



 software
softwareSimilar presentations:








")

Мониторинг. Основные типы мониторинга
1.
МониторингСаидмуродов
Бегмурод
2.
Введение и основные терминыМониторинг — это процесс постоянного наблюдения за состоянием и производительностью различных
систем, устройств, приложений или процессов с целью обнаружения и анализа возможных проблем,
отклонений или улучшений. В контексте информационных технологий мониторинг часто включает в себя
сбор, анализ и визуализацию данных, таких как:
1.Ресурсы системы: использование процессора, памяти, дисков, сети и других аппаратных ресурсов.
2.Программное обеспечение и приложения: отслеживание их работы, производительности, ошибок или
сбоев.
3.Сетевые процессы: мониторинг передачи данных и сетевой активности.
4.Безопасность: отслеживание потенциальных угроз и уязвимостей.
Основные цели мониторинга:
•Предотвращение сбоев: своевременное выявление потенциальных проблем для их устранения до того, как
они приведут к сбоям или потерям данных.
•Повышение производительности: оптимизация работы системы или приложения через анализ и
настройку процессов.
•Обеспечение безопасности: контроль за безопасностью системы, обнаружение вторжений или аномальной
активности.
3.
Основные типы мониторингаМониторинг охватывает различные слои и аспекты, которые помогают обеспечивать стабильность, производительность и
безопасность системы.
1. Хост-мониторинг → Host Monitoring – отслеживание серверных ресурсов (CPU, RAM, диски).
2. Мониторинг приложений → Application Monitoring – контроль работы приложений (транзакции, ошибки).
3. Мониторинг безопасности → Security Monitoring – обнаружение угроз и уязвимостей.
4. Бизнес-мониторинг → Business Monitoring – анализ бизнес-метрик (продажи, активность пользователей).
5. Сетевой мониторинг → Network Monitoring – контроль передачи данных, активности сетевых устройств.
6. Мониторинг виртуализации и контейнеров → Virtualization & Container Monitoring – отслеживание работы
виртуальных машин и контейнеров (например, Kubernetes, Docker).
7. Мониторинг производительности и доступности → Performance & Availability Monitoring – измерение
скорости работы систем, доступности сервисов.
4.
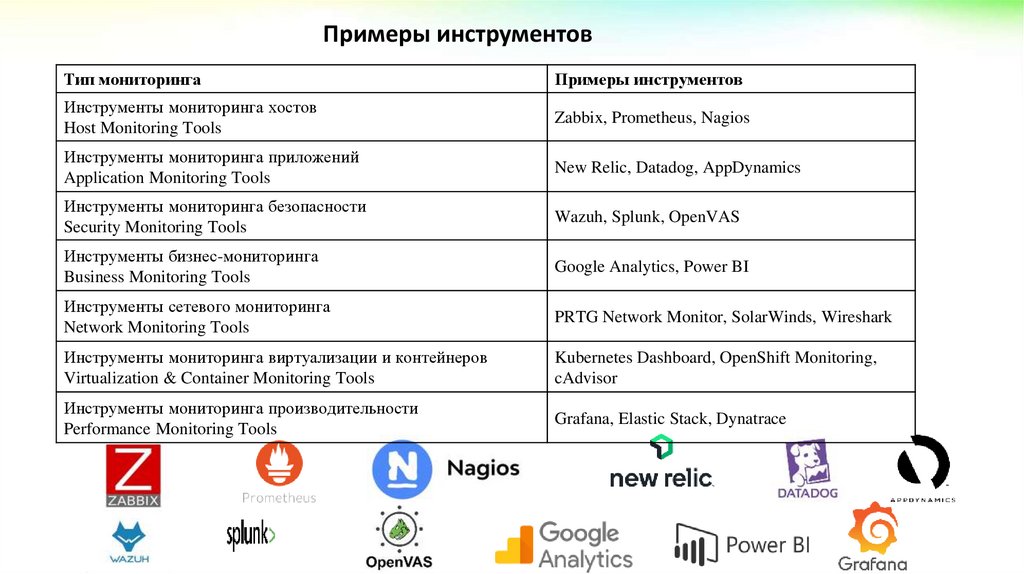
Примеры инструментовТип мониторинга
Примеры инструментов
Инструменты мониторинга хостов
Host Monitoring Tools
Zabbix, Prometheus, Nagios
Инструменты мониторинга приложений
Application Monitoring Tools
New Relic, Datadog, AppDynamics
Инструменты мониторинга безопасности
