



Similar presentations:










ВКР
1.
Проектирование системымаркировки текстовых
документов для защиты
авторских прав с
использованием
лингвистической
стеганографии
Студент: Габдрахманов А. Н.
2.
Актуальность проблемыНевидимая угроза цифровому контенту
Масштаб
Слабость защиты
Вывод
Более 76% компаний ежегодно
68% судебных споров по авторским
Существующие методы защиты
теряют $180+ млрд из-за кражи
правам проигрываются из-за
либо легко обходятся, либо
интеллектуальной собственности.
отсутствия неоспоримых
неприменимы на практике.
доказательств.
3.
Существующие методы и их недостаткиМетод
Суть
Ключевая проблема
Юридические (РАО,
Формальная фиксация
Не защищает от копирования, дорого,
нотариус)
Технические (водяные
медленно
Внедрение видимой/невидимой метки
знаки, метаданные)
Криптографические
Легко удаляются при копировании и
редактировании
Создание цифрового "слепка"
Теряют силу при любом изменении текста
Сравнение с базой данных
Не работают для неопубликованных и
(подписи, хэши)
Платформенные
(антиплагиат)
измененных текстов
4.
Цель и задачи исследованияЦель: Проектирование системы маркировки текстовых документов для защиты авторских прав с использованием лингвистической
стеганографии
1
2
Аналитическая
Алгоритмическая
Провести сравнительный анализ современных методов
Разработать и реализовать алгоритм маркировки на основе
лингвистической стеганографии.
арифметического кодирования и нейросетевой языковой
модели (например, ruGPT-3).
3
4
Инженерная
Экспериментальная
Спроектировать и реализовать прототип системы с модулями
Провести всестороннее тестирование прототипа на
маркировки и верификации.
незаметность, емкость и устойчивость к редактированию.
5.
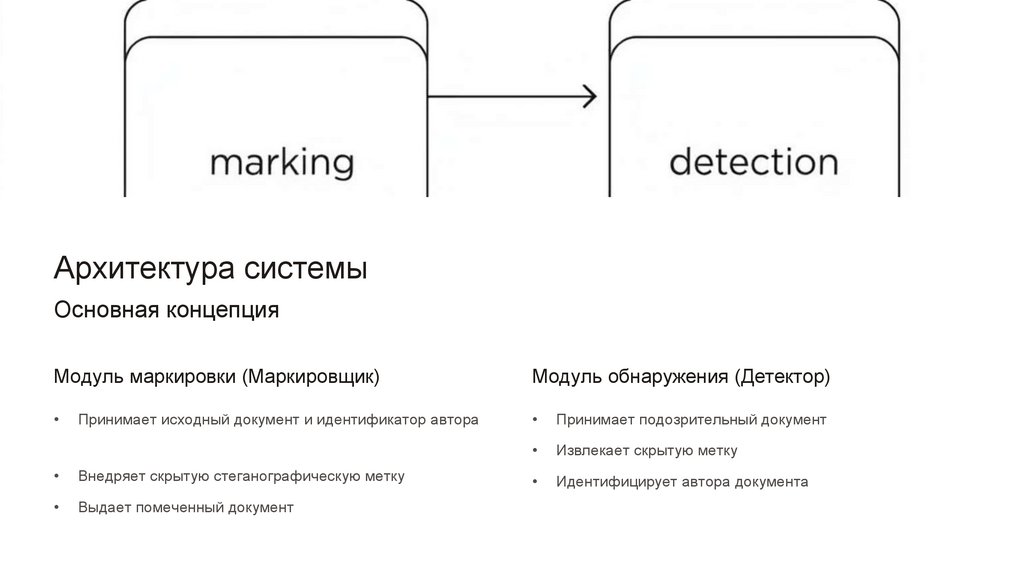
Архитектура системыОсновная концепция
Модуль маркировки (Маркировщик)
Модуль обнаружения (Детектор)
Принимает подозрительный документ
Извлекает скрытую метку
Идентифицирует автора документа
Принимает исходный документ и идентификатор автора
Внедряет скрытую стеганографическую метку
Выдает помеченный документ
6.
Принцип арифметического кодированияОсновная идея: Преобразовать ID автора в последовательность слов, которая статистически неотличима от обычного текста.
Аналогия: Секретное сообщение (ID) — это число от 0 до 1. Мы ищем его на "линейке", где у каждого слова — свой отрезок, пропорциональный
его вероятности.
Процесс на примере:
Сообщение: 011 (в двоичной системе = 0.375)
Контекст: "Кот сидит на..."
Модель предсказывает: "полу" (вер-ть 0.5), "кресле" (0.3), "столе" (0.2)
Шаг
Текущий интервал
Распределение слов
Выбор
1
[0.0, 1.0)
полу [0.0-0.5), кресле [0.5-0.8), столе [0.8-1.0)
полу (0.375 ∈ [0.0-0.5))
2
[0.0, 0.5)
и [0.0-0.3), , [0.3-0.5)
, (0.375 ∈ [0.3-0.5))
Результат: Сообщение 011 превратилось в текст "Кот сидит на полу," без потери смысла!
