





















































































 programming
programmingSimilar presentations:










Объектно-ориентированное программирование. Лекция 7
1.
к.т.н., доц.Томашевская В.С.
Лекция 7
Библиотека Pandas
ОБЪЕКТНО-ОРИЕНТИРОВАННОЕ ПРОГРАММИРОВАНИЕ
2.
Библиотека Pandas. Основныепонятия.
Pandas — это библиотека Python для обработки и анализа
структурированных данных, её название происходит от «panel data»
(«панельные данные»).
Панельными данными называют информацию, полученную в результате
исследований и структурированную в виде таблиц.
Для работы с такими массивами данных и создан Pandas.
Рandas упрощает анализ информации, тестирование приложений и другие
действия, предоставляя разработчику готовые алгоритмы.
Инструмент базируется на языке Python и применяется для предварительного
преобразования, обработки и очистки структурированных данных,
представленных в форматах, не подходящих для машинного обучения,
например, в виде таблиц Excel.
2
3.
3Библиотека Pandas. История.
Разработка Pandas началась в 2008 году в компании AQR Capital,
которая занимается инвестициями и финансами.
К концу 2009 он стал проектом с открытым исходным кодом (open
source), который и по сей день поддерживается сообществом
единомышленников со всего мира, которые безвозмездно вкладывают
свои силы и время в развитие этой библиотеки.
С 2015 года эта библиотека спонсируется компанией NumFOCUS,
которая поддерживает open source проекты.
4.
Библиотека Pandas. Основныепонятия.
Основные направления использования Pandas в Python:
Объединение нескольких таблиц в одну сводную.
Очищение данных от дубликатов и невалидных строк или столбцов.
Вывод определенных значений по фильтрам или уникальности.
Использование агрегирующих функций, включая подсчет значений,
суммы элементов, определение среднего значения.
Визуализация собранных данных.
4
5.
Библиотека Pandas. Основныепонятия.
Библиотека Pandas – мощный инструмент для анализа и обработки
табличных данных. Pandas используется в инженерных, научных и
финансовых вычислениях – словом, везде, где нужны:
Анализ, исследование, сегментация, очистка, преобразование
данных. Библиотека предоставляет множество функций для загрузки и
обработки данных из различных источников. С помощью Pandas
можно анализировать любую информацию, исследовать ее
характеристики и особенности, а также преобразовывать данные в
нужный формат для дальнейшего использования – в бизнесаналитике, машинном обучении и т.п.
5
6.
Библиотека Pandas. Основныепонятия.
Сортировка, группировка и агрегация данных. В Pandas есть удобные
функции для сортировки данных по различным критериям,
группировки по определенным признакам и выполнения агрегации
(суммирование, подсчет среднего значения, максимума и
минимума и т. д.)
Индексация, фильтрация и выборка многомерных данных. Pandas
позволяет использовать различные типы индексов и создавать
многомерные индексы с помощью MultiIndex. Это помогает легко
находить, фильтровать и выбирать нужные данные по различным
критериям.
6
7.
Библиотека Pandas. Основныепонятия.
Определение эффективности и рисков, прогнозирование событий,
оптимизация. Библиотеку можно использовать для прогнозирования
спроса на основе исторических данных, анализа трендов и
паттернов, а также для определения факторов, влияющих на
эффективность бизнеса, результативность кампаний и прибыльность
инвестиций.
Формирование отчетов и визуализация данных. Pandas используют
(совместно с Matplotlib и Seaborn) для создания отчетов и
визуализации многомерных данных в виде наглядных таблиц,
графиков и диаграмм.
7
8.
Библиотека Pandas. Основныепонятия.
Работа с временными рядами. Pandas обладает мощными
возможностями для работы с временными рядами – позволяет
выполнять индексацию по времени, агрегацию и ресемплирование
временных данных, проводит анализ и визуализацию временных
рядов. Это делает Pandas идеальным инструментом для работы с IoT,
финансовыми и климатическими данными и другими областями, где
временные ряды играют важную роль.
8
9.
Библиотека Pandas. Ключевыевозможности
Набор функций библиотеки Рandas весьма обширен. Разработчики
ценят этот продукт за следующие компоненты, упрощающие анализ
данных и другие действия с ними:
объекты data frame, позволяющие управлять индексированными
массивами двумерной информации;
встроенные инструменты совмещения данных, а также обработки
сопутствующих сведений;
функция обмена электронными материалами между структурами
памяти, а также различными файлами и документами;
срезы по значениям индексов;
9
10.
Библиотека Pandas. Ключевыевозможности
расширенные возможности при индексировании;
наличие выборки из больших объемов наборов информации;
вставка и удаление столбцов в массиве;
встроенные средства совмещения информации;
обработка отсутствующих сведений;
10
11.
Библиотека Pandas. Ключевыевозможности
слияние имеющихся информационных наборов;
иерархическое индексирование, помогающее обрабатывать
материалы высокой размерности в структурах с меньшей
размерностью;
группировка, делающая доступными одновременные трехэтапные
операции типа «разделение, изменение и объединение».
11
12.
12Библиотека Pandas.
Преимущества Pandas:
слияние имеющихся информационных наборов;
Высокая скорость благодаря оптимизации кода.
Интуитивно понятный интерфейс.
Расширенные возможности за счет интеграции с другим
библиотеками на Python, в частности, с NumPy, Matplotlib и Scikit-learn.
Сильное мировое комьюнити, силами которого продукт постоянно
совершенствуется.
13.
Библиотека Pandas. Данные в Pandas:Series и DataFrame.
Чтобы эффективно работать с pandas, необходимо освоить самые
главные структуры данных библиотеки: DataFrame и Series.
Без понимания что они из себя представляют, невозможно в дальнейшем
проводить качественный анализ.
13
14.
14Библиотека Pandas.
Series – это одномерная маркированная структура данных, состоящая из индексов и
соответствующих значений. В качестве меток могут выступать числа, даты, временные
интервалы и строки. Метки позволяют получать доступ к элементам данных по определенным
уникальным именам, а не только по индексам. Это особенно удобно в тех случаях, когда
нужно обращаться к конкретным значениям по определенным меткам или условиям.
Создать структуру Series можно на базе различных типов данных:
словари Python;
списки Python;
массивы из numpy: ndarray;
скалярные величины.
15.
15Библиотека Pandas.
