











 software
softwareSimilar presentations:





")




Структурные элементы Hadoop
1.
Структурные элементы Hadoopянварь 2014г.
2.
Структурные элементы Hadoop• В сконфигурированном кластере под «запуском Hadoop»
подразумевается запуск набора демонов (фоновых процесов),
или резидентных программ на различных сетевых серверах.
• Каждый из демонов выполняет свою задачу; некоторые
запускаются только на одном сервере, другие – на нескольких.
Существуют следующие демоны:
NameNode
DataNode
Secondary NameNode
JobTracker
TaskTracker
3.
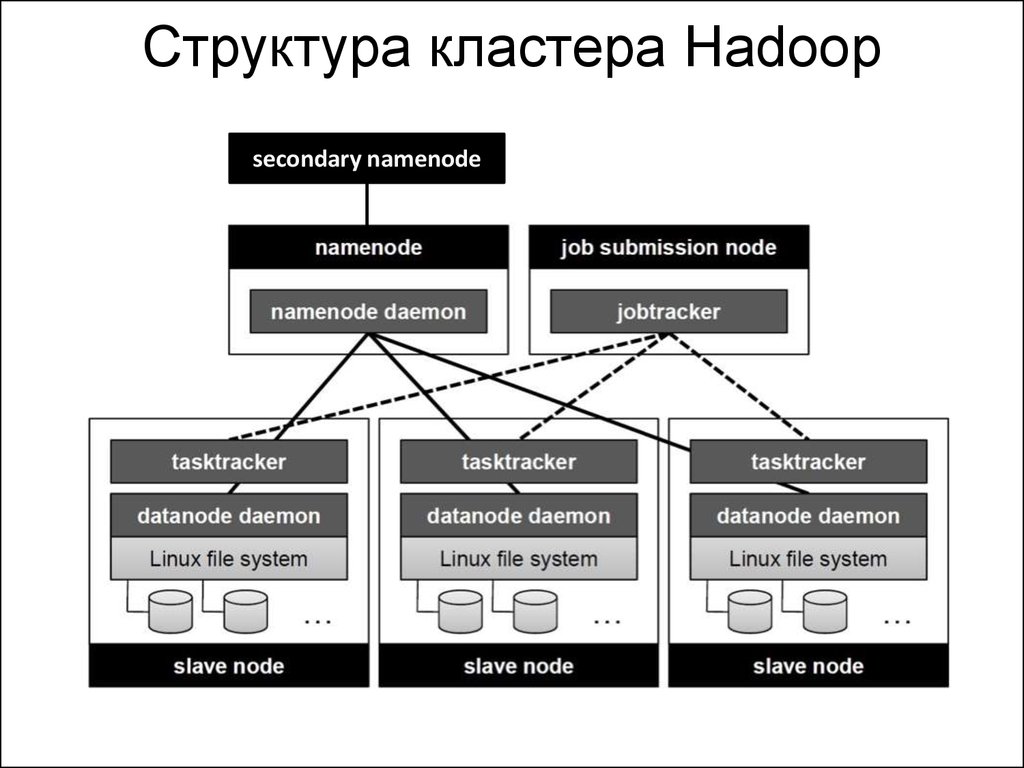
NameNode• Самый важный демон Hadoop – NameNode.
В Hadoop существует архитектура главный/подчиненный как для
хранения данных, так и для распределенных вычислений.
Распределенная система хранения данных называется HDFS –
Hadoop Distributed File System.
NameNode – это диспетчер HDFS. Он ведет учет разбиению
файлов на блоки, хранит информацию о том, на каких узлах эти
блоки находятся, и следит за общим состоянием файловой
системы.
Сервер NameNode не дублируется, как DataNode или TaskTracker.
4.
DataNode• На любой подчиненной машине кластера работает DataNode.
DataNode считывает и записывает блоки HDFS в физические
файлы, находящиеся в локальной файловой системе.
DataNode может взаимодействовать с такими же демонами для
осуществления дублирования блоков данных для обеспечения
резервирования.
Демоны
DataNode
взаимодействуют
с
NameNode,
при
инициализации сообщая ему о блоках данных, которые хранятся
на нем в настоящий момент, а далее передавая информацию о
локальных изменениях и получая инструкции о создании,
перемещении и удалении блоков с локального диска.
5.
Secondary NameNode• Secondary NameNode – это вспомогательный демон, который
занимается мониторингом состояния кластера HDFS.
В отличие от NameNode, он не протоколирует информацию об
изменениях в HDFS в режиме реального времени.
Он взаимодействует с NameNode для создания мгновенных
снимков метаданных HDFS.
В кластере Hadoop может быть только один Secondary NameNode.
6.
JobTracker• JobTracker – это посрединк между Hadoop и приложением.
JobTracker строит план выполнения вашего кода, то есть
определяет, какие файлы необходимо обрабатывать, назначает
узлы различным задачам и следит за ходом исполнения этих
задач.
В кластере Hadoop может быть только один JobTracker.
7.
TaskTracker• JobTracker – это главный демон, организующий общее
выполнение задачи MapReduce, а демоны TaskTracker
