














































































































 programming
programmingSimilar presentations:










Понятие архитектуры ЭВМ. Принципы Фон-Неймана. Понятие ассемблера
1.
Понятие архитектуры ЭВМПринципы Фон-Неймана
Понятие ассемблера
Институт Информационных Технологий
Челябинский Государственный Университет
2.
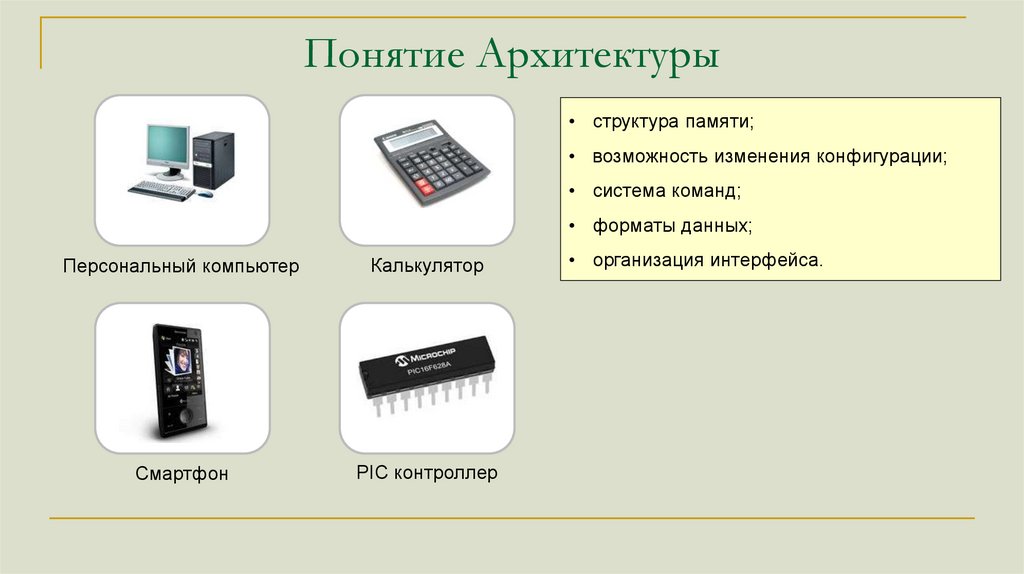
Понятие Архитектуры• структура памяти;
• возможность изменения конфигурации;
• система команд;
• форматы данных;
Персональный компьютер
Калькулятор
Смартфон
PIC контроллер
• организация интерфейса.
3.
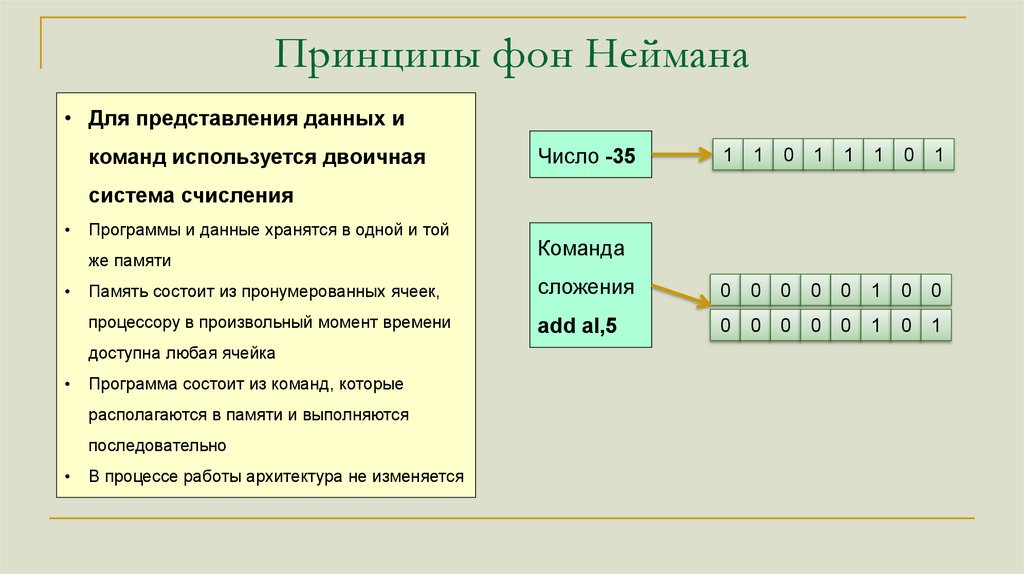
Принципы фон Неймана• Для представления данных и
команд используется двоичная
Число -35
1
1
0
1
1
1
0
1
система счисления
Программы и данные хранятся в одной и той
же памяти
Память состоит из пронумерованных ячеек,
сложения
0
0
0
0
0
1
0
0
процессору в произвольный момент времени
add al,5
0
0
0
0
0
1
0
1
доступна любая ячейка
Программа состоит из команд, которые
располагаются в памяти и выполняются
последовательно
Команда
В процессе работы архитектура не изменяется
4.
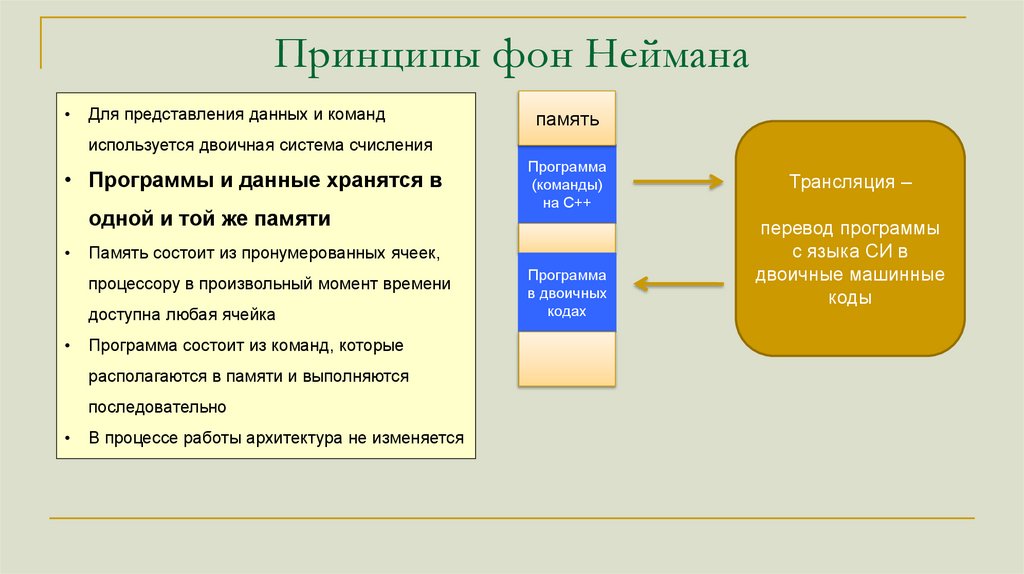
Принципы фон НейманаДля представления данных и команд
память
используется двоичная система счисления
• Программы и данные хранятся в
одной и той же памяти
Память состоит из пронумерованных ячеек,
процессору в произвольный момент времени
доступна любая ячейка
Программа состоит из команд, которые
располагаются в памяти и выполняются
последовательно
Программа
(команды)
на С++
В процессе работы архитектура не изменяется
Программа
в двоичных
кодах
Трансляция –
перевод программы
с языка СИ в
двоичные машинные
коды
5.
Принципы фон НейманаДля представления данных и команд
используется двоичная система счисления
Программы и данные хранятся в одной и той же
памяти
• Память состоит из
пронумерованных ячеек,
процессору в произвольный момент
времени доступна любая ячейка
Программа состоит из команд, которые
располагаются в памяти и выполняются
последовательно
В процессе работы архитектура не изменяется
6.
Принципы фон НейманаДля представления данных и команд
используется двоичная система счисления
Программы и данные хранятся в одной и той
же памяти
Память состоит из пронумерованных ячеек,
процессору в произвольный момент времени
доступна любая ячейка
• Программа состоит из команд,
которые располагаются в памяти и
выполняются последовательно
В процессе работы архитектура не изменяется
7.
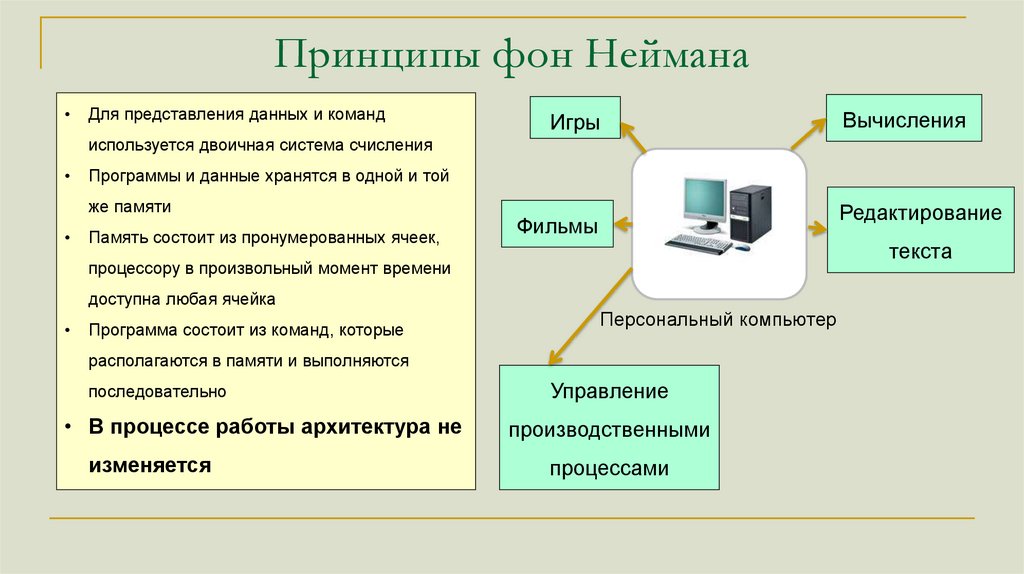
Принципы фон НейманаДля представления данных и команд
Игры
Вычисления
используется двоичная система счисления
Программы и данные хранятся в одной и той
же памяти
Память состоит из пронумерованных ячеек,
Редактирование
Фильмы
текста
процессору в произвольный момент времени
доступна любая ячейка
Программа состоит из команд, которые
Персональный компьютер
располагаются в памяти и выполняются
последовательно
• В процессе работы архитектура не
изменяется
Управление
производственными
процессами
8.
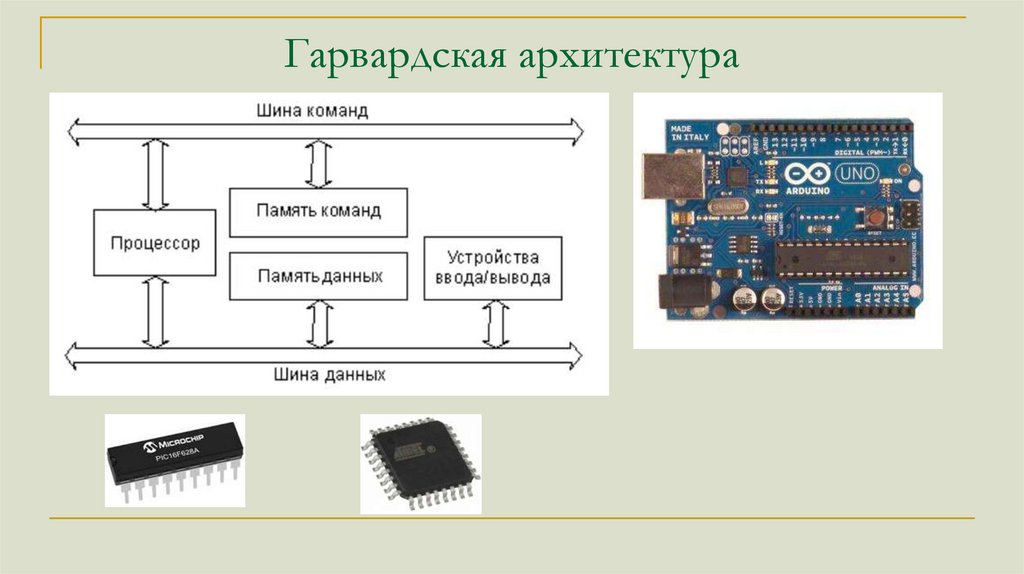
Гарвардская архитектура9.
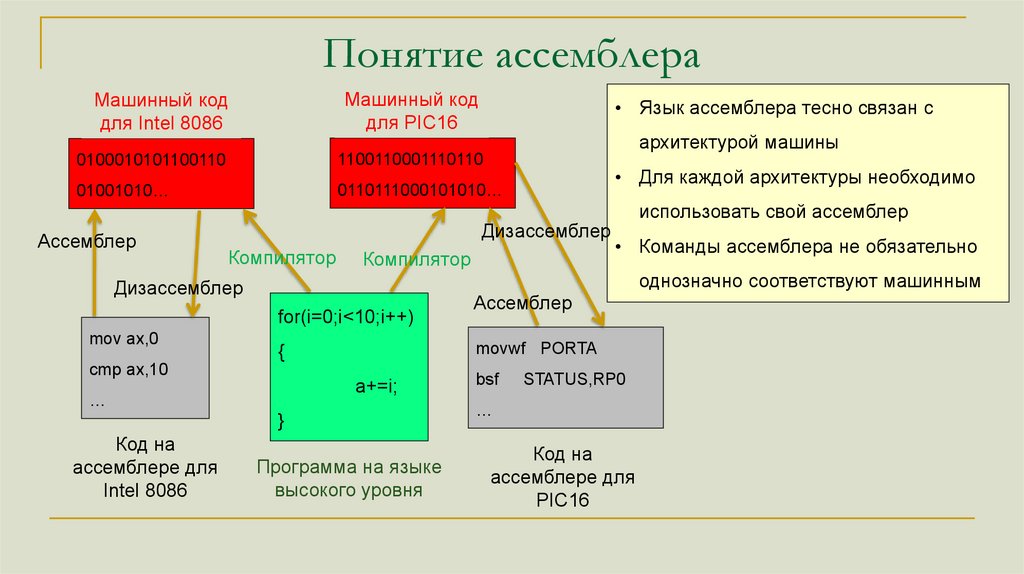
Понятие ассемблераМашинный код
для Intel 8086
Машинный код
для PIC16
0100010101100110
1100110001110110
01001010…
0110111000101010…
Ассемблер
Компилятор
• Для каждой архитектуры необходимо
Компилятор
использовать свой ассемблер
• Команды ассемблера не обязательно
однозначно соответствуют машинным
for(i=0;i<10;i++)
a+=i;
…
Ассемблер
movwf PORTA
{
cmp ax,10
}
Код на
ассемблере для
Intel 8086
архитектурой машины
Дизассемблер
Дизассемблер
mov ax,0
• Язык ассемблера тесно связан с
Программа на языке
высокого уровня
bsf
STATUS,RP0
…
Код на
ассемблере для
PIC16
10.
Устройствопамяти
и процессора
Институт Информационных Технологий
Челябинский Государственный Университет
11.
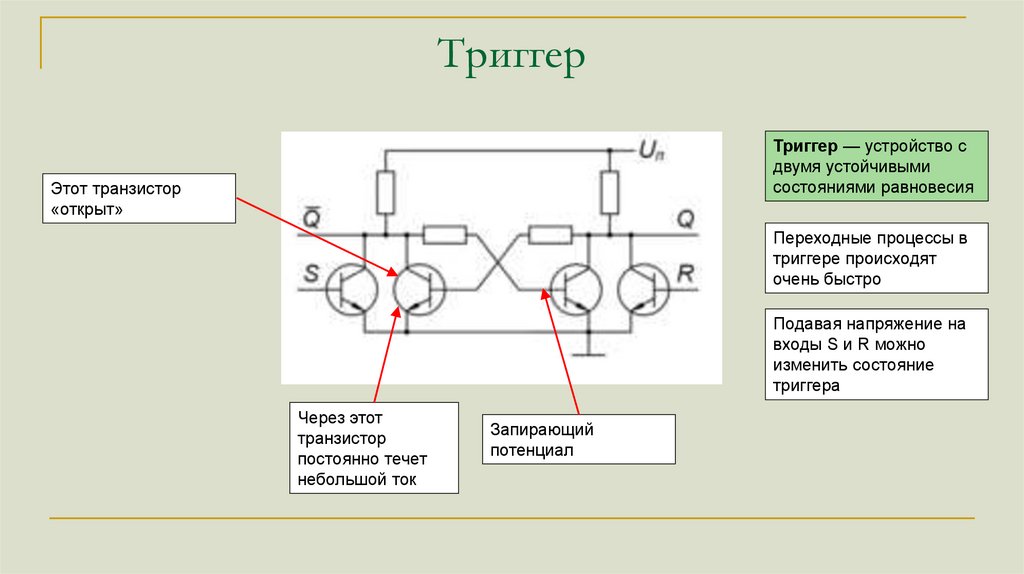
ТриггерТриггер — устройство с
двумя устойчивыми
состояниями равновесия
Этот транзистор
«открыт»
Переходные процессы в
триггере происходят
очень быстро
Подавая напряжение на
входы S и R можно
изменить состояние
триггера
Через этот
транзистор
постоянно течет
небольшой ток
Запирающий
потенциал
12.
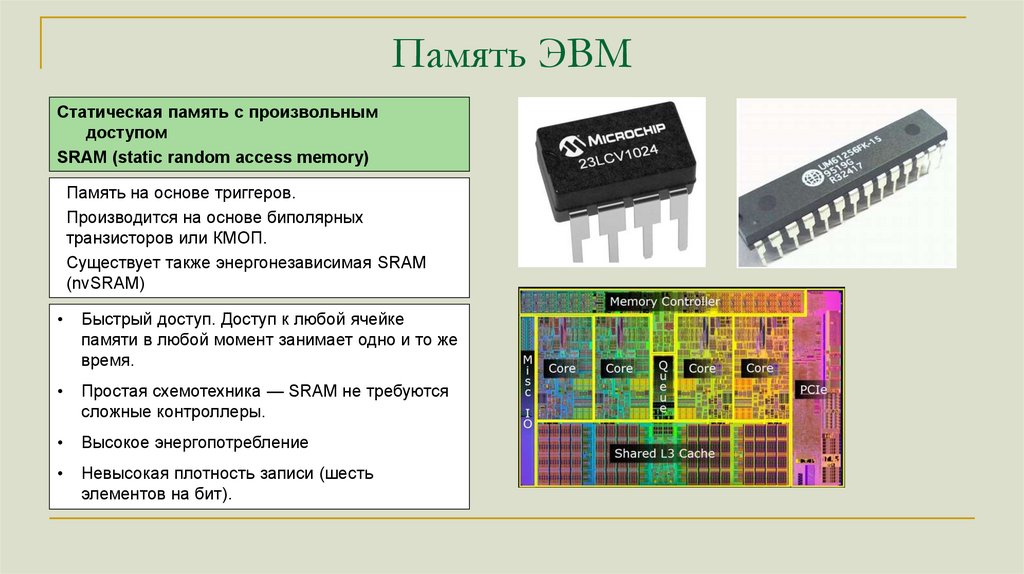
Память ЭВМСтатическая память с произвольным
доступом
SRAM (static random access memory)
Память на основе триггеров.
Производится на основе биполярных
транзисторов или КМОП.
Существует также энергонезависимая SRAM
(nvSRAM)
Быстрый доступ. Доступ к любой ячейке
памяти в любой момент занимает одно и то же
время.
Простая схемотехника — SRAM не требуются
сложные контроллеры.
Высокое энергопотребление
Невысокая плотность записи (шесть
элементов на бит).
13.
Память ЭВМДинамическая память с произвольным
доступом
DRAM (dynamic random access memory)
DRAM-память представляет собой набор
запоминающих ячеек, которые состоят из
конденсаторов и транзисторов
Относительно большое время доступа
Требуется подзарядка конденсаторов. Во время
подзарядки память недоступна
Относительно небольшое энергопотребление
Высокая плотность записи
14.
Устройство процессораТакт - промежуток времени, между последовательными сигналами синхронизации.
Величина такта выбирается такой, чтобы во время его прохождения в рассматриваемом объекте
заканчивались все переходные процессы, вызванные изменением входных сигналов.
Такт процессора — промежуток между двумя импульсами тактового генератора, который синхронизирует
выполнение всех операций процессора.
Выполнение различных команд может занимать от долей такта до многих тактов в зависимости от команды
и процессора.
Intel 80386
Тактовая частота
12—40 МГц
Intel Core i7
Тактовая частота
1,07—4,2 ГГц
15.
Устройство процессораРегистры процессора
Регистры — ячейки памяти, «территориально» расположенные прямо в процессорном ядре.
Регистры собираются из триггеров.
Регистры
процессора
8086
Регистры
процессора
Itanium
16.
