







")

 http://wordnetweb.princeton.edu/perl/webwn")





")
")









 и")











")

 informatics
informaticsSimilar presentations:

 из текстов")

")





")
Знания в задачах автоматической обработки текстов. Семантические сети
1. Знания в задачах автоматической обработки текстов
2. Семантические сети
• Идея представления:– набор понятий и отношений между ними
– Значений понятия определяется отношениями с
другими понятиями
• Семантическая сеть состоит из совокупности
вершин, соединенных размеченными дугами
– Вершины – понятия
– Дуги - отношения
• Графическое представление
M. Ross Quillian. "Semantic Memories", In M. M. Minsky,
editor, Semantic Information Processing, pages 216-270.
Cambridge, MA: MIT Press, 1968
3. Семантические сети - история
4. Семантическая сеть - состав
• Сущности – реальные и мнимые объекты предметнойобласти: индивиды, понятия, свойства, явления,
события, процессы, ситуации - находятся в
определенных отношениях друг с другом
• Семантическая сеть – ориентированный связный
граф из именованных вершин и ребер
– Вершины – представляемые сущности
– Ребра (дуги) – семантические связи вершинсущностей
– Вершины и ребра помечены, а ребра – направлены
–
• Обычно имена, приписываемые вершинам и рёбрам,
совпадают с названиями соответствующих сущностей и
отношений предметной области, тем самым: семантика
5. Наиболее распространенные отношения в семантических сетях
Отношение класс-подкласс (subclass_of)): X - этоподкласс Y, если X – это подмножество сущностей
более общего понятия Y.
Example: воробей –подкласс птица
Экземпляр (instance_of (=INST или обр)): X - это
экземпляр Y, если X – это индивидуальный
экземпляр общего понятия (отношение один ко
многому!)
Элвис – это экземпляр Человека
Подразумевается транзитивность отношения классподкласс: если Х – подкласс Y, Y – подкласс Z, то X
– подкласс Z
6. Транзитивность
• Транзитивность - важнейшее свойство отношениякласс-подкласс
– Позволяет сократить описания
• Не выполняется для отношений экземпляр-класс
7. Наследование
• Наследование – ключевое свойство,предполагаемое в семантических сетях
• Если понятие X имеет свойство P, то все
подпонятия имеют свойство P.
– Канарейки – это птицы, птицы едят
семена=>канарейки едят семена
– Пингвины – это птицы, птицы умеют летать =>
пингвины умеют летать
• Есть исключения, но наследование позволяет
сокращать описание
8. Таксономия –сем. сеть, состоящая из отношений класс-подкласс
Таксономия –сем.сеть, состоящая из
отношений классподкласс
object
organism
animal
mammal
cat
siamese
instances
frog
