
















 informatics
informaticsSimilar presentations:










Система оптического распознавания документов
1.
Система оптического распознавания документовПРЕЗЕНТАЦИЮ ВЫПОЛНИЛ: НИКОЛОВ АРТЁМ
2.
СодержаниеОптическое
распознавание
символов
История оптического
распознавания
текста
Поддерживаемые
языки OCR
OCR — оптическое
распознавание
символов
Azure AI Document
Intelligence
Как OCR связан с
интеллектуальной
обработкой
документов (IDP)?
Общие функции OCR
Подсистема OCR
Текущее состояние
технологии
оптического
распознавания
текста
3.
Оптическое распознавание символовОптическое распознавание символов (англ. optical character
recognition, OCR) — механический или электронный
перевод изображений
рукописного, машинописного или печатного текста
в текстовые данные использующиеся для представления
символов в компьютере (например, в текстовом редакторе).
Распознавание широко применяется для преобразования книг
и документов в электронный вид, для автоматизации систем
учёта в бизнесе или для публикации текста на веб-странице.
Оптическое распознавание символов позволяет
редактировать текст, осуществлять поиск слов или фраз,
хранить его в более компактной форме, демонстрировать или
распечатывать материал, не теряя качества, анализировать
информацию, а также применять к тексту электронный
перевод, форматирование или преобразование в речь.
4.
История оптическогораспознавания текста
В 1929 году Густав Таушек (нем. Gustav
Tauschek) получил патент на метод оптического
распознавания текста в Германии, после чего за
ним последовал Гендель (англ. Paul W. Handel),
получив патент на свой метод в США в 1933.
В 1935 году Таушек также получил патент США на
свой метод. Машина Таушека представляла собой
механическое устройство, которое использовало
шаблоны и фотодетектор.
5.
История оптического распознавания текстаВ 1950 году Дэвид Х. Шепард
(англ. David H.
Shepard), криптоаналитик из агентства
безопасности вооружённых сил
Соединённых Штатов,
проанализировав задачу
преобразования печатных сообщений
в машинный язык для обработки
компьютером, построил машину,
решающую данную задачу.
После того как он получил патент США,
он сообщил об этом в «Вашингтон
Дэйли Ньюз» (27 апреля 1951) и в «НьюЙорк Таймс» (26 декабря 1953). Затем
Шепард основал компанию,
разрабатывающую интеллектуальные
машины, которая вскоре выпустила
первые в мире коммерческие
системы оптического распознавания
символов.
6.
История оптическогораспознавания текста
Примерно в 1965 году «Ридерс дайджест» и «АрСи-Эй» начали сотрудничество с целью создать
машину для чтения документов, использующую
оптическое распознавание текста,
предназначенную для оцифровки серийных
номеров купонов «Ридерс дайджест», вернувшихся
из рекламных объявлений. Для печати на
документах барабанным принтером «Ар-Си-Эй»
был использован специальный шрифт OCR-A.
Машина для чтения документов работала
непосредственно с компьютером RCA 301 (одна из
первых полупроводниковых ЭВМ). Скорость работы
машины была 1500 документов в минуту: она
проверяла каждый документ, исключая те, которые
она не смогла обработать правильно.
7.
История оптическогораспознавания текста
В 1974 году Рэй Курцвейл создал компанию
«Курцвейл компьютер продактс» и начал работать
над развитием первой системы оптического
распознавания символов, способной распознать
текст, напечатанный любым шрифтом. Курцвейл
считал, что лучшее применение этой технологии —
создание машины чтения для слепых, которая
позволила бы слепым людям иметь компьютер,
умеющий читать текст вслух. Данное устройство
требовало изобретения сразу двух технологий —
ПЗС планшетного сканера и синтезатора,
преобразующего текст в речь. Конечный продукт
был представлен 13 января 1976 во время прессконференции, возглавлявшейся Курцвейлом и
руководителями Национальной федерации
слепых.
8.
