









































































 programming
programming informatics
informaticsSimilar presentations:










Интеллектуальная обработка данных: учебное пособие (практикум)
1.
Министерство науки и высшего образования Российской ФедерацииСибирский государственный университет науки и технологий
имени академика М. Ф. Решетнева
ИНТЕЛЛЕКТУАЛЬНАЯ ОБРАБОТКА ДАННЫХ
Утверждено редакционно-издательским советом университета
в качестве учебного пособия (практикума) для студентов магистратуры
по направлению
подготовки 27.04.03 «Системный анализ и управление»
очной формы обучения
Красноярск 2023
2.
УДК 004.928(075.8)ББК 32.977
К59
Рецензенты:
кандидат технических наук, доцент Р.И. Кузьмич
(Сибирский федеральный университет);
кандидат технических наук, доцент В.В. Становов
(Сибирский государственный университет науки и технологий
имени академика М. Ф. Решетнева)
Печатается по решению редакционно-издательского совета университета
К59
Интеллектуальная обработка данных: учебное
пособие (практикум) / Л.В. Липинский, С.С. Бежитский, А.С. Полякова,
А.В. Гуменникова, Е.А. Бежитская; СибГУ им. М. Ф. Решетнева. –
Красноярск, 2023. – 80 с.
Учебное пособие (практикум) «Интеллектуальная обработка данных»
содержит теоретический материал и задания к практическим занятиям
по разделам дисциплины «Интеллектуальная обработка данных».
Учебное пособие (практикум) «Интеллектуальная обработка данных»
предназначено для обучающихся технических направлений, а также
может быть рекомендовано для обучающихся других направлений,
изучающих область искусственного интеллекта и машинного обучения.
© СибГУ им. М. Ф. Решетнева, 2023
© Липинский Л. В., Бежитский С.С., Полякова А.С., Гуменникова А.В.,
Бежитская Е.А., 2023
2
3.
ОГЛАВЛЕНИЕОБЩИЕ СВЕДЕНИЯ .............................................................................. 4
1. ЗНАКОМСТВО С ЯЗЫКОМ ПРОГРАММИРОВАНИЯ
PYTHON 3.9 ................................................................................................ 6
1.1. Синтаксис языка Python ................................................................... 6
1.2. Библиотеки NumPy и Pandas ......................................................... 13
1.3. Предварительная обработка данных ............................................ 22
2. ПОСТРОЕНИЕ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ...... 28
2.1. Общая схема построения и оценки модели (на примере knnмоделей) .................................................................................................. 28
2.2. Оценка модели с помощью кросс-валидации ............................. 33
2.3. Выбор параметров с помощью решетчатого поиска .................. 36
3. ВИДЫ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ....................... 40
3.1. Линейные модели ........................................................................... 40
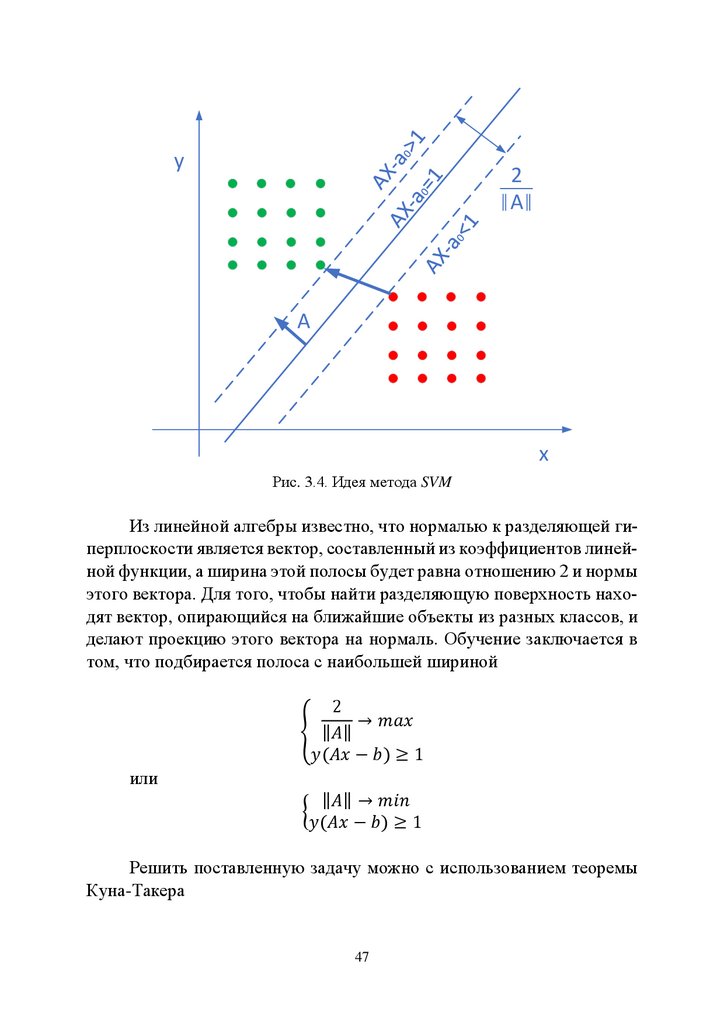
3.2 SVM.................................................................................................... 46
3.3 Деревья решений ............................................................................. 50
3.4. Ансамбли деревьев решений ......................................................... 54
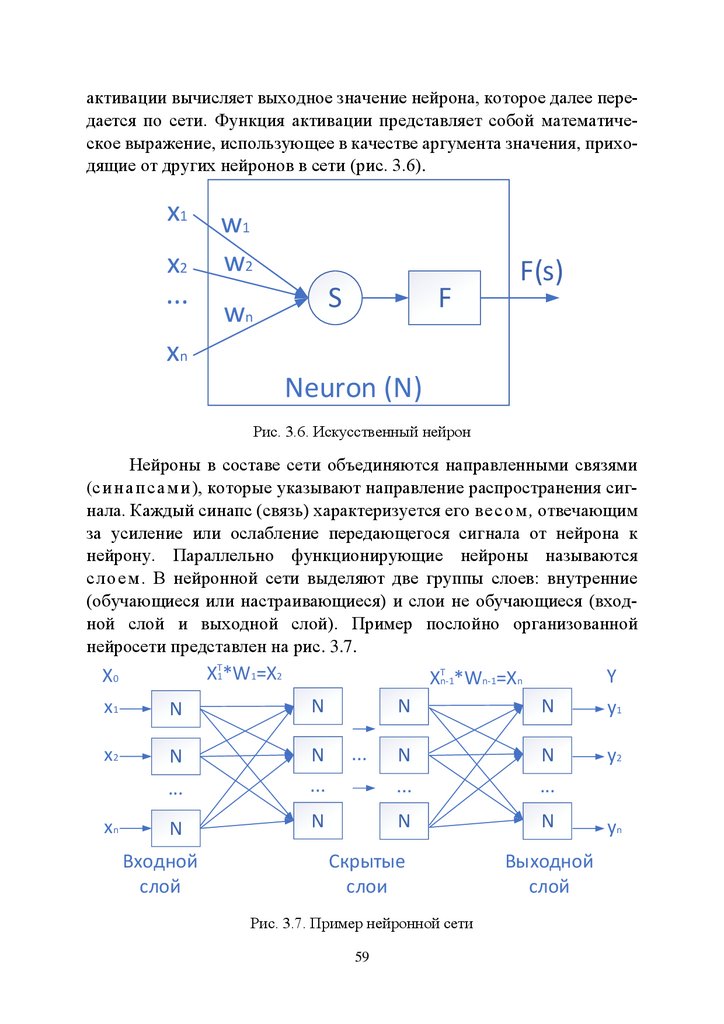
3.5. Нейронные сети .............................................................................. 58
4. ОФОРМЛЕНИЕ ОТЧЕТА ПО ПРАКТИЧЕСКОЙ РАБОТЕ ... 64
4.1. Требования к содержанию структурных элементов отчета ....... 64
