
















































 informatics
informaticsSimilar presentations:






")



Технология ввода информации с бумажного носителя при помощи сканера
1.
Информатика для СПО2.
Важную роль в переводеинформации с бумажного
носителя в цифровой формат
играют технологии
сканирования.
3.
Сканер предназначен дляввода в компьютер
графической информации с
помощью оптических
устройств. В роли таких
устройств могут выступать
фото и видео камеры.
4.
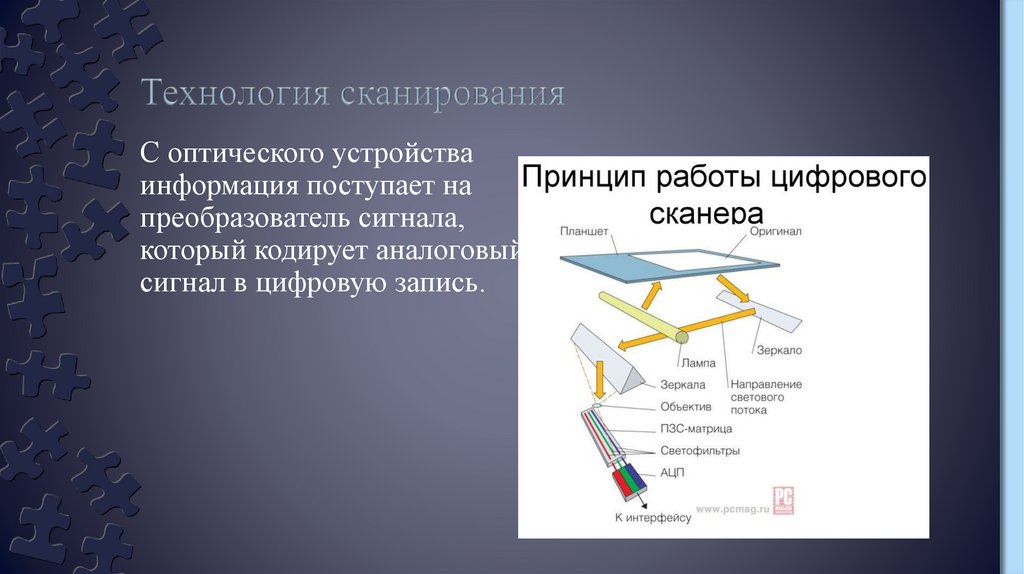
С оптического устройстваинформация поступает на
преобразователь сигнала,
который кодирует аналоговый
сигнал в цифровую запись.
5.
Для распознавания текста слиста бумаги, со страницы
журнала
или
книги
достаточно одного простого
оптического устройства и
одного преобразователя.
6.
Сканерыоцифровки
трехмерных
объектов
используют несколько камер
и
преобразователей
для
обеспечения многосторонней
съемки. Для работы сканера
необходимо
программное
обеспечение, которое создает
и
сохраняет
в
памяти
электронную
копию
трехмерных объектов.
7.
В результате сканированиямы получаем цифровое
изображение книги и ее
страниц. После этого мы
можем с помощью
специального программного
обеспечения распознавать
текстовые объекты,
содержащиеся в составе
изображения страницы, и
перекодировать их в текст.
8.
Для автоматизации вводаинформации сегодня
применяется также
технология распознавания
символов. В этом случае
информация кодируется с
помощью специальных
символов: штрих-кода, QRкода, Data Matrix и др.
9.
Считывание закодированныхсимволов происходит с
помощью сканирующих
устройств считывания штрихкодов. Считанная информация
преобразуется, выводится на
экран или бумажный чек и по
линиям связи передается на
более мощный компьютер для
дальнейшей обработки.
10.
Для считывания QR-кода нетребуются специальные
устройства. Достаточно иметь
любой компьютер с
фотокамерой и установленную
на нем программу
распознавания. Использование
QR-кода позволяет
пользователю, используя
личный смартфон, быстро и
автоматическом режиме считать
информацию об объекте,
получить доступ к связанным
ресурсам.
11.
