










 education
educationSimilar presentations:





(1)")




Powerpoint - Copy
1.
دانشگاه آزاداسالمی
واحد الهیجان
بهبود عملکرد سیستمهای توصیهگر با استفاده از
الگوریتم کا-نزدیکترین همسایه
ارائه کننده :میثم سعیدی فرید
استاد راهنما :دکتر عبدالرضا رضاپور
داوران:
2.
فهرست مطالبمقدمه
نتیجه
گیری و
پیشنهاد
ات
اهداف
ارزیابی
چالش ها
طرح
پیشنهاد
ی
پیشینه
پژوهش
مقایسه
سیستم ها
بهبود عملکرد سیستمهای توصیهگر با استفاده از الگوریتم کا-نزدیکترین همسایه
29
3.
مقدمه oمقدمه:
• بهینه سازی دقت توصیه ها و زمان پاسخ جهت سنجیدن یک
سیستم توصیه گر بهینه
oپیشینه پژوهش:
• ارائه ی روشهای یادگیری ماشین ،متنکاوی ،فیلترینگ
مبتنی بر محتوا ،فیلترینگ مشارکتی ،الگوریتم های
مبتنی بر شباهت اطالعات و کاربر جهت توصیه ی هوشمند
مقاالت
oروش پژوهش:
• ارائه ی یک روش جهت بهینهسازی بردار جستجو در
سیستمهای توصیهگر
• بهبود کیفی نتایج بازیابی توسط سنجش معیار امتیاز
سیستمتوصیهگر با استفاده از الگوریتم کا-نزدیکترین همسایه
توصیهیسیستمهای
بهبود عملکرد
29
4.
بیان مساله oضرورت پژوهش
• نیاز سیستمهای توصیه گر در مورد
برای دسترس پذیری بهتر مقاالت علمی
مقاله
دانشگاهی
oرویکرد پژوهش
• استفاده الگوریتمهای یادگیری ماشین در سیستمهای
توصیه گر و توسعه ی آن
• عملکرد بهتر در یافتن مقاالت مشابه جهت اتخاذ
تصمیمات بهتر
oنوآوری پژوهش
• تعیین فاصله ی مستندات با سیستم وزن دهی پیشنهادی
• ارائه ی یک روش ترکیبی با ادغام روش های فیلترینگ
مشارکتی و تحلیل محتوا
بهبود عملکرد سیستمهای توصیهگر با استفاده از الگوریتم کا-نزدیکترین همسایه
29
5.
اهداف oشناسایی روند بکارگیری الگوریتمهای یادگیری ماشین
در سیستمهای توصیه گر
oارائه
راهکاری
بهینه
برای
افزایش
دقت
توصیهگر در یافتن مستندات با استفاده از
oکمک
به
محققان
جدید
برای
قرارگیری
سیستمهای
K-NN
در
موقعیت
تحقیقاتی جدید با پیشنهاد مقاالت مرتبط
انبوهکا-مقاالت
پردازش
عملیاتبادر
خودکارسازی
o
نزدیکترین همسایه
الگوریتم
استفاده از
های توصیهگر
بهبود عملکرد سیستم
29
6.
چالش ها کمبود اطالعات
آسیب پذیری در برابر حمالت
مقیاس پذیری
ارزش زمان
شروع سرد
ارزیابی توصیه گرها
تنوع و دقت
واسط کاربری
بهبود عملکرد سیستمهای توصیهگر با استفاده از الگوریتم کا-نزدیکترین همسایه
29
7.
سیستم های توصیهگر oتوصیه ی موارد به کاربران با استفاده از روش های هوش
مصنوعی
oبررسی فعالیتهای گذشته کاربران به عنوان بخش مهمی از
داده ها
oسه گروه اصلی سیستمهای توصیهگر:
• فیلترینگ مشارکتی :عبارت است از در نظر گرفتن داده
های کاربر هنگام پردازش اطالعات برای توصیه
• فیلترینگ مبتنی بر محتوا :یعنی پایه گذاری توصیه
های RSها بر روی داده های در دسترس از کاربر
• فیلترینگ ترکیبی :یعنی ترکیب دو دسته ی مشارکتی و
مبتنی بر محتوا
بهبود عملکرد سیستمهای توصیهگر با استفاده از الگوریتم کا-نزدیکترین همسایه
29
8.
مقایسه سیستم های پیشیننویسندگان
سال
دیتاست
هورتادوو
همکاران
2019
و
SD4AI
Movielens
مزایا
روش
خوشه بندی فازی
Meansبرای تقسیم
اطالعات مشابه
C-
بهبود دقت
فیلترهای مشترک
سون و
همکاران
2018
داده های
گوگل
اسکوالر
شبکه های استنادی
چند سطحی
اثبات نظری روش
با مدل های ریاضی
اورتگا و
همکاران
2018
SD4AI
روش فاکتورسازی
ماتریس احتمالی
تعیین
کاردینالیتی هر
مقاله بر اساس
موضوع
مقایسه ی برخی از پژوهش های پیشین در زمینه سیستم
های توصیه گر مقاله
بهبود عملکرد سیستمهای توصیهگر با استفاده از الگوریتم کا-نزدیکترین همسایه
29
9.