4.2. Требования к оформлению и изложению содержательной части
отчета ...................................................................................................... 66
ЗАКЛЮЧЕНИЕ ...................................................................................... 75
БИБЛИОГРАФИЧЕСКИЙ СПИСОК ............................................... 76
3
4.
ОБЩИЕ СВЕДЕНИЯВ настоящее время методы машинного обучения из объектов исследования превратились в самостоятельные инструменты, способные
решать сложные задачи обработки и анализа данных и давать полезный
промышленный, коммерческий или научный результат. На сегодняшний день разработаны целые промышленные библиотеки по машинному обучению, которые находятся в свободном доступе и имеют хорошую документационную поддержку.
Заметнее прочих средств разработки выделяется Python 3.9. Внимание исследователей Python получил благодаря ряду библиотек, ориентированных на проведение научных вычислений и построение моделей машинного обучения. К этим библиотекам можно отнести Pandas,
NumPy, Scikit-learn, Scipy, Keras. Отдельно стоит отметить библиотеку
TensorFlow, разработанную компанией Google и предоставленную для
свободного доступа. Эта библиотека позволяет строить глубокие
нейронные сети с произвольной архитектурой и обладает широким инструментарием для эффективного обучения таких сетей. Владение подобными инструментами является неотъемлемым атрибутом современного аналитика.
В рамках дисциплины «Интеллектуальная обработка данных»
рассматриваются элементарные способы предварительной обработки
и структурирования данных, наиболее популярные виды моделей машинного обучения с учителем и способы их настройки, выбор эффективных параметров моделей и их оценки. В результате прохождения
курса обучающийся будет способен осуществлять постановку задачи
машинного обучения, формировать обучающие и тестовые наборы
данных, выбирать и настраивать модели машинного обучения для конкретной практической задачи и осуществлять критический анализ полученных результатов. Весь курс разделен на три основных модуля.
Модуль 1. Знакомство с языком программирования Python 3.9. В
данном модуле рассматриваются возможности применения для анализа данных библиотек Pandas и NumPy. Эти библиотеки необходимы
для подготовки «сырых» данных к машинному обучению. Обучающиеся научаться структурировать данные, формировать необходимые
«срезы», обрабатывать выбросы и пропуски, осуществлять фильтрацию данных.
Модуль 2. Построение моделей машинного обучения. В данном
модуле рассматривается общая схема построения моделей, начиная с
4
5.
подготовки данных и заканчивая валидацией модели. Обсуждается выбор эффективных параметров моделей и метрики эффективности моделей.Модуль 3. Виды моделей машинного обучения. В модуле рассматриваются популярные виды моделей машинного обучения с учителем для решения задач классификации и регрессии. Обсуждаются основные параметры моделей и способы их обучения.
Целью данного практикума является методическая помощь при
выполнении практических работ в рамках курса «Интеллектуальная
обработка данных».
Для упрощения восприятия материала в практикуме соблюдена
единая последовательность изложения для всех тем:
1) Краткие теоретические сведения. Целью данного пункта
является не восполнение пробелов в знаниях обучающихся (эта задача
решается в рамках лекционных занятий и самостоятельной работы обучающихся), а помощь им в структурировании собственных знаний по
теме.
2) Подробная постановка практической задачи по изучаемой
теме.
