








































 informatics
informaticsSimilar presentations:





")




Историческая справка. Наука о данных (лекция 1)
1.
Историческая справка• Наука о данных – это научное направление
на стыке анализа данных и компьютерных наук.
Data Science = Data Analysis + Computer Science
• Tukey, John W., 1962. The Future of Data Analysis.
Ann. Math. Statist. 33, No. 1, pp. 1-67
1
2.
Историческая справка• Наука о данных – это научное направление
на стыке анализа данных и компьютерных наук.
Data Science = Data Analysis + Computer Science
• Tukey, John W., 1962. The Future of Data Analysis. Ann.
Math. Statist. 33, No. 1, pp. 1-67
• Появилась новая парадигма: не пытаться предъявить
к данным какие-либо требования, а позволить
им самим «рассказать о себе».
2
3.
Историческая справка• Наука о данных – это научное направление
на стыке анализа данных и компьютерных наук.
Data Science = Data Analysis + Computer Science
• Tukey, John W., 1962. The Future of Data Analysis. Ann.
Math. Statist. 33, No. 1, pp. 1-67
• Появилась новая парадигма: не пытаться предъявить
к данным какие-либо требования, а позволить
им самим «рассказать о себе».
• Сам термин «Data Science» был введен на рубеже
1996–1997 гг.
3
4.
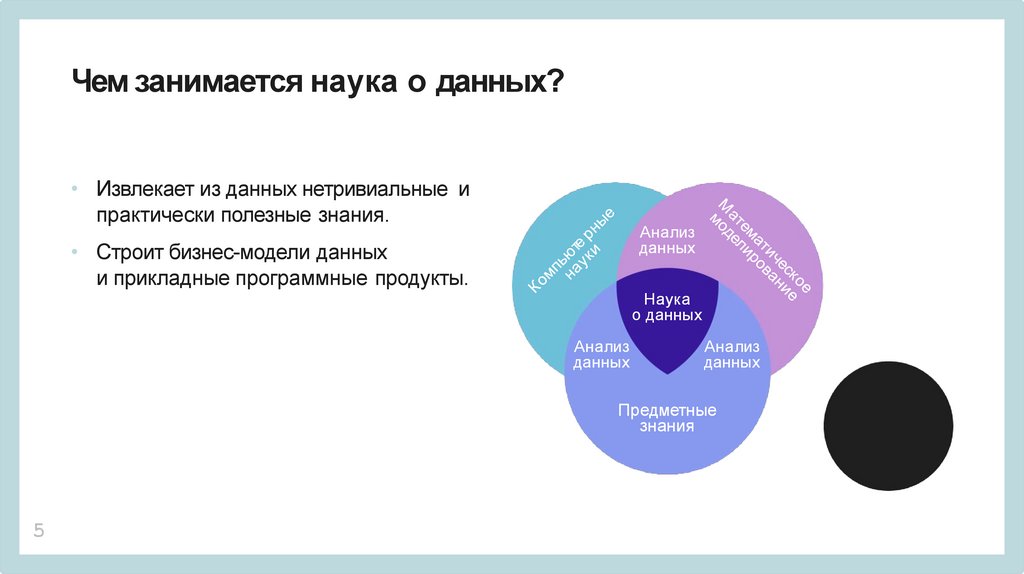
Чем занимается наука о данных?• Извлекает из данных нетривиальные и
практически полезные знания.
• Строит бизнес-модели данных
и прикладные программные продукты.
4
5.
Чем занимается наука о данных?• Извлекает из данных нетривиальные и
практически полезные знания.
Анализ
данных
• Строит бизнес-модели данных
и прикладные программные продукты.
Наука
о данных
Анализ
данных
Анализ
данных
Предметные
знания
5
6.
Перспективы науки о данных• Социальные процессы и явления.
• Промышленность и торговля.
• Медицина.
• Спорт.
6
7.
Аналитические исследованияв бизнесе и экономике
• Анализ поведения клиентов.
• Прогноз продаж товаров и оптимизация остатков
на складах.
7
8.