В 1978 году компания «Курцвейл компьютер продактс»начала продажи первой коммерчески успешной
компьютерной программы оптического
распознавания символов. Два года спустя Курцвейл
продал свою компанию корпорации «Ксерокс»,
которая была заинтересована в дальнейшей
коммерциализации систем распознавания текста.
«Курцвейл компьютер продактс» стала дочерней
компанией «Ксерокс», известной как «Скансофт».
9.
В 1993 году вышла технология распознавания текстовроссийской компании ABBYY. На её основе создан ряд
корпоративных решений и программ для массовых
пользователей. В частности, программа для распознавания
текстов ABBYY FineReader, приложения для распознавания
текстовой информации с мобильных устройств, система
потокового ввода документов и данных ABBYY FlexiCapture.
Лицензиарами технологий распознавания текстов ABBYY
OCR являются международные ИТ-компании, такие
как Fujitsu, Panasonic, Xerox, Samsung, EMC и другие.
10.
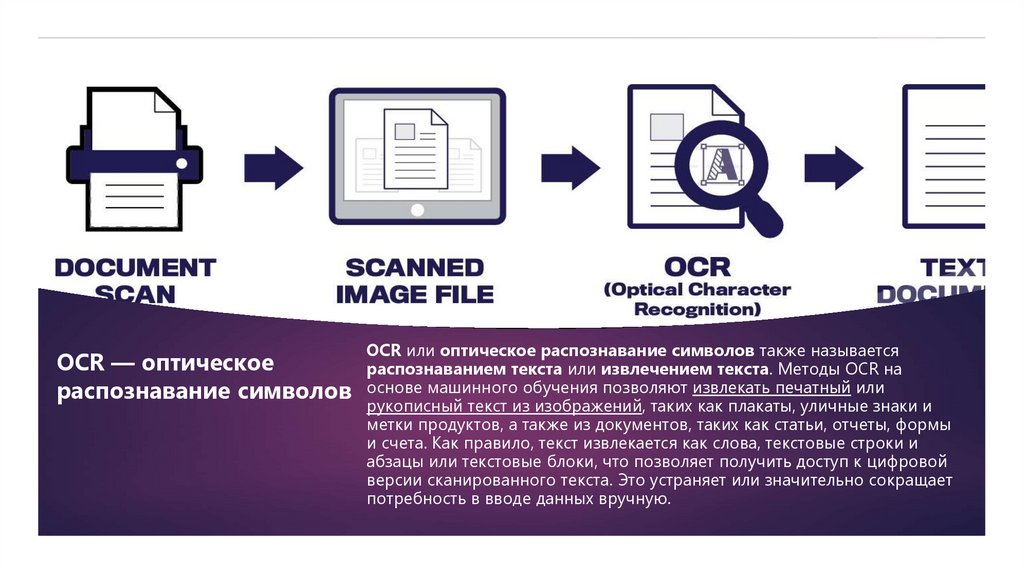
OCR — оптическоераспознавание символов
OCR или оптическое распознавание символов также называется
распознаванием текста или извлечением текста. Методы OCR на
основе машинного обучения позволяют извлекать печатный или
рукописный текст из изображений, таких как плакаты, уличные знаки и
метки продуктов, а также из документов, таких как статьи, отчеты, формы
и счета. Как правило, текст извлекается как слова, текстовые строки и
абзацы или текстовые блоки, что позволяет получить доступ к цифровой
версии сканированного текста. Это устраняет или значительно сокращает
потребность в вводе данных вручную.
11.
Как OCR связан синтеллектуальной
обработкой
документов (IDP)?
Интеллектуальная обработка документов (IDP) — это
технология автоматизации рабочих процессов,
которая сканирует, читает, извлекает,
классифицирует и упорядочивает важную
информацию из больших потоков данных в доступных
форматах. Технология может обрабатывать
различные типы документов: бумаги, PDFфайлы, документы Word, электронные таблицы и
множество других форматов.
12.
Как OCR связан синтеллектуальной
обработкой
документов (IDP)?
