
























 business
businessSimilar presentations:










Аналитика без стресса
1. Аналитика без стресса
12. Всем привет!
• Мансур Кадимов, управляющий партнер Reshape Analytics• Больше 11 лет опыта в аналитике:
Цепи поставок
Маркетинг
Коммерция
Управление проектами
• В ходе лекции мы примерим несколько шляп:
• Шляпа менеджера по аналитике (CDO)
• Шляпа дата-сайентиста (Data Scientist)
• Шляпа человека, делающего первые шаги в аналитике
2
3.
Чтоб понять, какие инструменты к каким аналитическим задачам применимы,нужно сначала ответить на вопрос:
− Какие задачи
решает аналитика?
− Задачи управления
3
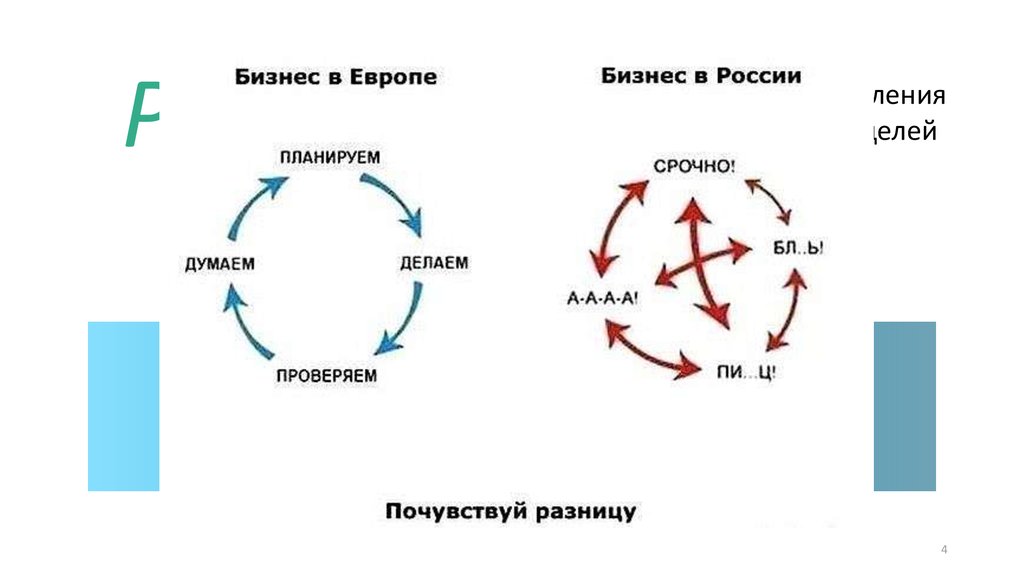
4.
PDCAPlan
Алгоритм управления
и достижения целей
Знакомая
Цикл
Act
Do
Деминга
аббревиатура?
Все ли тут очевидно?
Check
4
5.
ПланированиеВоздействие
Ёмкие Установка
словацелей,
оставляют
планирование работ для
и
пространство
распределения ресурсов
интерпретаций
Выполнение
Каскадный метод
Устранение причин отклонений,
изменение порядка
планирования ресурсов
Выполнение
запланированного
Проверка
Сбор информации,
сопоставление результатов
с целями, анализ отклонений
Планирование
Действие
Испытание
Итерационный метод
Решение о применении и
тиражировании результатов, или
повторении цикла
Реализация в малом
масштабе, достаточном для
получения информации
Изучение
Анализ результатов опыта,
извлечение знаний
5
6. При каком управленческом методе проще делать аналитику?
Каскадный метод• Длинные циклы
• Одновременно редко больше
одного
• Времени на обработку больше
• Стоимость ошибки выше
Итерационный метод
• Короткие циклы
• Может быть одновременно
несколько циклов
• Времени на обработку меньше
• Стоимость ошибки ниже
Значимой разницы нет. Почему?!
