













 software
softwareSimilar presentations:





")




MapReduce. HDFS. Повторение
1.
MapReduceИвченко Олег, 2023 г.
2.
HDFS. ПовторениеБольшие файлы, разделены на блоки
• Хранит блоки на множестве серверов (datanode)
• Устойчива к отказам datanode (репликация)
• “Write once, read many”
– последовательные чтение и запись
– не изменяем данные, создаем новые
2
3.
MapReduce2004 г. - статья Google, появление
MapReduce.
3
4.
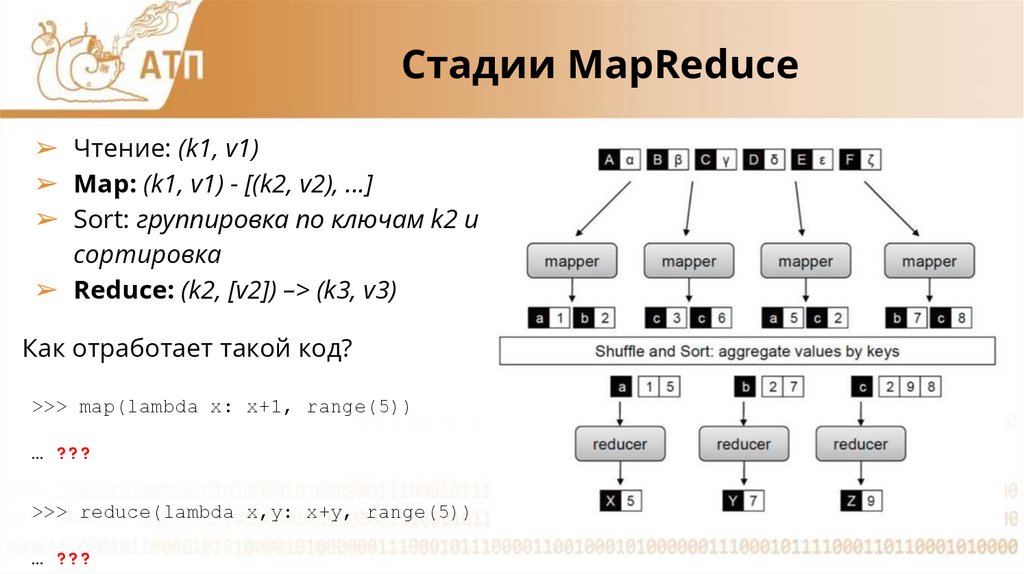
Стадии MapReduce➢ Чтение: (k1, v1)
➢ Map: (k1, v1) - [(k2, v2), ...]
➢ Sort: группировка по ключам k2 и
сортировка
➢ Reduce: (k2, [v2]) –> (k3, v3)
Как отработает такой код?
>>> map(lambda x: x+1, range(5))
… ???
>>> reduce(lambda x,y: x+y, range(5))
… ???
4
5.
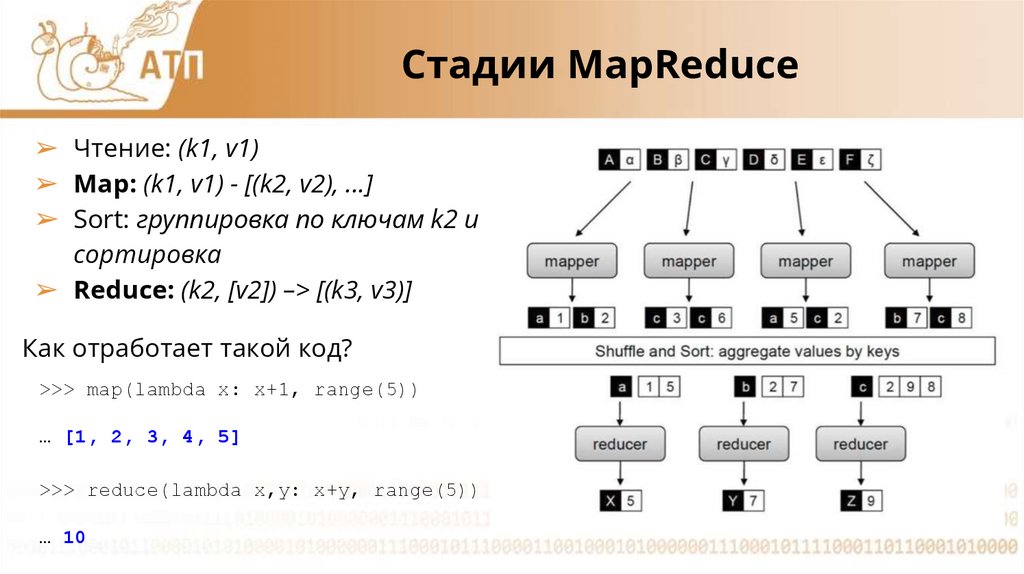
Стадии MapReduce➢ Чтение: (k1, v1)
➢ Map: (k1, v1) - [(k2, v2), ...]
