


























 informatics
informaticsSimilar presentations:








")
. Заявка освобождает место в очереди")
Статистическая языковая модель
1.
Статистическаяязыковая модель
Грацианова Татьяна Юрьевна
Ефремова Наталья Эрнестовна
2.
СодержаниеПонятие статистической языковой
модели
N-граммная модель языка
Методы сглаживания
Оценка качества модели
Выводы
✻ Домашнее задание
✻ Материалы для домашнего изучения
2
3.
Статистическая языковаямодель
3
Приписывание любой фразе/предложению
W=(w1 w2 … wM), где wi – слово, вероятности
P(W)=P(w1 w2 … wM) ее появления в тексте
Используя условную вероятность, можно получить:
P(w1 w2 … wM) = P(w1) * P(w2|w1) * …
… * P(wM|w1 w2 … wM-1)
И поставить задачу предсказания следующего
слова в последовательности P(wK|w1 w2 … wK-1)
При создании модели:
вычисляют вероятности (по корпусу)
при необходимости устраняют ее недостатки –
сглаживают
оценивают качество построенной модели
4.
Области примененияязыковых моделей
Выявление разного рода ошибок
опечатки: P(на странице 25) > P(на страннице 25)
неверный порядок слов: P(the bed is) > P(the is bed)
некорректное употребление слов:
P(my house is small) > P(my home is small)
Машинный перевод: проверка, насколько полученное
предложение вероятно, выбор слова при переводе
(а herd of horses – табун или стадо лошадей)
Распознавание речи: некоторые различные по написанию
слова произносятся одинаково. Нужно выбрать в контексте
правильное слово
P(кишечный грипп) > P(кишечный гриб)
P(несуразные вещи) ? P(несу разные вещи)
Генерация текста, например, составление рефератов и
аннотаций
4
5.
N-граммная модельКорпус ограничен: чем больше K, тем большего
количества правильных фраз такой длины там нет
P(wK|w1 w2 … wK-1) не всегда можно вычислить
Рассматривают N-граммы – последовательности из N
слов W=(w1 w2 … wM ). Обычно N = 1, 2, 3 или 4
Вероятность P всего предложения вычисляется как
произведение P входящих в него N-грамм
Марковская модель: учитывается только N-1
предыдущих слов. При N=3 получим
P(w1 w2 … wM) ≈ P(w1)*P(w2|w1)*P(w3|w1w2)…*P(wM|wM-2wM-1)
Вероятности вычисляются по корпусу, например, с
опорой на частоты фраз (C=Fa)
P(wK|w1 w2 … wK-1) = С(w1 w2 … wK) / w С(w1 w2 … wK-1 w)
5
6.
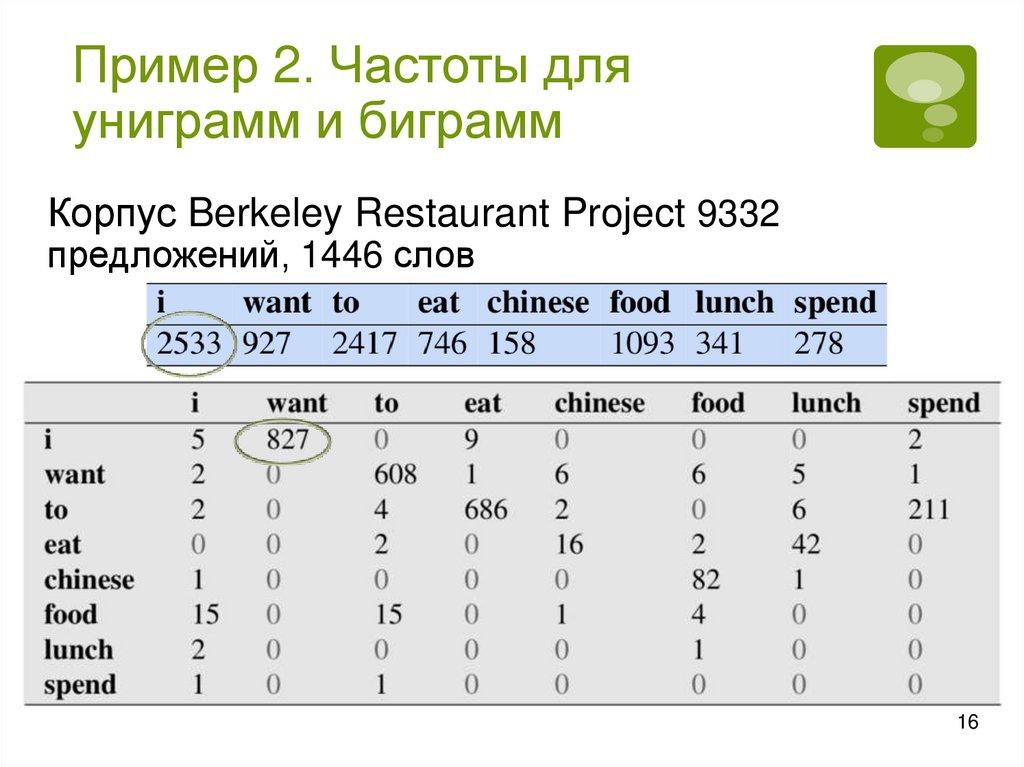
Пример 1. Вычислениевероятности предложения
Для простоты рассмотрим N=2
Вычислим P для предложения I want to eat:
P(I want to eat) =
P(I) * P(want|I) * P(to|want) * P(eat|to)
P(I) = C(I), P(want|I) = C(I want) / Fr(I) и т.д.
