






 mathematics
mathematicsSimilar presentations:










Доверительные интервалы. Проверка гипотез. Коэффициенты корреляции. Тема № 4.4
1.
Тема № 4.4Доверительные интервалы. Проверка
гипотез. Коэффициенты корреляции
Лекция
2.
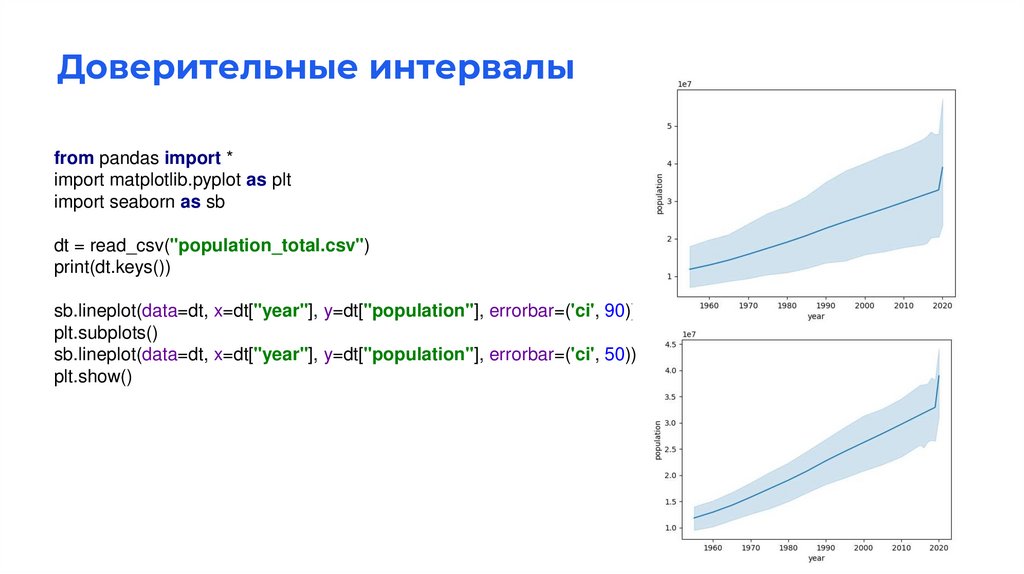
Доверительные интервалыВ математической статистике интервальной оценкой называется результат
использования выборки для вычисления интервала возможных значений неизвестного
параметра, оценку которого нужно построить. Следует отличать от точечной оценки,
которая даёт лишь одно значение. Самым распространенным видом интервальных
оценок являются доверительные интервалы.
Простыми словами - доверительный интервал это диапазон значений в котором с
определённой вероятностью находится искомое.
3.
Доверительные интервалыfrom pandas import *
import matplotlib.pyplot as plt
import seaborn as sb
dt = read_csv("population_total.csv")
print(dt.keys())
sb.lineplot(data=dt, x=dt["year"], y=dt["population"], errorbar=('ci', 90))
plt.subplots()
sb.lineplot(data=dt, x=dt["year"], y=dt["population"], errorbar=('ci', 50))
plt.show()
4.
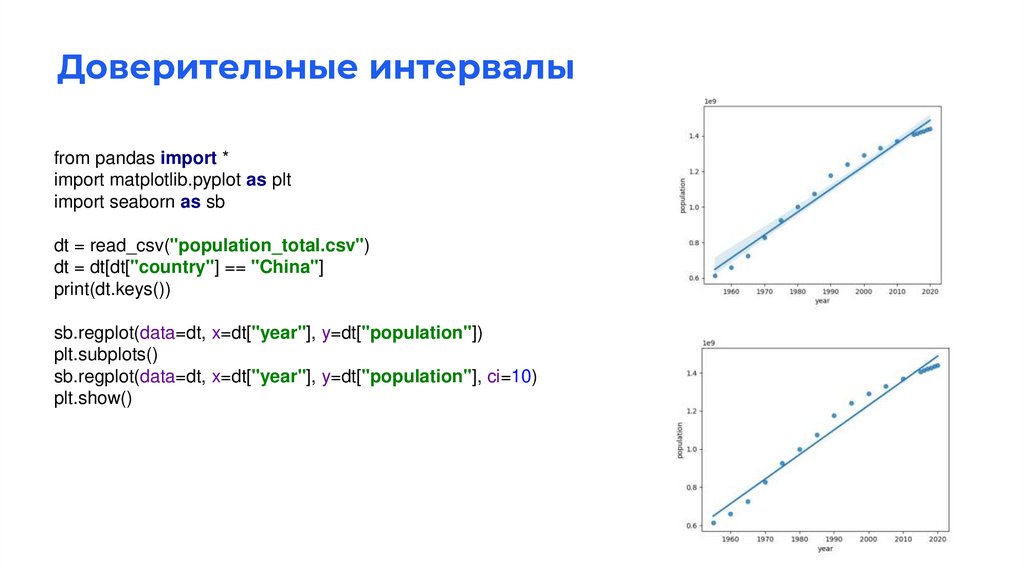
Доверительные интервалыfrom pandas import *
import matplotlib.pyplot as plt
import seaborn as sb
dt = read_csv("population_total.csv")
dt = dt[dt["country"] == "China"]
print(dt.keys())
sb.regplot(data=dt, x=dt["year"], y=dt["population"])
plt.subplots()
sb.regplot(data=dt, x=dt["year"], y=dt["population"], ci=10)
plt.show()
5.
