


























 database
databaseSimilar presentations:










Базы данных «ключ-значение»
1.
Базы данных «ключ-значение»2.
Перечень СУБД• Redis
• Riak
• Aerospike
• ScyllaDB
• …
3.
СУБД «ключ-значение»• Достоинства
• Хранение
произвольных
структур данных,
например множеств,
хеш-таблиц, строк
• Быстрый поиск по
ключу
• Недостатки
• Согласованность
данных относится
только к операциям
над отдельным
ключом
• Не возможны запросы
по атрибутам
3
4.
СУБД «ключ-значение»• Хранилище типа "ключ-значение" - это простая хештаблица,.
• Клиент может либо получить значение по ключу, либо
записать значение по ключу, либо удалить ключ из
хранилища данных. Значение - это двоичный объект
данных, который записан в хранилище без детализации
eгo внутренней структуры. что именно хранится в этом
объекте, определяет приложение.
• Примеры: Riak ,Redis (которую часто называют сервером
Data Structure) [Redis], Memcached DB и ее версии
,[Memcached], Berkeley DB [Вerkeley DB], HamsterDB
4
5.
Примеры использования
Хранение информации о сессии
Каждая веб-сессия является уникальной и имеет уникальный идентификатор sessionid.
Приложения, записывающие идентификатор sessionid на диск или в базу данных RDBMS,
могут извлечь немалую пользу из хранилищ типа "ключзначение", поскольку вся
информация о сессии может быть записана с помощью одного запроса PUT и получена с
помощью одного запроса GET. Операция, состоящая из одного запроса, выполняется очень
быстро, поскольку вся информация о сессии хранится в одном объекте. Во многих вебприложениях используется хранилище Memcached. Если требуется обеспечить высокую
доступность, можно использовать базу данных Riak.
Профили пользователей, предпочтения
Почти каждый пользователь имеет уникальный атрибут userid, username или какой-то
другой идентификатор, а также предпочтения, например, язык, цвет, часовой пояс,
выбранные товары и т.д. Все :это можно поместить в один объект и получать предпочтения
пользователя с помощью одной операции GET. Аналогично можно хранить профили
товаров.
Корзины заказа
Коммерческие веб-сайты используют корзины заказа, связанные с пользователем. Если
требуется, чтобы корзина заказа была доступна постоянно, независимо от браузеров,
компьютеров и сессий, всю информацию о покупках можно поместить в объект value с
ключом userid. Для таких ситуаций лучше всего подходит кластер Riak.
Кэширование данных
Работа с очередями
Организация блокировок (mutex)
рассылки сообщений на клиенты
6.
Когда хранилища типа "ключзначение» использовать не следуетОтношения между данными
Если между разными наборами данных необходимо установить отношения или
поддерживать корреляцию между разными наборами ключей, хранилища типа "ключзначение" являются неудачным выбором, даже несмотря на то, что некоторые из них
обеспечивают возможности перехода по ссылкам.
Транзакции, состоящие из многих операций
Если при сохранении нескольких ключей при записи одного из них произошел сбой и вы
хотите вернуться в исходное положение или выполнить откат остальных операций,
хранилища типа "ключ-значение" не смогут вам помочь.
Запрос по данным
Хранилища типа "ключ-значение" плохо справляются с поиском ключей по соответствующим
значениям. У них нет механизма для проверки значения на стороне базы данных, за
некоторыми исключениями, например механизма Riak Search или механизмов
индексирования Lucene [Lucene] и Solr [Solr].
Операции с множествами
Поскольку операции в каждый момент времени ограничены одним ключом, невозможно
работать с несколькими ключами одновременно. Если требуется обработать несколько
ключей сразу, это придется делать на клиентской стороне.
7.
