


















 informatics
informaticsSimilar presentations:









")
Математические основы информатики. Раздел 2
1.
2.
ЗНАКОВЫЕ СИСТЕМЫЗнаковые системы являются наборами знаков
определенного типа. С некоторыми знаковыми
системами вы хорошо знакомы и постоянно ими
пользуетесь (языки и системы счисления), с другими
познакомитесь в этом пункте.
Каждая знаковая система строится на основе
определенного алфавита (набора знаков) и правил
выполнения операций над знаками.
Алфавит - набор знаков системы.
3.
ЕСТЕСТВЕННЫЕ ЯЗЫКИЧЕЛОВЕК ШИРОКО ИСПОЛЬЗУЕТ ДЛЯ ПРЕДСТАВЛЕНИЯ ИНФОРМАЦИИ
ЗНАКОВЫЕ СИСТЕМЫ, КОТОРЫЕ НАЗЫВАЮТСЯ ЯЗЫКАМИ.
ЕСТЕСТВЕННЫЕ ЯЗЫКИ НАЧАЛИ ФОРМИРОВАТЬСЯ ЕЩЕ В ДРЕВНЕЙШИЕ
ВРЕМЕНА В ЦЕЛЯХ ОБЕСПЕЧЕНИЯ ОБМЕНА ИНФОРМАЦИЕЙ МЕЖДУ ЛЮДЬМИ.
В НАСТОЯЩЕЕ ВРЕМЯ СУЩЕСТВУЮТ СОТНИ ЕСТЕСТВЕННЫХ ЯЗЫКОВ
(РУССКИЙ, АНГЛИЙСКИЙ, КИТАЙСКИЙ И ДР.).
4.
ФОРМАЛЬНЫЕ ЯЗЫКИВ ПРОЦЕССЕ РАЗВИТИЯ НАУКИ БЫЛИ РАЗРАБОТАНЫ ФОРМАЛЬНЫЕ ЯЗЫКИ
(СИСТЕМЫ СЧИСЛЕНИЯ, АЛГЕБРА, ЯЗЫКИ ПРОГРАММИРОВАНИЯ И ДР.), ОСНОВНОЕ
ОТЛИЧИЕ КОТОРЫХ ОТ ЕСТЕСТВЕННЫХ ЯЗЫКОВ СОСТОИТ В СУЩЕСТВОВАНИИ
СТРОГИХ ПРАВИЛ ГРАММАТИКИ И СИНТАКСИСА.
НАПРИМЕР, ДЕСЯТИЧНУЮ СИСТЕМУ СЧИСЛЕНИЯ МОЖНО РАССМАТРИВАТЬ КАК
ФОРМАЛЬНЫЙ ЯЗЫК, ИМЕЮЩИЙ АЛФАВИТ (ЦИФРЫ) И ПОЗВОЛЯЮЩИЙ НЕ ТОЛЬКО
ИМЕНОВАТЬ И ЗАПИСЫВАТЬ ОБЪЕКТЫ (ЧИСЛА), НО И ВЫПОЛНЯТЬ НАД НИМИ
АРИФМЕТИЧЕСКИЕ ОПЕРАЦИИ ПО СТРОГО ОПРЕДЕЛЕННЫМ ПРАВИЛАМ.
СУЩЕСТВУЮТ ФОРМАЛЬНЫЕ ЯЗЫКИ, В КОТОРЫХ В КАЧЕСТВЕ ЗНАКОВ
ИСПОЛЬЗУЮТ НЕ БУКВЫ И ЦИФРЫ, А ДРУГИЕ СИМВОЛЫ, НАПРИМЕР
МУЗЫКАЛЬНЫЕ НОТЫ, ИЗОБРАЖЕНИЯ ЭЛЕМЕНТОВ ЭЛЕКТРИЧЕСКИХ ИЛИ
ЛОГИЧЕСКИХ СХЕМ, ДОРОЖНЫЕ ЗНАКИ, ТОЧКИ И ТИРЕ (КОД АЗБУКИ МОРЗЕ).
5.