Социальные сети, общениеи индустрия развлечений
• Рекомендации друзей и групп по интересам.
• Анализ дискуссий.
• Рекомендации фильмов и музыкальных композиций.
8
9.
Финансовая и банковская сферы• Прогнозирование биржевых котировок.
• Предсказание дефолтов физических и
юридических лиц.
9
10.
Какие бывают данныеПрежде чем приступать к решению задачи анализа данных,
нужно сначала понять, что у нас есть и что мы хотим.
Объем данных
• От нескольких сотен записей до десятков терабайт.
• Нам достаточно одного ноутбука или нужен кластер,
например с Spark/Hadoop?
10
11.
Хранение данных• Реляционная база данных (MySQL, SQLite, PostgreSQL, ...).
• Нереляционная база данных aka NoSQL (Cassandra,
HBase).
• Может будет достаточно Pandas DataFrame?
• Как их мы будем анализировать? Нужен ли online?
11
12.
Примеры• Изображения.
• Временные ряды.
• Текст.
• Сильно разреженные.
• Есть отсутствующие значения.
Кроме того, возникают вопросы приватности, этики и т. п.
12
13.
Классификация изображений• Нам нужно по фотографии определить марку машины.
• Задачи классификации изображений сейчас
эффективно решаются с помощью сверточных
нейронных сетей.
• Нужна видеокарта (GPU), на которой вычисления
происходят гораздо быстрее.
13
14.
Определение цены квартиры• Мы должны предсказать рыночную цену квартиры
по адресу, числу комнат, общей площади, этажу.
• Вероятнее всего, данная задача не потребует
серьезных вычислительных мощностей.
14
15.
Подбор рекламы для пользователя• На сайт заходит пользователь.
• Нужно подобрать ему рекламу, чтобы оптимизировать
вероятность клика.
• У нас есть исторические данные, информация о
пользователе (ник на форуме, возможно,
демографические характеристики).
• Подобные задачи требуют существенных
вычислительных ресурсов.
15
16.
Хранение данных16
Основные виды хранилищ:
Требования:
• Файловые хранилища;
• Встраиваемость?
• Реляционные базы данных;
• Распределенность?
• Нереляционные базы данных;
• Транзакции (ACID)?
• Графовые базы данных.
• Хранилище
в оперативной памяти?
17.
Реляционные базы данных• Проверенные решения (Oracle, PostgreSQL, MySQL).
• Надежность и транзации (банки, финансы).
• Существуют встраиваемые базы данных (SQLite, HSQLDB).
• Табличная модель не всегда удобна.
• Не подходит для потоковой обработки.
17
18.
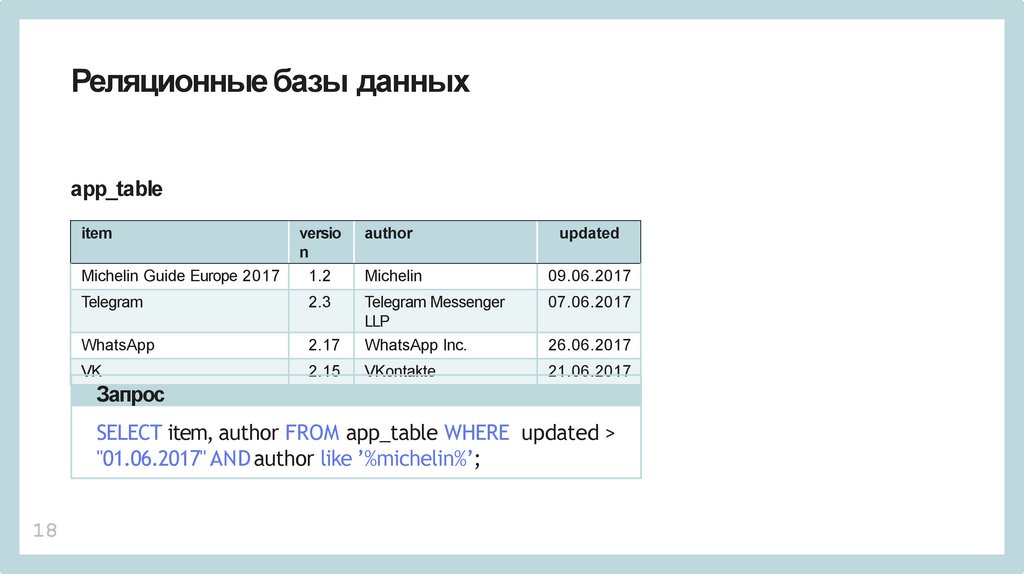
Реляционные базы данныхapp_table
item
author
updated
Michelin Guide Europe 2017
versio
n
1.2
Michelin
09.06.2017
Telegram
2.3
07.06.2017
2.17
Telegram Messenger
LLP
WhatsApp Inc.