Оптическое распознавание символов (англ. opticalcharacter recognition, OCR) — механический или
электронный перевод изображений рукописного,
машинописного или печатного текста в текстовые
данные, использующиеся для представления
символов в компьютере (например, в текстовом
редакторе). Распознавание широко применяется
для преобразования книг и документов в
электронный вид, для автоматизации систем учёта в
бизнесе или для публикации текста на вебстранице.
12.
Оптическое распознавание символов позволяетредактировать текст, осуществлять поиск слов или
фраз, хранить его в более компактной форме,
демонстрировать или распечатывать материал, не
теряя качества, анализировать информацию, а
также применять к тексту электронный перевод,
форматирование или преобразование в речь.
Оптическое распознавание текста является
исследуемой проблемой в областях распознавания
образов, искусственного интеллекта и
компьютерного зрения.
13.
Оптическое распознавание символов (англ. OpticalCharacter Recognition – OCR) – это технология,
которая позволяет преобразовывать различные типы
документов, такие как отсканированные документы,
PDF-файлы или фото с цифровой камеры, в
редактируемые форматы с возможностью поиска.
14.
Предположим, у вас есть бумажный документ,например, статья в журнале, брошюра или договор
в формате PDF, присланный вам партнером по
электронной почте. Очевидно, для того чтобы
получить возможность редактировать документ, его
недостаточно просто отсканировать. Единственное,
что может сделать сканер, – это создать
изображение документа, представляющее собой
всего лишь совокупность черно-белых или цветных
точек, то есть растровое изображение.
15.
Для того чтобы копировать, извлекать иредактировать данные, вам понадобится
программа для распознавания символов, которая
сможет выделить в изображении буквы, составить их
в слова, а затем объединить слова в предложения,
что в дальнейшем позволит работать с содержимым
исходного документа.
16.
Наиболее совершенные системы распознаваниясимволов, такие как ABBYY FineReader OCR, делают
акцент на использовании механизмов, созданных
природой. В основе этих механизмов лежат три
фундаментальных принципа: целостность,
целенаправленность и адаптивность (принципы IPA).
17.
Изображение, согласно принципу целостности,будет интерпретировано как некий объект, только
если на нем присутствуют все структурные части
этого объекта и эти части находятся в
соответствующих отношениях. Иначе говоря, ABBYY
FineReader не пытается принимать решение,
перебирая тысячи эталонов в поисках наиболее
подходящего. Вместо этого выдвигается ряд гипотез
относительно того, на что похоже обнаруженное
изображение. Затем каждая гипотеза
целенаправленно проверяется.
18.
И, допуская, что найденный объект может бытьбуквой А, FineReader будет искать именно те
особенности, которые должны быть у изображения
этой буквы. Как и следует поступать, исходя из
принципа целенаправленности. Принцип
адаптивности означает, что программа должна быть
способна к самообучению, поэтому проверять,
верна ли выдвинутая гипотеза, система будет,
опираясь на накопленные ранее сведения о
возможных начертаниях символа в данном
конкретном документе.
19.
Компания ABBYY, опираясь на результатымноголетних исследований, реализовала принципы
IPA в компьютерной программе. Система
оптического распознавания символов ABBYY
FineReader – единственная в мире система OCR,
действующая в соответствии с вышеописанными
принципами на всех этапах обработки документа.
Эти принципы делают программу максимально
гибкой и интеллектуальной, предельно приближая
ее работу к тому, как распознает символы человек.
20.
На первом этапе распознавания системапостранично анализирует изображения, из которых
состоит документ, определяет структуру страниц,
выделяет текстовые блоки, таблицы.
21.
Кроме того, современные документы частосодержат всевозможные элементы дизайна:
› иллюстрации,
› колонтитулы,
› цветной фон или
› фоновые изображения.
22.
Поэтому недостаточно просто найти и распознатьобнаруженный текст, важно с самого начала
определить, как устроен рассматриваемый
документ: есть ли в нем разделы и подразделы,
ссылки и сноски, таблицы и графики, оглавление,
проставлены ли номера страниц и т. д. Затем в
текстовых блоках выделяются строки, отдельные
строки делятся на слова, слова на символы.
23.