Когда аналитик испытывает меньший стресс?
6
7. Каждый метод управления несет свои сложности для аналитики
Каскадный методИтерационный метод
• Цели на дальний горизонт формулируются
сложнее и согласуются дольше, за это
время могут потерять актуальность
ключевые предпосылки в их основе
• Содержание последовательных, или
одновременно идущих итераций
может быть совершенно разным
• Результаты, полученные на малом
масштабе, должны быть
репрезентативны
• За короткий срок на ограниченном
количестве данных нужно принимать
множество решений
Аналитика должна фокусироваться на
• Собираемые
метрики могут устареть
в ходе
бизнес-целях
и повышать
вероятность их
выполнения, а остановить процесс, чтоб их
дополнить нет возможности
достижения
• Даже при достаточном объеме времени на
анализ можно столкнуться с дефицитом
качественных и объясняющих ход
выполнения данных
7
8. Понимание бизнеса, которое нужно до старта аналитических работ
• Цели и причины анализа• Целевая аудитория, сценарий использования результатов и реальная
готовность к этому
• Наличие ранее проведенного анализа и обратная связь по нему
• Существующие гипотезы и критерии успеха
• Доступные людские ресурсы: навыки, опыт и загруженность
• Доступные технические ресурсы: интеграция, хранение и калькуляция
• Срок выполнения работ
• Требований и ограничения, например, связанные с персональными
данными
8
9. Концепция, о которой нельзя забывать
Аналитические технологии могут бытьочень мощными, результаты
вдохновляющими, но без
комплексного развития, включающего
людей (аналитическую культуру,
компетенции) и процессы (гибкость,
зрелость), могут оказаться
невостребованными.
Люди
Процессы
Технологии
9
10. Четыре аналитических подхода
ВысокаяПредписывающий
Ценность
• Тем выше, чем выше глубина
анализа, количество,
актуальность, неочевидность и
точность выводов
Ценность
Предиктивный
Диагностический
Сложность
• Характеризуется объемом
усилий, компетенций и средств,
вложенных в первичное
создание аналитического
продукта и степени дальнейшей
автономности решения
Описательный
Низкая
Сложность
Высокая
10
11. Описательная аналитика
• Отвечает на вопрос: чтопроисходит сейчас или было в
прошлом (сколько, когда, где)?
• Кейсы: охват публикаций,
динамика посещений ресурса,
дочитывания, % отклика
• Способы: консолидация,
трансформация, агрегация и
визуализация данных
• Формы: регулярная отчетность,
дашбоарды, запросы на
выгрузку данных из систем.
11
12. Диагностическая аналитика
• Отвечает на вопрос: что это,почему это происходит, на что
обратить внимание?
• Кейсы: сравнение отклика,
глубокий анализ аудитории,
таргетинг, сегментаций аудитории,
анализ сентиментов
• Способы: обогащение данных,
кластеризация, когортный анализ,
выявление корреляций, анализ
значимости признаков, анализ
отклонений, распознавание
изображений и извлечение
информации из текстов и т.д.
• Формы: интерактивная
отчетность, причинноследственный анализ
12
13. Предиктивная аналитика
• Отвечает на вопрос: есть липаттерн? что может
произойти в будущем?
• Кейсы: прогнозирование объема
продаж, вероятности открытия
страницы и покупки
• Способы: построение
прогнозных моделей (регрессии,
нейросети), кластеризация
• Формы: часто встраивается в
системы рекомендаций,
управления ставками, скоринга
13
14. Предписывающая аналитика
• Отвечает на вопросы: что-если?как лучше всего поступить?
• Кейсы: разработка стратегий,
оптимизация портфеля, поиск
оптимального размещения
• Способы: комплексные
имитационные модели,
многократные вычислительные
эксперименты,
оптимизационные механики
• Формы: модели с заданной
логикой(событий, агентской или
системно-динамической) и
целевые много-подходные
эксперименты
14
15.
