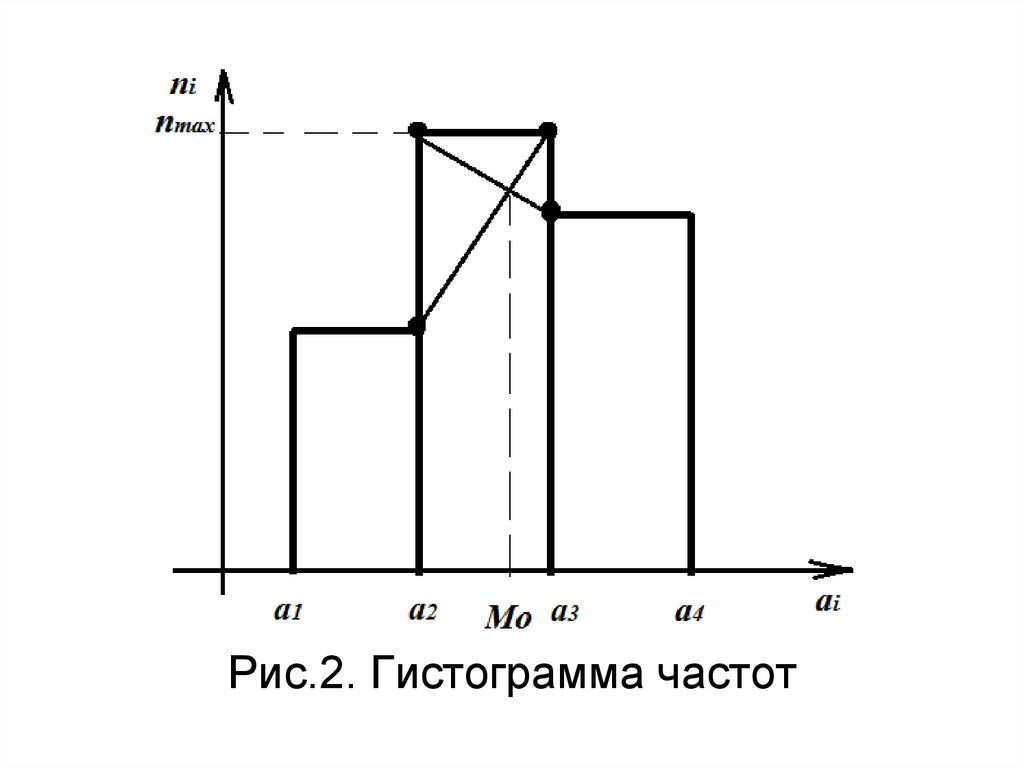
37. Графические представления выборки
Гистограмма частот – этоступенчатая фигура, состоящая из
прямоугольников, основаниями
которых являются частичные
интервалы, а высоты соответствуют
частоте.
По гистограмме можно найти
моду интервального ряда.
38.
Рис.3. Гистограмма частот39. Гистограмма
Если строят гистограммуотносительных частот, то высоты
соответствуют относительной частоте.
Если интервалы имеют разную
длину, то по оси ординат откладывают
плотность частоты или плотность
относительной частоты (ai – длина i-го
интервала):
40.
