








 education
educationSimilar presentations:










Дослідження методів балансування даних
1.
ДОСЛІДЖЕННЯ МЕТОДІВБАЛАНСУВАННЯ ДАНИХ
КЕРІВНИК К.Ф.-М.Н., ДОЦ. ФІРСОВ О.Д.
СТУДЕНТ ГРЕВЦОВ МИКОЛА ЄВГЕНІЙОВИЧ
2.
ОБ’ЄКТ ТА ПРЕДМЕТ ДОСЛІДЖЕННЯОБ’ЄКТ ДОСЛІДЖЕННЯ
• Об’єктом дослідження є процес балансування
даних у контексті машинного навчання. Цей
процес спрямований на подолання проблеми
дисбалансу класів у навчальних вибірках.
Об’єктом є різні методи, стратегії та техніки,
призначені для досягнення збалансованості в
даних з метою поліпшення продуктивності
моделей машинного навчання.
ПРЕДМЕТ ДОСЛІДЖЕННЯ
• Предметом дослідження є конкретні методи і
стратегії балансування даних у машинному
навчанні. У фокусі уваги перебувають
технології та підходи, що використовуються
для корекції дисбалансу в навчальних
вибірках з метою поліпшення
продуктивності моделей машинного
навчання.
3.
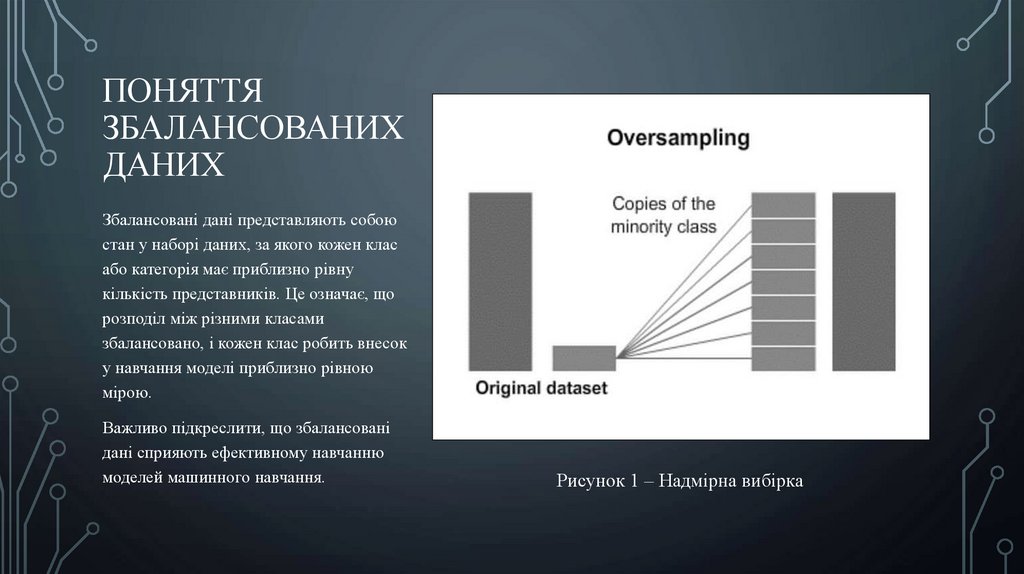
ПОНЯТТЯЗБАЛАНСОВАНИХ
ДАНИХ
Збалансовані дані представляють собою
стан у наборі даних, за якого кожен клас
або категорія має приблизно рівну
кількість представників. Це означає, що
розподіл між різними класами
збалансовано, і кожен клас робить внесок
у навчання моделі приблизно рівною
мірою.
Важливо підкреслити, що збалансовані
дані сприяють ефективному навчанню
моделей машинного навчання.
Рисунок 1 – Надмірна вибірка
4.