Ключевое преимущество: Такой текст невозможно отличить от настоящего статистическими методами.
7.
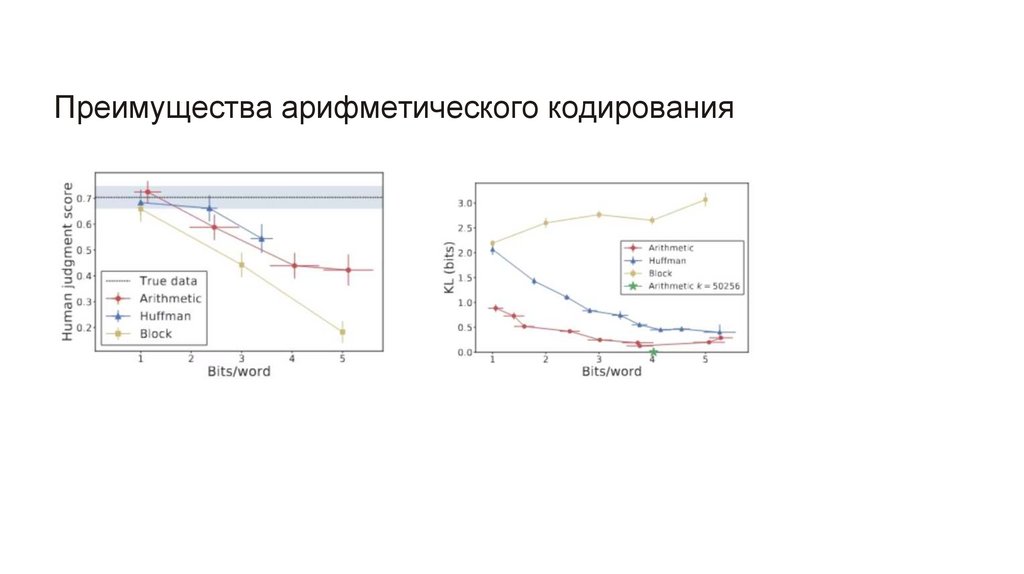
Преимущества арифметического кодирования8.
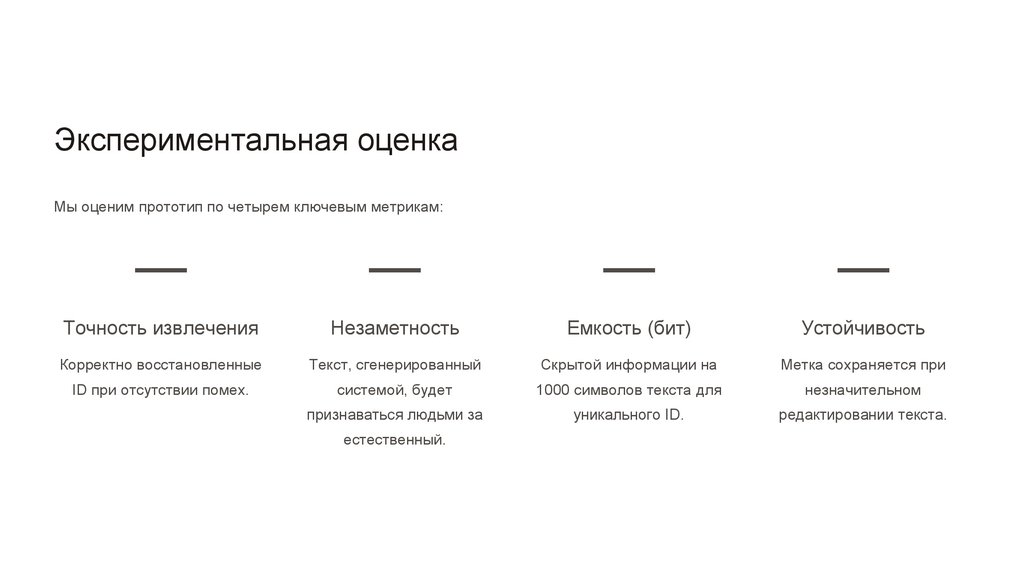
Экспериментальная оценкаМы оценим прототип по четырем ключевым метрикам:
—
—
—
—
Точность извлечения
Незаметность
Емкость (бит)
Устойчивость
Корректно восстановленные
Текст, сгенерированный
Скрытой информации на
Метка сохраняется при
ID при отсутствии помех.
системой, будет
1000 символов текста для
незначительном
признаваться людьми за
уникального ID.
редактировании текста.
естественный.
9.
Ожидаемые результаты и научная новизнаГлавный результат: Работоспособный прототип системы маркировки текстовых документов превосходящий по незаметности
и устойчивости традиционные стеганографические методы.
Научная и практическая новизна:
Адаптация метода
арифметического
кодирования
Комплексная оценка
Практическая ценность
Систематическое сравнение
Инструмент для журналистов,
метода не только по техническим
копирайтеров, ученых и юристов
Практическая реализация
(KL-дивергенция), но и по
для невидимой маркировки
стеганографии на основе
практическим метрикам.
текстов с целью последующего
арифметического кодирования
и больших языковых моделей
для защиты авторских прав
текстов на русском языке.
доказательства авторства.