













 informatics
informaticsSimilar presentations:
")
 из текстов")






")

Методы автоматической обработки текста
1.
Методы автоматической обработкитекста
Выполнила: Тотмина Екатерина, гр. 23225.2
2.
ОпределениеАвтоматическая обработка текста: Эти методы используются для сложного анализа и
интерпретации текста, часто с применением методов машинного обучения.
-
Цель: Cоздать системы, способные понимать языковые структуры и смыслы, а
также выполнять полезные задачи на основе этого понимания.
3.
Где используются1. Поисковые системы
2. Чат-боты и виртуальные ассистенты
3. Сентимент-анализ
4. Машинный перевод
5. Тематическое моделирование
6. Рекомендательные системы
4.
Мешок слов (BoW)Определение: Это упрощенное представление текста, которое показывает, какие слова
встретились в тексте.
Использование: Задачи классификации текста, кластеризации и рекомендательной
системы.
Ограничения:
1. BoW не учитывает семантику и порядок слов в тексте.
2. Проблема разреженности данных
5.
Алгоритм работы Bag of WordsИсходные предложения указаны слева, их представление — справа. Каждый индекс в
векторах представляет собой одно конкретное слово.
Подготовка -> Создание словаря -> Векторизация
6.
TF-IDFОпределение: TF-IDF — это статистическая мера, которая оценивает важность слова в
документе на основе его частотности в этом документе и его редкости во всем корпусе
документов.
Использование: Извлечение ключевых слов из документов и построение векторных
представлений текста.
Преимущества над BoW: Учитывается не только частота слова в документе (TF), но и
то, насколько редко оно встречается во всем корпусе (IDF).
7.
Алгоритм работы TF-IDFTF-IDF = TF*IDF
8.
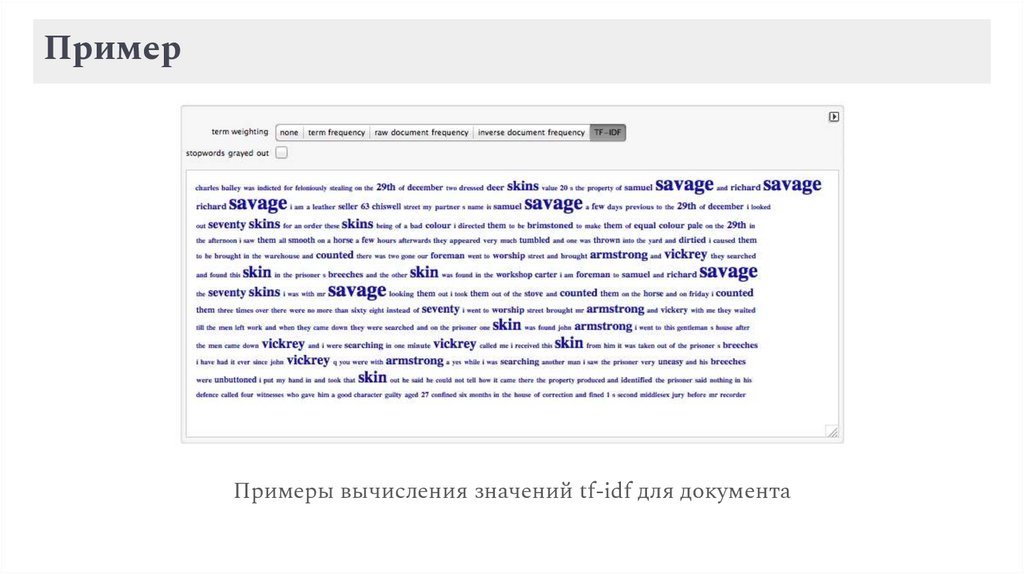
ПримерПримеры вычисления значений tf-idf для документа
9.
Наивный байесовский классификаторОпределение: Это статистический классификатор, основанный на применении
теоремы Байеса.
Применение: Классификации текстов (определение тональности отзывов, фильтрация
спама в электронной почте и другие задачи).
Преимущества:
1. Наивный байесовский классификатор обычно быстр и эффективен.
2. Он также работает хорошо с большим числом признаков.
10.
Алгоритм работы классификатораP(A | B) – апостериорная вероятность
(что A из B истинно)
P(A) – априорная вероятность
(независимая вероятность A)
P(B | A) – вероятность данного
значения признака при данном
классе. (что B из A истинно)
P(B) – априорная вероятность при
значении нашего признака.