9. Современность: Графы знаний (Knowledge graph)
10. Google: Knowledge Vault
11. Лексико-семантические ресурсы типа WordNet (тезаурусы) http://wordnetweb.princeton.edu/perl/webwn
• Семантическая сеть:понятия и отношения
между ними
• Один из наиболее
используемых ресурсов в
автоматической
обработке текстов
• Английский язык –
• Princeton WordNet – 155
тыс. слов и выражений
• Проекты по созданию
ворднетов для десятков
языков
12.
13. Тезаурус WordNet
• Реляционное описание лексики английского языка• Иерархическая сеть понятий (synset)
• Каждое слово относится к одному
или нескольким понятиям
• Отдельная иерархическая сеть для различных частей
речи – психолингвистическое обоснование
• Автор: George Miller
(Miller G. A. The magic number seven plus or minus two: Some limits on
our capacity for processing information //Psychological review. – 1956. –
Т. 63. – С. 91-97.)
• Версия 3.0:
• 117 тыс. синсетов, около 155 тысяч
разных слов и
словосочетаний, 200 тысяч отношений слово-синсет
14. Синсеты
• Синсет (набор синонимов) – единицасловаря => понятие
• Синонимы имеют одинаковое толкование
• Семантические отношения между синсетами
– Гипонимы, гиперонимы, часть, целое и др.
• Многозначные слова: слово входит в
несколько синсетов
15. Единицы WordNet - синсеты
16. Родовидовые отношения
• Гипоним (более конкретное слово –гипероним (более общее слово)
– собака – животное
– саднить - болеть
• Лингвистические тесты
– X – это Y,
– Х, Z и другие Y;
– к числу Y относятся X
17. Отношения гипоним-гипероним: Лексическая иерархия
• Отношение гипоним-гипероним– Грач – перелетная птица семейства вороновых
– Птица – покрытое пухом и перьями позвоночное
животное
– Животное – всякое живое существо, исключая
растения
– Грач – птица – животное – живое существо
• Свойства отношения
– Транзитивность
– Наследование свойств от гиперонимов к
гипонимам
18. Представление месяцев (ко-гипонимы)
19. WordNet (Miller et al. 1990; Fellbaum, 1998)
{wheeled vehicle}{brake}
ha
pa
s-
is-a
a
is-
has-part
has
-pa
rt
{wheel}
rt
isa
is-a
{motor vehicle}
{locomotive, engine,
locomotive engine,
railway locomotive}
{tractor}
is
-a
is-a
a
is-
t
{car,auto, automobile,
machine, motorcar}
has
-pa
r
{golf cart,
golfcart}
{splasher}
{self-propelled vehicle}
isa
{wagon,
waggon}
rt
has-pa
{car window}
ha
s-p
a
rt
{accelerator,
accelerator pedal,
{air bag}
Don’t Take Shortcuts! Computational Lexical Semantics and the Turing Test
gas pedal, throttle} 13/03/2024
{convertible}
Roberto Navigli
19
20. Отношение Часть-Целое
• Мероним – часть, холоним – целое• Проверочные фразы:
