
























 informatics
informaticsSimilar presentations:
")
")

")






Преобразование данных. Лекция 7
1.
Преобразование данныхЛекция 7
Cатыбалдиева Р.Ж.
2.
Содержание• Выявление и восполнение недостающих
значений
• Группировка
• Форматирование данных
Cатыбалдиева Р.Ж.
3.
Предварительная обработка данных сиспользованием Python
• предварительная обработка данных является необходимым
шагом в анализе данных.
• Это процесс преобразования или сопоставления данных из одной
исходной формы в другой формат, чтобы сделать его готовым для
дальнейшего анализа.
• Предварительная обработка данных часто называется очисткой
данных или спором данных.
Cатыбалдиева Р.Ж.
4.
Работа с отсутствующими значениями сиспользованием Python
• Что делать, когда вы сталкиваетесь с недостающими значениями
в ваших данных.
• эта значит, что функция имеет недостающее значение.
• Обычно отсутствующее значение в наборе данных отображается
как “?”, “N/A”, 0 или просто пустая ячейка.
• Есть много способов справиться с недостающими значениями, и
это независимо от Python, R или любого другого инструмента
Cатыбалдиева Р.Ж.
5.
Решение для отсутствующих значений• Во-первых, проверить, может ли человек или группа, которые собрали
данные, вернуться и найти фактическое значение.
• Другая возможность - просто удалить данные, в которых найдено это недостающее значение.
• Когда вы удаляете данные, вы можете либо удалить всю переменную, либо только одну запись
данных с отсутствующим значением.
• Если у вас нет большого количества наблюдений с отсутствующими данными, обычно
отбрасывать конкретную запись лучше всего.
• Если вы удаляете данные, вы хотите посмотреть, чтобы сделать что-то, что имеет наименьшее
влияние.
Cатыбалдиева Р.Ж.
6.
Замена данных• Замена данных лучше, так как данные не тратится впустую.
• Тем не менее, это менее точно, так как нам нужно заменить
отсутствующие данные догадкой о том, какими должны быть
данные.
• Одним из стандартных методов размещения является замена
пропущенных значений средним значением всей переменной.
• Но что делать, если значения не могут быть усреднены, как с
категориальными переменными?
Cатыбалдиева Р.Ж.
7.
Решение• попробовать использовать режим наиболее распространенный, как
бензин.
• Наконец, иногда мы можем найти другой способ угадать недостающие
данные.
• Обычно это происходит потому, что собранные данные знают что-то
дополнительное о недостающих данных
• можно просто оставить отсутствующие данные как отсутствующие
данные
• По той или иной причине может быть полезно сохранить это
наблюдение, даже если некоторые функции отсутствуют.
Cатыбалдиева Р.Ж.
8.
Решение в Python• Для удаления данных, содержащих отсутствующие
значения библиотека pandas имеет встроенный метод под
названием dropna.
• По сути, с помощью метода dropna вы можете удалить строки или
столбцы, содержащие отсутствующие значения, такие как NaN.
• нужно указать доступ равный 0, чтобы удалить строки или доступ
равен 1, чтобы удалить столбцы, содержащие отсутствующие
значения.
• Это можно просто сделать в одной строке кода, используя
dataframe.dropna.
Cатыбалдиева Р.Ж.
9.
Cатыбалдиева Р.Ж.Установка аргумента на месте true, позволяет
изменять набор данных напрямую.
На месте равно true, просто записывает
результат обратно в фрейм данных.
Это эквивалентно этой строке кода.
эта строка кода не изменяет фрейм данных, но
является хорошим способом убедитесь, что вы
выполняете правильную операцию.
Чтобы изменить фрейм данных, необходимо
установить параметр на месте равно true.
всегда надо проверять документацию, если вы
не знакомы с функцией или методом.
Веб-страница pandas содержит много полезных
ресурсов.
10.
Замена• Чтобы заменить отсутствующие значения, такие как NAN, фактическими значениями,
библиотека Pandas имеет встроенный метод, называемый replace, который может
быть использован для заполнения пропущенных значений вновь вычисленными значениями
• В примеру предположим, надо заменить пропущенные значения переменной
нормализованные потери на среднее значение переменной.
• недостающее значение должно быть заменено на среднее значение записей в этом столбце.
Cатыбалдиева Р.Ж.
11.
Метод replaceВ Python сначала вычисляем среднее значение столбца.
Затем мы используем метод replace to укажите значение,
которое мы хотели бы заменить в качестве первого параметра, в
данном случае NaN.
Вторым параметром является значение, которое надо заменить
его на то есть среднее в этом примере.
Cатыбалдиева Р.Ж.
12.
Форматирование данных сиспользованием Python
• Данные обычно собираются из разных мест разными людьми,
которые могут храниться в разных форматах.