ГистограммаРис. 4. Гистограмма частот выборки – рост
человека
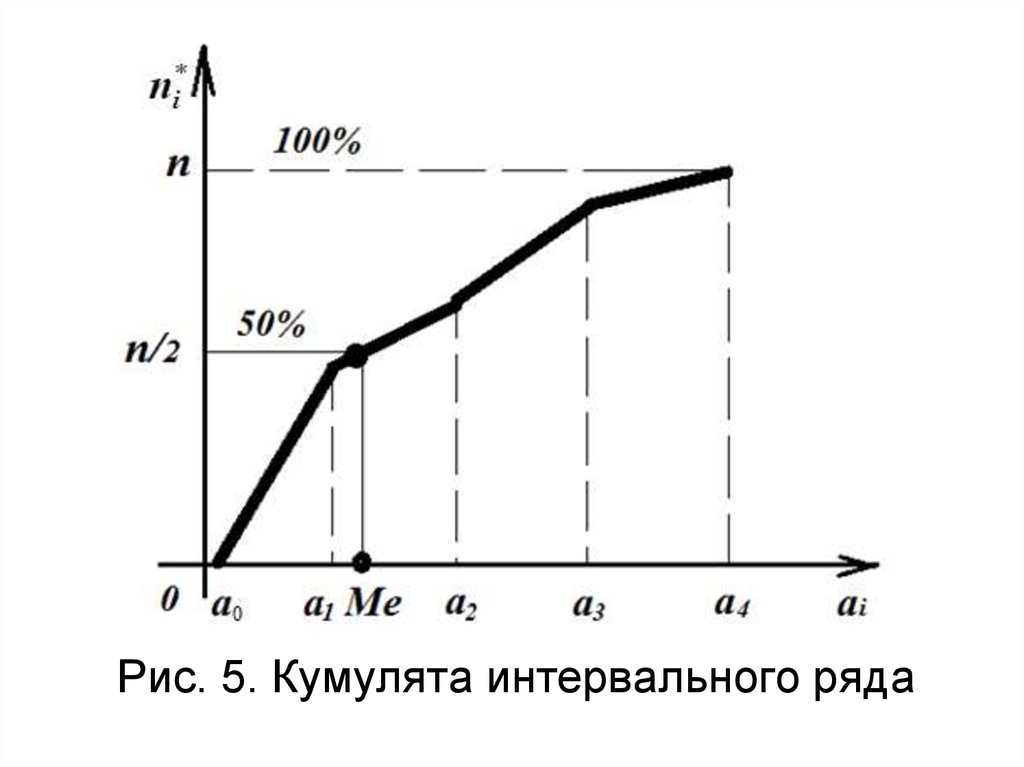
41. Графические представления выборки
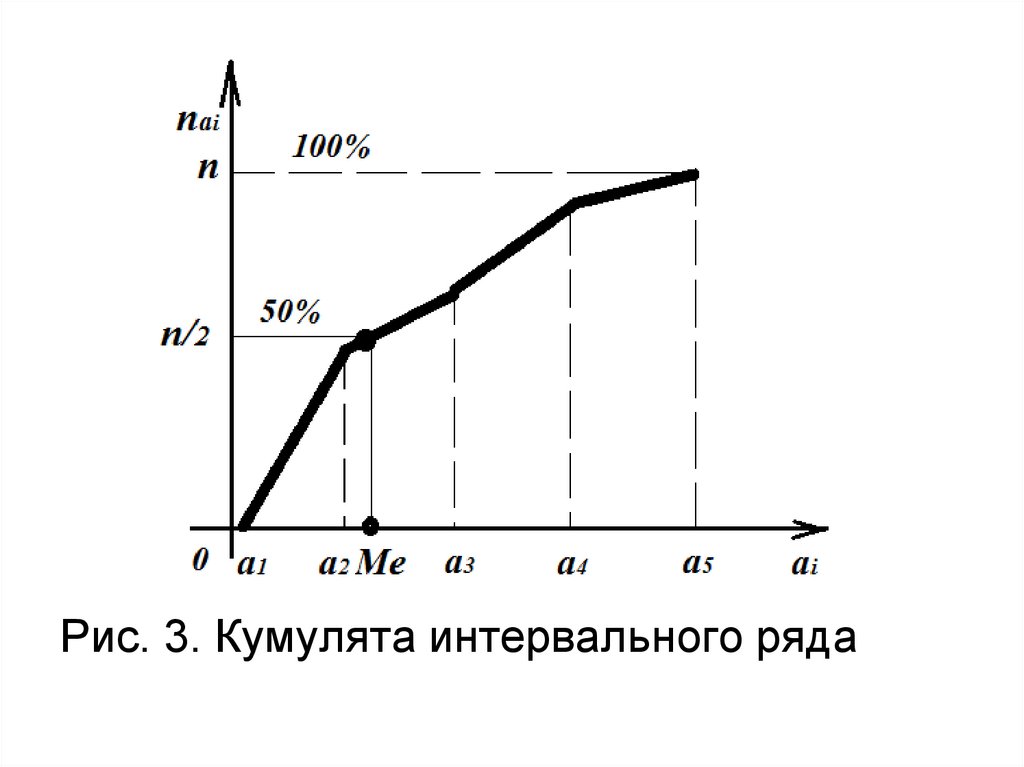
Кумулята – это ломанаялиния, с узлами в точке
(xi,ni⁕) дискретного
вариационного ряда и с
узлами в точках (ai,ni⁕) для
интервального ряда.
42.
Рис. 5. Кумулята интервального ряда43. Кумулята
ai-1 – аi1-2
2-3
3-4
3-5
ni
4
8
6
2
Построим дополнительную таблицу для построения кумуляты.