Устройство процессораALU- арифметико-логические
устройства
простые арифметические
действия (сложение,
вычитание, сравнение) с
целыми числами
логические операции («и»,
«или», «исключающее или» и
«не»)
копирование и простые
преобразования чисел
битовые сдвиги
2+2=4
FPU - блоки вычислений с
плавающей точкой
2.8/2.86=0,979020979020979
02097902097902098
SIMD (Single Instruction,
Multiple Data ) - блоки
векторной обработки
{1,3,5,8}+{0,1,3,7}={1,4,8,15}
Блоки обмена данных с
памятью.
17.
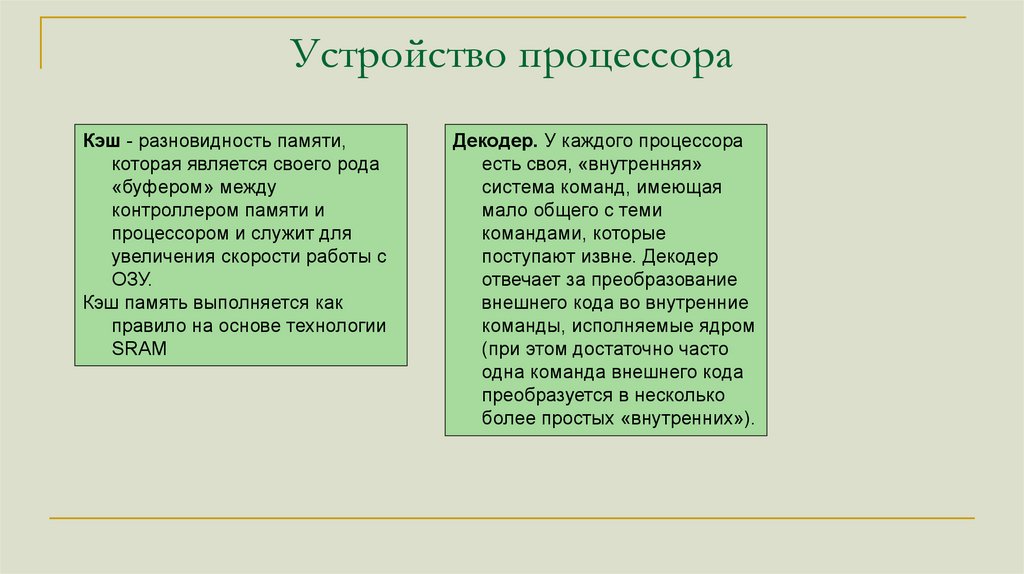
Устройство процессораКэш - разновидность памяти,
которая является своего рода
«буфером» между
контроллером памяти и
процессором и служит для
увеличения скорости работы с
ОЗУ.
Кэш память выполняется как
правило на основе технологии
SRAM
Декодер. У каждого процессора
есть своя, «внутренняя»
система команд, имеющая
мало общего с теми
командами, которые
поступают извне. Декодер
отвечает за преобразование
внешнего кода во внутренние
команды, исполняемые ядром
(при этом достаточно часто
одна команда внешнего кода
преобразуется в несколько
более простых «внутренних»).
18.
Организациявычислений
Институт Информационных Технологий
Челябинский Государственный Университет
19.
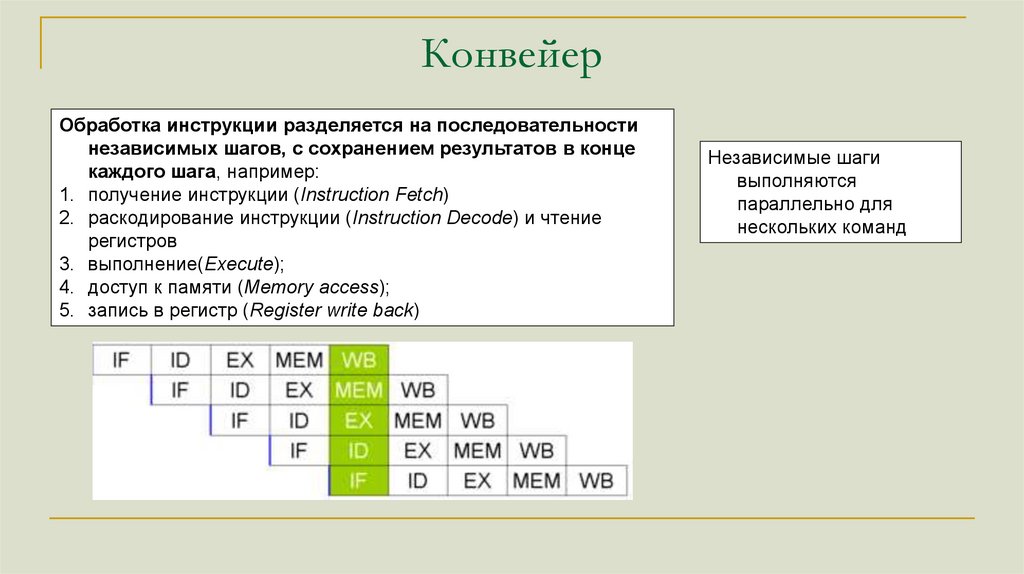
КонвейерОбработка инструкции разделяется на последовательности
независимых шагов, с сохранением результатов в конце
каждого шага, например:
1. получение инструкции (Instruction Fetch)
2. раскодирование инструкции (Instruction Decode) и чтение
регистров
3. выполнение(Execute);
4. доступ к памяти (Memory access);
5. запись в регистр (Register write back)
Независимые шаги
выполняются
параллельно для
нескольких команд
20.
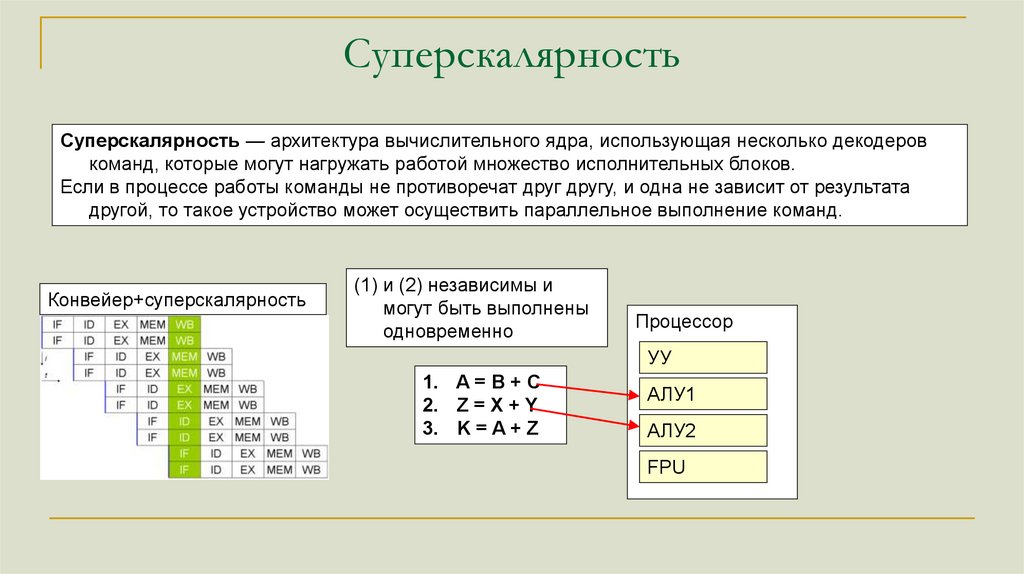
СуперскалярностьСуперскалярность — архитектура вычислительного ядра, использующая несколько декодеров
команд, которые могут нагружать работой множество исполнительных блоков.
Если в процессе работы команды не противоречат друг другу, и одна не зависит от результата
другой, то такое устройство может осуществить параллельное выполнение команд.
Конвейер+суперскалярность
(1) и (2) независимы и
могут быть выполнены
одновременно
Процессор
УУ
1. A = B + C
2. Z = X + Y
3. K = A + Z
АЛУ1
АЛУ2
FPU
21.
Организация вычисленийПРОБЛЕМЫ:
1. В процессорах используются инструкции самого разного рода,
не всегда можно разделить инструкцию на независимые шаги
2. Инструкции могут зависеть друг от друга
1. A = B + C
2. K = A + M
Нельзя выполнять инструкцию 2 пока не будет
выполнена инструкция 1
3. При наличии условных
переходов непонятно, какую
инструкцию необходимо
выполнять
22.
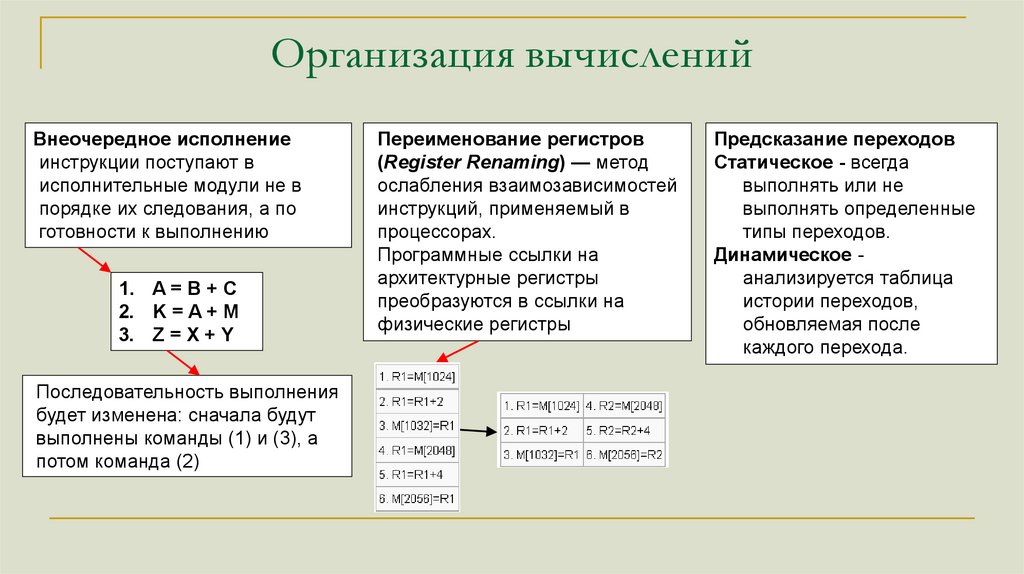
Организация вычисленийВнеочередное исполнение
инструкции поступают в
исполнительные модули не в
порядке их следования, а по
готовности к выполнению
1. A = B + C
2. K = A + M
3. Z = X + Y
Последовательность выполнения
будет изменена: сначала будут
выполнены команды (1) и (3), а
потом команда (2)
Переименование регистров
(Register Renaming) — метод
ослабления взаимозависимостей
инструкций, применяемый в
процессорах.
Программные ссылки на
архитектурные регистры
преобразуются в ссылки на
физические регистры
Предсказание переходов
Статическое - всегда
выполнять или не
выполнять определенные
типы переходов.
Динамическое анализируется таблица
истории переходов,
обновляемая после
каждого перехода.
23.
Hyper-ThreadingТехнология Hyper-Threading
позволяет на одном
физическом ядре
одновременно исполнять два
потока. Таким образом, одно
ядро воспринимается
операционной системой как
два логических
У каждого логического ядра
есть свой собственный
контроллер прерываний и
набор регистров.
Технология Hyper-Threading
может увеличить
эффективность процессора
только в том случае, если
1. Вычислительные процессы
распараллелены
2. Выполняются
одновременно операции,
использующие различные
блоки CPU
24.
Структура команди
Режимы адресации
25.
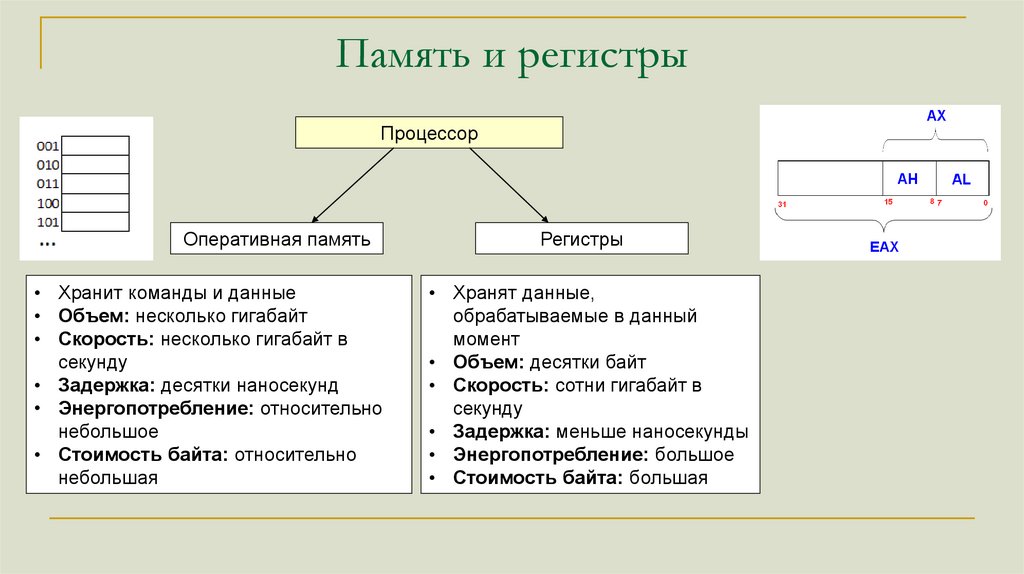
Память и регистрыПроцессор
Оперативная память
• Хранит команды и данные
• Объем: несколько гигабайт
• Скорость: несколько гигабайт в
секунду
• Задержка: десятки наносекунд
• Энергопотребление: относительно
небольшое
• Стоимость байта: относительно
небольшая
Регистры
• Хранят данные,
обрабатываемые в данный
момент
• Объем: десятки байт
• Скорость: сотни гигабайт в
секунду
• Задержка: меньше наносекунды
• Энергопотребление: большое
• Стоимость байта: большая
26.
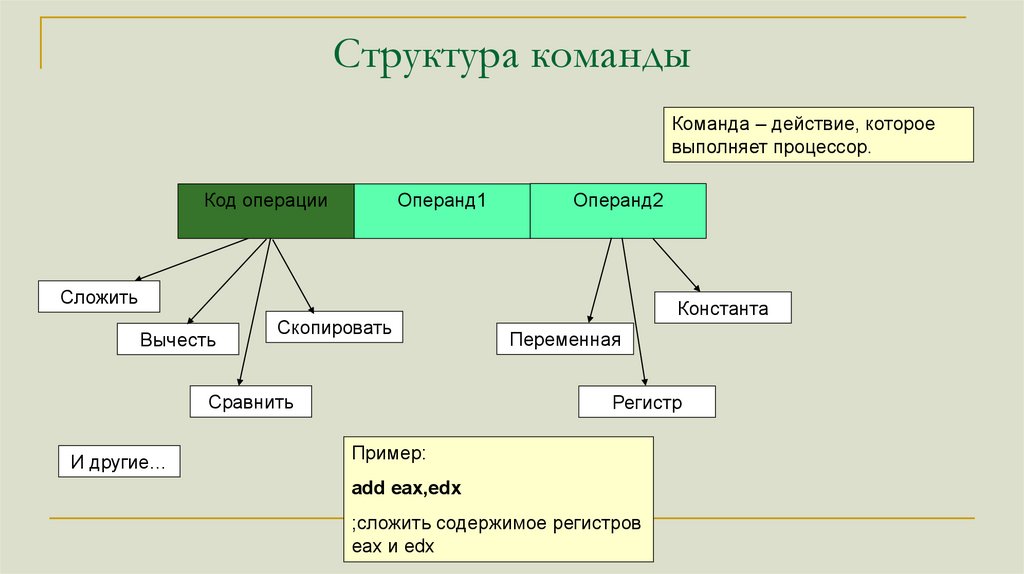
Структура командыКоманда – действие, которое
выполняет процессор.
Код операции
Операнд1
Операнд2
Сложить
Вычесть
Скопировать
Сравнить
И другие…
Константа
Переменная
Регистр
Пример:
add eax,edx
;сложить содержимое регистров
eax и edx
27.
Адресация операндов1) регистровая адресация – операнд (данное) находится в регистре
Команда
КОП
Регистры
Код Регистра
Регистр 1
Регистр 2
Регистр 3
Регистр 4
Операнд
28.
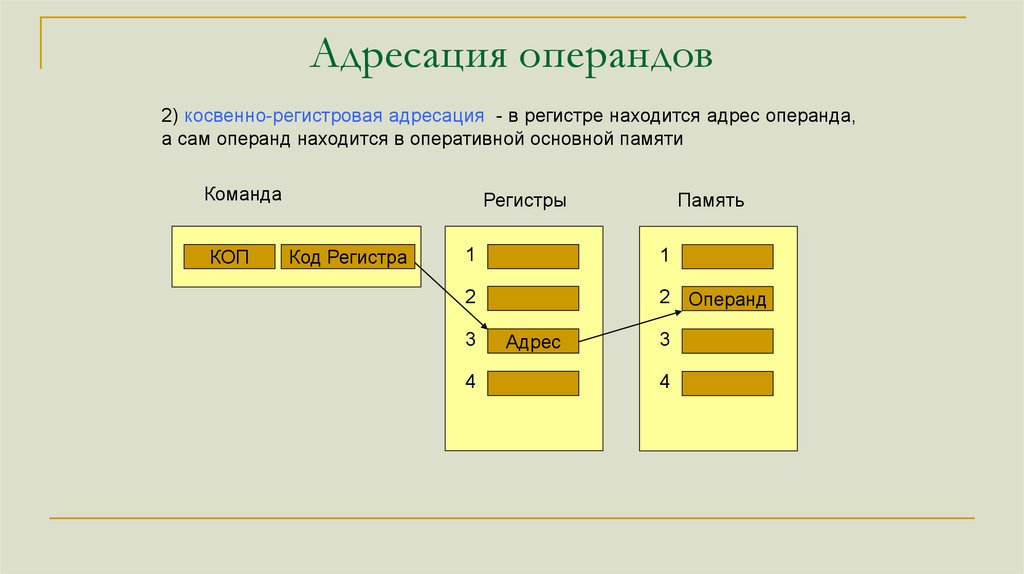
Адресация операндов2) косвенно-регистровая адресация - в регистре находится адрес операнда,
а сам операнд находится в оперативной основной памяти
Команда
КОП
Регистры
Код Регистра
Память
1
1
2
2 Операнд
3
4
Адрес
3
4
29.
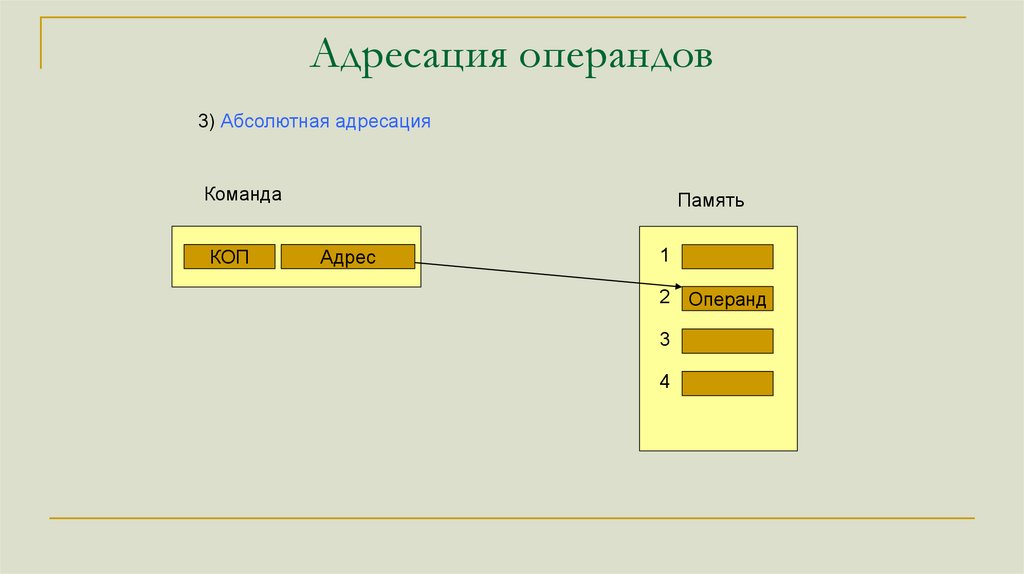
Адресация операндов3) Абсолютная адресация
Команда
КОП
Память
Адрес
1
2 Операнд
3
4
30.