По корпусу Berkeley Restaurant Project получено:
P(I) = 0,25
P(want|I) = 0,32
P(to|want)= 0,65
P(eat|to) = 0,26
Следовательно,
P(I want to eat) = 0,25*0,32*0,65*0,26 ≈ 0,014
Что тут может быть не так?
6
7.
Начало предложенияКакие-то слова встречаются в начале предложений, а
какие-то нет
Для более правильного подсчета вероятности для
первого слова добавим токен начала – <S>
N=2: P(Это тоже предложение) = P(это|<S>) *
P(тоже|это) * P(предложение|тоже)
N=3: P(Это тоже предложение) = P(это|<S> <S>) *
P(тоже|<S> это) * P(предложение|это тоже)
Дополнительно возможно введение токена конца:
для согласованности модели
чтобы незаконченные предложения не имели
большую вероятность
*I saw the и I saw the red house
8.
Практическая работа №1Вычислить P для предложения
I want English food:
P(I|<S>) = 0,25
P(english|want) = 0,0011
P(want|i) = 0,33 P(food|english) = 0,5
P(I want English food) =
8
9.
Практическая работа №1.Решение
Вычислить P для предложения
I want English food:
P(I|<S>) = 0,25
P(english|want) = 0,0011
P(want|i) = 0,33 P(food|english) = 0,5
P(I want English food) =
P(I|<S>) * P(want|I) *
P(english|want) * P(food|english) =
= 0,25 * 0,33 * 0,0011 * 0,5 = 0,000045
9
10.
Обсуждение1. Как сгенерировать случайное
предложение в N-граммной модели?
2. Что делать со словами, которых нет в
обучающем корпусе?
3. Назовите достоинства и недостатки
N-граммной модели
4. Назовите достоинства и недостатки
выбора большого/маленького N?
11.
Плюсы и минусыN-граммной модели
+ Возможность построения модели по корпусу
+ Относительная простота использования
− Предположение о независимости
вероятности от более длинной истории
The computer which I had just put into the machine room
on the fifth floor crashed
− Колоссальные объемы хранимой информации
Если в языке 1000 слов, то получим:
106 биграмм, 109 триграмм, 1012 тетраграмм
− Недостаточность данных для построения
модели (ограниченность корпуса и его специфика)
P=0 у неправильной N-граммы –
P=0 у N-граммы, которой нет в корпусе –
11
12.
