





")
")

























")

























































 marketing
marketingSimilar presentations:


")





")

Процедура обработки и методы анализа данных
1. Маркетинговые исследования
Тема 9 Процедура обработки иметоды анализа данных
2. Вопросы лекции
Цели преобразования данных. Табулирование данных.Простая и перекрестная табуляция.
Графическое представление данных
Классы процедур анализа данных.
Инструменты дескриптивного анализа. Использование
мер центральной тенденции (моды, медианы, средней).
Использование мер вариации (распределения частот,
размаха вариации, среднего квадратического отклонения).
Выводной статистический анализ.
Анализ различий
Анализ связей. Определение и интерпретация связей
между переменными
Предсказательный анализ.
Выбор методов обработки и анализа данных.
3. Преобразование данных
Преобразование данных - перевод «сырых данных» всжатую, осмысленную информацию, удобную для
анализа.
Оно включает:
полевое редактирование
введение данных в компьютер,
проверку на предмет ошибок (централизованное
редактирование)
кодирование,
представление в табличной форме (табулирование).
Далее проводится статистический анализ, т.е. определяются
средние величины, частоты, корреляционные и
регрессионные соотношения, осуществляется анализ
трендов.
4. Полевое редактирование
Предварительнаяпроверка
данных, проводимая с целью
обнаружения пропусков и
неточностей сбора данных
5. Функции преобразования данных:
Выделяют четыре функции (цели)преобразования данных:
обобщение
определение концепции (концептуализация),
перевод результатов статистического анализа
на понятный для менеджера язык
(коммуникация),
определение степени соответствия
полученных результатов всей совокупности
(экстраполяция).
6. Обобщение данных
Из-за неспособности человекаанализировать большие массивы
информации, необходимо исходные
собранные данные представить в удобном
для осмысления виде, т.е. их необходимо
обобщить, выразить через ограниченное
число понятных параметров.
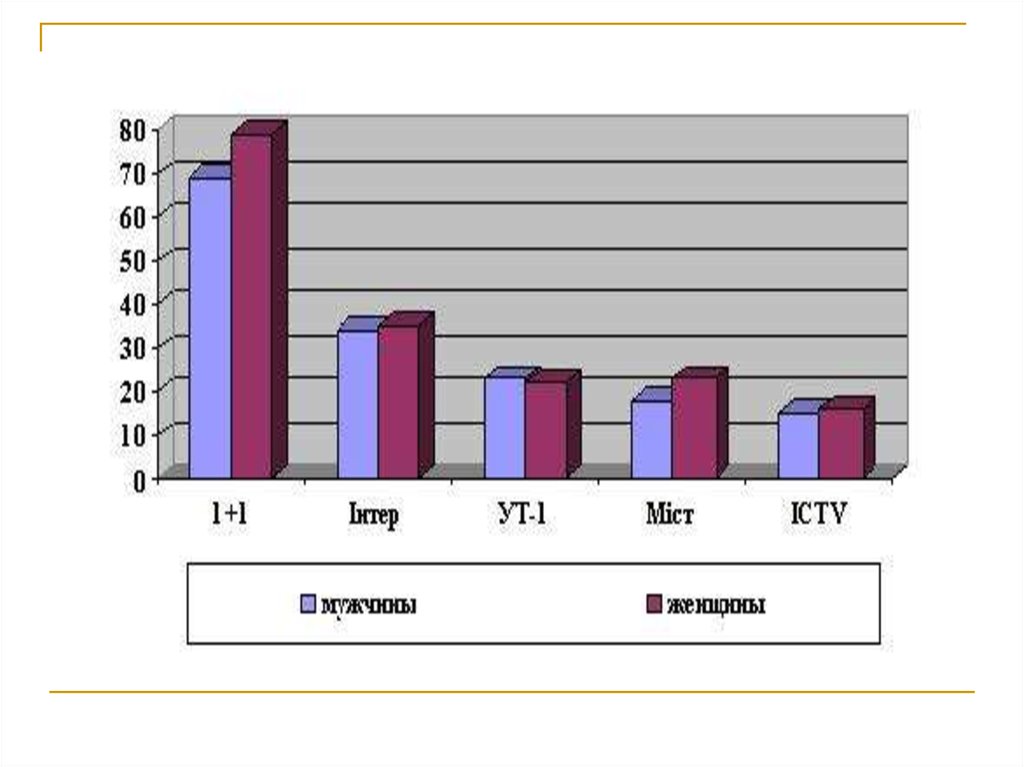
7. Определение концепции (концептуализация)
Большинство статистических меросновано на определенных
предположениях, которые определяют
базу анализа собранных данных.
Концептуализация направлена на оценку
результатов обобщения. Например,
слабый разброс оценок определенной
марки продукта вырабатывает у
исследователя одно суждение
(концепцию), сильный — другое.
8. Перевод результатов статистического анализа на понятный для менеджера язык (коммуникация)
Коммуникация предполагает приинтерпретации полученных результатов
использование понятных для заказчика
категорий.
Например, если для него понятна такая
статистическая мера как "мода", то она
используется при представлении
полученных результатов, если — нет, то
результаты описываются на
общепринятом языке.
9. Определение степени соответствия полученных результатов всей совокупности
Экстраполяция в данном случаепредполагает определение, в какой
степени данные выборки можно обобщить
на всю совокупность
10.
11. Табулирование данных
Исследователь, осуществляяпреобразование, старается найти
зависимости среди собранных данных и
в то же время достигнуть высокого уровня
обобщения.
Табулирование помогает исследователю
понять, что означают собранные данные.
Табулирование – подсчет количества
событий, которые попадают в
различные категории.
