











 software
softwareSimilar presentations:

")
")







Data Version Control
1. Data Version Control
Манина Антонина АндреевнаСтарший дата аналитик
2. DVC – для чего нужен?
1. Git используется для версионирования кода и не предназначен дляхранения файлов с данными (данные хранятся на HDFS)
2. DVC применяется для работы с датасетами и обеспечивает:
• Соответствие версии кода и данных (важно в командной работе)
• Управление пайплайном формирования датасетов (очередность
расчёта признаков)
3. Сценарии использования DVC в проекте
Рассмотрим практические примеры использования следующихсценариев:
- Версионирование данных. Управление отдельными файлами в
dvc
- Управление пайплайном формирования датасетов
(очередность расчёта признаков)
4. Версионирование данных. Управление отдельными файлами в dvc
https://habr.com/ru/company/raiffeisenbank/blog/461803/5. Подготовительные работы
• Создаём рабочую папку иокружение
• Активируем окружение
• Скачиваем dvc и pandas
внутри локального окружения
• Создаём репозиторий dvc_test
на GitLab и клонируем его
6. Сценарий 1. Отправление файлов в DVC
• Создаём рабочую веткуscenario_1
• Настраиваем DVC:
• Инициализируем DVC
• Добавляем удалённое хранилище
данных
• Добавляем в репозиторий
структуру и скрипт генерации
датасета
• Запускаем скрипт и добавляем
в dvc новый .csv файл
• Пушим все изменения в git
• Пушим файл в хранилище
7. Сценарий 1. Что же дальше?
• Удаляем локально репозиторий• Скачиваем его ещё раз и
переключаемся на рабочую ветку
• Подкачиваем данные из
удалённого хранилища с командой
dvc pull
• Смотрим, что получилось
8. Сценарий 2. Добавляем новый признак
• Переходим на ветку scenario_2• Изменяем файл step1 и запускаем
его, чтобы обновился файл с
данными
• Позволяем dvc учесть изменения в
новом файле
• Коммитим и пушим в git
• Пушим файл в dvc
• Профит! Теперь к каждому коммиту
с изменённым состоянием
признаков привязана ссылка dvc на
файл в удалённом хранилище
• Преимущества: трекаем все
состояния признаков,
воспроизводим все эксперименты с
моделями
9. Сценарий 3. Рисуем схему данных
• Переходим на новую рабочуюветку scenario_3
• Удаляем файлы с данными
• Добавляем dvc.yaml конфиг –
внутри него находятся
настройки пайплайна: порядка
воспроизведения скриптов
• Запускаем пайплайн
• Добавляем файлы и
отправляем в git
• Изучаем файл dvc.lock
• https://dvc.org/doc/start/datapipelines/data-pipelines
10. Сценарий 4. Добавляем ещё один шаг в пайплайн
Сценарий 4. Добавляем ещё один шаг в•пайплайн
Переходим на новую
рабочую ветку scenario_4
• Добавляем скрипт с
насчётом таргета
• Внутри dvc.yaml добавляем
ещё один шаг
• Пересчитываем пайплайн
командой dvc repro
• Коммит в гит
• Пушим в удалённое dvc
хранилище
• Смотрим на cхему dvc dag
• https://dvc.org/doc/start/datapipelines/data-pipelines
11. Добавление шагов пайплайна
• dvc stage add\• --name step1_prepare_dataset \
• --deps ../src/step1_prepare_dataset.py \
• --outs ../data/step1_result_file.csv \
• python -u ../src/step1_prepare_dataset.py
• dvc stage add \
• --name step2_get_target \
• --deps ../src/step2_get_target.py \
• --deps ../data/step1_result_file.csv \
• --outs ../data/step2_result_file.csv \
• python -u ../src/step2_get_target.py
12. Домашнее задание
• Инициализировать dvc в проекте• В виртуальном окружении установить dvc: poetry add dvc
• Инициализировать dvc в репозитории: dvc init
• Настроить локальное хранилище данных
• Добавление удалённого хранилища данных: dvc remote add –d myremote ../dvc_storage
• Настроить пайплайн подготовки датасетов
• dvc repro <step>
• dvc push
• Нарисовать схему dvc dag и приложить в МР
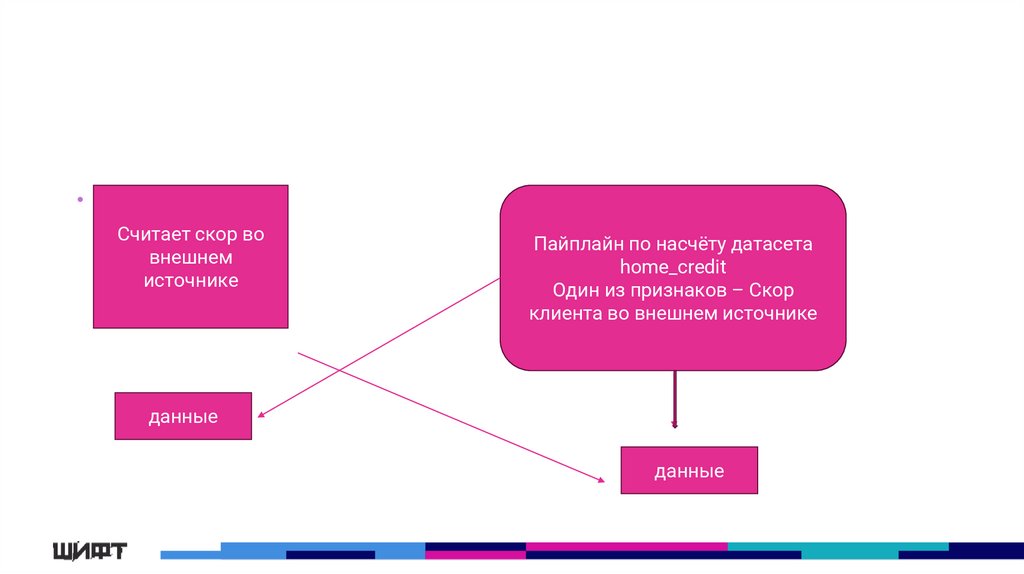
13.
• ДаСчитает скор во
внешнем
источнике
Пайплайн по насчёту датасета
home_credit
Один из признаков – Скор
клиента во внешнем источнике
данные
данные