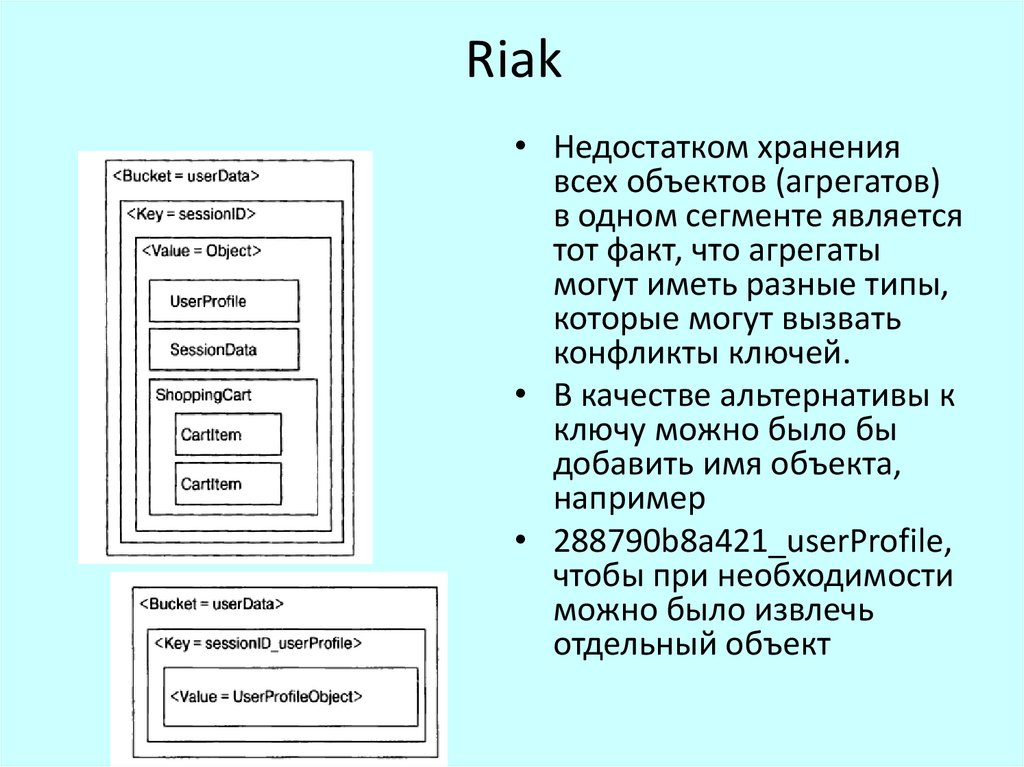
Riak• Riak хранит ключи в сегментах (buckets),
представляющих собой некое подобие пространств
имен, используемых для сегментирования ключей.
• Если бы мы захотели хранить данные сеанса
пользователя, информацию о его корзине товаров и
предпочтениях в базе данных Riak, то могли бы
просто записать их в один сегмент с одним ключом
для всех перечисленных объектов. В рамках такого
• сценария мы получили бы один объект,
содержащий все данные, и записали бы его в
отдельный сегмент
8.
Riak• Недостатком хранения
всех объектов (агрегатов)
в одном сегменте является
тот факт, что агрегаты
могут иметь разные типы,
которые могут вызвать
конфликты ключей.
• В качестве альтернативы к
ключу можно было бы
добавить имя объекта,
например
• 288790b8a421_userProfile,
чтобы при необходимости
можно было извлечь
отдельный объект
9.
Redis• Хранилище данных в памяти с открытым
исходным кодом, используемое
миллионами разработчиков в качестве
базы данных, кэша, механизма потоковой
передачи и брокера сообщений.
• Redis CLI
10.
КлючиКлючи Redis двоично безопасны, это означает, что вы можете использовать любую двоичную
последовательность в качестве ключа, от строки, такой как «foo», до содержимого файла
JPEG. Пустая строка также является допустимым ключом.
Очень длинные ключи - не лучшая идея. Например, ключ размером 1024 байта — плохая
идея не только с точки зрения памяти, но и потому, что поиск ключа в наборе данных может
потребовать нескольких дорогостоящих сравнений ключей. Даже когда задача состоит в том,
чтобы сопоставить существование большого значения, хеширование (например, с помощью
SHA1) является лучшей идеей, особенно с точки зрения памяти и пропускной способности.
Очень короткие ключи часто не являются хорошей идеей.