12. Группировка данных
Входе табулирования
осуществляется группировка
данных - разделение
обследуемой совокупности на
однородные группы, отдельные
единицы которых обладают
общим для всех них признаком
13. Таблица
Все группировки значений различныхпеременных, которые были
предусмотрены программой
исследования, ложатся в основу
статистических таблиц, которые обобщают
обработанную информацию.
Таблица – это перечень различных
сведений, (часто числовых данных),
приведенных в определенную систему
и разнесенных по графам – строкам и
столбцам.
14. Значение табулирования
Таблицы и графики в аналитическомотчете служат не просто
иллюстративными материалами, а
содержат в себе саму суть, ядро
полученной в ходе исследования
информации.
Без них просто невозможно выразить в
словесной форме выводы исследования, и
текстовой материал превращается в
простую словесную шелуху.
15. Построение таблицы
Хорошо сконструированная таблицапозволяет как самому исследователю, так
и заказчику более четко представить,
описать и объяснить смысл и сущность
изучаемого явления
Построение таблицы производится по
определенным правилам. Любая
статистическая таблица описывается с
помощью определенных параметров
16. Параметры таблицы
Заголовок – название таблицы, которое раскрываетструктуру группировки описываемых переменных,
либо характер связи (зависимости) между двумя и
более переменными. Наряду с этим в названии (или
чаще в подзаголовке) иногда указываются общие для
всех переменных единицы измерения (число ответов,
проценты, средний балл и т.д.).
Подлежащее – то, что подлежит описанию, то есть та
конкретная переменная, которая подвергается анализу.
Сказуемое – само описание, то есть числовые
значения, разнесенные по графам – ячейкам или
клеткам таблицы.
17. Степень значимости для потребителей фирмы “Евростиль” различных факторов маркетинга
Факторы,оказывающие
влияние на
поведение
потребителей
Численность покупателей (%),
отметивших фактор на:
Не
отметив
ших, %
I месте
II месте
II месте
IV месте
52
33
13,5
1,0
5
2. Насыщенность
ассортимента
29,5
22
37,5
11
3. Качество
обслуживания
11,5
20
31
37
5
7
24,5
17,5
50,5
1. Качество товара
4. Умеренная цена
18. Пример неправильного заголовка: Влияние географического расположения поставщика на цены
Цена за тоннуТранспортные
расходы
Цена с учетом
транспортных
расходов
Т- 112
7800-00
2100-00
9900-00
Т – 125
9700-00
------------
9700-00
Т – 140
7800-00
1200-00
9000-00
Т – 140
10170-00
--------------
10170-00
Т – 150
8600-00
1000-00
9600-00
Т – 175
8305-00
850-00
9155-00
Марка сырья
Бумага для
гофрирования
Картон
19. Простая табуляция
Простая табуляция (линейная) –подсчет количества событий, которые
попадают в каждую категорию, когда
категории базируются на одной
переменной.
Простые таблицы представляют собою
простой перечень (список) отдельных
значений той или иной переменной с
количественной или качественной
характеристикой каждой из них в
отдельности. Поэтому иногда их
называют также перечневыми.
20. Распределение респондентов по полу
полчастота
процент
мужчин
379
46,1
женщин
431
52,4
не указали
13
1,6
Всего
823
100,0
21. Статистическое использование простых таблиц
Простая табуляция служит исходнойбазой для построения гистограмм,
полигона частот, расчета таких
показателей, как:
мода,
медиана,
арифметическое среднее,
показатели вариации.
22. Пример простой табуляции
Первый вопрос анкетыВариант
ответа
Число
ответивших,
%
87,8
12,2
1
2
:
Второй вопрос анкеты
Вариант
ответа
Число
ответивших
,%
46,3
14,6
2,4
34,1
2,4
0
1
2
3
4
4
2
3
1
0
2
1
23. Перекрестная табуляция
Перекрестная табуляция – подсчет количествасобытий, когда категории базируются на двух или
более переменных, рассматриваемых
одновременно (перекрестный анализ).
Это наиболее широко используемый прием
анализа связей между переменными в
маркетинговых исследованиях.
Большинство комбинационных таблиц при
расчетах в программе SPSS формируется в ходе
операции, именуемой кросстабуляция
Последовательный ряд перекрестных табуляций
носит название – кросс-таб
24. Пример перекрестной табуляции
Социальнодемографические признаки
потребителей
Удельный
вес в общем
объеме
выборки, %
Доля потребителей в группах с разным уровнем
дохода, % к численности каждой группы
до 0,5
млн. руб.
от 0,5 до
1 млн.
руб.
от 1 до 3
млн. руб.
более 3
млн. руб.
I. Пол:
мужчины
26,5
16,7
11,5
37,3
31,7
женщины
73,5
83,3
88,5
62,7
68,3
Итого
100
100
100
100
100
II. Возраст:
до 20 лет
1,0
33,3
от 20 до 30 лет
31,5
66,7
49,2
19,6
23,2
от 30 до 40 лет
52,9
36,1
62,7
61,0
от 40 до 50 лет
14,5
14,8
13,7
15,8
от 50 лет и более
1,0
3,9
Итого
100
100
100
100
100
25. Перекрестные таблицы
Такие таблицы являют собою нечто большее,нежели простой перечень данных. Это
одновременно и способ, и вместе с тем
результат определенной систематизации
данных.
В комбинационных таблицах, чтобы избежать
излишнего нагромождения данных,
затрудняющего их восприятие, иногда
опускают абсолютные величины (частоты) тех
или иных значений переменных, оставляя
лишь пропорции или проценты
26. Важно понимать!
Хорошо сконструированнаятаблица позволяет
исследователю более четко
представить и описать смысл и
сущность изучаемого им явления
27. Графическое представление данных
Графическое представление данных – этонаиболее наглядное изображение полученного
распределения результатов исследования.
