


















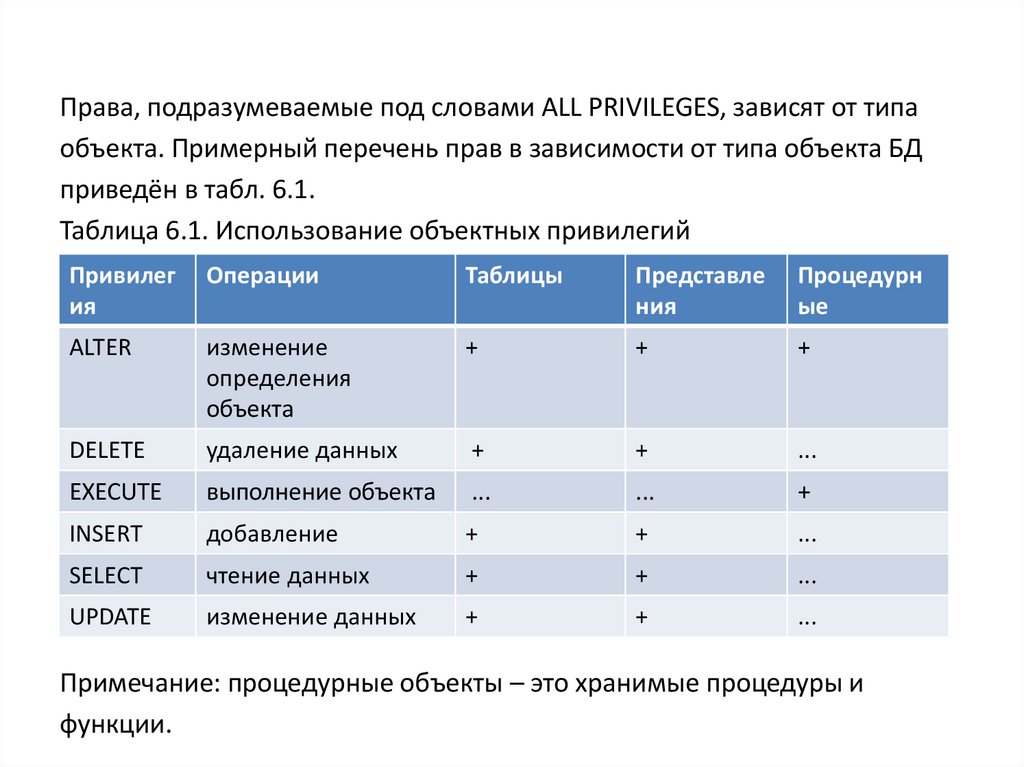
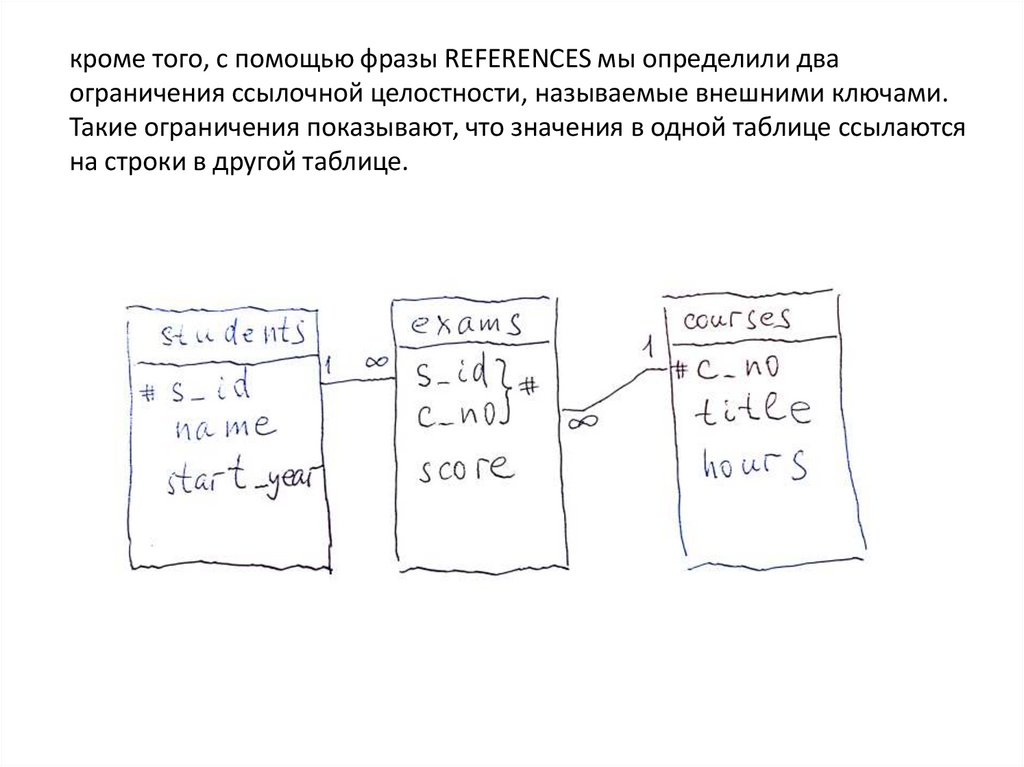
 архитектура \"клиент – сервер\".")

















")

")





















 связи")











































")
















")
































")
















")


















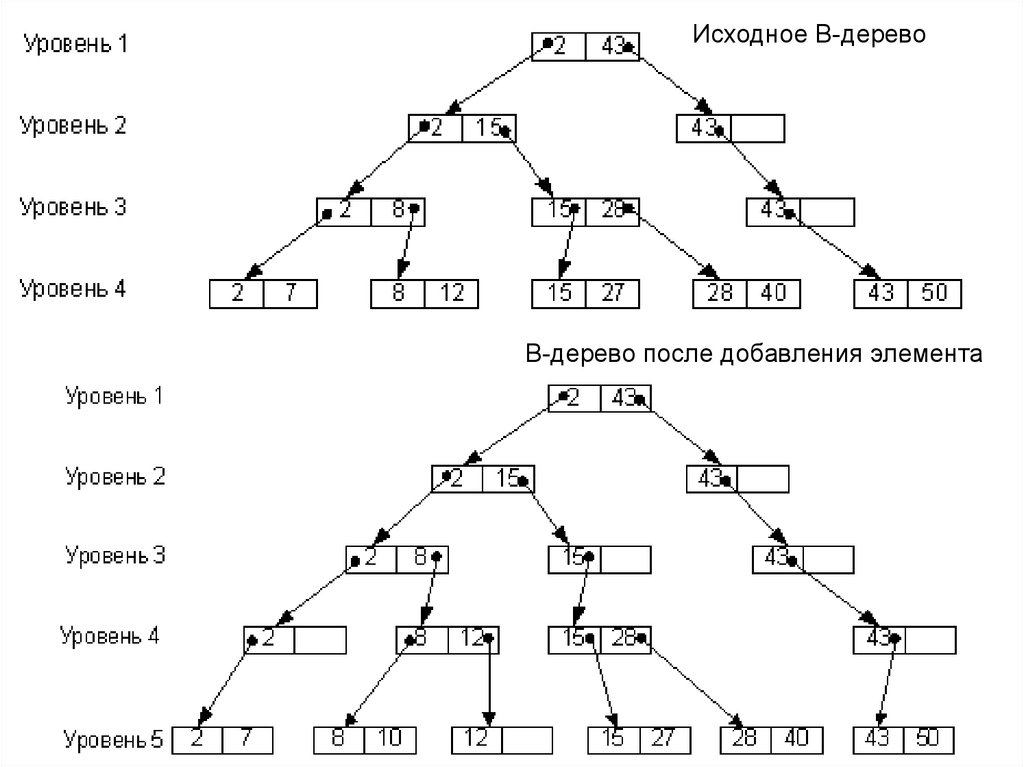


")
")





")









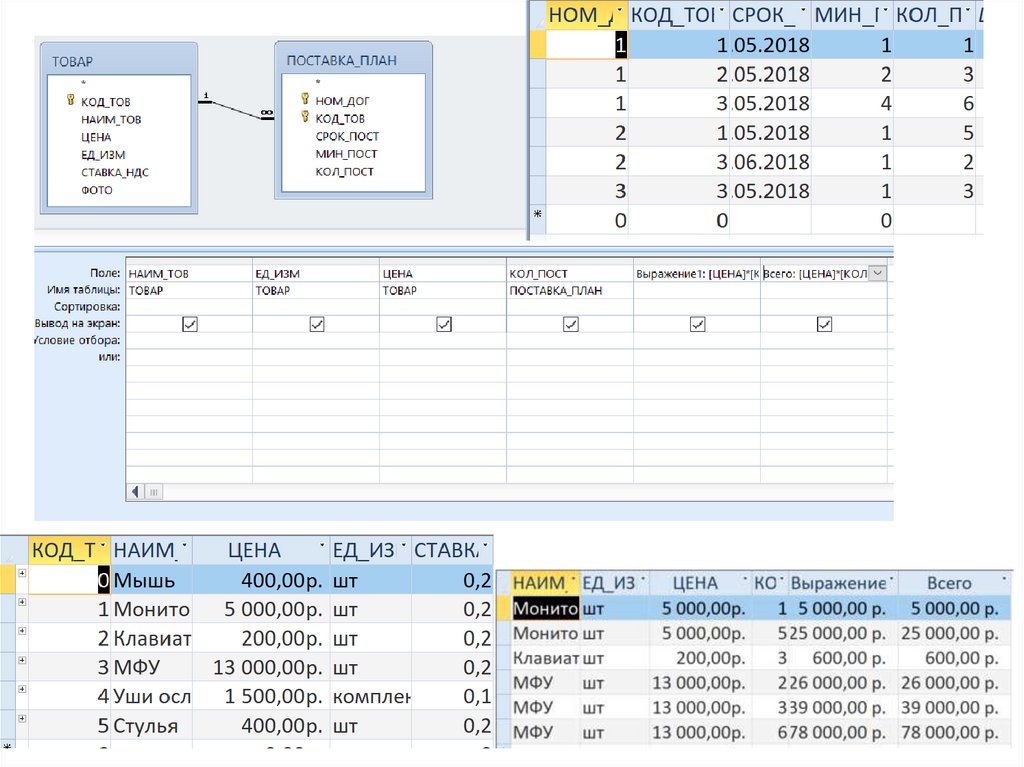

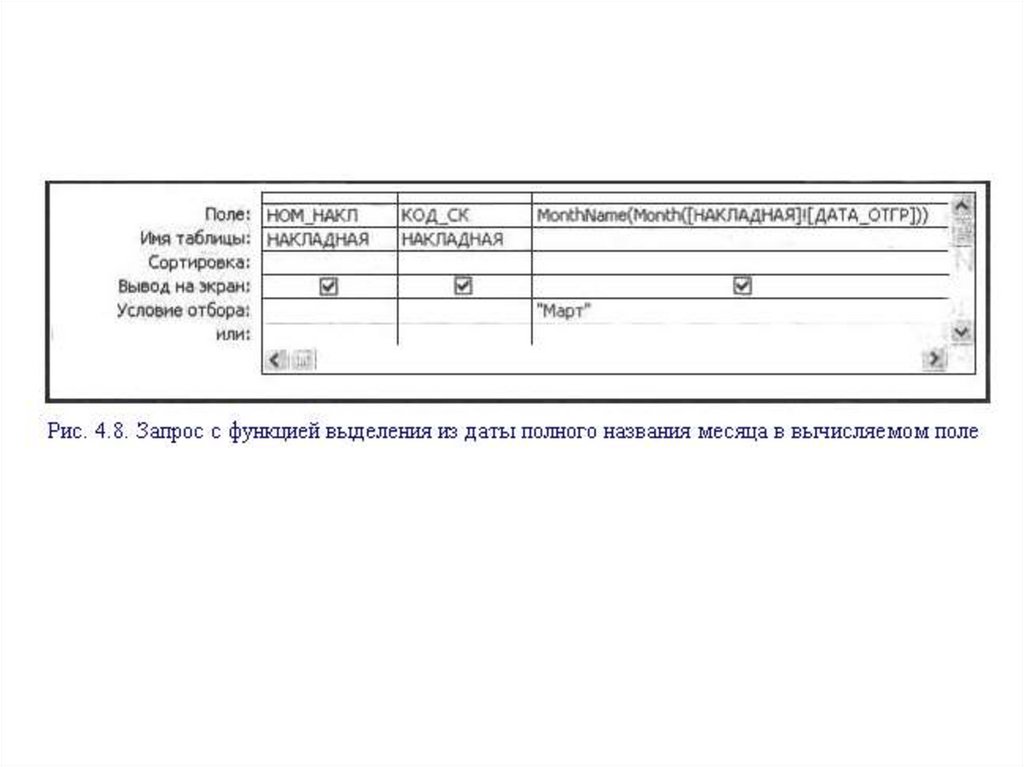

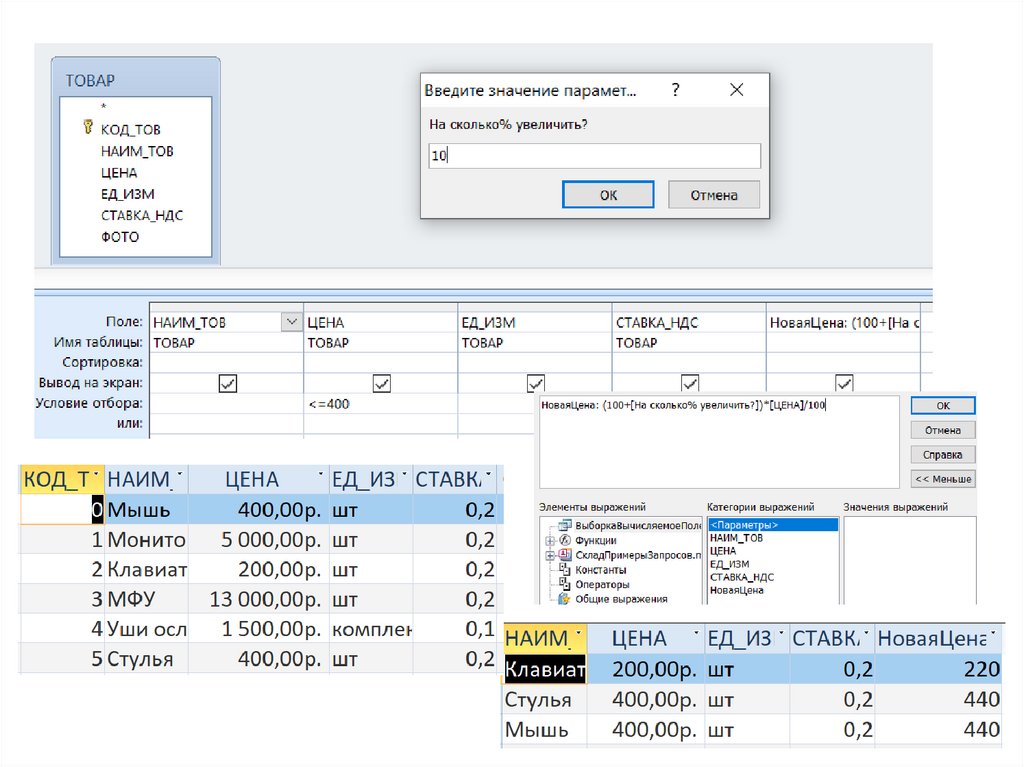


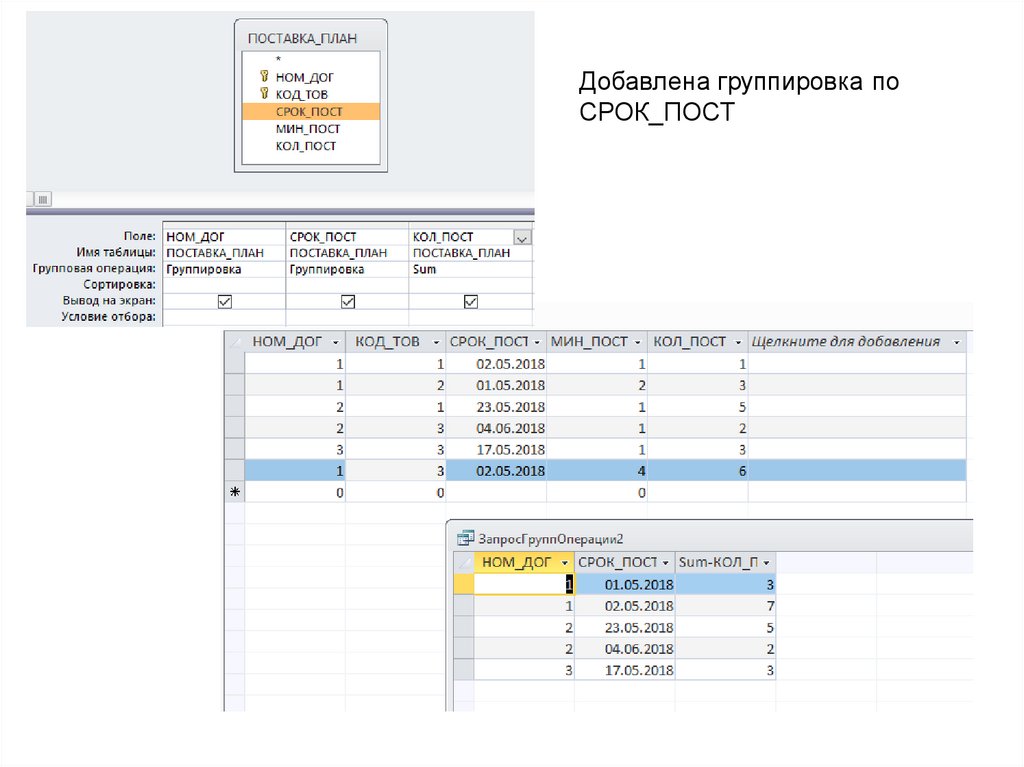









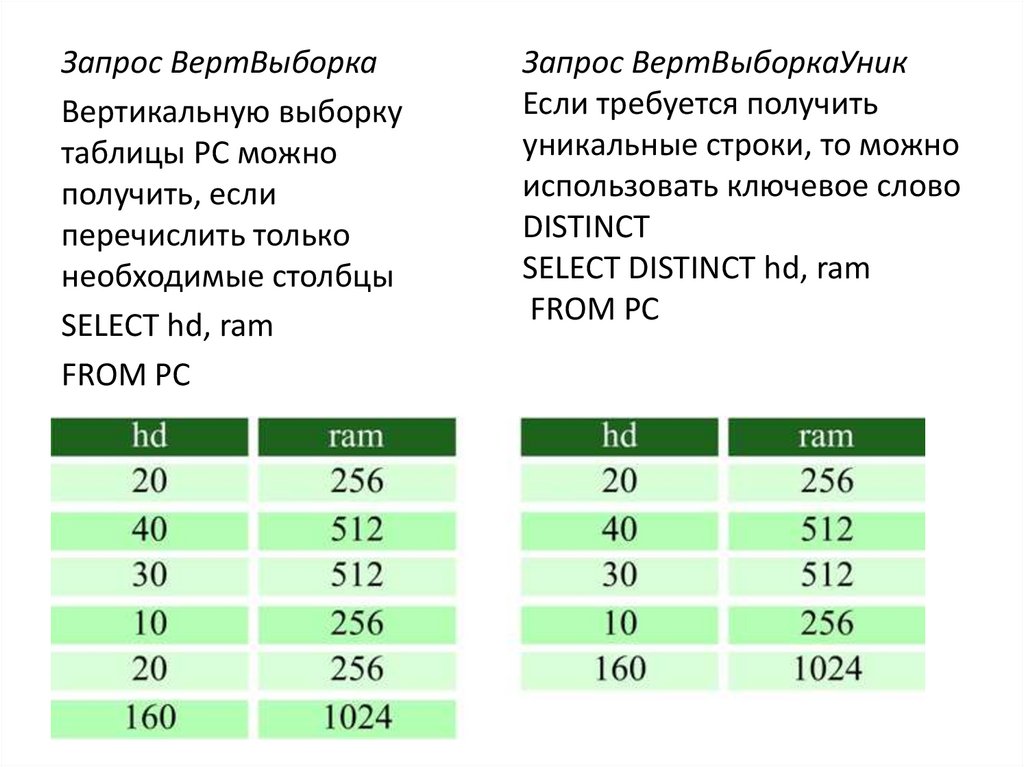
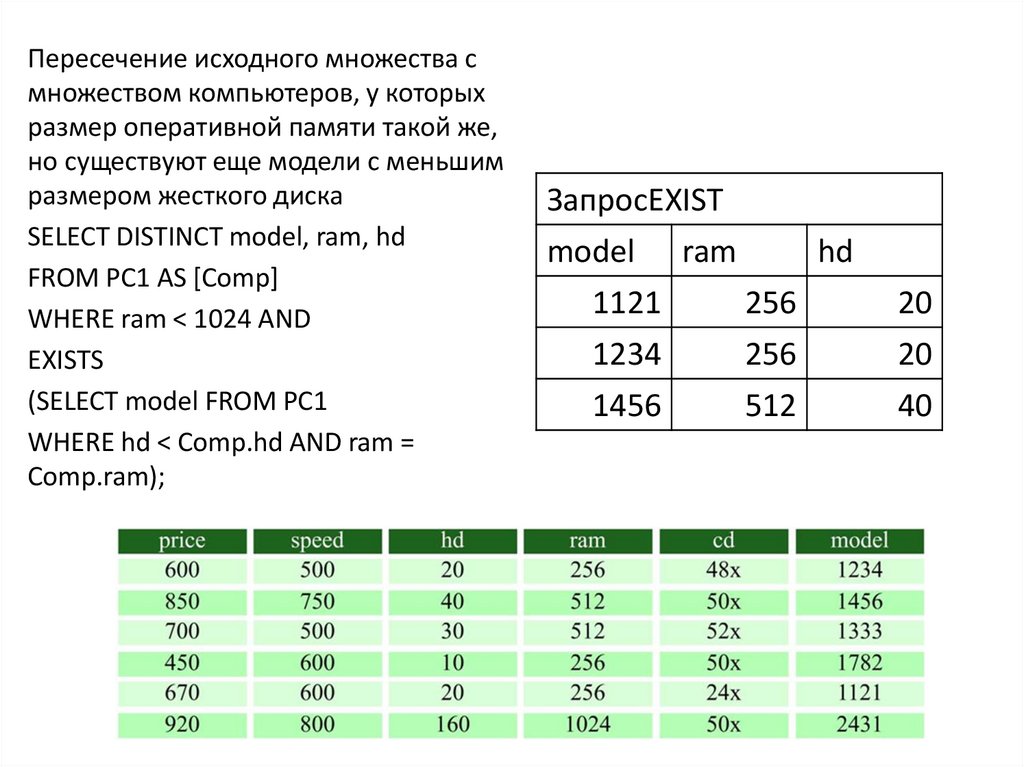
")