ГЕНЕТИЧЕСКИЙ АЛФАВИТЯВЛЯЕТСЯ "АЗБУКОЙ", НА КОТОРОЙ СТРОИТСЯ ЕДИНАЯ СИСТЕМА ХРАНЕНИЯ И ПЕРЕДАЧИ
НАСЛЕДСТВЕННОЙ ИНФОРМАЦИИ ЖИВЫМИ ОРГАНИЗМАМИ.
ГЕНЫ СОСТОЯТ ИЗ ЗНАКОВ ГЕНЕТИЧЕСКОГО АЛФАВИТА.
В ПРОЦЕССЕ ЭВОЛЮЦИИ ОТ ПРОСТЕЙШИХ ОРГАНИЗМОВ ДО ЧЕЛОВЕКА КОЛИЧЕСТВО ГЕНОВ
ПОСТОЯННО ВОЗРАСТАЛО, ТАК КАК БЫЛО НЕОБХОДИМО ЗАКОДИРОВАТЬ ВСЕ БОЛЕЕ
СЛОЖНОЕ СТРОЕНИЕ И ФУНКЦИОНАЛЬНЫЕ ВОЗМОЖНОСТИ ЖИВЫХ ОРГАНИЗМОВ.
ГЕНЕТИЧЕСКАЯ ИНФОРМАЦИЯ ХРАНИТСЯ В КЛЕТКАХ ЖИВЫХ ОРГАНИЗМОВ В
СПЕЦИАЛЬНЫХ МОЛЕКУЛАХ.
ЭТИ МОЛЕКУЛЫ СОСТОЯТ ИЗ ДВУХ ДЛИННЫХ СКРУЧЕННЫХ ДРУГ С ДРУГОМ В СПИРАЛЬ
ЦЕПЕЙ, ПОСТРОЕННЫХ ИЗ ЧЕТЫРЕХ РАЗЛИЧНЫХ МОЛЕКУЛЯРНЫХ ФРАГМЕНТОВ.
ФРАГМЕНТЫ ОБРАЗУЮТ ГЕНЕТИЧЕСКИЙ АЛФАВИТ И ОБЫЧНО ОБОЗНАЧАЮТСЯ
ЛАТИНСКИМИ ПРОПИСНЫМИ БУКВАМИ {A, G, С, Т}.
6.
ДВОИЧНАЯ ЗНАКОВАЯ СИСТЕМАВ ПРОЦЕССАХ ХРАНЕНИЯ, ОБРАБОТКИ И ПЕРЕДАЧИ
ИНФОРМАЦИИ В КОМПЬЮТЕРЕ ИСПОЛЬЗУЕТСЯ ДВОИЧНАЯ
ЗНАКОВАЯ СИСТЕМА, АЛФАВИТ КОТОРОЙ СОСТОИТ ВСЕГО ИЗ
ДВУХ ЗНАКОВ {0, 1}.
ФИЗИЧЕСКИ ЗНАКИ РЕАЛИЗУЮТСЯ В ФОРМЕ ЭЛЕКТРИЧЕСКИХ
ИМПУЛЬСОВ (НЕТ ИМПУЛЬСА - 0, ЕСТЬ ИМПУЛЬС - 1), А ТАКЖЕ
СОСТОЯНИЙ ЯЧЕЕК ОПЕРАТИВНОЙ ПАМЯТИ И УЧАСТКОВ
ПОВЕРХНОСТЕЙ НОСИТЕЛЕЙ ИНФОРМАЦИИ (ОДНО СОСТОЯНИЕ 0, ДРУГОЕ СОСТОЯНИЕ - 1).
7.
ФОРМУЛА ХАРТЛИВСЯ ИНФОРМАЦИЯ В КОМПЬЮТЕРЕ ХРАНИТСЯ В ДВОИЧНОМ КОДЕ. ПОЭТОМУ
НАДО НАУЧИТЬСЯ ПРЕОБРАЗОВЫВАТЬ СИМВОЛЫ В ДВОИЧНЫЙ КОД.