Оно дает возможность с одного взгляда
определить структуру и состав изучаемой
совокупности, структурные сдвиги, тенденции
изменений при переходе от одних значений
переменных к другим и т.д.
При анализе маркетинговой информации
наиболее часто используют такие виды
графического представления данных как
гистограмма, полигон частот и кумулята
распределения, а также различные виды
диаграмм.
28. Гистограмма
Гистограмма – это графическое изображениераспределения, построенного чаще всего по
интервальной шкале
Гистограмма представляет собою ряд
смежных прямоугольников, построенных на
одной прямой: площадь каждого из них
пропорциональна частоте нахождения
данной величины в интервале, на котором
построен данный прямоугольник.
При равных интервалах плотности
распределения пропорциональны частотам,
которые и откладываются по оси ординат.
29. Пример гистограммы: распределение опрошенных по возрасту.
35Возрастная группа
30
процент
25
до 30 лет
частота
процент
до 30 лет
264
32,1
30-39 лет
169
20,5
40-49 лет
195
23,7
50-59 лет
84
10,2
60 лет и старше
100
12,2
не указали
11
1,3
Всего
823
100,0
30-39 лет
20
40-49 лет
15
50-59 лет
60 лет и старше
10
5
0
1 интервал
возрастной
30. Комментарии
На этой гистограмме, удельный вес каждойвозрастной категории в общем объеме
выборочной совокупности выражается площадью
прямоугольника, а общая площадь равна 1
(100%).
Если бы мы строили гистограмму на основе
абсолютных значений частот, общая форма ее не
изменилась бы, но в этом случае площадь
каждого прямоугольника означала бы число лиц
данной категории, а общая площадь была бы
равна численности опрашиваемой совокупности
31. Важно понимать!
Обратим внимание на одну важнуюособенность гистограммы: протяженность
по оси абсцисс должна соответствовать
размеру отображаемого интервала.
Этим гистограмма отличается, к примеру,
от столбчатой (или столбиковой)
диаграммы, где ширина столбца значения
не имеет и просто фиксирует
определенную позицию.
32. Полигон распределения
Полигон распределения используетсяпреимущественно для графического
отображения распределений дискретных
рядов (в то время как гистограмма –
непрерывных).
Эти графики строятся также в прямоугольной
системе координат, в которой:
на горизонтальной оси х указываются значения
(или ранг) переменной
на вертикальной оси у отмечается общая
численность или доля респондентов (в
процентах), обладающая тем или иным
значением.
33.
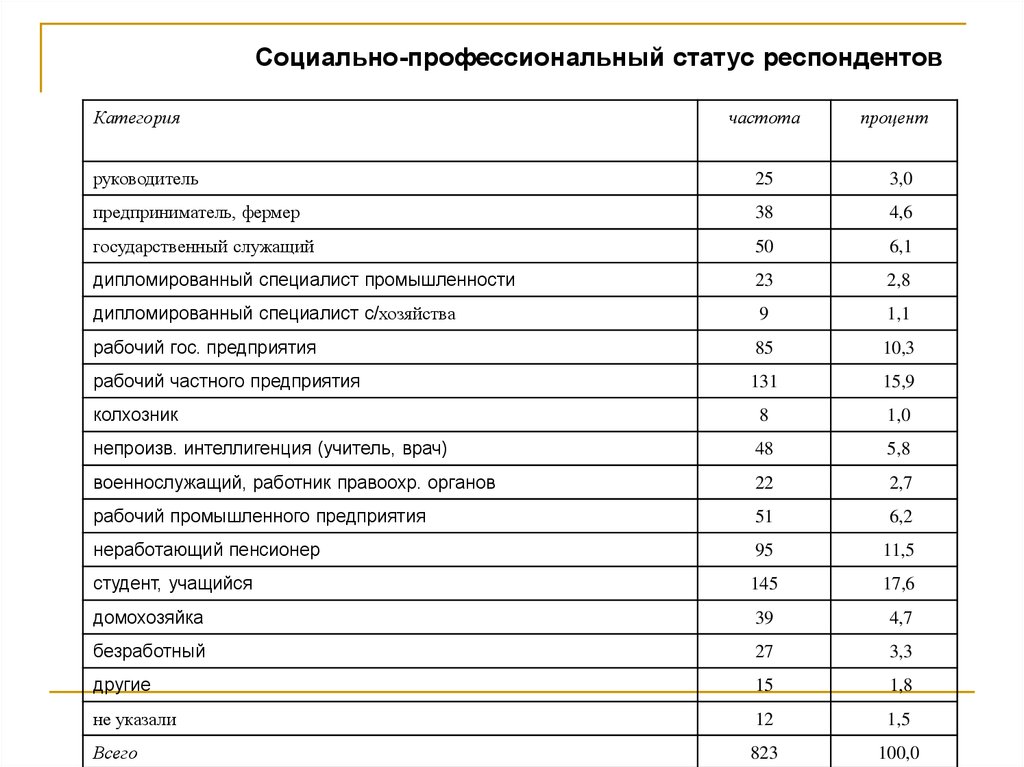
Социально-профессиональный статус респондентовКатегория
частота
процент
руководитель
25
3,0
предприниматель, фермер
38
4,6
государственный служащий
50
6,1
дипломированный специалист промышленности
23
2,8
дипломированный специалист с/хозяйства
9
1,1
рабочий гос. предприятия
85
10,3
рабочий частного предприятия
131
15,9
колхозник
8
1,0
непроизв. интеллигенция (учитель, врач)
48
5,8
военнослужащий, работник правоохр. органов
22
2,7
рабочий промышленного предприятия
51
6,2
неработающий пенсионер
95
11,5
студент, учащийся
145
17,6
домохозяйка
39
4,7
безработный
27
3,3
другие
15
1,8
не указали
12
1,5
Всего
823
100,0
34.
