


























 mathematics
mathematics biology
biologySimilar presentations:
")









Математическая биостатистика. Основные понятия и принципы обработки
1. Математическая биостатистика. Основные понятия и принципы обработки.
1. Биостатистика. Основные понятия.2. Получение и первичная обработка
материала.
3. Обработка данных в статистических
пакетах
1
2. 1.Основные понятия биостатистики
Биостатистика (Biostatistics) - научная отрасль,связанная с разработкой и использованием
статистических методов в научных исследованиях в
медицине, здравоохранении и эпидемиологии.
Два раздела: Описательная и Аналитическая.
Цель описательной биостатистики - сбор,
систематизация данных, получение обобщенных
показателей о предмете исследования;
Задача аналитической биостатистики - получение
статистических выводов на основе собранной и
систематизированной информации об объекте
исследования.
2
3.
• Во многом успехи, достигнутые биологией, связаны спланированием эксперимента и использованием
методов статистической обработки полученных
данных, т. е. с использованием биометрии.
• С помощью биометрии можно сделать обоснованные
выводы о процессах, протекающих в живой природе,
проверить достоверность гипотез, выявить
биологические закономерности.
• Данные, не обработанные математически, в
большинстве случаев не имеют научной ценности и
практической значимости.
• Более того, игнорирование возможностей
статистической обработки полученных данных может
привести к ошибочным заключениям.
3
4.
Биометрия – это наука о математическоманализе групповых свойств в биологии.
Групповые свойства – это такие особенности,
признаки, которые проявляются только у
группы объектов; отдельные объекты
групповыми свойствами не обладают.
Н/п, яйценоскость кур за месяц составила 25,5 яйца,
однако, ни одна курица пол-яйца не снесла.
Статистическая совокупность - множество
объектов, обладающих определенными
групповыми свойствами. Может иметь разный
объем.
Выделяют генеральную и выборочную
совокупность.
5. Генеральная совокупность
охватывает всех членов данного множества,ее объем может быть конечным, а чаще –
бесконечным.
Например, стадо коров учхоза представляет собой
новую породную группу. Значит, коровы учхоза
являются генеральной совокупностью, но они
являются составной частью другой, более обширной
генеральной совокупности всех коров, объем которой
бесконечен.
Генеральную совокупность можно создать
искусственно. Ее объем зависит от цели
исследования.
5
6. Выборочная совокупность
- это группа объектов, взятая из генеральнойсовокупности для характеристики
генеральной совокупности.
Выборочная совокупность определяется следующим
образом.
• берем генеральную совокупность (г.с.);
• выбираем достаточное количество объектов из г.с.,
чаще всего случайным образом.
При этом необходимо, чтобы в.с. была
репрезентативной – представительной.
Уже по трем объектам можно судить о параметрах г.с.
с определенной точностью и надежностью.
6
7.
Биостатистика изучает признаки, которые могутбыть качественными и количественными.
Качественные признаки воспринимаются
непосредственно органами чувств (цвет,
консистенция и т.п.). Качественные признаки
выступают в форме альтернативных,
взаимоисключающих признаков (белый – не
белый).
Количественные признаки требуют счета (счетные)
или меры (мерные). Счетные признаки
дискретны и выражаются целыми числами.
Мерные признаки требуют измерения (размеры,
вес и т.п.), при этом могут получиться любые
7
числа.
8. Любой признак в группе у разных объектов проявляется по-разному – варьирует.
Например, разный вес одновозрастныхживотных.
8
9. 2. Получение и первичная обработка материала
После составления выборочной совокупностипроизводится исследование (измерение)
материала.
Точность, определенный способ, одни и те
же инструменты, одинаковые условия.
Затем проводится анализ выборочных
показателей для оценки параметров г.с.
Полученные данные могут быть
представлены в виде статистических
таблиц.
9
10.
Урожайность по годам, в ц/гаСорт
А
Б
2015
2016
2017
10,5
6,8
12,3
10,5
9,2
7,2
Из таблицы можно сделать простой вывод, что
сорт А дает урожай во все годы больше, чем
сорт Б.
Но для полного анализа чаще нужна дальнейшая
обработка.
10
11.
Допустим, что величины признаков были:5,2,1,5,7,9,3,5,4,10,4,5,7,3,5,9,4,12,7,7.
По данному ряду чисел сделать какие-то
выводы трудно, а иногда и невозможно.
Поэтому в некоторых случаях проводится
ранжирование – значение признаков
(варианты или даты) распределяются по
величине в убывающем или возрастающем
порядке в ранжированный ряд:
12,10,9,9,7,7,7,7,5,5,5,5,5,4,4,4,3,3,2,1.