аi
1
2
3
4
5
ni⁕
0
4
12
18
20
Рис. 6. Пример построения кумуляты
44. Графические представления выборки
При построении кумулятыинтервального ряда
ординатой числа а0 – левой
границы первого интервала
принято считать 0. По
кумуляте можно найти
медиану интервального ряда.
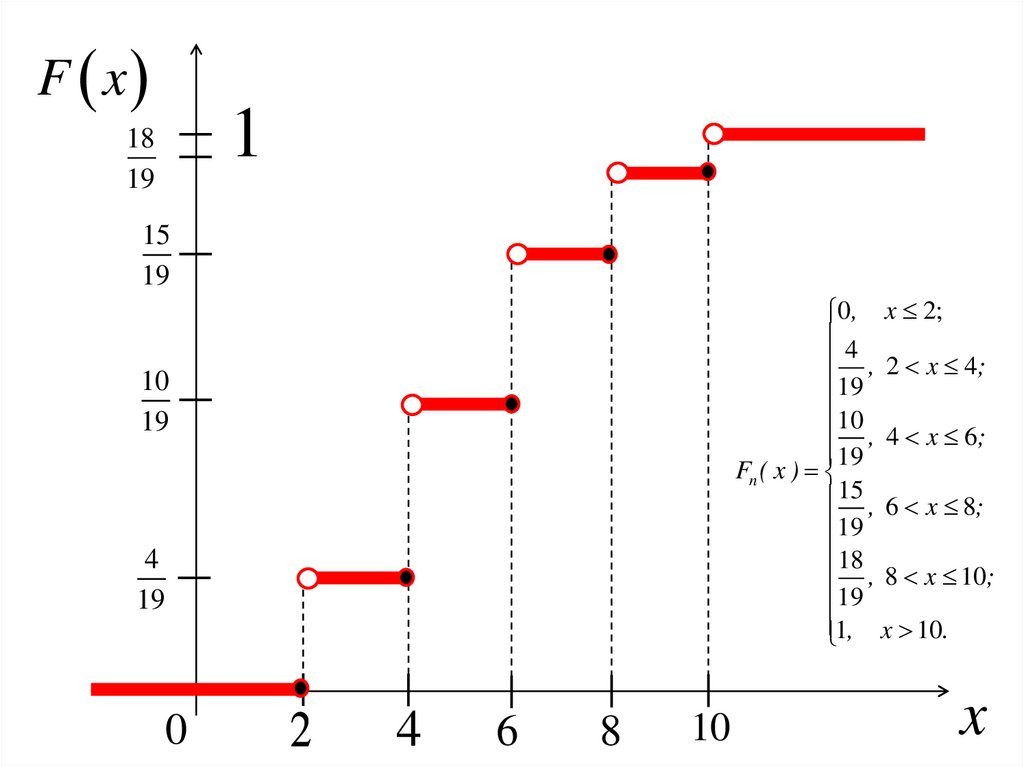
45. Эмпирическая функция распределения
Эмпирическая функцияраспределения находится по
формуле:
nx
Fn ( x )
n
Здесь n – это объем выборки; –
это число выборочных данных,
строго меньших х.
46. Свойства функции эмпирической функции распределения
1. 0 Fn x 12. неубывающая функция, то есть
x1 x2 Fn x1 Fn x2
3. Fn x 0, x xmin
Fn x 1, x xmax
Эмпирическая функция распределения – ступенчатая.
Необходимо разбить ось на интервалы точками xi, и
воспользоваться формулой для каждого интервала в
отдельности.
47.
24
xi
ni
4
6
6
5
8
3
10
1
Найдем объем выборки.
k
n ni 4 6 5 3 1 19
i 1
48.
xini
2
4
4
6
6
5
8
3
10
1
Эмпирическая функция
распределения – ступенчатая.
Разобьем ось на интервалы
точками 2, 4, 6, 8, 10, и применим
данную формулу для каждого
интервала в отдельности.
49.
xini
1)
2
4
4
6
6
5
8
3
х 2
nx 0
Fn ( x )
0
n 19
10
1
50.
xini
2)
2
4
4
6
6
5
8
3
2 x 4
nx 4
Fn ( x )
n 19
10
1
51.
xini
3)
2
4
4
6
6
5
8
3
10
1
4 x 6
nx 4 6 10
Fn ( x )
n
19
19
52.