Интеллектуальная обработка документов (IDP)
использует OCR в качестве основной технологии для
дополнительного извлечения структуры, связей, ключевых
значений, сущностей и других аналитических сведений,
ориентированных на документ, с расширенной службой
искусственного интеллекта на основе машинного
обучения, такой как Аналитика документов. Аналитика
документов включает оптимизированную для документа
версию Read в качестве обработчика OCR при
делегировании другим моделям для более высокого
уровня аналитики. Если вы извлекаете текст из
сканированных и цифровых документов,
используйте OCR для чтения документов.
13.
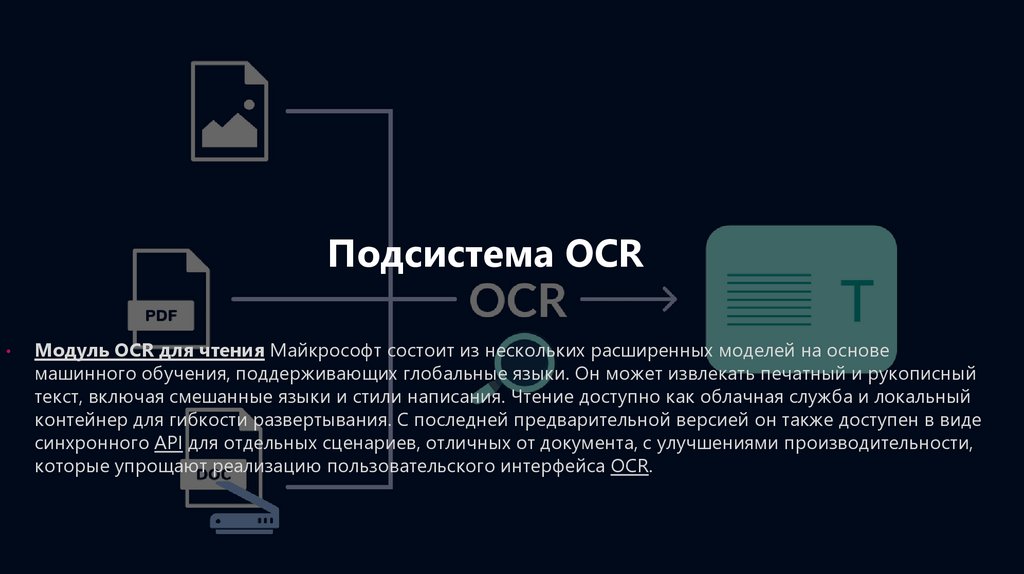
Подсистема OCRМодуль OCR для чтения Майкрософт состоит из нескольких расширенных моделей на основе
машинного обучения, поддерживающих глобальные языки. Он может извлекать печатный и рукописный
текст, включая смешанные языки и стили написания. Чтение доступно как облачная служба и локальный
контейнер для гибкости развертывания. С последней предварительной версией он также доступен в виде
синхронного API для отдельных сценариев, отличных от документа, с улучшениями производительности,
которые упрощают реализацию пользовательского интерфейса OCR.
14.
Поддерживаемые языки OCRОбе версии чтения , доступные сегодня в Azure
AI Vision, поддерживают несколько языков для
печати и рукописного текста. OCR для печатного
текста включает поддержку английского,
французского, немецкого, итальянского,
португальского, испанского, китайского,
японского, корейского, арабского, арабского,
Хинди и других международных языков,
использующих латинский, кириллический,
арабский и Деванагари. OCR для рукописного
текста включает поддержку английского,
китайского упрощенного, французского,
немецкого, итальянского, японского,
корейского, португальского и испанского
языков.
15.
Azure AI Document IntelligenceAzure AI Document Intelligence — это облачная служба ИИ Azure, которая
позволяет создавать интеллектуальные решения для обработки документов.
Большие объемы данных, охватывающие широкий спектр типов данных,
хранятся в формах и документах. Аналитика документов позволяет
эффективно управлять скоростью сбора и обработки данных и является
ключевым фактором для улучшения операций, принятия обоснованных
решений на основе данных и просвещенных инноваций.
16.
Общиефункции OCR
Модель OCR чтения доступна в Azure AI Vision и
Document Intelligence с общими базовыми
возможностями при оптимизации
соответствующих сценариев. В следующем списке
приведены общие функции:
1.