Специализированныерешения
Корпоративные
решения
Карта аналитических решений
Сетевые базы данных
MS SQL, Teradata, Greenplum, MySQL,
SAP HANA
Системы для
управления
мастер-данными
Корпоративные платформы для анализа данных
MS SQL Analysis Services, Microstrategy, IBM SPSS, Pentaho(free)
Облачные БД
Google, Amazon
Решения для визуализации
Tableau, QlikSense, SAP Lumira,
MS Power BI (+free)
Корпоративные информационные
системы (ERP, CRM, POS)
SAP, 1C
Языки программирования для машинного обучения (free)
Python, R
Self-service аналитические
решения (машинное обучение
без программирования)
Loginom (+free), RapidMiner
(+free), Orange (free),
Alteryx и Lobe (beta)
Распознавание фото (free)
на Python TensorFlow, Keras
Системы для имитационного
моделирования и нелинейной
оптимизации
AnyLogic (+free), IBM ILOG
Извлечение информации из текстов
Abbyy Compreno
Специализированные комплексные
оптимизационные решения
Albert.AI, HR-робот Вера
Распознавание речи
Yandex.SpeechKit, Alexa
Мониторинг и анализ соц.сетей
YouScan, BrandAnalytics
Локальные
решения
Инструменты веб-аналитики (free)
Google Analytics, Яндекс.Метрика
Старый добрый Excel
Сбор, обработка и хранение
данных
Визуализация данных
Диагностическая
аналитика
Предиктивная
аналитика
Предписывающая 15
аналитика
16.
Машинное обучение – это класс интеллектуальныхалгоритмов (моделей), способных самообучаться на
основе обобщения прецедентов и не содержащих в себе
прямого решения специфичных задач.
Метод машинного обучения встречается в диагностической, прогнозной
и предписывающей аналитике.
16
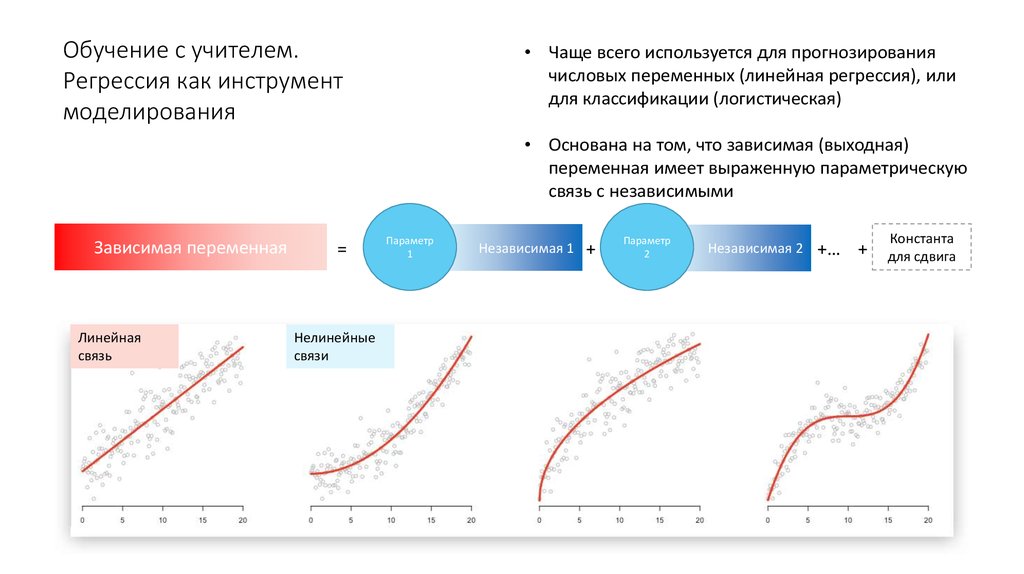
17. Обучение с учителем
Машинное обучение на основании известных пар правильных ответови «ситуаций» (предпосылок) с предсказанием ответов для новых пар.