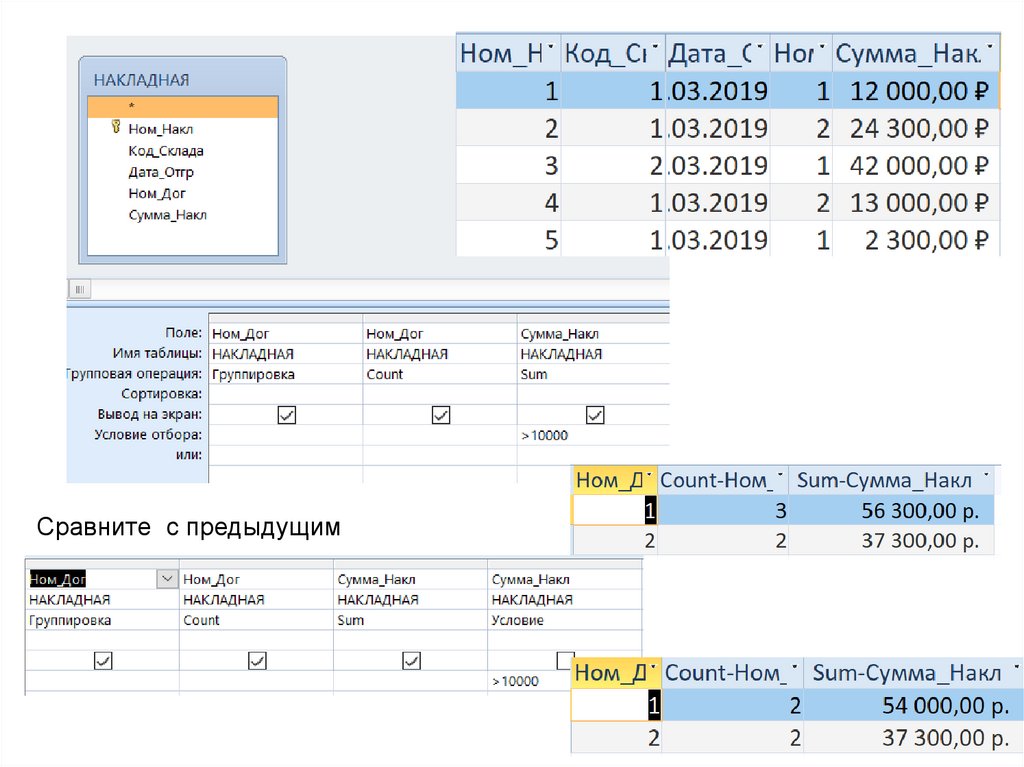
 значениями Оператор NULL")




























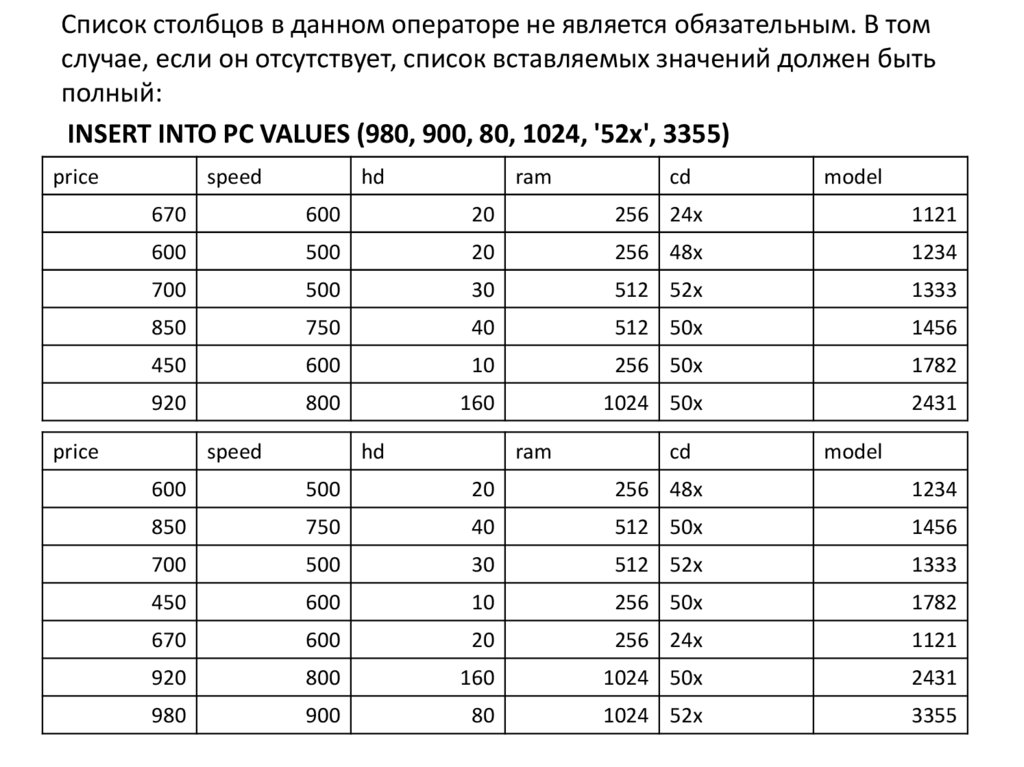


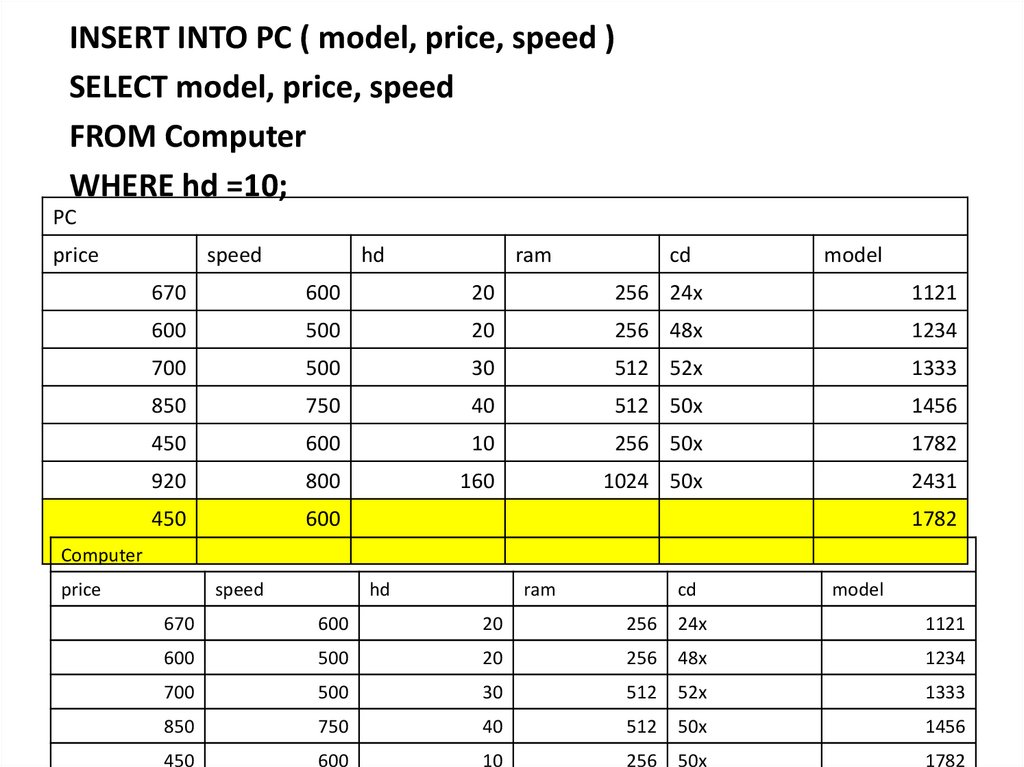
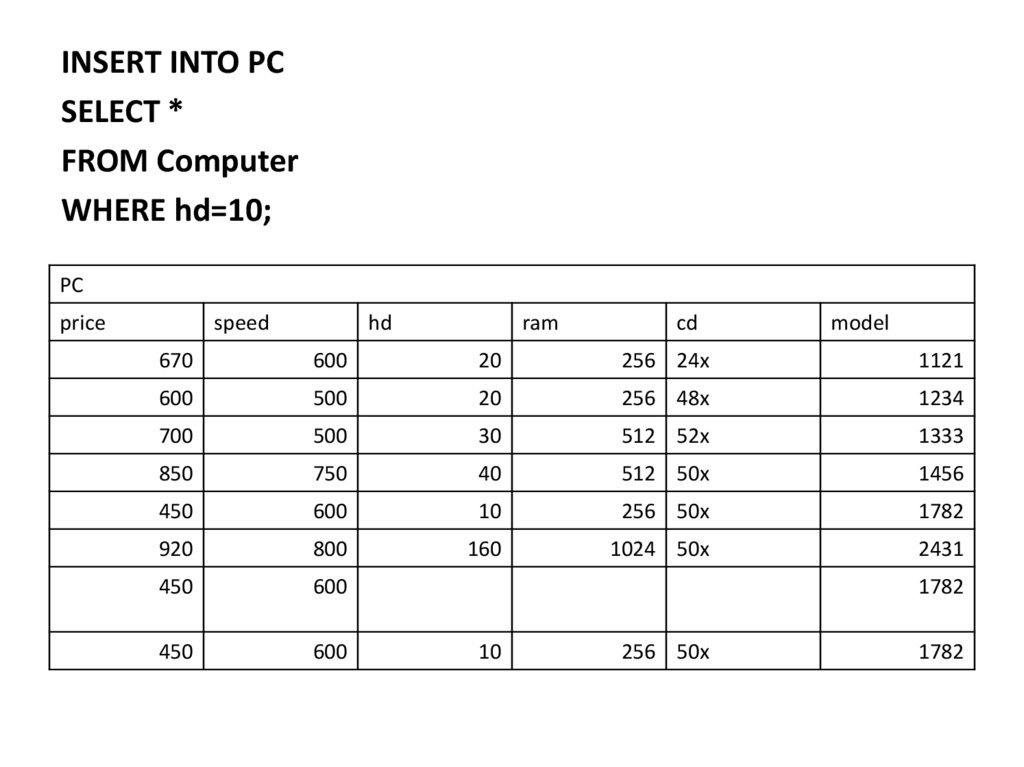

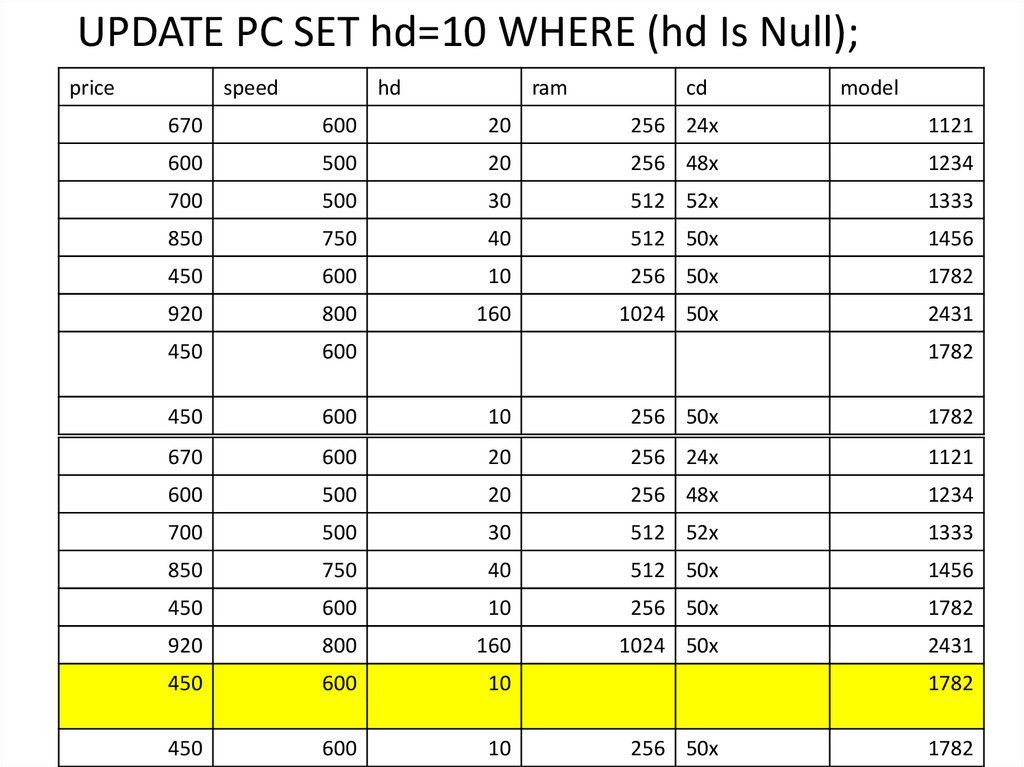
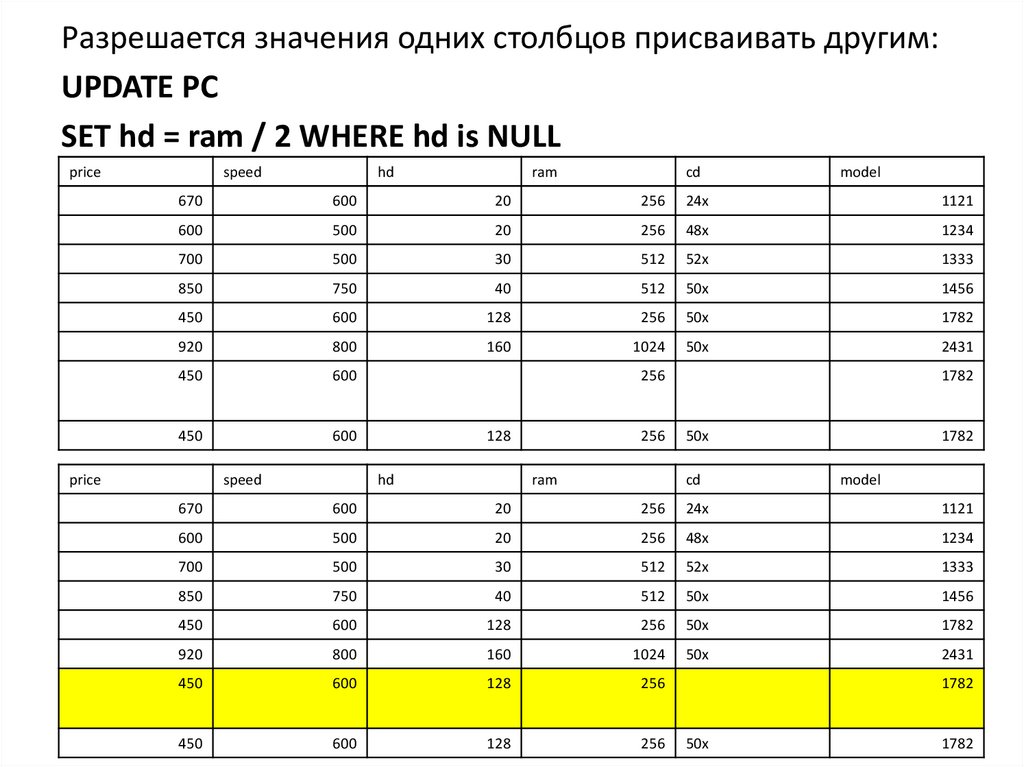


;")














































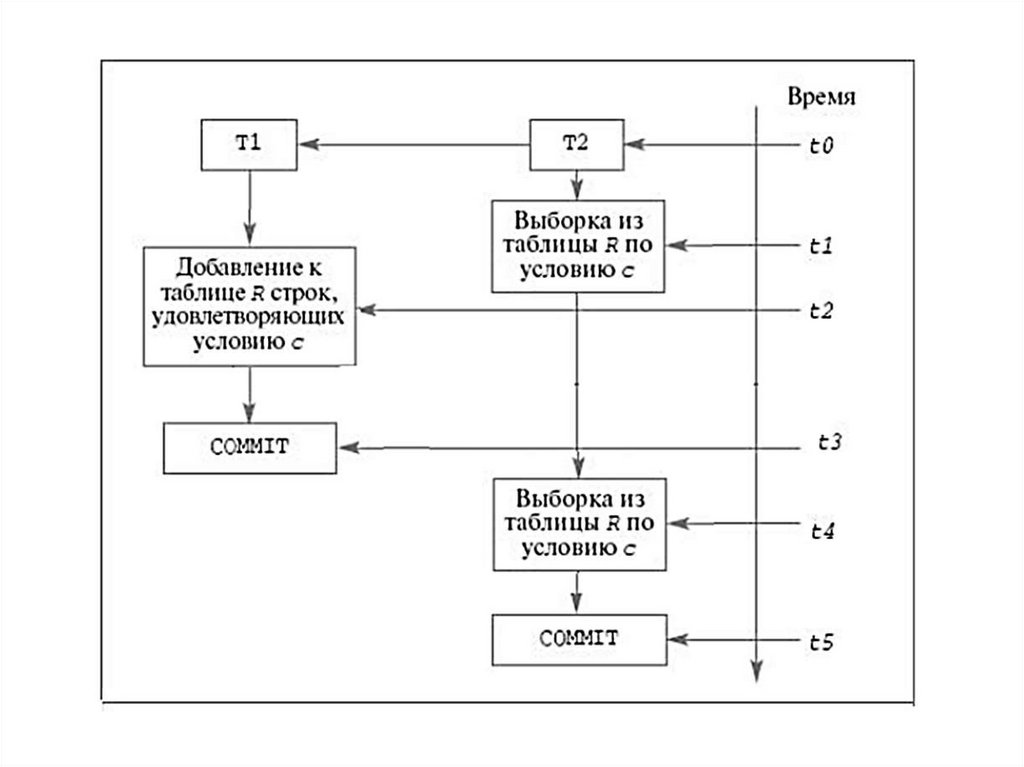




























")












































































 database
databaseSimilar presentations:










Базы данных. Состав и компоненты СУБД
1. Базы данных
2.
История баз данныхТрадиционно фиксация данных осуществляется с помощью
конкретного средства общения, например, с помощью
естественного языка на конкретном носителе. Обычно данные и их
интерпретация фиксируются совместно, так как естественный язык
достаточно гибок для представления того и другого.
Нередко данные и интерпретация разделены. Например, данные
представлены в виде таблицы, шапка которой содержит
интерпретацию, однако, такое разделение затрудняет работу с
данными.
Применение компьютера для обработки данных обычно приводит
к еще большему разделению данных и интерпретации, так как
компьютер имеет дело с данными как таковыми. Большая часть
интерпретирующей информации вообще не фиксируется в явной
форме.
3.
История систем управления базами данных начинается с одного из самыхзначительных событий двадцатого века – полета на Луну. Компания
Rockwell заключила контракт с правительством США на участие в проекте
Apollo. Построение космического корабля включает в себя сборку
нескольких миллионов деталей, поэтому была создана система
управления файлами, отслеживавшая информацию о каждой детали.
Однако в ходе последующей проверки обнаружилась огромная
избыточность. Выяснилось, что почти все данные повторяются в двух и
более файлах. Избыточность вела к ошибкам в данных
Rockwell в сотрудничестве с IBM в 1968 г. разработала
автоматизированную систему заказов. Названная IMS (Information
Management System – система управления информацией), она заложила
основу концепции СУБД.
Ключевым новшеством IMS было разделение данных и функций деловой
логики. Прикладные программисты получили возможность работать с
информацией на логическом уровне, а база данных брала на себя задачу
физического хранения. Подобное разделение труда привело к резкому
скачку производительности.
4.
5.
Причины появления БД• применение вычислительной техники для
выполнения численных расчетов, которые
слишком долго или вообще невозможно
производить вручную
• использование средств вычислительной
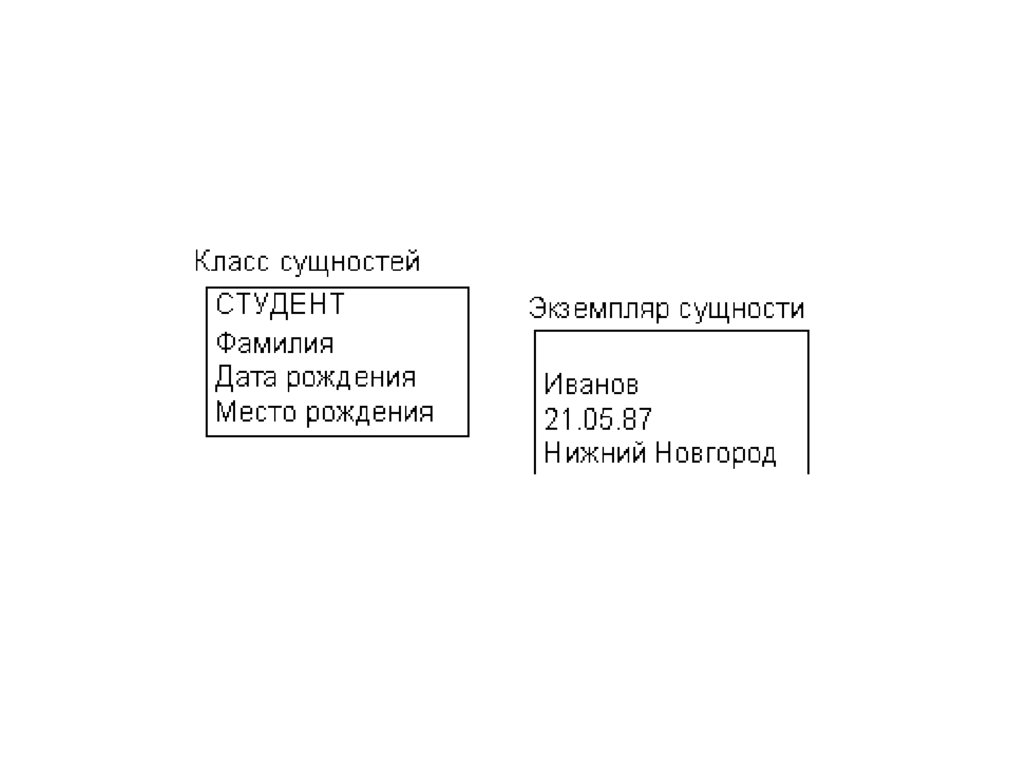
техники в автоматических или
автоматизированных информационных
системах
6. Информационная система
• надежное хранение информации в памятикомпьютера;
• выполнение специфических для данного
приложения преобразований информации
и вычислений;
• предоставление пользователям удобного и
легко осваиваемого интерфейса.
7. Примеры ИС
• банковские системы,• автоматизированные системы управления
предприятиями,
• системы резервирования авиационных или
железнодорожных билетов, мест в
гостиницах
• интернет-торговля
• Госуслуги
• Поисково-справочные системы
8. Причины появления БД
• программист решает задачи управлениеданными во внешней памяти
• увеличение объема памяти и ускорение
доступа к данным (магнитные дисков с
магнитными головками)
• проблемы параллельного доступа к
данным
9. Проблемы файловых структур
• создать файл (требуемого типа и размера);• открыть ранее созданный файл;
• прочитать из файла некоторую запись
(текущую, следующую, предыдущую,
первую, последнюю);
• записать в файл на место текущей записи
новую, добавить новую запись в конец
файла.
10. Другие проблемы
Зависимость программ от данных. Каждая программа,
работающая с файлом, должна была иметь у себя внутри
структуру данных, соответствующую структуре этого
файла. Поэтому при изменении структуры файла
требовалось изменять структуру программы, а это
требовало новой компиляции, то есть процесса перевода
программы в исполняемые машинные коды.
• Отсутствие централизованных методов управления
доступом к информации . Администрирование режимом
доступа к файлу в основном выполняется его создателемвладельцем. Для множества файлов, отражающих
информационную модель одной предметной области,
такой децентрализованный принцип управления
доступом вызывал дополнительные трудности.
11.
• Необходимость обеспечения эффективной параллельнойработы многих пользователей с одними и теми же
файлами. Одновременная работа нескольких
пользователей, связанная с модификацией данных в
файле, либо вообще не реализовывалась, либо была
очень замедлена.
12. Базы данных
База данных – организованная совокупностьданных, предназначенная для длительного
хранения во внешней памяти ЭВМ и постоянного
применения. Для хранения БД может
использоваться как один компьютер, так и
множество взаимосвязанных компьютеров.
Система управления базами данных – это комплекс
программ и языковых средств для создания,
ведения и использования баз данных.
13. Состав СУБД
14. Компоненты СУБД
- ядро, которое отвечает за управление данными во
внешней и оперативной памяти и журнализацию,
• - процессор языка базы данных, обеспечивающий
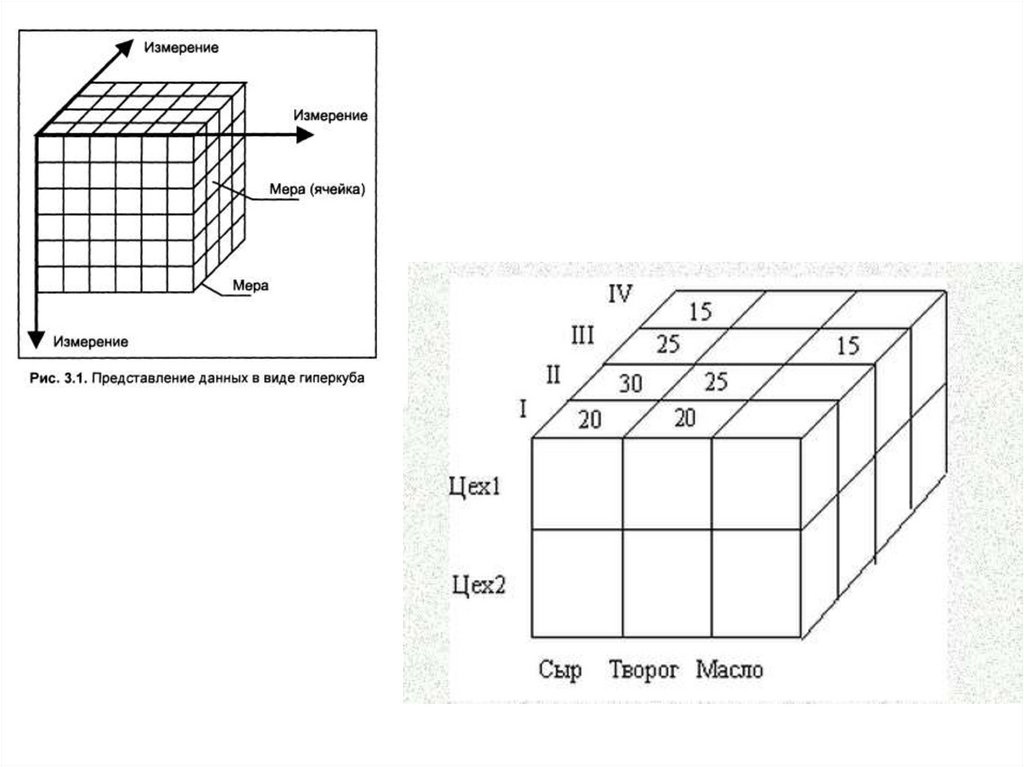
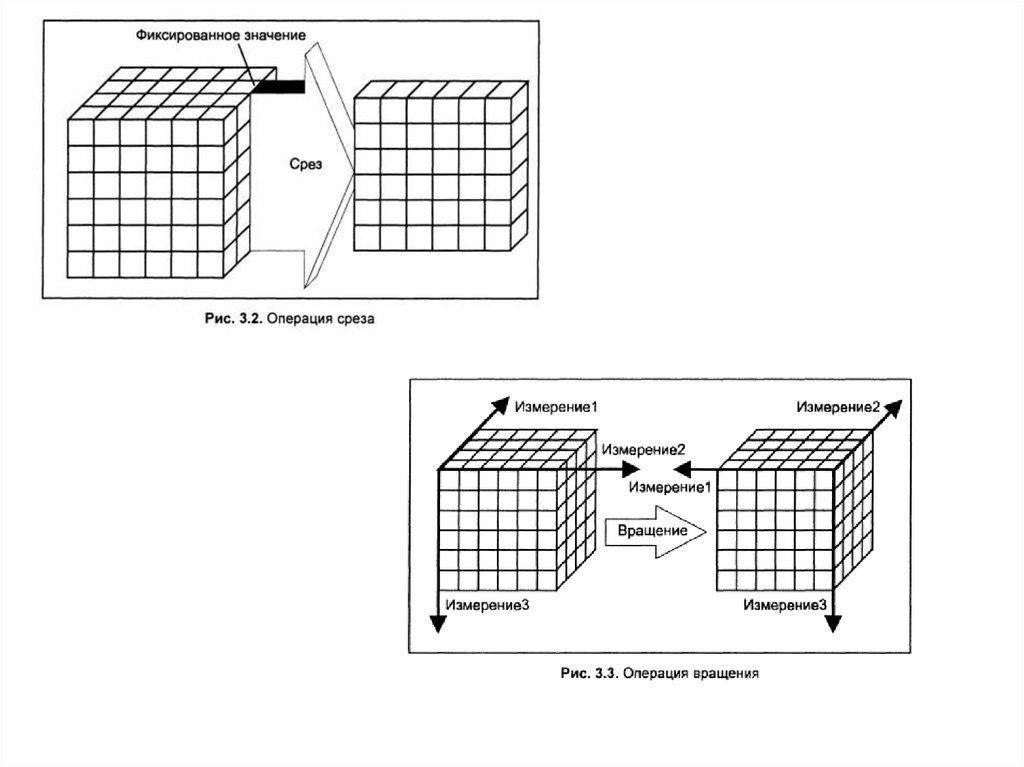
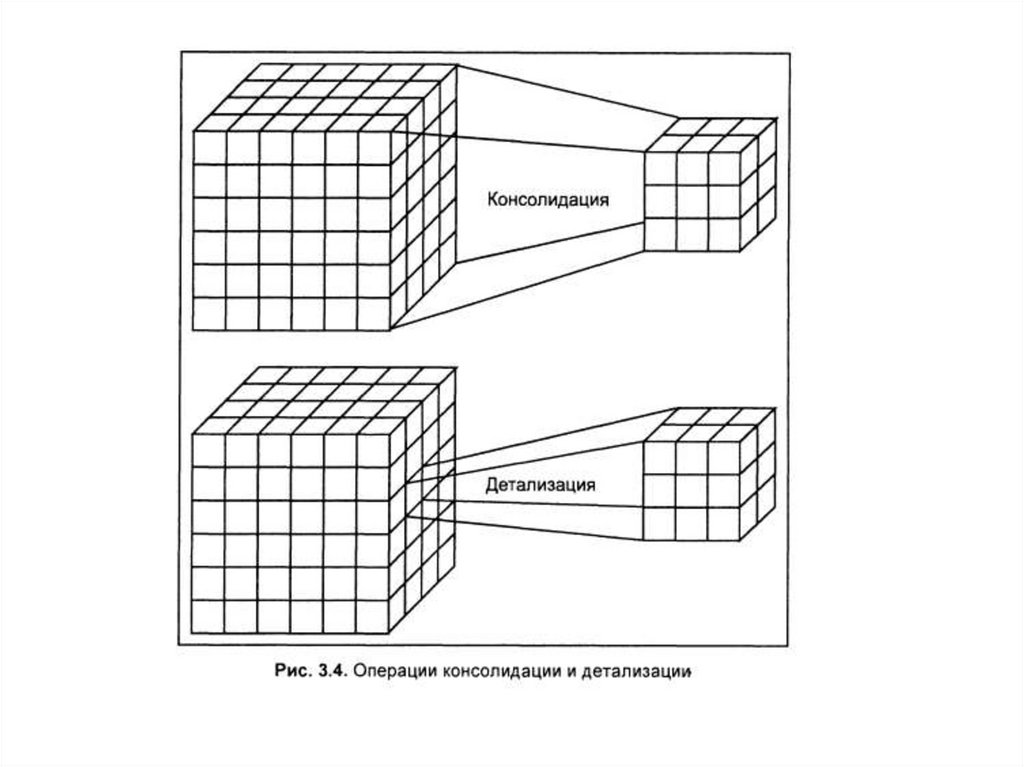
оптимизацию запросов на извлечение и изменение
данных и создание, как правило, машинно-независимого
исполняемого внутреннего кода,
• - подсистема поддержки времени исполнения, которая
интерпретирует программы манипуляции данными,
создающие пользовательский интерфейс с СУБД
• - сервисные программы (внешние утилиты),
обеспечивающие ряд дополнительных возможностей по
обслуживанию информационной системы
15. Функции СУБД
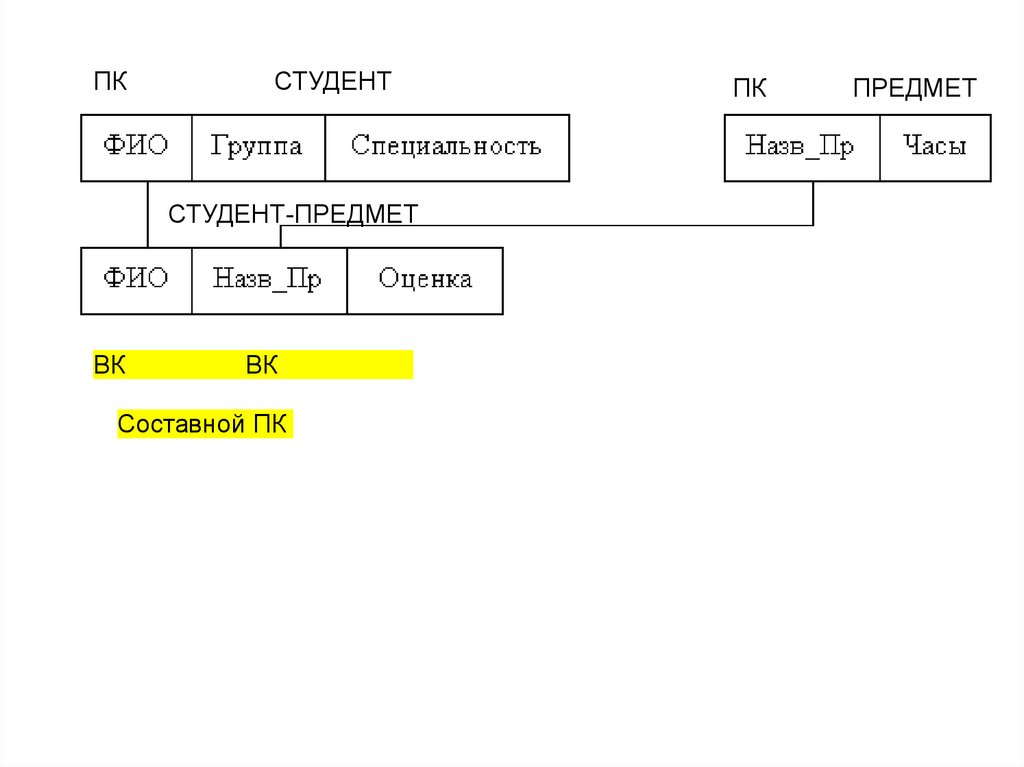
• Управление данными• Управление буферами ОЗУ
• Управление транзакциями
16. Классификации СУБД
• По характеру использования• По степени распределённости
• По способу доступа к БД
17. Компоненты БД
18.
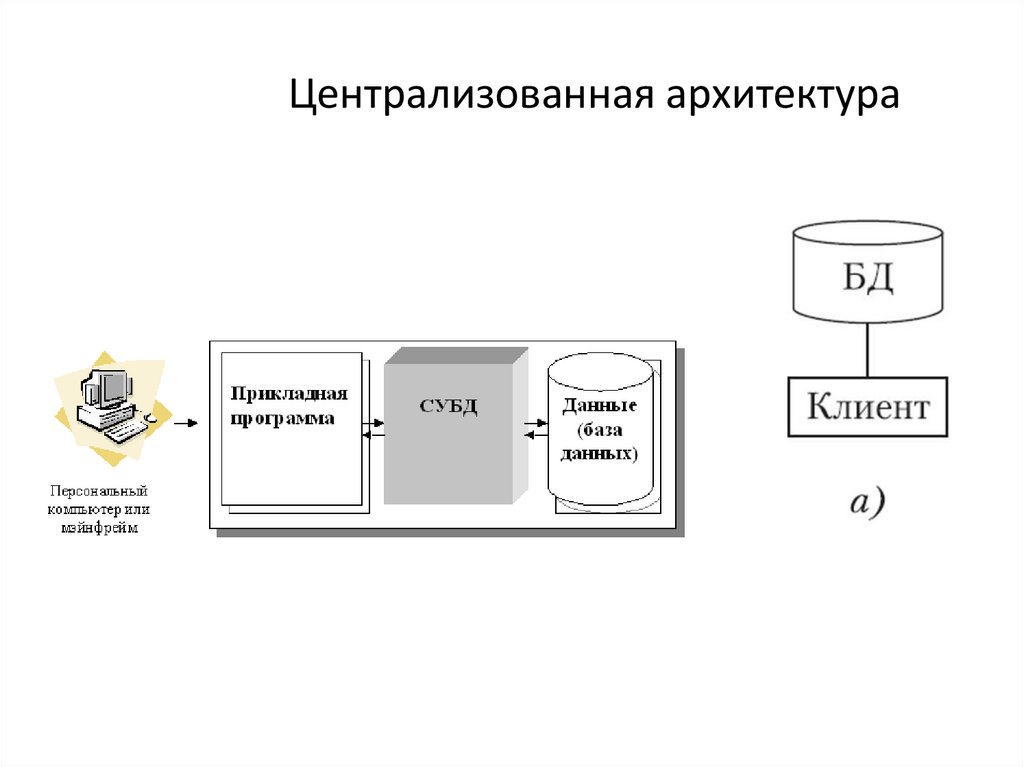
Централизованная архитектура19.
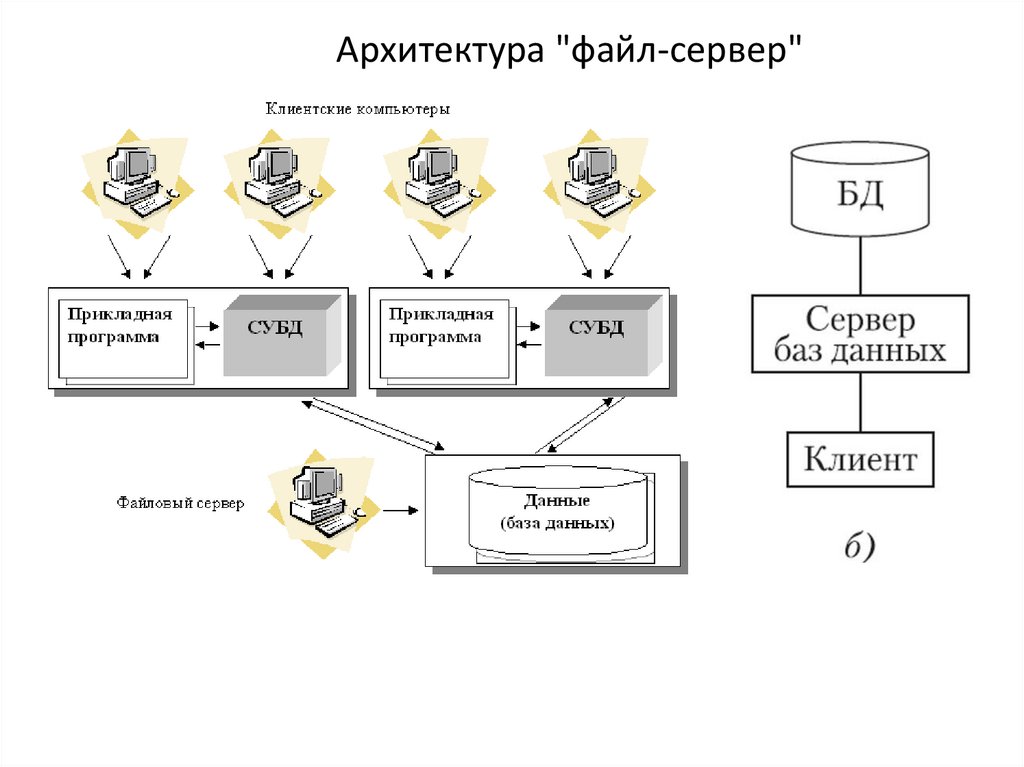
Архитектура "файл-сервер"20. Архитектура "файл-сервер"
Архитектура "файл-сервер"• База данных в виде набора файлов находится на жестком диске
специально выделенного компьютера (файлового сервера).
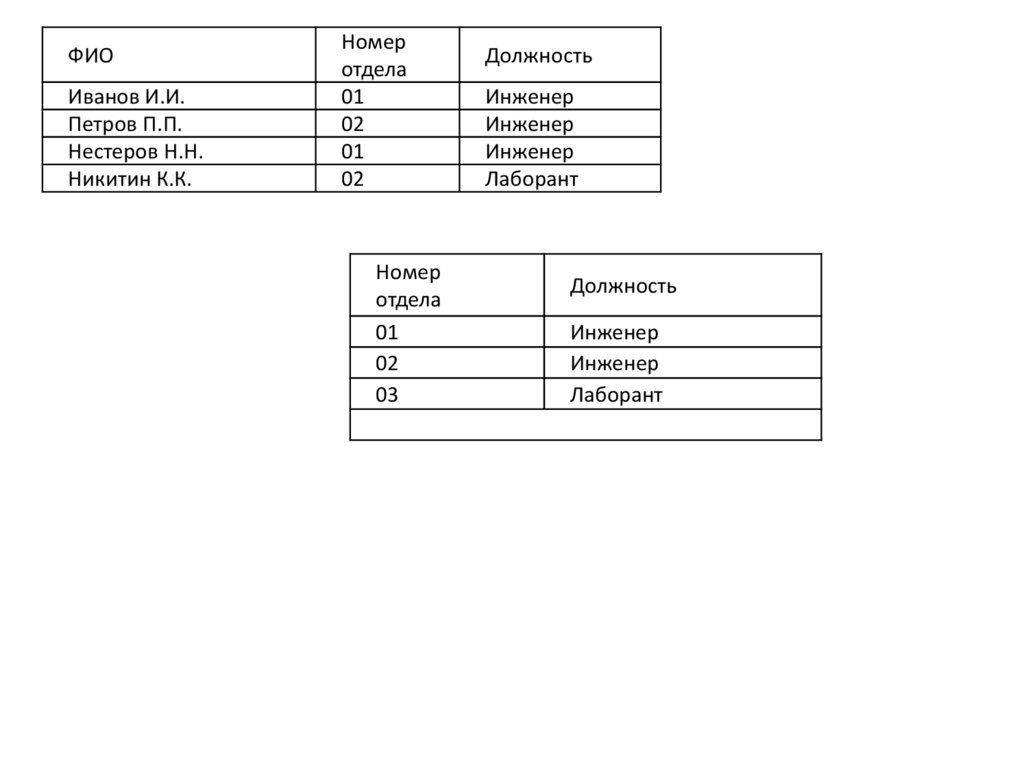
• Существует сеть, состоящая из клиентских компьютеров, на каждом из
которых установлены СУБД и приложение для работы с БД.
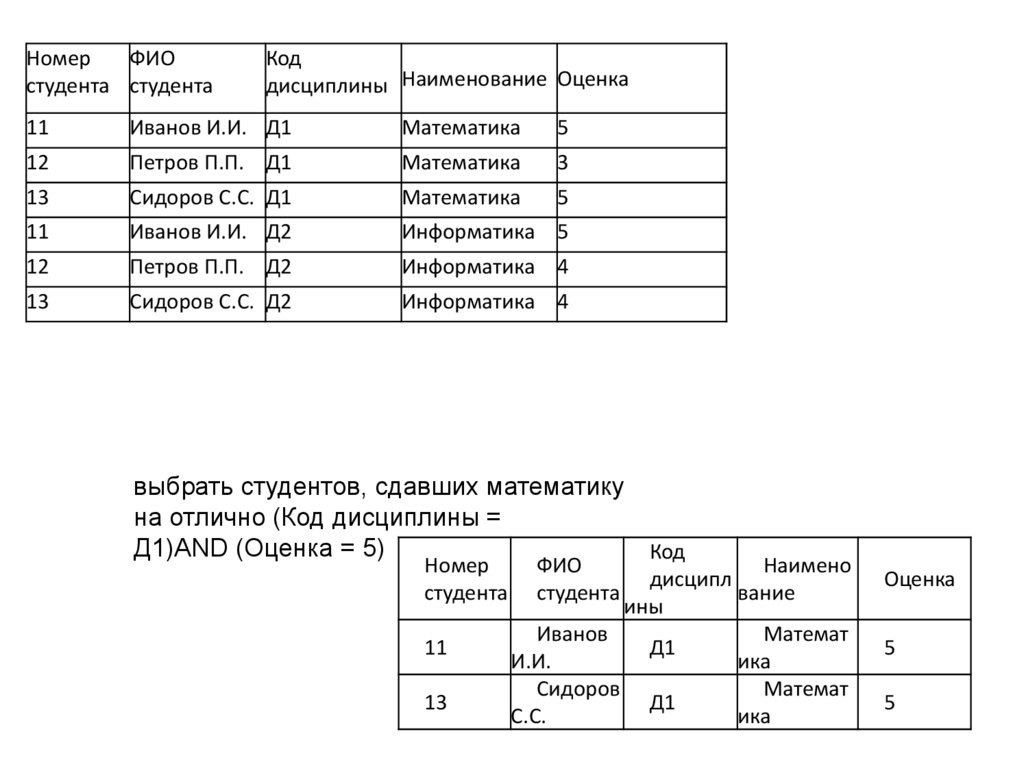
• На каждом из клиентских компьютеров пользователи имеют
возможность запустить приложение. Используя предоставляемый
приложением пользовательский интерфейс, он инициирует
обращение к БД на выборку/обновление информации.
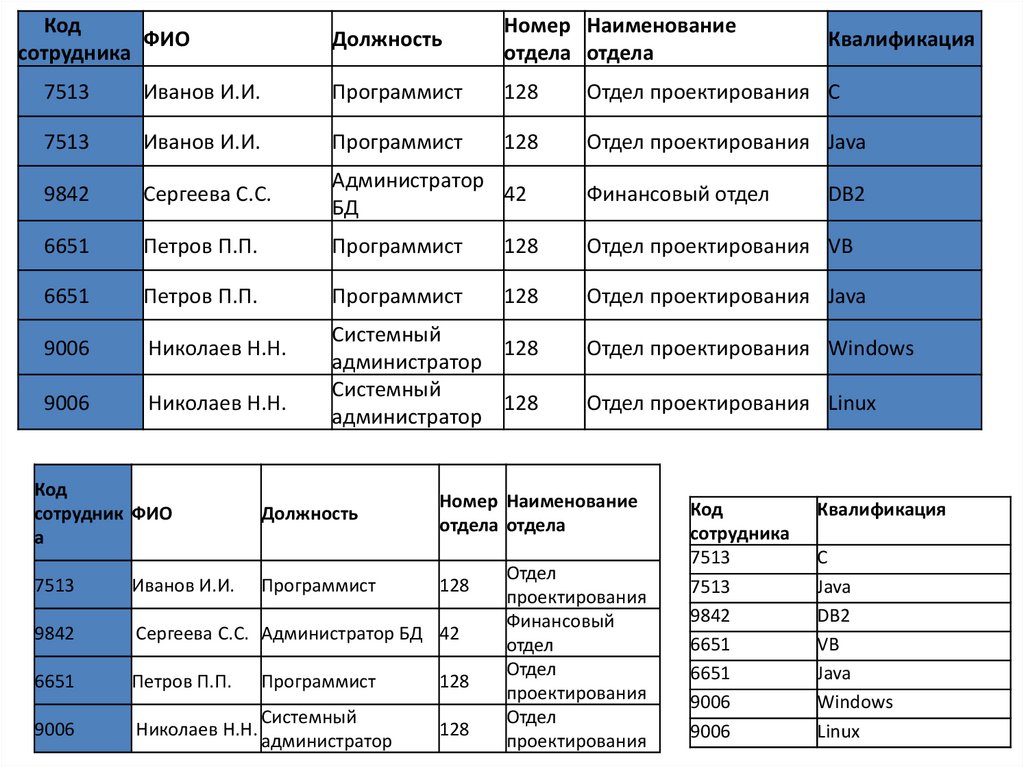
• Все обращения к БД идут через СУБД, которая инкапсулирует внутри
себя все сведения о физической структуре БД, расположенной на
файловом сервере.
• СУБД инициирует обращения к данным, находящимся на файловом
сервере, в результате которых часть файлов БД копируется на
клиентский компьютер и обрабатывается, что обеспечивает
выполнение запросов пользователя (осуществляются необходимые
операции над данными).
• При необходимости (в случае изменения данных) данные
отправляются назад на файловый сервер с целью обновления БД.
• Результат СУБД возвращает в приложение.
• Приложение, используя пользовательский интерфейс, отображает
результат выполнения запросов.
21.
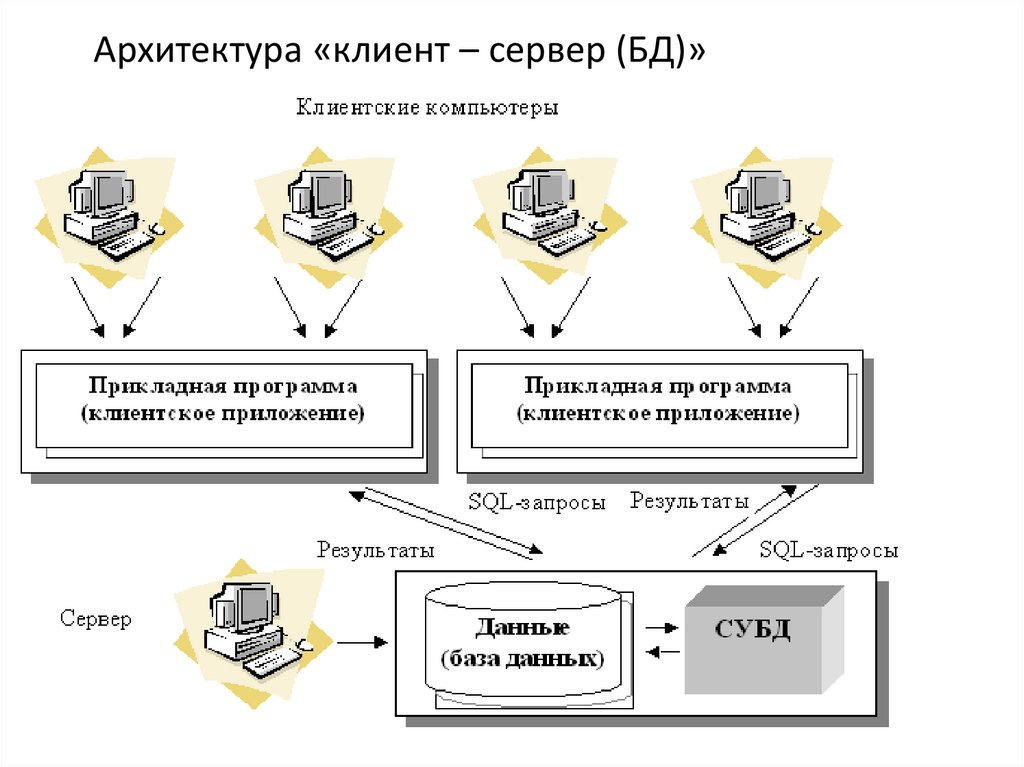
Архитектура «клиент – сервер (БД)»22. Архитектура «клиент – сервер»
• База данных в виде набора файлов находится на жестком дискеспециально выделенного компьютера (сервера).
• СУБД располагается также на сервере.
• Существует сеть, состоящая из клиентских компьютеров, на каждом из
которых установлено клиентское приложение для работы с БД.
• На каждом из клиентских компьютеров пользователи имеют возможность
запустить клиентское приложение. Используя предоставляемый
приложением пользовательский интерфейс, он инициирует обращение к
СУБД, расположенной на сервере, на выборку/обновление информации.
Для общения используется специальный язык запросов SQL, т.е. по сети от
клиента к серверу передается лишь текст запроса.
• СУБД инкапсулирует внутри себя все сведения о физической структуре БД,
расположенной на сервере.
• СУБД инициирует обращения к данным, находящимся на сервере, в
результате которых на сервере осуществляется вся обработка данных и
лишь результат выполнения запроса копируется на клиентский компьютер.
Таким образом СУБД возвращает результат в приложение.
• Клиентское приложение, используя пользовательский интерфейс,
отображает результат выполнения запросов
23. Трехзвенная (многозвенная) архитектура "клиент – сервер".
Трехзвенная (многозвенная) архитектура "клиент –сервер".
База данных в виде набора файлов находится на жестком диске специально
выделенного компьютера (файл-сервере или сервере БД).
СУБД располагается также на сервере.
Существует специально выделенный сервер приложений, на котором
располагается программное обеспечение (ПО) делового анализа (бизнеслогика)
Существует множество клиентских компьютеров, на каждом из которых
установлен так называемый "тонкий клиент" – клиентское приложение,
реализующее интерфейс пользователя.
На каждом из клиентских компьютеров пользователи имеют возможность
запустить приложение – тонкий клиент. Используя предоставляемый
приложением пользовательский интерфейс, он инициирует обращение к
ПО делового анализа, расположенному на сервере приложений.
Сервер приложений анализирует требования пользователя и формирует
запросы к БД. Для общения используется специальный язык запросов SQL,
т.е. по сети от сервера приложений к серверу БД передается лишь текст
запроса.
СУБД инкапсулирует внутри себя все сведения о физической структуре БД,
расположенной на сервере.
СУБД инициирует обращения к данным, находящимся на сервере, в
результате которых результат выполнения запроса копируется на сервер
приложений.
Сервер приложений возвращает результат в клиентское приложение
(пользователю).
Приложение, используя пользовательский интерфейс, отображает результат
выполнения запросов.
24. Персональные и многопользовательские СУБД
• Персональные СУБД обычно обеспечивают возможностьсоздания персональных БД и недорогих приложений,
работающих с ними. Персональные СУБД или разработанные с
их помощью приложения зачастую могут выступать в роли
клиентской части многопользовательской СУБД. К
персональным СУБД, например, относятся Access и др.
• Многопользовательские СУБД включают в себя сервер БД и
клиентскую часть и, как правило, могут работать в
неоднородной вычислительной среде (с разными типами ЭВМ
и операционными системами). К многопользовательским СУБД
относятся, например, СУБД Oracle и Informix, MS SQL Server.
25.
По используемой модели данных СУБД (как и БД), разделяютна реляционные, объектно-ориентированные и другие типы.
Некоторые СУБД могут одновременно поддерживать
несколько моделей данных.
С точки зрения пользователя, СУБД реализует функции
хранения, изменения (пополнения, редактирования и
удаления) и обработки информации, а также разработки и
получения различных выходных документов.
26. Языки СУБД
Для работы с хранящейся в базе данных информацией СУБД предоставляетпрограммам и пользователям следующие два типа языков:
• язык описания данных — высокоуровневый непроцедурный язык
декларативного типа, предназначенный для описания логической структуры
данных;
• язык манипулирования данными — совокупность конструкций,
обеспечивающих выполнение основных операций по работе с данными: ввод,
модификацию и выборку данных по запросам.
Названные языки в различных СУБД могут иметь отличия, Наибольшее
распространение получили два стандартизованных языка: QBE (Query By
Example) — язык запросов по образцу и SQL (Structured Query Language) —
структурированный язык запросов. QBE в основном обладает свойствами языка
манипулирования данными, SQL сочетает в себе свойства языков обоих типов —
описания и манипулирования данными.
27. Низкоуровневые функции
• управление данными во внешней памяти;• управление буферами оперативной памяти;
• управление транзакциями;
• ведение журнала изменений в БД;
• обеспечение целостности и безопасности
БД
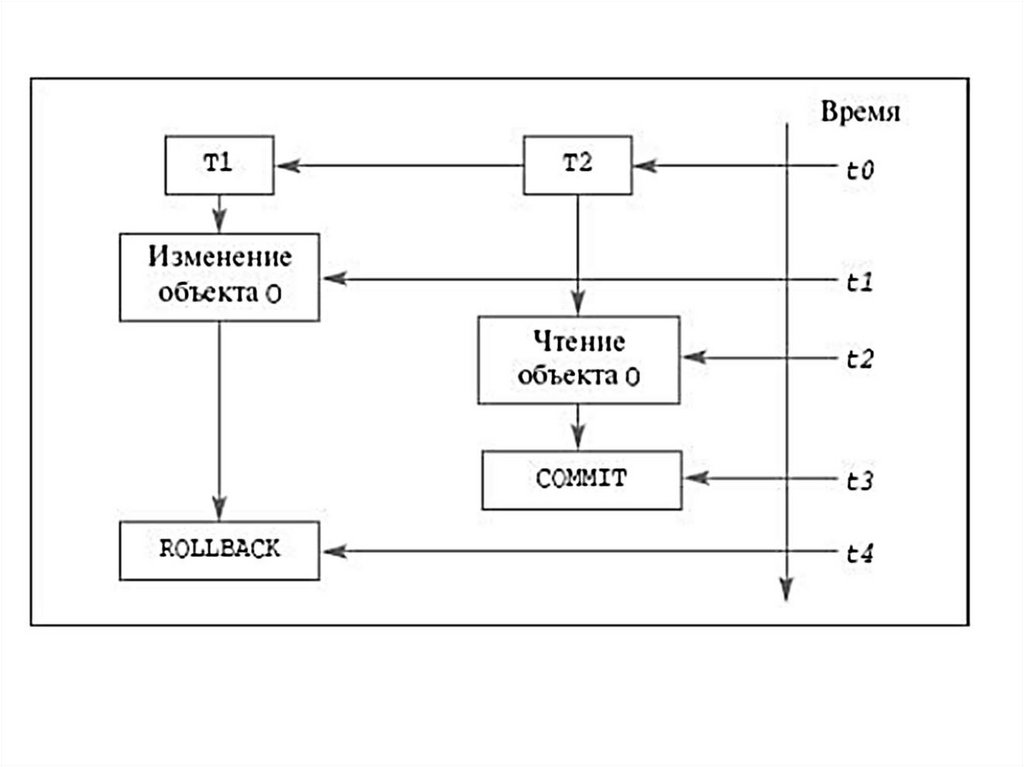
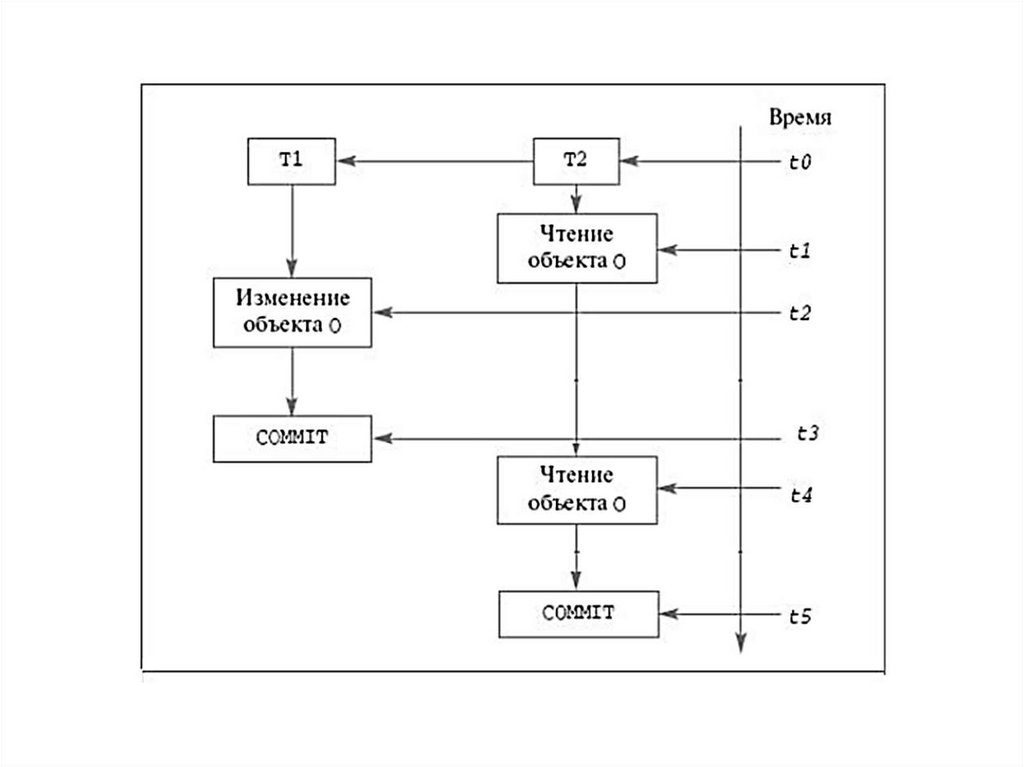
28. Механизм транзакций
используется в СУБД для поддержания целостности данных вбазе. Транзакцией называется некоторая неделимая последовательность
операций над данными БД, которая отслеживается СУБД от начала и до
завершения. Если по каким-либо причинам (сбои и отказы оборудования,
ошибки в программном обеспечении, включая приложение) транзакция
остается незавершенной, то она отменяется.
Говорят, что транзакции присущи три основных свойства:
• атомарность (выполняются все входящие в транзакцию операции или ни
одна);
• сериализуемость (отсутствует взаимное влияние выполняемых в одно и то
же время транзакций);
• долговечность (даже крах системы не приводит к утрате результатов
зафиксированной транзакции).
Примером транзакции является операция перевода денег с одного счета на
другой в банковской системе.
29. Журналы
Ведение журнала изменений в БД (журнализацияизменений) выполняется СУБД для обеспечения надежности
хранения данных в базе при наличии аппаратных сбоев и
отказов, а также ошибок в программном обеспечении.
Журнал СУБД - это особая БД или часть основной БД,
непосредственно недоступная пользователю и используемая
для записи информации обо всех изменениях базы данных.
В различных СУБД в журнал могут заноситься записи,
соответствующие изменениям в СУБД на разных уровнях: от
минимальной внутренней операции модификации страницы
внешней памяти до логической операции модификации БД
(например, вставки записи, удаления столбца, изменения
значения в поле) и даже транзакции.
30. Обеспечение целостности БД
составляет необходимое условие успешного функционирования БД,особенно для случая использования БД в сетях. Целостность БД есть
свойство базы данных, означающее, что в ней содержится полная,
непротиворечивая и адекватно отражающая предметную область
информация. Поддержание целостности БД включает проверку
целостности и ее восстановление в случае обнаружения противоречий в
базе данных. Целостное состояние БД описывается с помощью
ограничений целостности в виде условий, которым должны
удовлетворять хранимые в базе данные. Примером таких условий может