VK
2.15
VKontakte
21.06.2017
26.06.2017
Запрос
SELECT item, author FROM app_table WHERE updated >
"01.06.2017" AND author like ’%michelin%’;
18
19.
Нереляционные базы данныхОсновные виды:
• Хранилища Key-Value (Redis, Amazon DynamoDB).
• Документо-ориентированные базы данных
(MongoDB, MarkLogic, CouchDB).
• Графовые базы данных (Neo4j).
• Колоночные БД (HBase, Cassandra).
– Различные возможности и сфера применения.
– В основном рассчитаны на работу в кластере.
19
20.
JSONJavaScript Object Notation (Нотация объектов JavaScript).
• Текстовый формат.
• Произошел из языка программирования JavaScript.
• Хранение структурированных объектов (словари,
списки).
• Библиотеки для многих языков программирования.
20
21.
JSON, примерфайлаgoogle_play.json
{
}
21
"item_name" :"Michelin Guide Europe 2017",
"version" :1.2,
"contacts" :{
"url" :"https ://www.viamichelin.fr",
"email" :"mobile@p.michelin.com"
},
"updated" :"9 March 2017", "author" :
"Michelin",
"last_rates" :[4.5, 5, 3, 4]
22.
CSVComma-Separated Values (Значения, Разделенные Запятыми):
• Текстовый формат;
• Столбы разделены запятыми;
• На первой строчке часто используют заголовок;
• Существует стандарт RFC 4180, но в реальной жизни его часто не соблюдают. Различия
часто касаются способа представления текста (в котором тоже могут быть запятые);
• Иногда колонки разделяют табуляцией (Tab-Separated Values);
• Инструменты для чтения интегрированы во множество сред для анализа данных.
22
23.
CSV, пример файлаПример CSV-файла, содержащего информацию о недвижимости:
real_estate.csv
Комнат,Район города,Адрес,Этаж,Общ,Жил,Кух,Цена
1,Московский,Московское ш. 8,6/7,30.0,16.2,7.5,4100.0
1,Московский,Московский пр. 181,4/7,42.0,20.0,12.0,6000.0
1,Московский,Московский пр.,3/7,25.6,13.1,4.1,3140.0
1,Московский,Московский пр. 86,5/8,30.1,17.4,5.0,4100.0
1,Московский,Конституции пл. 1 к. 2,2/8,37.0,18.0,9.0,5600.0
1,Московский,Дунайский пр. 7,3/8,27.5,14.1,5.9,3401.0
23
24.
Apache ParquetБинарный колонко-ориентированный формат
хранения данных:
• Изначально создавался для экосистемы Hadoop,
с учетом возможности распределенной обработки.
• Поддерживает сложные структуры данных
Поддерживается эффективное сжатие.
• Инструменты для работы с Parquet на настоящий
момент реализованы в большинстве сред
для анализа данных.
24
25.
HDF5Hierarchical Data Format (Иерархический формат данных)
5-й версии:
• Несколько иная идеология, если сравнивать с
табличными данными.
• Иерархический формат (похоже на файловую систему)
хранения данных любой природы.
• Позволяет эффективно обращаться к данным, даже
очень большим данным.
• Существуют библиотеки для большинства популярных
сред для анализа данных.
25
26.
SQLiteВстраиваемая реляционная база данных:
• Легковесная альтернатива «большим» базам данных
(Oracle, MySQL, и т. п.).
• Вся БД хранится в одном файле.
• Существуют библиотеки для доступа из большинства
сред программирования (в частности, модуль
для работы с SQLite в стандартную поставку Python).