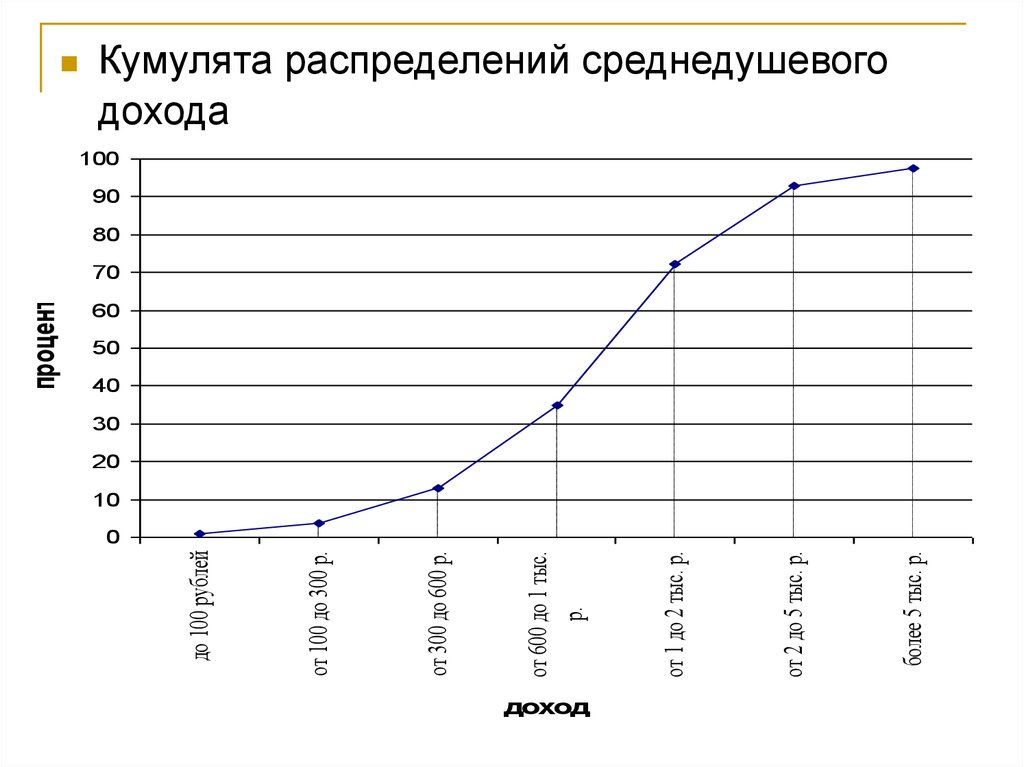
Полигон распределений социально-профессионального статуса35. Кумулята (от лат. cumulatio - накопление)
Кумулята (от лат. cumulatio накопление)При построении кумуляты, как и гистограммы, на
оси абсцисс откладываются значения дискретных
признаков (либо границы интервалов), а на оси
ординат – накопленные частоты,
соответствующие верхним границам частотных
интервалов.
Таким образом, отличие кумуляты от гистограммы
состоит в том, что на графике кумуляты ординаты,
пропорциональные частотам последовательно
накладываются один на другой, так что высота
последней ординаты соответствует сумме высот всех
столбцов гистограммы.
Кумулята округляет индивидуальные значения
признака и выглядит возрастающей ломаной линией.
36.
доходболее 5 тыс. р.
от 2 до 5 тыс. р.
от 1 до 2 тыс. р.
от 600 до 1 тыс.
р.
от 300 до 600 р.
от 100 до 300 р.
до 100 рублей
процент
Кумулята распределений среднедушевого
дохода
100
90
80
70
60
50
40
30
20
10
0
37. Что позволяет определить кумулята?
Кумулята позволяет быстро определитьудельный вес той доли совокупности,
которая находится выше или ниже
некоторой заданной величины значения
переменной.
Так, по данным, показанным на рисунке,
доля семейств, в которых месячный доход
на одного члена семьи не превышает 2
тысяч рублей, составляет несколько более
70 процентов (72,1%).
38. Диаграммы
Диаграмма – это обобщенное названиесамых разнообразных графических
изображений, наглядно показывающих
соотношение каких-либо величин
Диаграммы по одним и тем же
распределениям и вариационным рядам
могут принимать множество различных
видов и форм
39. Столбиковая диаграмма
9080
70
60
50
Восток
Запад
Север
40
30
20
10
0
1 кв
2 кв
3 кв
4 кв
40. Диаграммы
Если вы откроете Мастер диаграмм впрограмме Microsoft Excel, вы убедитесь, что там
предлагается достаточно большой набор их:
гистограммы, линейчатые, графики,
круговые, точечные, кольцевые лепестковые,
пузырьковые и т.п.
Выбор того или иного варианта – дело одного
лишь вкуса и чувства меры, поскольку, в
конечном счете, каждая из них лишь по-разному
– более или менее убедительно и, главное,
наглядно – отображают выраженные в числовой
форме ряды одних и тех же вариационных
рядов.