3) Изложение методических рекомендаций по выполнению задания.
4) Контрольные вопросы для закрепления полученных знаний.
По результатам выполнения каждой практической работы необходимо оформить отчет. Отчет должен содержать титульный лист, постановку задачи, описание данных, описание хода выполнения задания
и критический анализ полученных результатов. Подробное описание
требований к отчету по практическим работам приведено в четвертом
разделе.
5
6.
1. ЗНАКОМСТВО С ЯЗЫКОМ ПРОГРАММИРОВАНИЯPYTHON 3.9
Python представляет собой высокоуровневый язык программирования, который в последние годы набирает все большую популярность
в таких направлениях как web-разработка, разработка СУБД, разработка мобильных приложений и т.д. Особую популярность Python приобрел в среде аналитиков Data Science и разработчиков систем искусственного интеллекта. В первую очередь это обусловлено появлением
ряда библиотек, позволяющих эффективно осуществлять большие объемы вычислений для научных исследований, анализа данных, а также
применять алгоритмы машинного обучения. Рассмотрим синтаксис
языка Python более подробно.
1.1. Синтаксис языка Python
В данном языке программирования синтаксис достаточно прост,
но при этом высокая выразительность языка позволяет реализовывать
сложные алгоритмы, не применяя многострочных кодов. В рамках данного параграфа рассмотрим только минимальный набор синтаксических правил. За более подробными сведениями рекомендуем обратиться к [12]. Так как предполагается, что читатель уже владеет базовыми знаниями языка программирования C++, для более лаконичного
описания будем ссылаться на синтаксис языка C++ или приводить
сравнение с ним.
Переменные
Именование переменных. Все требования к именованию переменных, применяемые в языке программирования C++, применимы и к
языку Python. Однако, Python допускает некоторые вольности. Например, имена переменных можно задавать и на русском языке.
Типы данных. В языке Python существует большое количество
стандартных типов данных, которые встроены в сам язык, но также
есть типы данных, которые были разработаны под решение определенных задач и поставляются вместе со специализированными пакетами
6
7.
библиотек. Рассмотрим некоторые типы данных, которые могут понадобиться в рамках данного курса.Таблица 1.1
Типы данных
Наименование
bool
NoneType
int
float
complex
str
list
tuple
dict
set
function
module
Описание
Логический тип
Специальный тип данных, который обозначает отсутствие
объекта
Целые числа
Вещественные числа
Комплексные числа
Строки
Списки. Специальный тип массива
Кортежи. Специальный тип массива
Словари. Специальный тип массива
Множества. Специальный тип массива
Функции
Модули
Как видно из табл. 1.1 некоторые типы данных аналогичны языку
C++ (int, float…). Однако различий больше, чем сходств. Например, существуют четыре специальных встроенных типа для создания массива.
Так list (список) позволяет создавать многомерные массивы, добавлять, удалять и изменять элементы массива. В отличие от list, с помощью tuple (кортеж) задаются неизменяемые массивы. Значения элементов кортежей нельзя менять. С помощью типа dict (словарь) задаются
массивы, где индексация производится в явном, символьном виде. Тип
set (множество) определяет массивы, в которых содержатся уникальные значения. Философия Python ориентирована на объекты. Поэтому
функции и модули здесь представляются в виде объектов, т.е. некоторых переменных, определенных специальными классами.
Важное отличие языка Python в том, что он относится к языкам с
автоматическим определением типа переменной. Например, если выполнить команду
>>>x=3
среда автоматически создаст переменную x и определит ее тип как int.
7
8.
Ввод команды>>>x=3
приведет к созданию переменной типа float. Аналогично и с другими
типами.
Проверить тип переменной можно с помощью встроенной функции type, написав, например, следующие строчки кода
>>>x=3.
>>>type(x)
Out:
float
Операторы
В языке Python все операторы можно разделить на следующие основные группы:
− математические;
− двоичные;
− операторы для работы с последовательностями;
− операторы присваивания;
− условные операторы.
Рассмотрим их подробнее.
Математические операторы аналогичны операторам C++
(табл. 1.2).
Таблица 1.2
Математические операторы
Обозначение оператора
+
*
/
//
%
**
Выполняемое действие
Сложение
Вычитание
Умножение
Деление
Деление целых чисел без остатка (целочисленное деление)
Остаток от деления
Возведение в степень
8
9.
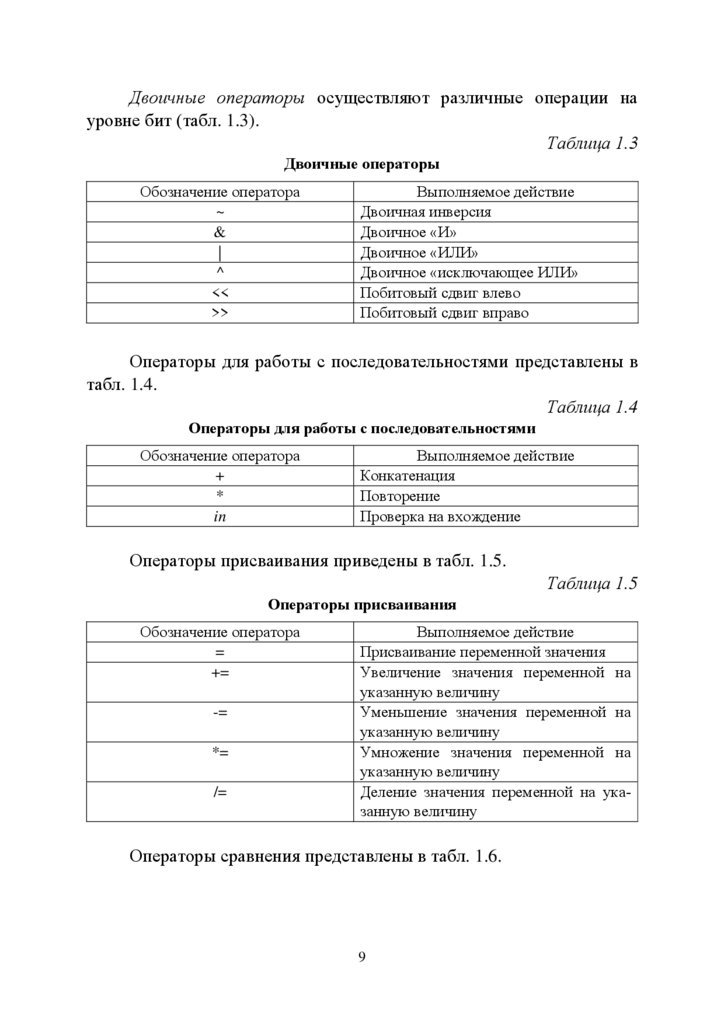
Двоичные операторы осуществляют различные операции науровне бит (табл. 1.3).