➢ Sort: группировка по ключам k2 и
сортировка
➢ Reduce: (k2, [v2]) –> [(k3, v3)]
Как отработает такой код?
>>> map(lambda x: x+1, range(5))
… [1, 2, 3, 4, 5]
>>> reduce(lambda x,y: x+y, range(5))
… 10
5
6.
MapReduce. Пример #1➢ Подсчёт частоты встречаемости слов в тексте.
Входные данные: текст.
I like football but I don't like chess
➢ Mapper: ?
➢ Sort: ?
➢ Reduce: ?
6
7.
MapReduce. Пример #1➢ Подсчёт частоты встречаемости слов в тексте.
Входные данные: текст.
I like football but I don't like chess
➢ Mapper: (I, 1), (like, 1), … (I, 1),…
➢ Sort: (I, [1, 1]), (like, [1, 1])…
➢ Reduce: (I, 2), (like, 2)…
7
8.
MapReduce. Пример #2Задача на подсчёт частоты слов.
Текст: Дж. Р.Р. Толкиен “Сильмариллион”
Mapper
import sys
import re
for line in sys.stdin:
words = line.strip().split()
for word in words:
print("{}\t{}".format(word, 1))
8
9.
MapReduce. Пример #2import sys
Reducer
current_key = None
word_sum = 0
for line in sys.stdin:
try:
key, count = line.strip().split('\t', 1)
count = int(count)
except ValueError as e:
continue
if current_key != key:
if current_key:
print("{}\t{}".format(current_key,
word_sum))
word_sum = 0
current_key = key
word_sum += count
if current_key:
print("{}\t{}".format(current_key, word_sum))
setup()
reduce() / map()
9
cleanup()
10.
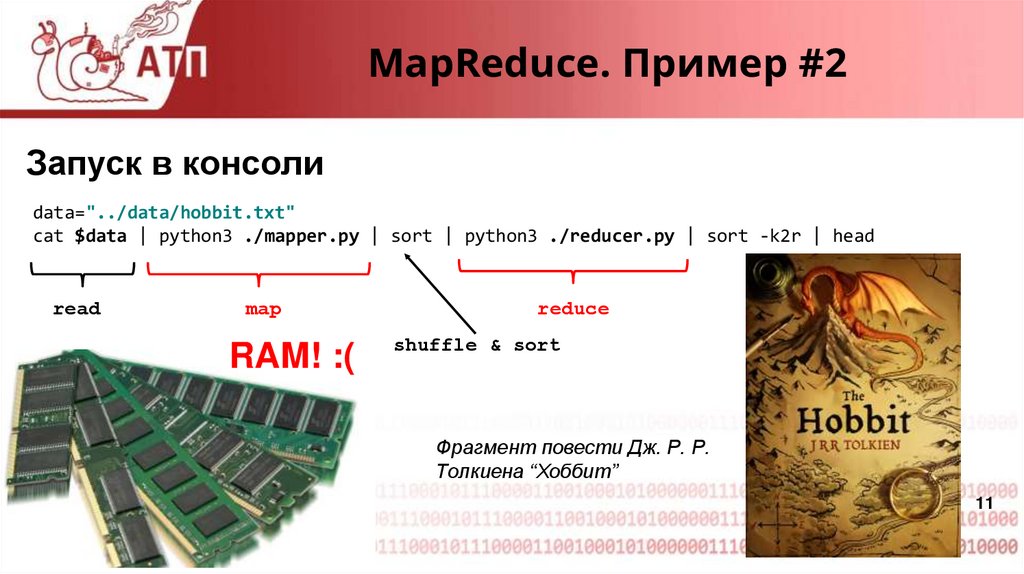
MapReduce. Пример #2Запуск в консоли
data="../data/hobbit.txt"
cat $data | python3 ./mapper.py | sort | python3 ./reducer.py | sort -k2r | head
read
map
reduce
shuffle & sort
Фрагмент повести Дж. Р. Р.