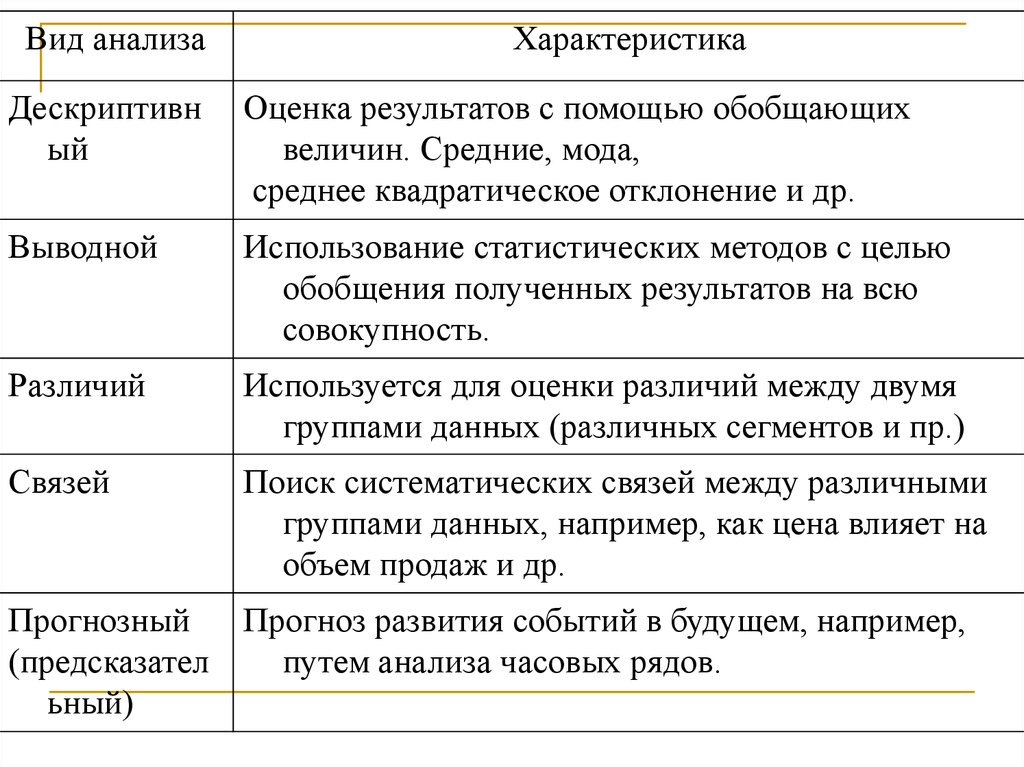
41. Классы процедур анализа данных
Выделяют пять основных видовстатистического анализа, используемых при
проведении маркетинговых исследований:
дескриптивный анализ
выводной анализ
анализ различий
анализ связей
предсказательный анализ.
Иногда эти виды анализа используются по
отдельности, иногда — совместно.
42.
Вид анализаХарактеристика
Дескриптивн
ый
Оценка результатов с помощью обобщающих
величин. Средние, мода,
среднее квадратическое отклонение и др.
Выводной
Использование статистических методов с целью
обобщения полученных результатов на всю
совокупность.
Различий
Используется для оценки различий между двумя
группами данных (различных сегментов и пр.)
Связей
Поиск систематических связей между различными
группами данных, например, как цена влияет на
объем продаж и др.
Прогнозный
(предсказател
ьный)
Прогноз развития событий в будущем, например,
путем анализа часовых рядов.
43. Важно понимать!
44. Дескриптивный анализа
Воснове дескриптивного
анализа лежит использование
таких статистических мер, как
средняя величина (средняя),
мода, среднее квадратическое
отклонение, размах или
амплитуда вариации.
45. Инструменты дескриптивного анализа
Для описания информации, полученной наоснове выборочных измерений, широко
используется две группы мер.
Первая включает меры "центральной
тенденции" или меры, которые описывают
типичного респондента или типичный
ответ
Вторая включает меры вариации или
меры, описывающие степень схожести или
несхожести респондентов или ответов от
"типичных" респондентов или ответов.
46. Меры центральной тенденции
Мода характеризует величинупризнака, появляющуюся наиболее
часто по сравнению с другими
величинами данного признака.
Мода носит относительный
характер и не обязательно, чтобы
большинство респондентов
указало именно эту величину
признака.
47. Меры центральной тенденции
Медиана характеризует значение признака,занимающее срединное место в
упорядоченном ряду значений данного
признака.
Средняя величина, которая чаще всего
рассчитывается как средняя арифметическая
величина. При ее вычислении общий объем
признака поровну распределяется между
всеми единицами совокупности.
Очевидно, что степень информативности
средней величины больше, чем медианы, а
медианы — чем моды
48. Итак,
мода (Мо) – величина признака, которыйпоявляется наиболее часто;
Медиана (Me) – это величина изучаемого
признака, которая находится в середине
упорядоченной совокупности. Половина чисел
этой совокупности имеют значения большие, чем
медиана, а половина чисел имеют значения
меньшие, чем медиана.
средняя (как правило, средняя арифметическая)
– значение признака, которое равномерно
распределено между всеми единицами
совокупности.
49. Пример расчета моды
В приведенном ниже распределении Мо являетсязначение = 3, которому соответствует
максимальная частота = 40%.
х
1
2
3
4
5
∑
F,
%
15
30
40
25
10
120
Для непрерывной переменной Мо может быть
определена только приблизительно и только после того,
как значения переменной сгруппированы в интервалы.
50. Формула для расчета порядкового номера медианы
Положение медианы, т.е. порядковыйномер медианы, определяется по
следующей формуле (при нечетном числе
вариантов):
где n – число единиц
совокупности
51. Пример расчета медианы
Например, стаж пяти рабочих составил 2, 4, 7, 8, 10лет. В таком упорядоченном ряду медиана - 7 лет.
(при нечетном числе вариантов). По обе стороны
от нее находится одинаковое число рабочих.
Если упорядоченный ряд состоит из четного числа
членов, то медианой будет средняя арифметическая
из двух вариант, расположенных в середине ряда.
Пусть теперь будет не пять человек в бригаде, а шесть,
имеющих стаж работы 2, 4, 6, 7, 8 и 10 лет. В этом
ряду имеются две варианты, стоящие в центре ряда.
Это варианты 6 и 7.
Средняя арифметическая из этих значений и будет
медианой ряда:
Ме = (6 + 7) / 2 = 6,5 лет
52. Формула для расчета средней
Определить среднюю во многих случаяхможно через исходное соотношение
средней
(ИСС).