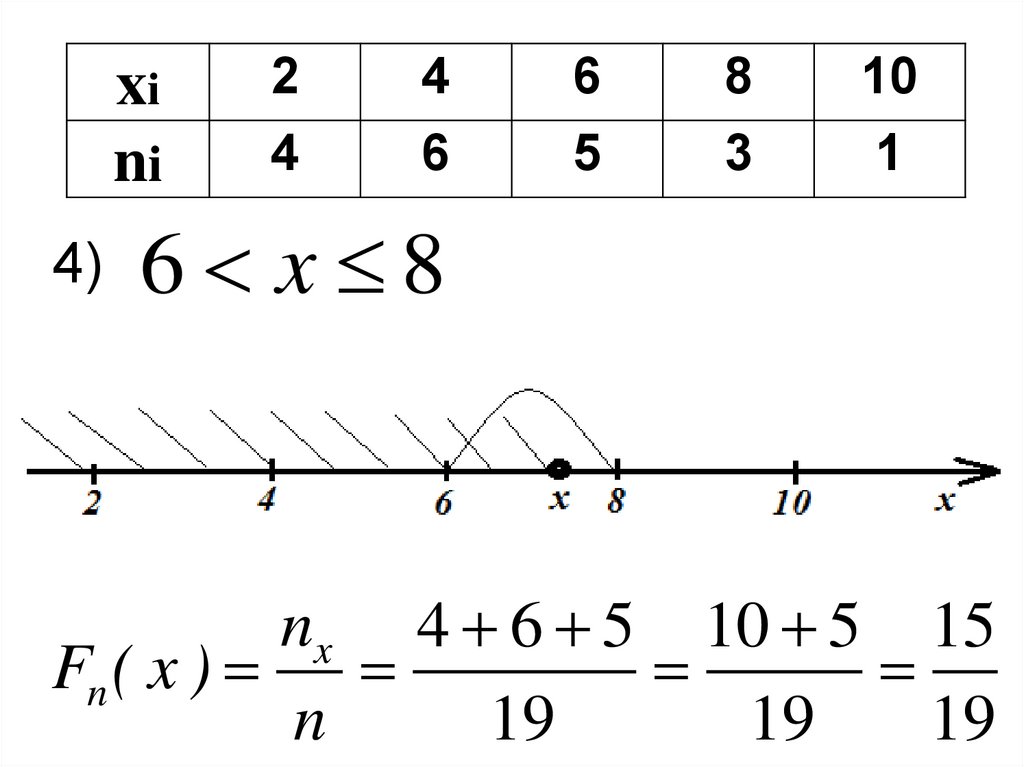
xini
4)
2
4
4
6
6
5
8
3
10
1
6 x 8
nx 4 6 5 10 5 15
Fn ( x )
n
19
19
19
53.
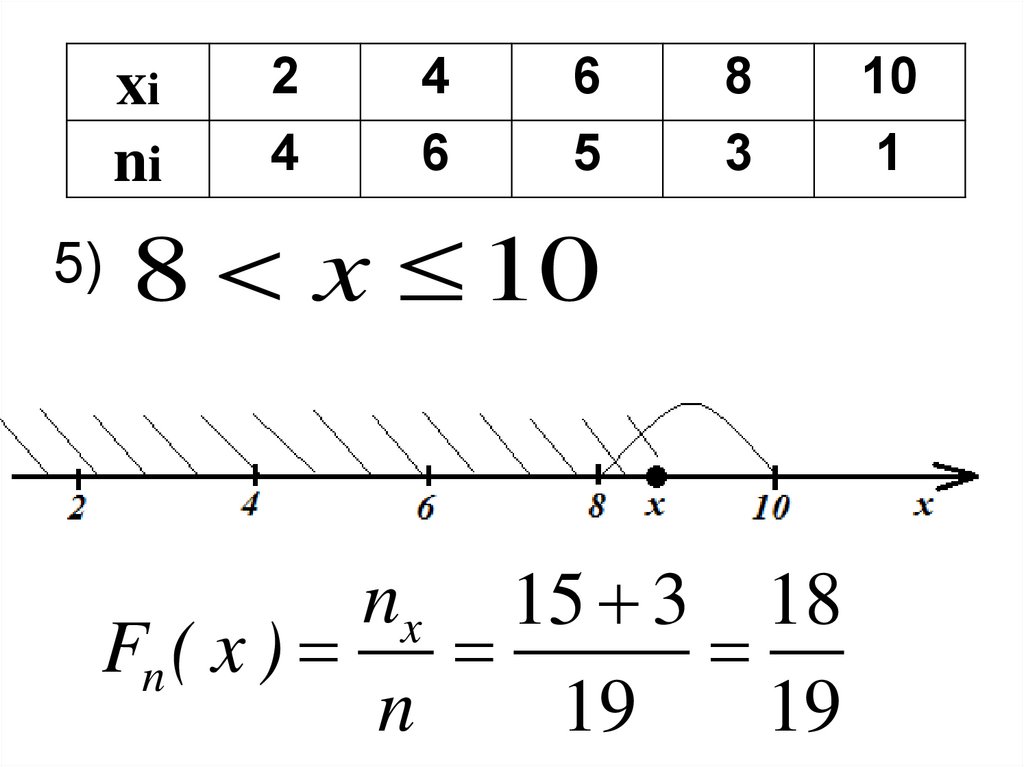
xini
5)
2
4
4
6
6
5
8
3
8 x 10
nx 15 3 18
Fn ( x )
n
19
19
10
1
54.