Нет смысла писать «u1000flw» в качестве ключа, если вместо этого вы можете написать
«user:1000:followers». Последний более удобочитаем, а добавленное пространство
незначительно по сравнению с пространством, используемым самим ключевым объектом и
объектом-значением.
Старайтесь придерживаться схемы. Например, "object-type:id" - хорошая идея, например,
"user:1000". Точки или тире часто используются для полей, состоящих из нескольких слов,
например, «comment:1234:reply.to» или «comment:1234:reply-to».
Максимально допустимый размер ключа составляет 512 МБ.
11.
Срок храненияХранилища ключей и значений типа Redis часто применяются как
быстрый кэш для хранения данных, которые трудно или долго вычислять каждый раз заново.
Задание срока хранения позволяет избежать неограниченного роста множества ключей,
поскольку Redis автоматически удаляет пару ключ-значение по истечении указанного
времени.
Чтобы задать срок хранения ключа, нам понадобится команда
EXPIRE, которой передается уже существующий ключ и время его
жизни в секундах. Ниже срок хранения 10 секунд. Если в
течение этого промежутка проверить существование ключа с помощью команды EXISTS, то мы
получим в ответ 1 (true). Но если немного подождать, то в конечном итоге команда вернет 0
(false).
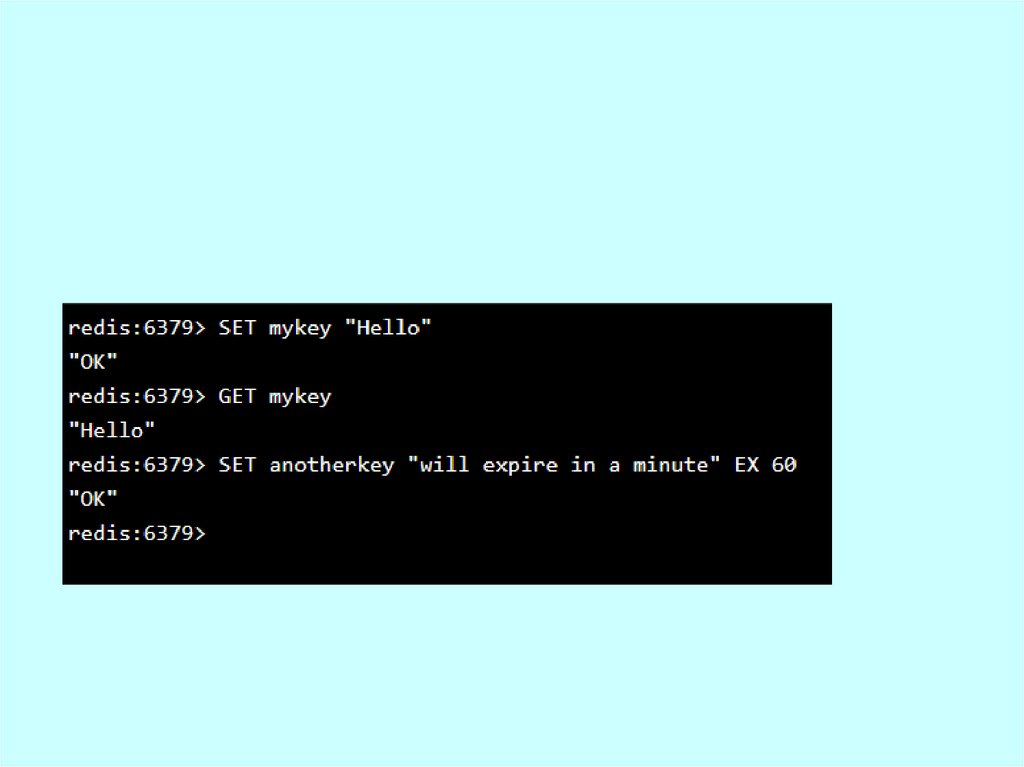
• redis 127.0.0.1:6379> SET ice “I’m melting…”
• OK
• redis 127.0.0.1:6379> EXPIRE ice 10
• (integer) 1
• redis 127.0.0.1:6379> EXISTS ice
• (integer) 1
• redis 127.0.0.1:6379> EXISTS ice
• (integer) 0
12.
redis 127.0.0.1:6379> SETEX ice 10 “I’m melting…”
Команда TTL позволяет запросить время жизни ключа
redis 127.0.0.1:6379> TTL ice
(integer) 4
В любой момент до истечения срока хранения таймаут
можно отменить, выполнив команду PERSIST ключ.