служить ограничение диапазонов возможных значений атрибутов
объектов, сведения о которых хранятся в БД, или отсутствие
повторяющихся записей в таблицах реляционных БД.
Ссылочная целостность данных (referential integrity) - набор правил,
обеспечивающих соответствие ключевых значений в связанных таблицах.
Обеспечение безопасности достигается в СУБД шифрованием
прикладных программ, данных, защиты паролем, поддержкой уровней
доступа к базе данных и к отдельным ее элементам (таблицам,
представлениям, хранимым процедурам и т. д.).
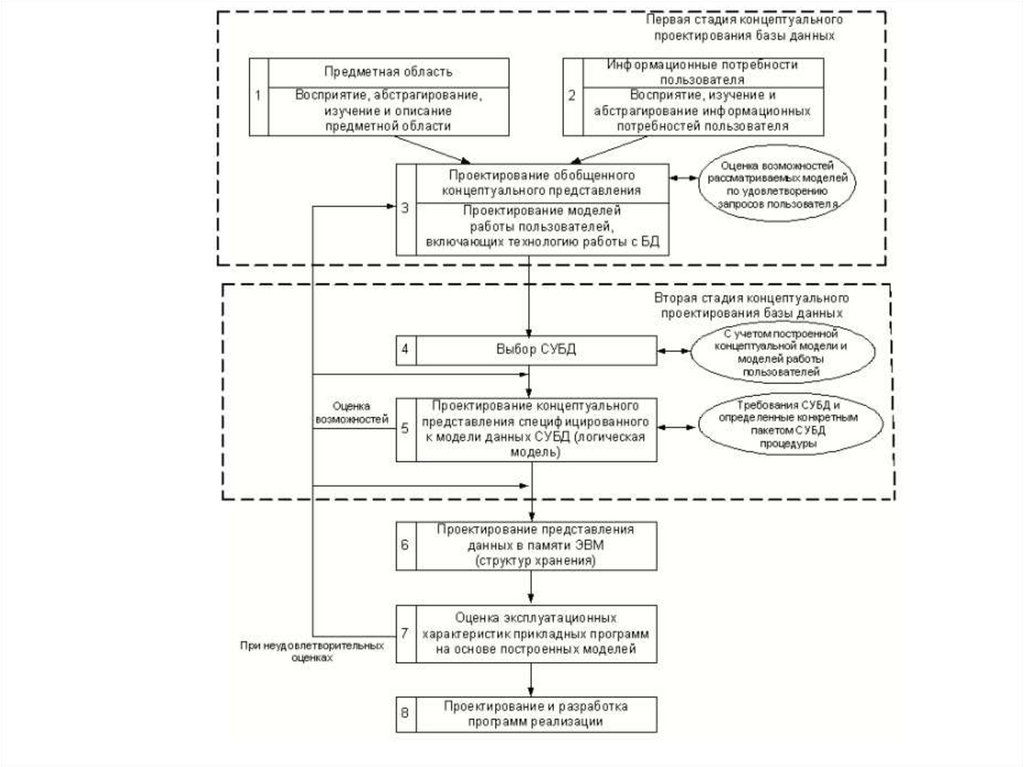
31. Основные этапы проектирования базы данных
Общая схема проектирования32. Этапы проектирования БД
Системный анализ и словесное описаниеинформационных объектов предметной
области.
Проектирование инфологической модели
предметной области — частично
формализованное описание объектов
предметной области в терминах некоторой
семантической модели, например, в терминах
ER-модели.
Даталогичеcкое или логическое
проектирование БД, то есть описание БД в
терминах принятой даталогической модели
данных.
Физическое проектирование БД, то есть выбор
эффективного размещения БД на внешних
носителях для обеспечения наиболее
эффективной работы приложения.
33. Системный анализ предметной области
Подробное словесное описаниеобъектов предметной области и реальных
связей, которые присутствуют между
описываемыми объектами.
Желательно, чтобы данное описание
позволяло корректно определить все
взаимосвязи между объектами предметной
области.
34. Подходы к анализу предметной области
• Функциональный подход (от функций кструктуре)
• Предметный подход (все, что может
пригодиться)
35. Различные представления о данных в базах данных. Основные этапы проектирования баз данных
Концептуальный этапОписание текстовое
36.
37. Пример проектирования реляционной базы данных издательства
• 1. Инфологическое проектирование *• 1.1. Анализ предметной области *
• 1.2. Анализ информационных задач и круга пользователей
системы *
• 2. Определение требований к операционной обстановке *
• 3. Выбор СУБД и других программных средств *
• 4. Логическое проектирование реляционной БД *
• 4.1. Преобразование ER–диаграммы в схему базы данных
*
38. Инфологическое проектирование Анализ предметной области
каждая книга издаётся в рамках контракта;
книга может быть написана несколькими авторами;
контракт подписывается одним менеджером и всеми авторами
книги;
каждый автор может написать несколько книг (по разным
контрактам);
порядок, в котором авторы указаны на обложке, влияет на
размер гонорара;
если сотрудник является редактором, то он может работать
одновременно над несколькими книгами;
у каждой книги может быть несколько редакторов, один из них –
ответственный редактор;
каждый заказ оформляется на одного заказчика;
в заказе на покупку может быть перечислено несколько книг.
39. Базовые сущности
Сотрудники компании. Атрибуты сотрудников – ФИО,
табельный номер, пол, дата рождения, паспортные данные,
ИНН, должность, оклад, домашний адрес и телефоны. Для
редакторов необходимо хранить сведения о редактируемых
книгах; для менеджеров – сведения о подписанных
контрактах.
Авторы. Атрибуты авторов – ФИО, ИНН
(индивидуальный номер налогоплательщика), паспортные
данные, домашний адрес, телефоны. Для авторов
необходимо хранить сведения о написанных книгах.
Книги. Атрибуты книги – авторы, название, тираж,
дата выхода, цена одного экземпляра, общие затраты на
издание, авторский гонорар.
40. Анализ информационных задач и круга пользователей
группы пользователей:администрация (дирекция);
менеджеры;
редакторы;
сотрудники компании, обслуживающие
заказы.
41. Требования
ведение БД (запись, чтение, модификация, удаление в
архив);
реализация наиболее часто встречающихся запросов
в готовом виде;
предоставление возможности сформировать
произвольный запрос на языке манипулирования данными.
обеспечение логической непротиворечивости БД;
обеспечение защиты данных от
несанкционированного или случайного доступа
(определение прав доступа);
42. Запросы (требования пользователей)
• получение списка всех текущих проектов (книг,находящихся в печати и в продаже);
• получение списка редакторов, работающих над книгами;
• получение полной информации о книге (проекте);
• получение сведений о конкретном авторе (с перечнем
всех книг);
• получение информации о продажах (по одному или по
всем проектам);
• определение общей прибыли от продаж по текущим
проектам;
• определение размера гонорара автора по конкретному
проекту
43. Этапы разработки БД
1. Концептуальный уровеньПервая верхнеуровневая модель для представления новой предметной области будущего
проекта: что в ней есть и с чем нужно работать. Например, в ПО для транспортной
компании будут сущности «Транспорт», «Груз», «Маршрут», «Накладная».
ER-модель концептуального уровня нужна системному аналитику и заказчику, чтобы
проверить, все ли термины учтены. Поэтому системный аналитик, как правило, создаёт её
самостоятельно и не привлекает технических специалистов из команды разработки.
2. Логический уровень
На этом уровне детализируют данные из концептуальной модели: к сущностям добавляют
характеристики — атрибуты. Например, на логическом уровне описывают характеристики
сущности «Транспорт»: марка и модель автомобиля, количество лошадиных сил, пробег,
грузоподъёмность.
Модель логического уровня тоже составляет системный аналитик, но уже не в одиночку. К
работе подключают технических специалистов ― разработчика или архитектора баз
данных. Готовую логическую ER-модель нужно презентовать команде разработки.
Разработчики проверяют, чтобы аналитик ничего не упустил, и согласовывают модель.
3. Физический уровень
На этом уровне описывают, как будет организована работа с данными: выбирают тип базы,
её содержание и где данные будут хранить. Например, выбирают реляционный тип базы
данных и СУБД для работы с ней, перечисляют таблицы в базе и определяют, что она будет
храниться на внутреннем сервере компании.
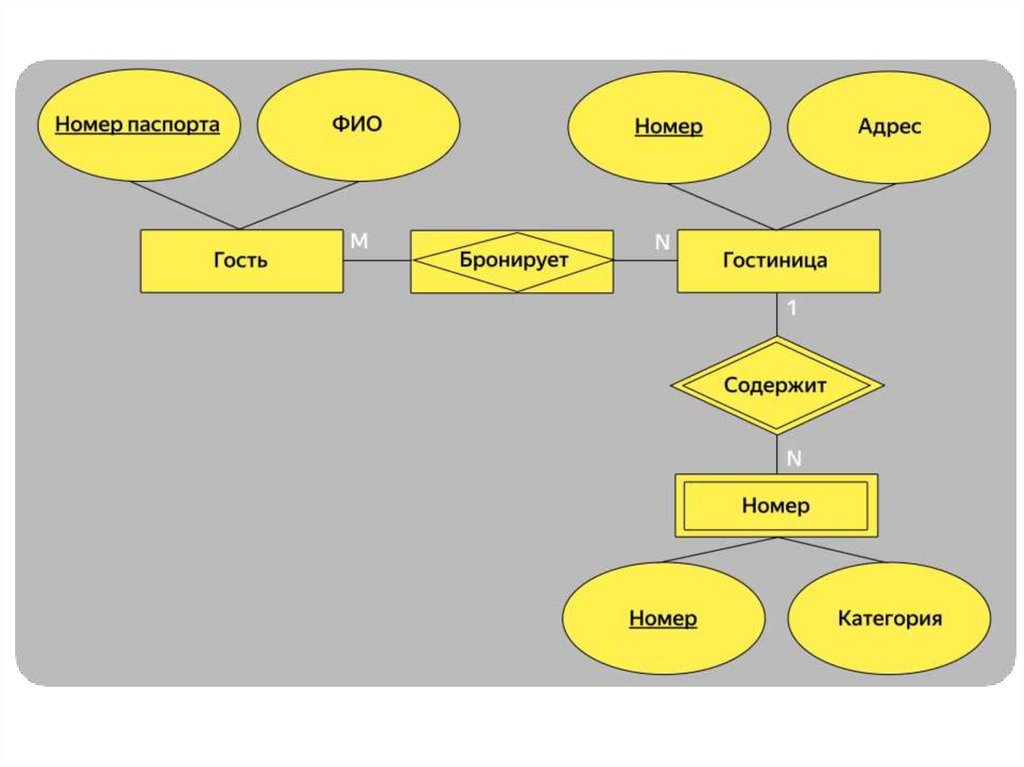
44. Диаграмма СУЩНОСТЬ-СВЯЗЬ (ER)
45. ER-диаграммы
Диаграммы "сущность-связь" (ER-диаграммы)–графическое представление модели
"сущность-связь".
46.
1. Нотация IDEF1X. Её относят к фундаментальным, но напрактике давно не используют, потому что есть более удобные
варианты.
2. Нотация Чена. Классическая нотация, которая состоит из
простых символов — прямоугольников, овалов и линий. Из-за
этого нотацию часто используют для концептуальных моделей,
которые презентуют заказчику. Человеку, который далёк от
аналитики данных, проще разобраться в понятных диаграммах
со знакомыми символами.
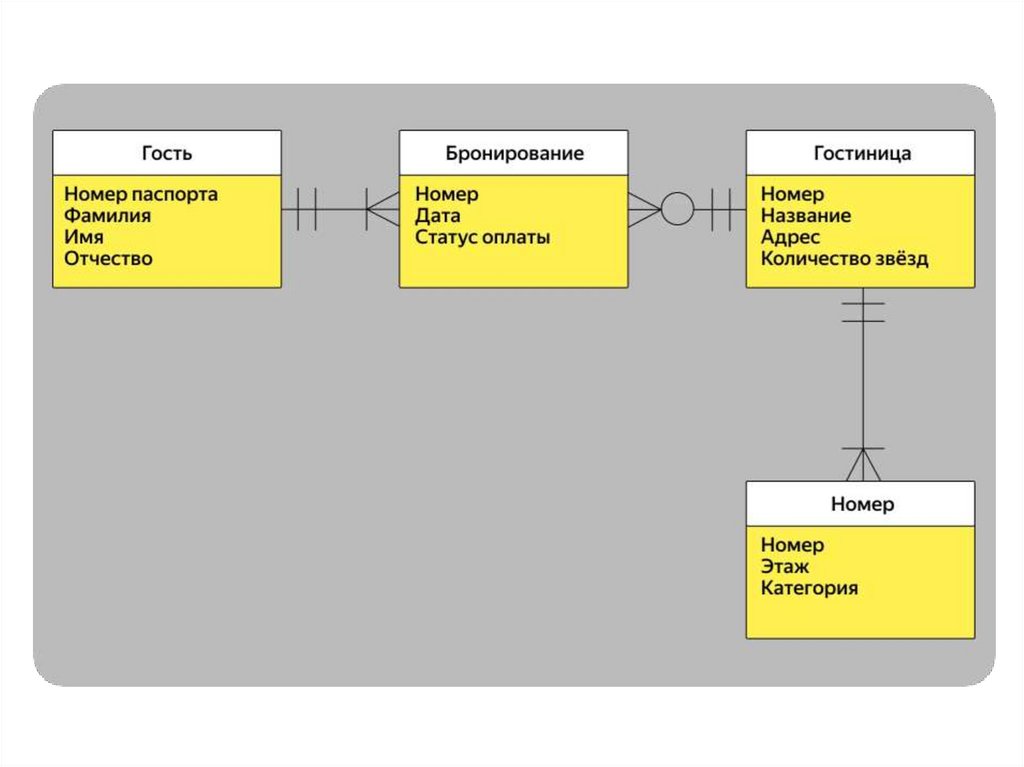
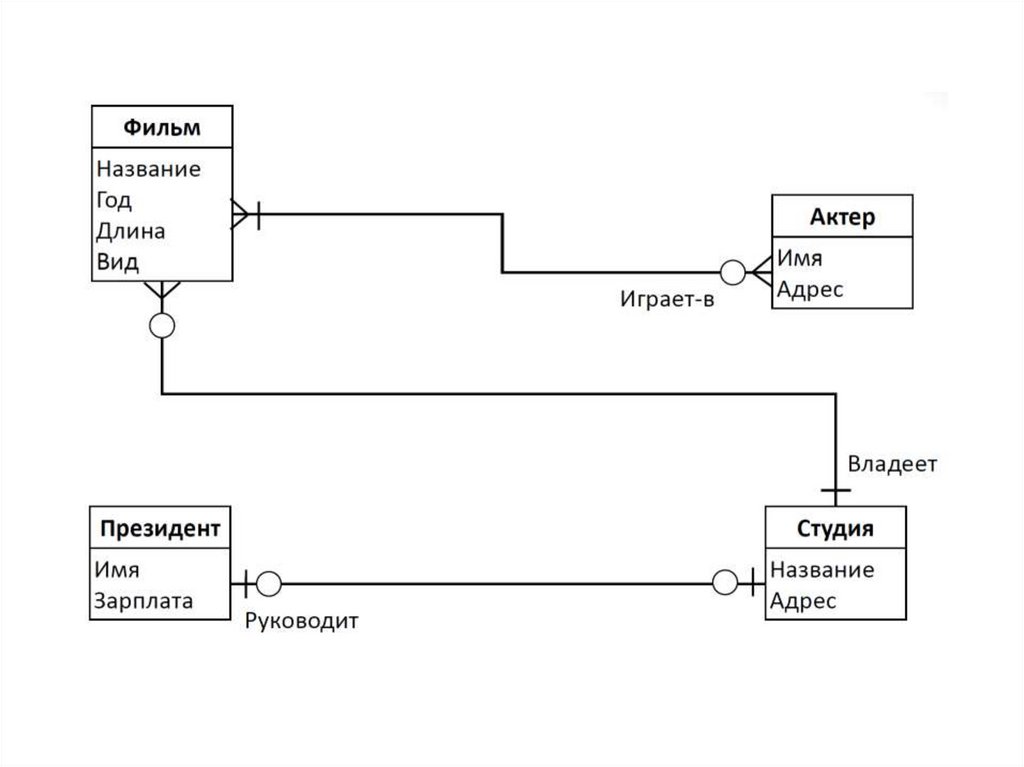
3. Нотация Мартина. Её ещё называют «воронья лапка» (от англ.
Crow's Foot). Она компактнее нотации Чена, поэтому её
используют для построения ER-моделей логического уровня,
когда нужно описать в модели все атрибуты сущностей.
47. Сущности и их атрибуты:нотация Чена
48. Сущности и их атрибуты:нотация Мартина
49. Связи между сущностями: нотация Чена
50. Связи между сущностями: вороньи лапки
51.
52.
53. 1. Определить сущности
Чтобы собрать все сущности будущегопроекта, системные аналитики общаются с
заказчиком и будущими пользователями ПО:
сотрудниками или клиентами компании.
Например, если нужно разработать ПО для
ветеринарной клиники, системный аналитик
проведёт интервью с руководителем
клиники, сотрудниками, врачами и
клиентами, которые будут записываться на
приём. На этом этапе обычно создают
концептуальную модель и согласовывают её с
заказчиком.
54. 2. Определить атрибуты
Системный аналитик детализируетинформацию, собранную во время интервью,
и описывает характеристики сущностей. Если
данных не хватает, нужно повторно опросить
заинтересованных лиц.
55. 3. Определить связи между сущностями
На этом этапе выясняют, какие сущностисвязаны между собой. Например, пациенты и
медицинская карта, филиал клиники и врачи,
которые ведут приём.
56. 4. Определить типы и характеристики связей
Например, пациенты и медицинская карта —это связь «один-к-одному», врач и день
приёма — «один-ко-многим».
57.
Затем ищут идентифицирующие связи междусущностями и определяют, какая из
сущностей родительская. Допустим, у
клиники есть филиалы — A, B и C. В каждом
филиале есть кабинеты под номерами от 1 до
5. Это значит, что нельзя использовать номер
кабинета без уточнения, в каком филиале он
находится. Филиал — родительская сущность,
а связь между филиалом и кабинетом —
идентифицирующая.
58. 5. Проверить ER-модель
После завершения работы над ER-модельюсистемный аналитик проверяет, нет ли в ней
лишних сущностей, дубликатов данных и
косвенных связей между данными в одной
таблице. Такую проверку называют
нормализацией данных.
59. Сущность и связь
60. Тип сущности и множество сущностей
61.
62. Атрибут, значение, множество значений
63. Информация о сущности
64. Информация о связях
65. Идентификация сущности
66. Виды бинарных связей
•Пусть имеются два множества сущностей: E1и E2 и R –связь между ними. Тогда
•R имеет вид "один-ко-много" в направлении
от E1 к E2, если посредством R каждый член
множества E2 может быть соединен не более
чем с одним членом из множества E1.
•R имеет вид "один-к-одному", если R в
обоих направлениях имеет вид "один-комного".
•R имеет вид "много-ко-много", если ни в
одном из направлений (от E1 к E2 и от E2 к
E1) связь R не относится к типу "один-комного".
11
67. Бинарные связи: вороньи лапки
68.
69. Многосторонние (n-арные) связи
70. Преобразование n-арныхсвязей в бинарные
•Любая n-арная связь может быть преобразована в наборбинарных связей "много-к-одному"с помощью введения
соединяющего множества сущностей.
71. Диаграммы «Сущность-Связь»
72. Примеры диаграмм ER
73. Инструменты
Lucidchart.https://www.lucidchart.com/pages/ru/examples
/er-diagram-tool
74. Построение концептуальной модели в виде ER-диаграммы На первом этапе производится сбор и анализ характеристик данных и строятся
Построение концептуальной модели в виде ERдиаграммыНа первом этапе производится сбор и анализ характеристик
данных и строятся так называемые модели локальных
представлений (локальные модели). Чаще всего локальная
модель отражает представление отдельного пользователя
(отдельной функциональной задачи).
• определить сущности.
– необходимо понять, какая информация должна храниться и обрабатываться и
можно ли это определить как сущность;
– присвоить этой сущности имя;
– выявить атрибуты сущности и присвоить им имя;
– определить уникальный идентификатор сущности.
• При определении связей
– то, как экземпляр одной сущности связан с экземпляром другой сущности;
– то, как должны быть установлены связи, чтобы была возможность ответа на все
запросы пользователей (исходя из их информационных потребностей).
• Далее необходимо присвоить связям имена и определить тип связей.
75.
Построенная модель должна удовлетворять ряду требований:• адекватно отражать представление пользователя о данных;
• давать возможность ответа на возможные запросы
пользователя, причем делать это с минимальными затратами
по количеству просматриваемых сущностей;
• представлять данные с минимальным дублированием.
Вариативность моделирования
определили сущность ФАКУЛЬТЕТ с атрибутами "номер
факультета", "название факультета". Введем сущность КАФЕДРА
с атрибутами "номер кафедры", "название кафедры". Между
этими сущностями есть связь "факультет состоит из кафедр".
Возможен другой вариант, в котором вышеуказанная
связь представляется через атрибуты сущности (у сущности
ФАКУЛЬТЕТ введем дополнительные атрибуты,
представляющие номера и названия всех кафедр этого
факультета).
76.
77. Связи
• Классы связей – это взаимоотношения между классами сущностей,• экземпляры связи – взаимоотношения между экземплярами
сущностей.
• Число классов сущностей, участвующих в связи,
называется степенью связи n = 2, 3, ...
78.
Редактирование введенных наименованийсущностей, атрибутов и связей
• устраняются расплывчатые наименования
(все наименования должны однозначно
пониматься каждым пользователем);
• устраняются синонимы (различные
наименования одного и того же понятия);
• устраняются омонимы (одно и то же
наименование разных понятий).
79. Объединение локальных моделей
• слияние идентичных элементов;• установление связей между наборами сущностей разных
моделей;
• введение новых агрегированных элементов для
представления связей между элементами разных
моделей;
• обобщение различных подобных типов сущностей,
позволяющее трактовать эти сущности как одну
обобщенную сущность.
80. Слияние идентичных элементов
Объединенная модель81. Введение агрегированных элементов
82. Обобщение подобных типов сущностей
83. Вторая стадия концептуального проектирования
Представление концептуальной модели средствами моделиданных СУБД
• Элемент данных (поле) – наименьшая поименованная единица
данных. Используется для представления значения атрибута.
• Запись – поименованная совокупность полей. Используется
для представления совокупности атрибутов сущности
(записи о сущности).
• Экземпляр записи – запись с конкретными значениями полей.
• Первичный ключ – минимальный набор полей записи,
однозначно идентифицирующий экземпляр записи файла.
• Файл – поименованная совокупность экземпляров записей
одного типа. Используется для представления однородного
набора сущностей.
• Набор файлов – поименованная совокупность файлов,
обрабатываемых в системе. Используется для представления
нескольких наборов сущностей.
84.
• Группа – это поименованная совокупностьэлементов данных и других групп.
• Групповое отношение – поименованное бинарное
отношение, заданное на двух множествах
экземпляров рассматриваемых групп. По характеру
бинарных связей различают групповые отношения
вида 1:1, 1:M, M:1, M:N. Пары чисел называют
коэффициентами группового отношения. В
групповом отношении один член группы
назначается владельцем отношения, другой –
членом.
• База данных – поименованная совокупность
экземпляров групп и групповых отношений.