Конструктор класса Series выглядит следующим образом:
pandas.Series(data=None, index=None, dtype=None, name=None, copy=False,
fastpath=False)
data – массив, словарь или скалярное значение, на базе которого будет построен
Series;
index – список меток, который будет использоваться для доступа к элементам Series.
Длина списка должна быть равна длине data;
dtype – объект numpy.dtype, определяющий тип данных;
copy – создает копию массива данных, если параметр равен True в ином случае
ничего не делает.
В большинстве случаев, при создании Series, используют только первые два
параметра.
16.
Библиотека Pandas. Данные вPandas: Series.
Самый простой способ создать Series – это
передать в качестве единственного
параметра в конструктор класса список
Python.
В данном примере была создана структура
Series на базе списка из языка Python. Для
доступа к элементам Series, в данном
случае, можно использовать только
положительные целые числа – левый столбец
чисел, начинающийся с нуля – это как раз и
есть индексы элементов структуры, которые
представлены в правом столбце.
import pandas as pd
my_series = pd.Series([5, 6, 7, 8, 9, 10])
my_series
0
5
1
6
2
7
3
8
4
9
5
10
dtype: int64
16
17.
Библиотека Pandas. Данные вPandas: Series.
В строковом представлении объекта Series,
индекс находится слева, а сам элемент
справа. Если индекс явно не задан, то
pandas автоматически создаёт RangeIndex
от 0 до N-1, где N общее количество
элементов.
import pandas as pd
Также стоит обратить внимание, что у Series
есть тип хранимых элементов, в нашем
случае это int64, т.к. мы передали
целочисленные значения.
my_series = pd.Series([5, 6, 7, 8, 9, 10])
my_series
0
5
1
6
2
7
3
8
4
9
5
10
dtype: int64
17
18.
Библиотека Pandas. Данные вPandas: Series.
Можно попробовать использоваться больше
возможностей из тех, что предлагает pandas, для
этого передадим в качестве второго элемента
список строк (в нашем случае – это отдельные
символы). Такой шаг позволит нам обращаться к
элементам структуры Series не только по
численному индексу, но и по метке, что сделает
работу с таким объектом, похожей на работу со
словарем.
import pandas as pd
Обратите внимание на левый столбец, в нем
содержатся метки, которые мы передали в
качестве index параметра при создании
структуры. Правый столбец – это по-прежнему
элементы нашей структуры.
18
s2 = pd.Series([1, 2, 3, 4, 5], ['a', 'b', 'c', 'd', 'e'])
print(s2)
a
1
b
2
c
3
d
4
e
5
dtype: int64
19.
Библиотека Pandas. Данные вPandas: Series.
У объекта Series есть атрибуты через которые
можно получить список элементов и
индексы, (values и index).
my_series.index
RangeIndex(start=0, stop=6, step=1)
my_series.values
array([ 5, 6, 7, 8, 9, 10], dtype=int64)
19
20.
Библиотека Pandas. Данные вPandas: Series.
Доступ к элементам объекта Series
возможны по их индексу (По аналогии со
словарем, где доступ можно осуществить
по ключу).
20
my_series[4]
9
my_series2 = pd.Series([5, 6, 7, 8, 9, 10],
index=['a', 'b', 'c', 'd', 'e', 'f'])
Индексы можно задавать явно:
my_series2['f']
10
21.
Библиотека Pandas. Данные вPandas: Series.
Делать выборку по нескольким индексам:
my_series2[['a', 'b', 'f']]
a
5
b
6
f
10
dtype: int64
21
22.
Библиотека Pandas. Данные вPandas: Series.
Осуществлять групповое присваивание:
my_series2[['a', 'b', 'f']] = 0
my_series2
a
0
b
0
c
7
d
8
e
9
f
0
dtype: int64
22
23.
Библиотека Pandas. Данные вPandas: Series.
Фильтровать и применять математические
операции:
my_series2[my_series2 > 0]
c
7
d
8
e
9
dtype: int64
my_series2[my_series2 > 0] * 2
c
14
d
16
e
18
dtype: int64
23
24.
Библиотека Pandas. Данные вPandas: DataFrame.
Если Series представляет собой одномерную структуру, которую для
себя можно представить как таблицу с одной строкой, то DataFrame –
это уже двумерная структура – полноценная таблица с множеством
строк и столбцов.
DataFrame располагает удобными методами для индексации,
фильтрации, сортировки, группировки, агрегирования, слияния,
объединения и преобразования данных.
DataFrame можно сравнить с таблицей в реляционной базе данных или
листом в Excel
24
25.
Библиотека Pandas. Данные вPandas: DataFrame.
import pandas as pd
# создаем DataFrame из словаря
data = {'Имя': ['Егор', 'Анна', 'Никита', 'Марина'],
'Возраст': [25, 30, 28, 35],
'Город': ['Москва', 'Самара', 'Ростов', 'Нижний Новгород']}
df = pd.DataFrame(data)
# выводим DataFrame на экран
print(df)
25
26.
Библиотека Pandas. Данные вPandas: DataFrame.
Результат:
Имя
Возраст
Город
0
Егор
25
Москва
1
Анна
30
Самара
2
Никита
28
Ростов
3
Марина
35
Нижний Новгород
26
27.
Библиотека Pandas. Данные вPandas: DataFrame.
Обычно табличные данные хранятся в файлах. Такие наборы данных
принято называть дата-сетами. Файлы с дата-сетом могут иметь
различный формат. Pandas поддерживает операции чтения и записи
для CSV, Excel 2007+, SQL, HTML, JSON, буфер обмена и др. Несколько
примеров, как получить дата-сет из файлов разных форматов:
CSV. Используется функция read_csv(). Аргумент file является строкой,
в которой записан путь до файла с дата-сетом. Для записи данных из
DataFrame в CSV-файл используется метод to_csv(file).
Excel. Используется функция read_excel(). Для записи данных из
DataFrame в Excel-файл используется метод to_excel().
JSON. Используется функция read_json(). Для записи данных из
DataFrame в JSON используется метод to_json().
27
28.
Библиотека Pandas. Данные вPandas: DataFrame.
Одним из самых популярных форматов хранения табличных данных
является CSV (Comma Separated Values, значения с разделителемзапятой). В файлах этого формата данные хранятся в текстовом виде.
Строки таблицы записываются в файле с новой строки, а столбцы
разделяются определённым символом, чаще всего запятой ',' или
точкой с запятой ';'. Первая строка, как правило, содержит заголовки
столбцов таблицы.
28
29.
Библиотека Pandas. Данные вPandas: DataFrame.