• Обычно довольно комфортно работать с данными
не превышающими 4–5 Гб.
26
27.
Представление данныхОбычно мы оперируем объектами,
которые состоят из атрибутов или признаков.
(1, ’Московский р-н’, ’Дунайский пр.’, 6/7, 42, 20, 12)
Отдельные элементы – признаки объекта.
Разберемся с видами признаков.
27
28.
Количественные признакиСамый простой и типичный случай: значение
признака – действительное число, в общем
случае ничем не ограниченное.
Примеры количественных признаков:
• Площадь квартиры;
• Вес человека;
• Среднее число букв в предложении (для текста).
28
29.
Категориальные признакиЗначение признака принадлежит какому-то конечному неупорядоченному множеству.
Примеры категориальных признаков:
• Название улицы;
• Группа крови;
• Марка машины.
Если возможных значений всего два, то такой признак часто называют бинарным.
Для некоторых методов машинного обучения необходимо перейти от
категориальных к количественным признакам. В этом случае применяют One-hot
Encoding или Hashing trick.
29
30.
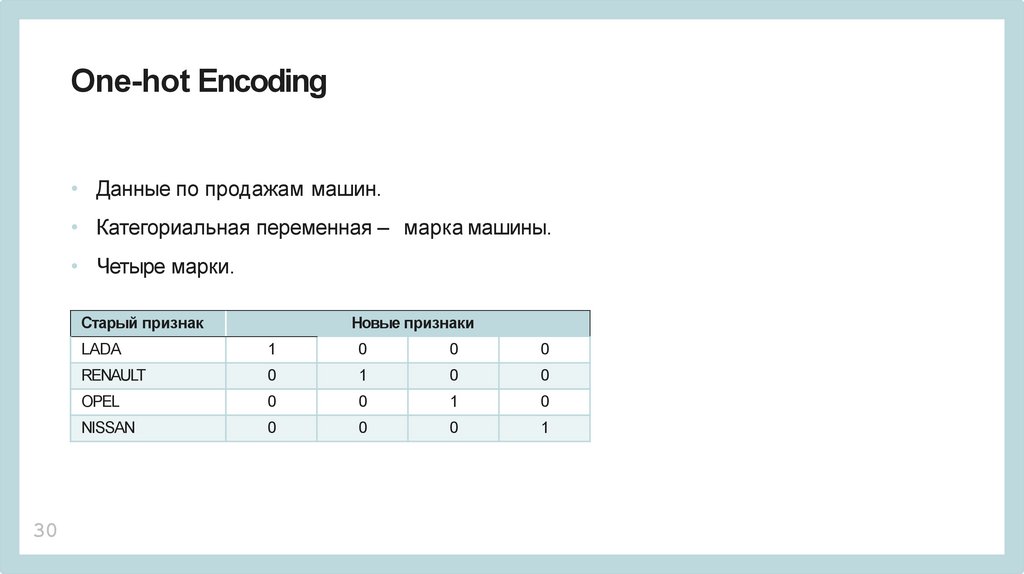
One-hot Encoding• Данные по продажам машин.
• Категориальная переменная – марка машины.
• Четыре марки.
Старый признак
30
Новые признаки
LADA
1
0
0
0
RENAULT
0
1
0
0
OPEL
0
0
1
0
NISSAN
0
0
0
1
31.
Хэширование признаков (hashing trick)• Категориальных признаков может быть очень много.
• Размерность данных неприлично возрастет.
• Не гарантируется, что в тренировочных данных будут все возможные категории.
Что делать:
• Выбираем число N – число наших новых признаков.
• Для каждой категории W считаем k = hash(W)%N.
• Присваиваем новому признаку на соответствующем месте k единицу.
• Существуют вариации, годится не для всех методов машинного обучения/анализа данных.
31
32.