В ранжированном ряду видно максимальное
или минимальное значение признака, какое
значение встречается чаще, реже и т.п.
11
12.
Однако, при многочисленных датах ранжированиетрудоемко, да и результаты незначительны. Поэтому
чаще строится простой или сложный вариационный
ряд.
Простой вариационный ряд представлен в виде двух
строк: в первой - значения вариант (V) по убыванию,
во второй – частота их встречаемости (f).
12,10,9,9,7,7,7,7,5,5,5,5,5,4,4,4,3,3,2,1
V
12
11
10
9
8
7
6
5
4
3
2
1
f
1
0
1
2
0
4
0
5
3
2
1
1
Общее количество дат (n) равно сумме частот:
n= f = 20
12
13.
Пример. Составить сложный вариационный ряд изследующих чисел
413
423
414
423
433
450
420
410
434
395
419
416
409
402
433
412
407
416
431
420
427
427
430
410
439
435
428
403
405
398
404
417
426
436
437
430
398
407
405
422
421
424
400
424
394
399
420
423
405
416
414
401
425
412
424
386
424
391
413
434
428
411
432
444
408
441
426
409
392
443
397
380
418
411
407
417
419
418
428
421
418
406
388
394
422
414
419
421
431
410
429
429
415
411
423
417
406
417
422
409
n=100, Vmax =450, Vmin =380
r=1+3,3lg n =1+3,3 lg 100= 1+3,3*2=7,6
Vmin 450 380 9,2 10
K Vmax
r
7,6
10
10
W 450, Wa 450 445; W 450 1 454.
2
2
16
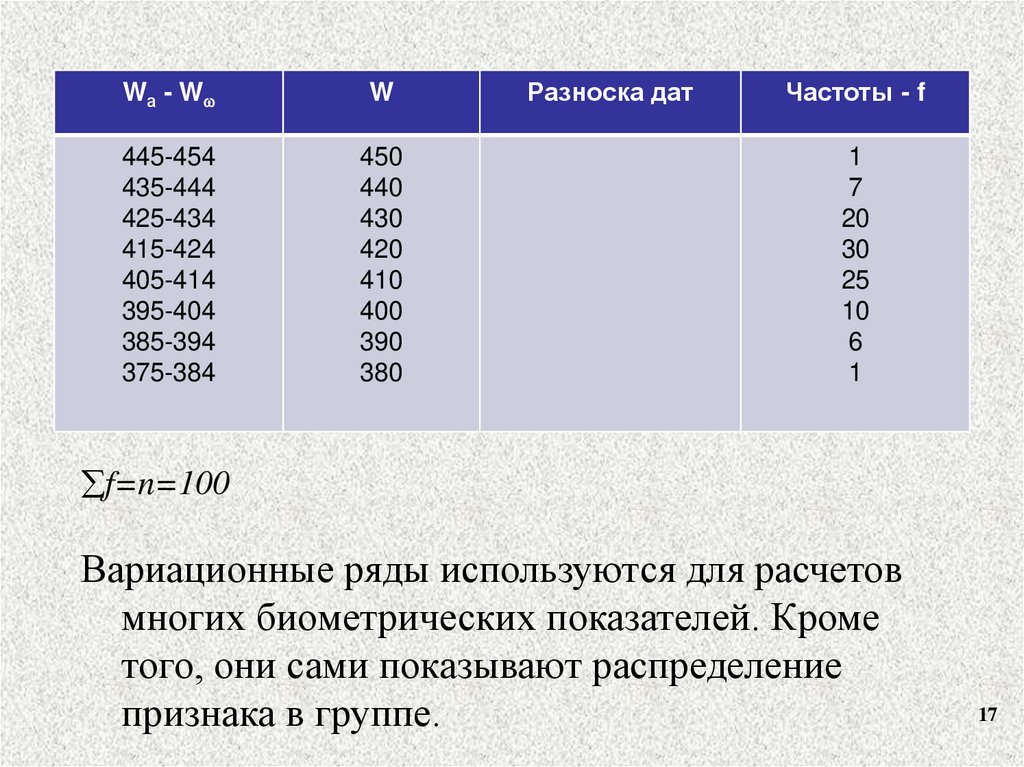
14.
Wа - WW
445-454
435-444
425-434
415-424
405-414
395-404
385-394
375-384
450
440
430
420
410
400
390
380
Разноска дат
Частоты - f
1
7
20
30
25
10
6
1
f=n=100
Вариационные ряды используются для расчетов
многих биометрических показателей. Кроме
того, они сами показывают распределение
признака в группе.
17
15.
3. Обработка данных в статистическихпакетах
• Обработку полученных данных можно провести
как в пакетах общего назначения, так и в
специализированных пакетах.