ФОРМУЛА ХАРТЛИ ОПРЕДЕЛЯЕТ КОЛИЧЕСТВО ИНФОРМАЦИИ В ЗАВИСИМОСТИ
ОТ КОЛИЧЕСТВА ВОЗМОЖНЫХ ВАРИАНТОВ:
N=2I, ГДЕ
N — ЭТО КОЛИЧЕСТВО ВАРИАНТОВ,
I — ЭТО КОЛИЧЕСТВО БИТ, НЕ ОБХОДИМЫХ ДЛЯ КОДИРОВАНИЯ.
8.
МОЩНОСТЬ АЛФАВИТАМОЩНОСТЬ АЛФАВИТА - КОЛИЧЕСТВО СИМВОЛОВ В
ИСПОЛЬЗУЕМОМ АЛФАВИТЕ
ЕСЛИ ПРЕОБРАЗУЕМ ЭТУ ФОРМУЛУ И ПРИМЕМ ЗА N МОЩНОСТЬ АЛФАВИТА, ТО МЫ ПОЙМЕМ, СКОЛЬКО
ПАМЯТИ ПОТРЕБУЕТСЯ ДЛЯ КОДИРОВАНИЯ ОДНОГО
СИМВОЛА.
9.
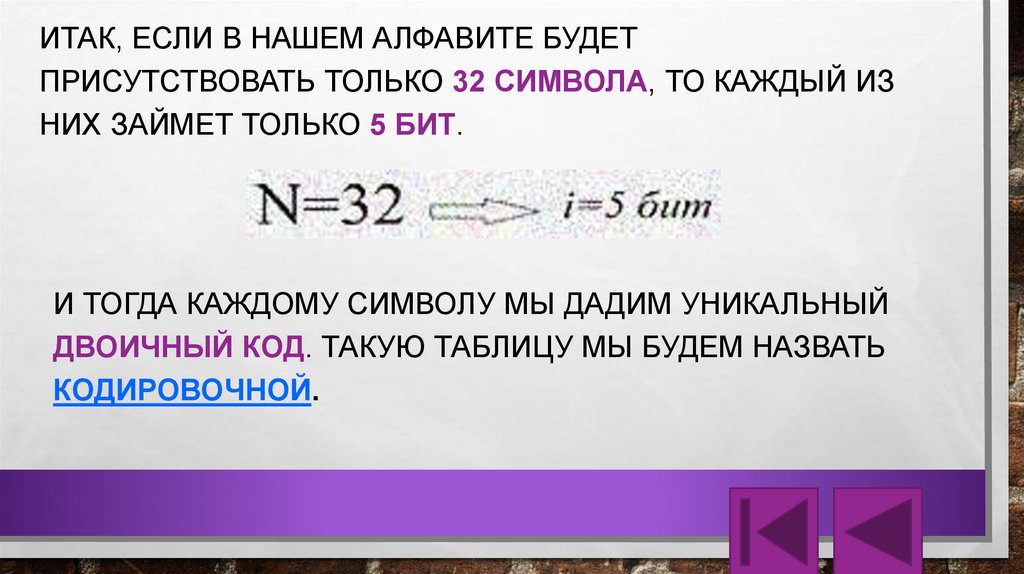
ИТАК, ЕСЛИ В НАШЕМ АЛФАВИТЕ БУДЕТПРИСУТСТВОВАТЬ ТОЛЬКО 32 СИМВОЛА, ТО КАЖДЫЙ ИЗ
НИХ ЗАЙМЕТ ТОЛЬКО 5 БИТ.