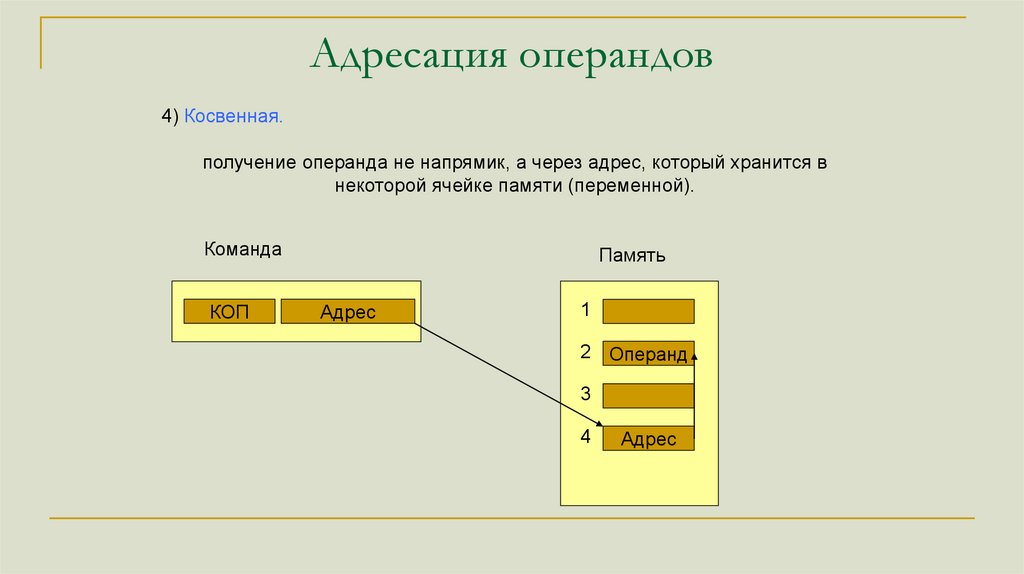
Адресация операндов4) Косвенная.
получение операнда не напрямик, а через адрес, который хранится в
некоторой ячейке памяти (переменной).
Команда
КОП
Память
Адрес
1
2 Операнд
3
4
Адрес
31.
Адресация операндов5) Индексная адресация - В РОН находится адрес и в коде операнда
находится индекс.
Используется при работе с массивами.
Команда
КОП
Регистры
Индекс
1
1
2
2
3
+
Память
4
Адрес
3 Операнд
4
32.
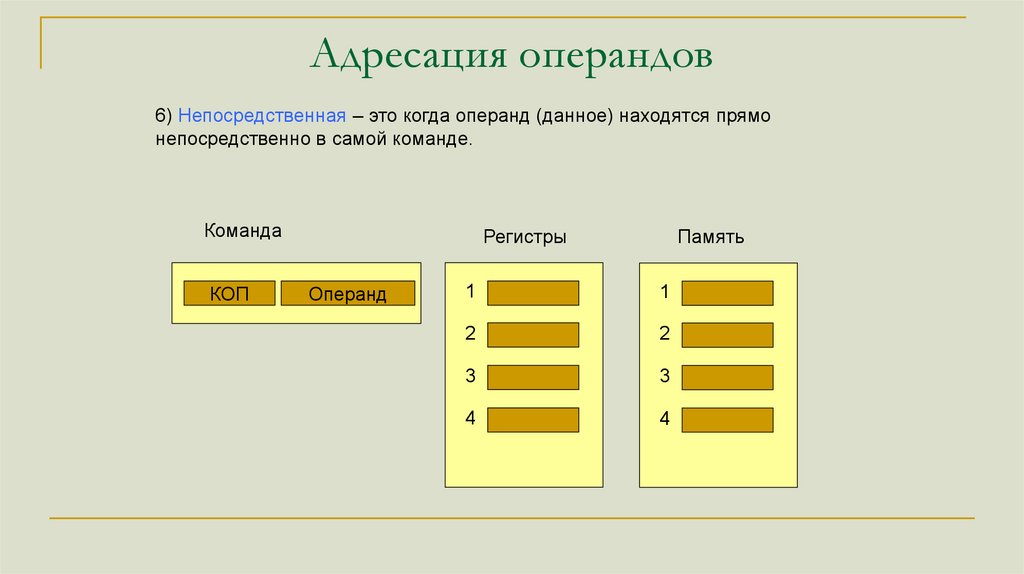
Адресация операндов6) Непосредственная – это когда операнд (данное) находятся прямо
непосредственно в самой команде.
Команда
КОП
Регистры
Операнд
Память
1
1
2
2
3
3
4
4
33.
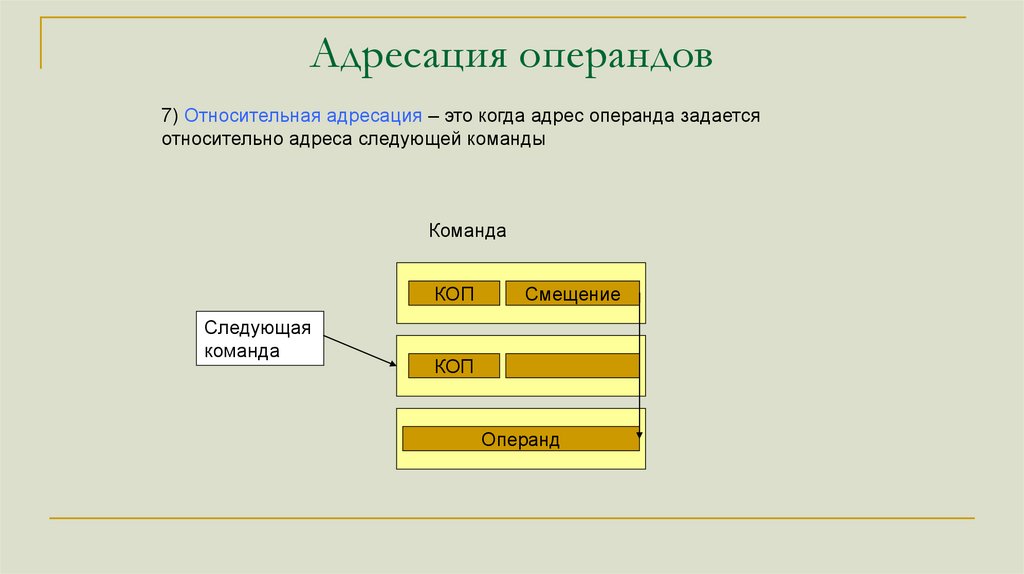
Адресация операндов7) Относительная адресация – это когда адрес операнда задается
относительно адреса следующей команды
Команда
КОП
Следующая
команда
Смещение
КОП
Операнд
34.
Структура команд ирежимы адресации
на примере PDP-11
Институт Информационных Технологий
Челябинский Государственный Университет
35.
Архитектура PDP-11PDP-11 — серия 16-разрядных мини-ЭВМ компании DEC, серийно производившихся и
продававшихся в 1970—80-х годах.
• Простая система команд: можно
отдельно запоминать команды, и
отдельно — методы доступа к
операндам.
• Можно считать, что любой
режим адресации будет работать
с любой операцией;
• Не нужно запоминать список
исключений и особых случаев.
36.
Архитектура PDP-1137.
Регистры PDP-11Название регистра
Код
регистра
000
R0
001
R1
010
R2
011
R3
100
R4
101
R5
Указатель кадра
110
R6
Указатель стека
111
R7
Счетчик команд
Универсальные регистры
38.
Команды PDP-11Команды управления:
Все биты определяют код операции, имеющий длину, равную
одному слову (16 бит).
• HALT(0000000000000000) – прекращение процессорных
операций,
• WAIT(0000000000000001) – прекращение извлечения команд
из памяти,
• RESET(0000000000000101) – все устройства на общей шине
устанавливаются в исходное состояние
39.
Команды PDP-11Однооперандные команды:
INC
DEC
NEG
X000101010
X000101011
X000101100
Двухоперандные команды :
MOV
X001
40.
Команды PDP-11Режимы адресации
Rn – специфицирует регистр.
@ - специфицирует прямая или косвенная
адресация (1 – косвенная, 0 - прямая)
Режим[5:3] – специфицирует, как будет использоваться регистр:
0 – регистровая адресация
2 – автоинкрементная адресация
4 – автодекрементная адресация
6 – индексная адресация
1 – регистровый косвенный режим
3 – автоинкрементный косвенный
режим
5 – автодекрементный косвенный
режим
7 – индексный косвенный режим
41.
Команды PDP-11Операнд в регистре R1
0
0
0
0
0
1
Операнд сразу после
команды
0
Операнд по адресу, который
указан в регистре R2
0
0
1
0
1
0
1
1
1
1
1
Режим не имеет смысла
0
0
0
1
1
1
42.
Архитектура x8643.
Регистры x86 (32-разрядные)EAX,EBX,ECX,EDX – 32-разрядные регистры для
хранения и обработки целочисленных значений
ESI,EDI – 32-разрядные регистры для работы со
строками (массивами)
ESP,EBP – 32-разрядные регистры для работы со
стеком
Предполагаемое использование регистров:
EAX – аккумулятор. Хранит результаты операций или
промежуточные данные.
EBX – базовый. Хранит адрес объекта в памяти
ECX – счетчик. Применяется для организации
повторяющихся действий (циклов)
EDX – данные.
44.
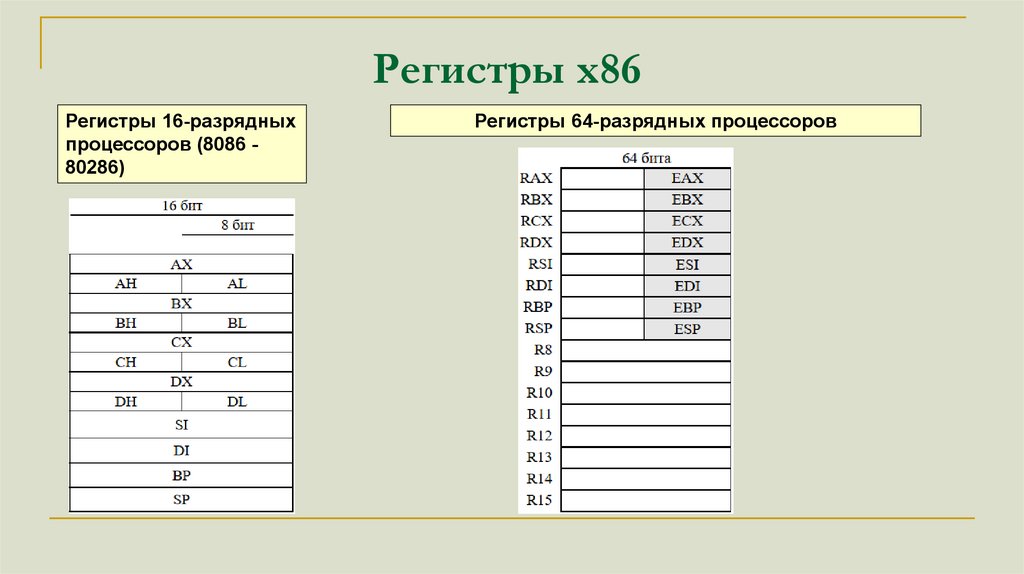
Регистры x86Регистры 16-разрядных
процессоров (8086 80286)
Регистры 64-разрядных процессоров
45.
Система командКоманда копирования данных MOV
r – регистр
m – переменная в оперативной памяти
imm – непосредственное значение
8/16/32 – разрядность операндов
Только один операнд может быть
переменной в оперативной памяти!
46.
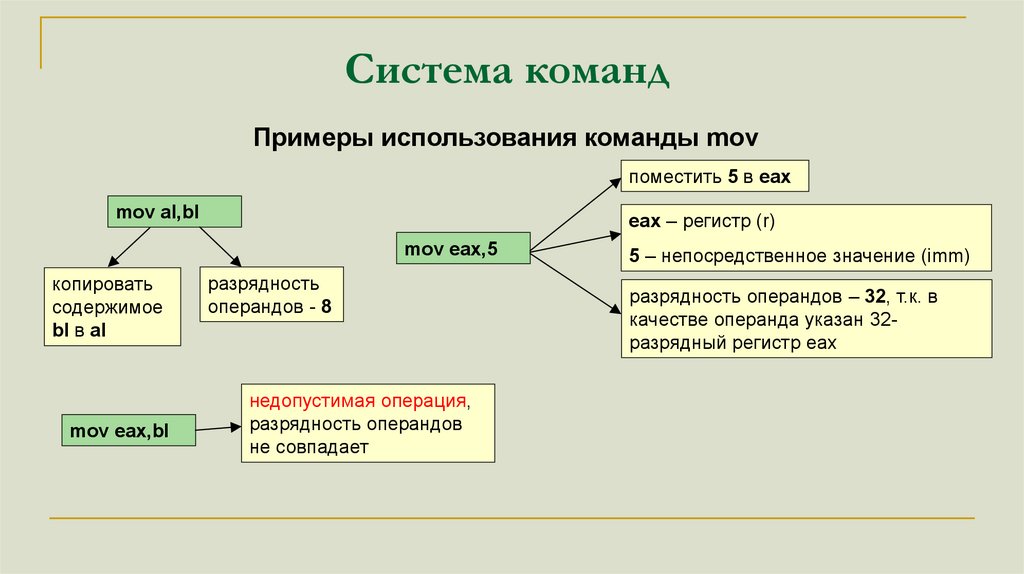
Система командПримеры использования команды mov
поместить 5 в eax
mov al,bl
eax – регистр (r)
mov eax,5
копировать
содержимое
bl в al
mov eax,bl
разрядность
операндов - 8
недопустимая операция,
разрядность операндов
не совпадает
5 – непосредственное значение (imm)
разрядность операндов – 32, т.к. в
качестве операнда указан 32разрядный регистр eax
47.
Система командПримеры использования команды mov
mov x, eax
скопировать содержимое eax в 32разрядную переменную x
mov x, y
скопировать содержимое переменной y в
переменную x
недопустимая операция – только один
операнд может быть переменной в
оперативной памяти!
48.
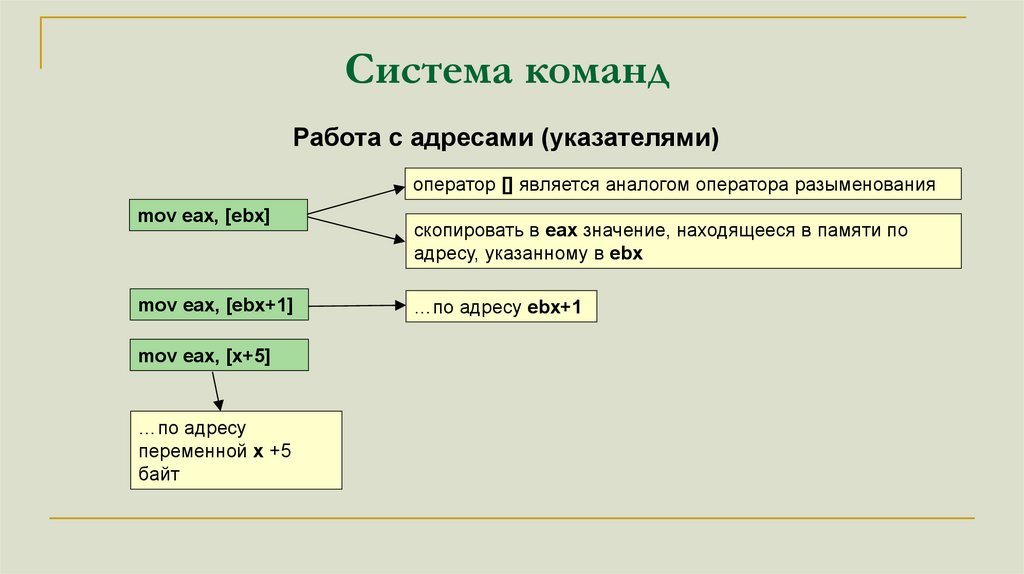
Система командРабота с адресами (указателями)
оператор [] является аналогом оператора разыменования
mov eax, [ebx]
mov eax, [ebx+1]
mov eax, [x+5]
…по адресу
переменной x +5
байт
скопировать в eax значение, находящееся в памяти по
адресу, указанному в ebx
…по адресу ebx+1
49.
Команды x86Примеры
50.
Команда addСложение операндов
Команда:
Пример 1
add operand1, operand2
add eax,ebx
Алгоритм:
Пример 2
operand1 = operand1 + operand2
Способы адресации:
REG, memory
memory, REG
REG, REG
memory, immediate
REG, immediate
Сложить eax+ebx
Полученное значение
поместить в eax
Прибавить 5 к значению ax
add ax,5
Пример 3
add 5, eax
Недопустимая команда.
«5» не может быть первым
операндом
51.
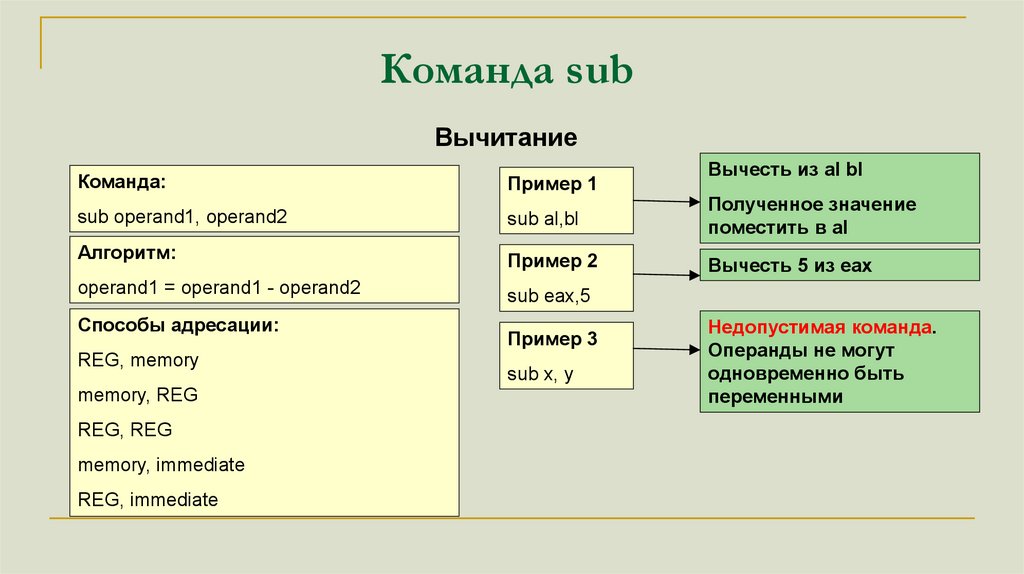
Команда subВычитание
Команда:
Пример 1
Вычесть из al bl
sub operand1, operand2
sub al,bl
Полученное значение
поместить в al
Алгоритм:
Пример 2
Вычесть 5 из eax
operand1 = operand1 - operand2
sub eax,5
Способы адресации:
REG, memory
memory, REG
REG, REG
memory, immediate
REG, immediate
Пример 3
sub x, y
Недопустимая команда.
Операнды не могут
одновременно быть
переменными
52.
Команда incИнкремент
Команда:
Пример 1
inc operand
inc ax
Алгоритм:
Пример 2
operand = operand + 1
inc y
Способы адресации:
REG
memory
Увеличить зачение
регистра ax на 1
Увеличить значение
переменной «y» на 1
53.
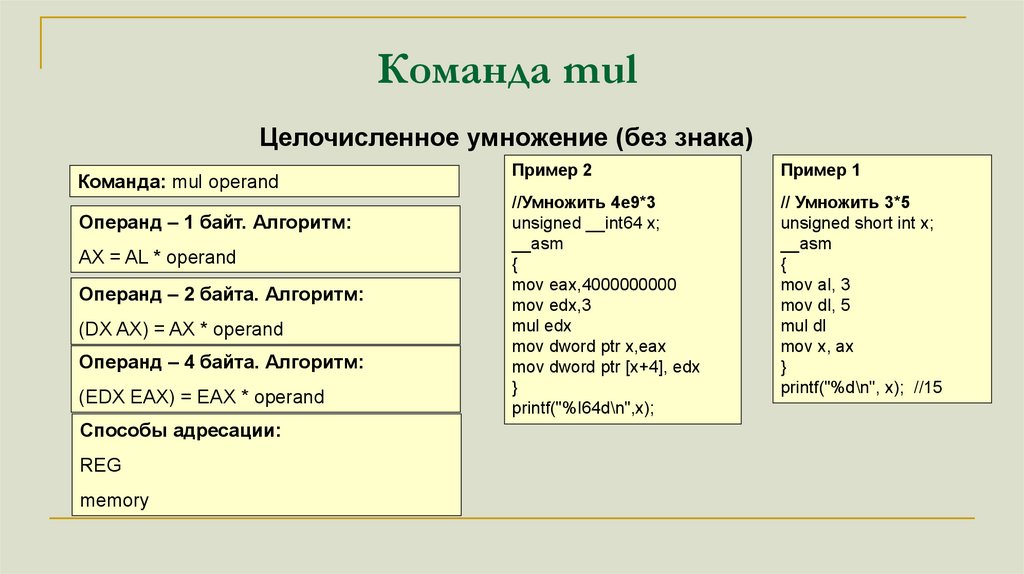
Команда mulЦелочисленное умножение (без знака)
Команда: mul operand
Операнд – 1 байт. Алгоритм:
AX = AL * operand
Операнд – 2 байта. Алгоритм:
(DX AX) = AX * operand
Операнд – 4 байта. Алгоритм:
(EDX EAX) = EAX * operand
Способы адресации:
REG
memory
Пример 2
Пример 1
//Умножить 4e9*3
unsigned __int64 x;
__asm
{
mov eax,4000000000
mov edx,3
mul edx
mov dword ptr x,eax
mov dword ptr [x+4], edx
}
printf("%I64d\n",x);
// Умножить 3*5
unsigned short int x;
__asm
{
mov al, 3
mov dl, 5
mul dl
mov x, ax
}
printf("%d\n", x); //15
54.