Толкиена “Хоббит”
10
11.
MapReduce. Пример #2Запуск в консоли
data="../data/hobbit.txt"
cat $data | python3 ./mapper.py | sort | python3 ./reducer.py | sort -k2r | head
read
map
RAM! :(
reduce
shuffle & sort
Фрагмент повести Дж. Р. Р.
Толкиена “Хоббит”
11
12.
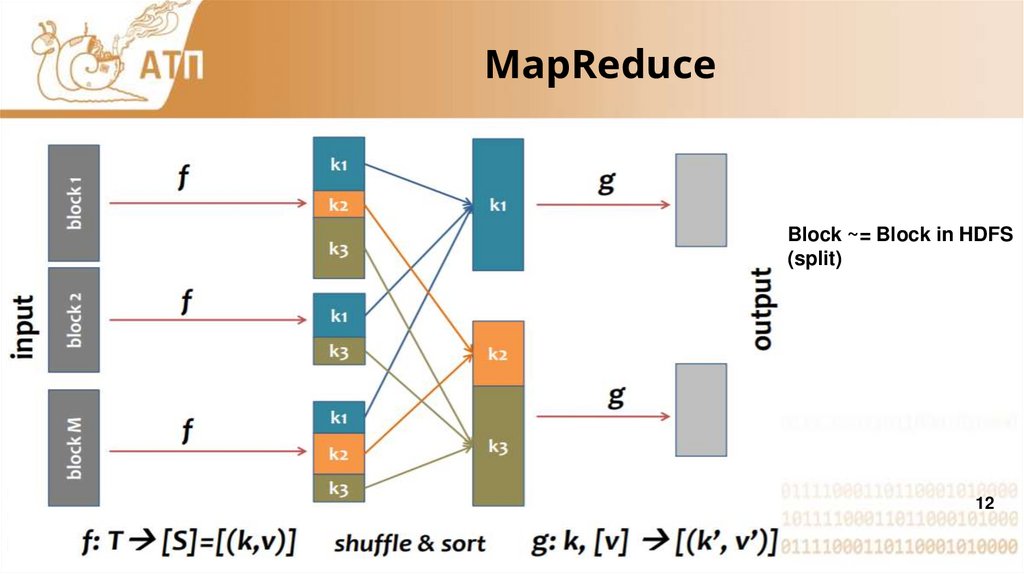
MapReduceBlock ~= Block in HDFS
(split)
12
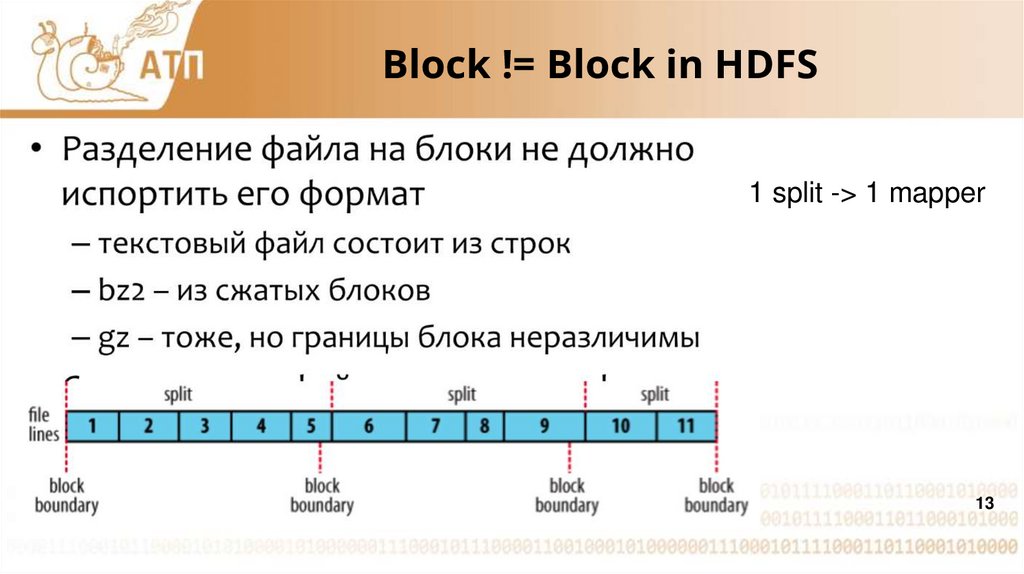
13.