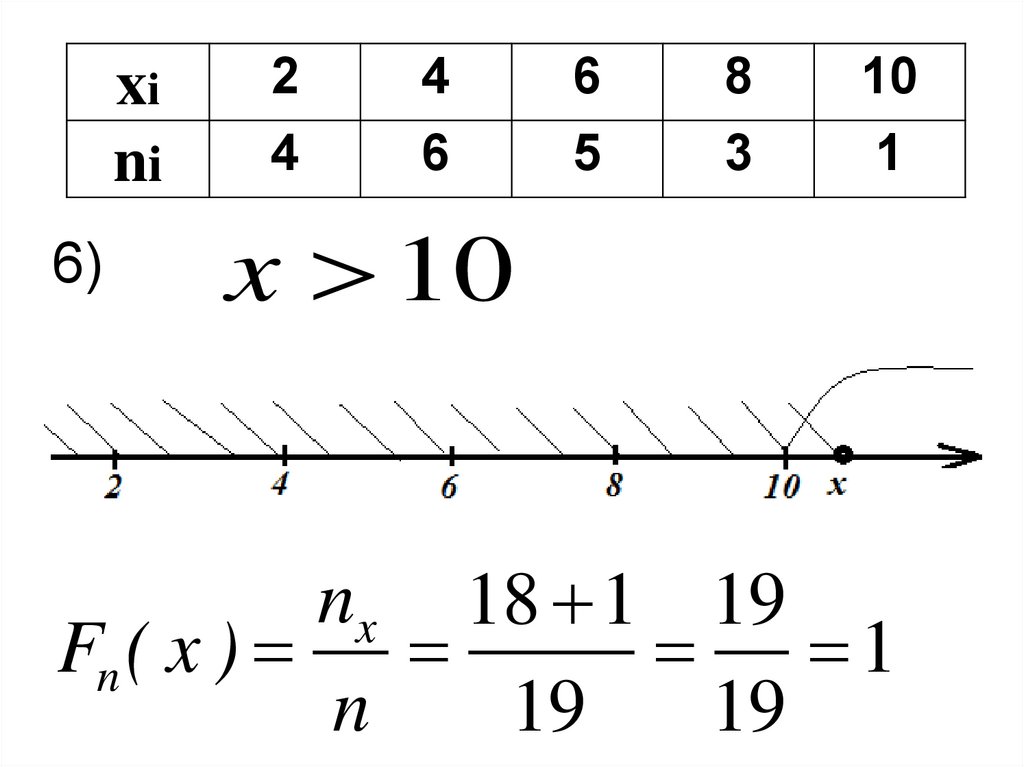
xini
6)
2
4
4
6
6
5
8
3
10
1
x 10
nx 18 1 19
Fn ( x )
1
n
19
19
55.
0 , x 2;4
, 2 x 4;
19
10
, 4 x 6;
19
Fn ( x )
15 , 6 x 8;
19
18
, 8 x 10;
19
1, x 10.
