






 software
softwareSimilar presentations:










Этапы DQN
1.
DQNМЕНМ-130201
Семенов Артём
2.
3.
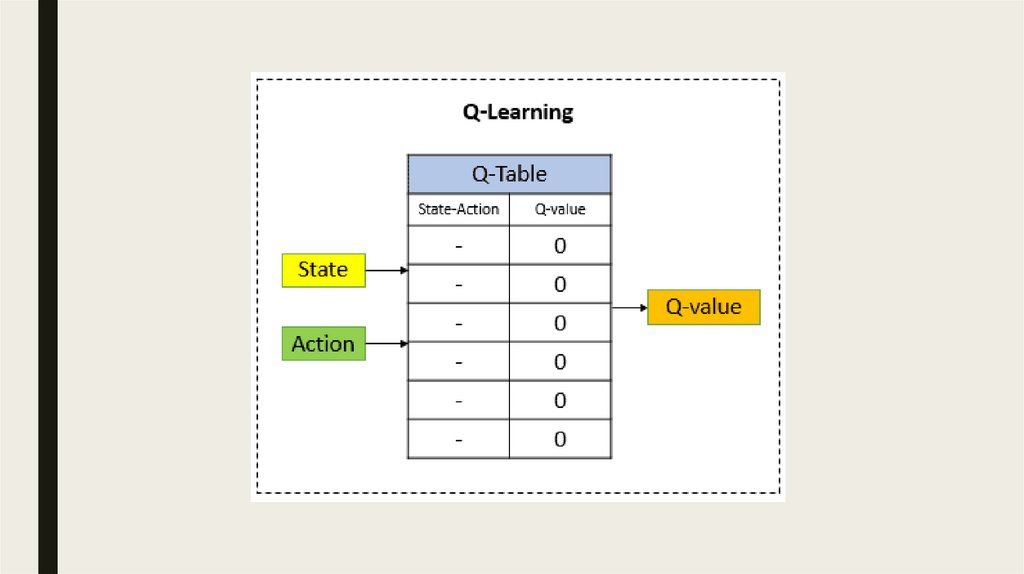
Проблема■ От роста Q-Table растет количество требуемого свободного места
■ Помимо этого на поиск более прибыльного действия потребуется куда больше
времени
4.
5.
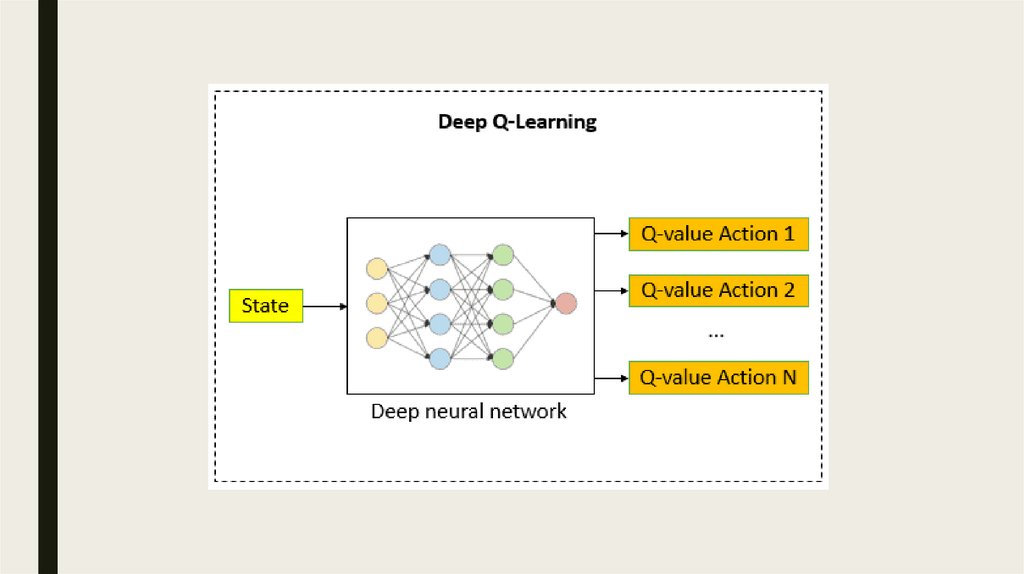
Этапы DQN■ Окружающая среда: DQN взаимодействует со средой с состоянием,
пространством действий и функцией вознаграждения
■ Память воспроизведения: DQN использует буфер памяти воспроизведения для
хранения прошлого опыта
■ Глубокая нейронная сеть: DQN использует глубокую нейронную сеть для оценки
Q-значений для каждой пары (состояние, действие)
■ Исследование с эпсилон-жадностью: DQN использует стратегию исследования с
эпсилон-жадностью , чтобы сбалансировать исследование и эксплуатацию
■ Целевая сеть: DQN использует отдельную целевую сеть для оценки целевых
значений добротности
6.
■ Обучение: DQN обучает нейронную сеть, используя уравнение Беллмана, дляоценки оптимальных значений Q. Функция потерь представляет собой
среднеквадратичную ошибку между прогнозируемым и целевым значениями.
Целевое значение добротности вычисляется с использованием целевой сети и
уравнения Беллмана. Веса нейронной сети обновляются с использованием
обратного распространения и стохастического градиентного спуска
■ Тестирование: DQN использует изученную политику для принятия решений по
окружающей среде после обучения. Агент выбирает действие с наибольшим
значением Q для данного состояния
7.
Алгоритм■ Инициализируем нейросеть со случайными весами
■ Дублируем в целевую сеть