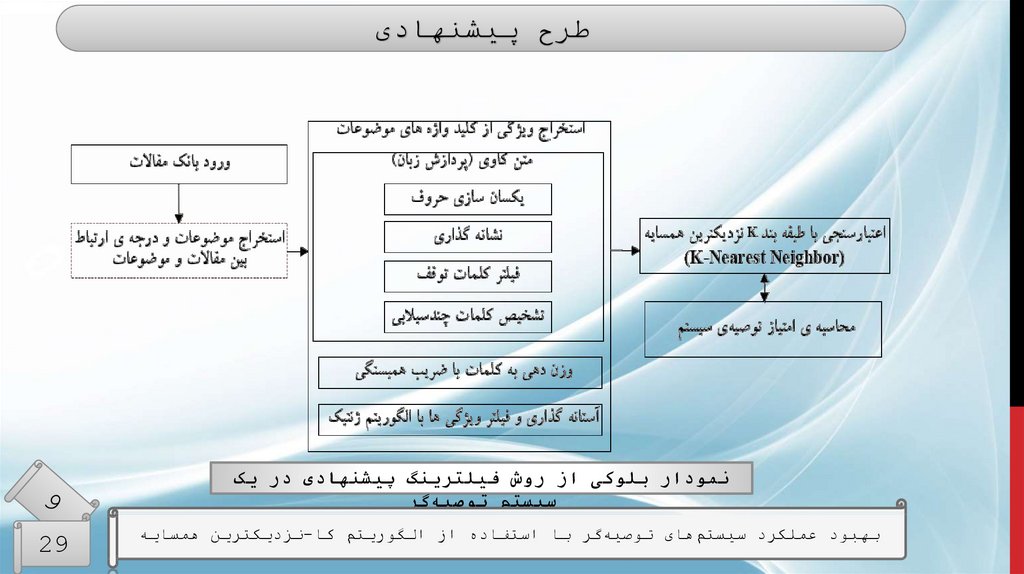
طرح پیشنهادینمودار بلوکی از روش فیلترینگ پیشنهادی در یک
سیستم توصیهگر
بهبود عملکرد سیستمهای توصیهگر با استفاده از الگوریتم کا-نزدیکترین همسایه
29
10.
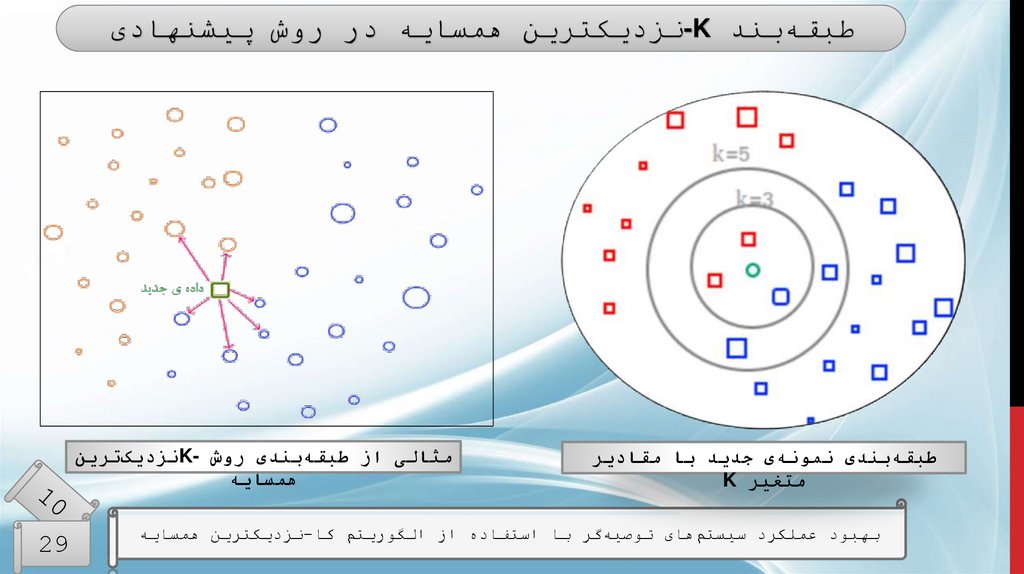
طبقهبند -Kنزدیکترین همسایه در روش پیشنهادیطبقهبندی نمونهی جدید با مقادیر
متغیر K
مثالی از طبقهبندی روش K-نزدیکترین
همسایه
بهبود عملکرد سیستمهای توصیهگر با استفاده از الگوریتم کا-نزدیکترین همسایه
29
11.