• redis 127.0.0.1:6379> PERSIST ice
• Можно также указать не относительное (в виде числа
секунд, начиная с текущего момента), а абсолютное
время удаления ключа. Для этого предназначена
команда EXPIREAT
13.
set• SET key value [ EX seconds | PX milliseconds | EXAT unix-time-seconds |
PXAT unix-time-milliseconds | KEEPTTL] [ NX | XX] [GET]
• EX секунд -- Установите указанное время истечения срока действия в
секундах.
• PX миллисекунды — установите указанное время истечения срока
действия в миллисекундах.
• EXAT timestamp-seconds -- Установите указанное время Unix, по
истечении которого истечет срок действия ключа, в секундах.
• PXAT timestamp-milliseconds -- Установите указанное время Unix, по
истечении которого истечет срок действия ключа, в миллисекундах.
NX -- Установите ключ только в том случае, если он еще не существует.
XX -- Установите ключ только в том случае, если он уже существует.
KEEPTTL -- Сохранить время жизни, связанное с ключом.
• GET -- возвращает старую строку, хранящуюся в ключе, или nil, если
ключ не существует. Возвращается ошибка и SET прерывается, если
значение, хранящееся в ключе, не является строкой.
14.
15.
Redis типы данных• String
• List
• Set
• Hash
• Sorted Set
• Bitmap
• HyperLogLog
• Stream
• Geospatial index
• https://redis.io/docs/manual/data-types/