Конструктор класса DataFrame выглядит так:
class pandas.DataFrame(data=None, index=None, columns=None,
dtype=None, copy=False)
data – массив ndarray, словарь (dict) или другой DataFrame;
index – список меток для записей (имена строк таблицы);
columns – список меток для полей (имена столбцов таблицы);
dtype – объект numpy.dtype, определяющий тип данных;
copy – создает копию массива данных, если параметр равен True в
ином случае ничего не делает.
29
30.
Библиотека Pandas. Данные вPandas: DataFrame.
Структуру DataFrame можно создать на базе:
словаря (dict) в качестве элементов которого должны выступать:
одномерные ndarray, списки, другие словари, структуры Series;
двумерные ndarray;
структуры Series;
структурированные ndarray;
другие DataFrame.
30
31.
Библиотека Pandas. Данные вPandas: DataFrame.
Пример: создание DataFrame из двумерного массива
nda1 = np.array([[1, 2, 3], [10, 20, 30]])
df4 = pd.DataFrame(nda1)
print(df4)
Результат:
0
1
2
0
1
2
3
1
10 20 30
31
32.
Библиотека Pandas. Основныеметоды Pandas. Чтение CSV и XLSX
файлов.
С помощью методов head() и tail() можно выводить определенное
число первых или последних строк файла:
import pandas as pd
# Чтение данных из файла CSV
dataframe = pd.read_csv('data.csv')
# Вывод первых 2 строк DataFrame
print(dataframe.head(2))
# Вывод последних 2 строк DataFrame
print(dataframe.tail(2))
32
33.
Библиотека Pandas. Данные вPandas: DataFrame.
Результат:
столбец_1 столбец_2
столбец_3
0
1
100
Яблоки
1
2
110
Апельсины
столбец_1 столбец_2
столбец_3
6
7
500
Черешня
7
8
250
Персики
Если в head() и tail() не передавать нужное количество строк, по
умолчанию будут выведены первые (или последние) 5 строк.
33
34.
Библиотека Pandas. Данные вPandas: DataFrame.
Для чтения Excel файлов используют метод read_excel():
import pandas as pd
# читаем Excel файл
df = pd.read_excel('data.xlsx')
# выводим DataFrame
print(df)
34
35.
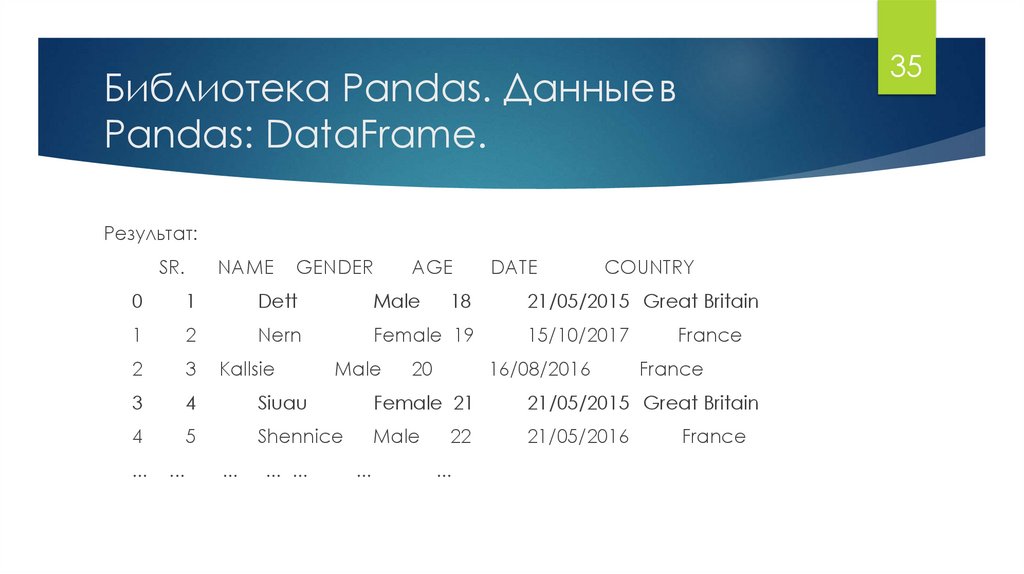
35Библиотека Pandas. Данные в
Pandas: DataFrame.
Результат:
SR.
NAME
GENDER
AGE
COUNTRY
0
1
Dett
Male
1
2
Nern
Female 19
2
3
3
4
Siuau
Female 21
21/05/2015 Great Britain
4
5
Shennice
Male
21/05/2016
...
...
Kallsie
...
... ...
Male
...
18
DATE
20
21/05/2015 Great Britain
15/10/2017
16/08/2016
22
...
France
France
France
36.
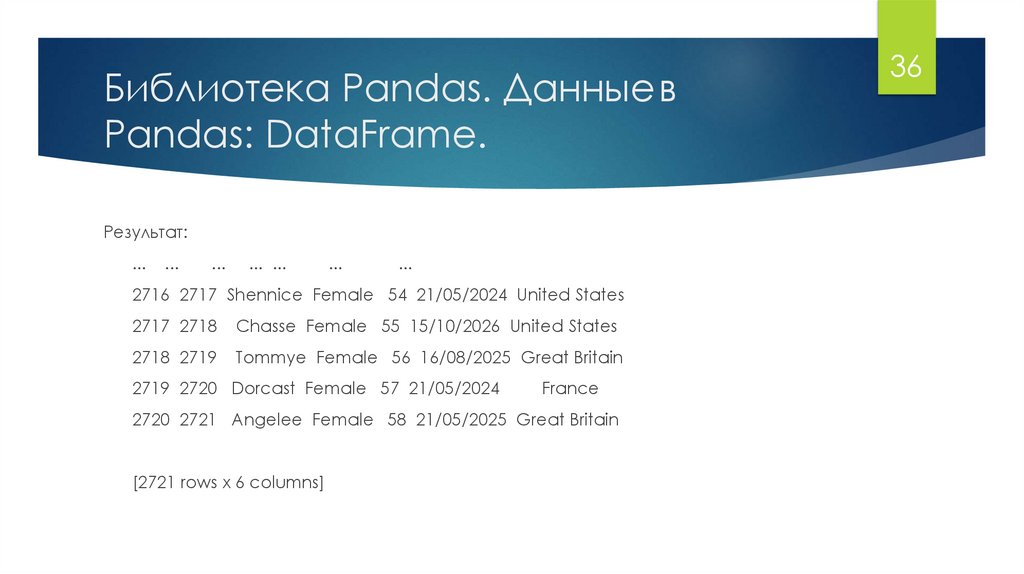
Библиотека Pandas. Данные вPandas: DataFrame.