Регрессии предсказывают значения
Классификации – категории
Оба метода также используются для решения задач прогнозирования будущего и ранжирования.
17
18. Обучение без учителя
Доступны только «ситуации», правильных ответов – нет, необходимоописать и дополнить «ситуации» новыми знаниями.
Кластеризация объединяет похожие объекты в группы
Ассоциативные правила формируют частые наборы
объектов
А еще это фильтрация выбросов, заполнение пропущенных значений и обобщение за счет
уменьшения количества признаков «ситуации»
18
19. А учитель кто? Не совсем анализ данных
А учитель кто? Не совсем анализ данныхОбучение с подкреплением
Модель обучается с целью максимизации
долговременного выигрыша, получая отклик на
принятые решения от динамичной среды, с
которой она взаимодействует
Генеративно-состязательный подход
Две подмодели имеют противоположные цели:
одна генерирует образцы, а другая старается
отбраковать эти образцы от «подлинных»
19
20. У машинного обучения очень много разных применений
Генерация текстов: обзоры матчейГенерация изображений, фото, видео
Предсказание исхода событий
Перевод текста
Предупреждение фрода, расследование
мошенничества
Диалоги с чат-ботами и с теле-роботами
Создание персонального пользовательского опыта
Оценка возможности УДО
Прогнозы событий в жизни потребителей
Распознавание эмоций, профилирование по
фотографиям
Категоризация документов, писем
Распознавание речи, жестов, ручного ввода
Интерпретация пресс-релизов для игры на бирже
Управление рекламным бюджетом
Отбор и фильтрация изображений
Техническая и медицинская диагностика
Самоуправляемые автомобили
Повышение урожайности, удоя
И даже генерация программного кода на основе изображений!!
20
21. На что нужно обращать внимание, используя машинное обучение
• Некоторые методы функционируют как «черный ящик», правила которогонеформализованны и непрозрачны, в то время как малейшее изменение
входных параметров может неожиданно сильно повлиять на результат
• Требуется большое количество качественных и размеченных данных: до 95%
времени уходит на их подготовку
• Возможна предвзятость модели из-за некорректно составленной исходной
выборки, что требует отдельной проверки
• Случается переобучение модели, когда из-за избыточной сложности она
теряет предсказательный потенциал
• Возможны ложные срабатывания или пропуски событий – метрики качества
должны это учитывать
• Требуется постоянный мониторинг качества результатов и данных,
подаваемых на вход (возможно, что угодно, в т.ч. троллинг)
21
22. Аналитический процесс
Итерации до получения применимой по качествумодели
Понимание
бизнеспроблемы
Сбор и
подготовка
данных
Исследование
данных
Создание
моделей
Обучение и
тестирование
Развертывание
модели
Постоянный мониторинг качества и оптимизация
22
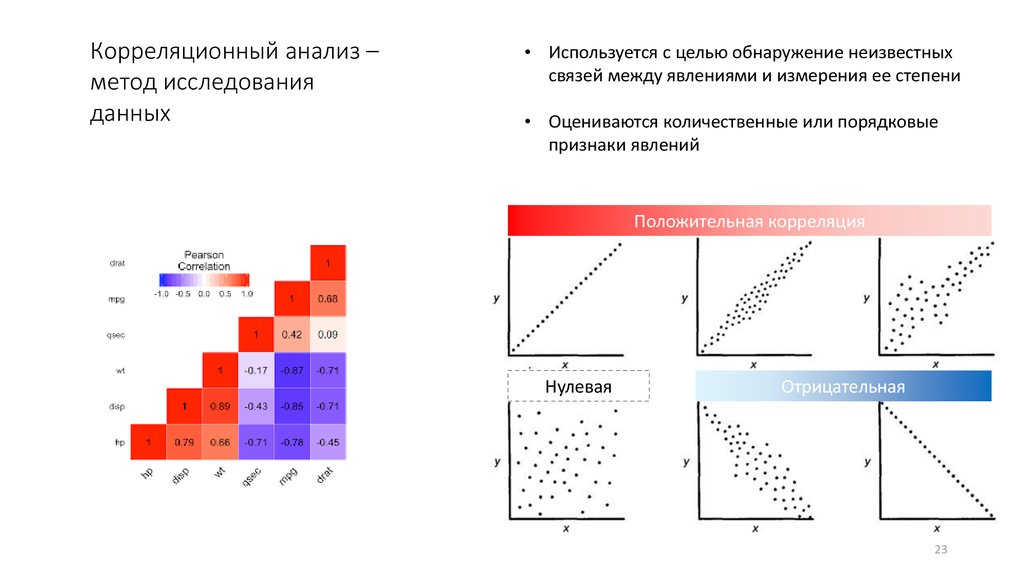
23.