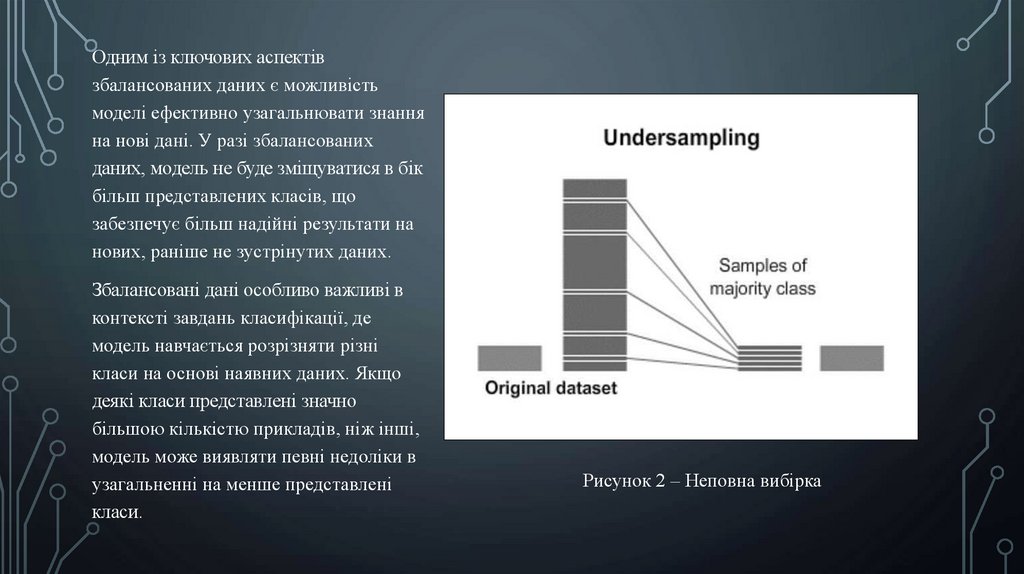
Одним із ключових аспектівзбалансованих даних є можливість
моделі ефективно узагальнювати знання
на нові дані. У разі збалансованих
даних, модель не буде зміщуватися в бік
більш представлених класів, що
забезпечує більш надійні результати на
нових, раніше не зустрінутих даних.
Збалансовані дані особливо важливі в
контексті завдань класифікації, де
модель навчається розрізняти різні
класи на основі наявних даних. Якщо
деякі класи представлені значно
більшою кількістю прикладів, ніж інші,
модель може виявляти певні недоліки в
узагальненні на менше представлені
класи.
Рисунок 2 – Неповна вибірка
5.
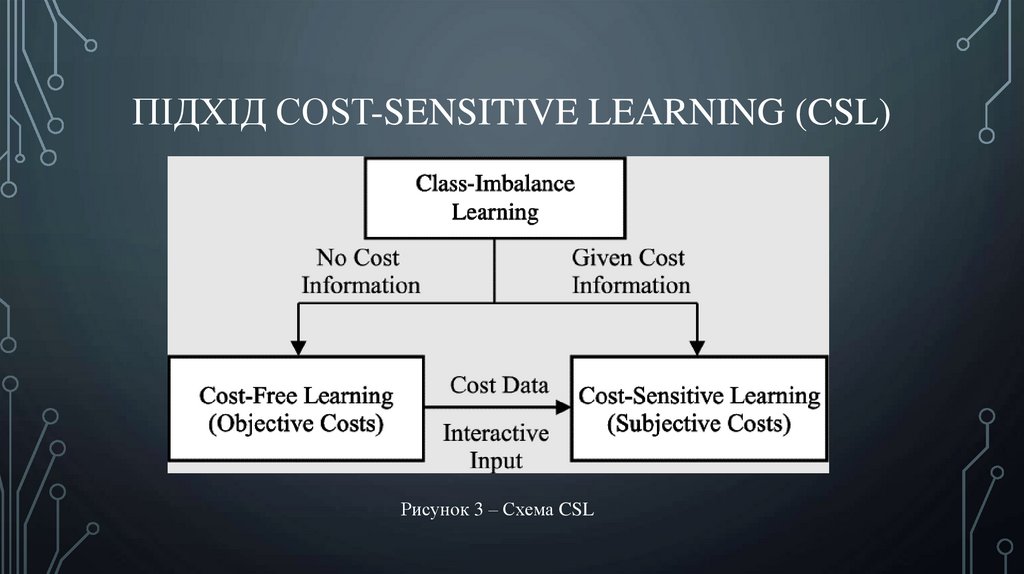
ПІДХІД COST-SENSITIVE LEARNING (CSL)Рисунок 3 – Схема CSL
6.