управляют исполнением отдельных заданий на подчиненных
узлах.
Одна из обязанностей TaskTracker – периодически докладывать о
себе демону JobTracker.
8.
Структура кластера Hadoopsecondary namenode
9. Реквизиты кластера
Сервера и роли:bds01.vdi.mipt.ru - сервер для разработки, имеет доступ к кластеру
bds02.vdi.mipt.ru - namenode + jobtracker кластера
bds03 - bds11.vdi.mipt.ru - ноды кластера (datanode + tasktracker)
ssh доступ на bds01:
внутренняя сеть: LOGIN@bds01.vdi.mipt.ru порт 22
снаружи:
LOGIN@remote.vdi.mipt.ru порт 51798
LOGIN = s<GROUP><NUMBER>
GROUP - номер вашей группы, от 291 до 299
NUMBER - двузначное число от 01 до 30, ваш номер в группе
Например: s29605
Пароль: writtenoncetormoziteverywhere
Для смены пароля, команда passwd
10. Web-интерфейс Hadoop
NameNode:- из внутренней сети: http://bds02.vdi.mipt.ru:50070
- снаружи:
http://remote.vdi.mipt.ru:61070
JobTracker:
- из внутренней сети: http://bds02.vdi.mipt.ru:50030
- снаружи:
http://remote.vdi.mipt.ru:61030
11. Команды HDFS
Еще раз, HDFS (Hadoop Distributed File System) – файловаясистема, предназначенная для обработки больших объемов
распределенных данных с помощью таких технологий, как
MapReduce.
По умолчанию рабочим каталогом HDFS является
/user/имя_текущего_пользователя
Команда Hadoop для работы с файлами имеет вид:
hadoop fs -cmd <args>,
где cmd – имя команды, <args> – аргументы команды.
hadoop fs -ls - посмотреть файлы в текущем каталоге
hadoop fs -mkdir имя_каталога – создать новый каталог
hadoop fs -rmdir имя_каталога - удалить каталог
hadoop fs -rm имя_файла - удалить файл
12. Команды HDFS
Имея рабочий каталог в Hadoop, мы можем поместить в него файлhadoop fs –put myfile /user/имя_текущего_пользователя
Для копирования файлов из рабочей директории системы HDFS в
локальную файловую систему служит команда get:
hadoop fs –get /user/имя_текущего_пользователя/myfile myfile
Справка по конкретной программе:
hadoop fs -help ls
13. Запуск java задачи Hadoop
Установить JAVA_HOME:- добавить в ~/.profile строчку:
JAVA_HOME=/usr/lib/jvm/java-7-oracle-cloudera
Компиляция:
javac -cp /usr/lib/hadoop/hadoop-common.jar:/usr/lib/hadoop-mapreduce/hadoopmapreduce-client-core.jar -d build src/WordCount.java (build и src – директории!)
и сборка jar
jar cf wc.jar -C build org (для файла-примера WordCount.java org = ru)
Запуск:
hadoop jar wc.jar
/user/login/dir_out
org.myorg.WordCount /user/login/sample_in
(для файла-примера WordCount.java org = ru, myorg = jiht)