(независимая вероятность B)
11.
Машины опорных векторов (SVM)Определение: SVM — это алгоритм, который ищет гиперплоскость (-и), разделяющую
данные таким образом, чтобы максимизировать зазор между разными классами.
Применение: Преимущественно задачи классификации текста
Преимущества: Имеет преимущество, когда данные разделимы, особенно в
высокоразмерных пространствах, что делает их подходящими для текстовых данных.
12.
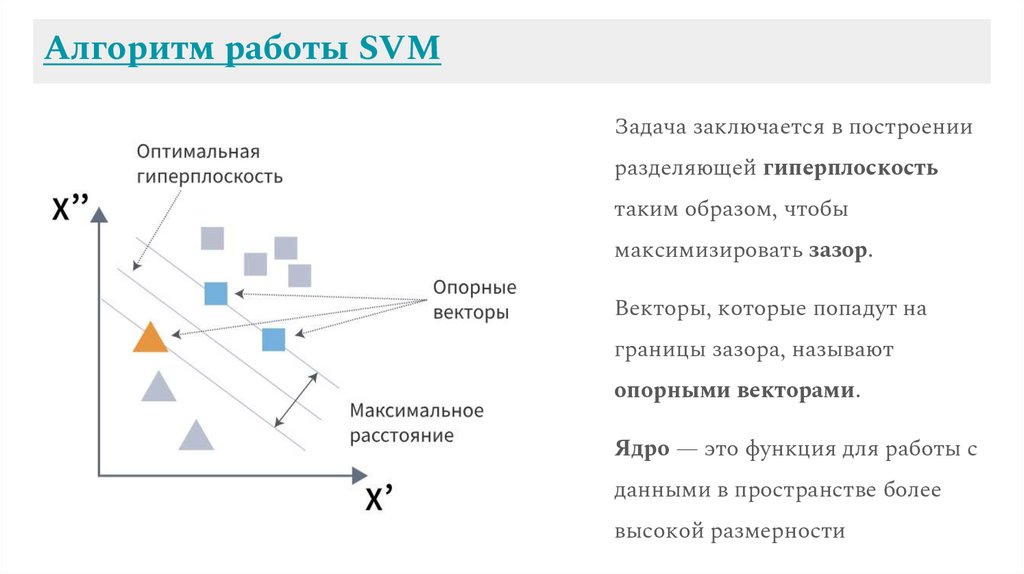
Алгоритм работы SVMЗадача заключается в построении
разделяющей гиперплоскость
таким образом, чтобы
максимизировать зазор.
Векторы, которые попадут на
границы зазора, называют
опорными векторами.
Ядро — это функция для работы с
данными в пространстве более
высокой размерности
13.
Рекуррентные нейронные сети (RNN)Определение: RNN — это тип нейронных сетей, предназначенный для работы с
последовательностями данных.
Применение: Различные задачи, таких как машинный перевод, распознавание
рукописного ввода, генерация текста и другие задачи, где важен контекст и порядок
слов.
Преимущества:
1. RNN учитывают порядок слов в тексте.
2. Однако они также имеют некоторые ограничения, такие как затрудненное
обучение на длинных последовательностях из-за проблемы "затухания градиента".
14.
Рекуррентные нейронные сети (RNN)Рекуррентная нейронная сеть и ее развертка (unfolding)
x_t — вход на временном шаге t.
s_t — это скрытое состояние на шаге t.
o_t — выход на шаге t.
15.
ТрансформерыОпределение: Трансформеры — это архитектура, которая была впервые представлена в
статье "Attention is All You Need".
Применение: классификация текста, вопросно-ответные системы, перевод и др.
Преимущества:
1. Механизм внимания позволяет моделям трансформера обрабатывать длинные
последовательности данных.
2. Учет контекста из разных частей текста.
16.