Команда idivЦелочисленное деление (со знаком)
Команда: idiv operand
Пример
Операнд – 1 байт. Алгоритм:
// Разделить (-15)/2
int x,rem;
__asm
{
mov eax, -15
mov edx, -1
mov ecx,2
idiv ecx
mov x, eax
mov rem,edx
}
printf("%d\n", x);// -7
printf("%d\n", rem);// -1
AL = AX / operand
AH - остаток
Операнд – 2 байта. Алгоритм:
AX = (DX AX) / operand
DX - остаток
Операнд – 4 байта. Алгоритм:
EAX = (EDX EAX) / operand EDX - остаток
Способы адресации:
REG
memory
55.
ПримерВычислить выражение
z=(x+y-2)*x
56.
Командыусловного перехода
57.
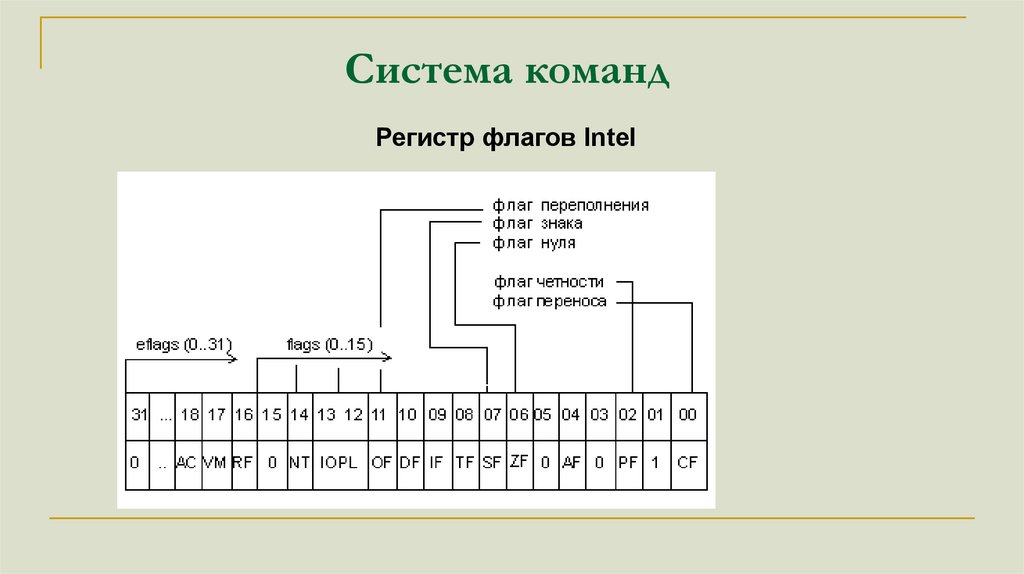
Система командРегистр флагов Intel
58.
Система командПример:
mov ax,-10
mov bx,-11
add ax,bx
1111111111110110
+
1111111111110101
= 1111111111101011
CF=1 Флаг переноса
ZF=0 Флаг нуля
SF=1 Флаг знака
OF=0 Флаг переполнения
PF=1 Флаг четности
59.
Система командПример:
mov al,255
mov bl,1
add al,bl
11111111
+
00000001
= 00000000
CF=1 Флаг переноса
ZF=1 Флаг нуля
SF=0 Флаг знака
OF=0 Флаг переполнения
PF=1 Флаг четности
60.
Система командКоманды перехода
Команда безусловного перехода
Адрес перехода
mov ax,bx
jmp label3
mov dx,cx
add ax,dx
label3: mov cx,ax
Команды будут
пропущены
61.
Система командКоманды условного перехода
if (a>b)
{
…
}
mov ax,a
cmp ax,b
jle label1
…
label1:
Условный оператор в языке
высокого уровня транслятор
заменяет на по крайней мере 2
команды процессора:
• Команда сравнения
• Команда условного перехода
Процессор Intel не умеет работать с двумя операндами в
памяти, поэтому один из них копируем в регистр
Сравниваем
Если a<=b переходим на адрес label1
62.
Система командКоманда cmp
Алгоритм работы команды cmp:
1. Вычесть из 1-го операнда 2-й
2. Соответствующим образом изменить
регистр флагов
Результат вычитания нигде не сохраняется
63.
Система командКоманды условного перехода
Сравнить
A=00000011
B=00000001
Сравнить
A=00000011
B=00000011
00000011
00000001
=00000010
00000011
00000011
=00000000
CF=0
ZF=0
A>B
CF=0
ZF=1
A=B
Сравнить
A=00000001
B=00000011
Занимаем
у старшего
разряда
00000001
00000011
=11111110
CF=1
ZF=0
A<B
64.
Система командКоманды условного перехода
65.
Система командКоманды условного перехода
66.
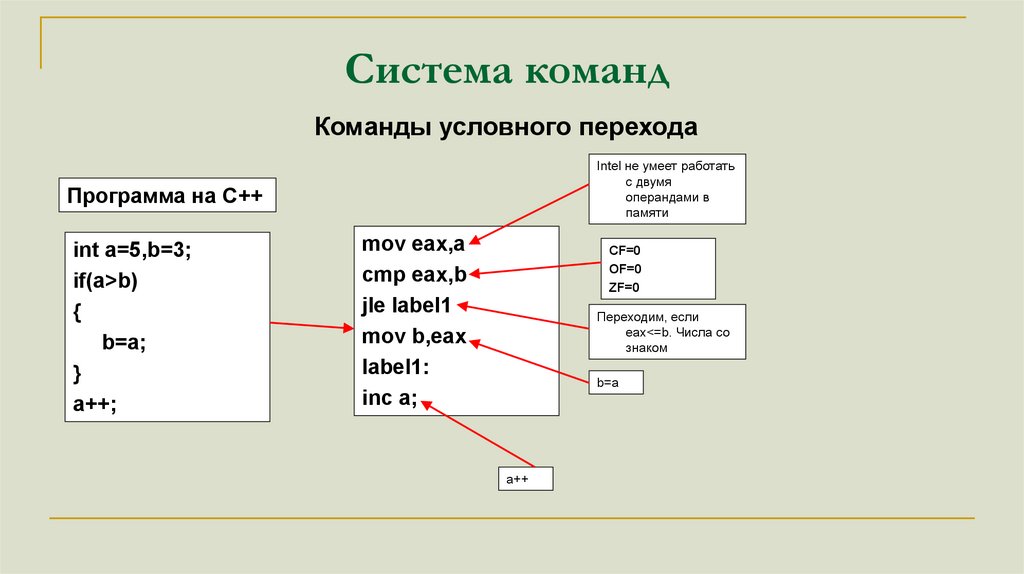
Система командКоманды условного перехода
Intel не умеет работать
с двумя
операндами в
памяти
Программа на C++
int a=5,b=3;
if(a>b)
{
b=a;
}
a++;
mov eax,a
cmp eax,b
jle label1
mov b,eax
label1:
inc a;
CF=0
OF=0
ZF=0
Переходим, если
eax<=b. Числа со
знаком
b=a
a++
67.
Переполнение68.
Переполнениецелые типы
unsigned char
беззнаковые
1
1
1
1
1
1
1
1
+255
+
0
0
0
0
0
0
0
1
+1
1
0
0
0
0
0
0
0
0
+0/должно быть +256
Не хватило разрядов.
Перенос за пределы
разрядной сетки
Для беззнаковых типов
переполнение определяется по
факту переноса бита за пределы
разрядной сетки/занятия бита за
пределами разрядной сетки
69.
Переполнениецелые типы
signed char
+
0
числа со знаком
0
0
0
0
0
0
1
1
+3
Перенос за
пределы
разрядной
сетки
0
0
0
0
0
0
1
0
+2
-
-
-
+
-
+
-
+
+
+
+
-
0
0
0
Переноса за
пределы
разрядной сетки
нет
0
0
1
0
1
Переноса в
знаковый разряд
нет
+5
Перенос в
знаковый
разряд
Переполнение
70.
Переполнениецелые типы
signed char
+
1
числа со знаком
1
0
0
0
1
0
0
0
-120
Перенос за
пределы
разрядной
сетки
1
0
0
0
0
0
0
1
-127
-
-
-
+
-
+
-
+
+
+
+
-
0
0
0
Перенос за
пределы
разрядной сетки
0
1
0
0
1
Переноса в
знаковый разряд
нет
+9
Перенос в
знаковый
разряд
Переполнение
71.
Переполнениецелые типы
signed char
+
0
числа со знаком
0
1
1
1
1
0
0
0
+120
Перенос за
пределы
разрядной
сетки
0
0
0
0
1
0
1
0
+10
-
-
-
+
-
+
-
+
+
+
+
-
1
0
0
Переноса за
пределы
разрядной сетки
нет
0
0
0
1
0
Перенос в
знаковый разряд
-126
Перенос в
знаковый
разряд
Переполнение
72.
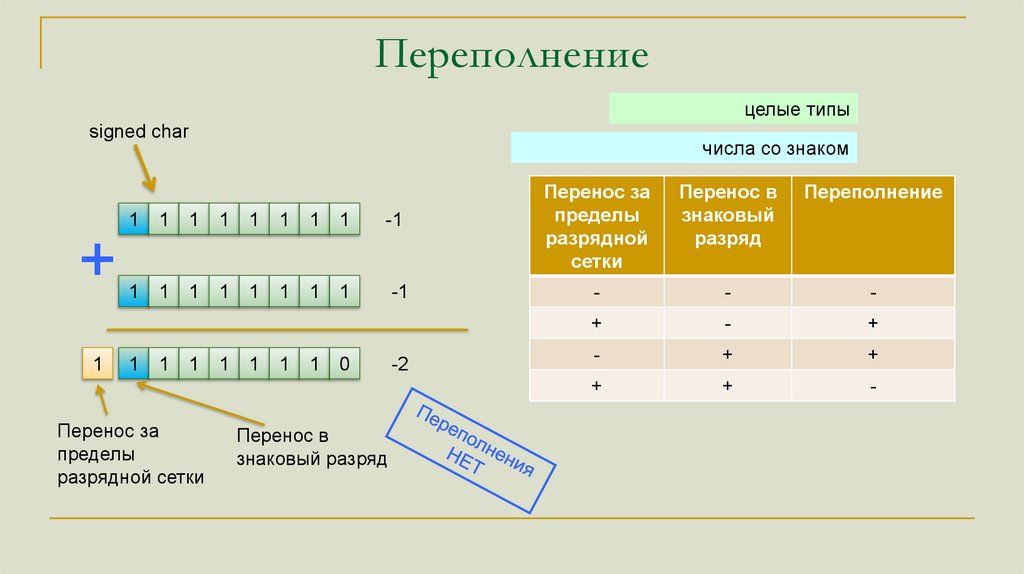
Переполнениецелые типы
signed char
+
1
числа со знаком
1
1
1
1
1
1
1
1
-1
Перенос за
пределы
разрядной
сетки
1
1
1
1
1
1
1
1
-1
-
-
-
+
-
+
-
+
+
+
+
-
1
1
1
Перенос за
пределы
разрядной сетки
1
1
1
1
0
Перенос в
знаковый разряд
-2
Перенос в
знаковый
разряд
Переполнение
73.
ПереполнениеЗнаковые и беззнаковые типы
Полностью эквивалентные
команды
mov al, -1
mov al, 255
unsigned char
signed char
1
1
1
Команды mov, add, sub не
различают знаковые и
беззнаковые типы
1
1
1
1
1
-1
1
1
1
1
1
1
1
1
255
74.
ПереполнениеПримеры
jo – команда
условного перехода.
Переход в случае
знакового
переполнения
jc – команда
условного перехода.
Переход в случае
переноса за
пределы разрядной
сетки
75.
СтекСтек – это определенный динамический способ хранения данных,
при котором в каждый момент времени доступ возможен только
к одному из элементов, а именно к тому, который был занесен в
стек последним.
Стек — структура данных с методом доступа к элементам LIFO (англ.
Last In — First Out, «последним пришел — первым вышел»).
76.
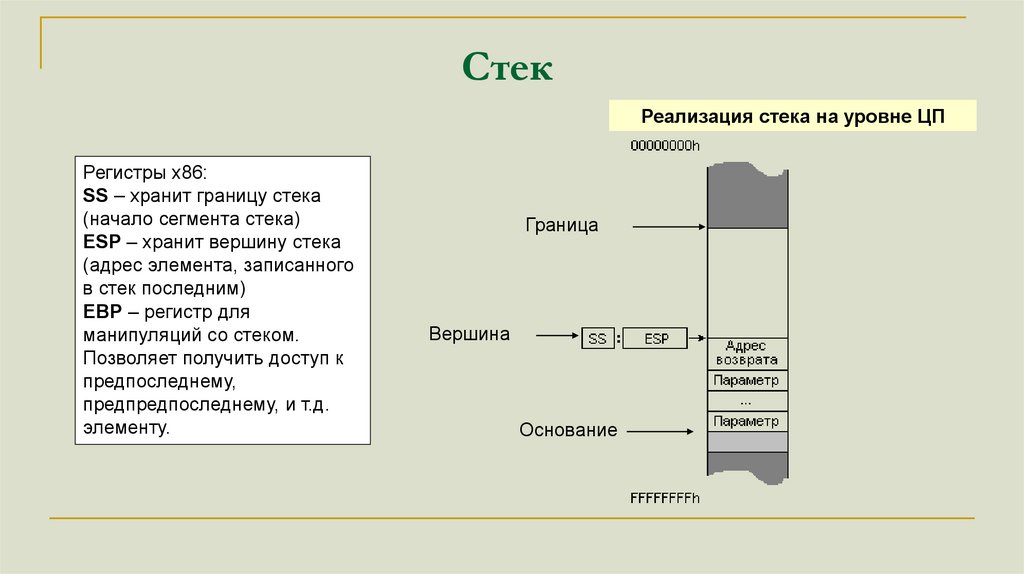
СтекРеализация стека на уровне ЦП
Регистры x86:
SS – хранит границу стека
(начало сегмента стека)
ESP – хранит вершину стека
(адрес элемента, записанного
в стек последним)
EBP – регистр для
манипуляций со стеком.
Позволяет получить доступ к
предпоследнему,
предпредпоследнему, и т.д.
элементу.
Граница
Вершина
Основание
77.
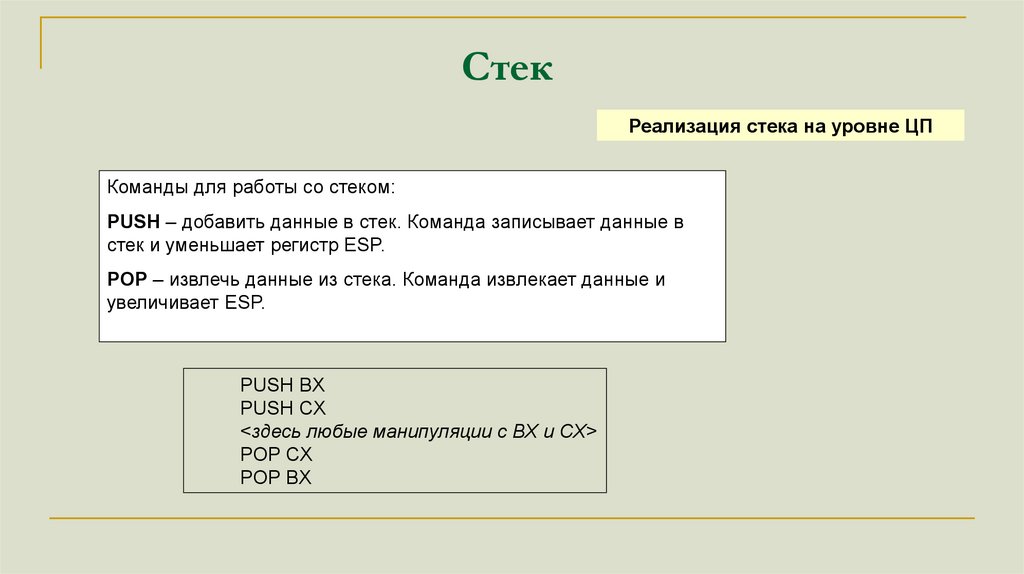
СтекРеализация стека на уровне ЦП
Команды для работы со стеком:
PUSH – добавить данные в стек. Команда записывает данные в
стек и уменьшает регистр ESP.
POP – извлечь данные из стека. Команда извлекает данные и
увеличивает ESP.
PUSH BX
PUSH CX
<здесь любые манипуляции с BX и CX>
POP CX
POP BX
78.
СтекРеализация стека на уровне ЦП
Регистры x86:
SS – хранит границу стека (начало сегмента стека)
ESP – хранит вершину стека (адрес элемента, записанного в стек
последним)
EBP – регистр для манипуляций со стеком. Позволяет получить
доступ к предпоследнему, предпредпоследнему, и т.д. элементу.
;код для 32-битного процессора
mov EBP,ESP
;получаем доступ к последнему
inc [EBP]
;можем изменить последний
add EBP,4
;получаем доступ к предпоследнему
inc [EBP]
;можем изменить предпоследний
79.
СтекПримеры работы со стеком
80.
СтекПримеры работы со стеком
81.
Стек иорганизация
подпрограмм
82.
Стек и организация подпрограммОрганизация подпрограмм
Подпрограмма — поименованная или иным образом
идентифицированная часть программы, содержащая описание
определённого набора действий.
Преимущества подпрограмм:
1.Возможность повторного использования программного кода.
2.Структуризация программы с целью удобства её понимания и
сопровождения.
Особенности использования функций:
1.Функции могут вызывать друг друга.
2.Как правило заранее нельзя предсказать, какие функции будут
вызваны, и в какой последовательности.
3.Возможен рекурсивный вызов функций, причем необязательно
напрямую: 1-я функция может вызвать 2-ю, а та, в свою очередь –
1-ю.
83.
Стек и организация подпрограммПроблемы:
Организация подпрограмм
Каждый раз при вызове функции необходимо хранить адрес
возврата. Таким образом, может оказаться, что в некоторый момент
времени необходимо хранить множество таких адресов.
func1() func2() func3() func2()…
После окончания работы функции такой адрес необходим, чтобы
вернуться в предыдущую функцию.
Для каждой вызванной функции необходимо отдельно хранить ее
локальные переменные и передаваемые параметры. Это связано с
тем, что возможен рекурсивный вызов функции, т.е. в один момент
времени могут выполняться несколько экземпляров функции,
каждый со своими параметрами.
84.
Стек и организация подпрограммОрганизация подпрограмм
Решение:
Адреса возврата, передаваемые параметры и локальные переменные
хранятся в стеке.
Таким образом, последними загружаются в стек значения последней
вызванной функции, а при их извлечении из стека, следующими будут
значения предыдущей, и т.д.
Обобщенный алгоритм вызова функции:
• Поместить в стек параметры, передаваемые функции
• Поместить в стек адрес возврата (адрес следующая команды, после вызова
функции).
• Функция работает. При необходимости, локальные переменные также
размещаются в стеке.
• Извлечь из стека все значения и перейти по адресу возврата, который
находится в стеке.
85.
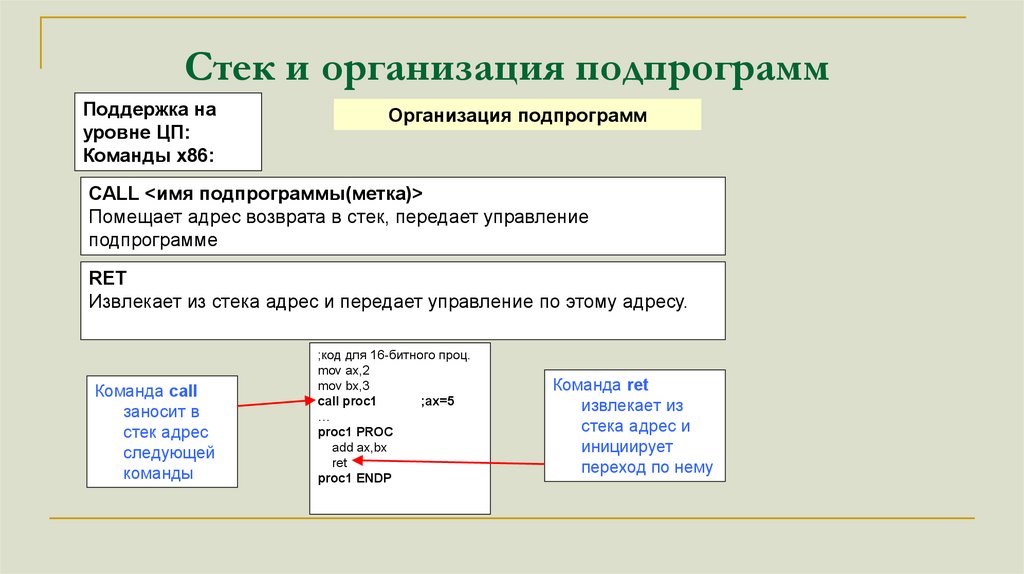
Стек и организация подпрограммПоддержка на
уровне ЦП:
Команды x86:
Организация подпрограмм
CALL <имя подпрограммы(метка)>
Помещает адрес возврата в стек, передает управление
подпрограмме
RET
Извлекает из стека адрес и передает управление по этому адресу.