Результат:
...
...
...
... ...
...
...
2716 2717 Shennice Female 54 21/05/2024 United States
2717 2718
Chasse Female 55 15/10/2026 United States
2718 2719
Tommye Female 56 16/08/2025 Great Britain
2719 2720 Dorcast Female 57 21/05/2024
France
2720 2721 Angelee Female 58 21/05/2025 Great Britain
[2721 rows x 6 columns]
36
37.
Библиотека Pandas. Данные вPandas: DataFrame.
В read_excel() можно передать дополнительный параметр, чтобы вывести
определенный лист по его названию или по индексу:
df = pd.read_excel('data.xlsx', sheet_name='Лист1') # по названию
df = pd.read_excel('data.xlsx', sheet_name=0) # по индексу
37
38.
Библиотека Pandas. Данные вPandas: DataFrame.
Можно прочитать листы выборочно:
sheets = ['Продажи', 'Затраты', 'Прибыль']
df_dict = pd.read_excel('data.xlsx', sheet_name=sheets)
# доступ к объектам DataFrame по именам
df1 = df_dict['Продажи']
df2 = df_dict['Затраты']
df3 = df_dict['Прибыль']
38
39.
Библиотека Pandas. Данные вPandas: DataFrame.
Запись данных в CSV и XLSX файлы.
Метод to_csv() сохраняет DataFrame в csv файле, причем индексы можно не
записывать:
import pandas as pd
# создание DataFrame
dataframe = pd.DataFrame({'M': [100, 120, 130], 'L': [140, 150, 165]})
# запись данных в файл CSV
dataframe.to_csv('output.csv', index=False)
39
40.
Библиотека Pandas. Данные вPandas: DataFrame.
Содержимое файла output.csv будет выглядеть следующим образом:
M,L
100,140
120,150
130,165
40
41.
Библиотека Pandas. Данные вPandas: DataFrame.
Запись данных в файл Excel выполняют с помощью функции to_excel():
import pandas as pd
# создание DataFrame
dataframe = pd.DataFrame({'Москва': [10000000, 250000, 300],
'Самара': [4000000, 150000, 600]})
# запись данных в файл Excel
dataframe.to_excel('output.xlsx', index=False)
41
42.
Библиотека Pandas. Данные вPandas: DataFrame. Срез фрейма.
Операция позволяет выделить из общего DataFrame несколько столбцов.
Для этого необходимо использовать срез, который выглядит как df[['Имя
столбца']]
Срез можно сохранить в новой переменной, в виде нового фрейма.
42
43.
Библиотека Pandas. Данные вPandas: DataFrame. Метод loc[].
При работе со структурами Series и DataFrame из библиотеки pandas,
как правило, используют два основных способа получения значений
элементов.
Первый способ основан на использовании меток, в этом случае работа
ведется через метод .loc. Если вы обращаетесь к отсутствующей метке,
то будет сгенерировано исключение KeyError.
43
44.
Библиотека Pandas. Данные вPandas: DataFrame. Свойство loc[].
Допустимые входные данные:
Одна метка, например, 5 или 'a'. Обратите внимание, что 5
интерпретируется как метка индекса, а не как целочисленная
позиция вдоль индекса.
Список или массив меток, например ['a', 'b', 'c'].
Объект-срез с метками, например 'a':'f'. Обратите внимание, что в
отличие от обычных срезов python, включены как начало, так и конец.
44
45.
Библиотека Pandas. Данные вPandas: DataFrame. Свойство loc[].
массив логических значений той же длины, что и разрезаемая ось
(строка/столбец), например [True, False, True].
Выравниваемый логический ряд. Индекс ключа будет выровнен перед
наложением маски.
Выравниваемый индекс. Возвращаемый индекс будет являться
входными данными.
Вызываемый объект с одним аргументом (Series или DataFrame),
которая возвращает допустимые данные для индексирования (одно из
приведенных выше)
45
46.
Библиотека Pandas. Данные вPandas. Индексация и доступ к
данным
Пример использования
import pandas as pd
# создаем DataFrame
dataframe = pd.DataFrame({'Велосипеды': [100, 200, 350], 'Самокаты': [240,
500, 650]})
print(dataframe.loc[0, 'Велосипеды']) # выводим значение в первой
строке и столбце 'Велосипеды'
print(dataframe.loc[1]) # выводим вторую строку целиком
print(dataframe.loc[:, 'Самокаты']) # выводим столбец 'Самокаты'
целиком
46
47.
Библиотека Pandas. Данные вPandas. Индексация и доступ к
данным
Результат:
100
Велосипеды
200
Самокаты
500
Name: 1, dtype: int64
0
240
1
500
2
650
Name: Самокаты, dtype: int64
47
48.
Библиотека Pandas. Данные вPandas: DataFrame. Метод iloc[].
Второй способ основан на использовании целых чисел для доступа к
данных, он предоставляется через метод .iloc.
При использовании .iloc, если вы обращаетесь к несуществующему
элементу, то будет сгенерировано исключение IndexError.
Логика использования .iloc очень похожа на работу с .loc.
48
49.
Библиотека Pandas. Данные вPandas: DataFrame. Свойство iloc[].
Свойство DataFrame.iloc[] осуществляет доступ к группе строк и
столбцов по целочисленной позиции (от 0 до len(DataFrame.index)-1
(len(Series.index)-1) для строк и от 0 до len(DataFrame.columns)-1 для
столбцов).
Свойство также может использоваться с массивом логических значений
той же длины, что и индекс строк/столбцов.
Разрешенные входные данные:
Целое число, например 5.
Список или массив целых чисел, например. [4, 3, 0].
49
50.
Библиотека Pandas. Данные вPandas: DataFrame. Свойство iloc[].
Объект среза с целыми числами, например. 1:7.
Массив логических значений той же длины, что и разрезаемая ось
(строка/столбец), например [True, False, True].
Вызываемый объект с одним аргументом (принимает Series или DataFrame) и
возвращающая действительный результат для индексации (один из
вышеперечисленных). Такое поведение полезно в цепочках методов, когда нет
ссылки на вызывающий объект, при этом необходимо основывать свой выбор
на каком-то значении.
Кортеж индексов строк и столбцов. Элементы кортежа состоят из одного из
вышеуказанных входных данных, например, (0, 1).
50
51.
Библиотека Pandas. Данные вPandas: DataFrame. Свойство iloc[].