Cost-Sensitive Learning (CSL) – це підхід у машинному навчанні, який враховує вартістьпомилок різних типів під час навчання моделей.
На відміну від традиційних методів, де всі помилки розглядаються як рівнозначні, CSL
дозволяє алгоритмам враховувати різні наслідки помилок для різних класів. Цей метод
особливо корисний у ситуаціях, де дисбаланс класів поєднується з нерівнозначною
важливістю помилок.
Основною ідеєю CSL є введення ваг, що відображають вартість помилок для кожного
класу. Ваги застосовуються під час навчання моделі, даючи їй змогу враховувати
додаткові витрати, пов’язані з помилками в конкретних класах. Це надає можливість
моделі точніше налаштовуватися на задані вимоги бізнесу або контексту завдання.
7.
ПІДХІД ENSEMBLE METHODSРисунок 4 – Складові Ensemble Methods
8.
• Ensemble Methods є сучасним підходом у машинному навчанні, якийоб’єднує прогнози від декількох моделей, щоб отримати більш точні та
стійкі прогнози, ніж та, яку могла б надати кожна модель окремо. Цей
метод ґрунтується на принципі «мудрості натовпу» і прагне використати
розмаїття моделей для поліпшення узагальнюючої здатності та
зниження ризику перенавчання.
• Основною ідеєю Ensemble Methods є комбінування прогнозів від
декількох базових моделей з метою створення єдиного, більш надійного
прогнозу. Цей процес відбувається на двох основних етапах:
– навчання;
– прийняття рішень.
9.
МЕТОД CLUSTER-BASED OVER SAMPLING(SMOTE-NC, SMOTE-ENN)
• Cluster-Based Over Sampling (SMOTE-NC, SMOTE-ENN) представляє