Это
соотношение
называется также логической формулой
средней:
53. Формами реализации ИСС являются:
1) средняя арифметическая;2) средняя гармоническая;
3) средняя геометрическая;
4) средняя степенная (квадратическая,
кубическая и пр.)
54. Простая средняя арифметическая
Простая средняя арифметическаяиспользуется в том случае, когда расчет
осуществляется по несгруппированным
данным:
55. Пример расчета средней арифметической
ПодразделениеСредняя
Численность
заработная плата
персонала (чел)
(руб.)
1
2
3
600
1600
2000
10
7
3
Без учета численности персонала в подразделениях
средняя заработная плата составит 1400 рублей на
человека. С учетом же численности персонала средняя
заработная плата составит 1160 рублей на человека
56. Вопрос аудитории?
Вспомните:как влияет шкала
измерений по которой построен
вопрос в анкете, на виды
статистического анализа,
которые можно использовать
при обработке полученных
данных
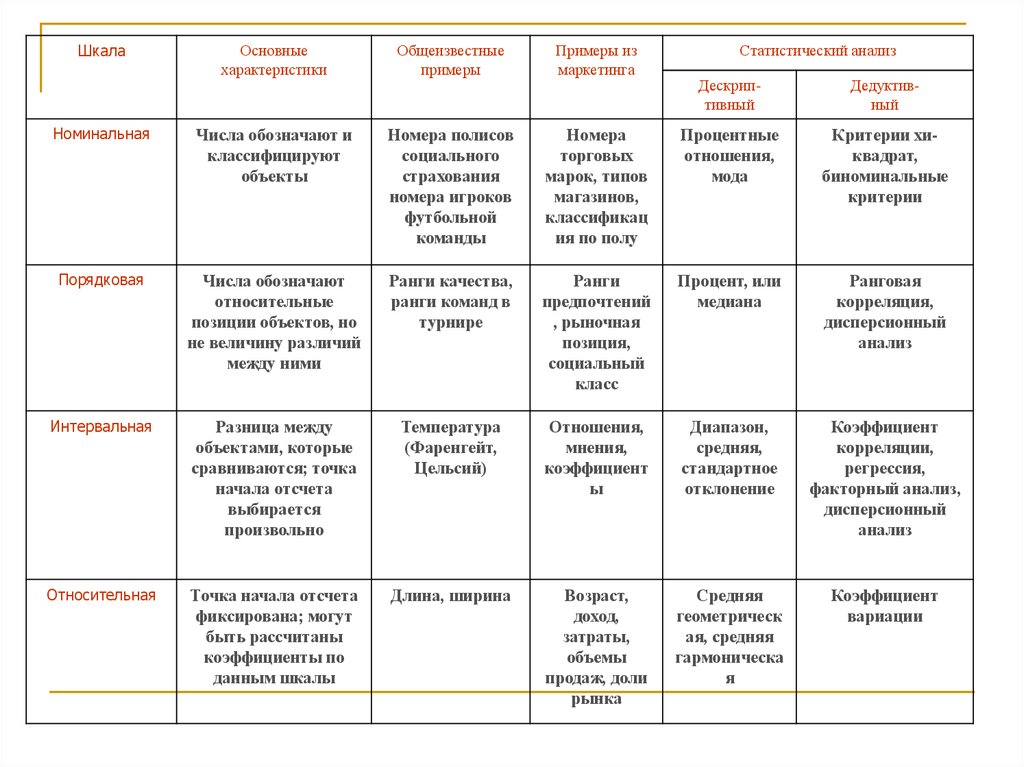
57.
ШкалаОсновные
характеристики
Общеизвестные
примеры
Примеры из
маркетинга
Номинальная
Числа обозначают и
классифицируют
объекты
Номера полисов
социального
страхования
номера игроков
футбольной
команды
Порядковая
Числа обозначают
относительные
позиции объектов, но
не величину различий
между ними
Интервальная
Относительная
Статистический анализ
Дескриптивный
Дедуктивный
Номера
торговых
марок, типов
магазинов,
классификац
ия по полу
Процентные
отношения,
мода
Критерии хиквадрат,
биноминальные
критерии
Ранги качества,
ранги команд в
турнире
Ранги
предпочтений
, рыночная
позиция,
социальный
класс
Процент, или
медиана
Ранговая
корреляция,
дисперсионный
анализ
Разница между
объектами, которые
сравниваются; точка
начала отсчета
выбирается
произвольно
Температура
(Фаренгейт,
Цельсий)
Отношения,
мнения,
коэффициент
ы
Диапазон,
средняя,
стандартное
отклонение
Коэффициент
корреляции,
регрессия,
факторный анализ,
дисперсионный
анализ
Точка начала отсчета
фиксирована; могут
быть рассчитаны
коэффициенты по
данным шкалы
Длина, ширина
Возраст,
доход,
затраты,
объемы
продаж, доли
рынка
Средняя
геометрическ
ая, средняя
гармоническа
я
Коэффициент
вариации
58. Пример
Один из вопросов демографическогоисследования, при проведении которого
использовалась шкала наименований, касался
национальности.
Русским был присвоен код 1, украинцам — 2,
татарам — 3 и т.д.
В данном случае, конечно, можно вычислить
среднее значение. Но как интерпретировать
среднюю национальность, равную, скажем, 5,67?
Для вычисления средних надо использовать
интервальную шкалу или шкалу отношений.
Однако в нашем примере можно использовать
моду.
59. Меры вариации
Распределение частот представляет втабличной или графической форме
число случаев появления каждого
значения измеренной характеристики
(признака) в каждом выбранном
диапазоне ее значений.
Распределение частот позволяет
быстро сделать выводы о степени
подобности результатов измерений.
60. Распределение частот: Распределение зрительской аудитории различных каналов по полу
TVпередачиПол
Мужчины
Женщины
1+1
69
79
Интер
34
35
УТ-1
23
22
Мост
18
23
ICTV
15
16
61.
