














 software
softwareSimilar presentations:


")






")
Сопровождение автоматизированных информационных систем. Повышение отказоустойчивости систем
1.
Сопровождение автоматизированныхинформационных систем
Повышение отказоустойчивости систем
Сарафанов Дмитрий
+79022550258
2.
Зачем это нужно?Отказ работоспособности инфраструктуры выливается в
следующие проблемы:
• Убытки для бизнеса
• Репутационные потери
Убытки для бизнеса - потери из оплаты сотрудников за время
простоя, и упущенной за это время прибыли. Также нужно
добавить суммы, затраченные на сам ремонт и
восстановление системы.
3.
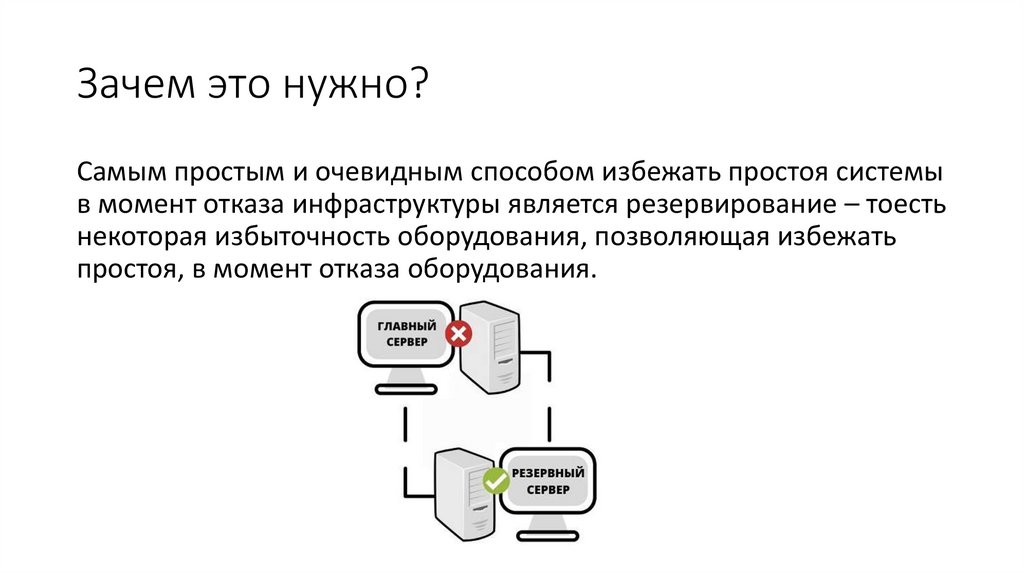
Зачем это нужно?Самым простым и очевидным способом избежать простоя системы
в момент отказа инфраструктуры является резервирование – тоесть
некоторая избыточность оборудования, позволяющая избежать
простоя, в момент отказа оборудования.
4.
Типы резервирования• Резервирование на самих узлах сервера
• Резервирование серверов
• Резервирование типа инфраструктуры
5.
Резервирование на самих узлахсервера
• Оперативная память
• Серверы имеют особый режим работы памяти: Memory Mirroring или Mirrored memory
protection. В этом режиме осуществляется зеркалирование каналов, то есть каналы
разбиваются на пары, и в каждой паре один из каналов становится копией другого. Все
банки памяти при этом должны быть сконфигурированы идентично.
• Недостатком такой организации является двукратное уменьшение объёма оперативной
памяти. Или, иными словами, двукратное увеличение ее стоимости.
• Диски
• Аналогично оперативной памяти можно организовать зеркалирование дисков. Для этого
каждому диску назначается дубликат, который содержит его полную копию благодаря
тому, что информация одновременно записывается на диск и дублирующую его копию. В
простейшем случае такая система состоит из двух одинаковых дисков.
• Питание
• Серверы среднего и старшего уровня имеют по два блока питания. В случае выхода из
строя одного из них, сервер продолжает работать от второго. Иногда серверы
оснащаются тремя и более блоками питания. В этом случае один из них остаётся
резервным (так называемая схема N+1), либо БП дублируются (схема N+N). В
последнем случае их число должно быть чётным.
6.