Корреляционный анализ –метод исследования
данных
• Используется с целью обнаружение неизвестных
связей между явлениями и измерения ее степени
• Оцениваются количественные или порядковые
признаки явлений
Положительная корреляция
Нулевая
Отрицательная
23
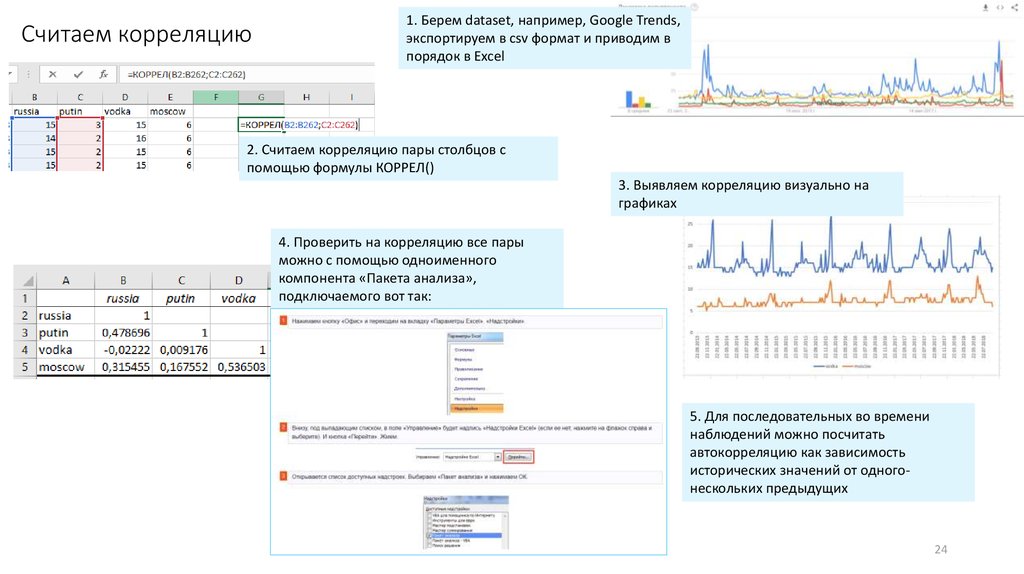
24.