Пример
import pandas as pd
# создаем DataFrame
dataframe = pd.DataFrame({'Кошки': [400, 500, 600], 'Собаки': [145, 255, 350]})
print(dataframe.iloc[0, 1]) # выводим значение в первой строке и втором столбце
print(dataframe.iloc[1]) # выводим вторую строку целиком
print(dataframe.iloc[:, 1]) # выводим второй столбец целиком
51
52.
Библиотека Pandas. Данные вPandas: DataFrame. Свойство iloc[].
Результат:
145
Кошки
500
Собаки
255
Name: 1, dtype: int64
0
145
1
255
2
350
Name: Собаки, dtype: int64
52
53.
Библиотека Pandas. Данные вPandas: DataFrame. Свойство at[].
Свойство at[] обеспечивает доступ к одному элементу по метке индекса
и столбца
import pandas as pd
dataframe = pd.DataFrame({'Фрукты': [150, 250, 350], 'Овощи': [420, 520,
625]})
print(dataframe.at[0, 'Фрукты']) # выводим значение в первой строке и
столбце 'Фрукты'
Результат:
150
53
54.
Библиотека Pandas. Данные вPandas: DataFrame. Свойство iat[].
Свойство iat[] предоставляет доступ к одному элементу по числовому
индексу и позиции:
import pandas as pd
dataframe = pd.DataFrame({'Возраст': [22, 25, 27],
'Зарплата': [70000, 90000, 12000]})
print(dataframe.iat[0, 1]) # выводим значение в первой строке и втором
столбце
Результат:
70000
54
55.
Библиотека Pandas. Данные вPandas: DataFrame. Манипуляции с
данными.
Метод shape() возвращает размеры DataFrame:
import pandas as pd
dataframe = pd.DataFrame({'Завтрак': [100, 20, 35],
'Обед': [40, 50, 65],
'Ужин': [20, 150, 75]})
# получаем размеры DataFrame с помощью shape
print(dataframe.shape) # выводим (3, 3) - 3 строки и 3 столбца
Результат: (3, 3)
55
56.
Библиотека Pandas. Данные вPandas: DataFrame. Манипуляции с
данными.
Метод drop() позволяет удалять столбцы и строки.
Пример с удалением столбцов:
import pandas as pd
# создаем DataFrame
dataframe = pd.DataFrame({'А': [1, 2, 3], 'Б': [4, 5, 6], 'В': [4, 5, 6]})
# удаляем столбцы 'A' и 'B'
dataframe_dropped = dataframe.drop(['А', 'В'], axis=1)
print(dataframe_dropped)
56
57.
Библиотека Pandas. Данные вPandas: DataFrame. Манипуляции с
данными.
Метод drop() позволяет удалять столбцы и строки.
Пример с удалением строк:
import pandas as pd
dataframe = pd.DataFrame({'А': [10, 20, 30], 'Б': [45, 55, 65],
'В': [74, 85, 96], 'Г': [94, 35, 66]})
# удаляем строки 0 и 1
dataframe_dropped = dataframe.drop([0, 1], axis=0)
print(dataframe_dropped)
57
58.
Библиотека Pandas. Данные вPandas: DataFrame. Манипуляции с
данными.
Метод rename() позволяет переименовать столбцы DataFrame:
import pandas as pd
dataframe = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
# переименование столбцов 'A' и 'B'
dataframe_renamed = dataframe.rename(columns={'A': 'Столбец_1', 'B':
'Столбец_2'})
print(dataframe_renamed)
58
59.
Библиотека Pandas. Данные вPandas: DataFrame. Манипуляции с
данными.
Метод sort_values() выполняет сортировку:
import pandas as pd
dataframe = pd.DataFrame({'А': [3, 2, 1], 'Б': [6, 5, 4], 'В': [9, 8, 7]})
# сортируем данные по столбцу 'A'
dataframe_sorted = dataframe.sort_values(by='А')
print(dataframe_sorted)
59
60.
Библиотека Pandas. Данные вPandas: DataFrame. Манипуляции с
данными.
Метод isnull() – возвращает True, если обнаруживает пропуск значения:
import pandas as pd
dataframe = pd.DataFrame({'Углеводы': [43, 27, None, 49],
'Жиры': [50, None, 17, 8],
'Белки': [25, 5, 11, None]})
# ищем пропущенные значения
missing_values = dataframe.isnull()
print(missing_values)
60
61.
Библиотека Pandas. Данные вPandas: DataFrame. Манипуляции с
данными.
Метод fillna() – заполняет пропущенные значения нужными показателями:
import pandas as pd
dataframe = pd.DataFrame({'Выручка': [105600, 209800, None, 403450],
'Убытки': [5034, None, 17093, 80666],
'Накладные расходы': [15000, None, 17000, 18000]})
# заполняем пропущенные значения нулями
filled_dataframe = dataframe.fillna(0)
print(filled_dataframe)
61
62.
Библиотека Pandas. Данные вPandas: DataFrame. Статистические
показатели.
Метод describe() – выводит основные статистические показатели:
import pandas as pd
dataframe = pd.DataFrame({'Лейкоциты': [134, 232, 321], 'Эритроциты': [474,
561, 690]})
# вывод основных статистических показателей
print(dataframe.describe())
62
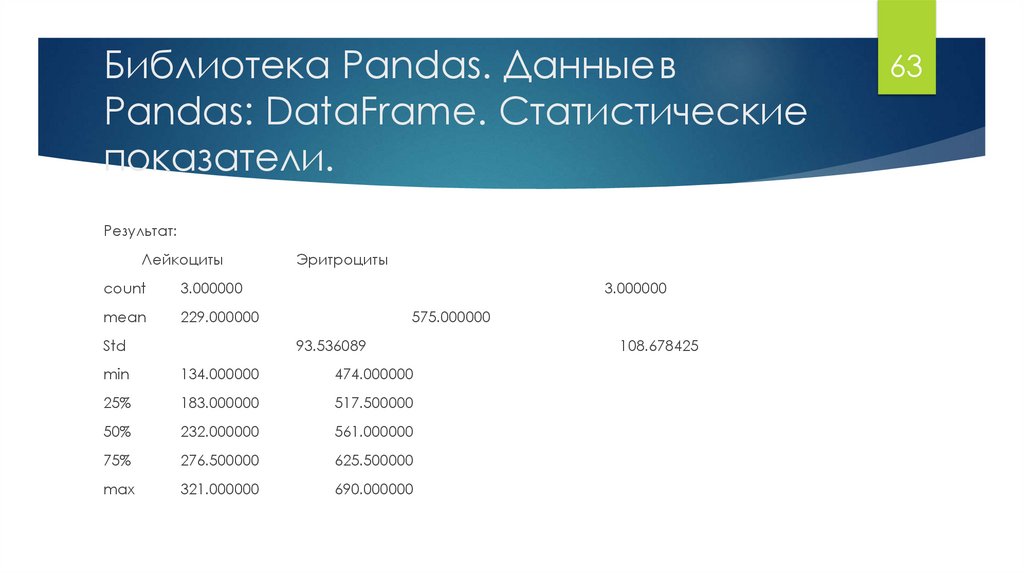
63.