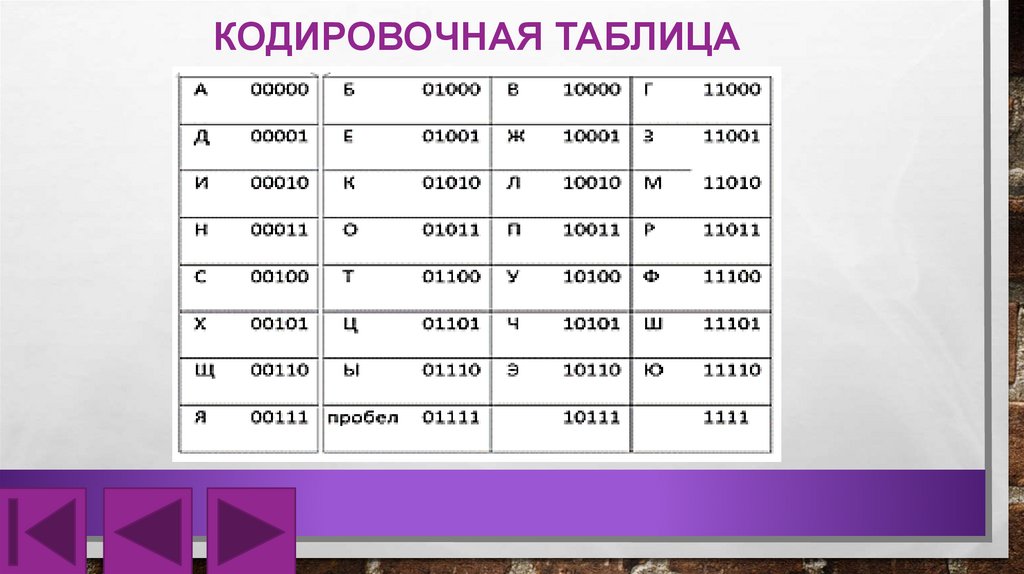
И ТОГДА КАЖДОМУ СИМВОЛУ МЫ ДАДИМ УНИКАЛЬНЫЙ
ДВОИЧНЫЙ КОД. ТАКУЮ ТАБЛИЦУ МЫ БУДЕМ НАЗВАТЬ
КОДИРОВОЧНОЙ.
10.
КОДИРОВОЧНАЯ ТАБЛИЦА11.
ASCIIПЕРВАЯ ШИРОКО ИСПОЛЬЗУЕМАЯ КОДИРОВОЧНАЯ
ТАБЛИЦА БЫЛА СОЗДАНА В США И НАЗЫВАЛАСЬ ASCII, ЧТО
В ПЕРЕВОДЕ ОЗНАЧАЛО AMERICAN STANDARD CODE FOR
INFORMATION INTERCHANGE. КАК ВЫ ВИДИТЕ, В ТАБЛИЦЕ
ПРИСУТСТВУЮТ НЕ ТОЛЬКО ЛАТИНСКИЕ БУКВЫ, НО И
ЦИФРЫ, И ДАЖЕ ДЕЙСТВИЯ. КАЖДОМУ СИМВОЛУ
ОТВОДИТСЯ 7 БИТ, А ЗНАЧИТ, ВСЕГО БЫЛО ЗАКОДИРОВАНО
128 СИМВОЛОВ
12.
13.
ЭТОГО КОЛИЧЕСТВА БЫЛО НЕДОСТАТОЧНО, СТАЛИСОЗДАВАТЬСЯ ДРУГИЕ ТАБЛИЦЫ, В КОТОРЫХ МОЖНО
БЫЛО ЗАКОДИРОВАТЬ И ДРУГИЕ СИМВОЛЫ.