• Форматирование данных означает приведение данных в общий
стандарт выражения, который позволяет пользователям делать
значимые сравнения.
• В рамках очистки набора данных форматирование
данных обеспечивает согласованность и легко понятность данных
Cатыбалдиева Р.Ж.
13.
Типы данных в Python и Pandas• По ряду причин, в том числе при импорте набора данных в Python, тип
данных может быть установлен неправильно.
• Для последующего анализа важно изучить тип данных объектов и
преобразовать их в правильные типы данных.
• В противном случае разработанные модели могут вести себя
странно, и полностью достоверные данные могут в конечном итоге
рассматриваться как отсутствующие данные.
• В Pandas много типов данных.
• Объекты могут быть буквами или словами.
• Int64 - целые числа, с плавающей точкой - реальные числа.
• Есть много других, которые мы не будем обсуждать.
Cатыбалдиева Р.Ж.
14.
Определение типа данных объектовЧтобы определить тип данных объектов, в Python мы можем
использовать метод
dataframe.dtypes
и проверить тип данных каждой переменной во фрейме данных.
• В случае неправильных типов данных метод
dataframe.astype
• может быть использован для преобразования типа данных из
одного формата в другой.
Cатыбалдиева Р.Ж.
15.
Нормализация данных с использованиемPython
• нормализация может облегчить некоторые статистические
анализы.
• Обеспечивая согласованность диапазонов между переменными,
нормализация позволяет сравнивать различные
функции, убедившись, что они имеют одинаковое влияние.
• Это также важно по вычислительным причинам.
Cатыбалдиева Р.Ж.
16.
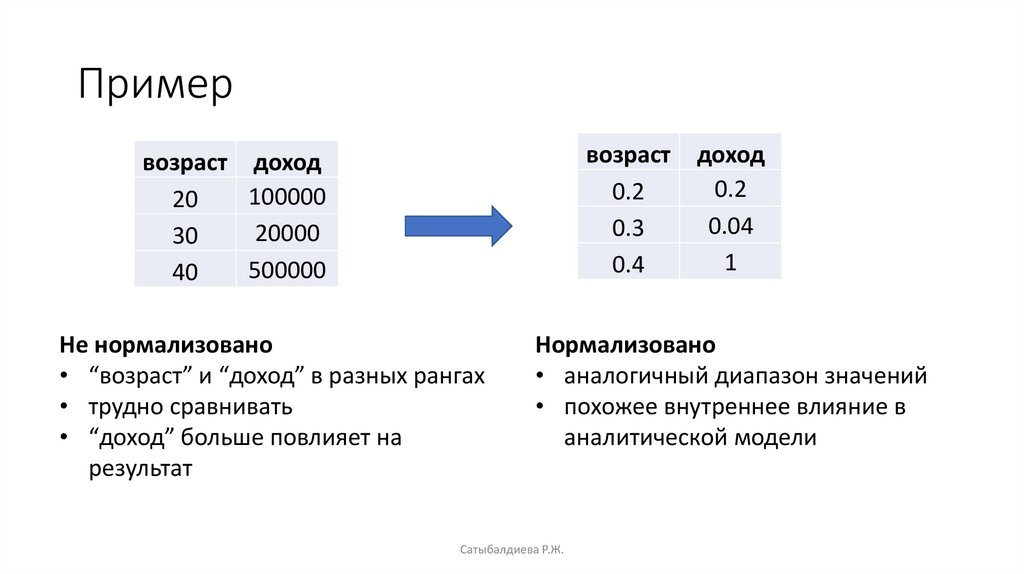
Примервозраст
0.2
0.3
0.4
возраст доход
100000
20
20000
30
500000
40
Не нормализовано
• “возраст” и “доход” в разных рангах
• трудно сравнивать
• “доход” больше повлияет на
результат
доход
0.2
0.04
1
Нормализовано
• аналогичный диапазон значений
• похожее внутреннее влияние в
аналитической модели
Cатыбалдиева Р.Ж.
17.
1. простое масштабирование объектов, просто делит каждое значение на максимальноезначение для этого объекта.
• Это делает новые значения диапазоном от нуля до единицы.
1. min-max, принимает каждое значение Xold вычитает его из минимального значения этой
функции, затем делится на диапазон этой функции.
• Опять же, результирующие новые значения варьируются от нуля до единицы.