Таблица 1.3
Двоичные операторы
Обозначение оператора
~
&
|
^
<<
>>
Выполняемое действие
Двоичная инверсия
Двоичное «И»
Двоичное «ИЛИ»
Двоичное «исключающее ИЛИ»
Побитовый сдвиг влево
Побитовый сдвиг вправо
Операторы для работы с последовательностями представлены в
табл. 1.4.
Таблица 1.4
Операторы для работы с последовательностями
Обозначение оператора
+
*
in
Выполняемое действие
Конкатенация
Повторение
Проверка на вхождение
Операторы присваивания приведены в табл. 1.5.
Таблица 1.5
Операторы присваивания
Обозначение оператора
=
+=
-=
*=
/=
Выполняемое действие
Присваивание переменной значения
Увеличение значения переменной на
указанную величину
Уменьшение значения переменной на
указанную величину
Умножение значения переменной на
указанную величину
Деление значения переменной на указанную величину
Операторы сравнения представлены в табл. 1.6.
9
10.
Таблица 1.6Операторы сравнения
Обозначение оператора
==
!=
<
>
<=
>=
if … else
for
while
Выполняемое действие
Сравнение на равенство
Сравнение на неравенство
Оператор «Меньше»
Оператор «Больше»
Оператор «Меньше или равно»
Оператор «Больше или равно»
Оператор ветвления
Цикл по заданному количеству шагов
Цикл по условию
Пользовательские функции
Создание пользовательской функции осуществляется в соответствии со следующим синтаксисом
def
<Имя функции> ([<Параметры>]):
<Тело функции>
return <значение>
В данной конструкции def – ключевое слово, которое подсказывает интерпретатору, что дальше идет объявление функции. Имя функции должно быть уникальным идентификатором, состоящим из латинских букв, цифр и, при необходимости, знаков подчеркивания. В целом, требования к имени функции соответствуют требованиям в языке
C++. Тело функции обозначается отступами. В Python принято в качестве одного отступа ставить четыре пробела.
Модули
Модулем называется файл с программным кодом. Каждый модуль может импортировать другой модуль и получать доступ к функциям и объектам этого модуля. Для импорта модуля используется инструкция import.
>>>import <имя модуля>
10
11.
Для загрузки конкретной функции или объекта используется инструкция from.>>> from <имя модуля> import <имя объекта или
функции>
Для более подробного изучения основ синтаксиса языка рекомендуем изучить [12, 23]. В целом, синтаксис Python является достаточно
выразительным и позволяет представлять сложные алгоритмы при минимальном количестве строк.
П рак тическая рабо та №1
Задание
Первым заданием в данном курсе будет необходимость установить Python и познакомиться с рабочим пространством программной
среды.
Ход выполнения
1) Python содержит большое количество реализаций с разным составом библиотек. Можно выбрать одну из таких реализаций, либо поставить «чистый» Python и установить необходимые библиотеки. Второй путь подходит для более опытных пользователей. Если Вы не являетесь опытным пользователем Python, рекомендуется выбрать готовую реализацию Anaconda.
Для установки Anaconda необходимо перейти на сайт производителя (https://www.anaconda.com/products/individual) в раздел дистрибутивов и скачать нужный дистрибутив в соответствии с установленной
на Вашем устройстве операционной системой.
В результате установки у Вас должно появиться четыре новых
программы:
− Spyder;
− Jupiter Notebook;
− Anaconda Navigator;
− Anaconda Promt.
Первые две представляют собой редакторы, в которых удобно писать программный код. Spyder сделан по подобию оболочки MatLab. В
нем удобно отлаживать программу и отслеживать значения переменных. Jupiter Notebook является web-редактором и подходит для более
опытных пользователей. Anaconda Navigator является системой
11
12.
управления, с помощью которой удобно управлять, устанавливать иудалять библиотеки. Последняя программа представляет собой консоль. Консоль удобна при управлении Python.
Для изучения курса рекомендуется использовать Spyder.