Библиотека Pandas. Данные вPandas: DataFrame. Статистические
показатели.
Результат:
Лейкоциты
count
3.000000
mean
229.000000
Std
Эритроциты
3.000000
575.000000
93.536089
min
134.000000
474.000000
25%
183.000000
517.500000
50%
232.000000
561.000000
75%
276.500000
625.500000
max
321.000000
690.000000
108.678425
63
64.
Библиотека Pandas. Данные вPandas: DataFrame. Статистические
показатели.
Метод sum() – суммирует значения по столбцам:
import pandas as pd
dataframe = pd.DataFrame({'Ноутбуки': [341, 267, 382],
'Планшеты': [374, 503, 466]})
# выводим суммы значений по столбцам
print(dataframe.sum())
64
65.
Библиотека Pandas. Данные вPandas: DataFrame. Статистические
показатели.
Метод mean() – вычисляет средние значения по столбцам:
import pandas as pd
dataframe = pd.DataFrame({'Выручка': [134500, 200670, 300345],
'Затраты': [40450, 50450, 60450]})
# выводим средние значения для столбцов
print(dataframe.mean())
65
66.
Библиотека Pandas. Данные вPandas: DataFrame. Статистические
показатели.
Методы min() и мах() – выводят минимальные и максимальные значения
для каждого столбца:
import pandas as pd
dataframe = pd.DataFrame({'Apple': [1034, 1245, 3985],
'Nvidia': [4034, 5124, 6723]})
print(dataframe.min()) # минимальные значение в столбцах
print(dataframe.max()) # максимальные значения в столбцах
66
67.
Библиотека Pandas. Копированиенабора данных.
Для чего нужно использовать метод copy?
Если просто воспользоваться присваиванием:
import pandas as pd
df1 = pd.DataFrame({ ‘a’:[0,0,0], ‘b’: [1,1,1]})
df2 = df1
df2[‘a’] = df2[‘a’] + 1
df1.head()
67
68.
Библиотека Pandas. Копированиенабора данных.
То можно обнаружить, что df1 изменен.
Это связано с тем, что df2 = df1 не делает копию df1 и присваивает ее
df2, а устанавливает указатель, указывающий на df1.
Таким образом, любые изменения в df2 приведут к изменениям в df1.
По этой причине необходимо использовать:
df2 = df1.copy ()
68
69.
69Библиотека Pandas. Очистка данных.
Для очистки данных можно использовать следующие функции:
drop_duplucates() удаляет дубликаты, то есть полностью идентичные
строки.
fillna() заменяет пропуски NaN на какое-то значение, например на
нули.
dropna() удаляет строки с NaN из таблицы.
Рассмотри их подробнее
70.
70Библиотека Pandas. Очистка данных.
Метод DataFrame.drop_duplicates() возвращает DataFrame с
удаленными дубликатами строк.
DataFrame.drop_duplicates(subset=None, *, keep='first', inplace=False,
ignore_index=False)
Поиск дублирующих значений в определенных столбцах subset не
является обязательным.
71.
71Библиотека Pandas. Очистка данных.
Принимаемые аргументы:
subset=None - поиск дубликатов только в определенных столбцах. По умолчанию
используются все столбцы. Принимает метку столбца или список меток столбцов.
keep='first' - определяет, какие дубликаты (если есть) оставлять в DataFrame.
first : пометить дубликаты как True, за исключением первого вхождения.
last : пометить дубликаты как True, за исключением последнего вхождения.
False: пометить все дубликаты как True.
inplace=False - следует ли изменять исходный DataFrame, а не создавать новый.
ignore_index=False - если значение True, то результирующая ось будет помечена как
0, 1, ..., n - 1.
72.
72Библиотека Pandas. Очистка данных.
Пример:
import pandas as pd
df = pd.DataFrame({
'brand': ['Yum Yum', 'Yum Yum', 'Indomie', 'Indomie', 'Indomie'],
'style': ['cup', 'cup', 'cup', 'pack', 'pack'],
'rating': [4, 4, 3.5, 15, 5]
})
73.
73Библиотека Pandas. Очистка данных.
Пример:
brand
style
0 Yum Yum
cup
4.0
1 Yum Yum
cup
4.0
2 Indomie
3 Indomie
4 Indomie
cup
3.5
pack
15.0
pack
5.0
rating
74.
74Библиотека Pandas. Очистка данных.
По умолчанию, метод удаляет повторяющиеся строки на основе всех столбцов.
df.drop_duplicates()
brand
style
rating
0 Yum Yum
cup
4.0
2 Indomie
cup
3.5
3 Indomie
pack
15.0
4 Indomie
pack
5.0
75.
75Библиотека Pandas. Очистка данных.
Чтобы удалить дубликаты значений столбцов 'brand' и 'style' и при этом
сохранить последние вхождения, используем аргумент keep.
df.drop_duplicates(subset=['brand', 'style'], keep='last')
brand
style
rating
1 Yum Yum
cup
4.0
2 Indomie
cup
3.5
4 Indomie
pack
5.0
76.
76Библиотека Pandas. Значения NaN.
NaN - это значение (Not a Number) используется в структурах данных pandas
для обозначения наличия пустого поля или чего-то, что невозможно обозначить
в числовой форме.
Как правило, NaN — это проблема, для которой нужно найти определенное
решение, особенно при работе с анализом данных.
Эти данные часто появляются при извлечении информации из
непроверенных источников или когда в самом источнике недостает данных.
Также значения NaN могут генерироваться в специальных случаях, например,
при вычислении логарифмов для отрицательных значений, в случае
исключений при вычислениях или при использовании функций.
Есть разные стратегии работы со значениями NaN.
77.
77Библиотека Pandas. Метод Fillna()
Метод fillna() используется для заполнения нулевых значений в наборе данных
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None,
**kwargs)
Параметры
Value - это значение, которое используется для заполнения нулевых значений, поочередно
Series/dict/DataFrame.
Method - метод, который используется для заполнения пустых значений в переиндексированном
ряду.