Команда call
заносит в
стек адрес
следующей
команды
;код для 16-битного проц.
mov ax,2
mov bx,3
call proc1
;ax=5
…
proc1 PROC
add ax,bx
ret
proc1 ENDP
Команда ret
извлекает из
стека адрес и
инициирует
переход по нему
86.
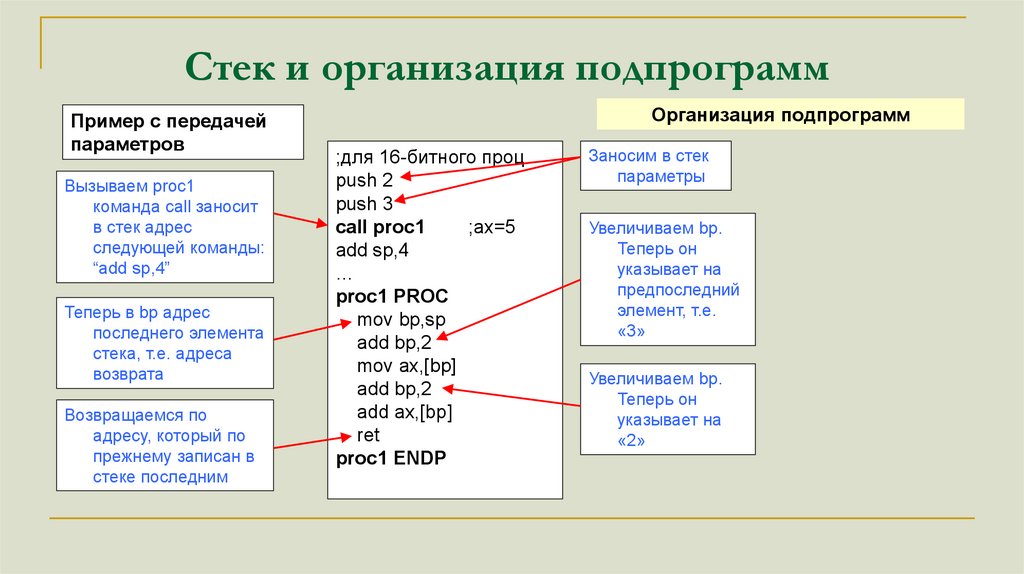
Стек и организация подпрограммПример с передачей
параметров
Вызываем proc1
команда call заносит
в стек адрес
следующей команды:
“add sp,4”
Теперь в bp адрес
последнего элемента
стека, т.е. адреса
возврата
Возвращаемся по
адресу, который по
прежнему записан в
стеке последним
Организация подпрограмм
;для 16-битного проц
push 2
push 3
call proc1
;ax=5
add sp,4
…
proc1 PROC
mov bp,sp
add bp,2
mov ax,[bp]
add bp,2
add ax,[bp]
ret
proc1 ENDP
Заносим в стек
параметры
Увеличиваем bp.
Теперь он
указывает на
предпоследний
элемент, т.е.
«3»
Увеличиваем bp.
Теперь он
указывает на
«2»
87.
Стек и организация подпрограммСоглашение вызова
определяет следующие
особенности процесса
использования подпрограмм:
• Расположение входных параметров подпрограммы и
возвращаемых ею значений.
• Порядок передачи параметров. Кто возвращает указатель стека на
исходную позицию.
• Какой командой вызывать подпрограмму и какой — возвращаться в
основную программу. Например, в стандартном режиме x86
подпрограмму можно вызвать через call near, call far и pushf/call far
(для возврата применяются соответственно retn, retf, iret).
• Содержимое каких регистров процессора подпрограмма обязана
восстановить перед возвратом.
Соглашение вызова
88.
Стек и организация подпрограммСоглашение вызова
Соглашение вызова cdecl
Основной способ вызова для Си (отсюда название, сокращение от
«c-declaration»). Аргументы передаются через стек, справа налево.
Очистку стека производит вызывающая программа. Возвращаемое
значение записывается в регистр ax (eax).
Пример:
int function_name(int, int, int);
int a, b, c, x;
x = function_name(a, b, c);
push c ; arg 3
push b ; arg 2
push a ; arg 1
call function_name
add esp, 12
mov x, eax
Очистка
стека
89.
Стек и организация подпрограммСоглашение вызова
Соглашение вызова pascal
Основной способ вызова для Паскаля. Аргументы передаются через стек,
слева направо. Указатель стека на исходную позицию возвращает
подпрограмма. У функций неявно создаётся дополнительный первый
изменяемый параметр Result, через который и возвращается значение.
Соглашение вызова stdcall/winapi
Применяется при вызове функций WinAPI. Аргументы передаются через стек,
справа налево. Очистку стека производит вызываемая подпрограмма.
Соглашение вызова fastcall
Передача параметров через регистры. Если все параметры и промежуточные
результаты умещаются в регистрах, манипуляции со стеком вообще не
нужны. Fastcall не стандартизирован, поэтому используется только в
функциях, которые программа не экспортирует наружу.
90.
Стек и организация подпрограммПример
Вызов готовой функции в
ассемблерной вставке
91.
ПрерыванияИнститут Информационных Технологий
Челябинский Государственный Университет
92.
ПрерыванияПрерывание
(interrupt) — сигнал,
сообщающий процессору
о наступлении какоголибо события.
При возникновении прерывания выполнение текущей
последовательности команд приостанавливается и
управление передаётся обработчику прерывания, который
реагирует на событие и обслуживает его, после чего
возвращает управление в прерванный код.
Общая схема обработки прерывания
1.Процессор получает сигнал о прерывании
2.Процессор завершает выполнение текущей машинной команды
3.Сохраняется текущее состояние процессора
4.Вызывается обработчик прерывания
5.Состояние процессора восстанавливается, происходит возврат к
командам, выполнение которых было прервано.
93.
Классификация прерыванийМаскируемые прерывания
Прерывания, которые можно запрещать
установкой соответствующих битов в
регистре маскирования прерываний.
Маскируемые прерывания могут
использоваться для обработки сигналов от
внешних устройств (мышь, клавиатура…).
Как правило, при обработке такого
прерывания устанавливается запрет на все
другие маскируемые прерывания.
Для управления флагом прерываний в
процессоре x86 используются команды
cli - clear interrupt flag (запрещает
прерывания).
sti - set interrupt flag (разрешает прерывания).
94.
Классификация прерыванийНемаскируемые прерывания
Прерывания, которые обрабатываются всегда, независимо
от запретов на другие прерывания.
Используются для ситуаций, которые должны быть
обработаны в любом случае, и для которых критично
время реакции:
• Критические ошибки оборудования
• Сигналы от системных таймеров
95.
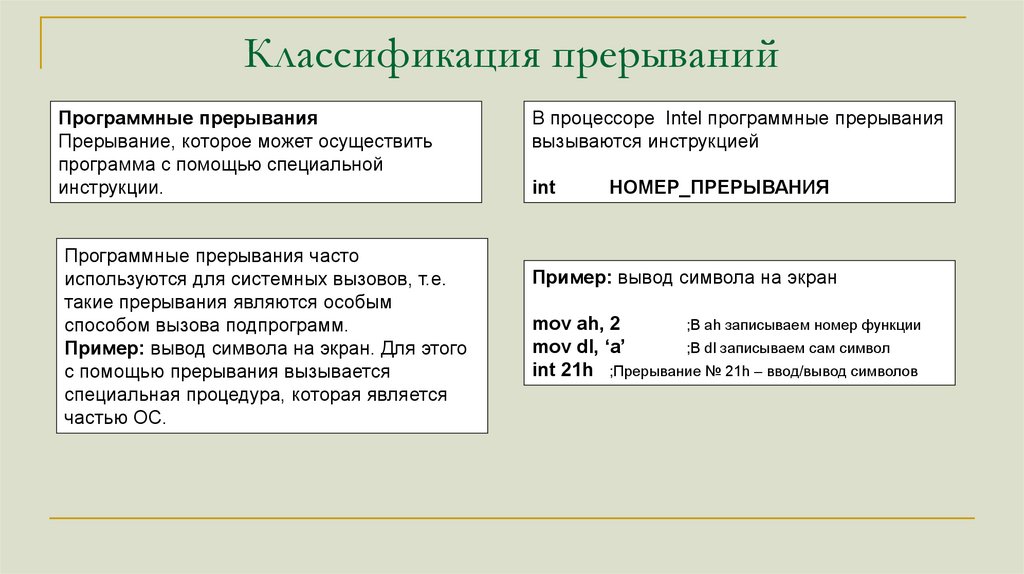
Классификация прерыванийПрограммные прерывания
Прерывание, которое может осуществить
программа с помощью специальной
инструкции.
Программные прерывания часто
используются для системных вызовов, т.е.
такие прерывания являются особым
способом вызова подпрограмм.
Пример: вывод символа на экран. Для этого
с помощью прерывания вызывается
специальная процедура, которая является
частью ОС.
В процессоре Intel программные прерывания
вызываются инструкцией
int
НОМЕР_ПРЕРЫВАНИЯ
Пример: вывод символа на экран
mov ah, 2
;В ah записываем номер функции
mov dl, ‘a’
;В dl записываем сам символ
int 21h ;Прерывание № 21h – ввод/вывод символов
96.
Классификация прерыванийМежпроцессорные прерывания
Особый тип прерываний.
Генерируются одним процессором,
чтобы прервать работу другого
процессора в многопроцессорных
системах.
Используются для управления и
синхронизации многопроцессорных
вычислений.
Ложные прерывания
Нежелательные аппаратные
прерывания. Возникают по
причине электромагнитных помех,
или генерируются некорректно
работающим либо неправильно
настроенным оборудованием.
97.
Номера и векторы прерыванийНомера и векторы прерываний
Каждое прерывание имеет номер. Обычно
номера обозначаются как IRQ 0, IRQ 1, IRQ 2
…
Вектор прерывания – адрес в памяти, по
которому находится обработчик прерывания.
В памяти хранится таблица соответствия
номера и вектора прерывания
В 16-битных процессорах Intel такая таблица
хранится в адресах начиная с нулевого
В 32-битных процессорах Intel адрес начала
таблицы хранится в регистре IDTR
98.
Номера и векторы прерыванийУстройство может иметь свой выделенный номер прерывания, либо делить
этот номер с другими устройствами.
Например клавиатура генерирует прерывания IRQ 1, другие устройства этот
номер не используют.
В случае, если несколько устройств используют один номер прерывания,
обработчик сам должен определить, что за устройство вызвало прерывание.
Способы назначения прерывания устройству:
• Фиксированный номер прерывания. То есть устройство всегда
генерирует прерывание с номером, определенным при его
изготовлении
• Номер прерывания устанавливается с помощью перемычки на
устройстве (например старые звуковые платы)
• Номер прерывания назначается автоматически операционной
системой (Технология Plug&Play)
99.
Структура машинныхкоманд процессоров
x86
Институт Информационных Технологий
Челябинский Государственный Университет
100.
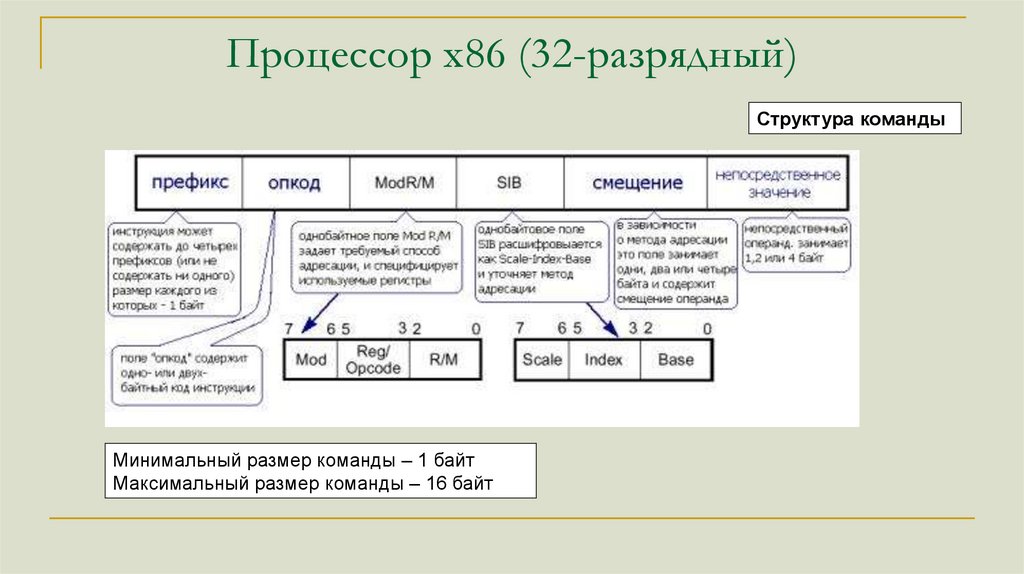
Процессор x86 (32-разрядный)Структура команды
Минимальный размер команды – 1 байт
Максимальный размер команды – 16 байт
101.
Процессор x86 (32-разрядный)1. Префиксы блокировки и повторения:
0xF0 LOCK
0хF2 REPNZ (только для строковых инструкций).
0xF3 REP (только для строковых инструкций).
2. Префиксы переопределения сегмента:
0х2E CS:
0х36 SS:
0х3E DS:
0х26 ES:
0х64 FS:
0х65 GS:
3. Префикс переопределения размеров операндов:
0х66
4. Префикс переопределения размеров адреса:
0х67
Префикс
Префиксы переопределения сегмента
указывают какой именно сегментной
регистр следует использовать для
обращения к ячейке памяти
Если в 32-разрядном коде встречается
префикс переопределения размеров
операндов, то процессор
интерпретирует операнды следующей
за ним инструкции как 16-разрядные и,
соответственно, наоборот.
102.
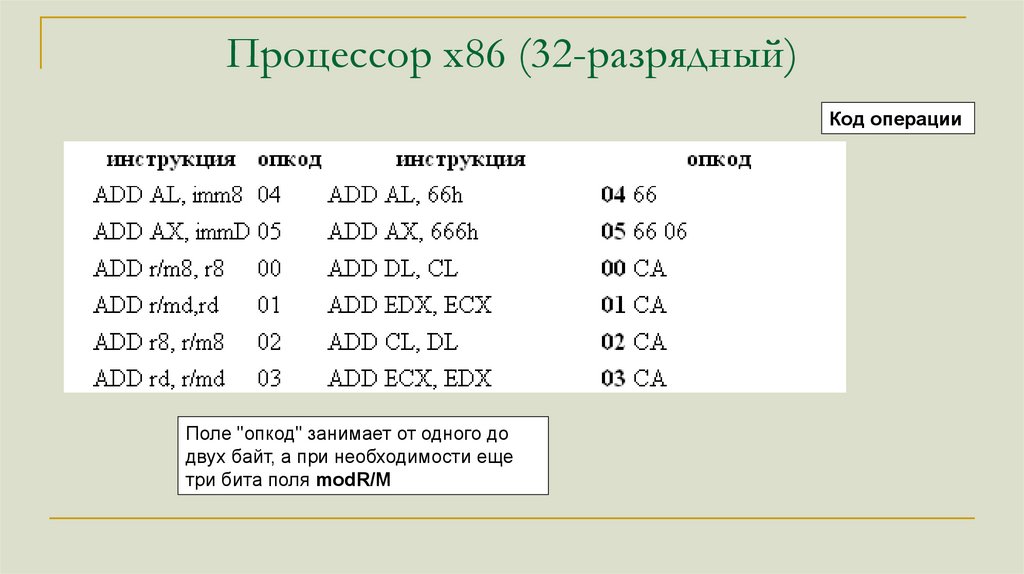
Процессор x86 (32-разрядный)Код операции
Поле "опкод" занимает от одного до
двух байт, а при необходимости еще
три бита поля modR/M
103.
Процессор x86 (32-разрядный)Поле modR/M
Содержит информацию об
операндах и режиме
адресации. Используется не
для всех команд.
mod=00 Операнд находится в
памяти, адрес находится в регистре,
код регистра хранится в R/M.
mod=01 К адресу прибавляется
значение поля «Смещение» (8 бит)
mod=10 Смещение 32 бита
mod=11 Операнды находятся в
регистрах
104.
Процессор x86 (32-разрядный)Поле SIB
Base - базовый регистр
Index – индексный регистр
Scale - степень двойки для
масштабирования
Например, если Scale=01, адрес
будет вычислен как
[ Base+(Index*2) ]
105.
Процессор x86 (32-разрядный)Примеры
add ah,bl
00000010 11100011
(02E3h)
add eax,[ebx+esi]
000000011 00000100 00110011
Опкод= 00000010 ADD r8,r/m8
mod=11 – регистры
reg=100 – регистр ah
R/M=011 – регистр bl
add al,3
00000100 00000011
(0403h)
Опкод= 00000100 ADD AL,imm8
00000011 – непосредственное значение
Опкод= 00000011 ADD r16/32 , r/m16/32
mod=00 – операнд в памяти
reg=000 – регистр eax
R/M=100 – Адрес в поле SIB
scale=00
index=110 – регистр esi
base=011 – регистр ebx
106.
Процессор x86 (32-разрядный)Примеры
add eax,i
add i,eax
000000011 00000101 00001111 11111111
00000000 10100011
000000001 00000101 00001111 11111111
00000000 10100011
Опкод= 00000011 ADD r16/32 , r/m16/32
mod=00 – операнд в памяти
reg=000 – регистр eax
Опкод= 00000001 ADD r/m16/32 , r16/32
mod=00 – операнд в памяти
reg=000 – регистр eax
R/M=101 – для mod=00 32-битный адрес в
поле смещение
0FFF00A3h – смещение, адрес
переменной i
R/M=101 – для mod=00 32-битный адрес
в поле смещение
0FFF00A3h – смещение, адрес
переменной i
107.
Процессор x86 (32-разрядный)add eax,A[esi]
000000011 10000110 00001111 11111111 00000000 10100011
Опкод= 00000011 ADD r16/32 , r/m16/32
mod=10 – операнд в памяти, 32-разрядное смещение +
регистр
reg=000 – регистр eax
R/M=110 – Регистр esi
0FFF00A3h – смещение, адрес массива A
Примеры
108.
Представление чиселс плавающей точкой
в ЭВМ
Институт Информационных Технологий
Челябинский Государственный Университет
109.
Представление чисел с плавающей точкойЭкспоненциальная запись — представление
действительных чисел в виде мантиссы и
порядка
N M *n
1000 1 * 10
Нормализованная экспоненциальная запись
накладывает ограничение:
p
1 | M | n
N — записываемое число;
M — мантисса;
n — основание;
p (целое) — порядок;
Примеры:
Экспоненциальная запись
Примеры:
3
500 50 *10
1
500 5 *10
5 1.25 * 2
2
2
110.
Представление чисел с плавающей точкойЗнак порядка не хранится.
Используется смещенный
порядок:
СП 2
a 1
1 ИП
В двоичном представлении
целая часть мантиссы
нормализованного числа всегда
равна 1. Поэтому целая часть не
хранится.
Чем больше разрядов отводится под запись мантиссы, тем выше
точность представления числа.
Чем больше разрядов занимает порядок, тем шире диапазон от
наименьшего до наибольшего числа
111.
Представление чисел с плавающей точкойПример
Общая длина – 32 бита
Порядок – 8 бит
Мантисса – 23 бита
- 247,37510 -11110111,0112 -1,11101110112 * 2
Порядок=7
Смещенный порядок=127+7=134
1 10000110 11101110110000000000000
7
112.
Представление чисел с плавающей точкойСложение вещественных чисел
Сложение вещественных чисел
1.
Порядки чисел выравниваются по
большему из них Для этого
мантисса меньшего числа
сдвигается на необходимое
количество разрядов вправо
(часть значащих цифр при этом
могут оказаться утерянными).
2.
Выполняется операция сложения
(вычитания) над мантиссами.
3.
Мантисса результата должна быть
нормализована (получившийся
после нормализации порядок
может отличаться как в меньшую,
так и в большую сторону).
Пример: 247,375+ 0,03125
0 10000110 11101110110000000000000
+
0 01111010 00000000000000000000000
Сдвигаем мантиссу меньшего числа на 12 разрядов
вправо:
0 10000110 11101110110000000000000
+
0 10000110 00000000000100000000000
0 10000110 11101110110100000000000(247,40625)
113.
Представление чисел с плавающей точкойТочность представления
Пример: 1048576 +0,03125
0 10010011 00000000000000000000000
+
0 01111010 00000000000000000000000
После операции сложения:
0 10010011 00000000000000000000000
=1048576
Несмотря на то, что оба числа могут быть
представлены, результат теряет часть младших
разрядов
114.