– X – это часть Y
• Внутри отношения меронимии
дополнительно выделяются
отношения
– быть_элементом (member_of)
– быть_материалом (substance_of)
21.
Частимеронимы22. Определение семантического сходства слов по семантической сети
23. Семантическое сходство слов
Используется при
Семантическом групировании слов
Нахождении сходства между текстами
(предложениями)
Расширение поискового запроса и др.
Нахождение связей между частями текста
Задача: выработать некоторую величину для пары
слов: 1 – полное сходство, 0 – нет никакого сходства
24. Подходы к вычислению семантическое близости на основе семантической сети
• Вычисление близости связано с существующимипутями между узлами, в которых расположены слова
• Пути обычно рассматриваются не любые, а
пересечение по движению вверх по иерархии
– Важно ближайшее пересечение путей при
движении вверх от слов: Least Common Subsumer
- наименее общее родовое понятие
25.
Miter saw - торцовочная пилаSander – шлифовальная машина
Screwdriver - отвертка
26. «Стандартные» методы подсчета меры схожести
• Методы, использующие путь (расстояние) между узлами виерархии (PATH):
Rada et al., 1989 (path)
• Методы, использующие путь (расстояние) между узлами в
иерархии и глубину узлов в иерархии (PATH + DEPTH):
Wu & Palmer, 1994 (wup)
Leacock & Chodorow, 1998 (lch)
• Методы, использующие путь между узлами в иерархии и
информационное содержание (PATH + INFORMATION
CONTENT):
Resnik, 1995 (res)
Lin, 1998 (lin)
27. Path Based Measures
•Подсчитывать расстояние между узлами в дереведля вычисления меры семантической схожести
интуитивно кажется правильным
•Но есть существенный недостаток! В данном
методе предполагается, что все расстояния между
узлами имеют одинаковый вес.
•Далее везде предполагается, что синонимы - это
путь с шагом 1
•Пример меры (но могут быть и другие варианты)
28. Еще пример вычисления семантической близости на основе пути
• Вход: два понятия. Результат: мера близости• (Leacock and Chodorow 1998)
• Similarity (C1, C2)= - log2d (path (C1,C2)/2D)
• D – глубина таксономии
• Similarity(wolf, dog) = 0.60
Similarity(wolf, bear) = 0.42
29. Мера семантической схожести показывает, что hammer и power tool схожи в той же степени, что и mitre saw (торцовочная пила) и
sander(шлифовальная машина).
30. Path + Depth
• Если учитывать только длину пути, то мы лишаемсяинформации о специфичности понятий.
• Концепты, лежащие на более глубоких уровнях
иерархии, являются более специфичными.
• Семантическое расстояние между концептами,
принадлежащими более глубоким уровням иерархии,
меньше
31. Пример вычисления меры Wu, Palmer
