









 informatics
informaticsSimilar presentations:








")

Теория кодирования
1. Теория кодирования
Одна из задач теории информации - отыскание наиболееэффективных методов кодирования, позволяющих передать
заданную информацию с помощью минимального количества
символов как при отсутствие, так и при наличии помех в канале
связи.
Кодирование в ЭВМ предназначено для решения
следующих основных задач программирования:
представления различных данных (чисел, текста, графики) в
памяти компьютера;
защита информации от несанкционированного доступа;
обеспечение помехоустойчивости при передаче данных по
каналам связи;
сжатие информации.
2. Кодирование
• При кодировании каждый символ источника Siзаменяется последовательностью букв некоторого
другого алфавита A = {a1,a2,...an}, которые затем уже
передаются по линиям связи в виде сигналов.
• Последовательность букв, соответствующих некоторому
символу источника, называется кодовым словом.
• Множество кодовых слов называется кодом.
• Коды бывают равномерные и неравномерные. В
равномерных кодах каждое кодовое слово одинаковой
длины.
• Неравномерные коды могут быть префиксными,
которые не требуют разделительных знаков между
кодовыми словами и обладают свойством
самосинхронизации, позволяющим однозначно
разделять кодовые слова в последовательности
сообщений.
3. Метод кодирования Шеннона-Фано
1. Расположить сообщения в порядке возрастания ихвероятности появления.
2. Разбить сообщения на 2 подмножества, так чтобы
вероятности сообщений внутри каждого из подмножеств
были близки друг к другу (не переставляя элементы);
3. Присвоить каждому из подмножеств двоичный знак,
например первому -1, а второму -0.
4. Произвести операции 2 - 3 с каждым из подмножеств.
5. Все сообщения закодированы? Да - конец, нет - 4 шаг.
Код символа читается начиная с корня дерева.
4. Я НАДЕЮСЬ ОСТАТЬСЯ НА СТИПЕНДИИ
• Я2• Н3
• А3
• Д2
• Е2
• Ю1
• С3
• Ь2
• О1
• Т3
• И3
• П1
• ПРОБЕЛ 4
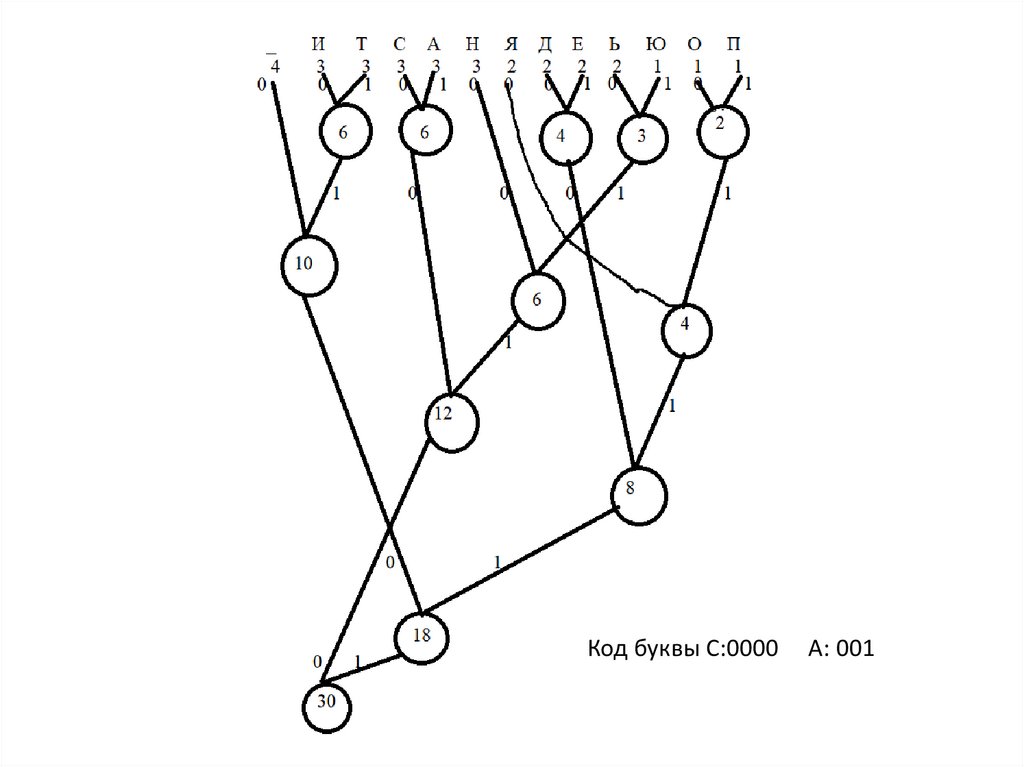
5.
Буква С: 0110, А: 0111 и т.д.6. Метод Хаффмана
1.Символы входного алфавита образуют список свободных узлов.Каждый лист имеет вес, который равный вероятности его
появления.
2. Выбираются два свободных узла дерева с наименьшими весами.
3. Создается их родитель с весом, равным их суммарному весу.
4. Родитель добавляется в список свободных узлов, а два его
потомка удаляются из этого списка.
5. Одной дуге, выходящей из родителя, ставится в соответствие бит
1, другой — бит 0
6. Шаги, начиная со 2, повторяются до тех пор, пока в списке
свободных узлов не останется только один свободный узел (корень
дерева)
Чтобы определить код для каждого из символов, входящих в
сообщение, мы должны пройти путь от корня дерева до
соответствующего текущему символу листа, накапливая биты
при перемещении по ветвям дерева
7.
Код буквы С:0000А: 001
8. Кодовые слова
символШеннон-Фано
Хаффман
Ь 2
1000
0110
Н 3
100
010
А 3
0111
001
Д 2
1101
1100
Е 2
1011
1101
Ю 1
1110
0111
С
3
0110
000
О
1
11111
11110
Т
3
010
011
И
3
001
1010
П
1
11110
11111
Пробел 4
000
100
Я 2
1100
1110
n‘ ШФ=(2*4+3*3+3*4+2*4+2*4+1*4+3*4+1*5+3*3+3*3+1*5+4*3+2*4)/30=3,63
n‘ Х =(2*4+3*3+3*3+2*4+2*4+1*4+3*3+1*5+3*3+3*4+1*5+4*3+2*4)/30=3,53
Начало предложения ШФ:110000010001111011011…
9. Особенности методов
• Сжатие данных по Хаффману применяется присжатии фото- и видеоизображений (JPEG, стандарты
сжатия MPEG), в архиваторах (PKZIP, LZH и др.), в
протоколах передачи данных MNP5 и MNP7.
• Для восстановления содержимого сжатого
сообщения декодер должен знать таблицу частот,
которой пользовался кодер. Следовательно, длина
сжатого сообщения увеличивается на длину
таблицы частот, которая должна посылаться
впереди данных, что может свести на нет все
усилия по сжатию сообщения.
10. Оценка эффективности кодирования
• Энтропия – это степень неопределенностиn
H ( x ) pi log pi
i 1
где pi - вероятности появления
символа
Свойства энтропии:
1. Энтропия обращается в ноль, когда одно из
состояний достоверно, а другие невозможны.
2. При заданном числе состояний H(x)
обращается в максимум, когда состояния
равновероятны.
11.
• Эффективность кодирования измеряется отношениемэнтропии на ср. число знаков кодового слова
• Эффективность кодирования тем выше, чем ближе этот
показатель к 1.
• Средняя длина кодового слова – это сумма произведений
вероятности появления символа на длину его кодового слова
n‘=длина кодового слова * вероятность буквы + …