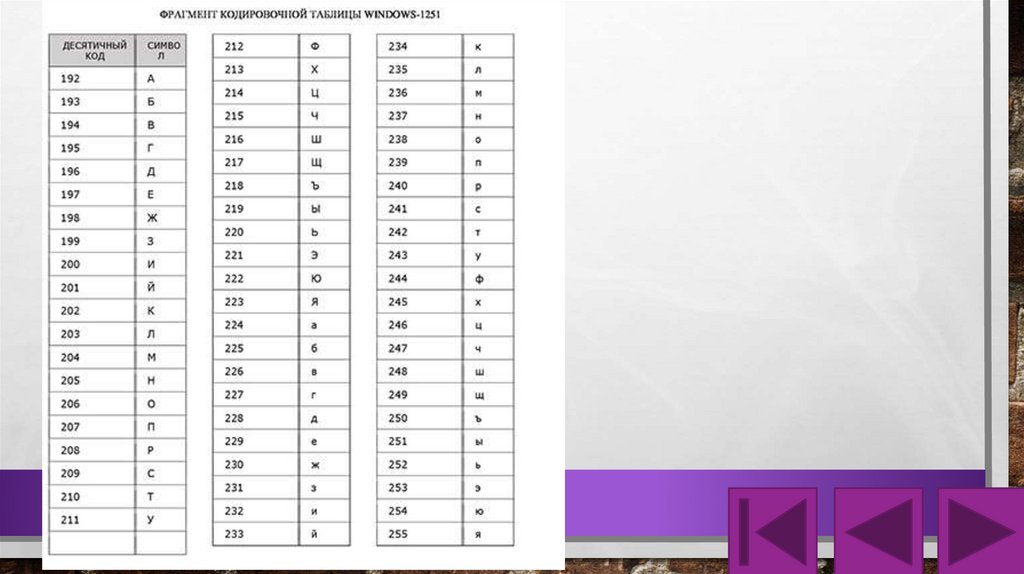
НАПРИМЕР, ТАБЛИЦА WINDOWS-1251, КОТОРАЯ,
ЯВЛЯЛАСЬ ИЗМЕНЕНИЕМ ТАБЛИЦЫ ASCII, В КОТОРУЮ
ДОБАВИЛИ БУКВЫ КИРИЛЛИЦЫ.
ТАКИХ ТАБЛИЦ БЫЛО СОЗДАНО МНОЖЕСТВО: MS-DOS,
КОИ-8, ISO, MAC И ДРУГИЕ
14.
15.
ПРОБЛЕМА ИСПОЛЬЗОВАНИЯ ТАКИХ РАЗЛИЧНЫХТАБЛИЦ ПРИВОДИЛА К ТОМУ, ЧТО ТЕКСТ, НАПИСАННЫЙ
НА ОДНОМ КОМПЬЮТЕРЕ, МОГ НЕКОРРЕКТНО
ЧИТАТЬСЯ НА ДРУГОМ. НАПРИМЕР:
16.
РАВНОМЕРНЫЙ КОДВСЕ ЕГО КОДОВЫЕ СЛОВА СОДЕРЖАТ ОДИНАКОВОЕ ЧИСЛО БУКВ
(ОДИНАКОВУЮ ДЛИНУ СЛОВ).
КОДИРОВАНИЕ НАЗЫВАЕТСЯ РАВНОМЕРНЫМ, ЕСЛИ
СООТВЕТСТВУЮЩИЙ ЕМУ КОД ИМЕЕТ ПОСТОЯННУЮ ДЛИНУ.
В НАСТОЯЩЕЕ ВРЕМЯ В ИНФОРМАТИКЕ БОЛЕЕ УПОТРЕБИТЕЛЬНО
РАВНОМЕРНОЕ КОДИРОВАНИЕ.
В КОМПЬЮТЕРАХ ПРИ КОДИРОВАНИИ ИНФОРМАЦИИ В ОСНОВНОМ
ИСПОЛЬЗУЮТСЯ РАВНОМЕРНЫЕ КОДЫ, СООТВЕТСТВУЮЩИЕ
РАЗМЕРАМ КОМПЬЮТЕРНЫХ ЯЧЕЕК.
17.
КОД ТРИСИМЕЗНАКАМ ЛАТИНСКОГО АЛФАВИТА СТАВЯТСЯ В СООТВЕТСТВИЕ
КОДОВЫЕ СЛОВА ДЛИНЫ 3 НАД АЛФАВИТОМ ИЗ 3-Х СИМВОЛОВ: {1, 2, 3}.
НЕ МОЖЕТ КОДИРОВАТЬ БОЛЕЕ ЧЕМ 33=27 СИМВОЛОВ.
Число букв в алфавите
кода называется
основанием кода, а
длина кодовых слов
равномерного кода
называется порядком
кода.
18.
НЕРАВНОМЕРНЫЙ КОДЕГО КОДОВЫЕ СЛОВА ИМЕЮТ РАЗНОЕ ЧИСЛО БУКВ (НЕОДИНАКОВУЮ ДЛИНУ СЛОВ).