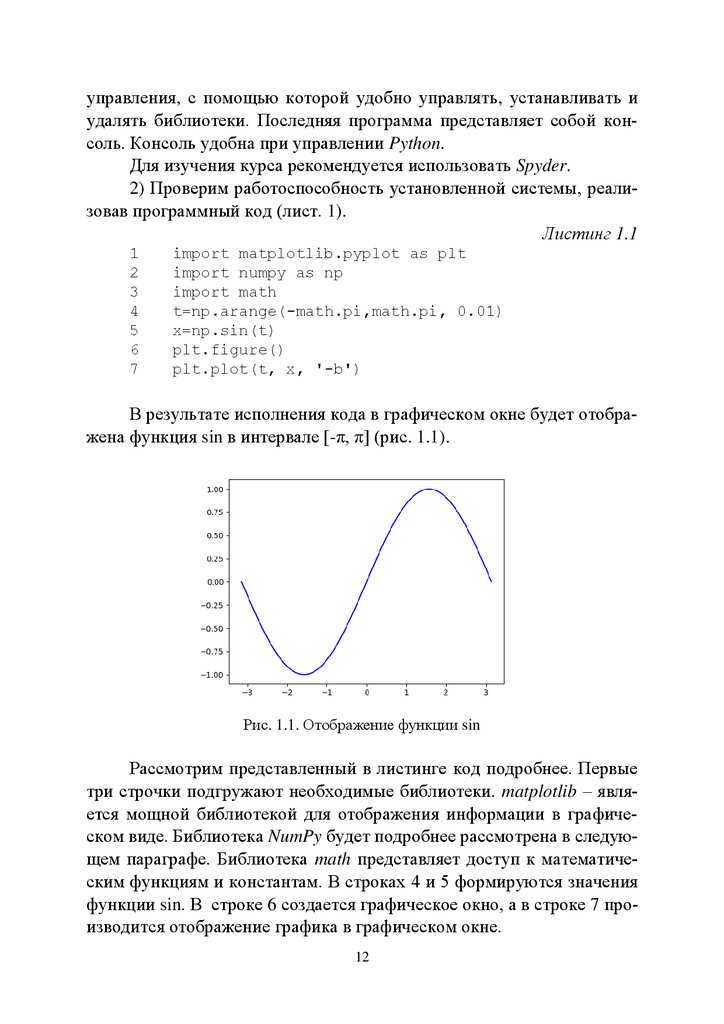
2) Проверим работоспособность установленной системы, реализовав программный код (лист. 1).
Листинг 1.1
1
2
3
4
5
6
7
import matplotlib.pyplot as plt
import numpy as np
import math
t=np.arange(-math.pi,math.pi, 0.01)
x=np.sin(t)
plt.figure()
plt.plot(t, x, '-b')
В результате исполнения кода в графическом окне будет отображена функция sin в интервале [-π, π] (рис. 1.1).
Рис. 1.1. Отображение функции sin
Рассмотрим представленный в листинге код подробнее. Первые
три строчки подгружают необходимые библиотеки. matplotlib – является мощной библиотекой для отображения информации в графическом виде. Библиотека NumPy будет подробнее рассмотрена в следующем параграфе. Библиотека math представляет доступ к математическим функциям и константам. В строках 4 и 5 формируются значения
функции sin. В строке 6 создается графическое окно, а в строке 7 производится отображение графика в графическом окне.
12
13.
Контрольные вопросы1) Что такое динамическая типизация?
2) Перечислите основные типы операторов в языке Python?
3) Перечислите основные типы переменных в языке Python?
4) Назовите основные отличия Python от С++.
5) Что такое модуль в языке Python и чем модуль отличается от
пользовательской функции?
6) В чем принципиальное отличие операторов присваивания от
операторов сравнения?
7) В чем принципиальное отличие оператора от функции?
8) Какие основные программы требуются при работе со сборкой
Anaconda?
9) Какими двумя способами можно устанавливать новые библиотеки в Anaconda?
10) Перечислите основные стандартные типы данных в Python
для хранения массивов.
1.2. Библиотеки NumPy и Pandas
Наличие библиотек Pandas и NumPy являются одним из главных
факторов, определивших популярность Python в научной среде. Данные библиотеки позволяют эффективно реализовывать сложные вычислительные процедуры с большими наборами данных благодаря высокоскоростным операциям, интегрированным в состав библиотек. Исторически библиотека NumPy была реализована раньше, а библиотека
Pandas является очень удачной надстройкой для NumPy.
Рассмотрим библиотеки в порядке их появления.
Библиотека NumPy
Библиотека NumPy (Numeric Python) была разработана для эффективного хранения и преобразования плотных массивов данных. За
динамическую типизацию Python приходится платить памятью и скоростью обработки. Для решения этой проблемы была разработана библиотека NumPy. Рассмотрим некоторые возможности данной библиотеки.
13
14.
Создание массивов NumPy. Для создания массивов в библиотекесуществует ряд функций (табл. 1.7). Фактически все подходы сводятся
к двум основным: создание на базе готового массива и генерация нового по какому-либо принципу.
Таблица 1.7
Функции для создания массивов
Синтаксис записи функции
Выполняемое действие
zeros(<размерность>)
Создание массива, заполненного нулями
ones(<размерность>)
Создание массива, заполненного единицами
full(<размерность>, <значение>) Создание массива, заполненного заданным
значением
arrange(min, max, step)
Создание массива, заполненного равномерно
в диапазоне [min, max) с шагом step
linspase(min, max, n)
Создание массива, заполненного равномерно
в диапазоне [min, max] с количеством значений n
array(<массив>)
Создание массива NumPy на основе имеющегося
Массив NumPy обладает следующими атрибутами:
− ndim – размерность массива (количество осей);
− shape – размерность каждого измерения;
− size – общий размер массива.
Индексация в массивах NumPy является неявной, т.е. нет таблицы
индексов, в которой бы каждому элементу соответствовал бы некий
индекс или метка. Обращение к элементам массива осуществляется по
неявному индексу, который отсчитывается от начала массива. Индексация в массиве начинается с нуля.
В лист. 1.2 приводится пример создания массива из 5 чисел, заполняемого значениями от 0 до 10 с равным шагом. Полученный массив выводится на экран.
Листинг 1.2
import NumPy as np
y=np.linspace(0, 10, 5)
for i in range(5):
print(y[i])
14
15.