Block != Block in HDFS1 split -> 1 mapper
13
14.
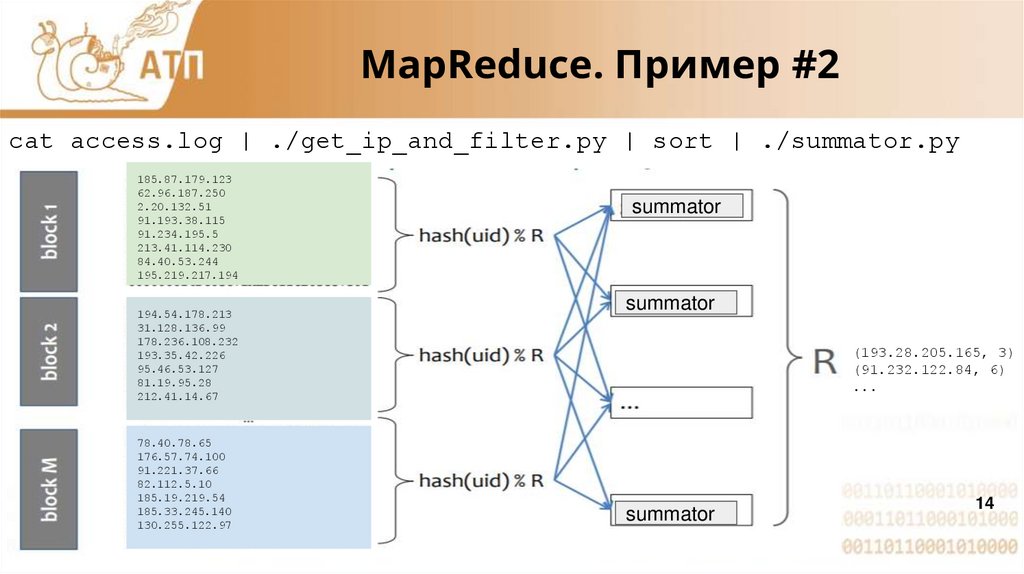
MapReduce. Пример #2cat access.log | ./get_ip_and_filter.py | sort | ./summator.py
185.87.179.123
62.96.187.250
2.20.132.51
91.193.38.115
91.234.195.5
213.41.114.230
84.40.53.244
195.219.217.194
194.54.178.213
31.128.136.99
178.236.108.232
193.35.42.226
95.46.53.127
81.19.95.28
212.41.14.67
78.40.78.65
176.57.74.100
91.221.37.66
82.112.5.10
185.19.219.54
185.33.245.140
130.255.122.97
summator
summator
(193.28.205.165, 3)
(91.232.122.84, 6)
...
summator
14
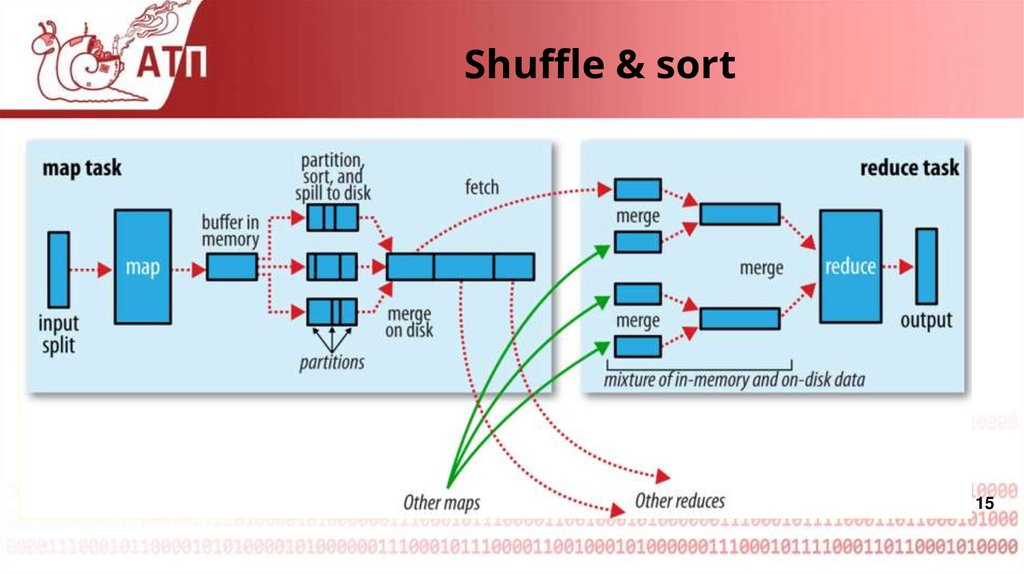
15.