6.
Проверка гипотезimport scipy.stats as st
from pandas import *
dt = read_csv("weight-height.csv")
dta = dt["Weight"]
dtm = dt[dt["Gender"] == "Male"]["Weight"]
dtf = dt[dt["Gender"] == "Female"]["Weight"]
#p>0.05 и p<1 Одновыборочный t-критерий
print(st.ttest_1samp(a=dta, popmean=161))
#p>0.05 и p<1 Двухвыборочный t-критерий
print(st.ttest_ind(a=dtm, b=dtf))
#p>0.05 и p<1 Стьюдентный критерий для парных выборок
print(st.ttest_rel(a=dtm, b=dtf))
pvalue=0.17026001640854646
pvalue=0.0
pvalue=0.0
Одновыборочный t-критерий используется для
проверки того, равно ли среднее значение
совокупности некоторому значению.
Двухвыборочный t-критерий используется для
проверки того, равны ли средние значения двух
совокупностей.
Стьюдентный критерий для парных
выборок используется для сравнения средних
значений двух выборок, когда каждое
наблюдение в одной выборке может быть
сопоставлено с наблюдением в другой выборке.
7.
Проверка гипотезimport scipy.stats as st
import pandas as pd
df = pd.read_csv("/content/drive/MyDrive/data/weightheight.csv")
dtm = df[df["Gender"] == "Male"]["Weight"]
dtf = df[df["Gender"] == "Female"]["Weight"]
statistic, p = st.mannwhitneyu(dtm, dtf)
print(p)
Тест Манна-Уитни - это
непараметрический статистический тест
для сравнения двух независимых
выборок. Используется когда:
• Данные не распределены нормально
• Данные представлены в порядковой
шкале
• Выборки независимые
8.
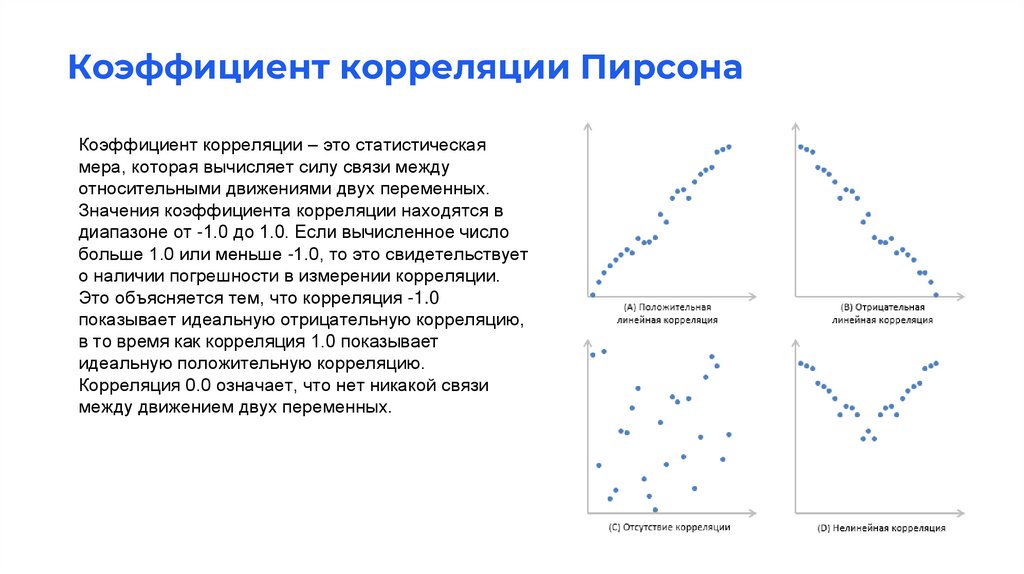
Коэффициент корреляции ПирсонаКоэффициент корреляции – это статистическая
мера, которая вычисляет силу связи между
относительными движениями двух переменных.