Axis - принимает целочисленное или строковое значение для строк/столбцов. Ось, по которой нам
нужно заполнить пропущенные значения.
Inplace - если это True, он заполняет значения на пустом месте.
Limit - это целочисленное значение, указывающее максимальное количество последовательных
заполнений значения NaN вперед/назад.
Downcast - требуется dict, указывающий, что следует преобразовывать, например Float64, в int64.
78.
78Библиотека Pandas. Метод Fillna()
Пример:
import pandas as pd
info = pd.DataFrame(data={'x':[10,20,30,40,50,None]})
print(info)
info.fillna(value=0, inplace=True)
print(info)
79.
79Библиотека Pandas. Очистка данных.
До:
После:
x
0
10.0
0
10.0
1
20.0
1
20.0
2
30.0
2
30.0
3
40.0
3
40.0
4
50.0
4
50.0
5
NaN
5
0.0
x
80.
80Библиотека Pandas. Dropna().
По умолчанию dropna() удаляет строки, которые содержат хотя бы одно
пропущенное значение.
df_cleaned = df.dropna()
print(df_cleaned)
Чтобы удалить столбцы, содержащие пропущенные значения можно
воспользоваться параметром axis=1.
df_cleaned_columns = df.dropna(axis=1)
print(df_cleaned_columns)
81.
81Библиотека Pandas. Dropna().
Можно указать столбцы, для которых должна быть применена проверка
на NaN, используя параметр subset.
df_cleaned_subset = df.dropna(subset=['Name', 'City'])
print(df_cleaned_subset)
В этом случае будут удалены только те строки, в которых отсутствуют
значения в столбцах Name или City.
82.
Библиотека Pandas. Визуализацияданных.
При анализе информации и данных часто нужно строить графики,
диаграммы и гистограммы. Визуализация помогает оценивать
масштабы значений, сравнивать показатели, понимать тренды и многое
другое.
В библиотеке Pandas есть встроенный функционал для большинства
типов графиков. Эти методы построены на базе библиотеки Matplotlib —
одного из популярных среди аналитиков решений для визуализации на
Python.
82
83.
Библиотека Pandas. Визуализацияданных.
Способы построения диаграмм в Pandas:
Метод plot у DataFrame, принимающий в качестве аргумента kind,
который определяет вид графика;
Вызов функции для построения hist, bar, line (линейный) через метод
plot;
Напрямую обратиться к bar, boxplot или hist.
83
84.
Библиотека Pandas. Визуализацияданных.
Способы построения диаграмм в Pandas:
Метод plot у DataFrame, принимающий в качестве аргумента kind,
который определяет вид графика;
Вызов функции для построения hist, bar, line (линейный) через метод
plot;
Напрямую обратиться к bar, boxplot или hist.
В качестве примера возьмем набор данных с отзывами о винных
изделиях разных стран,
84
85.
Библиотека Pandas. Визуализацияданных. Диаграмма рассеяния
В диаграмме рассеяния каждая точка одного атрибута соответствует
каждой точке другого.
1-й метод построения заключается в том, что у DataFrame есть метод
plot, одним из аргументов которого является kind, определяющий вид
графика.
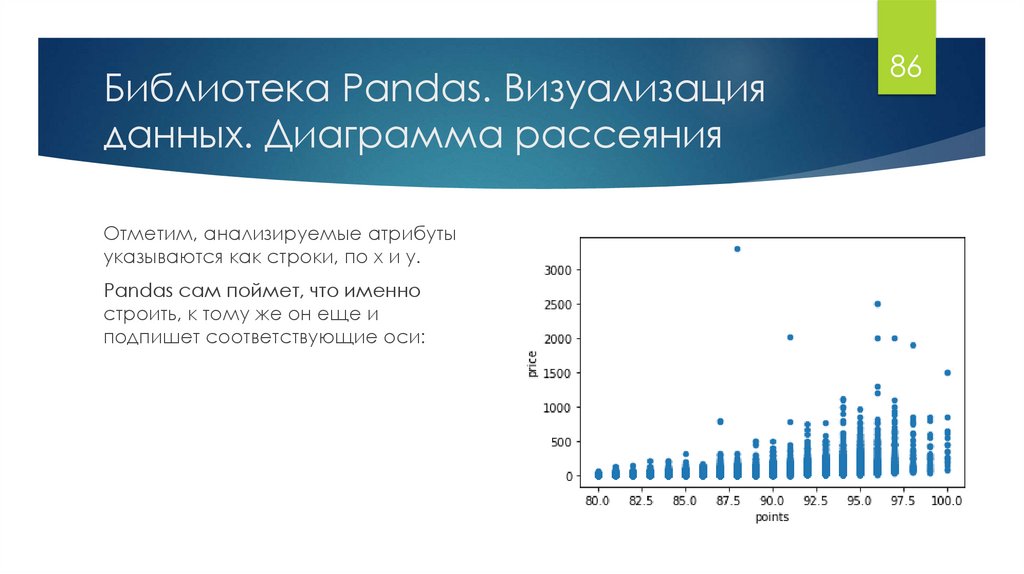
data.plot(x='points', y='price', kind='scatter')
Так как у нас точечный график, нужно указать scatter
85
86.
Библиотека Pandas. Визуализацияданных. Диаграмма рассеяния
Отметим, анализируемые атрибуты
указываются как строки, по x и y.
Pandas сам поймет, что именно
строить, к тому же он еще и
подпишет соответствующие оси:
86
87.
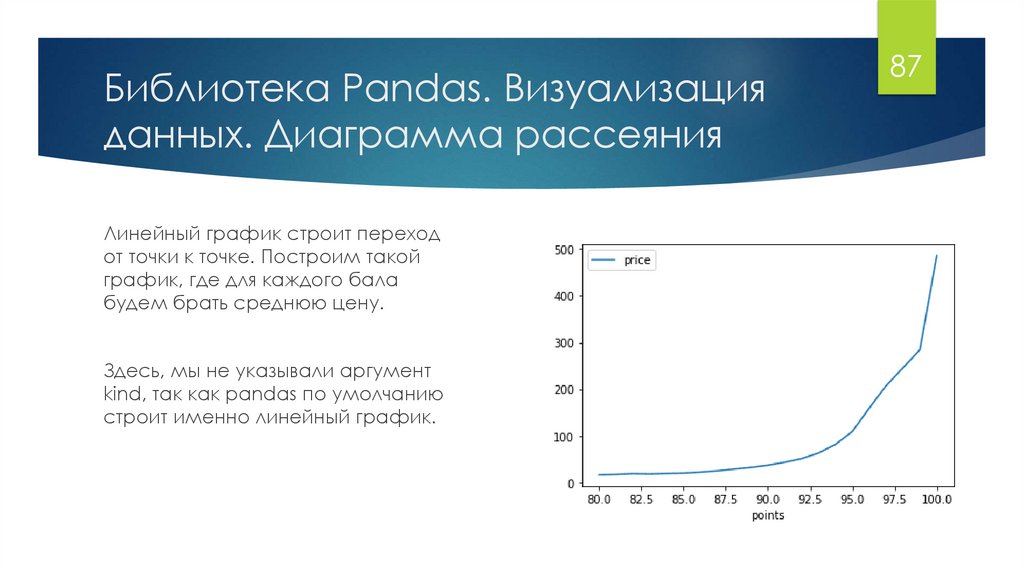
Библиотека Pandas. Визуализацияданных. Диаграмма рассеяния
Линейный график строит переход
от точки к точке. Построим такой
график, где для каждого бала
будем брать среднюю цену.