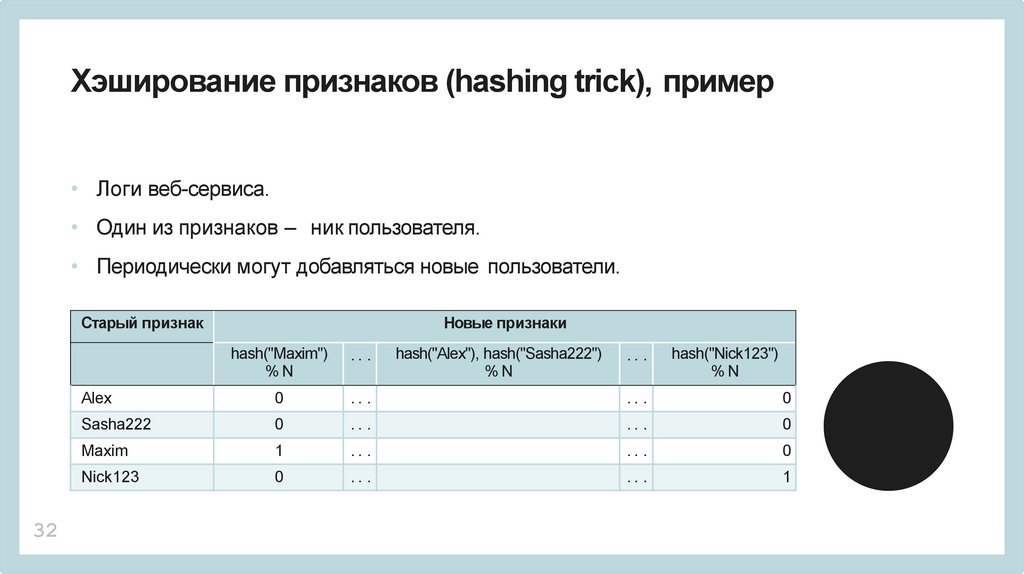
Хэширование признаков (hashing trick), пример• Логи веб-сервиса.
• Один из признаков – ник пользователя.
• Периодически могут добавляться новые пользователи.
Старый признак
32
Новые признаки
hash("Maxim")
%N
.. .
hash("Alex"), hash("Sasha222")
%N
Alex
0
.. .
.. .
0
Sasha222
0
.. .
.. .
0
Maxim
1
.. .
.. .
0
Nick123
0
.. .
.. .
1
.. .
hash("Nick123")
%N
33.
Обработка текстаАнализ текстов – важное направление
анализа данных (классификация,
кластеризация, тональность):
• Многие алгоритмы требуют
численного представления.
• Данные должны быть
фиксированного размера.
• Проблема разреженности данных.
33
Допущения:
• Модель Bag of Words (BoW) –
«мешок слов».
• Последовательность слов в тексте
не имеет значения.
• Учитывается только количество.
34.
Токенизация и нормализация34
Токенизация:
Нормализация:
• Выделение границ слов.
• Стемминг (корове →коров)
или лемматизация (корове →корова).
• Регулярные выражения, сложные
парсеры.
• Удаление стоп-слов.
Миша, который встретил Машу →
[’Миша’, ’который’, ’встретил’, ’Машу’]
[’Миша’, ’который’, ’встретил’, ’Машу’] →
[’миша’, ’встретить’, ’маша’]
35.
ТрансформацияТрансформация:
• tf-idf и вариации,
• Hashing trick,
• Уменьшение размерности.
[’миша’, ’встретить’, ’маша’] →[0, 0.12, . . . , 0.7, 0]
35
36.
Коллекция документов• Текстовая коллекция.
• Коллекция уже обработанная, последовательность слов.
• 4 документа (обозначим число документов константой N).
• 5 различных слов.
Text id
36
Текст
0
кошка собака корова
1
корова лев волк лев
2
волк собака
3
кошка корова кошка
37.
Количество слов• Посчитаем сколько каждое слово встречается в каждом документе.
• f(wi , d)
• Размерность вектора – число уникальных слов в коллекции.
• Не учитывается размер документов, то как часто слова встречаются в коллекции.
37
Text id
волк
корова
кошка
лев
собака
0
0
1
1
0
1
1
1
1
0
2
0
2
1
0
0
0
1
3
0
1
2
0
0
38.
Частота словВведем величину tf(wi , d) – termfrequency.