Представление чисел с плавающей точкойОсобые значения
+0
0 00000000 00000000000000000000000
-0
1 00000000 00000000000000000000000
+∞
0 11111111 00000000000000000000000
-∞
1 11111111 00000000000000000000000
NAN
1 11111111 11111111111111111111111
115.
Математическийсопроцессор
Процессор Intel 8087 был выпущен в 1980 году, он стал первым
математическим сопроцессором для линейки процессоров 8086
Предназначен для
расчетов с плавающей
точкой
Начиная с Intel 80486 является
неотъемлемой частью
процессора
116.
Математический сопроцессорРегистры
Регистры данных (R0 – R7) не
адресуются по именам. Вместо этого эти
восемь регистров рассматриваются как
стек, вершина которого называется ST, а
более глубокие элементы – ST(1), ST(2) и
так далее до ST(7).
117.
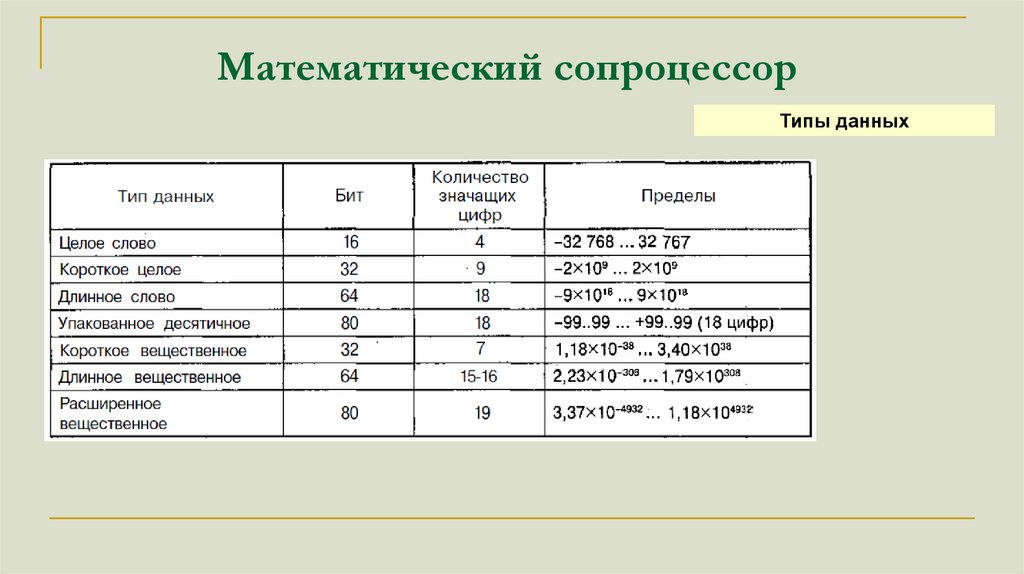
Математический сопроцессорТипы данных
118.
Математический сопроцессорКоманды пересылки данных
FLD – загрузить вещественное число в стек
FST – скопировать вещественное число из стека
FSTP – считать вещественное число из стека
FILD – загрузить целое число в стек
FIST – скопировать целое число из стека
FISTP – считать целое число из стека
119.
Математический сопроцессорАдресация операндов
120.
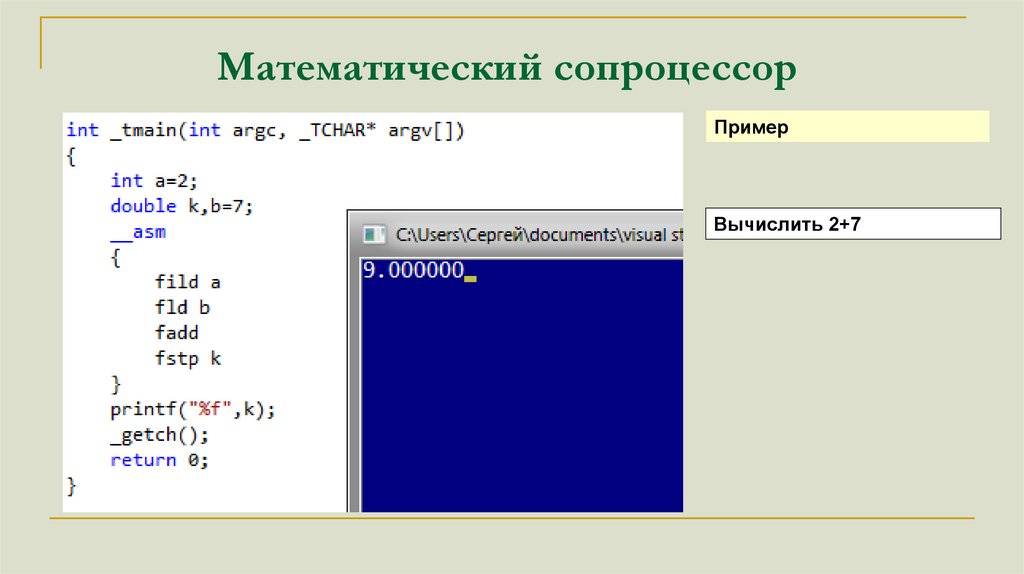
Математический сопроцессорПример
Вычислить 2+7
121.
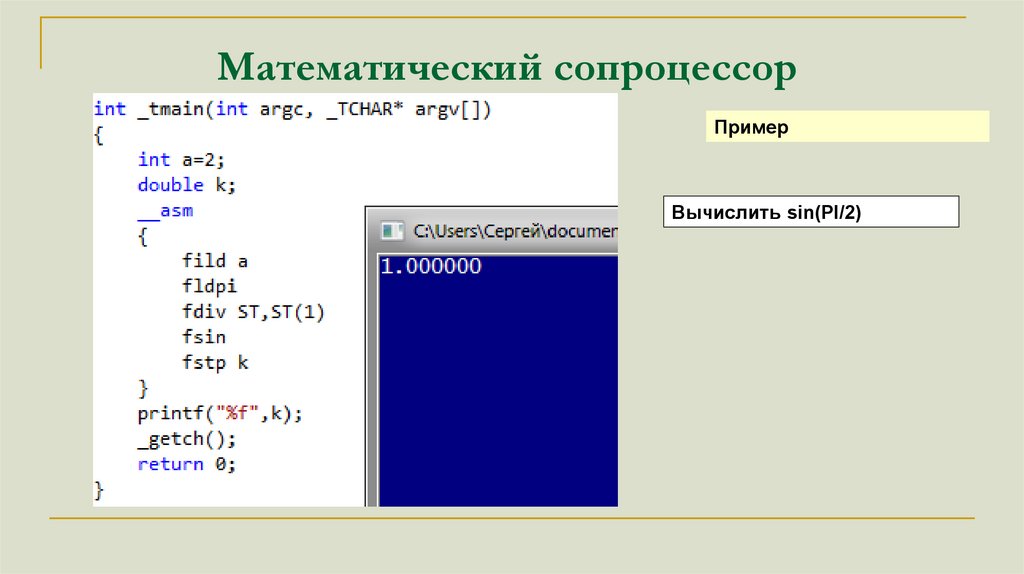
Математический сопроцессорПример
Вычислить sin(PI/2)
122.
Шины ипередача
данных
123.
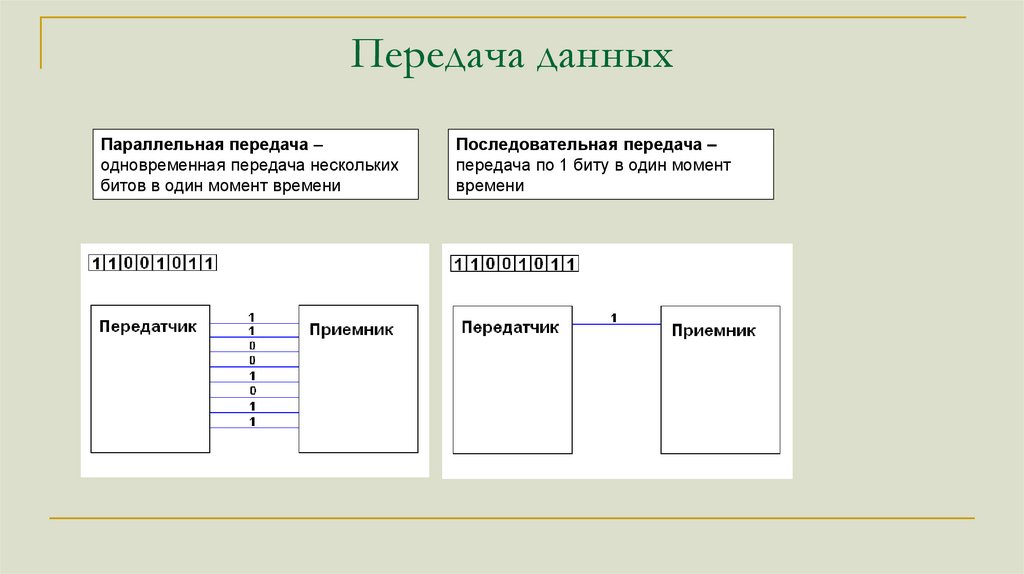
Передача данныхПараллельная передача –
одновременная передача нескольких
битов в один момент времени
Последовательная передача –
передача по 1 биту в один момент
времени
124.
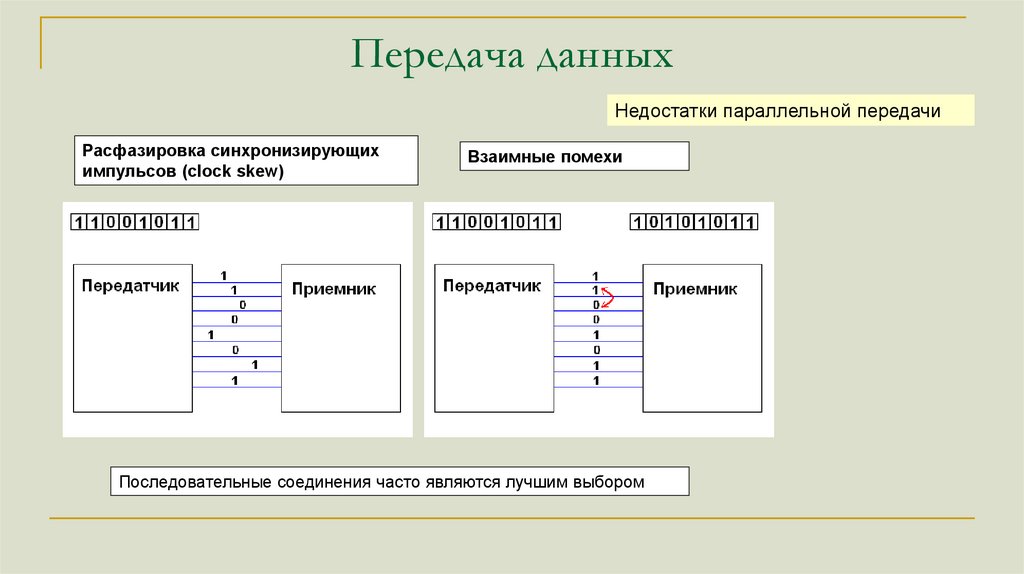
Передача данныхНедостатки параллельной передачи
Расфазировка синхронизирующих
импульсов (clock skew)
Взаимные помехи
Последовательные соединения часто являются лучшим выбором
125.
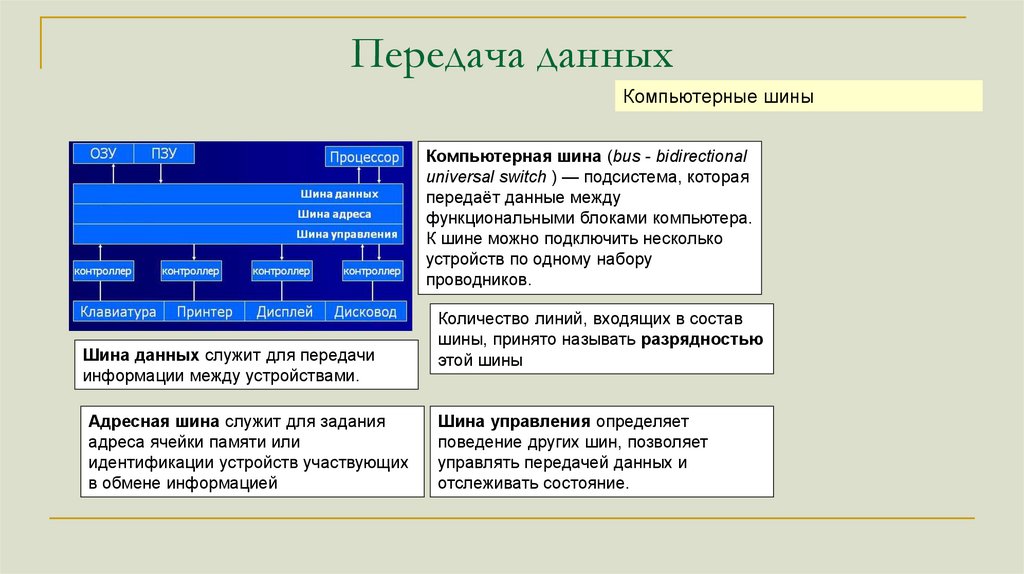
Передача данныхКомпьютерные шины
Компьютерная шина (bus - bidirectional
universal switch ) — подсистема, которая
передаёт данные между
функциональными блоками компьютера.
К шине можно подключить несколько
устройств по одному набору
проводников.
Шина данных служит для передачи
информации между устройствами.
Адресная шина служит для задания
адреса ячейки памяти или
идентификации устройств участвующих
в обмене информацией
Количество линий, входящих в состав
шины, принято называть разрядностью
этой шины
Шина управления определяет
поведение других шин, позволяет
управлять передачей данных и
отслеживать состояние.
126.
Компьютерные шиныПростейшая шина
127.
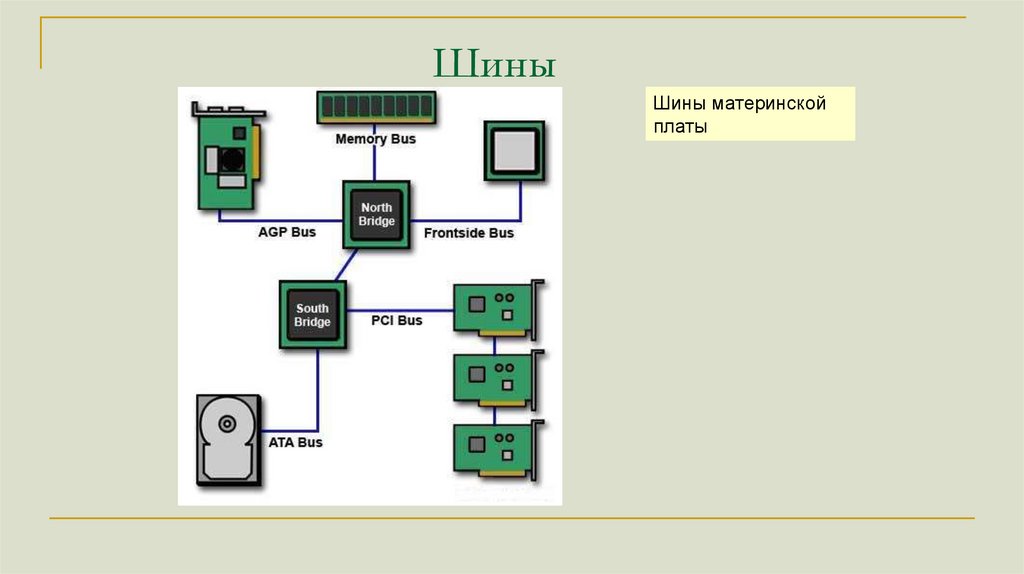
ШиныШины материнской
платы
128.
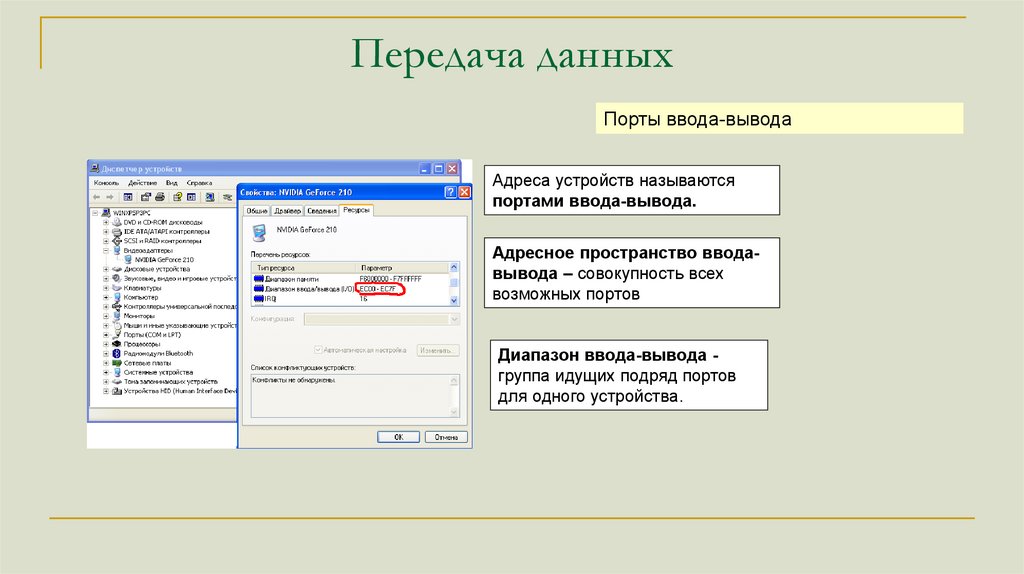
Передача данныхПорты ввода-вывода
Адреса устройств называются
портами ввода-вывода.
Адресное пространство вводавывода – совокупность всех
возможных портов
Диапазон ввода-вывода группа идущих подряд портов
для одного устройства.
129.
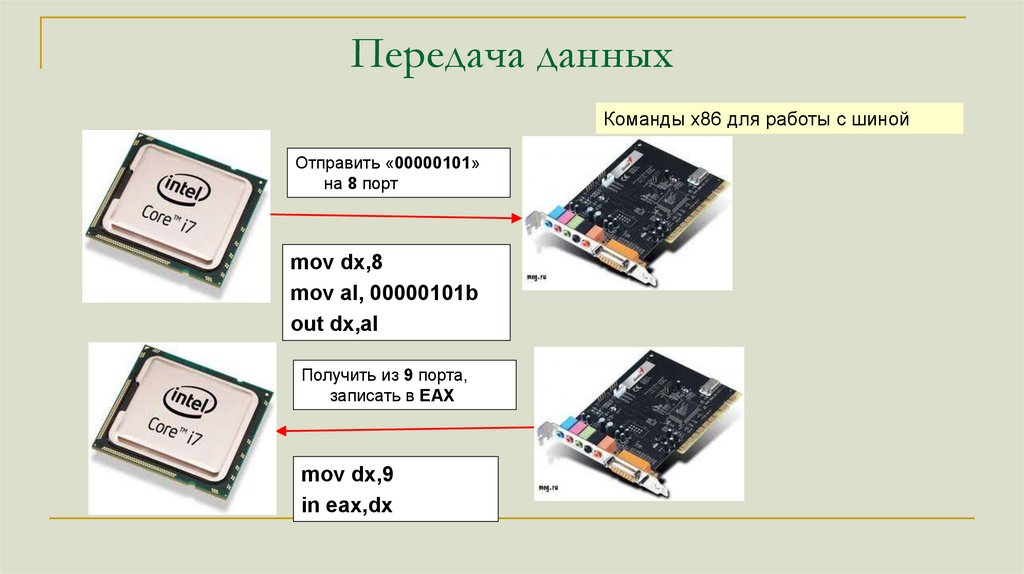
Передача данныхКоманды x86 для работы с шиной
Порт
Приемник
данных
Источник
данных
IN – читать данные с шины
OUT – отправить данные на шину
130.
Передача данныхКоманды x86 для работы с шиной
Отправить «00000101»
на 8 порт
mov dx,8
mov al, 00000101b
out dx,al
Получить из 9 порта,
записать в EAX
mov dx,9
in eax,dx
131.
Работа с шиной напримере I2C и SPI
Институт Информационных Технологий
Челябинский Государственный Университет
132.