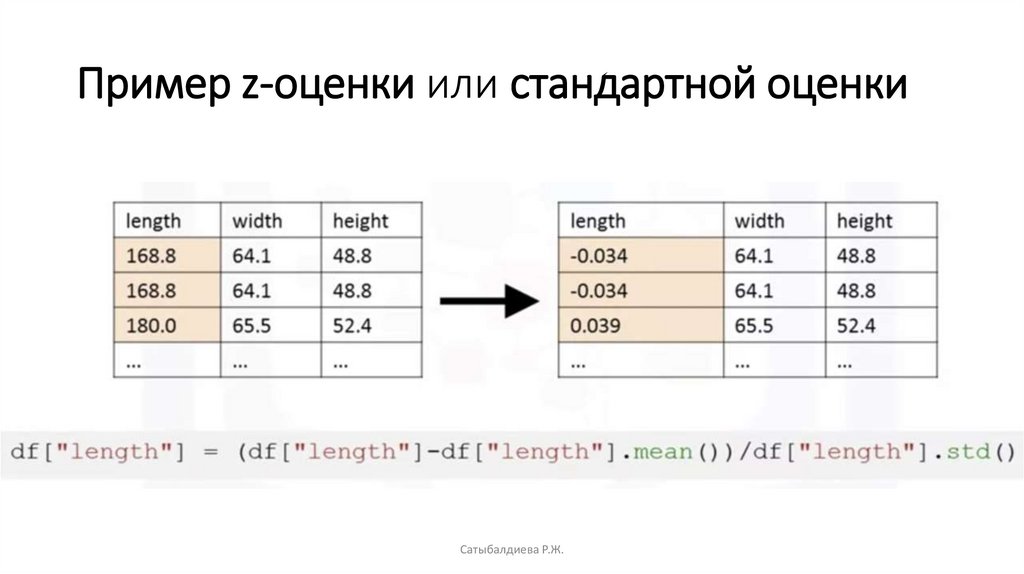
1. z-оценка или стандартная оценка.
Методы
нормализации
данных
• В этой формуле для каждого значения вы вычитаете mu, которое является средним
значением объекта, а затем делите на стандартное отклонение сигма.
• Полученные значения зависают вокруг нуля, и обычно варьируются между
отрицательными тремя и положительными тремя, но могут быть выше или ниже.
Cатыбалдиева Р.Ж.
18.
Пример простого масштабированияобъектов
Cатыбалдиева Р.Ж.
19.
Пример min-maxCатыбалдиева Р.Ж.
20.
Пример z-оценки или стандартной оценкиCатыбалдиева Р.Ж.
21.
Метод предварительной обработкиданных binning
• Binning — это когда вы группируете значения вместе в бины.
Например, вы можете разбить «возраст»
• на [от 0 до 5], [от 6 до 10], [от 11 до 15] и так далее.
• Иногда Binning может повысить точность прогнозных моделей.
• Кроме того, иногда мы используем бининг данных для группировки
набора числовых значений в меньшее количество бинов, чтобы лучше
понять распределение данных.
• Например, «цена» здесь представляет собой диапазон атрибутов от 5
000 до 45 500.
• Используя binning, мы классифицируем цену на три бина: низкая цена,
средняя цена и высокие цены
Cатыбалдиева Р.Ж.
22.
Пример binningCатыбалдиева Р.Ж.
23.
Преобразование категориальных переменных вколичественные переменные в Python
• Большинство статистических моделей не могут принимать объекты или
строки в качестве входных данных, а для обучения модели использовать
только числа в качестве входных данных.
• В наборе данных автомобиля функция типа топлива в качестве
категориальной переменной имеет два значения, газ или дизель, которые
находятся в строковом формате.
• Для дальнейшего анализа мы можем преобразовать эти переменные в
некоторую форму числового формата.
• Мы кодируем значения, добавляя новые функции,
соответствующие каждому уникальному элементу в исходной функции,
которую мы хотели бы кодировать.
• Когда значение встречается в исходном объекте, мы устанавливаем
соответствующее значение на единицу в новом объекте.
• Остальные функции установлены на ноль.
Cатыбалдиева Р.Ж.
24.
ПримерВ примере топлива для автомобиля В стоимость топлива составляет дизельное топливо.
Поэтому мы устанавливаем функцию дизельного топлива равным единице, а газового объекта равным
нулю.
Аналогичным образом, для автомобиля D стоимость топлива - газ.
Поэтому мы устанавливаем функцию газа равным единице, а особенность дизеля равным нулю.
Этот метод часто называют «одноразовым горячим кодированием.
Cатыбалдиева Р.Ж.
25.
Метод get_dummies• В Pandas мы можем использовать метод get_dummies для
преобразования категориальных переменных в фиктивные
переменные.
• В Python преобразование категориальных переменных в
фиктивные переменные просто.
• Следуя примеру, метод pd.get_dummies получает столбец типа
топлива и создает фрейм данных dummy_variable_1.
• Метод get_dummies автоматически генерирует список
чисел, каждый из которых соответствует определенной категории
переменной.
Cатыбалдиева Р.Ж.
26.
Пример в PandasCатыбалдиева Р.Ж.
27.
Заключение• Были рассмотрены примеры преобразования, нормализации
данных в Python
Cатыбалдиева Р.Ж.