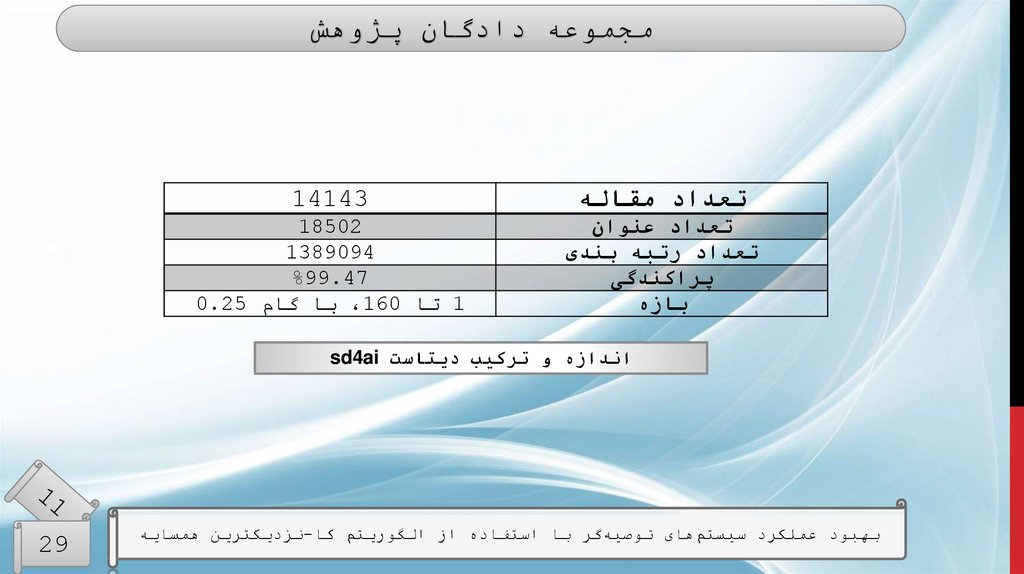
مجموعه دادگان پژوهشتعداد مقاله
14143
تعداد عنوان
تعداد رتبه بندی
پراکندگی
بازه
18502
1389094
%99.47
1تا ،160با گام 0.25
اندازه و ترکیب دیتاست sd4ai
بهبود عملکرد سیستمهای توصیهگر با استفاده از الگوریتم کا-نزدیکترین همسایه
29
12.
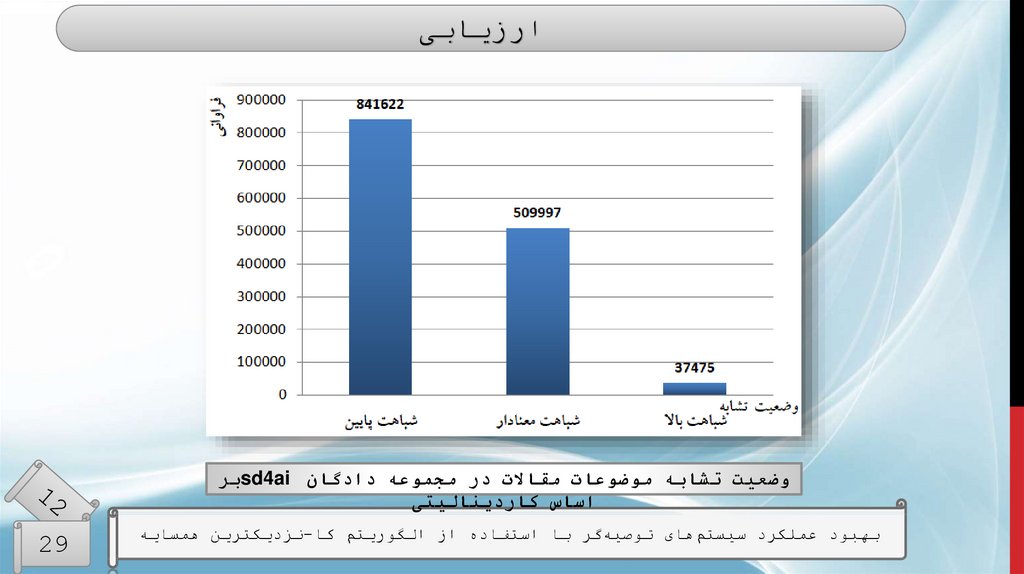
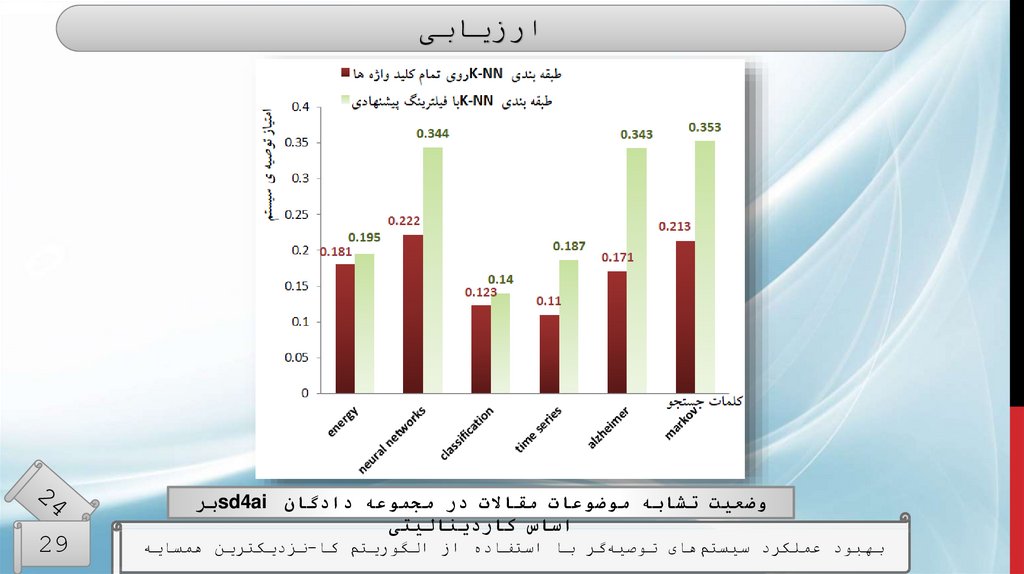
ارزیابیوضعیت تشابه موضوعات مقاالت در مجموعه دادگان sd4aiبر
اساس کاردینالیتی
بهبود عملکرد سیستمهای توصیهگر با استفاده از الگوریتم کا-نزدیکترین همسایه
29
13.