85. Логическое проектирование реляционной БД Преобразование ER–диаграммы в схему базы данных
86. Обозначения
87. Реляционная база данных
88. Типы БД
89.
• а) Графовая. Группы изображаются вершинамиграфа, связи между группами – дугами,
направленными от группы-владельца к группечлену с указанием имени отношения и
коэффициента. Различают:
– иерархическую модель (граф без циклов – дерево) ;
– сетевую модель (ориентированный граф общего
вида).
• б) Табличная. Связь между группами изображается
таблицей, столбцы которой представляют ключи
соответствующих групп. Для формального описания
таблицы используется математическое (теоретикомножественное) понятие отношения.
Соответствующая модель данных называется
реляционной моделью.
90. Модель данных СУБД
Модель данных СУБДопределены возможные типы и характеристики логических структур данных
(полей, записей, файлов);
заданы правила составления структур более общего типа из структур более
простых типов (например, записей из полей, файлов из записей и т.д.);
определен способ представления связей (отношений) между файлами и
записями с помощью дополнительных полей ;
определены возможные действия над структурами и правила их выполнения,
включающие:
– основные элементарные операции над данными;
– обобщенные операции (процедуры);
– средства контроля относительно простых условий корректности операций
добавления, обновления или удаления данных (ограничения),
реализуемые автоматически запускаемыми при выполнении
вышеуказанных операций специальными процедурами (триггерами);
– средства контроля сколь угодно сложных условий корректности
выполнения определенных действий (правила);
– специальный класс процедур (триггеры).
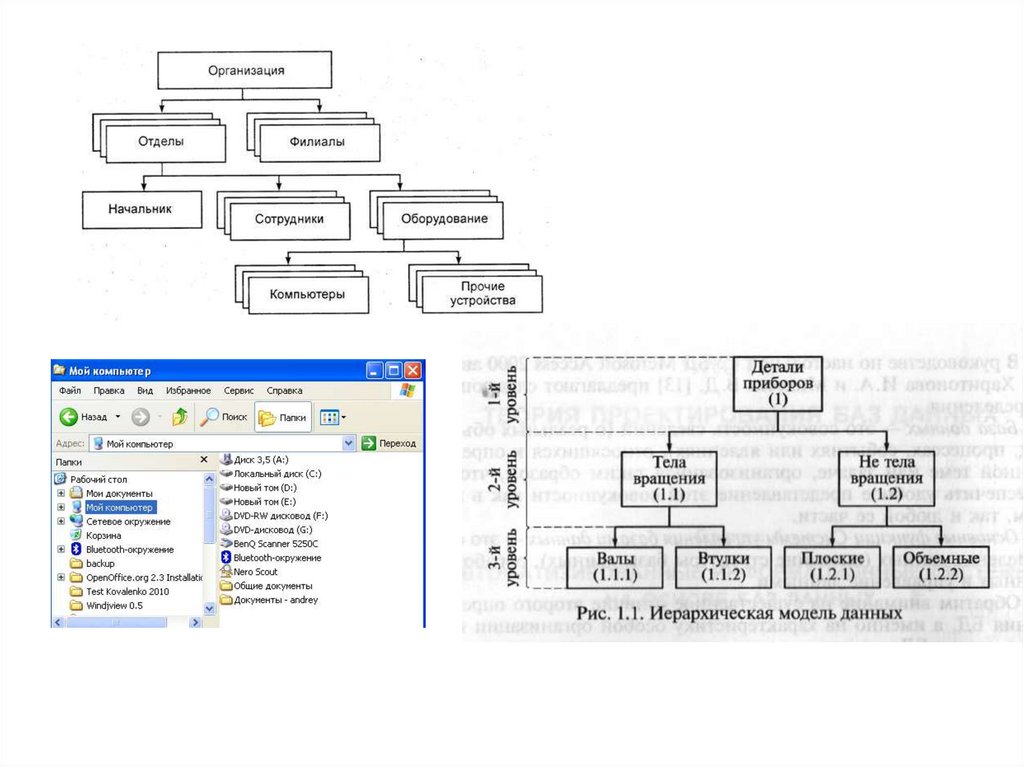
91. Иерархическая модель данных
• Исторически первыми появились СУБД, реализующиеиерархическую модель данных: первая коммерческая СУБД
IBM IMS относится к этому типу. В иерархической системе
данные организованы в наборы древовидных структур
(иерархий). Основными информационными единицами
являются поле, сегмент (запись), связь, БД.
• Поле данных (или просто "поле", в некоторых изданиях,
аналогично сетевой модели, также называется "элемент") –
минимальная именованная единица данных, доступная
пользователю с помощью СУБД.
• Сегмент или запись составляет основную единицу обработки
БД: записи запоминаются, извлекаются, удаляются. Определяют
тип и экземпляр записи (сегмента). Тип записи – это
именованная совокупность полей данных с указанием их типов,
экземпляр записи (или просто запись) – некоторая
совокупность значений элементов в последовательности,
соответствующей определению типа. Иными словами, тип
записи задает все множество подобных объектов, а экземпляр
– конкретный объект из этого множества.
92.
• Для того чтобы можно было однозначно различать записи,каждый тип записи должен иметь ключ – набор полей,
однозначно идентифицирующий экземпляр записи.
Например, в записи, описывающей человека, таким
ключом может быть номер паспорта.
• Связь (англ. link) – иерархическое отношение между
записями двух типов; некоторые авторы по аналогии с
сетевой моделью пользуются термином "групповое
отношение". Связи при графическом изображении
обозначаются дугами ориентированного графа, типы
записей – вершинами.
93.
Тип связи определяется ее именем и задает свойства, общие для всехэкземпляров связи данного типа. Экземпляр связи задается логически
исходной записью ("владельцем") и множеством (возможно пустым)
подчиненных записей. Таким образом, каждой подчиненной записи в
иерархической модели может соответствовать только одна исходная;
одной исходной записи может соответствовать несколько подчиненных.
В иерархической модели сегменты и связи между ними создают
древовидные структуры (деревья). В каждом дереве существует только
одна запись, которая не связана ни с какой исходной записью, – она
называется корневой. Таким образом, дерево – совокупность корневой
записи и множества подчиненных записей.
94.
95. Элементы иерархической модели БД
Атрибут(элемент данных) - наименьшая единица структуры данных. Обычно каждому элементу при описании базы данныхприсваивается уникальное имя. По этому имени к нему обращаются при обработке. Элемент
данных также часто называют полем.
Запись
- именованная совокупность атрибутов. Использование записей позволяет за одно обращение к
базе получить некоторую логически связанную совокупность данных. Именно записи изменяются,
добавляются и удаляются. Тип записи определяется составом ее атрибутов. Экземпляр записи конкретная запись с конкретным значением элементов.
Групповое отношение
- иерархическое отношение между записями двух типов. Родительская запись (владелец
группового отношения) называется исходной записью, а дочерние записи (члены группового
отношения) - подчиненными. Иерархическая база данных может хранить только такие древовидные
структуры.
96.
Сетевая модель данныхСтандарт сетевой модели данных был опубликован в отчете организации
CODASYL (от англ. Conference on DAta SYstems Languages) в 1971 г. Так
же как и иерархическая, сетевая модель относится к разряду теоретикографовых, но она позволяет строить структуры данных, описываемые
графом более общего вида, чем предполагает иерархическая модель.
Базовые структуры данных сетевой модели: элемент данных, агрегат
данных, запись (или группа), набор (групповое отношение), БД.
Элемент данных (или просто "элемент") – минимальная именованная
единица данных, доступная пользователю с помощью СУБД.
Агрегат данных – именованная совокупность элементов или других
агрегатов данных.
Запись – это агрегат, который не входит в состав никакого другого агрегата,
обычно описывает некоторый объект реального мира и составляет
основную единицу обработки БД (записи запоминаются, извлекаются,
удаляются).
97. Элементы сетевой модели
Элемент данныхАгрегат данных
Запись
98. Набор записей. База данных
Набор записей – это
именованная двухуровневая
иерархическая структура,
которая содержит управляемую
и управляющую записи.
База данных сетевой модели
данных – это именованная
совокупность экземпляров
записей различного типа и
экземпляров наборов, хранящих
в себе типы связей между
записями.
99.
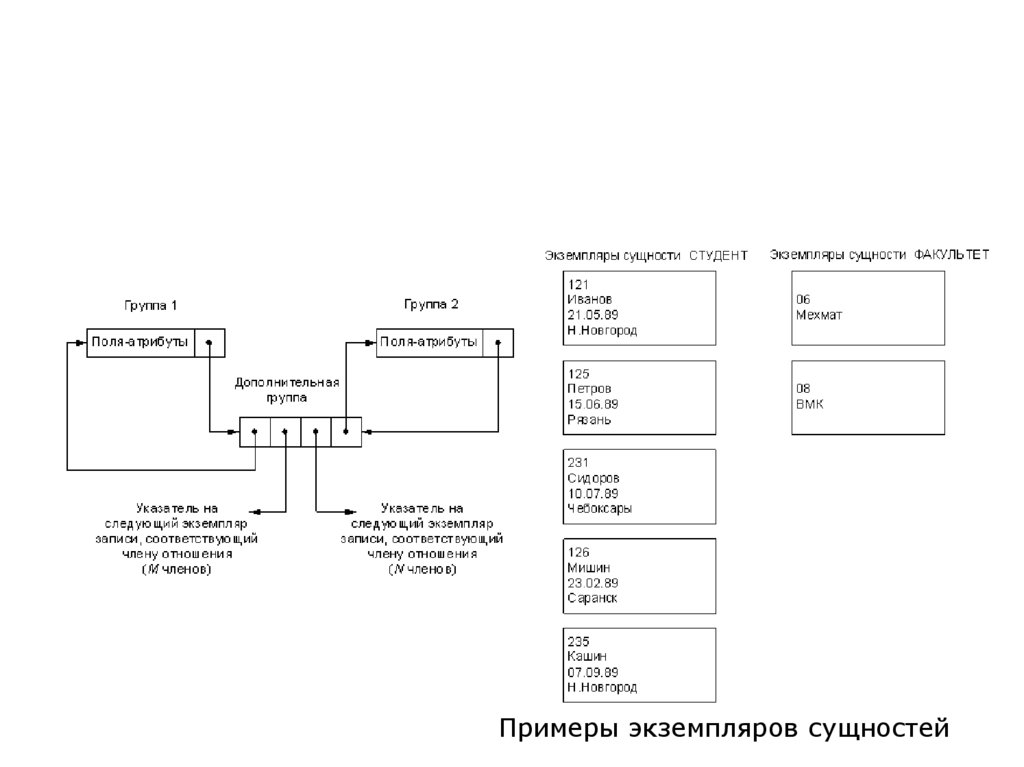
Примеры экземпляров сущностей100. Сравнение моделей
101. Пример сетевой модели концептуального представления
102. Пример сетевой БД
103. Реляционная модель данных
Данные распределены по смыслу по таблицамМежду таблицами есть отношения
Отношения между таблицами определяются с помощью primary key и
foreign key.
104.
Отношение, представляется в виде таблицы, столбцы которой соответствуют
атрибутам сущности (структура строки таблицы аналогична структуре записи).
Каждый атрибут может принимать определенное множество значений,
называемое доменом. Здесь для формального описания таблицы используется математическое
(теоретико-множественное) понятие отношения.
Строка таблицы с конкретными значениями полей здесь называется
кортежем (соответствует понятию "экземпляр записи").
Поля таблицы предполагаются элементарными (неделимыми). Таким
образом, понятие "таблица" здесь соответствует понятию "файл" модели
данных.
Первичный ключ здесь –минимальный набор атрибутов, однозначно
идентифицирующий кортеж в отношении.
Групповое отношение может представляться двумя способами. При первом
способе в таблицы, соответствующие группам – членам отношения,
добавляются столбцы ключевых полей (атрибутов) другого члена отношения
(связь описывается через ключевые атрибуты).
При втором способе групповое отношение определяется как дополнительная
группа (дополнительная таблица). Столбцами этой дополнительной таблицы
являются ключи групп – членов отношения.
105. Колоночная реляционная БД
Реляционная БДSELECT * FROM table WHERE color = 5235
• | type | style | color | method |
• --------------------------------• |
1| 10| 3421|
32 |
• |
2|
4| 543| 43295 |
• |
5|
6| 5235| 82341 |
106. Сортировка данных
ПоискКолонка type: 1, 2, 5
Колонка style: 10, 4, 6
Колонка color: 3421, 543, 5235
Колонка method: 32, 43295, 82341
Отсортированные данные (номер в
списке)
Колонка type: 1(1), 2(2), 5(3)
Колонка style: 4(2), 6(3), 10(1)
Колонка color: 543(2), 3421(1), 5235(3)
Колонка method: 32(1), 43295(2), 82341(3)
107. Сравнение эффективности
Обновление и удаление данныхUPDATE table SET type = 2 WHERE style = 10
Для этого необходимо сначала выбрать номер записей из колонки style, а затем
найти их в колонке type и обновить. Строчная база данных сделает обновление за
одну операцию.
Добавление и удаление колонок
Поскольку колонки — это просто отдельные файлы, добавление и удаление колонок ничего
не стоит. Это просто создание и удаление файлов на диске.
В случае же строчной базы данных, новая колонка приводит к обновлению данных в
каждой строке таблицы
Сжатие
Поскольку каждая колонка — это отдельный файл, каждый файл хранит всегда данные
только одного типа. В отличие от строчных, где каждая строка имеет совокупность разных
типов.
108. СУБД NO SQL
Тип базы данныхСУБД
BerkeleyDB Key-Value ("Базы данных типа
"ключ-значение")
Memcached
Projecr Voldemorr
Redis
Riak
CouchDB Documenr ("Документные базы
данных")
MongoDB
OrientDB
RavenDB
Terrastore
Amazon SimpleDB Column-Family
("Семейства столбцов")
Cassandra
HBase
HyperraЫe
FlockDB Graph ("Графовые базы данных")
HyperGraphDB
Infinire Graph
Neo4J
OrienrDB
109. Хранилище ключ-значение
Реляционная БДХранилище типа ключ-значение
База данных состоит из таблиц,
Для доменов можно провести аналогию с
таблицы содержат колонки и строки, а таблицами, однако в отличие от таблиц для доменов
строки состоят из значений колонок.
не определяется структура данных. Домен – это
Все строки одной таблицы имеют
такая коробка, в которую вы можете складывать
единую структуру.
все что угодно. Записи внутри одного домена могут
иметь разную структуру.
Модель данных1 определена заранее. Записи идентифицируются по ключу, при этом
Является строго типизированной,
каждая запись имеет динамический набор
содержит ограничения и отношения
атрибутов, связанных с ней.
для обеспечения целостности данных.
Модель данных основана на
естественном представлении
содержащихся данных, а не на
функциональности приложения.
В некоторых реализация атрибуты могут быть
только строковыми. В других реализациях атрибуты
имеют простые типы данных, которые отражают
типы, использующиеся в программировании: целые
числа, массива строк и списки.
Модель данных подвергается
нормализации, чтобы избежать
дублирования данных. Нормализация
порождает отношения между
таблицами. Отношения связывают
данные разных таблиц.
Между доменами, также как и внутри одного
домена, отношения явно не определены.
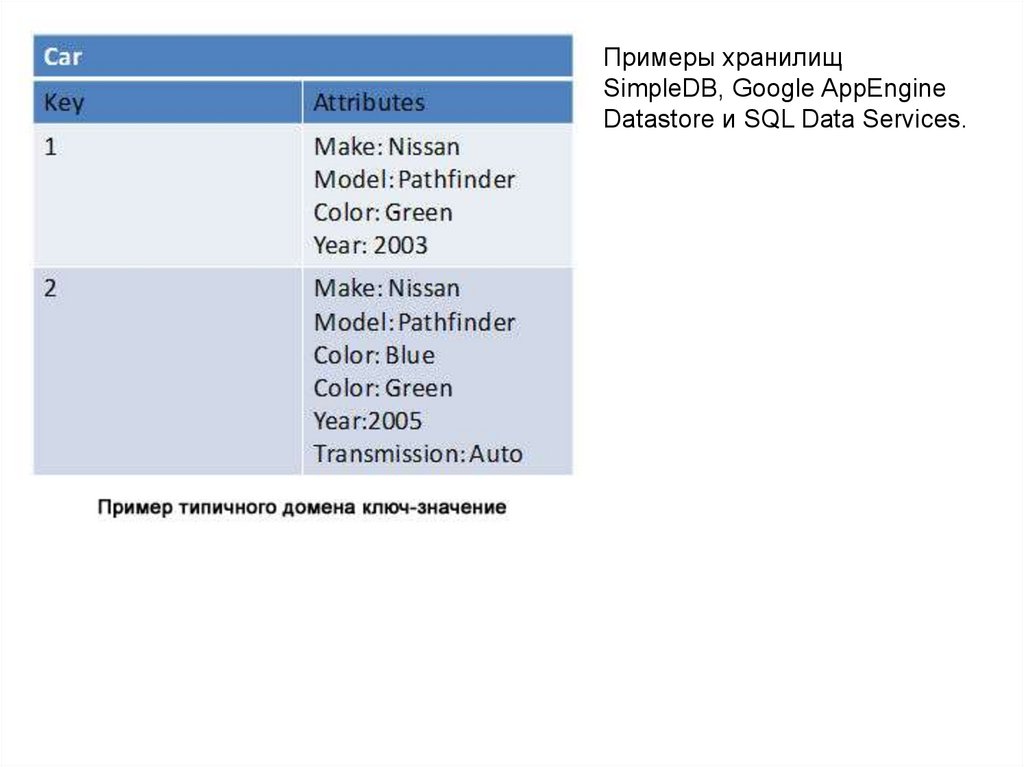
110.
Примеры хранилищSimpleDB, Google AppEngine
Datastore и SQL Data Services.
111. Ключ-значение
Преимущества•подходят для облачных сервисов
•более естественная интеграция с кодом
Недостатки
•контроль целостности данных полностью
лежит на приложениях
•отсутствует проект модели данных
•ограниченная аналитика данных
112. Документоориентированная БД
представляет собой систему хранения иерархических структур данных(документов), имеющую структуру дерева или леса. Структура дерева
начинается с корневого узла и может иметь несколько внутренних и
листовых узлов. Листовые узлы содержат конечные данные, которые при
добавлении заносятся в индексы базы, благодаря которым можно
осуществлять быстрый поиск даже при достаточно сложной общей
структуре хранилища. Фактически документоориентированные БД
являются более сложной версией хранилищ “ключ-значение” - они все
ещё не очень хороши для систем, подразумевающих множество связей
между элементами, но позволяют осуществлять выборку по запросу без
полной загрузки отдельных документов в оперативную память.
Механизмы поиска позволяют находить как документы целиком, так и
части документов, а древовидная структура позволяет организовывать
отдельные коллекции документов одного типа или схожей тематики.
113.
К примеру, при создании музыкального хранилища можно создатьколлекцию музыки 80-х годов, в ней сделать отдельные коллекции по
годам, а внутри них отдельные документы с треками выпущенных в
этот год альбомов. Но если пользователь пожелает увидеть рейтинг
самых популярных композиций определенного десятилетия - этот
запрос будет выполняться достаточно долго, ведь придется
просмотреть каждый документ всей базы данных. Таким образом,
можно сделать вывод что документоориентированные БД найдут
своё применение в задачах, где требуется упорядоченное хранение
информации, но нет множества связей между данными и не нужно
постоянно собирать статистику по ним. Документы не требуют
определения схемы - это значит что каждый отдельный документ
может состоять из любого количества уникальных полей - в отличие
от реляционных баз данных, в которых при попытке хранить
разнородные данные неизбежно появляются пустые поля.
114. Что такое MapReduce
MapReduce – это модель распределённых вычислений от компанииGoogle, используемая в технологиях Big Data для параллельных
вычислений над очень большими (до нескольких петабайт) наборами
данных в компьютерных кластерах, и фреймворк для вычисления
распределенных задач на узлах (node) кластера.
Изначально название MapReduce было запатентовано корпорацией
Google, но по мере развития технологий Big Data стало общим
понятием мира больших данных. Сегодня множество различных
коммерческих, так и свободных продуктов, использующих эту модель
распределенных вычислений: Apache Hadoop, Apache CouchDB,
MongoDB, MySpace Qizmt и прочие Big Data фреймворки и библиотеки,
написанные на разных языках программирования.
https://biconsult.ru/services/chto-takoemapreduce
115. НАЗНАЧЕНИЕ И ОБЛАСТИ ПРИМЕНЕНИЯ
MapReduce можно по праву назвать главной технологией Big Data, т.к.она изначально ориентирована на параллельные вычисления в
распределенных кластерах. Суть MapReduce состоит в разделении
информационного массива на части, параллельной обработки каждой