Security Monitoring Tools
Wazuh, Splunk, OpenVAS
Инструменты бизнес-мониторинга
Business Monitoring Tools
Google Analytics, Power BI
Инструменты сетевого мониторинга
Network Monitoring Tools
PRTG Network Monitor, SolarWinds, Wireshark
Инструменты мониторинга виртуализации и контейнеров
Virtualization & Container Monitoring Tools
Kubernetes Dashboard, OpenShift Monitoring,
cAdvisor
Инструменты мониторинга производительности
Performance Monitoring Tools
Grafana, Elastic Stack, Dynatrace
5.
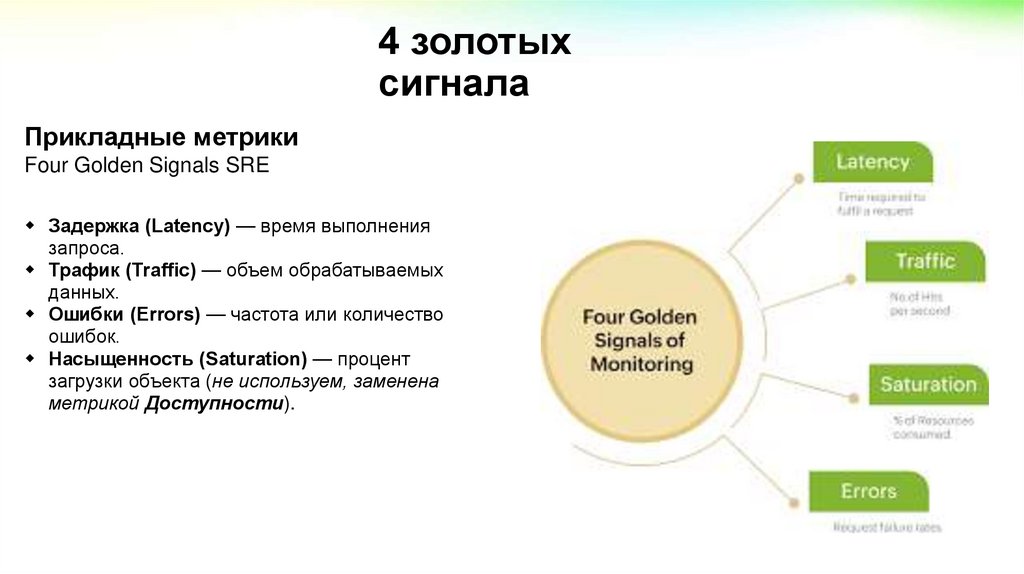
4 золотыхсигнала
Прикладные метрики
Four Golden Signals SRE
Задержка (Latency) — время выполнения
запроса.
Трафик (Traffic) — объем обрабатываемых
данных.
Ошибки (Errors) — частота или количество
ошибок.
Насыщенность (Saturation) — процент
загрузки объекта (не используем, заменена
метрикой Доступности).
6.
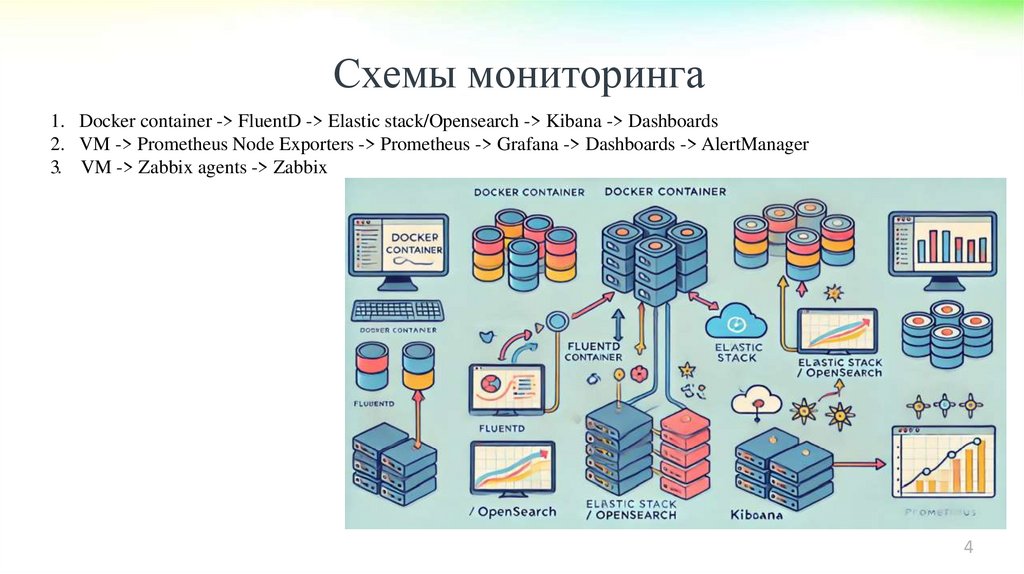
Схемы мониторинга1. Docker container -> FluentD -> Elastic stack/Opensearch -> Kibana -> Dashboards
2. VM -> Prometheus Node Exporters -> Prometheus -> Grafana -> Dashboards -> AlertManager
3. VM -> Zabbix agents -> Zabbix
4
7.
Рост сложности мониторингаС развитием технологий сложность мониторинга систем постоянно растет. Рассмотрим, как эволюция
вычислительных платформ и архитектур повлияла на этот процесс.
1.20 лет назад:
В те времена использовались одноядерные процессоры, и задачи распределялись по сети. Приложения
взаимодействовали через базы данных или общие папки. Мониторинг в таких системах был относительно
прост, так как задачи были локализованы и однозначно определялись.
2.Распространение кластерных вычислений:
Вслед за этим начали развиваться кластерные решения, что увеличило сложность как самих систем, так и их
мониторинга. Кластеры состояли из множества узлов, каждый из которых мог выполнять различные задачи, и
для мониторинга требовались более сложные инструменты.
3.Многопоточные вычисления:
С развитием многопоточности, вычисления стали еще более сложными. Программы начали параллельно
обрабатывать несколько задач, что привело к необходимости отслеживания не только отдельных процессов,
но и их взаимодействий.
4.Современные платформы и приложения:
Современные системы, такие как Node.js, требуют еще более сложного мониторинга. Например, в Node.js
происходит постоянное переключение между событиями — одно событие обрабатывается, потом
переключается на другое. Это делает анализ и понимание происходящего в приложении намного сложнее.