Извлечение текста на печатных и рукописных
текстах на поддерживаемых языках
2.
Страницы, текстовые строки и слова с оценкой
расположения и достоверности
3.
Поддержка смешанных языков, смешанный
режим (печать и рукописный ввод)
4.
Функция доступна как контейнер Distroless
Docker для локального развертывания
17.
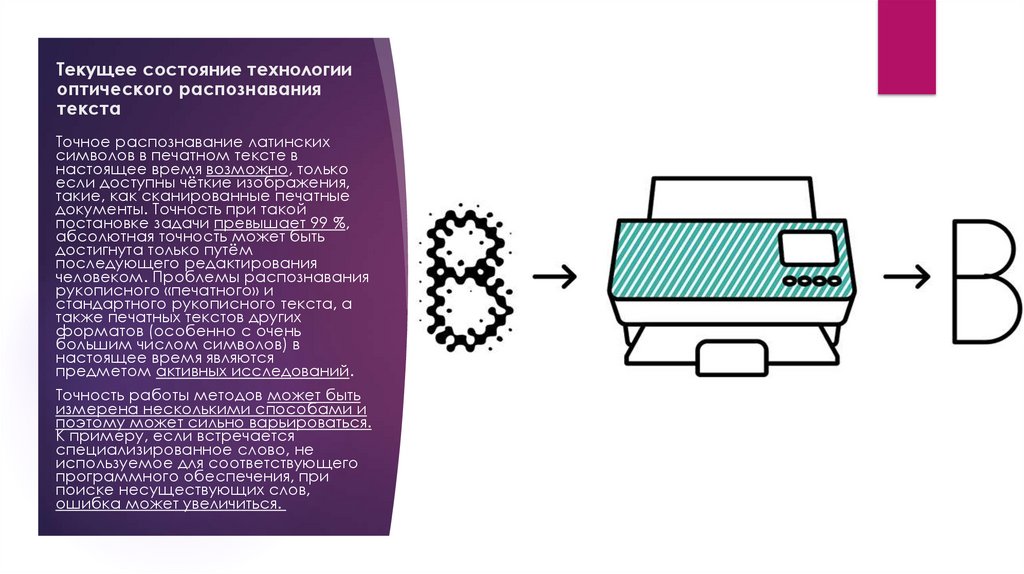
Текущее состояние технологииоптического распознавания
текста
Точное распознавание латинских
символов в печатном тексте в
настоящее время возможно, только
если доступны чёткие изображения,
такие, как сканированные печатные
документы. Точность при такой
постановке задачи превышает 99 %,
абсолютная точность может быть
достигнута только путём
последующего редактирования
человеком. Проблемы распознавания
рукописного «печатного» и
стандартного рукописного текста, а
также печатных текстов других
форматов (особенно с очень
большим числом символов) в
настоящее время являются
предметом активных исследований.
Точность работы методов может быть
измерена несколькими способами и
поэтому может сильно варьироваться.
К примеру, если встречается
специализированное слово, не
используемое для соответствующего
программного обеспечения, при
поиске несуществующих слов,
ошибка может увеличиться.
18.
ВыводВ ходе презентации была представлена система оптического распознавания документов
(OCR), которая является важным инструментом для автоматизации процесса работы с
документами.
Основная цель системы OCR - преобразовать отсканированные изображения или
электронные документы в текстовый формат, что позволяет проводить поиск, анализ и
обработку информации значительно быстрее и эффективнее.
Преимущества системы OCR включают в себя повышение производительности и точности
работы с документами, сокращение времени на обработку информации, снижение
риска ошибок ввода данных, а также улучшение доступности документов для поиска и
анализа.
Кроме того, система OCR может быть интегрирована с другими программными
продуктами и системами, что позволяет автоматизировать рабочие процессы и
увеличивать эффективность работы всей организации.
Таким образом, система оптического распознавания документов является неотъемлемой
частью современного офиса и предоставляет большие возможности для оптимизации
работы с документами и улучшения производительности организации.
19.
Источники1)
OCR — оптическое распознавание
символов
2)
Что такое Аналитика документов
Azure ИИ?
3)
Оптическое распознавание символов