части на отдельном узле и финального объединения всех результатов.
116. Map
Map – предварительная обработка входныхданных в виде большого список значений.
При этом главный узел кластера (master node)
получает этот список, делит его на части и
передает рабочим узлам (worker node). Далее
каждый рабочий узел применяет функцию
Map к локальным данным и записывает
результат в формате «ключ-значение» во
временное хранилище.
117. Shuffle (перетасовать)
Shuffle, когда рабочие узлыперераспределяют данные на основе ключей,
ранее созданных функцией Map, таким
образом, чтобы все данные одного ключа
лежали на одном рабочем узле.
118. Reduce
Reduce – параллельная обработка каждымрабочим узлом каждой группы данных по
порядку следования ключей и «склейка»
результатов на master node. Главный узел
получает промежуточные ответы от рабочих
узлов и передаёт их на свободные узлы для
выполнения следующего шага. Получившийся
после прохождения всех необходимых шагов
результат – это и есть решение исходной
задачи.
119.
Программы, использующие MapReduce, автоматическираспараллеливаются и исполняются на распределенных
узлах кластера, при этом исполнительная система сама
заботится о деталях реализации (разбиение входных данных
на части, разделение задач по узлам кластера, обработка
сбоев и сообщение между распределенными
компьютерами). Благодаря этому программисты могут легко
и эффективно использовать ресурсы распределённых Big
Data систем.
120.
Технология практически универсальна: она можетиспользоваться для индексации веб-контента, подсчета слов
в большом файле, счётчиков частоты обращений к
заданному адресу, вычисления объём всех веб-страниц с
каждого URL-адреса конкретного хост-узла, создания списка
всех адресов с необходимыми данными и прочих задач
обработки огромных массивов распределенной
информации. Также к областям применения MapReduce
относится распределённый поиск и сортировка данных,
обращение графа веб-ссылок, обработка статистики логов
сети, построение инвертированных индексов, кластеризация
документов, машинное обучение и статистический
машинный перевод. Также MapReduce адаптирована под
многопроцессорные системы, добровольные
вычислительные, динамические облачные и мобильные
среды.
121. Синтаксический анализ посредством map/reduce
• CouchDB, Couchbase, MarkLogic, MongoDB, eXistmap/reduce ― это практический метод синтаксического анализа и обработки
больших объемов данных независимо от того, хранится ли исходная информация
в подходящей базе данных
122. Графовые БД
Гра́фовая база данных — разновидность баз данных среализацией сетевой модели в виде графа и его обобщений.
Анализ социальных сетей: графы могут быть использованы
для анализа структуры социальных сетей, выявления
сообществ, ключевых участников и влиятельных
пользователей.
Рекомендательные системы: графы могут быть
использованы для создания рекомендательных систем,
основанных на предпочтениях пользователей, истории
просмотров и сходстве продуктов.
Анализ связей между данными: графы могут быть
использованы для анализа связей между различными
типами данных, такими как текстовые документы,
изображения или аудиофайлы.
123. Инструменты и языки запросов для работы с графовыми базами данных
Для работы с графовыми базами данных существует множествоинструментов и языков запросов. Некоторые из них включают:
Neo4j: популярная графовая база данных с открытым исходным кодом,
которая предлагает мощный язык запросов — Cypher.
Amazon Neptune: управляемая графовая база данных, созданная Amazon
Web Services, поддерживает языки запросов Gremlin и SPARQL.
OrientDB: многофункциональная база данных с поддержкой графов,
документов и объектов, использует язык запросов SQL-подобный язык.
ArangoDB: гибкая база данных с поддержкой графов, документов и ключзначение, использует язык запросов AQL.
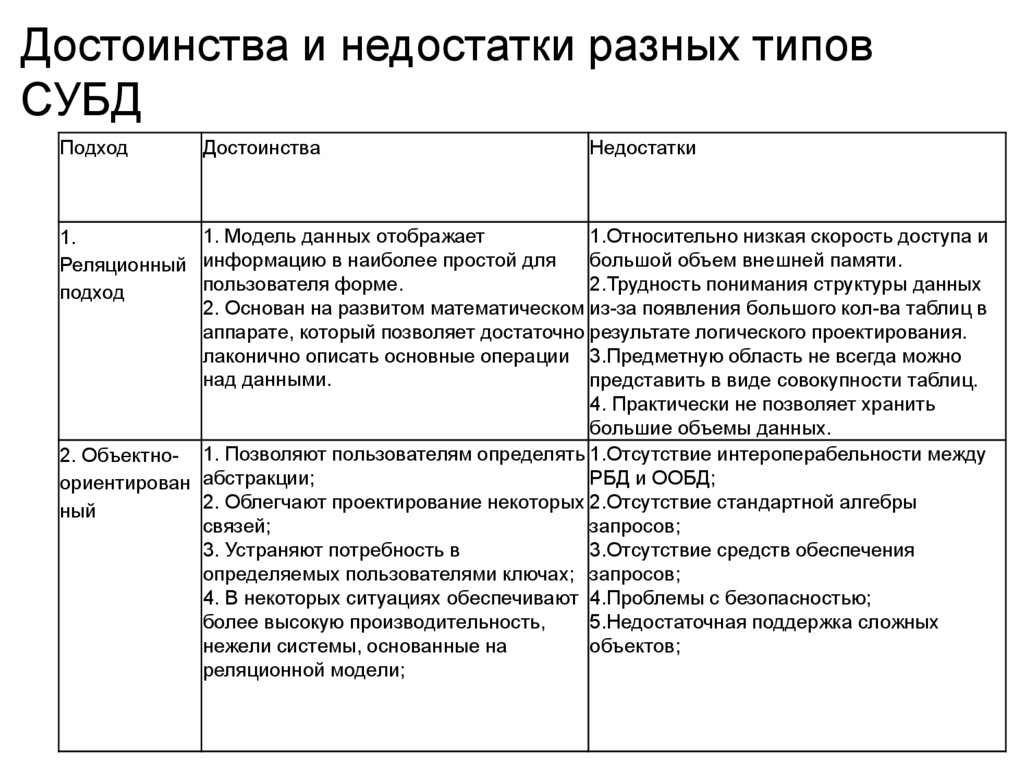
124.
Достоинства и недостатки разных типовСУБД
Подход
Достоинства
Недостатки
1. Модель данных отображает
1.Относительно низкая скорость доступа и
1.
большой объем внешней памяти.
Реляционный информацию в наиболее простой для
пользователя форме.
2.Трудность понимания структуры данных
подход
2. Основан на развитом математическом из-за появления большого кол-ва таблиц в
аппарате, который позволяет достаточно результате логического проектирования.
лаконично описать основные операции 3.Предметную область не всегда можно
над данными.
представить в виде совокупности таблиц.
4. Практически не позволяет хранить
большие объемы данных.
2. Объектно- 1. Позволяют пользователям определять 1.Отсутствие интероперабельности между
РБД и ООБД;
ориентирован абстракции;
2. Облегчают проектирование некоторых 2.Отсутствие стандартной алгебры
ный
связей;
запросов;
3. Устраняют потребность в
3.Отсутствие средств обеспечения
определяемых пользователями ключах; запросов;
4. В некоторых ситуациях обеспечивают 4.Проблемы с безопасностью;
более высокую производительность,
5.Недостаточная поддержка сложных
нежели системы, основанные на
объектов;
реляционной модели;
125.
3. Документо- 1. В сравнении с реляционными базами 1. Отсутствие транзакционной логики иориентирован данных лучшая производительность при контроля целостности в большинстве
ный
индексировании больших объёмов
реализаций: необходимо реализовывать
данных и большим количестве запросов её в логике приложения. (Хотя
на чтение.
специализированная логика может
оказаться эффективнее, общих
2. Легче масштабируются в сравнении с
алгоритмов реляционных ДБ)
SQL решениями
2. Для обработки данных необходимо
3. Легко менять "схему" данных: не
использование дополнительного языка
нужно выполнять никаких операций
программирования.
обновления для добавления новых
полей.
3.Система MongoDB допускает
максимальный размер БД всего 2 Гб на
4. Нет проблем с хранением
32-битных системах.
неструктурированных данных.
5. Единое место хранения всей
информации об объекте: меньше
операций вида "join".
6. Простой интерфейс общения с БД
126. Применение
Реляционныйподход
Данные легко представить в виде таблиц, они составляют
несколько отдельных сущностей. Вам требуются в большей
степени нетривиальные выборки. Вам не особо важна
зависимость скорости работы программы от количества данных и
сложности запроса, не нужно много онлайн-транзакций.
ОбъектноВы работаете с данными, среди которых одни данные наследуют
ориентированный свойства от других или обладают строго индивидуальными
свойствами.
ДокументоОсновными данными являются документы, Вам важна скорость
ориентированный работы программы и очень тяжело отсортировать данные по
таблицам и сущностям. Вам нужны быстрые онлайн-транзакции.
Вам нужны связи один-к-одному или многие-ко-многим и Вы не
хотите их убирать.
127. Многомерная модель данных
128. Многомерные хранилища данных
Основное назначение многомерных хранилищ данных (МХД) —поддержка систем, ориентированных на аналитическую обработку
данных, поскольку такие хранилища лучше справляются с
выполнением сложных нерегламентированных запросов.
Многомерная модель данных, лежащая в основе построения
многомерных хранилищ данных, опирается на концепцию
многомерных кубов, или гиперкубов. Они представляют собой
упорядоченные многомерные массивы, которые также часто
называют OLAP-кубами (аббревиатура OLAP расшифровывается как
On-Line Analytical Processing — оперативная аналитическая
обработка). Технология OLAP представляет собой методику
оперативного извлечения нужной информации из больших массивов
данных и формирования соответствующих отчетов.
129. Сущность многомерного представления
Сущность многомерного представления данных состоит в следующем.Большинство реальных бизнес-процессов описывается множеством
показателей, свойств, атрибутов и т.д. Например, для описания процесса
продаж могут понадобиться сведения о наименованиях товаров или их
групп, о поставщике и покупателе, о городе, где производились продажи,
а также о ценах, количествах проданных товаров и общих суммах. Кроме
того, для отслеживания процесса во времени должен быть введен в
рассмотрение такой атрибут, как дата. Если собрать всю эту информацию
в таблицу, то она окажется сложной для визуального анализа и
осмысления. Более того, она может оказаться избыточной.
Геометрическая аналогия.
Примерно то же самое можно сказать об информации, представленной
несколькими рядами данных. Каждый такой ряд (поле таблицы) можно
рассматривать как своего рода информационное измерение, и тогда
«плоская» таблица может быть интерпретирована как результат
преобразования многомерной информационной структуры в
совершенно несвойственную ей плоскую форму.
130. Многомерное представление данных
Измерения — это категориальные атрибуты, наименования и свойстваобъектов, участвующих в некотором бизнес-процессе. Значениями измерений
являются наименования товаров, названия фирм-поставщиков и покупателей,
ФИО людей, названия городов и т.д. Измерения могут быть и числовыми, если
какой-либо категории (например, наименованию товара) соответствует
числовой код. Они дискретны.
Факты — это данные, количественно описывающие бизнес-процесс,
непрерывные по своему характеру, то есть они могут принимать бесконечное
множество значений. Примеры фактов — цена товара или изделия, их
количество, сумма продаж или закупок, зарплата сотрудников, сумма кредита,
страховое вознаграждение и т.д.
Многомерный куб можно рассматривать как систему координат, осями
которой являются измерения, например Дата, Товар, Покупатель. По осям
будут откладываться значения измерений — даты, наименования товаров,
названия фирм-покупателей, ФИО физических лиц и т.д. В такой системе
каждому набору значений измерений (например, «дата — товар —
покупатель») будет соответствовать ячейка, в которой можно разместить
числовые показатели (то есть факты), связанные с данным набором. Таким
образом, между объектами бизнес-процесса и их числовыми
характеристиками будет установлена однозначная связь.
131.
132.
133.
134.
135. Преимущества многомерного подхода
Представление данных в виде многомерных кубов более наглядно,чем совокупность нормализованных таблиц реляционной модели,
структуру которой представляет только администратор БД.
Возможности построения аналитических запросов к системе,
использующей МХД, более широки.
В некоторых случаях использование многомерной модели позволяет
значительно уменьшить продолжительность поиска в МХД,
обеспечивая выполнение аналитических запросов практически в
режиме реального времени. Это связано с тем, что агрегированные
данные вычисляются предварительно и хранятся в многомерных
кубах вместе с детализированными, поэтому тратить время на
вычисление агрегатов при выполнении запроса уже не нужно.
136. Недостатки многомерного подхода
Для ее реализации требуется больший объем памяти. Это связано стем, что при реализации физической многомерности используется
большое количество технической информации, поэтому объем
данных, который может поддерживаться МХД, обычно не превышает
нескольких десятков гигабайт.
Кроме того, многомерная структура труднее поддается модификации;
при необходимости встроить еще одно измерение требуется
выполнить физическую перестройку всего многомерного куба.
На основании этого можно сделать вывод, что применение систем
хранения, в основе которых лежит многомерное представление
данных, целесообразно только в тех случаях, когда объем
используемых данных сравнительно невелик, а сама многомерная
модель имеет стабильный набор измерений.
137. Реляционные базы данных
138.
ПКСТУДЕНТ
СТУДЕНТ-ПРЕДМЕТ
ВК
ВК
Составной ПК
ПК
ПРЕДМЕТ
139. Определение требований к операционной обстановке (нефункциональные требования)
,• где li – длина записи в i-й таблице (в
байтах),
• Ni – примерное (максимально возможное)
количество записей в i-й таблице,
• Na – количество записей в архиве i-й
таблицы
140. Расчет объема памяти
• одновременно осуществляется около 50 проектов, работанад проектом продолжается в среднем два месяца (по
0,3К);
• в компании работает 100 сотрудников (по 0,2К на каждого
сотрудника);
• издательство сотрудничает с тридцатью авторами (по
0,2К);
• в день обслуживается порядка двадцати заявок (по 0,1К);
• устаревшие данные переводятся в архив.
• Тогда объём памяти для хранения данных за первый год
примерно составит:
• Mc = 2(100*0,2+6(50*0,3)+30*0,2+250(20*0,1)) = 1232 К
141. Понятия целостности
• Целостность по существованию:потенциальный ключ отношения не может иметь
пустого значения (NULL).
каждый кортеж любого отношения должен отличатся от
любого другого кортежа этого отношения (т.е. любое
отношение должно обладать первичным ключом).
• Обеспечивается
при добавлении записей в таблицу проверяется
уникальность их первичных ключей
не позволяется изменение значений атрибутов,
входящих в первичный ключ.
142.
• Целостность по связи – определяется понятием внешнегоключа отношения:
Связи между данными отношениями описываются в
терминах функциональных зависимостей.
Для отражения функциональных зависимостей между
кортежами разных отношений используется
дублирование первичного ключа одного отношения
(родительского) в другое (дочернее). Атрибуты,
представляющие собой копии ключей родительских
отношений, называются внешними ключами.
• Обеспечивается
для каждого значения внешнего ключа,
появляющегося в дочернем отношении, в
родительском отношении должен найтись кортеж с
таким же значением первичного ключа.
143. Реляционная алгебра
• 1. Традиционные операции над множествами(модифицированные с учетом того, что их
операндами являются отношения) –
объединение, пересечение, разность
(вычитание), декартово произведение и деление.
• 2. Специальные реляционные операции –
выборка, проекция, соединение.
144. Объединение
ОбъединениеФИО
Иванов
И.И.
Сидоров
С.С.
Козлов К.К.
ФИО
Цветкова
Н.Н.
Петрова
П.П.
Козлов К.К.
ФИО
Иванов
И.И.
Сидоров
С.С.
Козлов К.К.
Цветкова
Н.Н.
Петрова
П.П.
Год
рождения
1948
1953
Должность
Зав.
кафедрой
Доцент
Кафедра
22
22
1980
Ассистент
23
Год
рождения
1965
Должность
Кафедра
Доцент
23
1953
Ст.