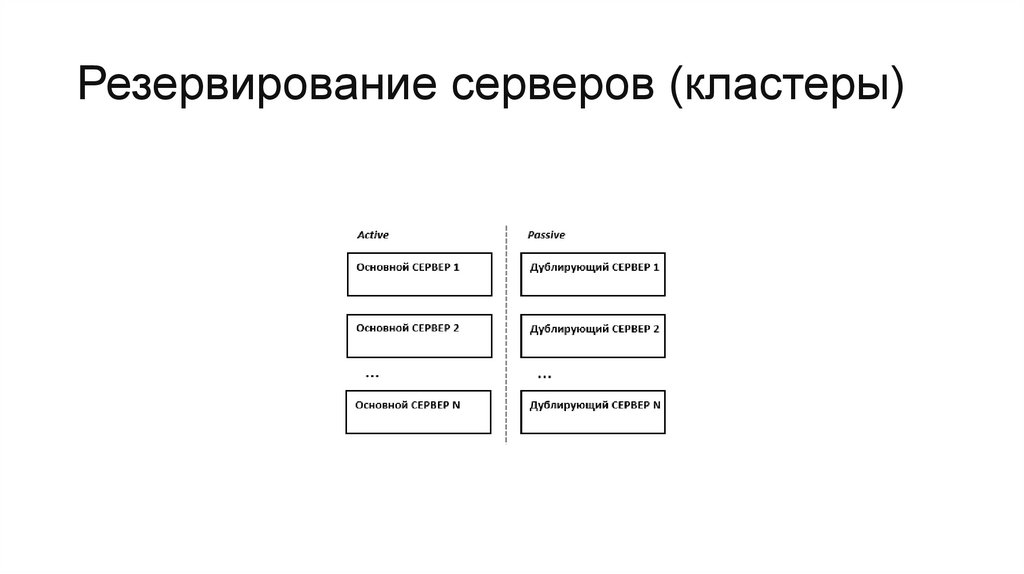
Резервирование серверов (кластеры)• В подобных случаях применяется резервирование сервера
целиком. C помощью специального программного обеспечения
несколько серверов объединяются в единую систему. В случае
аварии на одном из них, его нагрузка перекладывается на
другие, входящие в систему.
• В простейшем и самом распространённом случае система
состоит из двух серверов, один из которых является основным, а
другой —дублирующим, резервным
(конфигурация active/passive). Все вычисления производятся на
основном сервере, а дублирующий сервер включается в работу
в случае аварии на основном. Такая конфигурация является
затратной, так как каждый узел дублируется. На схеме ниже
показана конфигурация active/passive, состоящая из нескольких
(N) серверов.
7.
Резервирование серверов (кластеры)8.
Резервирование серверов (кластеры)• В другом варианте построения кластера серверы (два или
больше) могут иметь равноценный статус, то есть работать
одновременно (конфигурация active/active). В такой
конфигурации нагрузка вышедшего из строя сервера
распределяется по остальным серверам кластера. Если
серверов в кластере немного, то скорее всего произойдёт
снижение производительности, так как нагрузка на
оставшиеся в кластере серверы возрастёт.
9.
Резервирование серверов (кластеры)• Третьим, альтернативным вариантом,
который позволяет избежать как высоких
расходов, так и потери
производительности кластера при отказе
одного из узлов, является конфигурация
N+1. В этой конфигурации кластер имеет
один полноценный резервный сервер,
который при работе в обычном режиме не
несёт на себе никакой нагрузки, а
включается в работу только в случае
отказа одного из активных серверов.
10.
Отказоустойчивость СХД• К системам хранения данных в части обеспечения
отказоустойчивости предъявляются более высокие
требования, чем к серверам. Проблема неисправности
сервера в большинстве случаев относительно легко
решается его ремонтом или заменой. В то же время потеря
данных может оказать серьёзное негативное влияние на
бизнес и принести существенные убытки.
11.