ارزیابیروند رشد بردار جستجو در سیستمهای توصیهگر با روش استخراج کلید
واژه
بهبود عملکرد سیستمهای توصیهگر با استفاده از الگوریتم کا-نزدیکترین همسایه
29
14.
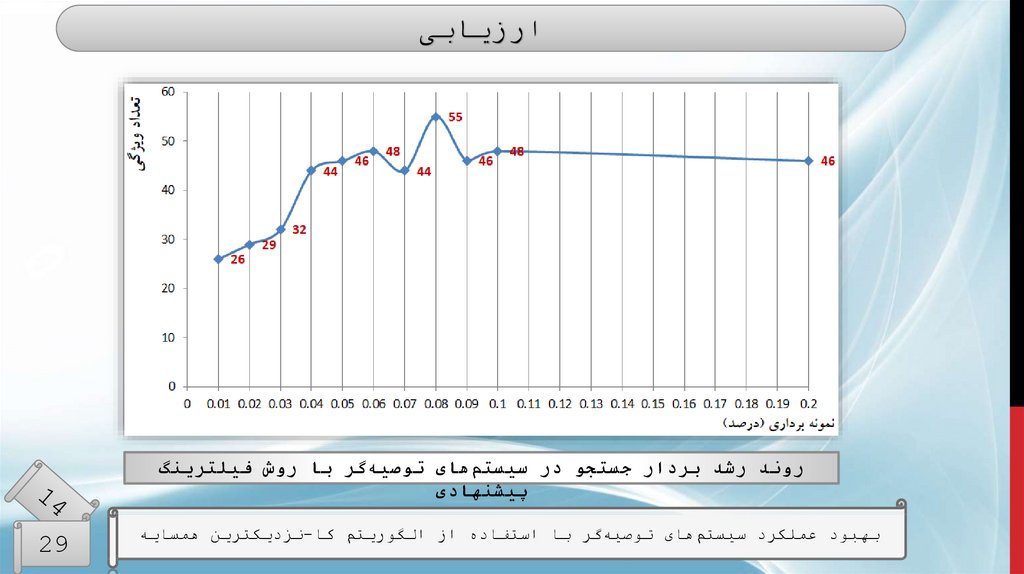
ارزیابیروند رشد بردار جستجو در سیستمهای توصیهگر با روش فیلترینگ
پیشنهادی
بهبود عملکرد سیستمهای توصیهگر با استفاده از الگوریتم کا-نزدیکترین همسایه
29
15.