Важно отметить, что выделение символов и ихраспознавание также реализовано в виде
составных частей единой процедуры. Это позволяет
в полной мере использовать преимущества
принципов IPA. Выделенные изображения символов
поступают на рассмотрение механизмов
распознавания букв, называемых
классификаторами.
24.
В системе ABBYY FineReader применяютсяклассификаторы следующих типов: растровый,
признаковый, контурный, структурный, признаководифференциальный и структурно-дифференциальный.
Растровый и признаковый классификаторы
анализируют изображение и выдвигают несколько
гипотез о том, какой символ на нем представлен. В ходе
анализа каждой гипотезе присваивается определенная
оценка (так называемый вес). По итогам проверки мы
получаем список гипотез, проранжированный по весу
(то есть по степени уверенности в том, что перед нами
именно такой символ). Можно сказать, что в данный
момент система уже «догадывается», на что похож
рассматриваемый символ.
25.
После этого в соответствии с принципами IPA ABBYYFineReader проводит проверку выдвинутых гипотез.
Это делается с помощью дифференциального
признакового классификатора.
26.
Кроме того, следует отметить, что ABBYY FineReaderподдерживает 192 языка распознавания. Интеграция
системы распознавания со словарями помогает
программе при анализе документов:
распознавание происходит более точно и
упрощает дальнейшую проверку результата с
учетом данных об основном языке документа и
словарной проверки отдельных предположений.
После подробной обработки огромного числа
гипотез программа принимает решение и
предоставляет пользователю распознанный текст.
27.
Изображения, полученные при помощи цифровойкамеры, отличаются от отсканированных документов или
PDF, представляющих собой изображение.
У них зачастую могут быть определенные дефекты,
например искажения перспективы, засветки от
фотовспышки, изгибы строк. При работе с
большинством приложений такие дефекты могут
существенно усложнить процесс распознавания. В
связи с этим последние версии ABBYY FineReader
содержат технологии предварительной обработки
изображения, которые успешно выполняют задачи по
подготовке изображений к распознаванию.
28.
Технология ABBYY FineReader OCR проста виспользовании – процесс распознавания в целом
состоит из трех этапов: открытие (или
сканирование) документа, распознавание и
сохранение в наиболее подходящем формате
(DOC, RTF, XLS, PDF, HTML, TXT и т. д.) либо перенос
данных напрямую в офисные программы, такие как
Microsoft® Word®, Excel® или приложения для
просмотра PDF.
29.
Кроме того, последняя версия ABBYY FineReaderпозволяет автоматизировать задачи по
распознаванию и конвертации документов с
помощью приложения ABBYY Hot Folder. С помощью
него можно настраивать однотипные или
повторяющиеся задачи по обработке документов и
увеличить производительность работы.
30.
Высокое качество технологий распознавания текстаABBYY OCR обеспечивает точную конвертацию
бумажных документов (сканов, фотографий) и PDFдокументов любого типа в редактируемые
форматы. Применение современных OCRтехнологий позволяет сэкономить много сил и
времени при работе с любыми документами.
31.
С ABBYY FineReader OCR вы можете сканироватьбумажные документы и редактировать их. Вы
можете извлекать цитаты из книг и журналов и
использовать их без перепечатывания. С помощью
цифровой фотокамеры и ABBYY FineReader OCR вы
можете моментально сделать снимок увиденного
постера, баннера, а также документа или книги,
когда под рукой нет сканера, и распознать
полученное изображение. Кроме того, ABBYY
FineReader OCR можно использовать для создания
архива PDF-документов с возможностью поиска.
32.
Весь процесс преобразования из бумажногодокумента, снимка или PDF занимает меньше
минуты, а сам распознанный документ выглядит в
точности как оригинал!
33.
Весь процесс преобразования из бумажногодокумента, снимка или PDF занимает меньше
минуты, а сам распознанный документ выглядит в
точности как оригинал!
34.
В 1929 году Густав Таушек (Gustav Tauschek) получилпатент на метод оптического распознавания текста
в Германии, после чего за ним последовал Гендель
(Paul W. Handel), получив патент на свой метод
в США в 1933. В 1935 году Таушек также
получил патент США на свой метод. Машина
Таушека представляла собой механическое
устройство, которое использовало шаблоны и
фотодетектор.