Срезы. Одной из основных операций над массивами являетсясрез. В NumPy реализован очень удобный механизм осуществления
срезов. Операция среза обозначается «:». Например:
X[:5] – выбор первых пяти элементов с индексами 0…4;
X[5:] – выбор элементов, начиная с шестого и до конца массива
(элементы с индексами 5, 6…);
X[4:6] – выбор элементов с индексами 4, 5. Элемент с индексом 6
не включается в срез. Это особенность Python.
Для многомерных массивов срез выполняется аналогично.
Маски и булева логика – это альтернативный подход к формированию подмассивов. Кроме числовых индексов выборку из массива
можно сделать с помощью логической маски. Рассмотрим пример логической индексации массива (лист. 1.3).
Листинг 1.3
Логическая индексация массива
import NumPy as np
y=np.arange(0, 10, 1)
i=y<5
print(i)
print(y[i])
Out:
[ True True True True True False False False False False]
[0 1 2 3 4]
В примере создается массив чисел 1, 2…9. Операция i=y<5 формирует логическую маску, где True соответствует элементам, удовлетворяющим условию y<5. При индексации по логической маске возвращаются только те значения, которым в маске соответствует значение True. Применяя булеву логику, можно формировать подмассивы с
очень сложными логическими условиями.
Слияние и разбиение массивов. Операция среза касается только
представления массива. С самим массивом никаких преобразований не
происходит. Для изменений массива существуют операции слияния и
разбиения массива, а также изменения формы (табл. 1.8).
15
16.
Таблица 1.8Функции слияния и разбиения массивов
Синтаксис записи функции
concatenate(<список массивов>)
vstack(<список массивов>)
hstack(<список массивов>)
split(<список массивов>)
vsplit(<список массивов>)
hsplit(<список массивов>)
reshape(<массив>, <размерность>)
newaxis
Выполняемое действие
Слияние массива по заданной оси
Вертикальное слияние массивов
Горизонтальное слияние массивов
Разбиение массива по заданной оси
Вертикальное разбиение массивов
Горизонтальное разбиение массивов
Изменение формы массива
Добавление новой оси в массив (увеличение размерности)
При слиянии и разбиении массивов необходимо следить за размерностью массивов и их формой. Если форма одного массива не соответствует форме другого массива, это можно исправить с помощью
функций reshape и newaxis.
Самое главное достоинство библиотеки NumPy – это высокоскоростные операции над элементами массивов. Библиотека позволяет
выполнять векторные операции, что существенно быстрее, чем представление тех же операций через циклы.
Рассмотрим пример, иллюстрирующий сравнение циклов и векторных операций (лист. 1.4).
Листинг 1.4
Сравнение циклов и векторных операций
import NumPy as np
from datetime import datetime
import time
start_cikl = datetime.now()
y=np.arange(0, 1e6, 1)
for i in range(len(y)):
y[i]+=1
end_cikl = datetime.now()
y+=1
start_vector = datetime.now()
print("время выполнения цикла: {0}".format( end_ciklstart_cikl) )
print("время
выполнения
цикла:
{0}".format(
start_vector-end_cikl) )
16
17.
Out:время выполнения цикла: 0:00:02.479750
время выполнения цикла: 0:00:00.002001
В примере создается массив из миллиона элементов. Каждый элемент массива увеличивается на 1. Сначала эта операция реализована
через цикл for, а затем через векторную сумму. Для каждого способа
измерено время выполнения. Результат выведен в консоль. Как видно
из примера, векторная операция выполняется на порядок быстрее.
Арифметические операторы NumPy. Рассмотрим основные
арифметические операторы, реализованные в NumPy (табл. 1.9).
Таблица 1.9
Векторные арифметические операции NumPy
Функция
add
subtract
negative
multiply
divide
floor_divide
power
mod
Перегрузка оператора по умолчанию
+
*
/
//
**
%
Выполняемое действие
Сложение
Вычитание
Унарная операция отрицания
Умножение
Деление
Деление с округлением в меньшую сторону
Возведение в степень
Остаток от деления
Функции агрегирования. Кроме арифметических операций исследователю часто требуется вычисление агрегирующих функций. В
табл. 1.10 приведен неполный список агрегирующих функций.
Таблица 1.10
Функции агрегирования
Функция
sum
prod
mean
std
min
max
argmin
argmax
median
percentile
Выполняемое действие
Вычисление суммы элементов
Вычисление произведения элементов
Вычисление среднего значения элементов
Вычисление среднеквадратического уклонения
Вычисление минимального значения среди элементов
Вычисление максимального значения среди элементов
Вычисление индекса минимального элемента
Вычисление индекса максимального элемента
Вычисление медианы
Вычисление квантилей
17
18.
Библиотека PandasБиблиотека Pandas выступает как удачная надстройка для библиотеки NumPy. Практически все, что работает для NumPy будет работать и для Pandas. Однако Pandas дает много дополнительных, очень
полезных на практике, возможностей. Основным объектом NumPy являются массивы NumPy. В Pandas существует два основных объекта
для представления данных: Series и DataFrame.
Series представляет собой одномерный массив с явной индексацией. Индекс может быть как числовым, так и символьным (лист. 1.5).
Листинг 1.5
Пример объекта Series
import Pandas as pd
m={"Иванов":5, "Петров":4, "Сидоров":3}
m=pd.Series(m)
print(m)
Out:
Иванов 5
Петров 4
Сидоров 3
dtype: int64
В данном примере создается словарь с индексами: «Иванов»,
«Петров», «Сидоров». Каждому индексу соответствует оценка по некоторому предмету. Словарь преобразовывается в объект типа Series и
объект выводится на экран.