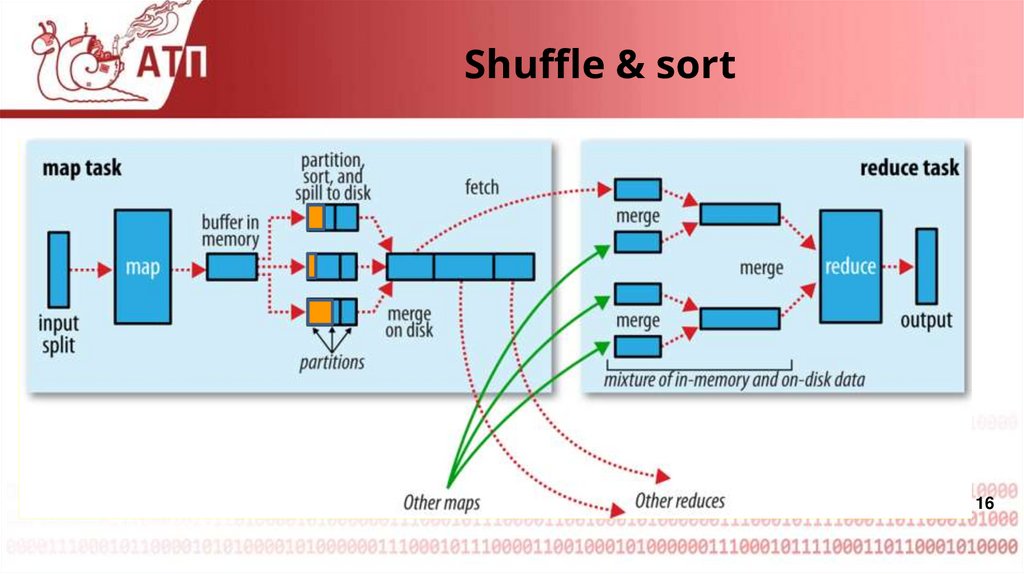
Shuffle & sort15
16.
Shuffle & sort16
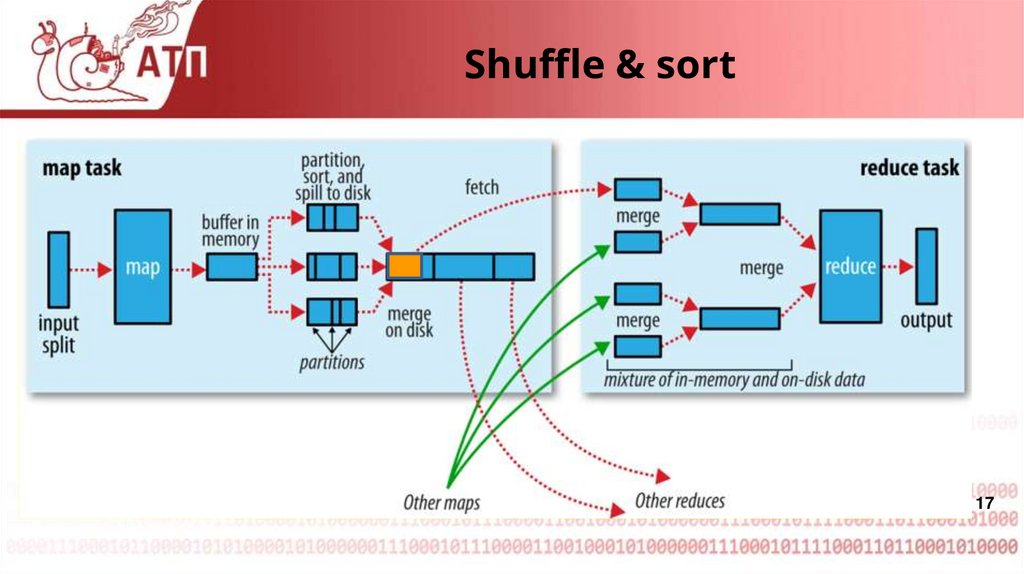
17.