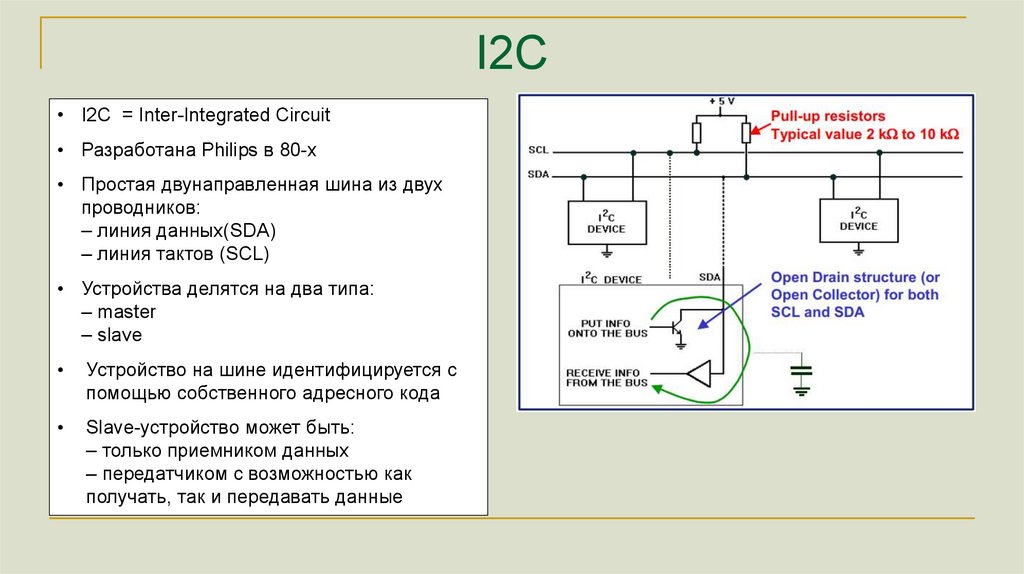
I2C• I2C = Inter-Integrated Circuit
• Разработана Philips в 80-х
• Простая двунаправленная шина из двух
проводников:
– линия данных(SDA)
– линия тактов (SCL)
• Устройства делятся на два типа:
– master
– slave
Устройство на шине идентифицируется с
помощью собственного адресного кода
Slave-устройство может быть:
– только приемником данных
– передатчиком с возможностью как
получать, так и передавать данные
133.
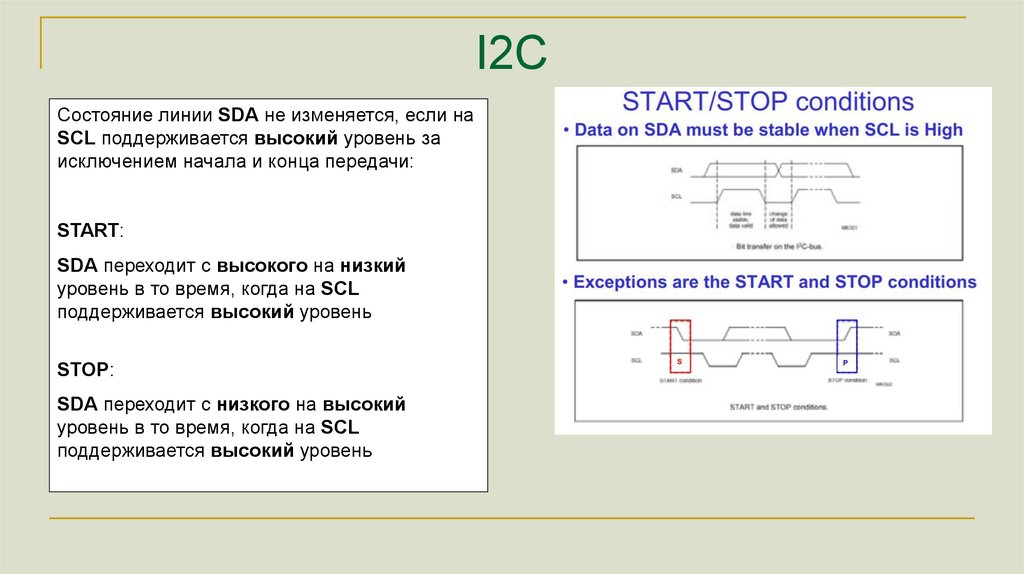
I2CСостояние линии SDA не изменяется, если на
SCL поддерживается высокий уровень за
исключением начала и конца передачи:
START:
SDA переходит с высокого на низкий
уровень в то время, когда на SCL
поддерживается высокий уровень
STOP:
SDA переходит с низкого на высокий
уровень в то время, когда на SCL
поддерживается высокий уровень
134.
I2C• Данные передаются блоками по 8 бит, 9-й
бит подтверждает прием данных
• Первый блок представляет собой 7битный адрес устройства + 1 бит
направления передачи
• Биты передаются путем выставления
высокого или низкого уровня на SDA в
то время, пока на SCL поддерживается
низкий уровень. Когда на SCL появляется
высокий уровень, принимающее
устройство должно считать бит
• Линией SCL управляет master. Однако
slave может устанавливать низкий
уровень на SCL, если он не успевает
обработать бит
135.
SPI• SPI (Serial Peripheral Interface —
последовательный синхронный стандарт
передачи данных в режиме полного
дуплекса
В SPI используются четыре цифровых
сигнала:
• MOSI(Master Out Slave In) — служит для
передачи данных от ведущего устройства
ведомому.
• MISO(Master In Slave Out) — служит для
передачи данных от ведомого устройства
ведущему.
• SCLK — последовательный тактовый
сигнал. Служит для передачи тактового
сигнала для ведомых устройств.
• CS или SS — выбор микросхемы, выбор
ведомого (Chip Select, Slave Select).
136.
Архитектурапроцессора
CISC (complex instruction set computer)
До начала 80-х совершенствование процессоров было
направлено на то, чтобы сконструировать по возможности
более функциональный компьютер, который позволил бы
выполнять как можно больше разных инструкций.
Причины:
• Удобно для программистов, так как компиляторы языков
высокого уровня еще только начинали развиваться, программы
писались на ассемблере.
• Такой подход позволяет уменьшить количество инструкции.
Это уменьшает размеры программы и время ее выполнения.
CISC
137.
Архитектура процессораCISC
инструкции «на все случаи
жизни»:
синус
косинус
квадратный
корень
факториал
добавить элемент в
очередь
провести
интерполяцию
полиномом
множество способов адресации
памяти:
регистровая
Косвеннорегистровая
взять в качестве аргумента инструкции
данные, записанные по адресу,
записанному вон в том регистре, со
смещением, записанным вот в этом
регистре
138.
Архитектура процессораОбщие признаки CISC:
Нефиксированное значение длины команды;
Действия с данными кодируются в одной команде;
Небольшое число регистров, каждый из которых выполняет
строго определённую функцию.
Недостатки CISC:
Инструкции сложно не только выполнять, но и декодировать
(выделять из машинного кода).
Оказалось, что даже в программах на ассемблере эти
"сверхвозможности" почти никогда не использовали, а
компиляторы языков высокого уровня - и не пытались
использовать.
Частые обращения к «медленной» оперативной памяти.
Сложности с реализацией конвейера и суперскалярности (все
инструкции разные по длине и по содержанию)
CISC
139.
Архитектура процессораRISC
RISC (restricted (reduced) instruction set computer)
RISC проектировался в расчете на типовой код, генерируемый
компиляторами.
1. Набор инструкций сведен к минимуму.
2. Количество режимов адресации – к абсолютному минимуму. В
классическом варианте RISC для обращения к оперативной
памяти оставлены только две инструкции - Load - загрузить
данные в регистр и Store - сохранить данные из регистра
(Load/Store-архитектура)
3. Увеличено количество регистров общего назначения.
140.
Архитектура процессораОбщие признаки RISC:
Фиксированная длина машинных инструкций и простой формат
команды.
Специализированные команды для операций с памятью —
чтения или записи. Операции вида «прочитать-изменитьзаписать» отсутствуют. Любые операции «изменить»
выполняются только над содержимым регистров.
Большое количество регистров общего назначения (32 и
более).
Преимущества RISC:
Простота реализации
Меньше обращений к «медленной» памяти (промежуточные
данные можно хранить в регистрах)
Просто реализуемый конвейер.
Более эффективное предсказание переходов.
RISC
141.
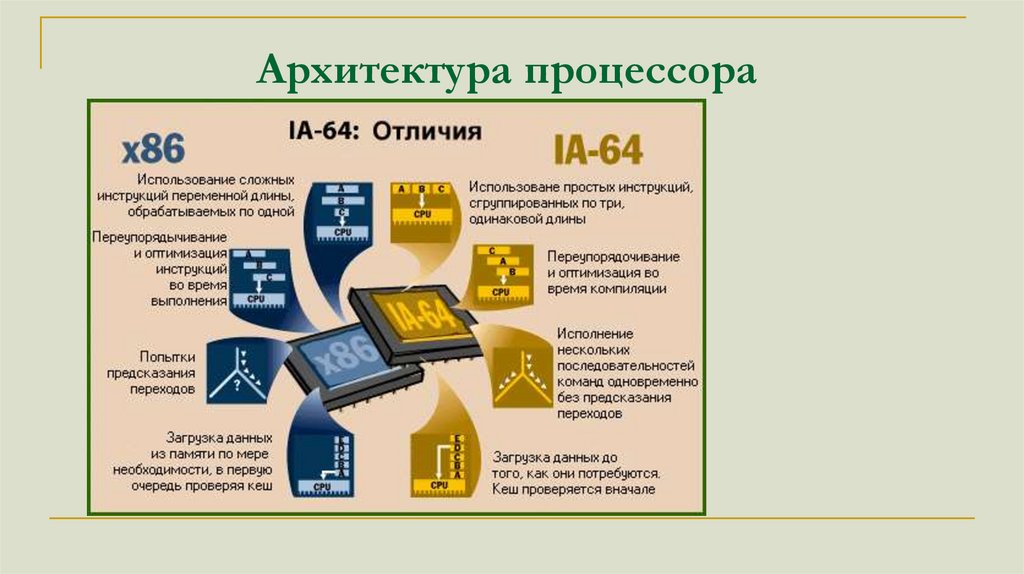
Архитектура процессораАрхитектура x86
Процессоры архитектуры x86 ранее являлись CISCпроцессорами, однако, начиная с Intel 486, являются CISCпроцессорами с RISC-ядром. Перед исполнением CISCинструкции x86 преобразуются в более простой набор
внутренних инструкций RISC.
Проблемы 32 разрядной архитектуры x86:
32 разрядная адресация позволяет использовать не более 4
Гб оперативной памяти (на практике не более 2).
Всего 4 регистра для хранения данных, частые обращения к
оперативной памяти. Как следствие, много тактов процессор
простаивает, ожидая данные.
Сложности с параллельным выполнением команд.
142.
Архитектура процессора64 разрядные архитектуры
IA-64
Разработана Intel и Hewlett Packard.
Процессоры: Itanium и Itanium 2.
x86-64
Разработана AMD.
Другие названия: x64, AA-64, Hammer Architecture, AMD64,
EM64T, IA-32e, Intel 64.
Процессоры: Athlon 64, Athlon II, Phenom, Turion 64,
Opteron, Sempron, Pentium Dual-Core, Core 2 Duo, Core 2
Quad, Core i3, Core i5, Core i7, Atom, Xeon.
143.
Архитектура процессораIA-64
Архитектура IA-64 основана на технологии EPIC (Explicity Parallel
Instruction Computing – вычисления с явной параллельностью
инструкций).
Регистры:
• 128 регистров общего назначения GR0-127
• 128 регистров с плавающей запятой FR0-127
• 64 регистра предикатов PR. Одноразрядные, в них
помещаются результаты команд сравнения.
• 8 регистров перехода BR. 64-разрядные, применяются для
указания адреса перехода
• 128 прикладных регистров AR. Специализированные (в
основном 64-разрядные) регистры.
• Счетчик команд IP.
144.
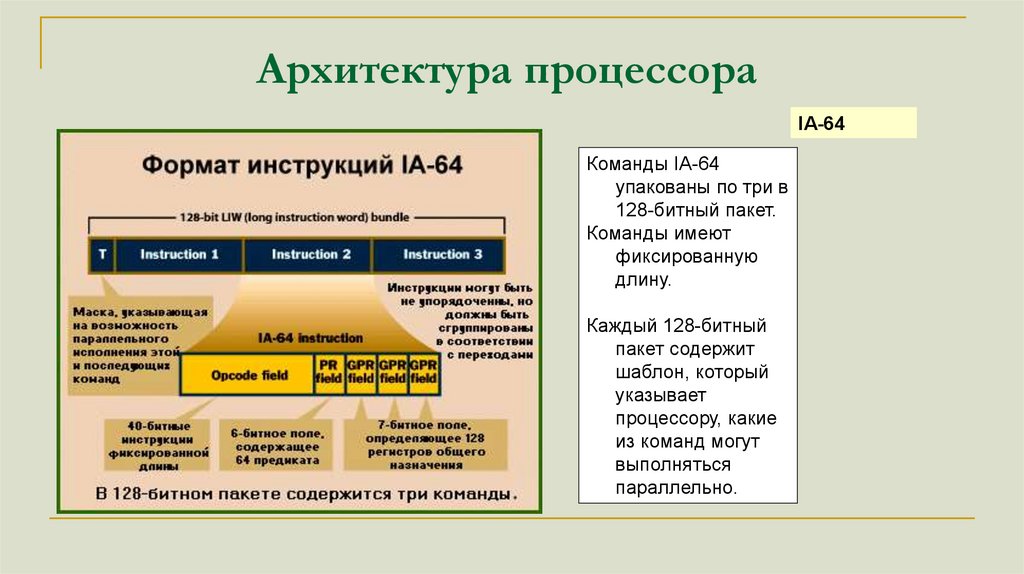
Архитектура процессораIA-64
Команды IA-64
упакованы по три в
128-битный пакет.
Команды имеют
фиксированную
длину.
Каждый 128-битный
пакет содержит
шаблон, который
указывает
процессору, какие
из команд могут
выполняться
параллельно.
145.
Архитектура процессораIA-64
Технология "отмеченных команд" (predication)
Компилятор может отметить все команды, относящиеся к одному
пути ветвления, уникальным идентификатором(предикатом).
Например, путь, соответствующий значению условия
ветвления TRUE, помечается предикатом Р1, а каждая
команда пути, соответствующего значению условия ветвления
FALSE - предикатом Р2.
Когда процессор обнаруживает "отмеченное" ветвление, он
начинает параллельно выполнять блоки, соответствующие
всем возможным путям ветвления.
В какой-то момент процессор вычислит значение условия
ветвления в операторе условного перехода. Предположим, оно
равно TRUE, следовательно, правильный путь отмечен
предикатом Р1. Результат работы всех остальных команд будет
отброшен.
146.
Архитектура процессораIA-64
Предварительная загрузка (speculative loading)
Компиляторы для IA-64 могут просматривать исходный код с
целью поиска команд, использующих данные из памяти. Найдя
такую команду, они могут добавить пару команд - команду
предварительной загрузки (speculative loading) и проверки
загрузки (speculative check).
Во время выполнения программы первая из команд загружает
данные в память до того, как они понадобятся программе.
Вторая команда проверяет, успешно ли произошла загрузка.
Предварительная загрузка позволяет уменьшить потери
производительности из-за задержек при доступе к памяти, а
также повысить параллелизм.
147.
Архитектура процессора148.
Архитектура процессораIA-64
(+) Возможность использовать до нескольких терабайт
оперативной памяти.
(+) Минимизированы задержки при доступе к «медленной»
памяти.
(+) Распараллеливание на этапе компиляции.
(-) Несовместимость с большинством ПО.
(-) Для использования всех возможностей необходим
принципиально новый компилятор. Компиляция будет
занимать много времени.
(-) Относительно большой размер конечного машинного кода.
149.
Архитектура процессораx86-64
x86-64 – расширение архитектуры x86 с полной обратной
совместимостью.
Режимы работы:
Long Mode(«Длинный» режим) дает возможность
воспользоваться всеми дополнительными преимуществами,
предоставляемыми архитектурой x86-64. Для использования
этого режима необходима 64-битная операционная система,
например, Windows XP Professional x64 Edition.
Legacy Mode позволяет процессору выполнять инструкции,
рассчитанные для процессоров x86, и предоставляет полную
совместимость с 32-битным кодом и операционными
системами. В этом режиме процессор ведёт себя точно так же,
как x86-процессор, например Pentium 4.
150.
Архитектура процессораx86-64
Регистры:
16 регистров общего
назначения (RAX, RBX, RCX,
RDX, RBP, RSI, RDI, RSP, R8 —
R15). Можно обращаться к
младшим 8-, 16- и 32-битам
новых регистров.
• 64-битный указатель RIP
• 64-битный регистр флагов
RFLAGS.
151.
Архитектура процессораx86-64
Преимущества
64-битное адресное пространство.
Расширенный набор регистров.
Привычный для разработчиков набор команд.
Возможность запуска старых 32-битных приложений в 64битной операционной системе.
Возможность использования 32-битных операционных
систем.
Недостатки
Увеличение требований программ к памяти из-за того, что
увеличился размер адресов и операндов.
Нет принципиального повышения производительности.
152.
Кэширование данных.Кэш процессора.
Институт Информационных Технологий
Челябинский Государственный Университет
153.
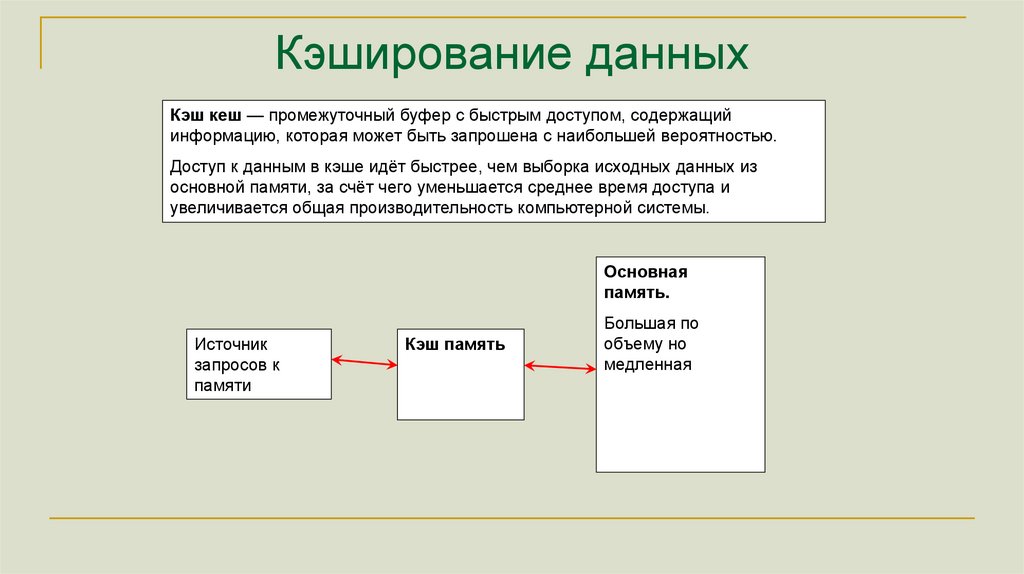
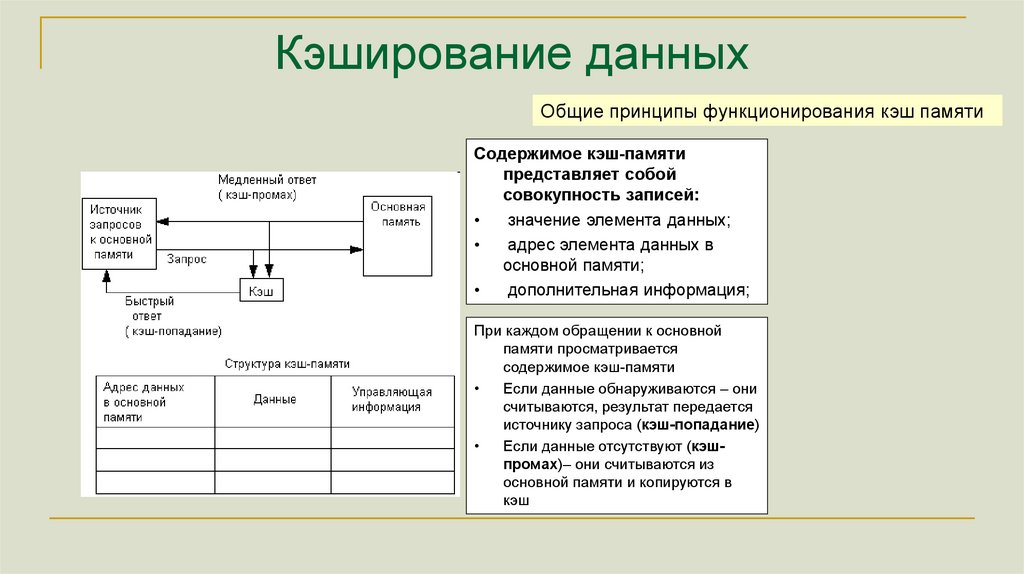
Кэширование данныхКэш кеш — промежуточный буфер с быстрым доступом, содержащий
информацию, которая может быть запрошена с наибольшей вероятностью.
Доступ к данным в кэше идёт быстрее, чем выборка исходных данных из
основной памяти, за счёт чего уменьшается среднее время доступа и
увеличивается общая производительность компьютерной системы.
Основная
память.
Источник
запросов к
памяти
Кэш память
Большая по
объему но
медленная
154.