преподаватель
Ассистент
22
1980
23
Должность
Кафедра
Зав. кафедрой
22
1953
Доцент
22
1980
1965
Ассистент
Доцент
23
23
1953
Ст.
преподаватель
22
Год
рождения
1948
145. Разность
РазностьФИО
Должность
Кафедра
Зав. кафедрой
22
1953
Доцент
22
1980
Ассистент
23
Год
рождения
1965
Должность
Кафедра
Доцент
23
1953
Ст.
преподаватель
Ассистент
Год
рождения
Иванов И.И. 1948
Сидоров
С.С.
Козлов К.К.
ФИО
Цветкова
Н.Н.
Петрова
П.П.
Козлов К.К.
ФИО
Иванов
И.И.
Сидоров
С.С.
1980
Год
рождения
1948
1953
Должность
Зав.
кафедрой
Доцент
r
a
b
a
d
a
f
c
b
d
s
b
g
a
d
a
f
r - s
22
23
Кафедра
22
22
a
b
a
c
b
d
146. Декартово произведение
Номерстудента
11
12
13
Декартово произведение
ФИО
студента
Иванов И.И.
Петров П.П.
Сидоров С.С.
Код
Наименов
дисципли ание
ны
Д1
Математи
ка
a
b
a
d
a
f
Д2
c
b
d
r
Информа
тика
Номер ФИО
студент студента
а
Код
дисциплин Наименован
Оценка
ие
ы
b
g
a
11
Д1
Математика 5
d
a
f
Д1
Математика 3
12
13
11
12
13
Иванов
И.И.
Петров
П.П.
Сидоров
С.С.
Иванов
И.И.
Петров
П.П.
Сидоров
С.С.
s
r x s
Д1
Математика 5
a
b
a
b
g
a
Д2
Информатик 5
а
Информатик 4
а
Информатик 4
а
a
b
a
d
a
f
d
a
f
b
g
a
d
a
f
d
a
f
c
b
d
b
g
a
c
b
d
d
a
f
Д2
Д2
147. Проекция
Проекцияr
a
b
a
d
a
f
c
b
d
148.
ФИОИванов И.И.
Петров П.П.
Нестеров Н.Н.
Никитин К.К.
Номер
отдела
01
02
01
02
Номер
отдела
01
02
03
Должность
Инженер
Инженер
Инженер
Лаборант
Должность
Инженер
Инженер
Лаборант
149. Выборка
150.
НомерФИО
студента студента
Код
дисциплины Наименование Оценка
11
Иванов И.И. Д1
Математика
5
12
Петров П.П. Д1
Математика
3
13
Сидоров С.С. Д1
Математика
5
11
Иванов И.И. Д2
Информатика 5
12
Петров П.П. Д2
Информатика 4
13
Сидоров С.С. Д2
Информатика 4
выбрать студентов, сдавших математику
на отлично (Код дисциплины =
Д1)AND (Оценка = 5)
Код
Номер
студента
11
13
ФИО
студента
Наимено
дисципл
вание
ины
Иванов
Математ
Д1
И.И.
ика
Сидоров
Математ
Д1
С.С.
ика
Оценка
5
5
151. Пересечение
ФИОГод
рождения
Должность
Кафедра
Иванов И.И.
1948
Зав. кафедрой
22
Сидоров С.С.
1953
Доцент
22
Козлов К.К.
1980
Ассистент
23
Должность
Кафедра
Доцент
23
Ст.
преподаватель
Ассистент
22
ФИО
Год
рождения
Цветкова Н.Н.
1965
Петрова П.П.
1953
Козлов К.К.
1980
ФИО
Год рождения
Должность
Кафедра
Козлов К.К.
1980
Ассистент
23
23
152. Деление
ДелениеНомер
студента
ФИО
студента
Код
дисциплины
Наименование
Оценка
11
Иванов И.И.
Д1
Математика
5
12
Петров П.П.
Д1
Математика
3
13
Сидоров С.С.
Д1
Математика
5
11
Иванов И.И.
Д2
Информатика
5
12
Петров П.П.
Д2
Информатика
4
13
Сидоров С.С.
Д2
Информатика
4
Наименование
Математика
Оценка
5
Код
дисциплин
Номер
студента
ФИО
студента
11
Иванов И.И.
Д1
Математика
5
13
Сидоров С.С.
Д1
Математика
5
ы
Наименова
ние
Оценка
153. Реляционные термины
154. Аномалии данных
КодФИО
сотрудника
Должность
Номер Наименование
отдела отдела
Квалификация
Отдел
проектирования
C, Java
Финансовый
отдел
DB2
Петров П.П. Программист 128
Отдел
проектирования
VB, Java
Системный
администрато 128
р
Отдел
проектирования
Windows, Linux
7513
Иванов И.И. Программист 128
9842
Сергеева С.С.
6651
9006
Николаев
Н.Н.
Администрато
42
р БД
избыточность данных;
· потенциальная противоречивость (аномалии).
155. Избыточность и противоречивость
• Под избыточностью понимают повторениеданных в разных строках одной таблицы
или в разных таблицах БД
• Аномалии – это проблемы, возникающие в
данных из-за дефектов проектирования БД.
• Существуют три вида аномалий: вставки,
удаления и модификации.
156. Аномалии
• Аномалии вставки проявляются при вводе данных в дефектнуютаблицу. Добавляя информацию о новом сотруднике, мы должны
добавить номер и название отдела.
• Аномалии удаления возникают при удалении данных из дефектной
схемы. Предположим, что все сотрудники отдела 128 уволились в
один и тот же день. После удаления записей этих сотрудников в БД
больше не будет ни одной записи, содержащей информацию об
отделе 128.
• Аномалии модификации возникают при изменении данных
дефектной схемы. Предположим, что отдел 128 решили
переименовать в отдел передовых технологий. Необходимо изменить
соответствующие данные о каждом сотруднике отдела. Если мы
пропустим хотя бы одну запись, возникнет аномалия модификации.
157. Нормализация БД
Эдгар Франк «Тед» Кодд (англ. Edgar Frank Codd; 23 августа1923 — 18 апреля 2003) — британский учёный, работы
которого заложили основы теории реляционных баз данных.
В 1970 издал работу «A Relational Model of Data for Large
Shared Data Banks», которая считается первой работой по
реляционной модели данных.Работая в компании IBM, он
создал реляционную модель данных. Он также внёс
существенный вклад в другие области информатики.
В 1976 Кодд получил почетное звание IBM Fellow. В 1981 он
получил премию Тьюринга.
В 2002 журнал Forbes поместил реляционную модель данных
в список важнейших инноваций последних 85 лет.
158. Зависимости· функциональные; многозначные; транзитивные
• Атрибут В функционально зависит от атрибута А, если каждомузначению А соответствует в точности одно значение В.
• Если атрибут А зависит от атрибута В, а атрибут В зависит от атрибута С
(С ’ В ’ А), но обратная зависимость отсутствует, то зависимость А от С
называется транзитивной.
• Говорят, что один атрибут отношения многозначно определяет другой
атрибут того же отношения, если для каждого значения первого
атрибута существует множество соответствующих значений второго
атрибута. Многозначные зависимости могут быть:
• один-ко-многим (1:М);
• многие-к-одному (М:1);
• многие-ко-многим (М:М).
159. Определения
• Нормальная форма – свойство отношения в реляционноймодели данных, характеризующее его с точки зрения
избыточности, которая потенциально может привести к
логически ошибочным результатам выборки или
изменения данных.
• Нормализация – это процесс преобразования отношений
базы данных к виду, отвечающему нормальным формам.
Нормализация предназначена для приведения структуры
БД к виду, обеспечивающему минимальную логическую
избыточность
160. Нормальные формы
• первая нормальная форма (1НФ);• вторая нормальная форма (2НФ);
• третья нормальная форма (3НФ);
• усиленная 3НФ или нормальная форма
Бойса-Кодда (БКНФ);
• четвертая нормальная форма (4НФ);
• пятая нормальная форма (5НФ).
161. 1 НФ
• Первая нормальная форма(1NF). Таблицанаходится в первой нормальной форме только
тогда, когда в любом допустимом значении
отношения каждый его кортеж содержит только
одно значение для каждого из атрибутов.
• Таблица находится в первой нормальной форме,
когда каждый ее атрибут атомарен. т.е. столбец
может содержать одно и только одно значение
для заданной строки.
162. 1НФ
• Каждая строка в таблице обязана содержатьодинаковое количество столбцов
• Каждый столбец в строке должен быть строго
типизирован
• Каждая строка должна иметь независимый
первичный ключ. Нежелательно использовать в
роли первичного ключа атрибуты внешнего мира,
такие как ФИО сотрудника, наименование города
и т.д. Лучше – номер цифровой
последовательности
163.
Кодсотрудника
ФИО
Должность
7513
Иванов И.И.
9842
Сергеева С.С.
6651
Петров П.П.
9006
Николаев Н.Н.
Код
ФИО
сотрудника
Номер
отдела
Наименование отдела
Квалификация
Программист 128
Отдел проектирования
C, Java
Администрато
42
р БД
Финансовый отдел
DB2
Отдел проектирования
VB, Java
Отдел проектирования
Windows, Linux
Наименование
отдела
Квалификация
Программист 128
Системный
администрато 128
р
Должность
Номер
отдела
7513
Иванов И.И.
Программист128
Отдел проектирования
C
7513
Иванов И.И.
Программист128
Отдел проектирования
Java
9842
Сергеева С.С.
Администрат
42
ор БД
Финансовый отдел
DB2
6651
Петров П.П.
Программист128
Отдел проектирования
VB
6651
Петров П.П.
Программист128
Отдел проектирования
Java
Отдел проектирования
Windows
Отдел проектирования
Linux
9006
Николаев Н.Н.
9006
Николаев Н.Н.
Системный
администрат 128
ор
Системный
администрат 128
ор
164. Другой пример нормализации
ФИОДругой пример нормализации
Табельный номер Паспортные
данные
Город проживания
Дети сотрудника
Иванов Е. Г.
00001
9207 045345
Воронеж
Петрова Елена
Николаевна
00002
9207 45645
Воронеж
Иванова Татьяна
13.06.2009Иванов Михаил
20/03/10
Наталья Федоровна
Хлебникова Ольга 00003
Александровна
9143 567897
Москва
PK_ Фамили Имя Отчество
ИД я
Табель Сери Номер Город
Дата
Фамил Имя Отчеств
ный я
паспор прожива рожден ия
Ребен о
номер пасп та
ния
ия
ребенк ка
Ребенка
орта
ребенк а
а
00001 9207 045345 Воронеж 13.06.2 Иванов Татьян
009
а
а
00001 9207 045345 Воронеж 20.03.2 Иванов Михаи
010
л
00002 9207 45645 Воронеж
Наталь Федоро
я
вна
1
Иванов Егор Григорьевич
2
Иванов Егор Григорьевич
3
Петрова Елен Николаевна
а
4
Хлебник Ольг Александровн 00003 9143 567897 Москва
ова
а
а
165. 2 НФ
• Таблица находится во второй нормальной форме,ели она находится в первой нормальной форме и
при этом любой ее атрибут, не входящий в состав
первичного ключа, функционально полно зависит
от первичного ключа. Функционально полно
означает, что атрибут зависит от всего первичного
ключа, но не зависит от его какой-либо части.
166. Несоответствие 2НФ
• Код сотрудника, Квалификация ’ ФИО,Должность, Номер отдела, Наименование
отдела
• Код сотрудника ’ ФИО, Должность, Номер
отдела, Наименование отдела
Код сотрудника, Квалификация – первичный
составной ключ
Код сотрудника – часть первичного ключа
167.
КодФИО
сотрудника
Должность
Номер Наименование
отдела отдела
Квалификация
7513
Иванов И.И.
Программист
128
Отдел проектирования C
7513
Иванов И.И.
Программист
128
Отдел проектирования Java
9842
Сергеева С.С.
Администратор
42
БД
Финансовый отдел
6651
Петров П.П.
Программист
128
Отдел проектирования VB
6651
Петров П.П.
Программист
128
Отдел проектирования Java
9006
Николаев Н.Н.
9006
Николаев Н.Н.
Код
сотрудник ФИО
а
Системный
128
администратор
Системный
128
администратор
Должность
Программист
Отдел проектирования Windows
Отдел проектирования Linux
Номер Наименование
отдела отдела
7513
Иванов И.И.
128
9842
Сергеева С.С. Администратор БД 42
6651
Петров П.П.
Программист
128
9006
Николаев Н.Н.
Системный
администратор
128
DB2
Отдел
проектирования
Финансовый
отдел
Отдел
проектирования
Отдел
проектирования
Код
сотрудника
7513
7513
9842
6651
6651
9006
9006
Квалификация
C
Java
DB2
VB
Java
Windows
Linux
168. Еще пример не 2НФ
Исходное отношение• R = { ’Название группы’, ’Название СД-диска’, ’Название песни’,
'Автор слов’, ’Композитор’ }
Одна и та же песня может входить в несколько дисков, также теоретически возможны
одноименные альбомы с одноименными песнями у разных групп. При этом атрибуты
’Автор слов’ и ’Композитор’ зависят от множества атрибутов { ’Название группы’,
’Название песни’ }. Это и есть нарушение 2NF.
Следствием такой модели есть избыточность хранения значений атрибутов ’Автор слов’ и
’Композитор’ для каждого СД-диска в который входит песня.
Другим следствием есть то, что песни, которые еще не выпущены на СД-дисках, а просто
транслированы по радио или выпущены на других носителях, не подходят под указанную
схему данных. Соответственно мы не сможем добавить новую песню в базу данных пока
она не будет выпущена на СД. Это пример аномалии вставки.
Аналогично если мы захотим удалить какой-либо диск из базы данных, мы будем
вынуждены потерять информацию об авторах и композиторах всех песен, которые входят
только в этот диск, поскольку в данной модели нет возможности представить
информацию об авторе и композиторе, если песня не входит в какой-либо СД. Это пример
аномалии удаления.
169. Приведение к 2НФ
• R1 = { ’Название группы’, ’Название СД’,’Название песни’ }
• R2 = { ’Название группы’, ’Название песни’,
’Автор’, ’Композитор’ }
Обе схемы имеют 2NF, R1 — поскольку у нее нет
неключевых атрибутов, а R2 — поскольку ’Автор’ и
’Композитор’ зависят от ключа { ’Название группы’,
’Название песни’ } и не зависят (функционально) от
любого из атрибутов 'Название группы’ или
’Название песни’.
170. 2НФ
• Таблицы должна соответствовать первойнормальной форме.
• Определите главную таблицу по правилам
отношения «один ко многим»,
• В зависимой таблице добавьте внешний
ключ.
171. Цели приведения к 2НФ
1.Главной целью приведения ко второй нормальной форме есть
желание избавиться от избыточности хранения данных и как следствие
избежать аномалий модификации этих данных (аномалий изменения,
вставки и удаления)
2.
Второй по порядку, но не по значению, целью нормализации в
2NF есть максимально разбить модель данных на отдельные отношения,
чтобы их можно было комбинировать и использовать в выражениях
новыми, не предусмотренными изначально способами.
3.
Минимизировать усилия по изменению схемы в случае
необходимости. Чем меньше зависимостей внутри схемы, тем меньше
изменений в ней потребуется при изменении модели данных.
4.
Понятность схемы для пользователя. Чем держать все данные в
одной большой таблице, проще представить данные как несколько
связанных и логически разделенных отношений. Это проще читать,
воспринимать, проектировать и поддерживать.
172. 3-НФ
Отношение находится в третьей нормальной форме (ЗНФ), если ононаходится во 2НФ и ни один из его неключевых атрибутов не связан
функциональной зависимостью с любым другим неключевым атрибутом.
Код
сотрудника
ФИО
Должность
Номер Наименование
отдела отдела
7513
Иванов И.И.
Программист
128
Отдел
проектирования
9842
Сергеева С.С. Администратор БД
42
Финансовый отдел
6651
Петров П.П.
128
Отдел
проектирования
9006
НиколаевСистемный
Н.Н.
администратор
128
Отдел
проектирования
Код
сотрудника
7513
9842
6651
9006
ФИО
Иванов И.И.
Сергеева
С.С.
Петров П.П.
Программист
Должность
Программист
Администратор БД
Программист
Системный
Николаев Н.Н.
администратор
Номер
отдела
128
42
128
128
Номер Наименование
отдела отдела
42
Финансовый отдел
128
Отдел проектирования
173. 3НФ
• Таблицы должны соответствовать второйнормальной форме.
• В зависимой таблице внешний ключ должен быть
not null.
• Все поля стремятся быть not null
• Избавиться от избыточной информации,
содержащейся в не ключевых столбцах. Другими
словами неключевая информация должна
храниться только в одной таблице в одном поле
174. Схема нормализации