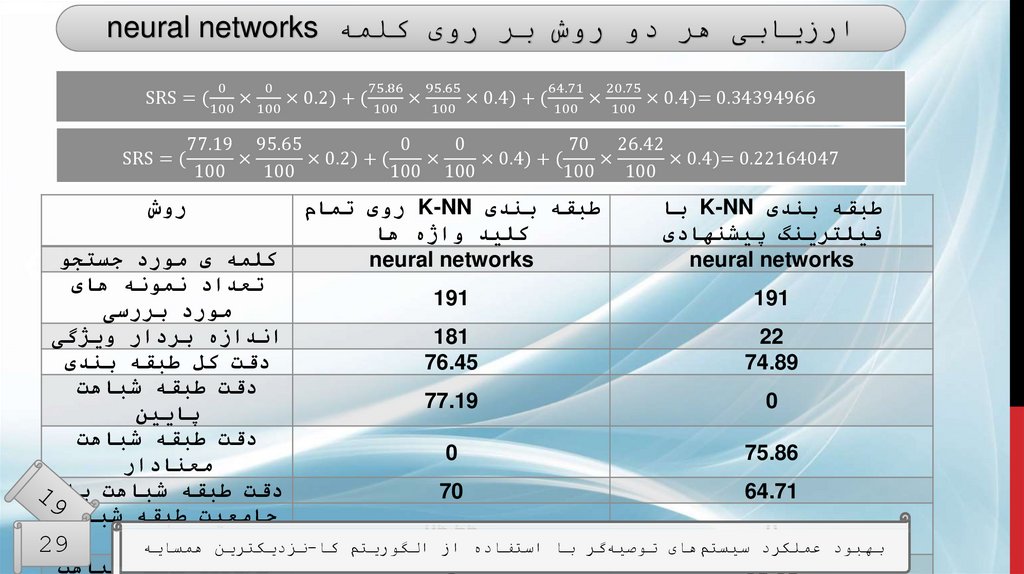
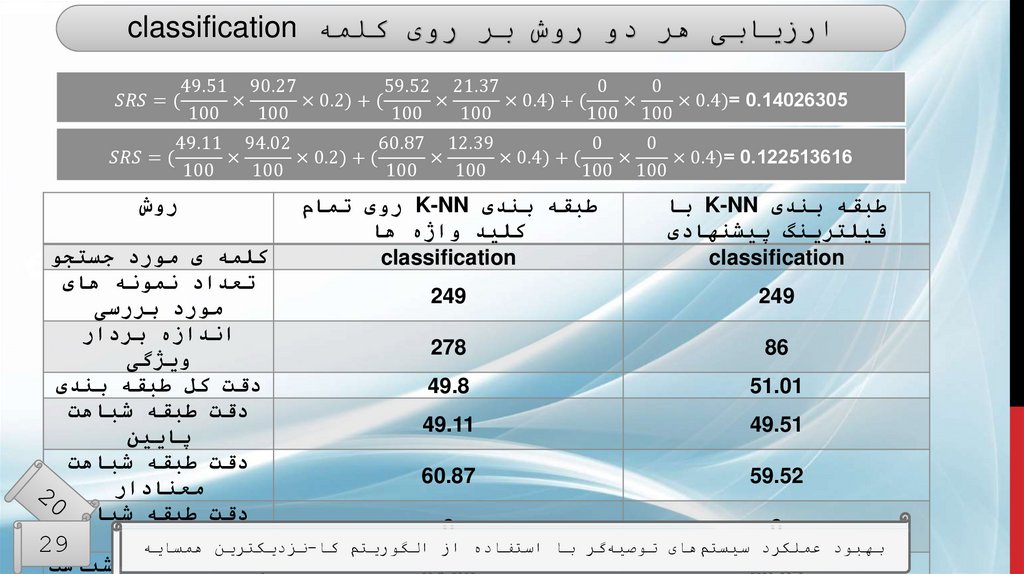
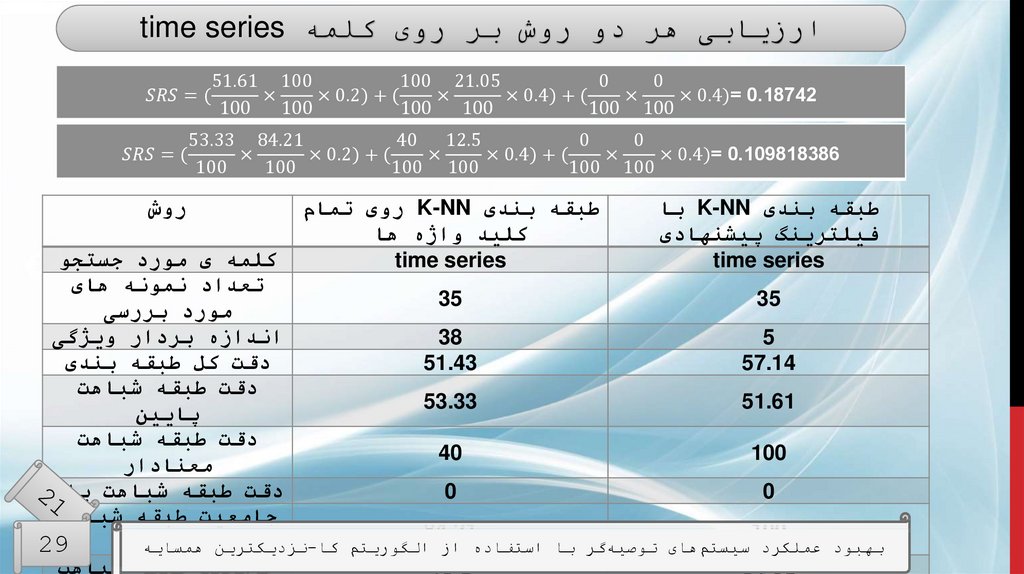
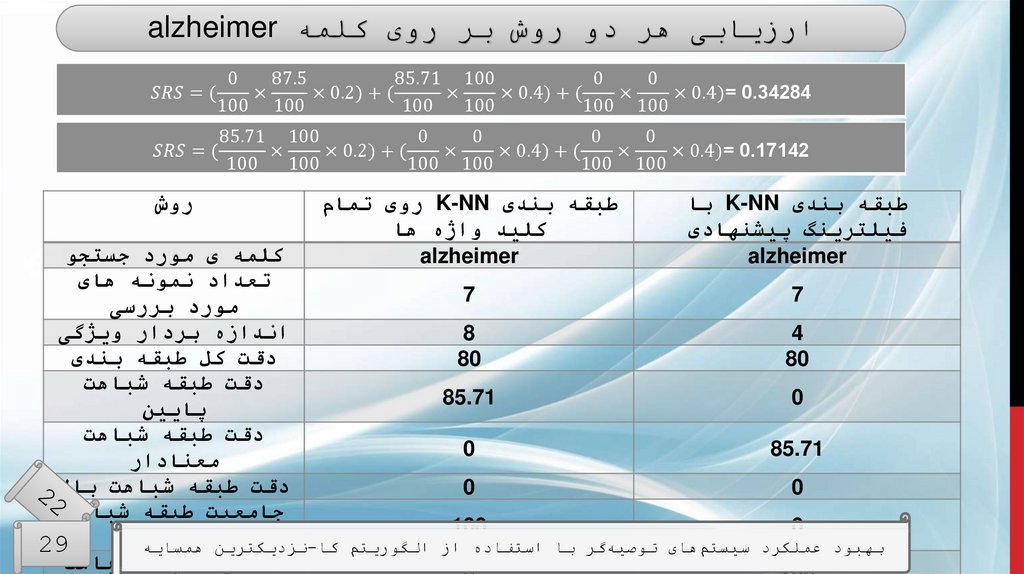
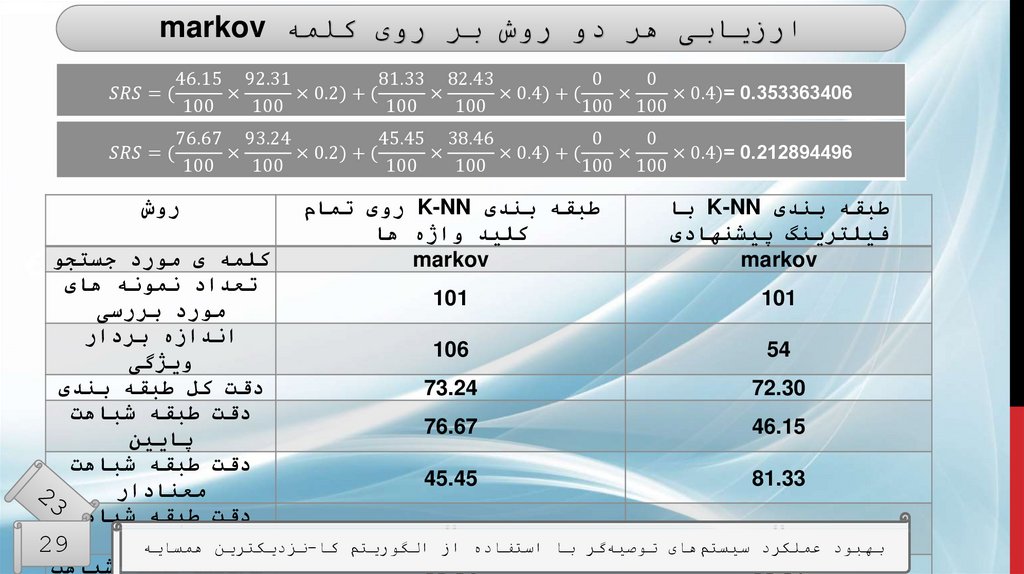
ارزیابیطبقه بندی K-NNبا فیلترینگ
پیشنهادی
60.83
0.4
طبقه بندی K-NNروی تمام
کلید واژه ها
51
0.446
معیارها
دقت طبقه بندی
میانگین خطای
مطلق
دقت طبقه شباهت
40.81
61
پایین
دقت طبقه شباهت
66.92
54.55
معنادار
دقت طبقه شباهت
24.44
20
باالر
مقایسهی نتایج طبقهبندی K-NNبا روش فیلترینگ پیشنهادی و روش فیلت
جامعیت طبقه
66
98.92
ها
تمام کلید واژه
شباهت پایین
جامعیت طبقه
43.5
3.47
شباهت معنادار
الگوریتم کا-نزدیکترین همسایه
بهبود عملکرد
سیستمهای توصیهگر با استفاده از 3.49
0.32
جامعیت طبقه29
شباهت باال
16.