Можно определить следующим образом:
Для простоты остановимся
на tf(wi, d) = f(wi, d)
• Бинарное взвешивание
tf(wi, d) = |f(wi, d) > 0|
Text id
волк
корова
кошка
лев
собака
0
0
1
1
0
1
1
1
1
0
2
0
2
1
0
0
0
1
3
0
1
2
0
0
• Число слов tf(wi, d) = f(wi, d)
f(wi ,d)
• Частота слов tf(w i, d) =
∑wj∈d f(w j, d)
• Нормализация по самому
популярному слову в документе
f(wi ,d)
tf(wi , d) = 0.5 + 0.5
maxwt(w
, d)j
∈d
j
38
39.
Документная частота• Посчитаем, в скольких документах встречается каждое слово.
• df(wi) – document frequency, документная частота.
N
+
1
• idf(w ) = log
+ 1 – обратная документная
i
частота.
df(wi ) +1
• Если слово встречается во всех документах, то idf(wi) = 1.
Слово
39
Документная частота (df) idf
волк
2
1.51
корова
3
1.22
кошка
2
1.51
лев
1
1.92
собака
2
1.51
40.
TF-IDF• Каждому слову wi в каждом документе d
сопоставляется значение:
tf-idf(wi , d) = tf(wi, d) × idf (wi)
• Учитывается значимость слова в коллекции и
значимость слова в конкретном документе.
• Для каждого документа значения нормализуются:
tf-idfn(wi, d) =
40
tf-idf(wi ,d)
√ tf-idf(w1, d)2 + ... + tf-idf(wn , d)2
d
41.
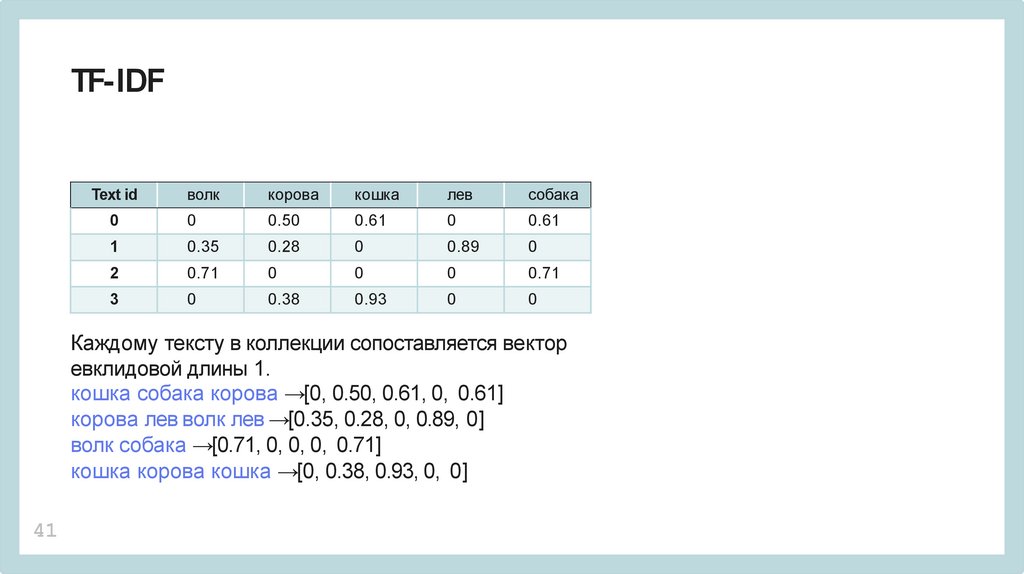
TF-IDFволк
корова
кошка
лев
собака
0
0
0.50
0.61
0
0.61
1
0.35
0.28
0
0.89
0
2
0.71
0
0
0
0.71
3
0
0.38
0.93
0
0
Text id
Каждому тексту в коллекции сопоставляется вектор
евклидовой длины 1.
кошка собака корова →[0, 0.50, 0.61, 0, 0.61]
корова лев волк лев →[0.35, 0.28, 0, 0.89, 0]
волк собака →[0.71, 0, 0, 0, 0.71]
кошка корова кошка →[0, 0.38, 0.93, 0, 0]
41
42.
Подготовка данных• Данные для курса – набор отрывков одинаковой длины
из книг русских писателей.
• 10 авторов.
• Public Domain.
• Всего 47 книг в формате fb2.
42
43.