В отличии от Series, DataFrame представляет собой многомерный
(чаще всего двумерный) массив с явной индексацией по строкам и
столбцам. Можно сказать, что DataFrame состоит из нескольких Series
(лист. 1.6).
Листинг 1.6
Пример объекта DataFrame
import Pandas as pd
mat=pd.Series({"Иванов":5, "Петров":4, "Сидоров":3})
rus=pd.Series({"Иванов":4, "Петров":3, "Сидоров":5})
lit=pd.Series({"Иванов":3, "Петров":5, "Сидоров":4})
18
19.
result=pd.DataFrame({"Математика":mat,язык":rus, "Литература":lit})
print(result)
"Русский
Out:
Иванов
Петров
Сидоров
Математика
5
4
3
Русский язык
4
3
5
Литература
3
5
4
Индексация может быть как числовой, так и символьной. Рассмотрим механизмы создания объектов. Для создания объектов используется соответствующий конструктор (табл. 1.11).
Таблица 1.11
Конструктор объектов Pandas
Функция
Series(<Массив>)
DataFrame(<Массив>)
Комментарий
Создать объект Series можно на основе любого другого массива (list, tuple, dict, NumPy)
Создать объект DataFrame можно на основе любого
другого массива (list, tuple, dict, NumPy)
Объекты DataFrame и Series поддерживают развитый механизм
срезов и выбора подмассивов. Удобными механизмами индексации являются индексаторы: loc, iloc, ix (табл. 1.12).
Таблица 1.12
Индексаторы объектов Pandas
Функция
loc
iloc
ix
Назначение
Индексация по явным индексам
Индексация по неявным индексам
Комбинированная индексация
Рассмотрим пример индексации (лист. 1.7). В данном примере используются срезы с применением разного типа индексации.
В первом случае используется явная индексация. Для задания
срезов взяты значения индексов: «Иванов», «Петров» и значения
столбцов: «Математика» и «Русский».
Во втором случае приведен пример использования уже неявной
индексации. Элементы отсчитываются от нулевой строки и нулевого
19
20.
столбца и выводятся в том порядке, в котором они сохранены в объекте.Третий и четвертый варианты демонстрируют использование
смешанного вида индексации. В третьей строке вывода по строкам задана явная индексация, а по столбцам неявная. В четвертой же наоборот, тут уже по строкам идет неявная индексация, а по столбцам явная.
Листинг 1.7
Пример индексации объектов Pandas
print(result.loc["Иванов":"Петров",
"Математика":"Русский
язык"])
print(result.iloc[0:2, 0:2])
print(result.ix["Иванов":"Петров", 0:2])
print(result.ix[0:2, "Математика":"Русский язык"])
Out:
Математика
Иванов
5
Петров
4
Русский язык
4
3
Математика
Иванов
5
Петров
4
Русский язык
4
3
Математика
Иванов
5
Петров
4
Русский язык
4
3
Математика
Иванов
5
Петров
4
Русский язык
4
3
Кроме того, объекты Pandas поддерживают логическую индексацию, агрегирование и много других полезных механизмов, аналогичных механизмам NumPy.
20
21.
П рак тическая рабо та № 2Задание
Определить статистические показатели для выборки.
Для выполнения задания Вам необходимо загрузить файл с данными и вычислить на основе этих данных требуемые показатели.
Для примера возьмем данные с общедоступного ресурса
https://gist.github.com/michhar/2dfd2de0d4f8727f873422c5d959fff5.
Ход выполнения
1) Загрузите данные, скачав файл titanic.csv.
2) Определите количество женщин и мужчин.
3) Посчитайте количество пассажиров первого класса.
4) Определите вероятность выжить для пассажира Титаника.
5) Посчитайте вероятность выжить для пассажиров первого
класса.
6) Определите вероятность выжить для пассажира-мужчины и
вероятность выжить пассажиру-женщине.
7) Найдите самое популярное женское имя на Титанике.
Результат оформите в виде аналитического отчета с приведением
применяемого программного кода.
Контрольные вопросы
1) Перечислите и поясните основные атрибуты массива.
2) Перечислите основные способы создания массива NumPy «с
нуля».
3) Перечислите и поясните основные методы преобразования
формы массива.
4) Перечислите и поясните основные способы индексации массива DataFrame.
5) Перечислите и поясните основные функции агрегирования.
6) Перечислите основные объекты библиотеки Pandas.
7) Перечислите основные способы индексации массивов NumPy.
8) В чем принципиальное отличие объектов DataFrame и Series?
9) Перечислите основные функция разбиения массивов и расскажите об их особенностях.
10) Перечислите основные функции слияния массивов и расскажите об их особенностях.
21
22.
1.3. Предварительная обработка данныхНа практике редко попадаются наборы данных, где данные в исходном виде можно подавать на модель. Чаще эти данные, их еще
называют «сырые данные», требуют проведения специальных операций, которые в целом называют предварительной обработкой данных.
К типичным операциям предварительной обработки данных
обычно относят:
1) Форматирование данных.
2) Устранение пропусков.
3) Устранение выбросов.
4) Сглаживание.
5) Масштабирование.
Рассмотрим каждый из этих этапов подробнее.
Форматирование данных – это процесс преобразования данных в
форму, которая подходит для решения поставленной задачи. Форма
данных зависит от постановки задачи. Незначительное изменение цели
или понимания задачи может существенно влиять на требуемую
форму. Основной формой данных в машинном обучении является двумерная таблица. Строки этой таблицы представляют собой некоторые
объекты, а столбцы – некоторые признаки (параметры) объекта, которые можно измерить (табл. 1.13).