35.
В 1950 году Дэвид Х. Шепард (David H. Shepard),криптоаналитик из агентства безопасности вооружённых
сил Соединённых Штатов, проанализировав задачу
преобразования печатных сообщений в машинный язык
для обработки компьютером, построил машину,
решающую данную задачу. После того как он получил
патент США, он сообщил об этом в «Вашингтон Дэйли
Ньюз» (27 апреля 1951) и в «Нью-Йорк Таймс» (26
декабря 1953). Затем Шепард основал компанию,
разрабатывающую интеллектуальные машины, которая
вскоре выпустила первые в мире коммерческие
системы оптического распознавания символов.
36.
Первая коммерческая система была установленана «Ридерс Дайджест» в 1955 году. Вторая система
была продана компании «Стандарт Ойл» для
чтения кредитных карт для работы с чеками. Другие
системы, поставляемые компанией Шепарда, были
проданы в конце 1950-х годов, в том числе сканер
страниц для национальных воздушных сил США,
предназначенный для чтения и передачи по
телетайпу машинописных сообщений. IBM позже
получила лицензию на использование патентов
Шепарда.
37.
Примерно в 1965 году «Ридерс Дайджест» и «Ар-Си-Эй»начали сотрудничество с целью создать машину для
чтения документов, использующую оптическое
распознавание текста, предназначенную для
оцифровки серийных номеров купонов «Ридерс
Дайджест», вернувшихся из рекламных объявлений. Для
печати на документах барабанным принтером «Ар-СиЭй» был использован специальный шрифт OCR-A.
Машина для чтения документов работала
непосредственно с компьютером RCA 301 (одна из
первых полупроводниковых ЭВМ). Скорость работы
машины была 1500 документов в минуту: она проверяла
каждый документ, исключая те, которые она не смогла
обработать правильно.
38.
Почтовая служба Соединённых Штатов с 1965 года длясортировки почты использует машины, работающие по
принципу оптического распознавания текста, созданные на
основе технологий, разработанных исследователем Яковом
Рабиновым. В Европе первой организацией, использующей
машины с оптическим распознаванием текста, был
британский почтамт. Почта Канады использует системы
оптического распознавания символов с 1971 года. На
первом этапе в центре сортировки системы оптического
распознавания символов считывают имя и адрес получателя
и печатают на конверте штрихкод. Он наносится
специальными чернилами, которые отчётливо видимы
в ультрафиолетовом свете. Это делается, чтобы избежать
путаницы с полем адреса, заполненным человеком, которое
может быть в любом месте на конверте.
39.
В 1974 году Рэй Курцвейл создал компанию «КурцвейлКомпьютер Продактс», и начал работать над развитием
первой системы оптического распознавания символов,
способной распознать текст, напечатанный любым
шрифтом. Курцвейл считал, что лучшее применение
этой технологии — создание машины чтения для слепых,
которая позволила бы слепым людям иметь компьютер,
умеющий читать текст вслух. Данное устройство
требовало изобретения сразу двух технологий —
ПЗС планшетного сканера и синтезатора,
преобразующего текст в речь. Конечный продукт был
представлен 13 января 1976 во время прессконференции, возглавляемой Курцвейлом и
руководителями национальной федерации слепых.
40.
В 1978 году компания «Курцвейл КомпьютерПродактс» начала продажи коммерческой версии
компьютерной программы оптического
распознавания символов. Два года спустя Курцвейл
продал свою компанию корпорации «Ксерокс»,
которая была заинтересована в дальнейшей
коммерциализации систем распознавания текста.
«Курцвейл Компьютер Продактс» стала дочерней
компанией «Ксерокс», известной как «Скансофт».
41.
Первой коммерчески успешной программой,распознающей кириллицу, была программа «AutoR»
российской компании «ОКРУС». Программа начала
распространяться в 1992 году, работала под
управлением операционной системы DOS и
обеспечивала приемлемое по скорости и качеству
распознавание даже на персональных
компьютерах IBM PC/XT с процессором Intel 8088 при
тактовой частоте 4,77 МГц. В начале 90-х
компания Hewlett-Packard поставляла свои сканеры на
российский рынок в комплекте с программой «AutoR».