62. Меры вариации
Размах вариации определяетабсолютную разность между
максимальным и минимальным
значениями измеренного признака.
Говоря другими словами, это разница
между конечными точками в
распределении упорядоченных величин
измеренного признака.
Данная мера определяет интервал
распределения значений признака.
63. Размах вариации внутри возрастных групп
ПередачаМост, %
Возраст опрошенных
< 20
20-29
30-39
40-49
> 50
5
16
24
35
18
64. Размах вариации внутри возрастных групп
65. Меры вариации
Среднее квадратическое отклонениеявляется обобщающей статистической
характеристикой вариации значений
признака.
Если эта мера мала, то кривая
распределения имеет узкую, сжатую
форму (результаты измерений обладают
высокой степенью схожести); если мера
велика, то кривая распределения имеет
широкий, растянутый вид (велика степень
различия оценок
66. Расчет среднего квадратического отклонения
.Показатель s, равный ,
называется средним квадратическим отклонением
67. Итак,
распределение частот – показывает число случаевпоявления каждого значения признака, который
измеряется;
размах вариации – это разница между конечными
точками упорядоченного ряда значений;
средне квадратичное отклонение – обобщающая
характеристика вариации. Означает процент
схожести или различий оценок.
среднее квадратическое отклонение характеризует
среднее расстояние от средней оценки ответов
каждого респондента на определенный вопрос.
68. Взаимосвязь шкал измерения и мер вариации
Что касается мер вариации, то прииспользовании номинальной шкалы
применяется распределение частот,
при использовании шкалы порядков —
кумулятивное распределение частот,
при использовании интервальной шкалы
и шкалы отношений — среднее
квадратическое отклонение.
69. Выводной анализ. Понятие вывода
Вывод является видом логическогоанализа, направленного на получение
общих заключений о всей совокупности на
основе наблюдений за малой группой
единиц данной совокупности.
Выводы делаются на основе анализа малого
числа фактов. Например, если два ваших
товарища, имеющих одну и ту же марку
автомобиля, жалуются на его качество, то вы
можете сделать вывод о низком качестве
данной марки автомобиля в целом.
70. Выводной анализ
Статистический вывод основан настатистическом анализе результатов
выборочных исследований и направлен на
оценку параметров совокупности в целом.
Анализ, в основе которого лежит
использование статистических процедур
(например, проверка гипотез) с целью
обобщения полученных результатов на
всю совокупность, называется выводным
анализом.
71. Пример
Автомобилестроительная компания провела дванезависимых исследования с целью определения
степени удовлетворенности потребителей своими
автомобилями.
Первая выборка включала 100 потребителей,
купивших данную модель в течение последних шести
месяцев.
Вторая выборка включала 1000 потребителей.
В ходе телефонного интервьюирования респонденты
отвечали на вопрос: «Удовлетворены вы или не
удовлетворены купленной вами моделью
автомобиля?»
Первый опрос выявил 30%неудовлетворенных,
второй — 35%
72. Какой же общий вывод можно сделать в данном случае?
Существуют ошибки выборки и в первом и вовтором случаях,? Как избавиться от термина
«около»? Для этого введем показатель ошибки:
30% ± х% и 35% ± у% и сравним х и у.
Используя логический анализ, можно сделать
вывод, что большая выборка содержит
меньшую ошибку и что на ее основе можно
сделать более правильные выводы о
мнении всей совокупности потребителей.
Видно, что решающим фактором для
получения правильных выводов является
размер выборки.
Данный показатель присутствует во всех
формулах, определяющих содержание
различных методов статистического вывода.
73. Методы выводного анализа
При проведении маркетинговыхисследований чаще всего используются
следующие методы статистического вывода:
оценка параметров
проверка гипотез
(подробнее см. учебник Голубкова Е.П.
«Маркетинговые исследования», стр. 191194)
74. Анализ различий
Анализ различий используется длясравнения результатов исследования
двух групп (двух рыночных сегментов)
для определения степени реального
отличия в их поведении
Кроме того, в ряде случаев
представляет интерес сравнение
ответов на два или более независимых
вопросов для одной и той же выборки.
75. Пример анализа различий
Примером первого случая может служить изучениевопроса: что предпочитают пить по утрам жители
определенного региона: кофе или чай.
Первоначально было опрошено на основе
формирования случайной выборки 100
респондентов, 60% которых отдают предпочтение
кофе; через год исследование было повторено, и
только 40% из 300 опрошенных человек высказалось
за кофе.
Как можно сопоставить результаты этих двух
исследований?
Прямым арифметическим путем сравнивать 40% и
60% нельзя из-за разных ошибок выборок.
Хотя в случае больших различий в цифрах, скажем,
20 и 80%, легче сделать вывод об изменении вкусов
в пользу кофе.
76. Как можно сопоставить результаты этих двух исследований?
При проведении подобного сравнения в расчетнеобходимо принять два критических фактора: степень
существенности различий между величинами параметра
для двух выборок и средние квадратические ошибки двух
выборок, определяемые их объемами.
Для проверки, является ли существенной разница
измеренных средних, используется нулевая гипотеза.
Нулевая гипотеза предполагает, что две совокупности,
сравниваемые по одному или нескольким признакам,
не отличаются друг от друга.
При этом предполагается, что действительное различие
сравниваемых величин равно нулю, а выявленное по
данным отличие от нуля носит случайный характер
77. Как можно сопоставить результаты этих двух исследований?
Для проверки существенности разницы между двумяизмеренными средними (процентами) вначале
проводится их сравнение, а затем полученная разница
переводится в значение среднеквадратических ошибок,
и определяется, насколько далеко они отклоняются от
гипотетического нулевого значения.
Как только определены среднеквадратические ошибки,
становится известной площадь под нормальной кривой
распределения и появляется возможность сделать
заключение о вероятности выполнения нулевой
гипотезы.