16.
StringСтроки Redis безопасны двоично безопасны, это означает, что строка Redis
может содержать любые данные, например изображение JPEG или
сериализованный объект Ruby.
Строковое значение может иметь длину не более 512 мегабайт.
Можно использовать строки как атомарные счетчики, используя команды
семейства INCR: INCR, DECR, INCRBY.
Приписать строки к строкам с помощью команды APPEND.
Использовать строки в качестве векторов произвольного доступа с
помощью GETRANGE и SETRANGE.
Кодировать много данных на небольшом пространстве или создайте
фильтр Блума на основе Redis с помощью GETBIT и SETBIT.
Фильтр Блума (англ. Bloom filter) — это вероятностная структура данных,
придуманная Бёртоном Блумом в 1970 году, позволяющая проверять
принадлежность элемента к множеству. При этом существует возможность
получить ложноположительное срабатывание (элемента в множестве нет, но
структура данных сообщает, что он есть), но не ложноотрицательное.
17.
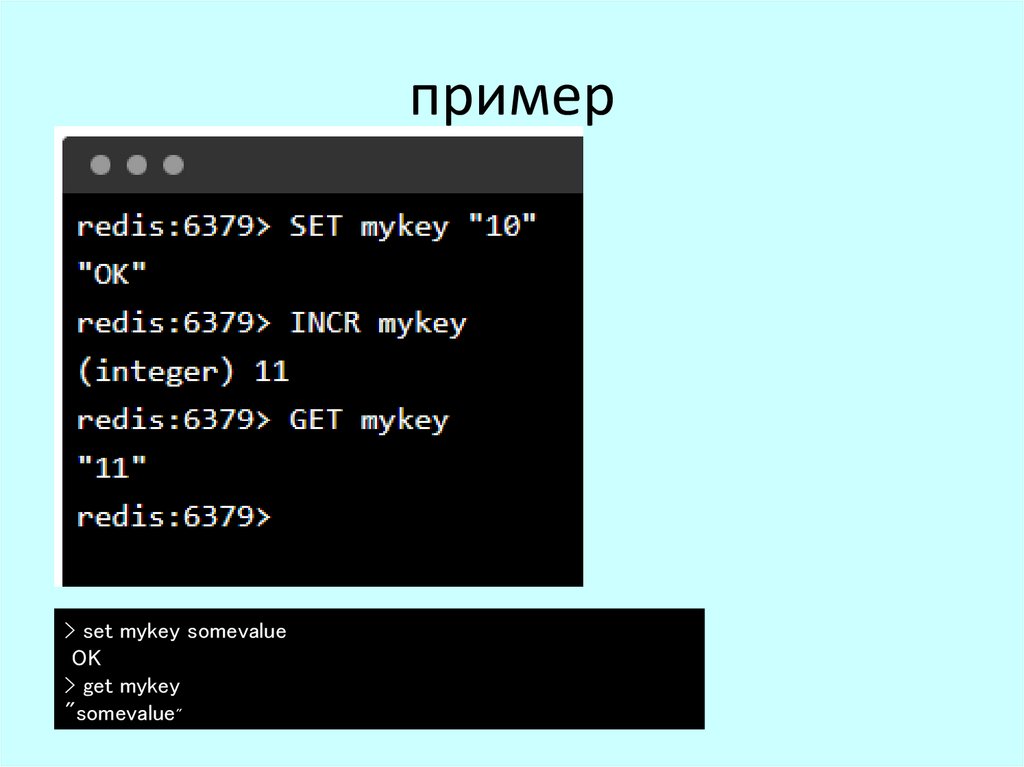
пример> set mykey somevalue
OK
> get mykey
"somevalue"
18.
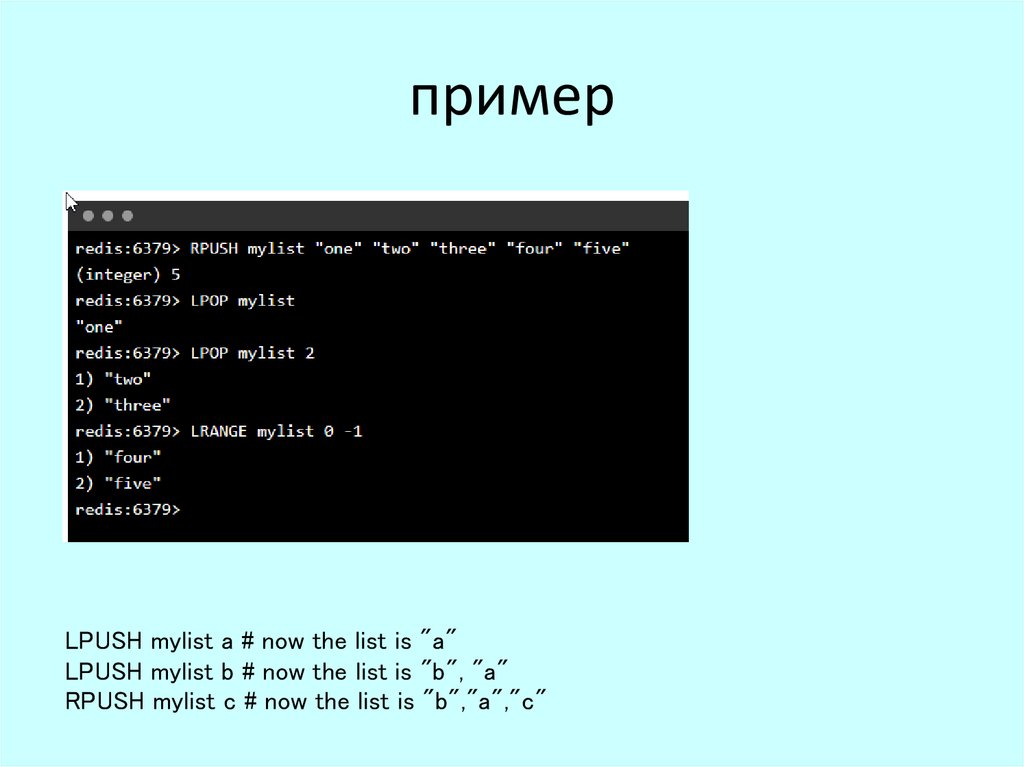
ListСписки Redis — это списки строк, отсортированные по порядку вставки. Можно добавлять
элементы в список Redis, помещая новые элементы в начало (слева) или в конец (справа)
списка.