Shuffle & sort17
18.
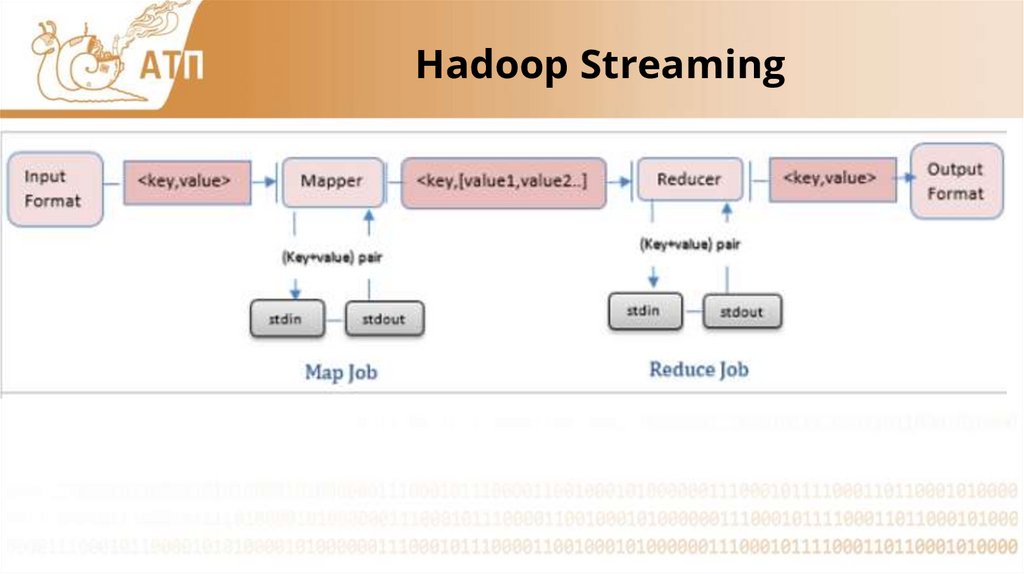
Hadoop Streaming19.
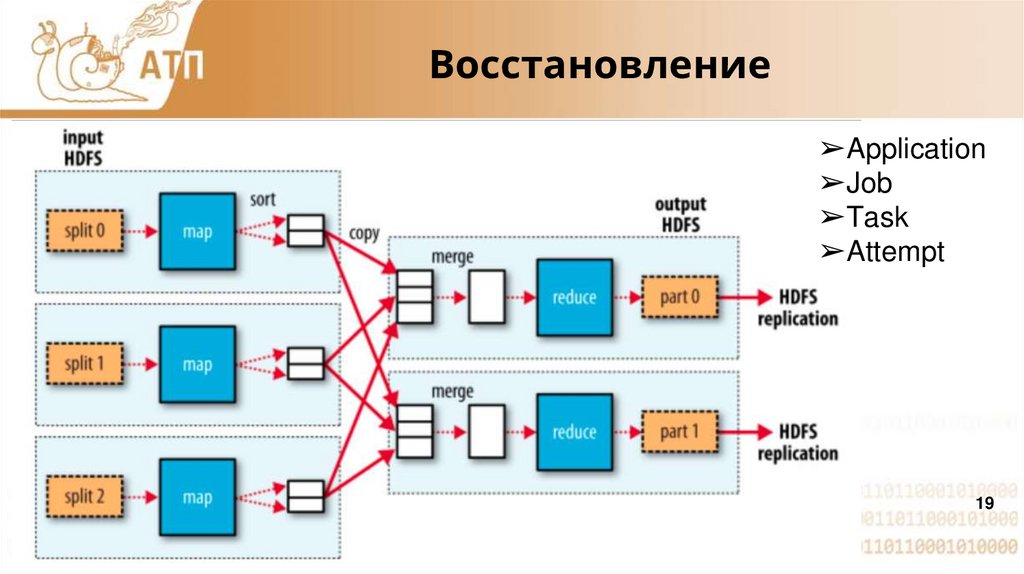
Восстановление➢Application
➢Job
➢Task
➢Attempt
19
20.