собою інноваційний метод балансування даних, що об’єднує переваги
алгоритму Synthetic Minority Over-sampling Technique (SMOTE) з
використанням методів Cluster Centroids (SMOTE-NC) і Edited Nearest
Neighbours (SMOTE-ENN).
• Цей підхід прагне впоратися з проблемою дисбалансу класів, з якою
стикаються моделі машинного навчання.
10.
SMOTE-NCSMOTE-NC додає в процес генерації
синтетичних прикладів додатковий
крок, званий Neighborhood Cleaning.
Цей крок спрямований на видалення
шуму з навчальної вибірки. У
процесі SMOTE-NC, кластери даних
формуються, і для кожного прикладу
з меншого класу генеруються
синтетичні приклади, як і в
звичайному SMOTE.
Рисунок 5 – Приклад використання SMOTE-NC
11.
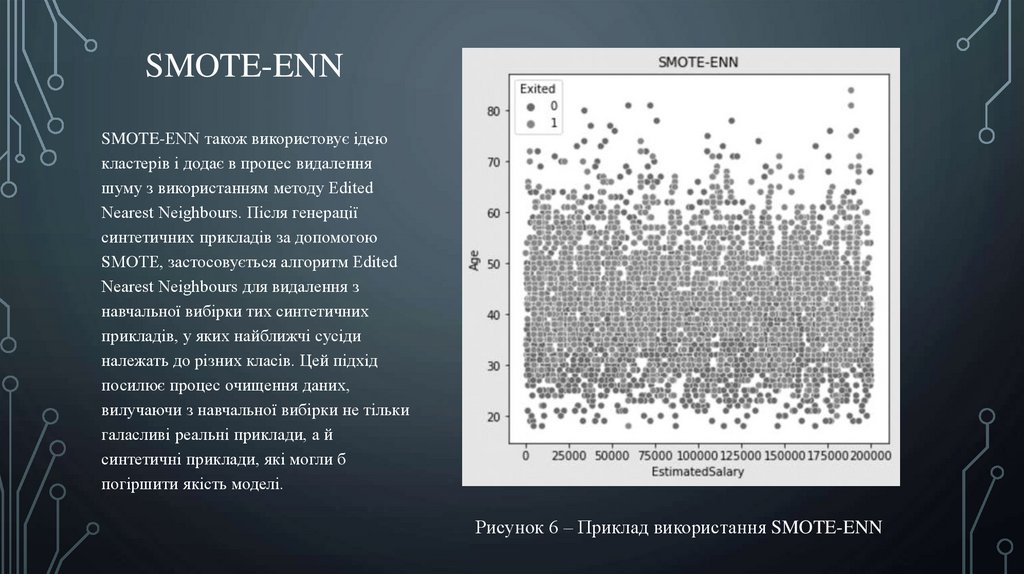
SMOTE-ENNSMOTE-ENN також використовує ідею
кластерів і додає в процес видалення
шуму з використанням методу Edited
Nearest Neighbours. Після генерації
синтетичних прикладів за допомогою
SMOTE, застосовується алгоритм Edited
Nearest Neighbours для видалення з
навчальної вибірки тих синтетичних
прикладів, у яких найближчі сусіди
належать до різних класів. Цей підхід
посилює процес очищення даних,
вилучаючи з навчальної вибірки не тільки
галасливі реальні приклади, а й
синтетичні приклади, які могли б
погіршити якість моделі.
Рисунок 6 – Приклад використання SMOTE-ENN
12.
ПРОГРАМНА РЕАЛІЗАЦІЯРисунок 7 – Процес балансування даних за допомогою метода RandomOverSampler
13.
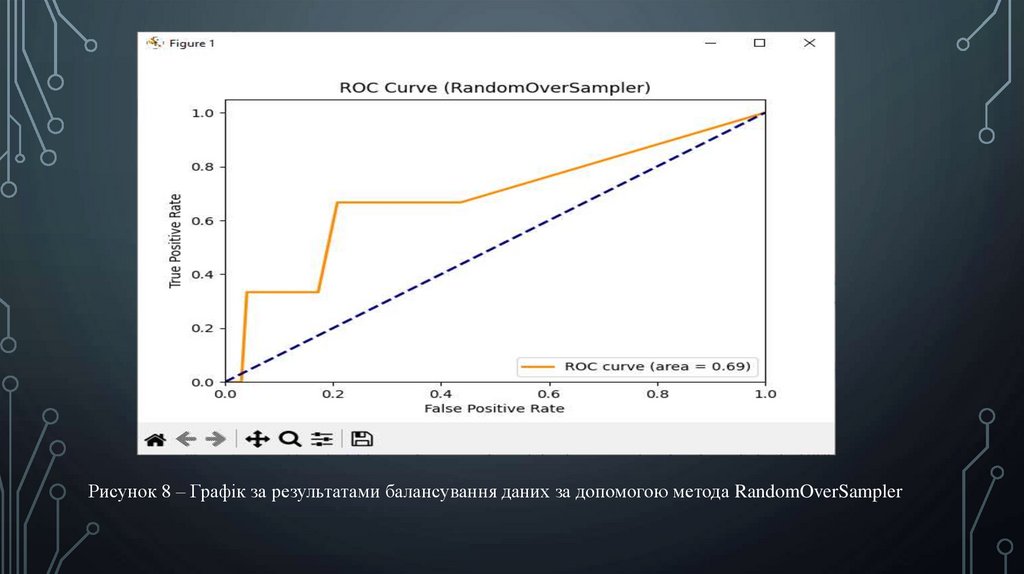
Рисунок 8 – Графік за результатами балансування даних за допомогою метода RandomOverSampler14.