Команда LPUSH вставляет новый элемент в голову, а RPUSH вставляет новый элемент в хвост.
Если одна из этих операций выполняется с пустым ключом, то создается новый список
Обратные команды
LPOP key [count]
Удаляет из списка и возвращает первые элементы списка, хранящиеся по ключу. По
умолчанию команда извлекает один элемент из начала списка.
RPOP key [count]
Удаляет и возвращает последние элементы списка, хранящиеся в ключе.
По умолчанию команда извлекает один элемент из конца списка.
Ключ удаляется из пространства ключей, если операция со списком очистит список.
Все команды списка будут вести себя одинаково, как они были вызваны с пустым списком,
если они вызываются с несуществующим ключом в качестве аргумента.
Максимальная длина списка 232 - 1
19.
примерLPUSH mylist a # now the list is "a"
LPUSH mylist b # now the list is "b", "a"
RPUSH mylist c # now the list is "b","a","c"
20.
Set• Множества Redis — это неупорядоченная коллекция строк.
Можно добавлять, удалять и проверять наличие элементов в O
(1) (постоянное время, независимо от количества элементов,
содержащихся в наборе).
• Множества Redis обладают не допускают повторяющихся
элементов. Добавление одного и того же элемента несколько
раз приведет к тому, что набор будет иметь единственную
копию этого элемента.
• Множества Redis поддерживают ряд команд на стороне
сервера для вычисления множеств из существующих множеств,
поэтому вы можете выполнять объединения, пересечения,
разность множеств за очень короткое время.
• Максимальное кол-во элементов множества 232 - 1
21.
Hash• Хэши Redis — это сопоставления(map) между строковыми
полями и строковыми значениями, поэтому они являются
идеальным типом данных для представления объектов
(например, пользователя с несколькими полями, такими как
имя, фамилия, возраст и т. д.):
• Хэш с несколькими полями (~до 100) хранится так, что занимает
очень мало места, можно хранить миллионы объектов в
небольшом экземпляре Redis.
• Хэши используются в основном для представления объектов,но
они способны хранить множество элементов, поэтому можно
использовать хэши и для многих других задач.
• Каждый хеш может хранить до 232 -1 пар поле-значение
22.
Sorted SetСортированные множества Redis, как и множества Redis, представляют собой
неповторяющиеся коллекции строк. Разница в том, что каждый элемент
отсортированного набора связан с рейтингом, который используется для
поддержания порядка отсортированного множества, от наименьшего
рейтинга к наибольшему.
Хотя элементы уникальны, рейтинг может повторяться.
В сортированных множествах время добавления, удаления или обновления
элементов логарифмическое(пропорциональное логарифму числа элементов)
Поскольку элементы хранятся отсортированными, а не упорядочиваются
впоследствии, можно очень быстро получить диапазоны по рейтингу или по
рангу (позиции). Доступ к середине отсортированного набора также очень
быстрый, поэтому вы можете использовать отсортированные множества как
умный список неповторяющихся элементов, где вы можете быстро получить
доступ ко всему, что вам нужно: элементы по порядку, быстрая проверка
существования, быстрый доступ к элементам в середине!
Сортированные множества часто используются для индексации данных,
хранящихся внутри Redis.
23.
Пример> zadd hackers 1940 "Alan Kay"
(integer) 1
> zadd hackers 1957 "Sophie Wilson"
(integer) 1
> zadd hackers 1953 "Richard Stallman"
(integer) 1
> zadd hackers 1949 "Anita Borg"
(integer) 1
> zadd hackers 1965 "Yukihiro Matsumoto"
(integer) 1
> zadd hackers 1914 "Hedy Lamarr"
(integer) 1
> zadd hackers 1916 "Claude Shannon"
(integer) 1
> zadd hackers 1969 "Linus Torvalds"
(integer) 1
> zadd hackers 1912 "Alan Turing"
(integer) 1
> zrange hackers 0 -1
1) "Alan Turing"
2) "Hedy Lamarr"
3) "Claude Shannon"
4) "Alan Kay"
5) "Anita Borg"
6) "Richard Stallman"
7) "Sophie Wilson"
8) "Yukihiro Matsumoto"
9) "Linus Torvalds"
24.