Считаем корреляцию1. Берем dataset, например, Google Trends,
экспортируем в csv формат и приводим в
порядок в Excel
2. Считаем корреляцию пары столбцов с
помощью формулы КОРРЕЛ()
3. Выявляем корреляцию визуально на
графиках
4. Проверить на корреляцию все пары
можно с помощью одноименного
компонента «Пакета анализа»,
подключаемого вот так:
5. Для последовательных во времени
наблюдений можно посчитать
автокорреляцию как зависимость
исторических значений от одногонескольких предыдущих
24
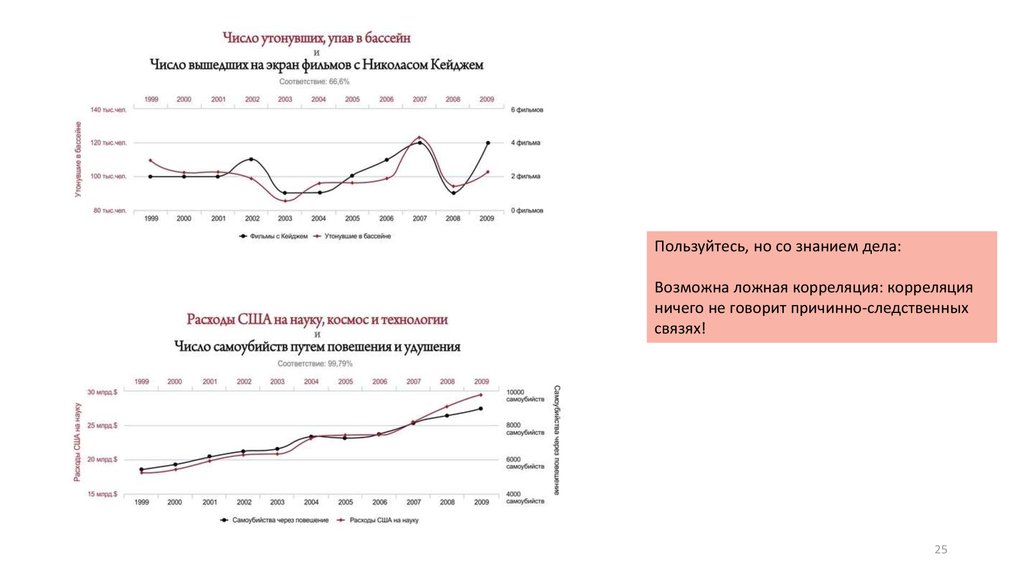
25.
Пользуйтесь, но со знанием дела:Возможна ложная корреляция: корреляция
ничего не говорит причинно-следственных
связях!
25
26.
Обучение с учителем.Регрессия как инструмент
моделирования
• Чаще всего используется для прогнозирования
числовых переменных (линейная регрессия), или
для классификации (логистическая)
• Основана на том, что зависимая (выходная)
переменная имеет выраженную параметрическую
связь с независимыми
Зависимая переменная
Линейная
связь
=
Параметр
1
Независимая 1
+
Параметр
2
Независимая 2
+… +
Константа
для сдвига
Нелинейные
связи
26
27.
Исходная выборка
Начинайте с одного независимого параметра (простой регрессии)
Меньше независимых параметров в множественной регрессии – больше скорость
Независимые параметры не должны между собой коррелировать
Наличие автокорреляции параметров может существенно повлиять на результат, поэтому включите в план
соответствующую регрессию
Желательно, чтоб в независимых параметрах была вариативность
Необходимо предварительно исключить выбросы
Границы прогнозного потенциала регрессии формируются исходными данными, экстраполяция за их
пределы может быть нерелевантной
Тестовая выборка
• От 20% до 30% значений в
зависимости от объема
исходной выборки
• Отбор значений:
• Случайный
• Последовательный
• Репрезентативный
Показатели качества по итогам построения регрессии
• Проверьте значения зависимой переменной на допустимость
• Посчитайте ошибки (остатки) для каждого рассчитанного значения,
• Постройте график ошибок, предварительно их упорядочив, график
должен иметь вид нормального распределения
• Рассчитайте сводную ошибку для разных типов регрессий и набора
независимых параметров, например, среднеквадратическую