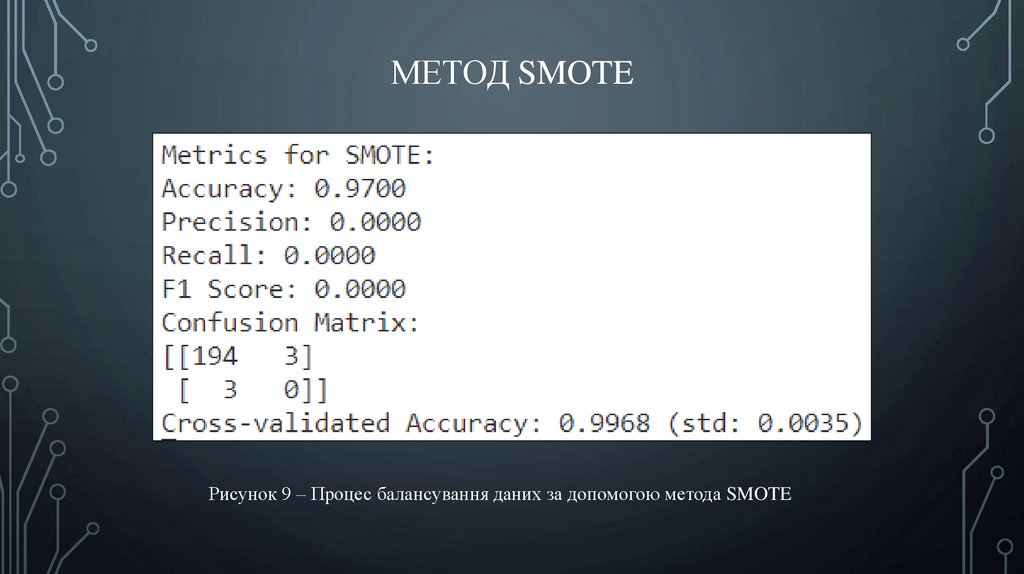
МЕТОД SMOTEРисунок 9 – Процес балансування даних за допомогою метода SMOTE
15.
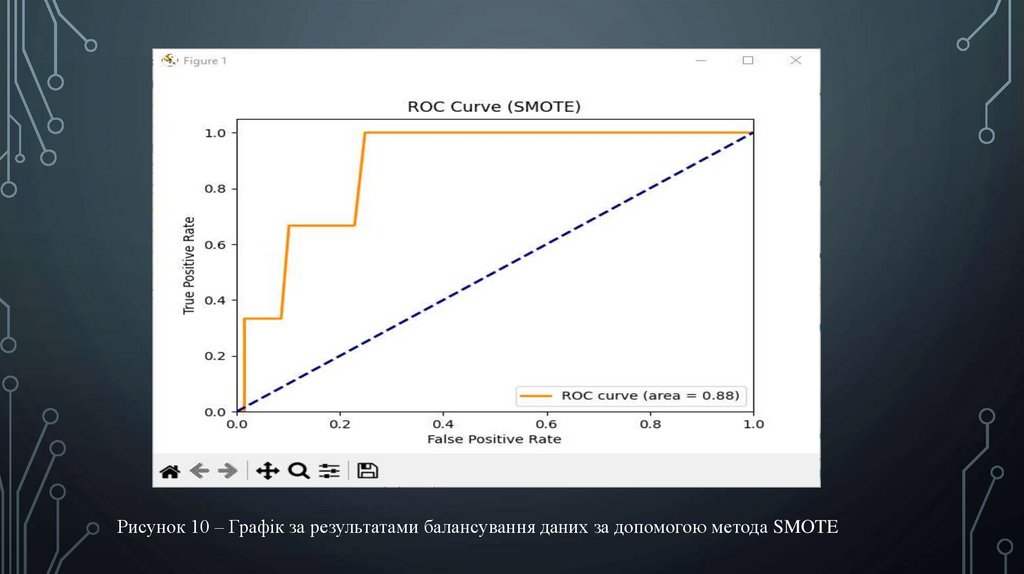
Рисунок 10 – Графік за результатами балансування даних за допомогою метода SMOTE16.