Bitmap• Bitmaps — это не совсем тип данных, а набор
битовых операций, определенных для типа String.
Поскольку строки являются бинарно безопасными
большими двоичными объектами, а их
максимальная длина составляет 512 МБ, они
подходят для установки до 232 различных битов.
Битовые операции делятся на две группы:
однобитовые операции с постоянным временем,
такие как установка бита в 1 или 0 или получение
его значения, и операции с группами битов,
например, подсчет количества установленных битов
в заданном диапазоне битов.
25.
HyperLogLog• HyperLogLog — это вероятностная структура данных,
используемая для подсчета уникальных вещей
(технически это относится к оценке кардинальности
множества). Обычно для подсчета уникальных
элементов требуется использование объема памяти,
пропорционального количеству элементов, которые вы
хотите подсчитать, потому что вам нужно помнить
элементы, которые вы уже видели в прошлом, чтобы
избежать их многократного подсчета. Однако
существует набор алгоритмов, которые обменивают
память на точность: вы получаете оценочную меру со
стандартной ошибкой, которая в случае реализации
Redis составляет менее 1%.
26.
Stream• Поток Redis — это структура данных, которая действует как
журнал только для добавления. Потоки удобны для записи
событий в порядке их возникновения.
• С Redis 5.0
• Что делает потоки Redis наиболее сложным типом Redis,
несмотря на то, что сама структура данных довольно проста,
так это тот факт, что он реализует дополнительные,
необязательные функции: набор блокирующих операций,
позволяющих потребителям ждать новых данных,
добавленных в поток производители, а в дополнение к этому
понятие, называемое потребительскими группами.
• > XADD mystream * sensor-id 1234 temperature 19.8
1518951480106-0
• <millisecondsTime>-<sequenceNumber>
27.
Geospatial index• Redis предоставляет геопространственные
индексы, которые полезны для поиска
местоположений в заданном
географическом радиусе. Вы можете
добавлять местоположения в
геопространственный индекс с помощью
команды GEOADD. Затем вы ищете
местоположения в пределах заданного
радиуса, используя команду GEORADIUS.
28.
Сложные структуры$data = {" student:1" :
{ name : “ivan",
password : "123“
logs : "25th october" "30th october" "12 sept",
friends : "34" , "24", "10" } "
student:2" :
{ name : “anna"
password : "4567"
logs : friends: "" }
}
29.
Вариант хранения• hmset student:1 name " ivan" password "12344"
• hmset student:2 name "anna" password
"232342"
• Отдельно список логов и отдельно список
друзей
• logs:1 { here 1 is the user id }
• lpush logs:1 "" "" ""
• lpush logs:2 "" "" ""
30.
Вариант хранения 2• Хэш-карта с выгруженными данными json в
виде строк
• hmset student:1 name "ivan" password
"12344" logs "String_dumped_data" friends
"string of dumped data"
31.
Пространства именНапример, если вы пишете интернационализированное хранилище ключей и значений, то можете
хранить переводы ответов на разные языки в разных пространствах имен. В немецком
пространстве имен ключу greeting (приветствие) будет сопоставлено значение «guten tag», а во
французском – «bonjour».
После того как пользователь выберет предпочтительный язык, приложение будет извлекать
значения из соответствующего пространства имен.
В терминологии Redis пространство имен называется базой данных, и каждому такому пространству
сопоставляется числовой ключ. Пока что мы работали с подразумеваемым по умолчанию
пространством имен 0 (оно также называется базой данных 0).
Следующие команды сопоставляют ключу greeting английское слово hello.
redis 127.0.0.1:6379> SET greeting hello
OK
redis 127.0.0.1:6379> GET greeting
“hello”
Но если переключиться на другую базу данных командой SELECT, то этот ключ станет недоступен.
redis 127.0.0.1:6379> SELECT 1
OK
redis 127.0.0.1:6379[1]> GET greeting
(nil)
redis 127.0.0.1:6379[1]> SET greeting “guten tag”
OK
redis 127.0.0.1:6379[1]> SELECT 0
OK
redis 127.0.0.1:6379> GET greeting
“hello”