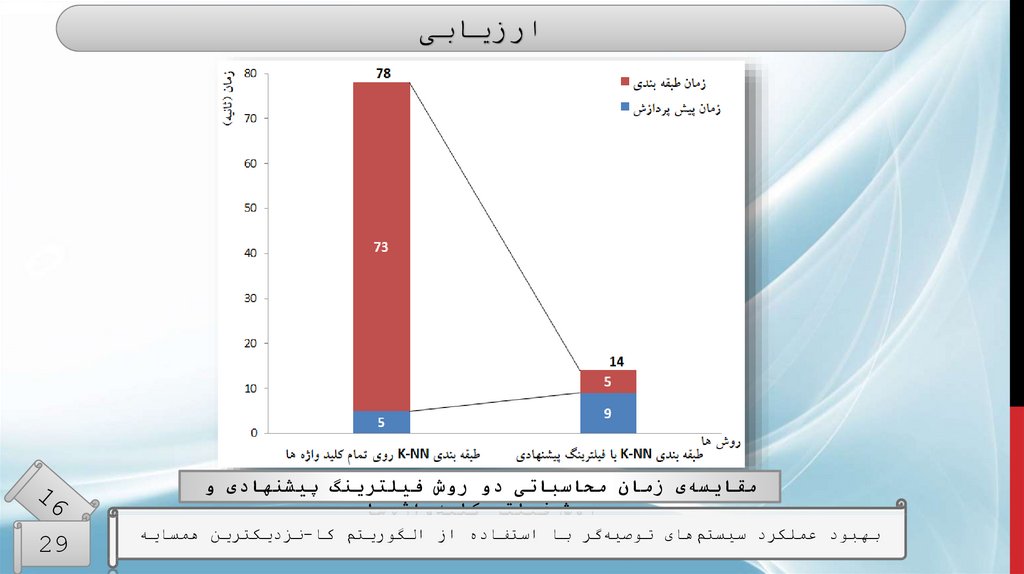
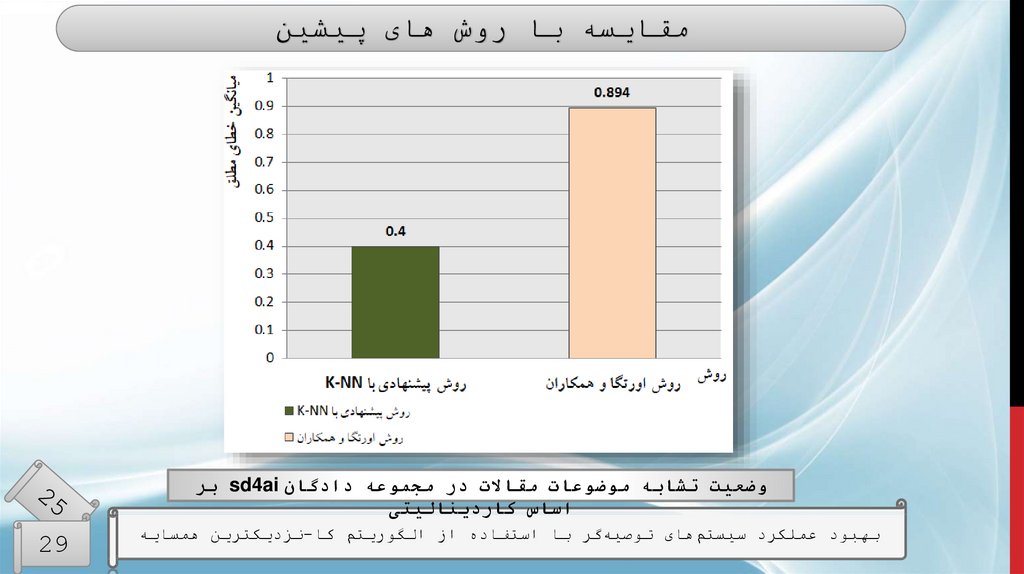
ارزیابیمقایسهی زمان محاسباتی دو روش فیلترینگ پیشنهادی و
روش فیلتر کلیدواژهها
بهبود عملکرد سیستمهای توصیهگر با استفاده از الگوریتم کا-نزدیکترین همسایه
29
17.
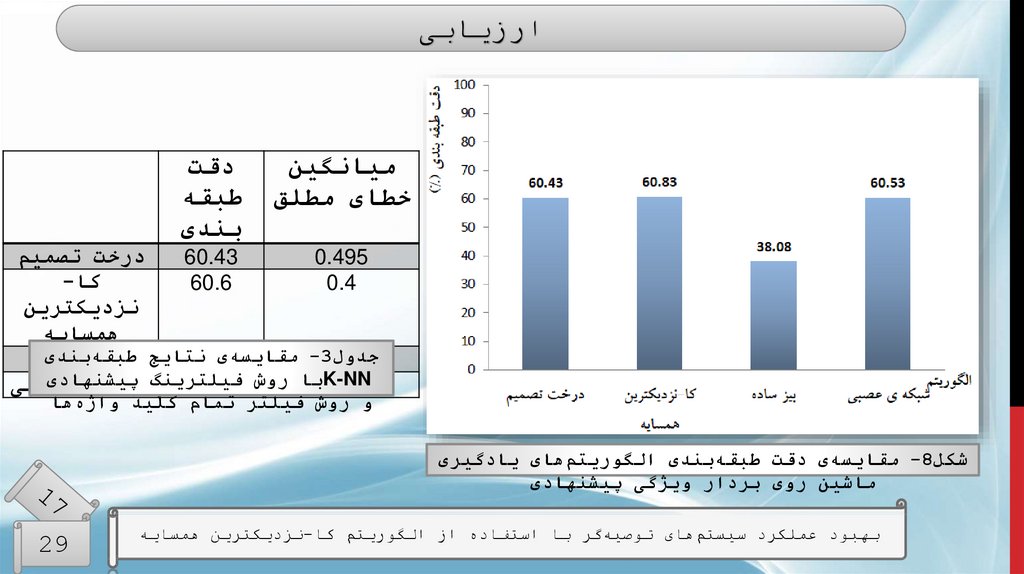
ارزیابیمیانگین
خطای مطلق
دقت
طبقه
بندی
درخت تصمیم
60.43
0.495
کا-
60.6
0.4
نزدیکترین
همسایه
طبقهبندی
-0.593مقایسهی
جدول3
ساده
نتایج بیز
38.08
پیشنهادی
عصبی
فیلترینگشبکه ی
K-NNبا روش 60.53
0.4
و روش فیلتر تمام کلید واژهها
شکل -8مقایسهی دقت طبقهبندی الگوریتمهای یادگیری
ماشین روی بردار ویژگی پیشنهادی
بهبود عملکرد سیستمهای توصیهگر با استفاده از الگوریتم کا-نزدیکترین همسایه
29
18.