Здесь, мы не указывали аргумент
kind, так как pandas по умолчанию
строит именно линейный график.
87
88.
Библиотека Pandas. Визуализацияданных. Барный график.
88
На барном графике каждая категория в виде бара имеет высоту, соответствующую
числовому значению этой категории.
Построим первые 7 стран по производству вина.
countries = data['country'].value_counts().head(7)
countries.plot.bar()
В данном примере мы используем второй метод построения - вызов конкретного
графика через метод plot.
89.
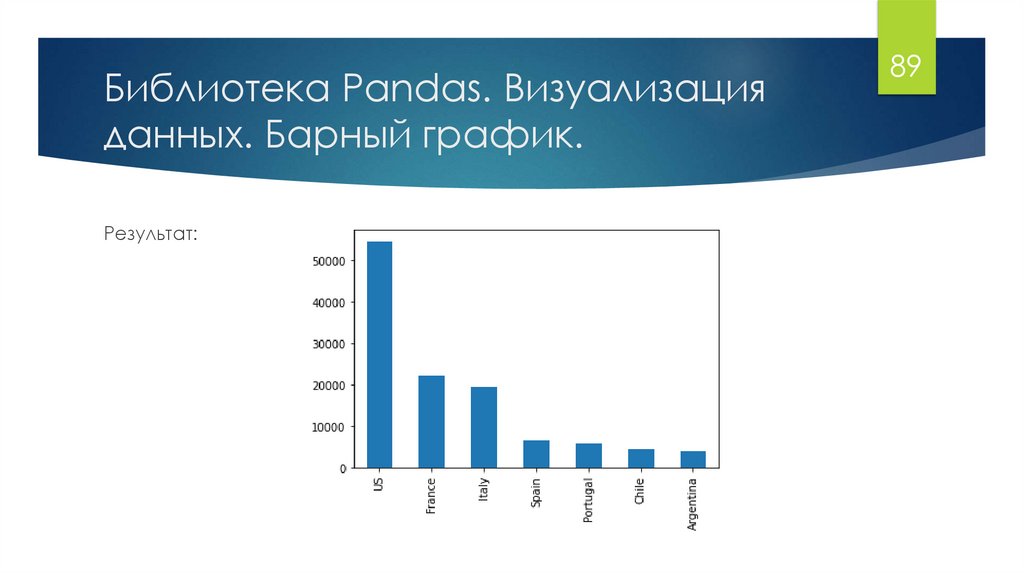
Библиотека Pandas. Визуализацияданных. Барный график.
Результат:
89
90.
Библиотека Pandas. Визуализацияданных. Барный график.
Подобным же образом можно вывести и другие вида графиков в Python:
data.plot.scatter() # диаграмма рассеяния
data.plot.hist() # гистограмма
90
91.
Библиотека Pandas. Визуализацияданных. Гистограмма.
В машинном обучении плотности распределения служат хорошим
инструментом анализа, особенно для линейных моделей.
Например, плотность распределения остатков близкое к нормальному
показывает, что на этих данных можно построить линейную регрессию.
Гистограммы могут помочь с этим.
data.hist(column='points', bins=40, density=True)
91
92.
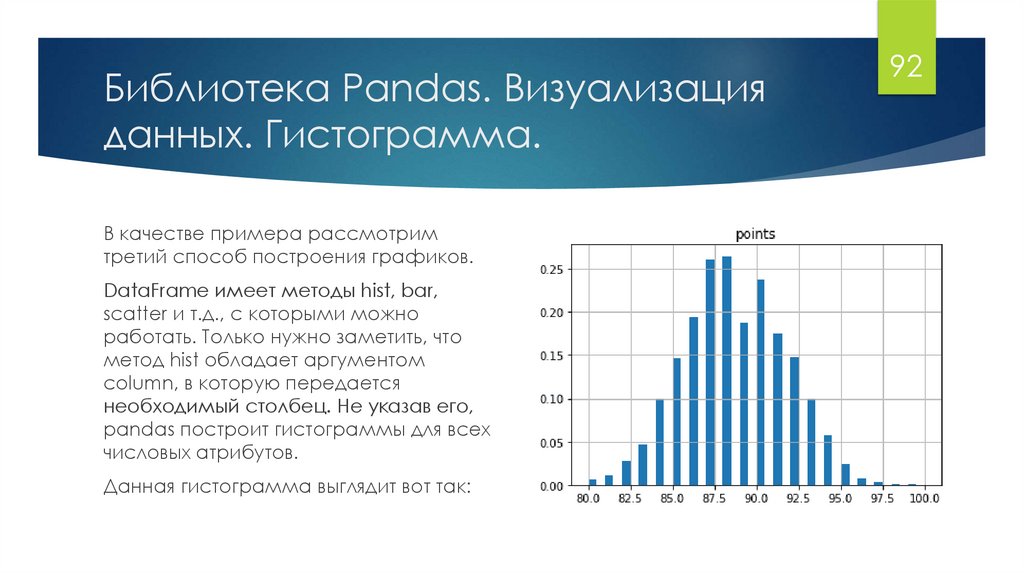
Библиотека Pandas. Визуализацияданных. Гистограмма.
В качестве примера рассмотрим
третий способ построения графиков.
DataFrame имеет методы hist, bar,
scatter и т.д., с которыми можно
работать. Только нужно заметить, что
метод hist обладает аргументом
column, в которую передается
необходимый столбец. Не указав его,
pandas построит гистограммы для всех
числовых атрибутов.
Данная гистограмма выглядит вот так:
92
93.
93БЛАГОДАРЮ ЗА ВНИМАНИЕ!