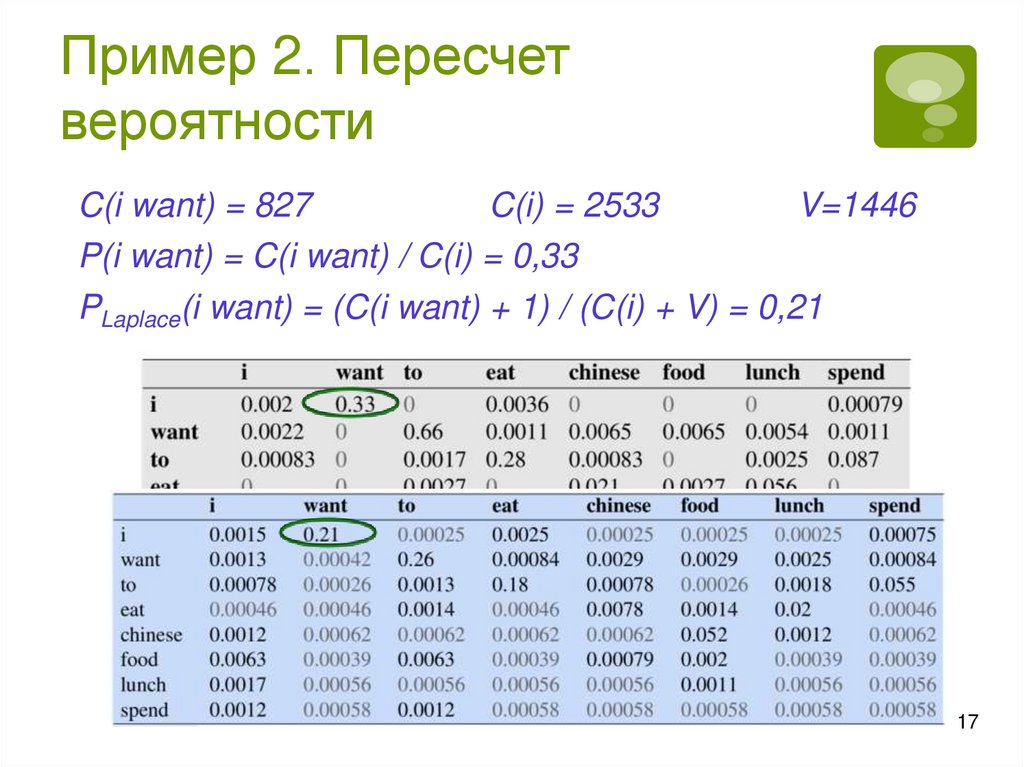
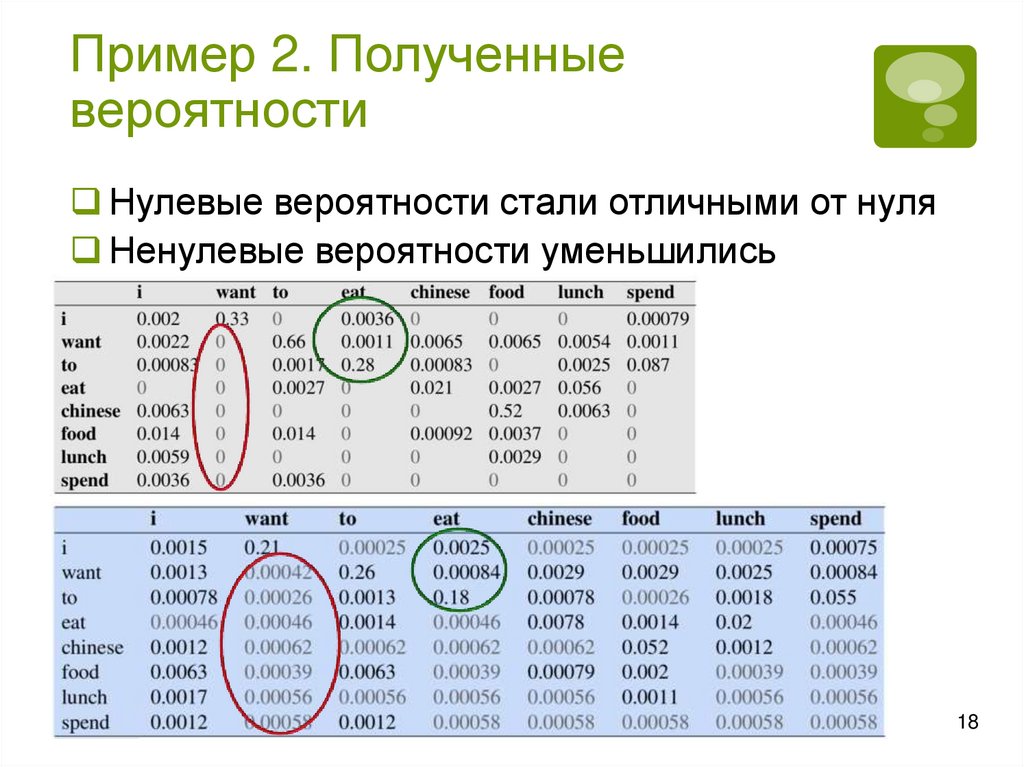
Сглаживание. ИдеяНедостаточность данных для построения модели
некорректные вероятности
Пусть в корпусе нет фразы Russian food. Тогда
P(food|Russian)=0 и, следовательно,
P(I want Russian food) = 0
Применяется сглаживание: модифицируются
частоты/вероятности – понижают частоты/вероятности
у одних и повышают их у других
Один из способов – добавление 1 (Add-One Smoothing,
Laplace Smoothing). Например, для биграмм