Значения коэффициента корреляции находятся в
диапазоне от -1.0 до 1.0. Если вычисленное число
больше 1.0 или меньше -1.0, то это свидетельствует
о наличии погрешности в измерении корреляции.
Это объясняется тем, что корреляция -1.0
показывает идеальную отрицательную корреляцию,
в то время как корреляция 1.0 показывает
идеальную положительную корреляцию.
Корреляция 0.0 означает, что нет никакой связи
между движением двух переменных.
9.
Коэффициент корреляции Пирсонаimport scipy.stats as st
from pandas import *
dt = read_csv("weight-height.csv")
dta = dt[["Weight", "Height"]]
dtm = dt[dt["Gender"] == "Male"]["Weight"]
dtf = dt[dt["Gender"] == "Female"]["Weight"]
#Коэффициент корреляции Пирсона
print(st.pearsonr(dtm, dtf))
#вычисление корреляции между несколькими переменными
print(dta.corr())
print(dt["Weight"].corr(dt["Height"]))
Коэффициент корреляции Пирсона,
измеряющий линейную связь между двумя
переменными.
Всегда принимает значение от -1 до 1, где:
• -1 указывает на совершенно отрицательную
линейную корреляцию
• 0 указывает на отсутствие линейной
корреляции
• 1 указывает на совершенно положительную
линейную корреляцию
statistic=-0.019590166861499746, pvalue=0.16604618806632282
Weight Height
Weight 1.000000 0.924756
Height 0.924756 1.000000
0.9247562987409148
10.
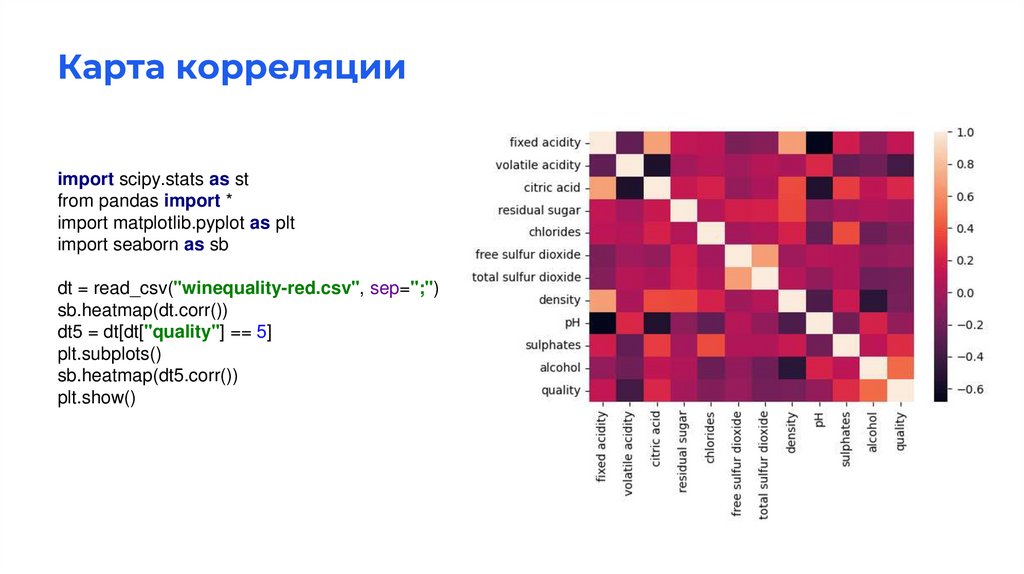
Карта корреляцииimport scipy.stats as st
from pandas import *
import matplotlib.pyplot as plt
import seaborn as sb
dt = read_csv("winequality-red.csv", sep=";")
sb.heatmap(dt.corr())
dt5 = dt[dt["quality"] == 5]
plt.subplots()
sb.heatmap(dt5.corr())
plt.show()
11.
Вашивопросы
12.
Подведём итоги➜ Что вам больше всего понравилось
в сегодняшнем занятии?
➜ Что вызвало трудности?