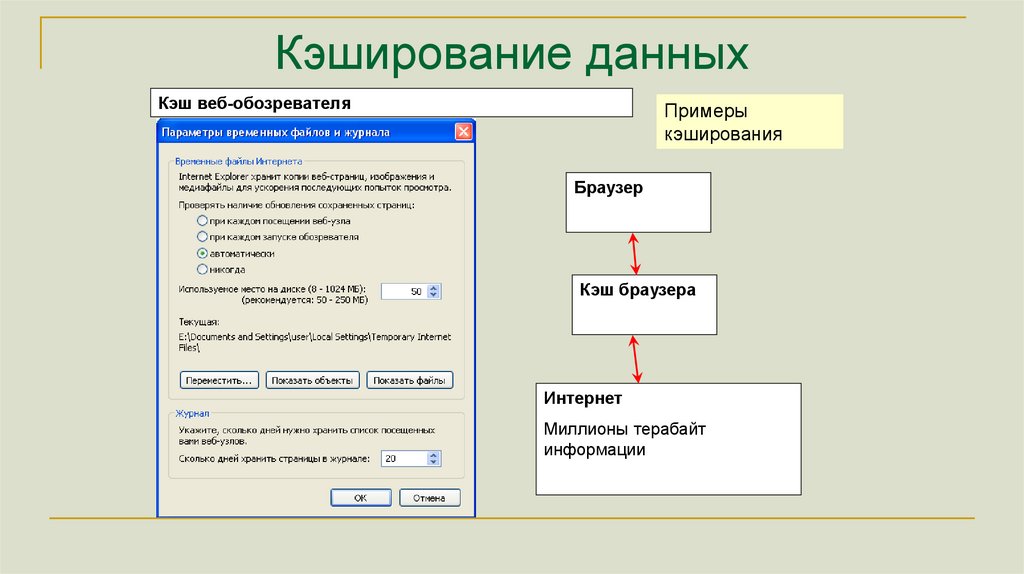
Кэширование данныхКэш веб-обозревателя
Примеры
кэширования
Браузер
Кэш браузера
Интернет
Миллионы терабайт
информации
155.
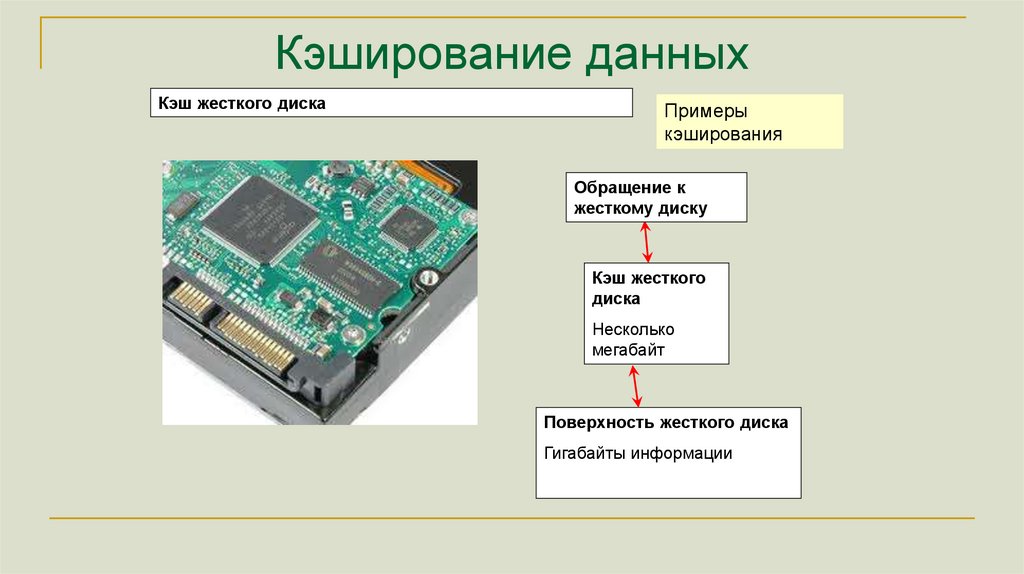
Кэширование данныхКэш жесткого диска
Примеры
кэширования
Обращение к
жесткому диску
Кэш жесткого
диска
Несколько
мегабайт
Поверхность жесткого диска
Гигабайты информации
156.
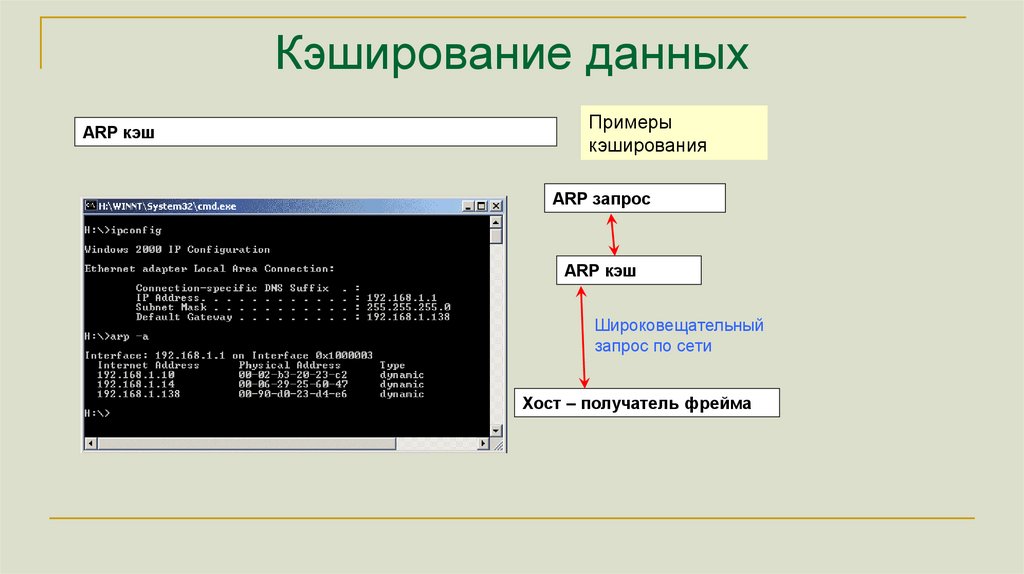
Кэширование данныхARP кэш
Примеры
кэширования
ARP запрос
ARP кэш
Широковещательный
запрос по сети
Хост – получатель фрейма
157.
Кэширование данныхОбщие принципы функционирования кэш памяти
Содержимое кэш-памяти
представляет собой
совокупность записей:
значение элемента данных;
адрес элемента данных в
основной памяти;
дополнительная информация;
При каждом обращении к основной
памяти просматривается
содержимое кэш-памяти
Если данные обнаруживаются – они
считываются, результат передается
источнику запроса (кэш-попадание)
Если данные отсутствуют (кэшпромах)– они считываются из
основной памяти и копируются в
кэш
158.
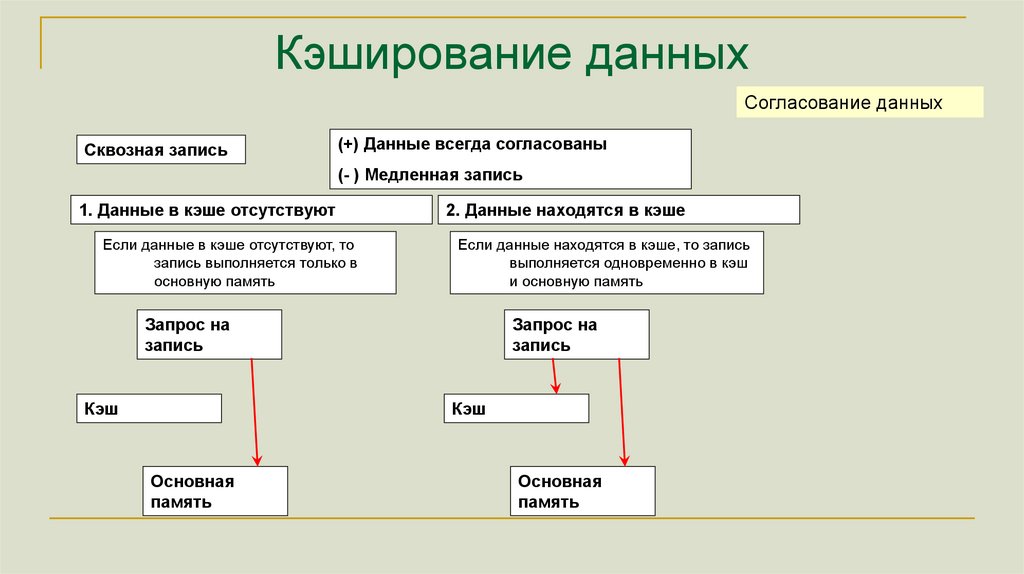
Кэширование данныхСогласование данных
Сквозная запись
(+) Данные всегда согласованы
(- ) Медленная запись
1. Данные в кэше отсутствуют
Если данные в кэше отсутствуют, то
запись выполняется только в
основную память
2. Данные находятся в кэше
Если данные находятся в кэше, то запись
выполняется одновременно в кэш
и основную память
Запрос на
запись
Кэш
Запрос на
запись
Кэш
Основная
память
Основная
память
159.
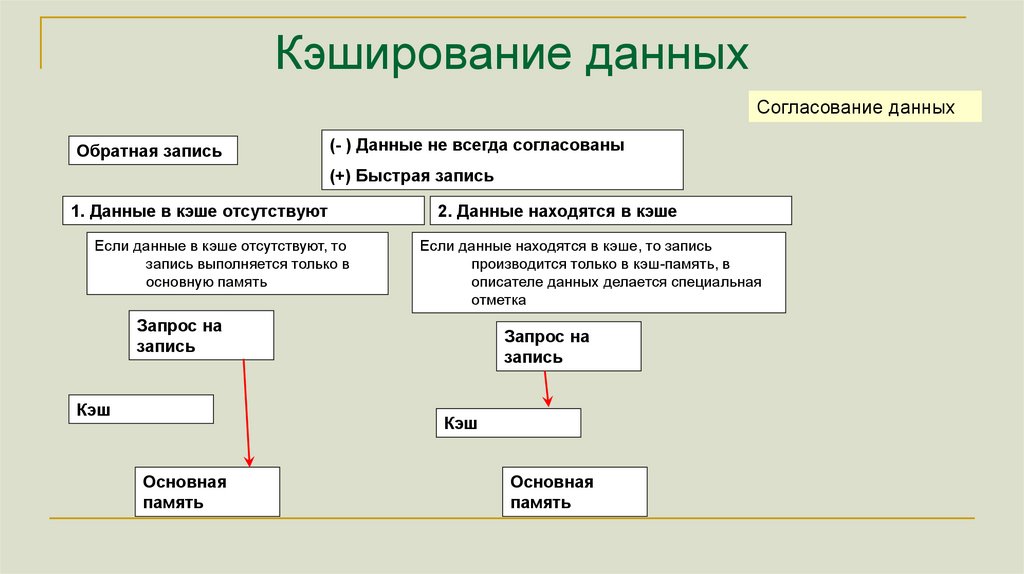
Кэширование данныхСогласование данных
Обратная запись
(- ) Данные не всегда согласованы
(+) Быстрая запись
1. Данные в кэше отсутствуют
Если данные в кэше отсутствуют, то
запись выполняется только в
основную память
2. Данные находятся в кэше
Если данные находятся в кэше, то запись
производится только в кэш-память, в
описателе данных делается специальная
отметка
Запрос на
запись
Кэш
Запрос на
запись
Кэш
Основная
память
Основная
память
160.
Кэширование данныхОтображение основной памяти на кэш
Ассоциативный поиск со случайным отображением
Элемент оперативной памяти
может быть размещен в
произвольном месте кэшпамяти. Данные
помещаются вместе с их
адресом
Электронная реализация
памяти должна позволять
параллельный поиск
произвольного адреса.
(- ) Дорого в реализации
(+) Эффективное
использование всего
пространства кэш-памяти
161.
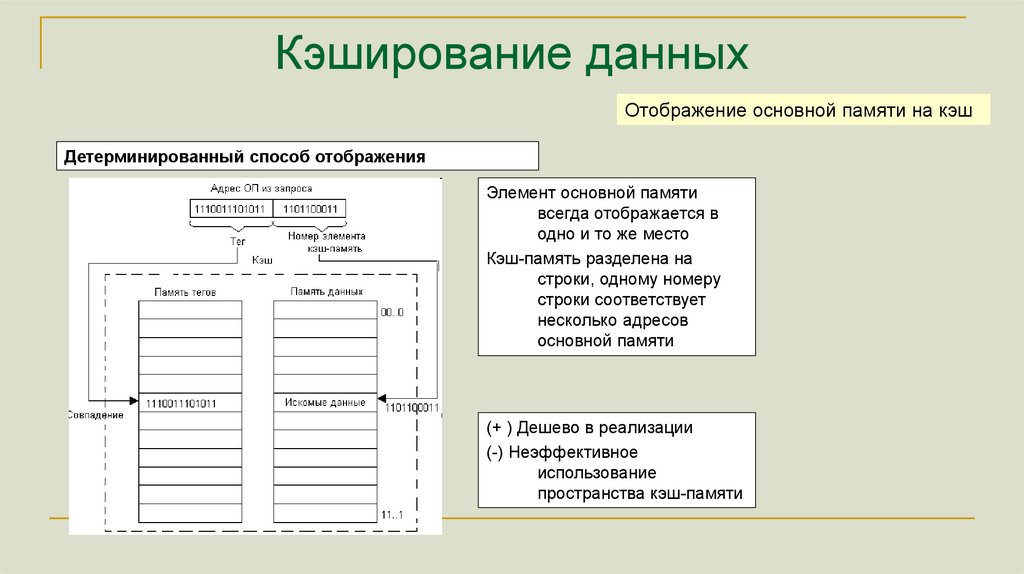
Кэширование данныхОтображение основной памяти на кэш
Детерминированный способ отображения
Элемент основной памяти
всегда отображается в
одно и то же место
Кэш-память разделена на
строки, одному номеру
строки соответствует
несколько адресов
основной памяти
(+ ) Дешево в реализации
(-) Неэффективное
использование
пространства кэш-памяти
162.
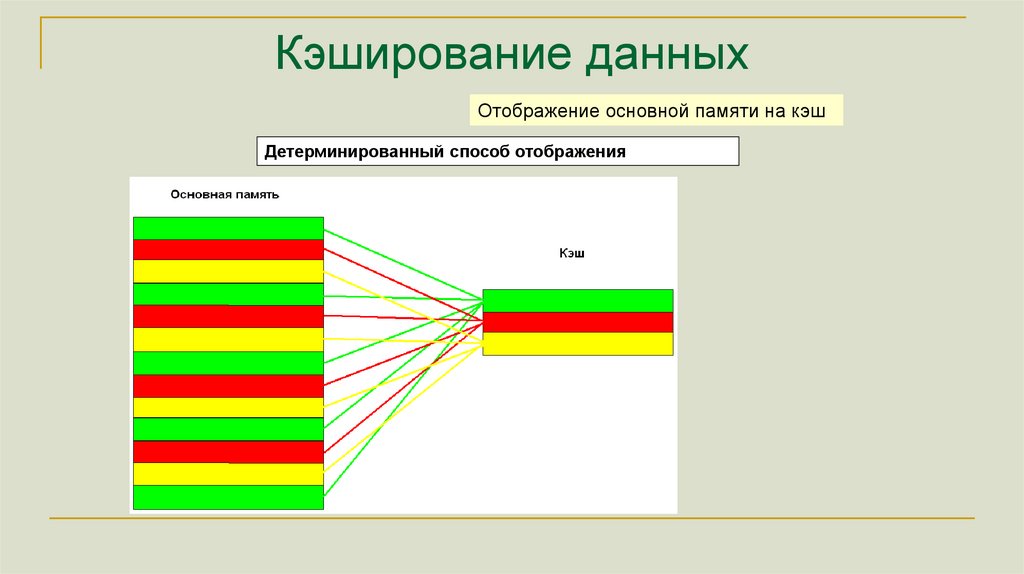
Кэширование данныхОтображение основной памяти на кэш
Детерминированный способ отображения
163.
Кэширование данныхОтображение основной памяти на кэш
Смешанный способ отображения
(N-Way Set Associative
N-канальная ассоциативность)
Произвольный адрес основной
памяти отображается на
группу адресов кэшпамяти
(+ ) Относительно дешево в
реализации
(+) Относительно эффективное
использование
пространства кэш-памяти
164.
Кэширование данныхАлгоритмы вытеснения
Если свободных записей кэша больше нет, то выполняется алгоритм
вытеснения. Алгоритм вытеснения существенно влияет на
производительность кэша.
Алгоритм Белади
Отбрасывать из кэша ту информацию, которая не понадобится в будущем
дольше всего. Так как в общем случае невозможно предсказать когда
именно в следующий раз потребуется именно эта информация, то на
практике (опять же, в общем случае) подобная реализация
невозможна.
Least Recently Used (LRU): в первую очередь, вытесняется
неиспользованный дольше всех. Этот алгоритм требует отслеживания
того, что и когда использовалось, что может оказаться довольно
накладно.
Общая реализация этого метода требует сохранения «битов возраста» для
строк кэша.
При каждом обращении к строке кэша увеличивается «возраст» всех
остальных строк.
165.
Кэширование данныхАлгоритмы вытеснения
Most Recently Used (MRU): В первую очередь вытесняется
последний использованный элемент.
Такой алгоритм полезен для схем с циклическим сканированием
данных.
Исследования показывают, что для схем случайного доступа и
циклического сканирования больших наборов данных
алгоритмы кэширования MRU имеют больше попаданий по
сравнению с LRU за счет их стремления к сохранению старых
данных.
Псевдо-LRU (PLRU): Для кэшей с большой ассоциативностью
(обычно >4 каналов), цена реализации LRU становится
непомерно высока. В этом случае можно использовать
алгоритм PLRU, требующий для элемента кэша только один
бит.
166.
Кэширование данныхКэш процессора
До начала 80-х память и процессор работали на одной и той же
частоте, с использованием одного тактового генератора.
Доступ в память был лишь немного медленнее доступа к
процессорным регистрам.
Ранние кэши были внешними по
отношению к процессору
с 1980х разрыв в производительности
между процессорами и памятью
стал нарастать. Микропроцессоры
совершенствовались быстрее чем
память. Память становилась узким
местом при достижении полной
производительности от системы.
Решение – ввести в систему
небольшую, но быструю кэш
память, для смягчения разрыва
в производительности
167.
Кэширование данныхКэш процессора – процессоры Intel
Внешняя кэш память впервые добавлена для Intel 80386.
Процессор работал на частоте 20 и более мегагерц.
Системное ОЗУ DRAM, имела задержки до 120 нс.
Кэш был построен на базе быстрой SRAM, которая в те времена
имела задержки около 10 нс.
С выходом процессора Intel 80486 8 КБ кэша было интегрировано
непосредственно на кристалл микропроцессора.
Этот кэш был назван L1. Кэш на материнской плате назван L2.
В процессоре Pentium
впервые используется
раздельный кэш, команд
и данных
168.
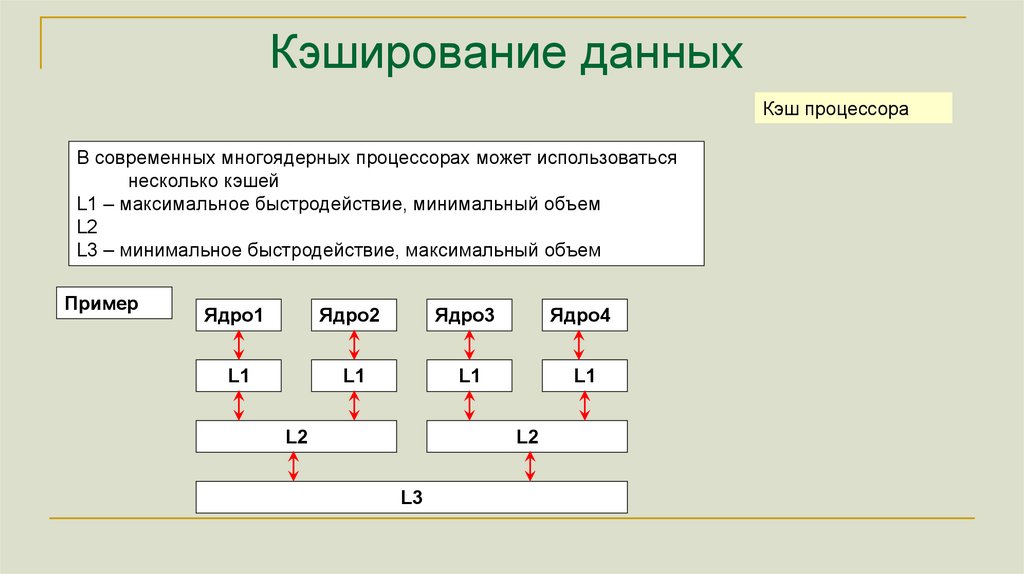
Кэширование данныхКэш процессора
В современных многоядерных процессорах может использоваться
несколько кэшей
L1 – максимальное быстродействие, минимальный объем
L2
L3 – минимальное быстродействие, максимальный объем
Пример
Ядро1
Ядро2
Ядро3
Ядро4
L1
L1
L1
L1
L2
L2
L3