Алгоритм «AutoR» был компактный, быстрый и в полной
мере «интеллектуальный», то есть по-настоящему
шрифтонезависимый.
42.
Этот алгоритм разработали и испытали ещё в конце 60х два молодых биофизика, выпускники МФТИ —Г. М. Зенкин и А. П. Петров. Свой метод распознавания
они опубликовали в журнале «Биофизика» в номере 12,
вып. 3 за 1967 год. В настоящее время алгоритм ЗенкинаПетрова применяется в нескольких прикладных
системах, решающих задачу распознавания
графических символов. На основе алгоритма
компанией Paragon Software Group в 1996 была создана
технология PenReader. Г.М Зенкин продолжил работу
над технологией PenReader в компании Paragon
Software Group[1]. Технология используется в
одноимённом продукте компании[2].
43.
В 1993 году вышла технология распознавания текстовроссийской компании ABBYY. На её основе создан
ряд корпоративных решений и программ для
массовых пользователей. В частности, программа
для распознавания текстов ABBYY FineReader,
приложения для распознавания текстовой
информации с мобильных устройств, система
потокового ввода документов и данных ABBYY
FlexiCapture. Технологии распознавания текстов
ABBYY OCR лицензируют международные ИТкомпании, такие
как Fujitsu, Panasonic, Xerox, Samsung[3], EMC и
другие.
44.
Точное распознавание латинских символов впечатном тексте в настоящее время возможно,
только если доступны чёткие изображения, такие,
как сканированные печатные документы. Точность
при такой постановке задачи превышает 99 %,
абсолютная точность может быть достигнута только
путём последующего редактирования человеком.
Проблемы распознавания рукописного «печатного»
и стандартного рукописного текста, а также
печатных текстов других форматов (особенно с
очень большим числом символов) в настоящее
время являются предметом активных исследований.
45.
Точность работы методов может быть измеренанесколькими способами и поэтому может сильно
варьироваться. К примеру, если встречается
специализированное слово, не используемое для
соответствующего программного обеспечения, при
поиске несуществующих слов, ошибка может
увеличиться.
46.
Распознавание символов онлайн иногда путают соптическим распознаванием символов.
Последний — это офлайн-метод, работающий со
статической формой представления текста, в то
время как онлайн-распознавание символов
учитывает движения во время письма. Например, в
онлайн-распознавании, использующем PenPoint OS
или планшетный ПК, можно определить, с какой
стороны пишется строка: справа налево или слева
направо.
47.
Онлайн-системы для распознавания рукописного текста «налету» в последнее время стали широко известны в качестве
коммерческих продуктов. Алгоритмы таких устройств
используют тот факт, что порядок, скорость и направление
отдельных участков линий ввода известны. Кроме того,
пользователь научится использовать только конкретные
формы письма. Эти методы не могут быть использованы в
программном обеспечении, которое использует
сканированные бумажные документы, поэтому проблема
распознавания рукописного «печатного» текста по-прежнему
остаётся открытой. На изображениях с рукописным
«печатным» текстом без артефактов может быть достигнута
точность в 80 % — 90 %, но с такой точностью изображение
будет преобразовано с десятками ошибок на странице.
Такая технология может быть полезна лишь в очень
ограниченном числе приложений.
48.
Ещё одной широко исследуемой задачейявляется распознавание рукописного текста. В данное
время достигнутая точность даже ниже, чем для
рукописного «печатного» текста. Более высокие
показатели могут быть достигнуты только с
использованием контекстной и грамматической
информации. Например, в ходе распознания искать
целые слова в словаре легче, чем пытаться выявить
отдельные знаки из текста. Знание грамматики языка
может также помочь определить, является ли слово
глаголом или существительным. Формы отдельных
рукописных символов иногда могут не содержать
достаточно информации, чтобы точно (более 98 %)
распознать весь рукописный текст.
49.
Для решения более сложных задач в областираспознавания используются, как правило,
интеллектуальные системы распознавания, такие,
как искусственные нейронные сети.
Для калибровки систем распознавания текста
создана стандартная база данных MNIST, состоящая
из изображений рукописных цифр.
50.
Контактная информация:Губанов Василий Сергеевич, к.т.н,
email: gvs1819kmt@yandex.ru