• Наиболее популярным пакетом общего
назначения является электронная
таблица Excel, из специализированных пакетов
специалисты предпочитают программу
Statistica.
• Полученные в результате обработки значения
биометрических характеристик необходимо
проанализировать. Для этого необходимо
18
знать основы биометрии.
16. Пример. Составить сложный вариационный ряд из следующих чисел
Статистическая обработка данных в Excel• Хотя Excel существенно уступает
специализированным статпакетам обработки
данных, тем не менее этот раздел математики
представлен в нем наиболее полно.
• В Excel включены основные, наиболее часто
используемые статистические процедуры:
средства описательной статистики, критерии
различия, корреляционные и другие методы,
позволяющие проводить необходимый
статистический анализ биологических,
экономических, социологических и других
типов данных.
19
17.
Статистические функции ExcelВ мастере функций Excel имеется ряд статистических
функций, предназначенных для статистической обработки
данных, вычисления выборочных характеристик.
Примеры статистических функций:
СРЗНАЧ - вычисляет среднее арифметическое (невзвешенное) из нескольких
массивов (аргументов) чисел.
СЧЁТ - подсчитывает количество ячеек, содержащих числа.
СЧЕТЕСЛИ – подсчитывает ячейки, удовлетворящих заданному критерию.
МАКС – находит наибольшее число из аргументов.
МИН – находит наименьшее число из аргументов.
ДИСП - позволяет оценить дисперсию по выборочным данным.
СТАНДОТКЛОН - вычисляет стандартное отклонение.
МОДА - определяет наиболее часто встречающееся значение в выборке.
МЕДИАНА - позволяет получать медиану заданной выборки. Медиана - это
центральный элемент выборки: число элементов выборки со значениями больше
медианы и меньше равно.
КОРРЕЛ – оценивает степень и характер зависимости между различными наборами
данных и др.
20
18. 3. Обработка данных в статистических пакетах
• В пакете Excel помимо мастерафункций имеется набор более мощных
инструментов для работы с
несколькими выборками и углубленного
анализа данных, называемый Пакет
анализа, который может быть
использован для решения задач
статистической обработки выборочных
данных.
21
19. Статистическая обработка данных в Excel
Пакет Анализ данныхРассмотрим некоторые из инструментов, входящих
в пакет анализа.
22
20. Статистические функции Excel
Описательная статистика• выводит на экран
статистический отчет
для входных данных.
Выходная таблица
содержит два столбца
информации для
каждого набора
данных.
Левый столбец содержит
названия
статистических
характеристик, а
правый столбец – их
значения.
23
21.
В этой таблице будут содержаться следующиехарактеристики: среднее, стандартная ошибка, мода,
медиана, стандартное отклонение, дисперсия,
эксцесс, асимметрия, размах варьирования
интервала, минимальное и максимальное значения,
сумма всех элементов выборки, объем выборки.
Инструмент Описательная статистика существенно
упрощает статистический анализ тем, что нет
необходимости вызывать каждую функцию для
расчета статистических характеристик отдельно.
24
22. Пакет Анализ данных
Гистограмма• вычисляет частоты появления данных.
Числовой промежуток между наибольшим и наименьшим значениями
данных делится на интервалы, называемые карманами. Под
частотой понимается количество значений, попавших в один
такой карман.
Данный инструмент также позволяет представить результаты
анализа в графическом виде, построив гистограмму частот:
интервалы разбиения откладываются по оси абсцисс гистограммы,
на каждом из интервалов в виде столбцов изображается частота.
25
23. Описательная статистика
Генерация случайных чисел• используется как вспомогательный
инструмент для получения набора
случайно выбранных элементов из
генеральной совокупности (т.е. для
выборки).
26
24.
Корреляция• является количественной
характеристикой взаимосвязи двух
признаков, позволяет найти показатель
силы связи между ними.
Результатом использования инструмента
Корреляция является таблица
(матрица) с коэффициентами
корреляции для каждой пары
переменных измерений.
27
25. Гистограмма
Связь между переменными величинами X и Y можно определить присоотношении числовых значений одной из них с соответствующими
значениями другой. Если при увеличении одной переменной увеличивается
(уменьшается) другая, это свидетельствует о положительной
(отрицательной) связи между этими величинами.
Зависимость между переменными, которым соответствуют средние
величины, называется корреляцией. Таким образом, коэффициент
корреляции может варьировать в пределах от –1 до +1.
r < 0,30 – слабая связь, 0,31 < r < 0,50 – умеренная, 0,51 < r < 0,70 –
значительная, 0,71 < r < 0,90 – сильная; от 0,91 < r < до 0,99 – очень сильная.
28