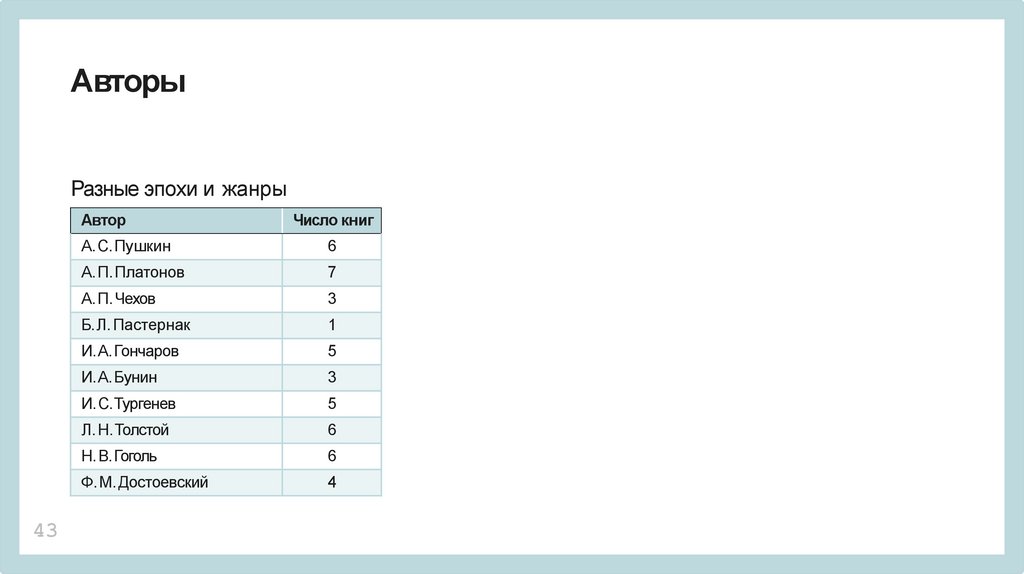
АвторыРазные эпохи и жанры
Автор
43
Число книг
А. С.Пушкин
6
А. П.Платонов
7
А. П.Чехов
3
Б.Л. Пастернак
1
И.А. Гончаров
5
И.А. Бунин
3
И.С.Тургенев
5
Л. Н.Толстой
6
Н.В.Гоголь
6
Ф.М. Достоевский
4
44.
Обработка• В каждой книге отсекались сноски,
комментарии, примечания, не относящиеся
к основному произведению.
• Оставшиеся части делились на параграфы,
параграфы на предложения.
• Предложения склеивались в отрывки (chunk)
размером от 200 до 250 символов.
• Для каждого автора выборка примерно
одинакового размера.
• Токенизация и лемматизация.
44
45.
Пример отрывковАвтор
45
Отрывок
А. С.Пушкин
этот два сочинение явиться видимый причина бор...
А. П.Платонов
вчера отец спотыкнуться на улица и упасть объя...
А. П.Чехов
весь быть решить думать он подходить к гостины...
Б.Л. Пастернак
и москва внизу и вдали родной город автор и по...
И.А. Гончаров
надо мосье быть немного ловчий а то вот вы пус...
И.А. Бунин
ничтожество жалкий девочка у который нет ничто...
И.С.Тургенев
с один сторона рот зуб нет так что весь лицо н...
Л. Н.Толстой
на другой день я весь сила употребить чтобы по...
Н.В.Гоголь
добрый день папа дворецкий бог какой божествен...
Ф.М. Достоевский
прощать дмитрий фёдор прощать раздаться вдруг ...
46.
ХранениеРезультаты сохранены в базе данных в формате SQLite.
Схема таблицы
CREATE TABLE chunk (
chunk_id INTEGER NOT NULL, author VARCHAR(100)
NOT NULL, book_id VARCHAR(100) NOT NULL, text
TEXT NOT NULL,
PRIMARY KEY (chunk_id )
);
46
47.
ЗадачиВ рамках курса предполагается решение следующих задач:
• Отработка базовых навыков обработки текстов;
• Знакомство с экосистемой языка Python для научных
вычислений;
• Тестирование различных методов классификации
(определение автора или книги);
• Кластеризация текстов.
47