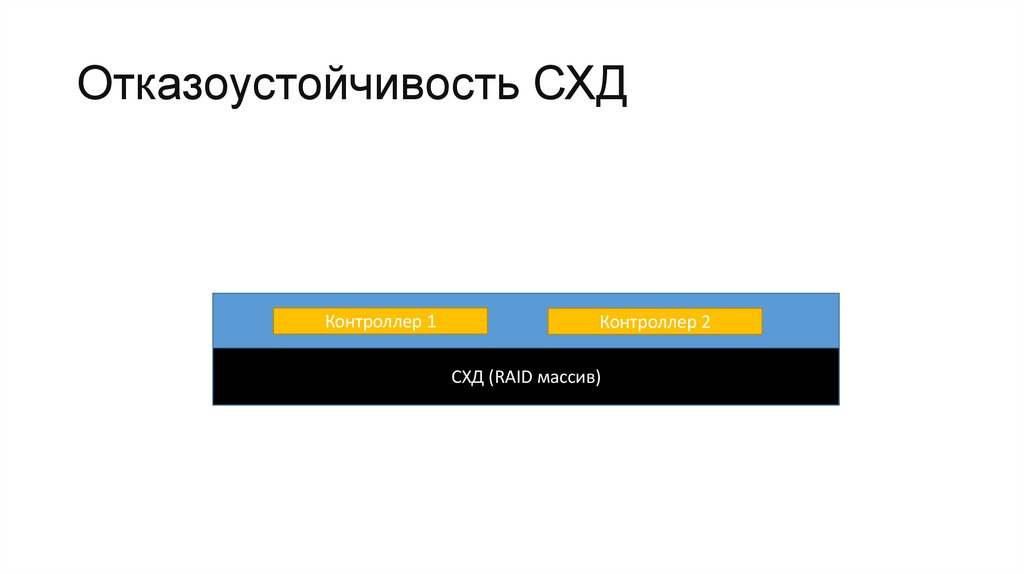
Отказоустойчивость СХД• Во всех СХД корпоративного класса применяется
дублирование контроллеров, благодаря чему при выходе из
строя одного из них доступ к данным сохраняется.
• СХД используют организацию дисков в RAID-массивы,
которые позволяют восстановить данные при отказе
нескольких дисков массива.
• СХД имеет кластерные конфигурации, когда несколько СХД
объединяются в единую систему. Такая система состоит из
нескольких контроллеров (принадлежащих разным
физическим СХД), а данные могут быть распределены
между различными СХД, входящими в её состав.
12.
Отказоустойчивость СХДКонтроллер 1
Контроллер 2
СХД (RAID массив)
13.
Резервирование kubernetes• Масштабируется автоматически (при использовании
автоскелинга).
• В случае если что-то произойдет, восстановится само.
• Много воркер нод, много мастеров. При выходе нескольких
рабочих нод или мастеров из строя, наш кластер
перебалансируется, и приложение продолжит работать
14.
Резервирование kubernetes• Горячий резерв кластера. То есть кластер, на который вы
можете переключиться в любой момент. При этом с точки
зрения кубера, инфраструктуры должны быть полностью
идентичными.
• Параллельный деплой – самое простое и верное решение
для построения резервного кластера
• Резерв не должен находиться на той же
площадке/машинном зале.
• Разделение нагрузки (nginx)
15.
Healthcheck и probes• Liveness (работоспособности) и readiness (готовности)
пробы это два основных типа проверок, доступных в kube.
Они имеют схожий интерфейс настройки, но разные
значения для платформы.
• Когда liveness проверка не проходит, то это сигнализирует
kube, что контейнер мертв и должен быть перезагружен.
• Когда readiness проверка не проходит, то это опознается
kube как то, что проверяемый контейнер не готов к
принятию входящего сетевого трафика. В будущем это
приложение может прийти в готовность, но сейчас оно не
должно принимать трафик.
16.
Liveness probe• Если liveness проверка успешна, и в то же время readiness
проверка не прошла, kube знает, что контейнер не готов
принимать сетевой трафик. Например, часто приложениям
нужно длительное время для инициализации и старта.
• Liveness проверка отправляет сигнал kube, что контейнер
либо жив, либо мертв. Если контейнер жив, тогда kube не
делает ничего, потому что текущее состояние контейнера в
порядке. Если контейнер мертв, то kube пытается починить
приложение через его перезапуск.
17.
Readiness probe• Kube используют readiness проверки для того, чтобы узнать
когда проверяемый контейнер будет готов принимать сетевой
трафик. Если ваш контейнер вошел в состояние, когда он все
ещё жив, но не может обрабатывать входящий трафик (частый
сценарий во время запуска), вам нужно, чтобы readiness
проверка не проходила. В этом случае kube не будет отправлять
сетевой трафик в контейнер, который к этому не готов.
• Как и liveness проверки, название readiness проба (проба
готовности) передает семантическое значение. Фактически это
проверка отвечает на вопрос: “Готов ли этот контейнер
принимать сетевой трафик?”.
• Если вы не зададите readiness проверку, kube решит, что
контейнер готов к принятию трафика как только процесс с PID
1 запустился. Это никогда не является желаемым поведением.
18.
Readiness probe• spec:
containers:
- image: registry.sigma.ru
name: application-test
imagePullPolicy: Always
ports:
- containerPort: 8443
protocol: TCP
readinessProbe:
httpGet:
scheme: HTTPS
path: /index.html
port: 8443
initialDelaySeconds: 10
periodSeconds: 5