КОДИРОВАНИЕ НАЗЫВАЕТСЯ НЕРАВНОМЕРНЫМ, ЕСЛИ СООТВЕТСТВУЮЩИЙ ЕМУ КОД
НЕРАВНОМЕРНЫЙ.
ТИПИЧНЫМ ПРИМЕРОМ НЕРАВНОМЕРНОГО КОДА ЯВЛЯЕТСЯ ТЕЛЕГРАФНЫЙ КОД, КОТОРЫЙ
ПРИНЯТО НАЗЫВАТЬ АЗБУКОЙ МОРЗЕ.
19.
ПРЕИМУЩЕСТВО НЕРАВНОМЕРНЫХ КОДОВСООБЩЕНИЯ МОЖНО ПЕРЕДАВАТЬ БОЛЕЕ ЭКОНОМНЫМ
СПОСОБОМ, ТАК КАК ЧАСТО ПЕРЕДАВАЕМЫЕ КОДОВЫЕ СЛОВА
БОЛЕЕ КОРОТКИЕ, А ЗНАЧИТ, КОДОВАЯ ПОСЛЕДОВАТЕЛЬНОСТЬ
МОЖЕТ ИМЕТЬ МЕНЬШУЮ ДЛИНУ, ЧЕМ ДЛЯ РАВНОМЕРНЫХ
КОДОВ.
НЕДОСТАТОК НЕРАВНОМЕРНЫХ КОДОВ
У РАВНОМЕРНЫХ КОДОВ КОДОВАЯ ПОСЛЕДОВАТЕЛЬНОСТЬ
ЛЕГКО ДЕЛИТСЯ НА КОДОВЫЕ СЛОВА. НО НЕ ДЛЯ ВСЕХ
НЕРАВНОМЕРНЫХ КОДОВ ДОСТИГАЕТСЯ ОДНОЗНАЧНОСТЬ
ДЕКОДИРОВАНИЯ КОДОВЫХ ПОСЛЕДОВАТЕЛЬНОСТЕЙ.
20.
УСЛОВИЕ ФАНОНИКАКОЕ КОДОВОЕ СЛОВО НЕ ЯВЛЯЕТСЯ НАЧАЛОМ
ДРУГОГО КОДОВОГО СЛОВА.
ЕСЛИ ЭТО УСЛОВИЕ ВЫПОЛНЕНО, ТО НИКАКИХ
ПРОБЛЕМ С ДЕКОДИРОВАНИЕМ НЕ БУДЕТ.
КОДЫ, УДОВЛЕТВОРЯЮЩИЕ УСЛОВИЮ ФАНО,
НАЗЫВАЮТСЯ ПРЕФИКСНЫМИ. ЕСЛИ КОД ПРЕФИКСНЫЙ,
ОН ДОПУСКАЕТ ОДНОЗНАЧНОЕ ДЕКОДИРОВАНИЕ.
21.
КОД, СОСТОЯЩИЙ ИЗ КОДОВЫХ СЛОВ {0, 10, 11}, ЯВЛЯЕТСЯПРЕФИКСНЫМ, И СЛЕДУЮЩУЮ КОДОВУЮ ПОСЛЕДОВАТЕЛЬНОСТЬ
01001101110 МОЖНО РАЗБИТЬ НА КОДОВЫЕ СЛОВА ЕДИНСТВЕННЫМ
ОБРАЗОМ: 0 10 0 11 0 11 10.
КОД, СОСТОЯЩИЙ ИЗ КОДОВЫХ СЛОВ {0, 10, 11, 100}, ПРЕФИКСНЫМ НЕ
ЯВЛЯЕТСЯ И ОН НЕ ДОПУСКАЕТ ОДНОЗНАЧНОГО ДЕКОДИРОВАНИЯ.
ДЕЙСТВИТЕЛЬНО, ТУ ЖЕ САМУЮ ПОСЛЕДОВАТЕЛЬНОСТЬ МОЖНО
РАЗБИТЬ НА КОДОВЫЕ СЛОВА РАЗНЫМИ СПОСОБАМИ: 0 10 0 11 0 11 10
ИЛИ 0 100 11 0 11 10.