56.
xini
2
4
4
6
6
5
8
3
10
1
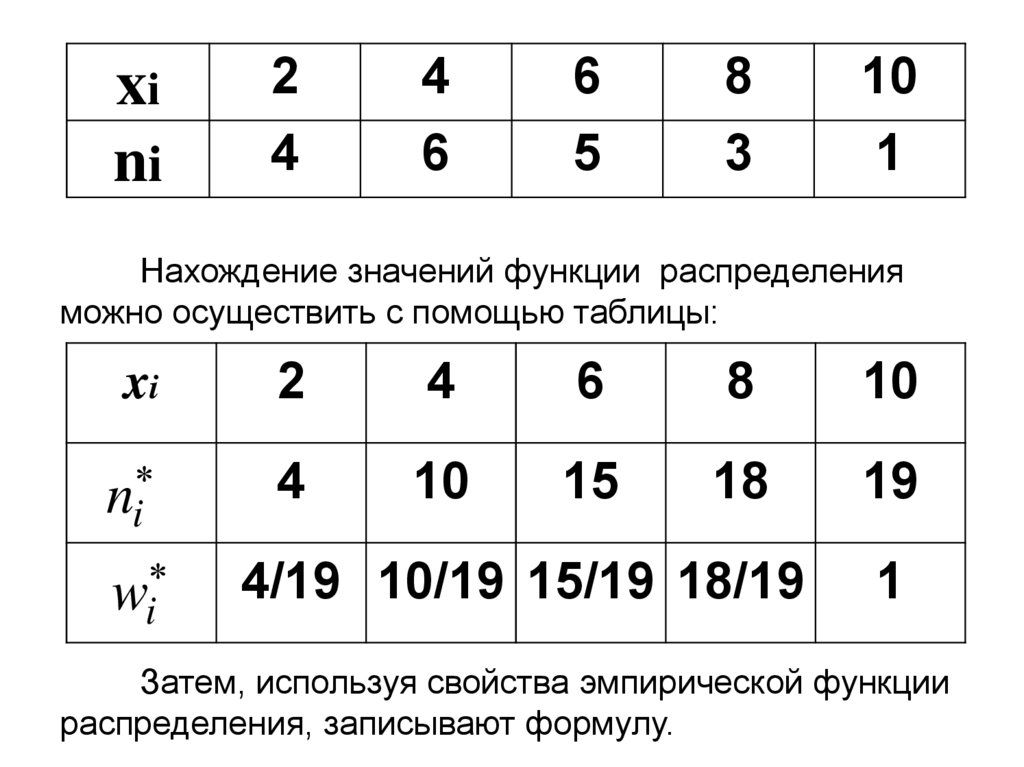
Нахождение значений функции распределения
можно осуществить с помощью таблицы:
xi
2
4
6
8
10
ni
wi
4
10
15
18
19
4/19 10/19 15/19 18/19
1
Затем, используя свойства эмпирической функции
распределения, записывают формулу.
57.
F x1
18
19
15
19
0 , x 2;
4
, 2 x 4;
19
10
, 4 x 6;
19
Fn ( x )
15 , 6 x 8;
19
18
, 8 x 10;
19
1, x 10.
10
19
4
19
0
2
4
6
8
10
x
58. Точечные оценки
Точечной оценкойнеизвестного
параметра число,
приблизительно
равное неизвестному
параметру.
59. Точечные оценки
Точечная оценка - этофункция от выборочных
данных
~
Тn x1 , x 2 , ... , x n
60. Нормальное распределение
61. Оценки меры центральной тенденции
К оценкам меры центральнойтенденции относятся числа
характеризующие наиболее типичные
результаты наблюдений:
1.Оценка генерального среднего М(Х);
2.Оценка Мо(Х);
3.Оценка Ме(Х).
62. Мода выборки
Мода выборки – это наиболее частовстречающееся выборочное
значение.
Мод может быть несколько.
Моды может не быть вообще.
Моду дискретного ряда можно найти по
полигону.
Моду интервального ряда можно найти по
гистограмме.
63.
Рис.1. Полигон частот64.
Рис.2. Гистограмма частот65. Мода интервального ряда
ni ni 1Мо х0 h
ni ni 1 ni ni 1
Х0 – начало модального интервала;
h – его длина;
ni – его частота;
ni-1 –частота предшедствующего интервала;
n i+1 –частота следующего интервала.
66. Медиана выборки
Медиана выборки – этосередина
ранжированного ряда.
Иначе говоря – это точка
числовой оси, левее и
правее которой лежит по
50 % выборочных данных.
67. Медиана дискретного ряда
При нечетном nМе х n 1
2
При четном n
Ме
хn
2
2
x n 1
2
68.