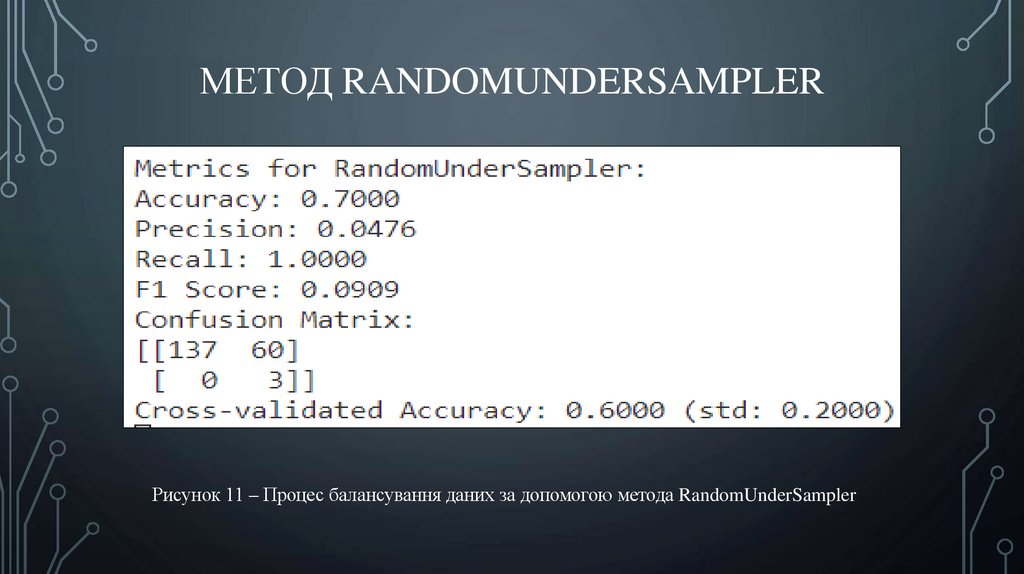
МЕТОД RANDOMUNDERSAMPLERРисунок 11 – Процес балансування даних за допомогою метода RandomUnderSampler
17.
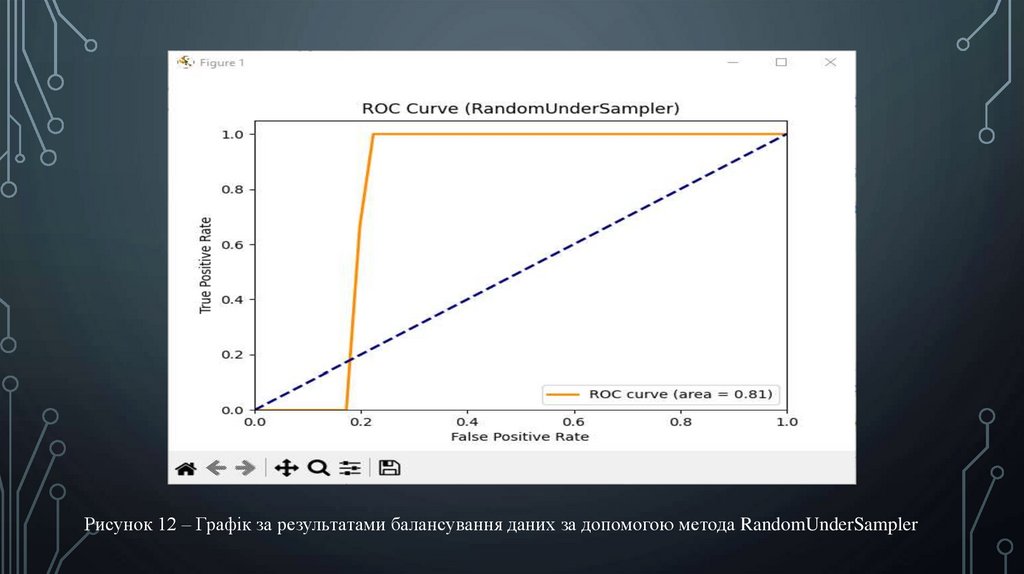
Рисунок 12 – Графік за результатами балансування даних за допомогою метода RandomUnderSampler18.
ВИСНОВКИ• Отримані результати показали, що в залежності від обраного метода,
результати експериментів можуть суттєво відрізнятись. Так, у
останньому методі RandomUnderSampler точність склала усього 60%,
тоді як попередні методи дозволили досягти точності майже 100%.
• Після отриманих результатів були побудовані відповідні графіки, які
демонструють результат балансування даних з використанням
різноманітних методів.