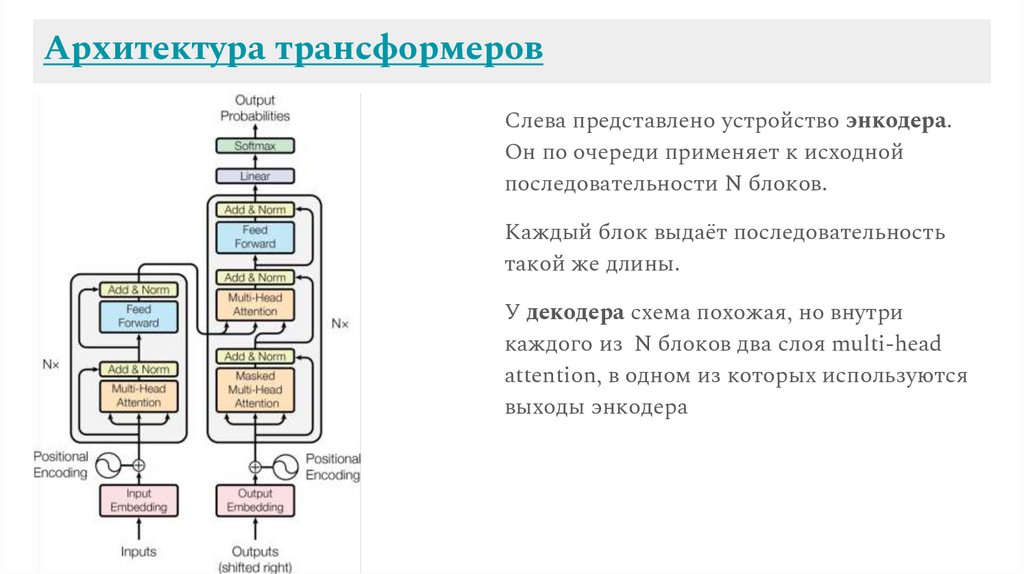
Архитектура трансформеровСлева представлено устройство энкодера.
Он по очереди применяет к исходной
последовательности N блоков.
Каждый блок выдаёт последовательность
такой же длины.
У декодера схема похожая, но внутри
каждого из N блоков два слоя multi-head
attention, в одном из которых используются
выходы энкодера
17.
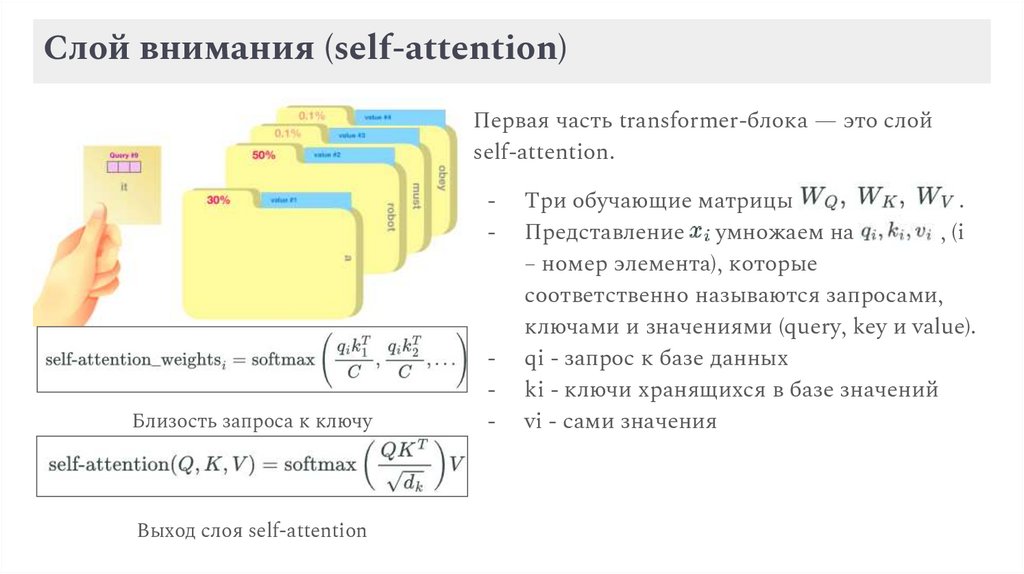
Слой внимания (self-attention)Первая часть transformer-блока — это слой
self-attention.
-
Близость запроса к ключу
Выход слоя self-attention
-
Три обучающие матрицы
.
Представление xi умножаем на
, (i
– номер элемента), которые
соответственно называются запросами,
ключами и значениями (query, key и value).
qi - запрос к базе данных
ki - ключи хранящихся в базе значений
vi - сами значения
18.
ЗаключениеАвтоматическая обработка текста продолжает развиваться с быстрыми темпами
благодаря новым методам и технологиям машинного обучения. Она играет ключевую
роль в создании интеллектуальных систем, способных взаимодействовать с человеком
на естественном языке, обеспечивая новые возможности в различных отраслях, от
бизнеса и медицины до развлечений и образования.