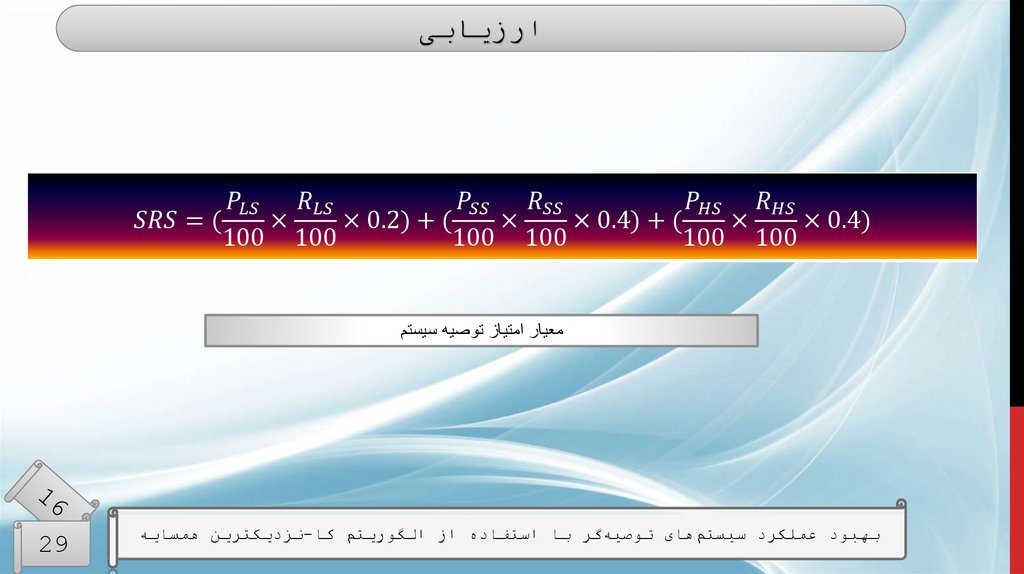
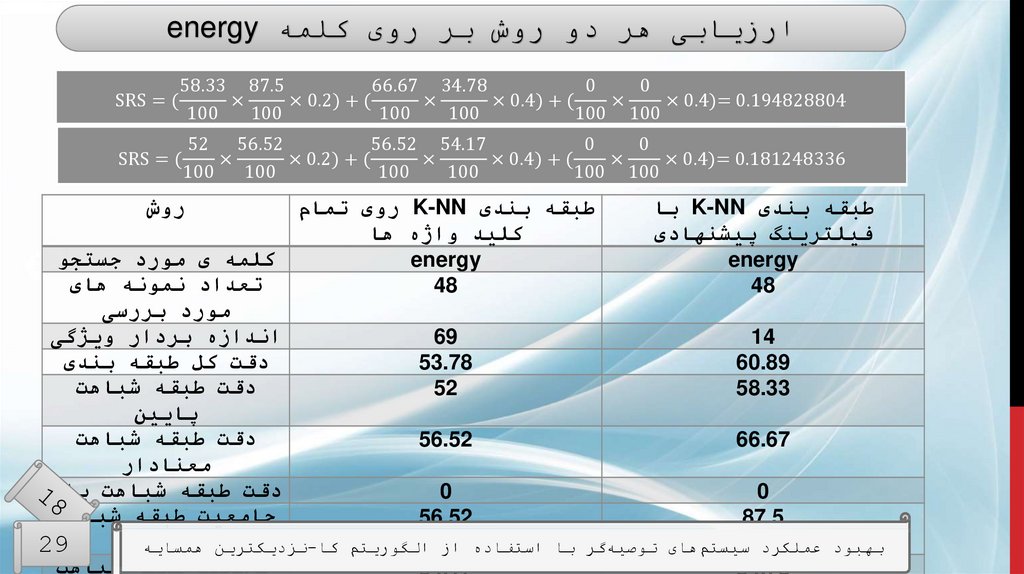
ارزیابی