• Отберите регрессию (формулу) с минимальной сводной ошибкой и
проверьте ее на тестовой выборке
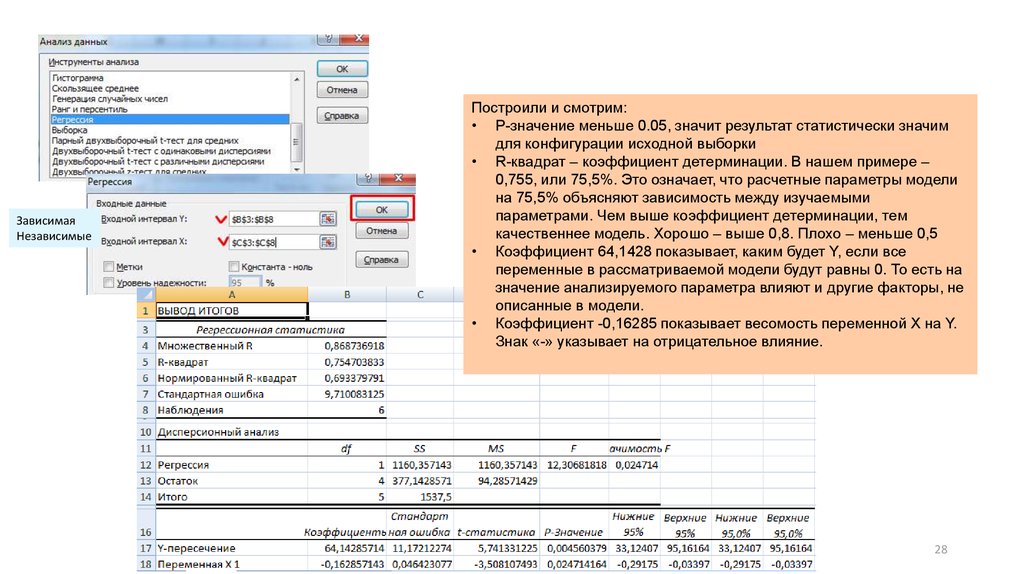
28.
ЗависимаяНезависимые
Построили и смотрим:
• P-значение меньше 0.05, значит результат статистически значим
для конфигурации исходной выборки
• R-квадрат – коэффициент детерминации. В нашем примере –
0,755, или 75,5%. Это означает, что расчетные параметры модели
на 75,5% объясняют зависимость между изучаемыми
параметрами. Чем выше коэффициент детерминации, тем
качественнее модель. Хорошо – выше 0,8. Плохо – меньше 0,5
• Коэффициент 64,1428 показывает, каким будет Y, если все
переменные в рассматриваемой модели будут равны 0. То есть на
значение анализируемого параметра влияют и другие факторы, не
описанные в модели.
• Коэффициент -0,16285 показывает весомость переменной Х на Y.
Знак «-» указывает на отрицательное влияние.
28
29. Рекомендации
• Машинное обучение простыми словамиhttp://vas3k.ru/blog/machine_learning/
• Марафон по Tableau http://tableau.pro/m01, http://tableau.pro/m02 и т.д.
• Блог «Путь война. Менеджерами не рождаются. Менеджерами становятся»,
рубрика Статистика http://baguzin.ru/wp/category/8stat/
• Подборки ссылок на курсы https://github.com/demidovakatya/vvedeniemashinnoe-obuchenie или https://habr.com/company/spbifmo/blog/417641/
• Подборки книг https://proglib.io/p/data-science-books/ или
https://www.mann-ivanov-ferber.ru/tag/analytics-books/
29
30. К семинару
1. Скачайте Loginom Academichttps://loginom.ru/downloads
2. Откройте справку и изучите как минимум
Быстрый старт
3. Скачайте датасет
https://www.kaggle.com/c/demand-forecastingkernels-only/data#_=_
4. Загрузите датасет в Loginom
5. Для узла «Текстовый файл» создайте
визуализатор Статистика, изучите
характеристики выборки
6. С помощью визуализатора Куб сначала
найдите store с максимальным объемом sales,
а затем для него найдите item с
максимальным sale
7. Отберите с помощью Фильтра строки, у
которых соответствующие store и item
8. Для узла «Фильтр строк» постройте диаграмму
типа «Разброс» для значений sale
9. Как вы думаете, какие точки на графике
являются выбросами?
30
31.
Спасибо!km@reshape.team
+7 926 555 15 53
31