Таблица 1.13
Основная форма представления данных в машинном обучении
Признак 1
Признак 2
…
Признак n
Объект 1
Объект 2
…
Объект n
При определе нии формы дан ных необходимо решить некоторые задачи. Первая задача состоит в определении того, что в конкретном случае является объектом измерения и анализа. Иногда объект
явным образом определяется сутью задачи. Например, при разработке
системы медицинской диагностики объектом измерения является пациент, при разработке системы распознавания лиц объектом измерения
является человек, а в задаче распознавании рукописных цифр объектом
измерения будет цифра.
22
23.
При этом бывают задачи, в которых сложно определить объектизмерения. Например, когда исследователи только начинали решать
задачу распознавания речи, было не ясно, что брать за объект измерения: все предложение целиком или отдельные слова, или отдельные
буквы и т.д. Эффективным оказался подход, когда объектом измерения
и распознавания стала фонема. Сама по себе фонема не имеет лексического смысла, но комбинация фонем легко преобразуется в лексически
осмысленные сочетания. Другим примером является задача распознавания интереса со стороны покупателя к товару на полке. Интерес покупателя – это очень неконкретное понятие, которое можно измерить
только косвенно. Например, через количество вопросов консультантам
или через количество покупателей, подошедших к полке с товаром,
или через количество совершенных покупок, или суммарное время рассмотрения товара и т.д. Ни один из этих объектов не является тождественным исходному и поэтому выбрать один из них или их комбинацию достаточно сложно.
После определения объекта измерения необходимо опре дели ть пер вичный на бор пара ме тро в , которые требуется измерять и исследовать. При последующем анализе будет исследовано влияние этих атрибутов на результирующую переменную и, возможно,
часть из них будет отброшена или преобразована. Но для того, чтобы
выполнить анализ, нужно определить первичный набор потенциально
полезных параметров.
Следующая задача требует опре деле ния формы пре дста вле ния измере ний . Например, при анализе динамики продаж нет возможности анализировать каждый чек. Количество чеков может измеряться несколькими миллионами. При этом требуется агрегирование
по временным интервалам. Например, агрегирование по дням, неделям, месяцам. Это определяется целью решаемой задачи.
Устранение пропусков. Данные без пропусков, как правило, бывают только в учебных или тестовых задачах. На практике получить
такие данные практически невозможно. Обработка пропусков – это
естественный процесс при подготовке данных. При этом необходимо
учитывать природу пропусков. В некоторых случаях пропуск означает
ошибку оператора. Например, измеряется температура объекта и пропущенное значение означает отсутствие данных на какой-то момент
времени. В других же случаях, отсутствие значения может также
23
24.
представлять собой сведения об объекте. Например, в анамнезе пациента отсутствие сведений о повторной операции означает отсутствиеповторной операции. В первом случае требуется применять специализированные приемы обработки пропусков. Во втором случае необходимо учитывать наличие и отсутствие повторной операции отдельным
параметром. Рассмотрим подробнее подходы к обработке пропущенных значений.
Выделяют несколько вариантов обработки пропущенных значений:
1) Удаление строк, содержащих пропуски. Если объектов с пропусками не очень много и выборка достаточно объемная, то можно
просто удалить такие объекты.
2) Если признак объекта количественный, то заполнить пропуски можно средним значением по столбцу. Если признак категориальный, то заполнить наиболее часто встречающимся значением по
столбцу.
3) Если первые два подхода не дают удовлетворительных результатов, то можно попытаться восстановить столбец с пропусками
через модели машинного обучения, как зависимость от других столбцов.
В библиотеки Pandas есть специализированные методы, позволяющие обрабатывать пропуски (табл. 1.14).
Таблица 1.14
Функции для работы с пропусками
Функция
isnull(<DataFrame>)
fillna(значение)
dropna()
Описание
Возвращает таблицу размерностью, совпадающей с таблицей DataFrame. Таблица состоит из значений
True/False. True соответствует ячейкам с пропусками,
False – с заполненными значениями. Возвращаемую таблицу можно использовать как таблицу логических индексов
Заменяет все пропуски указанным значением
Удаляет из таблицы объекты с пропусками
Устранение выбросов. Под выбросами обычно понимают нетипичные значения, которые очень сильно отличаются от среднего, выходят за рамки технологического регламента, выглядят неестественными для измеряемого объекта. Причина выбросов, как правило,
24
25.
связана с ошибочным измерением или его регистрацией. Количествовыбросов в выборке редко превышает 5%. Выявить аномальные значения признаков можно с помощью визуального анализа данных. Например, гистограммы, или корреляционные графики позволяют визуально
определить подозрительные измерения, которые стоит обсудить с экспертами предметной области. Однако, если количество признаков достаточно большое (десятки, сотни или тысячи), то провести визуальный анализ каждого из них достаточно сложно. Поэтому применяют
другие подходы. Например, кластеризация позволяет выявить нетипичные, аномальные значения.
В Pandas существуют свои встроенные средства визуализации
данных (табл. 1.15).
Таблица 1.15
Функции для визуализации данных
Функция
hist()
plot()
Описание
Создает графическое окно и выводит гистограмму
Осуществляет построение графика
Для более сложных задач визуализации удобно использовать
библиотеку matplotlib.
Сглаживание. С какой бы точность не производились измерения
эта точность всегда имеет некоторый предел. При этом, сами значения
измерений имеют некоторую флуктуацию. Причин этому много: влияние случайных факторов, действие магнитных, электрических, тепловых и других полей, техническое несовершенство прибора измерения
и т.д. Такую флуктуацию называют шумом. Шум является «вредной»
составляющей сигнала, т.к. он не связан с объектом измерения, а связан
со способом или моментом измерения. Поэтому от шума в данных стараются избавиться либо снизить шумовой эффект. Этого можно добиться с помощью специализированных процедур фильтрации.
Способов фильтрации достаточно много. Одним из простейших
способов является применение экспоненциальной скользящей средней