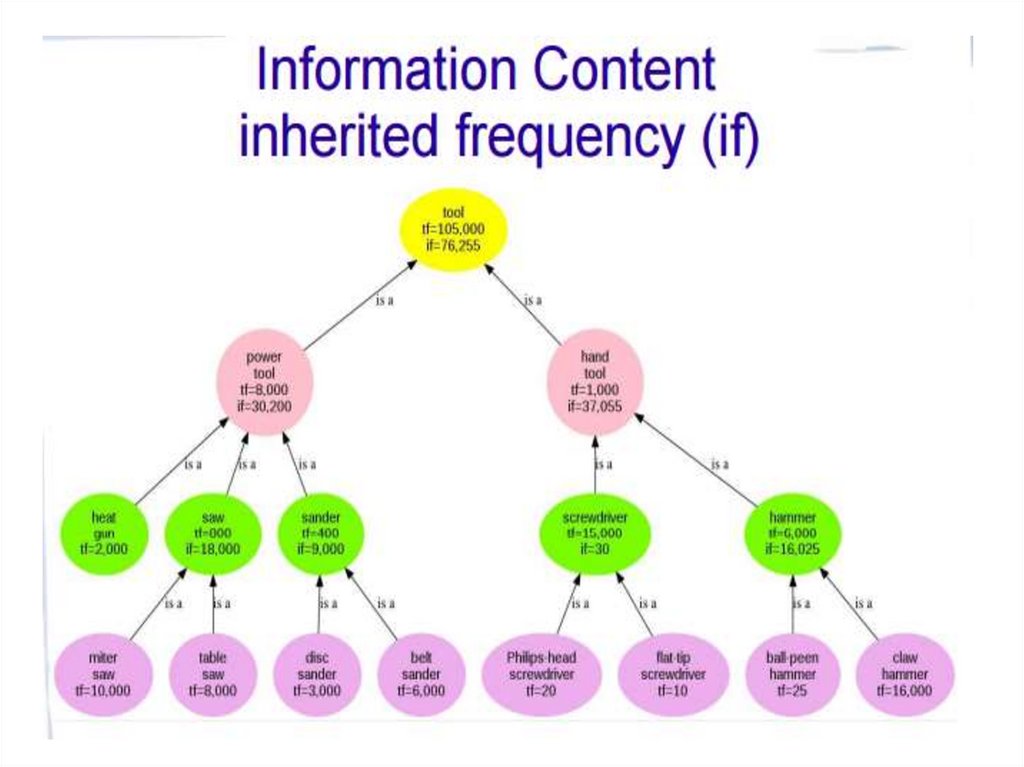
32. Метрика на основе информационного содержания
• Хорошо бы учесть частоту слова – чем режеслова из какой-то области, тем ближе по
смыслу они кажутся
– IC=-log p(concept), где p(concept)=C (concept)/N
– т.е. IC – это положительное число
– Чем реже слово, тем больше число
• Для понятий (синсетов), под которыми есть
другие узлы, нужно суммировать собственную
частотность+частотность всех нижестоящих
узлов
33.
34.
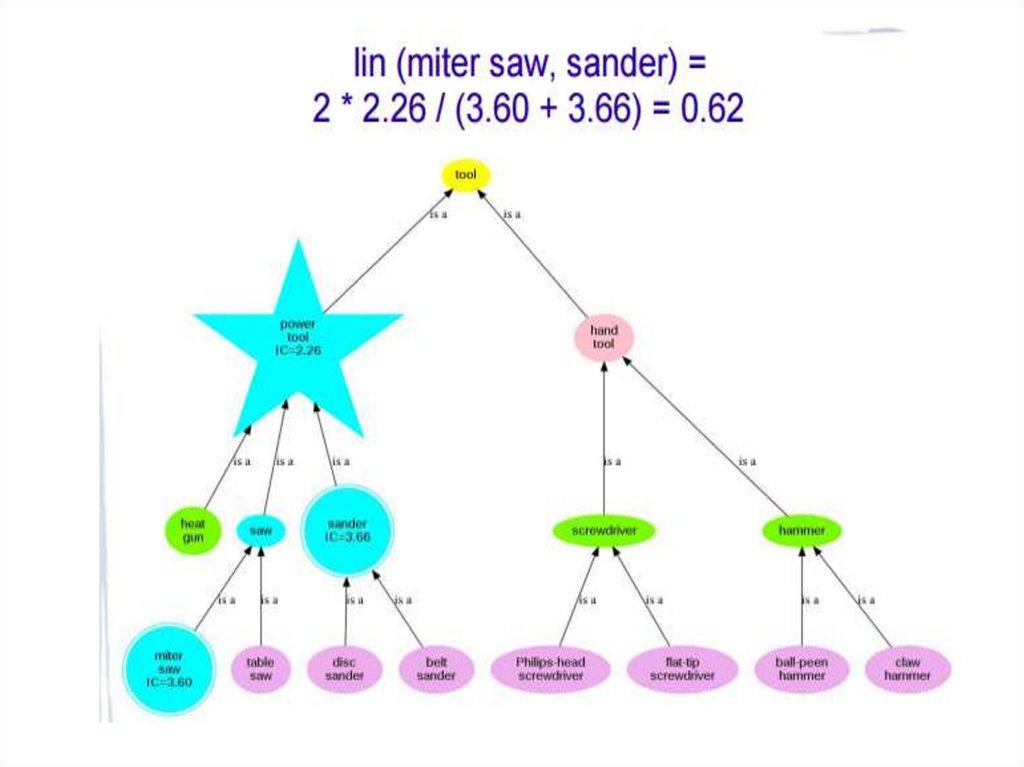
35. Lin, 1998
Wup и lin похожи, однако lin использует IC,a wup – depth.
36.
37.
38. Сравнение коэффициентов
• Lin : miter saw и sander (0.62) более схожи,чем hammer и power tool (0.28)
• Wu and Palmer : miter saw и sander (0.57)
более схожи, чем hammer и power tool (0.4)
• Path: miter saw и sander (0.25) в равной
степени схожи с hammer и power tool (0.25)
39. Тестирование автоматических методов определения семантической близости
• На основе оценки семантической близости пар слов– Выбираются пары слов
– Люди оценивают семантическую близость пар слов по какойлибо шкале
– Получается ранжированный список пар от самых близких к
менее близких
– Затем берем метод автоматической оценки близости,
который проставляет автоматические оценки
– Создаем автоматический список упорядоченный пар
– Два списка можно сравнить с помощью мер статистической
корреляции: Спирмен, Пирсон3
40. Тестирование подходов по определению сходства слов
41.
42. WordSim-353: similarity vs. relateddess
tiger cat
plane
train car
television
media
bread
cucumber
doctor
professor
student
smart
wood
money
7.35
car
5.77
6.31
radio 6.77
radio 7.42
butter 6.19
potato 5.92
nurse 7.00
doctor 6.62
professor 6.81
stupid 5.81
forest 7.73
cash 9.15
computer
keyboar 7.62
Jerusalem Israel 8.46
planet
galaxy 8.11
canyon
landscape 7.53
OPEC
country 5.63
day summer
3.94
day dawn 7.53
country
citizen 7.31
planet
people 5.75
environment ecology 8.81
Maradona football 8.62
OPEC
oil
8.59
money
bank 8.50
43. Simlex-999 dataset – 999 пар слов (2015)
44. Задание. Wordsim similarity- http://alfonseca.org/eng/research/wordsim353.html
Задание. Wordsim similarityhttp://alfonseca.org/eng/research/wordsim353.html• Wordsim 353 Goldstandard – relatedness, similarity
Пользуясь пакетом nltk доступа к WordNet
https://www.nltk.org/howto/wordnet.html
Посчитать близость слов методами lch, wup и jcn
Получить ранжированный список по мере снижения близости
Оценить меру Спирмена
Сделать анализ, почему некоторый близкие слова по мнению человека
оказались далекими автоматически, и наоборот