Рис. 3. Кумулята интервального ряда69. Медиана интервального ряда
Медиану интервального рядаможно найти по кумуляте:
Ме – это абсцисса той точки
кумуляты, ордината которой
равна половине объема
выборки.
70. Медиана интервального ряда
n/ 2 nМe х0 h
ni
i 1
Х0 – начало медианного интервала;
h – его длина;
ni – его часто та;
– накопленная частота предшествуi 1
ющего интервала;
n – объем выборки
n
71. Пример
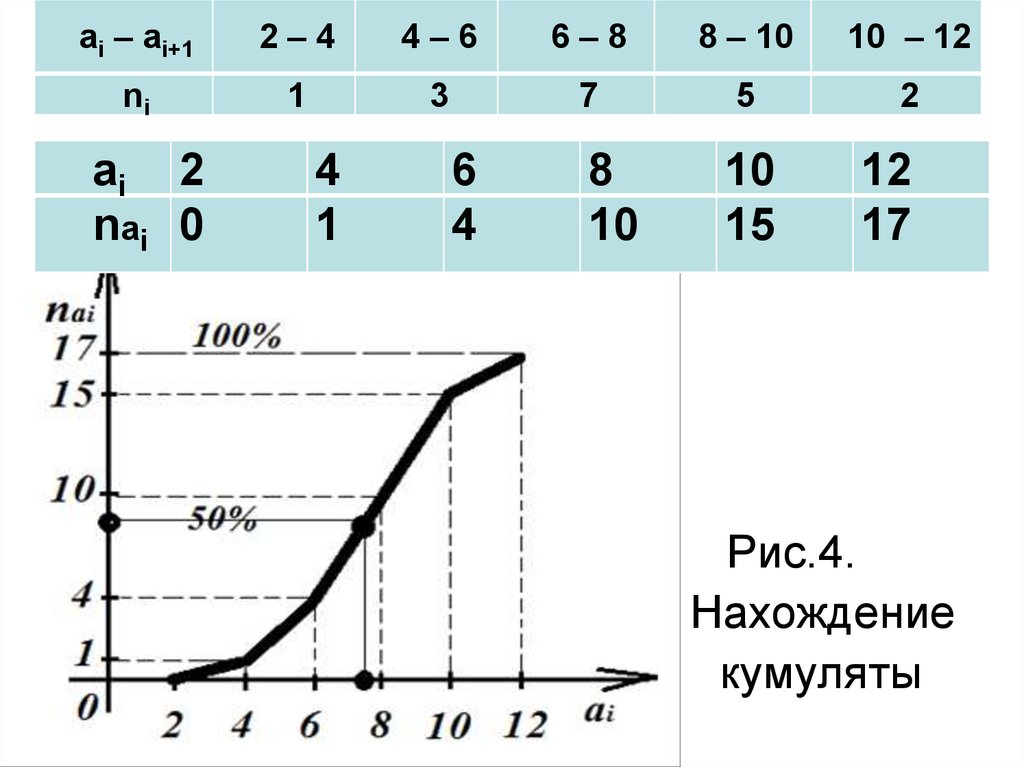
ai – ai+12–4
4–6
6–8
8 – 10
10 – 12
ni
1
3
7
5
2
Рис.4. Гистограмма. Нахождение моды
интервального ряда
72.
ai – ai+12–4
4–6
6–8
8 – 10
10 – 12
ni
1
3
7
5
2
ai 2
nаi 0
4
1
6
4
8
10
10
15
12
17
Рис.4.