WordCount in HadoopЗапуск задачи в Hadoop Streaming
yarn jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-streaming.jar \ # подключаем
jar-файл с инструментами Hadoop Streaming
-D mapreduce.job.name="my_wordcout_example" \ # назовите свою задачу
-D mapreduce.job.reduces=${NUM_REDUCERS} \ # устанавливаем кол-во reducer'ов в задаче
-files mapper.py,reducer.py \ # добавляем файлы в distributed cache чтоб каждая нода имела к
ним доступ
-mapper "python3 ./mapper.py" \
-reducer "python3 ./reducer.py" \
-input /data/silmarillion \ # входны и выходные данные
-output $OUT_DIR # относительный путь
Исходник:
➢ /home/velkerr/sber-hadoop2023-1/materials/02mapreduce/00-wordcount-lecture
Как скопировать файл в Linux в текущую папку: cp -r <source> ./
21.
MapReduce. Основные особенности➢ Работаем с парами ключ-значение
➢ Map: поэлементная параллельная обработка входных данных
➢ Shuffle & sort:
○ группируем данные согласно ключам,
○ сортируем по ключам
➢ Reduce: обрабатываем каждый набор ключей независимо
○ множества ключей, кот. встретились на 1 редьюсере, не
встретятся на других.
21
22.
MapReduce➢ Mapper:
○ Работает с одной записью, преобразует ее
○ Обычно: фильтр , парсер, форматирование
○ На выходе: от 0 до нескольких пар (k, v)
➢ Reducer:
○ Получает на вход N записей с одним и тем же ключом
○ Обычно: агрегация записей, например sum, avg, max
○ На выходе: от 0 до нескольких пар (k, v)
23.
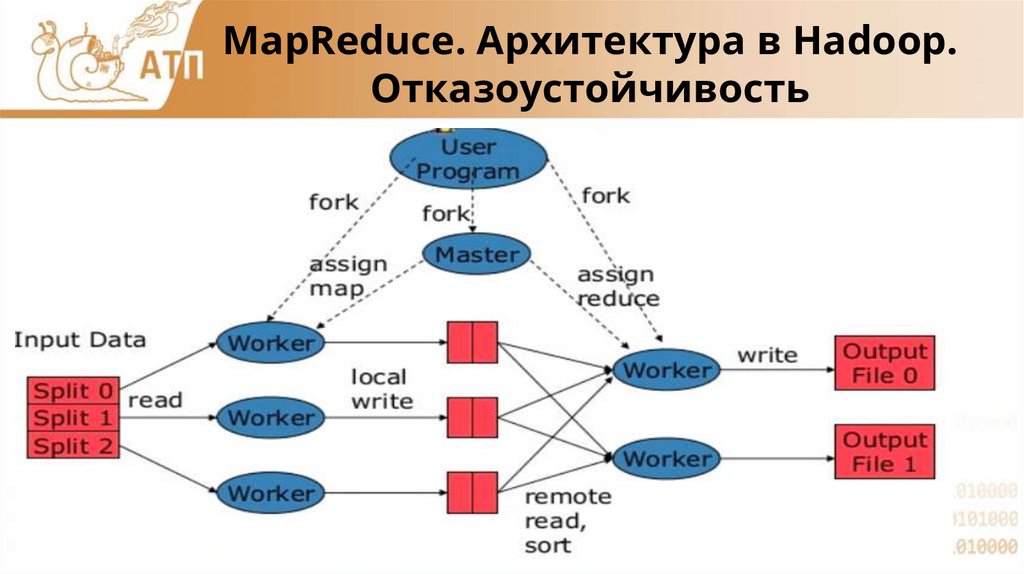
MapReduce. Архитектура в Hadoop.Отказоустойчивость
24.
Hadoop StreamingMapper и reducer – программы, команды или Java-класс
• Читают из stdin, пишут в stdout
• Sort & shuffle обеспечивает hadoop
• Reducer вызывается один на одну reduceзадачу
25.
MapReduce в подробностяхMapReduce в подробностях:
https://i1.wp.com/0x0fff.com/wp-content/uploads/2014/12/MapReducev3.png
25
26.
Недостатки➢ Только пакетная обработка
○ не подходит для realtime задач
➢ Активное использование дисков (пишем мин. 2 раза за job’у) и сети
➢ Надо писать много кода
27.
Вопросы?Tutorial по Hadoop Streaming от Michael Noll: https://www.michaelnoll.com/tutorials/writing-an-hadoop-mapreduce-program-in-python/