Подробнее см. учебник Голубкова Е.П.
«Маркетинговые исследования», стр. 194-196)
78. Анализ связей
Анализ связей направлен на определениесистематических связей (их направленности
и силы) переменных.
Очень часто маркетолог ищет ответы на
вопросы типа:
- «Увеличится ли показатель рыночной доли
при увеличении числа дилеров?»,
- «Есть ли связь между объемом сбыта и
рекламой?»
В поставленных вопросах можно
определенно говорить о влиянии одного
фактора на другой
79. Типы связей
Связь между двумя переменными может бытьсильной, умеренной, слабой или
отсутствовать.
Сильная зависимость характеризуется
высокой вероятностью существования связи
между двумя переменными, слабая — малой
вероятностью.
Существуют специальные процедуры для
определения указанных выше характеристик
связей.
Подробнее см. учебник Голубкова Е.П.
«Маркетинговые исследования», стр. 195-201
80. Корреляционный анализ
Теснота связи и ее направлениеопределяются путем расчета
коэффициента корреляции, который
изменяется от -1 до +1.
Абсолютная величина коэффициента
корреляции характеризует тесноту связи, а
знак указывает на ее направление
81. Сила связи в зависимости от величины коэффициента корреляции
Коэффициенткорреляции
От±0, 81 до±1,00
Сила связи
От ±0,61 до ±0, 80
Умеренная
От±0,41 до±0,6
Слабая
От ±0,21 до ±0,4
Очень слабая
От±0,00до ±0,19
Отсутствует
Сильная
82. Итог анализа: корреляция между числом сбытовиков и объемами продаж
83. Предсказательный анализ
Предсказательный анализиспользуется в целях
прогнозирования развития событий
в будущем, например, путем
анализа временных рядов.
Здесь используются
статистические методы
прогнозирования
84. Вопрос аудитории
В чем разницамежду методами
проведения
исследований и
методами обработки
и анализа данных?
85. Выбор методов обработки и анализа данных
Методология маркетингового анализапроистекает из его целей. Она
определяется предметом анализа и в
известной мере обусловлена характером
имеющейся информации.
Наиболее широко в перечне методов
маркетингового анализа представлена
статистика.
86. Классификация методов обработки и анализа данных
Статистические методы обработки информации:абсолютные, средние и относительные
величины;
динамические ряды и ряды распределения;
группировки;
индексный анализ;
вариационный и дисперсионный анализ;
корреляционно-регрессионный анализ;
графический метод, трендовые модели, методы
экспертных оценок.
87. Классификация методов обработки и анализа данных
Многомерные методы (в первую очередьфакторный и кластерный анализы). Они
используются для обоснования маркетинговых
решений, в основе которых лежат
многочисленные взаимосвязанные переменные.
Например, определение объема продаж нового
продукта в зависимости от его технического
уровня, цены, конкурентоспособности, затрат на
рекламу и др.
88. Классификация методов обработки и анализа данных
Регрессионные и корреляционные методы. Онииспользуются для установления взаимосвязей между
группами переменных, описывающих маркетинговую
деятельность.
Имитационные методы. Они применяются тогда, когда
переменные, влияющие на маркетинговую ситуацию
(например, описывающие конкуренцию), не поддаются
определению с помощью аналитических методов.
Методы статистической теории принятия решений
(теория игр, теория массового обслуживания,
стохастическое программирование) используются для
стохастического описания реакции потребителей на
изменение рыночной ситуации
89. Классификация методов обработки и анализа данных
Детерминированные методы исследования операций (впервую очередь линейное и нелинейное
программирование). Эти методы применяют тогда, когда
имеется много взаимосвязанных переменных и надо найти
оптимальное решение — например, вариант доставки
продукта потребителю, обеспечивающий максимальную
прибыль, по одному из возможных каналов
товародвижения.
Гибридные методы, объединяющие детерминированные
и вероятностные (стохастические) характеристики
(например, динамическое и эвристическое
программирование), применяются прежде всего для
исследования проблем товародвижения
90. Классификация методов обработки и анализа данных
В маркетинговом анализе широкоприменяются матричные модели, в
частности стратегически матрицы . Их
часто используют для целей разработки
оптимальной стратегии.
Известная роль принадлежит также
неформальному описательному и
качественному анализу, сценариям
развития и т.п.
91. Выбор конкретных методов анализа диктуется рядом факторов:
сущностью изучаемых процессов иявлений;
степенью срочности получения выводов;
структурой сведений;
доступностью или ограниченностью
информации;
возможностями применения компьютерной
технологии.
92. Итак,
Эти группы количественных методов, безусловно, неисчерпывают всего их разнообразия.
Широта применения тех или иных методов при
проведении маркетинговых исследований
определяется возможностями компании. Очевидно, что
у крупных организаций таких возможностей существенно
больше, чем у организаций малого бизнеса.
Уровень глубины анализа определяется целью
исследования и показывает степень освоения различных
статистических и эконометрических методов сводки,
группировки и анализа информации, которые позволяют
получить оценку исследуемых проблем и выявить
причинно-следственные связи для формулировки выводов
и рекомендаций.
93.
94. \
Моосмюллер Г., РебикН.Н., Инфра-М | 2007 г.
В пособии подробно описаны
основные методы
статистического анализа,
применяемые при обработке
маркетинговой информации с
использованием программного
комплекса SPSS.
Приводятся детальные
инструкции пользования
программой, показано, как
проводить поэтапную
интерпретацию результатов
анализа.
95. Спасибо за внимание!
96. Домашнее задание
Изучите материалы презентацииПодготовитесь к практическому занятию:
ответьте на вопросы для самопроверки
знаний и подготовки к тестированию (тема
9)
Изучите рекомендованную литературу
Проанализируйте содержание реального
маркетингового исследования и ответьте
на поставленные вопросы