Нахождение
кумуляты
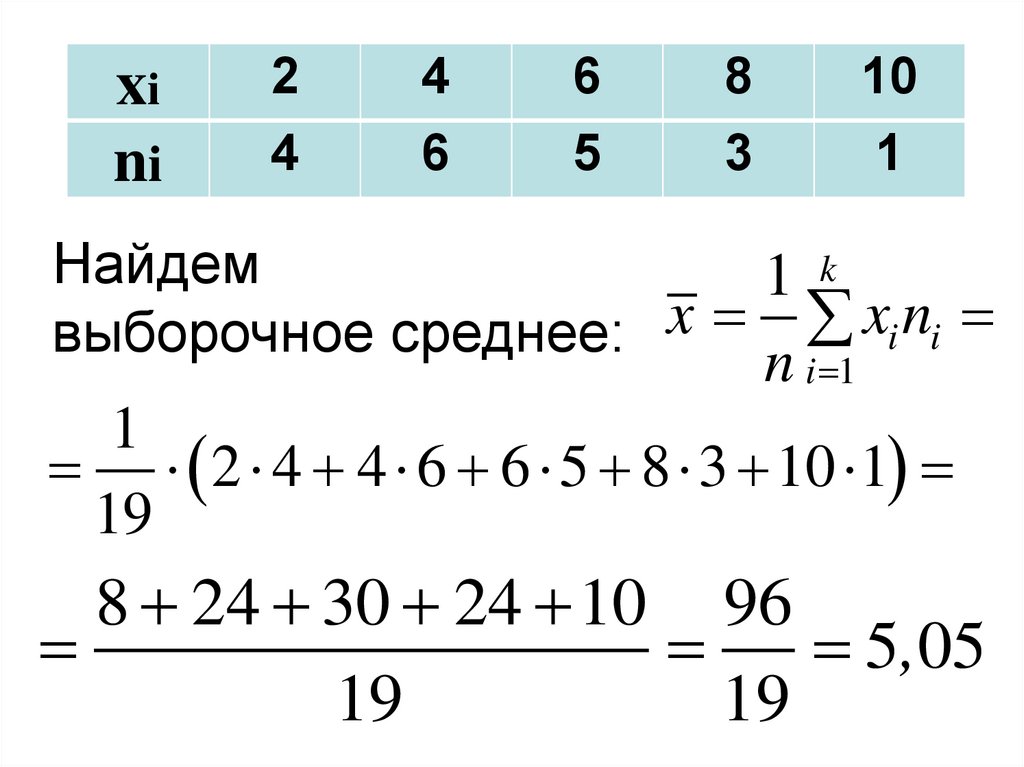
73. Выборочное среднее
Для несгруппированной выборки:n
1
x xi
n i 1
Для сгруппированной выборки:
k
1
x x i ni
n i 1
Для интервального ряда
а i a i 1
xi
2
74.
24
xi
ni
4
6
6
5
8
3
10
1
Найдем объем выборки.
k
n ni 4 6 5 3 1 19
i 1
75.
xini
2
4
4
6
6
5
8
3
10
1
Мода выборки – это наиболее
часто встречающееся выборочное
значение. В данном случае, мода
равна 4, так как именно 4
встречается в выборке
наибольшее количество раз – 6
раз.
76.
xini
2
4
4
6
6
5
8
3
10
1
Медиана выборки – это середина
ранжированного ряда. Иначе
говоря – это точка числовой оси,
левее и правее которой лежит по
50 % выборочных данных.
77.
xini
2
4
4
6
6
5
8
3
10
1
Для дискретного вариационного
ряда, при нечетном n, медиана
находится по формуле:
Ме хn 1 х19 1 х10
2
2
78.
xini
2
4
4
6
6
5
8
3
10
1
Десятое место в данном
вариационном ряду занимает 4, так
как первые 4 места (с 1-ого по 4ое) занимает 3, а следующие 6
мест (с 5-ог по 10-ое) занимает
именно 4. Поэтому Ме = 4.
79.
xini
2
4
4
6
6
5
8
3
10
1
Найдем
1 k
выборочное среднее: x xi ni
n i 1
1
2 4 4 6 6 5 8 3 10 1
19
8 24 30 24 10 96
5,05
19
19
80. Выборочная дисперсия
Для несгруппированной выборки:n
1
2
2
D xi x
n i 1
Для сгруппированной выборки:
k
1
2
2
x xi ni x
n i 1
Для интервального ряда
а i a i 1
xi
2
81. Выборочное среднеквадратическое отклонение
DТрехсигмовый интервал:
x 3 X x 3
Частота попадания
в 3 ый интервал 1
82.
xini
2
4
4
6
6
5
8
3
10
1
Найдем выборочную дисперсию:
1 k 2
2
x xi ni x
n i 1
1
2
2
2
2
2
2
2 4 4 6 6 5 8 3 10 1 5,05
19
16 96 180 192 100
25,5025
19
5,2343
83.
xini
2
4
4
6
6
5
8
3
10
1
Найдем выборочное среднеквадратическое
отклонение и трехсигмовый интервал:
D 5,2343 2,29
x 3 X x 3
5,05 3 2,29 X 5,05 3 2 ,29
5,05 6,87 X 5,05 6 ,87
1,82 X 11,92