КОД НАЗЫВАЕТСЯ ОДНОЗНАЧНО ДЕКОДИРУЕМЫМ, ЕСЛИ ЛЮБОЕ
КОДОВОЕ СООБЩЕНИЕ МОЖНО РАСШИФРОВАТЬ ЕДИНСТВЕННЫМ
СПОСОБОМ (ОДНОЗНАЧНО).
22.
ЗАДАЧАРАССМОТРИМ КОД:
Д О
Б
Р
Е
10 00 1011 001 0101
У
Т
1000
0111
Пробел
ОН НЕ ЯВЛЯЕТСЯ ПРЕФИКСНЫМ, Т.К. КОД БУКВЫ Д (10)
СОВПАДАЕТ С НАЧАЛОМ КОДА БУКВЫ Б (1011), У(1000) И
КОД БУКВЫ О(00) СОВПАДАЕТ С НАЧАЛОМ КОДА БУКВЫ Р
(001).
1111
23.
Д ОБ
Р
Е
10 00 1011 001 0101
У
Т
1000
0111
Пробел
1111
ЗАКОДИРУЕМ НАШЕ СООБЩЕНИЕ:
ДОБРОЕ УТРО→ 10 00 1011 001 00 0101 1111 1000 0111 001 00
НАЧНЁМ РАСКОДИРОВАТЬ С НАЧАЛА. ПЕРВАЯ – Д, ИЛИ У, А ДАЛЬШЕ ИДУТ
ВООБЩЕ РАЗНЫЕ ВАРИАНТЫ: Р ИЛИ Б… Т.Е. НАДО «ЗАГЛЯДЫВАТЬ» ВПЕРЁД,
ЧТО ОЧЕНЬ НЕУДОБНО.
ПОПРОБУЕМ РАСКОДИРОВАТЬ СООБЩЕНИЕ С КОНЦА – ОНО ОДНОЗНАЧНО
ДЕКОДИРУЕТСЯ! ВЫПОЛНЯЕТСЯ ОБРАТНОЕ УСЛОВИЕ ФАНО: НИКАКОЕ
КОДОВОЕ СЛОВО НЕ СОВПАДАЕТ С ОКОНЧАНИЕМ ДРУГОГО КОДОВОГО
СЛОВА.
24.
КОДЫ, ДЛЯ КОТОРЫХ ВЫПОЛНЯЕТСЯ ОБРАТНОЕ УСЛОВИЕ ФАНО,НАЗЫВАЮТСЯ ПОСТФИКСНЫМИ.
СООБЩЕНИЕ ДЕКОДИРУЕТСЯ ОДНОЗНАЧНО, ЕСЛИ ДЛЯ ИСПОЛЬЗУЕМОГО
КОДА ВЫПОЛНЯЕТСЯ ПРЯМОЕ ИЛИ ОБРАТНОЕ УСЛОВИЕ ФАНО.
УСЛОВИЕ ФАНО - ЭТО ДОСТАТОЧНОЕ, НО НЕ НЕОБХОДИМОЕ УСЛОВИЕ
ОДНОЗНАЧНОЙ ДЕКОДИРУЕМОСТИ:
- ДЛЯ ОДНОЗНАЧНОЙ ДЕКОДИРУЕМОСТИ ДОСТАТОЧНО ВЫПОЛНЕНИЯ ХОТЯ
БЫ ОДНОГО ИЗ ДВУХ УСЛОВИЙ - ПРЯМОГО ИЛИ ОБРАТНОГО.
- МОГУТ СУЩЕСТВОВАТЬ КОДЫ, ДЛЯ КОТОРЫХ НЕ ВЫПОЛНЯЕТСЯ НИ ПРЯМОЕ,
НИ ОБРАТНОЕ УСЛОВИЕ ФАНО, НО ТЕМ НЕ МЕНЕЕ ОБЕСПЕЧИВАЕТСЯ
ОДНОЗНАЧНОЕ ДЕКОДИРОВАНИЕ, Т.К. ИНАЧЕ ТЕРЯЕТСЯ СМЫСЛ ВЫРАЖЕНИЯ.