175. Физические модели данных (внутренний уровень)
176. Схема работы ЭВМ
177.
Основные свойства оперативной памяти:• единицей памяти является байт;
• память прямоадресуема (каждый байт имеет адрес);
• процессор выбирает для обработки нужные данные,
непосредственно адресуясь к последовательности байтов,
содержащих эти данные.
Основные свойства внешней памяти:
• минимальной адресуемой единицей является физическая запись ;
• для последующей обработки (например, работы с полями) запись
должна быть считана в оперативную память;
• время чтения записи в ОП на несколько порядков выше времени
обработки процессором записи из ОП;
• организация обмена осуществляется порциями, т.к. невозможно
считать сразу всю базу данных.
178. Представление экземпляра логической записи
Логическая записьПоле 1 Поле 2 ...
Тип поля
Характеристика поля
Поле
N
Последовательность байтов
ОП
B1
B2
...
BN
Bi – последовательность
байтов ОП, используемая для
хранения поля i
Длина
Представление не делает различий для записей в сетевой,
иерархической и реляционных моделях.
В большинстве современных СУБД используется формат записей
фиксированной длины. В этом случае все записи имеют
одинаковую длину, определяемую суммарной длиной полей,
составляющих запись.
179. Представление полей переменной длины
Вместо поля (полей), принимающего значение существенно разной длины, взапись включается поле-указатель на область памяти, где будет
размещаться значение исходного поля. Как правило, эта область является
областью внешней памяти прямого доступа. В процессе ввода
соответствующего значения в выделенной области занимается столько
памяти, какова длина этого значения.
Пример: поле типа МЕМО в СУБД Access.
180. Организация обмена между оперативной и внешней памятью
181.
Ввод исходных данных в БД :• в ОП последовательно вводятся k экземпляров логических
записей (кортежей);
• введенные k экземпляров объединяются в физическую
запись (блок);
• физическая запись заносится во внешнюю память.
Обработка данных, хранящихся во внешней памяти:
• физическая запись (блок) считывается в оперативную
память;
• обрабатываются экземпляры логических записей внутри
блока (выбираются нужные поля, производится сравнение
ключевого поля с заданным значением, осуществляется
корректировка полей, выполняются операции удаления и
т.п.).
182. Структуры хранения данных во внешней памяти ЭВМ
• Последовательное размещениефизических записей
Количество физических записей
I –номер физической записи, содержащей k логических записей
183.
Логические записиj+1
j+2
j+k
Физические записи
1
2
i
184. Поиск записи с заданным значением ключа
• Читается первая физическая запись, в ОП она разбиваетсяна k логических записей (разблокируется),
• заданное значение ключа сравнивается со значением ключа каждой
логической записи.
• при несовпадении читается следующая физическая запись и процесс
повторяется.
где N – число логических записей, k – коэффициент
блокировки,
число физических записей.
Чтение записи с заданным значением ключа
Сначала необходимо найти нужную запись (смотри операцию "поиск").
После окончания операции "поиск" нужная запись уже считана в ОП.
Число обращений к ВП равно ТР.
185.
• Корректировка записи• Сначала необходимо найти нужную запись (смотри
операцию "поиск"). После окончания операции "поиск" в
ОП найденная логическая запись корректируется,
формируется физическая запись (блок) и заносится во
внешнюю память по тому адресу, откуда она была
считана. Число обращений к ВП равно ТР+1.
• Удаление записи
• Аналогична операции корректировки. Служебное поле
соответствующей логической записи помечается как
"удаленная запись". Число обращений к ВП равно ТР+1.
186. Добавление записи
1. Пользователь вводит новую логическую запись в конецтаблицы
Число обращений к ВП равно соответственно либо 2, либо
1.
Рассмотрим два случая.
В первом случае пользователь вводит новую логическую
запись в конец таблицы. Тогда вводимая логическая
запись добавляется в конец файла. Она заносится либо в
последнюю физическую запись (если в ней меньше k
логических записей – блок неполон), для чего эта запись
должна быть считана в ОП, или формируется новая
физическая запись, которая заносится в конец файла.
Число обращений к ВП равно соответственно либо 2, либо
1.
187. 2. Пользователь вводит новую логическую запись в указываемую им i-ю строку таблицы
2. Пользователь вводит новую логическую запись вуказываемую им i-ю строку таблицы
Если соответствующая физическая запись содержит пустые
логические записи:
читается физическая запись с номером ,
содержащая i-ю логическую запись,
добавляемая запись вставляется в этот блок, блок записывается
на свое место в ВП. Число обращений к ВП равно 2
Если указанная физическая запись содержит k экземпляров
логических записей исходной таблицы, читается физическая
запись с номером . Если эта физическая запись содержит
пустые логические записи, добавляемая запись вставляется в
этот блок, блок записывается на свое место в ВП. Суммарное
число обращений в этом случае будет на единицу больше и
равно 3.
188.
Если физические записи с номерами
и
содержат
по k экземпляров исходных логических записей, необходимо формировать
дополнительную физическую запись. Соответствующий блок будет содержать
добавляемую логическую запись и k-1 пустых логических записей. Блоки с
номерами
переписываются на одну позицию
ниже (сдвигаются). Сформированная физическая запись заносится на
освободившееся место (место записи с номером
).
В лучшем случае (i = N) ни один блок не сдвигается. В худшем случае (i =
1) сдвигаются все блоки. Среднее число обращений к ВП для перезаписи
блоков (чтение + запись) составит
.
Тогда суммарное число
обращений к ВП при добавлении записи в этом случае будет равно
.
Заметим, что если записи упорядочены по значениям ключа поиск может
производиться дихотомическим методом и число обращений к внешней
памяти будет пропорционально не
а
т.е.
существенно меньше. Однако добавление записи потребует для сохранения
упорядоченности, как правило, сдвига большого числа записей. Поэтому
размещение физических записей с упорядочением их по значениям ключа в
СУБД не используется.
189. Размещение физических записей в виде списковой структуры
Список физических записейкаждая физическая запись состоит, как и ранее, из k логических записей
Список свободных элементов
190.
• Поиск записи с заданным значениемключа
Чтение записи Оценка числа обращений к ВП та же. .
Поэтому поиск можно вести только с помощью перебора. В
ОП читается первая запись списка, разблокируется, значения
ключевых полей логических записей этой физической записи
сравниваются с заданным значением. Если значения совпали,
нужная запись найдена, если не совпали, из записи
выбирается адрес следующей записи списка, читается эта
запись. Далее процедура повторяется.
• Корректировка записи
Считанная запись корректируется и заносится в ВП на свое место
(по своему адресу). Число обращений к ВП на единицу больше,
чем при чтении.
191.
Удаление записиЗаметим, что мы говорим об операциях над
логическими записями. Операция удаления логической
записи аналогична операции корректировки. Служебное
поле соответствующей логической записи помечается
как "удаленная запись". Сформированная физическая
запись заносится в ВП. Число обращений к ВП
равно ТР+1.
Добавление записи
Для определенности будем считать, что задан ключ
логической записи, после которой должна быть
добавлена новая запись. Осуществляется операция
поиска и чтения физической записи, в которой
расположена запись с ключом РК. Если в этом блоке
естьлогическая запись, помеченная как удаленная,
добавляемая запись заносится на ее место. Блок
записывается в ВП. Число обращений к ВП равно ТР+1
192.
Если в этом блоке нет логических записей, помеченныхкак удаленные, необходимо добавлять
новую физическую запись, выбираемую из списка
свободных элементов. С этой целью адрес связи
найденной ранее физической записи заменяется на
адрес начала списка свободных элементов.
Читается первая физическая запись списка свободных
элементов. Адрес связи этой записи заменяет адрес
начала пустого списка. В ОП формируется
новая физическая запись, содержащая
добавляемую логическую запись. В качестве ее адреса
связи заносится адрес связи из физической записи,
предшествующей добавляемой. Каждая из этих записей
заносится в ВП. Число обращений к ВП при добавлении
записи будет примерно равно ТР+3.
193. Использование индексов (индексирование)
k=1Поиск нужной записи по заданному значению ключа осуществляется в
индексном файле методом половинного деления. Заметим, что так как записи
индекса содержат всего два поля, суммарный объем записей индекса невелик,
поэтому индекс, как правило, целиком считывается для обработки в ОП за одно
обращение к ВП. После того как в индексном файле обнаружена искомая
запись, по адресу связи читается полная соответствующая запись основной
структуры хранения. Если необходим поиск по другому ключу, строится еще
один индекс по соответствующему ключу. Таким образом, по любому ключу
поиск можно осуществлять дихотомическим методом.
194. Метафора индексирования
Метафора индексирования
Помещение библиотеки— это таблица в базе данных. Книги хранятся на
пронумерованных стеллажах с пронумерованными полками. Если чуть проще, то
любое скопище однотипных данных (тех же книг), по сути, представляет собой
таблицу.
Поиск книги — это sql-запросы получения данных. При этом важно отметить, что
сами по себе они не меняются. То есть вам как нужно было найти
«Термодинамику», так и осталось нужным найти «Термодинамику». Другое дело,
как вы будете это осуществлять — прочесывая тысячи книг или открыв каталог.
Каталог — это и есть упрощенный вариант индекса в базе данных. То есть, индекс
это набор дополнительных данных, записанных в удобном виде, который
позволяет существенно быстрее осуществлять поиск, хоть и требующий
дополнительных усилий для поддерживания его актуальности. В карточке каталога
записан стеллаж и полка, где хранится книга или несколько книг.
Имя книги (страничка) — это ключ в индексе. То уникальное значение, которое
может ссылаться как на одну какую-то запись, так и на несколько. Стоит отметить,
что даже если записей для каждого значения будет несколько, это все равно
быстрее, чем полный перебор всех данных.
Карточки также упорядочены по названиям, фамилиям авторов, тематике
195.
Когда атрибут или набор атрибутов помечаетсякак ключ, дополнительно создается индекс.
Индекс хранит список значений ключа и
указатели на кортежи, содержащие эти
значения. Наличие индекса позволяет системе
управления базами данных быстро находить
нужные кортежи. В целом индексы ускоряют
выполнение операций чтения, но замедляют
выполнение операций записи, так как при этом
необходимо обновлять индекс.
196. Типы индексов
197. Первичная индексация
Первичный индекс — это упорядоченный файл сфиксированной длиной и двумя полями. Первое поле — это
тот же первичный ключ, а второе поле указывает на этот
конкретный блок данных. В первичном индексе всегда
существует отношение один к одному между записями в
таблице индекса.
Первичная индексация также делится на два типа.
• Плотный индекс
• Разреженный индекс
198. Плотный индекс
В плотном индексе записьсоздается для каждого поискового
ключа, оцененного в базе
данных. Это помогает быстрее
выполнять поиск, но требует
больше места для хранения
записей индекса. В этом
индексировании записи метода
содержат значение ключа поиска и
указывают на реальную запись на
диске
199. Разреженный индекс
Это индексная запись, котораяотображается только для некоторых
значений в файле. Разреженный
индекс поможет вам решить
проблемы плотного индексирования.
В этом методе методики
индексирования диапазон столбцов
индекса хранит один и тот же адрес
блока данных, и когда данные
должны быть извлечены, адрес блока
будет выбран.
Однако разреженный индекс хранит
записи индекса только для некоторых
значений ключа поиска. Ему требуется
меньше места, меньше затрат на
обслуживание для вставки и
удаления, но он медленнее по
сравнению с плотным индексом для
поиска записей.
200. Вторичный индекс
может быть создан с помощьюполя, которое имеет
уникальное значение для
каждой записи, и это должен
быть ключ-кандидат. Он также
известен как
некластеризованный индекс.
Этот двухуровневый метод
индексации базы данных
используется для уменьшения
размера отображения первого
уровня. Для первого уровня изза этого выбирается большой
диапазон чисел; размер
отображения всегда остается
небольшим.
201. Индекс кластеризации
В кластеризованном индексе сами записи хранятся виндексе, а не в указателях. Иногда индекс создается для
столбцов не первичного ключа, которые могут быть не
уникальными для каждой записи. В такой ситуации вы
можете сгруппировать два или более столбцов, чтобы
получить уникальные значения и создать индекс, который
называется кластеризованным индексом. Это также поможет
вам быстрее идентифицировать запись.
202. Многоуровневое индексирование
создается, когдапервичный индекс не
помещается в памяти. В
этом методе индексации
вы можете сократить
число обращений к диску,
чтобы сократить любую
запись и сохранить ее на
диске в виде
последовательного файла,
а также создать
разреженную базу для
этого файла.
203.
• Поиск записи с заданным значением ключаодно обращение к ВП.
• Чтение записи
В ходе операции поиска искомая запись считана в ОП.
• Корректировка записи
Считанная запись корректируется и заносится на свое место (еще
одно обращение к ВП).
• Удаление записи
Число обращений к ВП в этом случае по сравнению с числом
обращений к ВП при поиске увеличивается на два.
• Добавление записи
Добавляемая запись заносится в конец основного файла.
Формируется новая запись индекса, соответствующая
добавляемой записи. Записи индекса переупорядочиваются по
значениям ключа, и индекс заносится в ВП. Число обращений к
ВП в этом случае, в основном, определяется чтением-записью
индекса.
204. В-дерево, многоуровневые индексы
• Последовательность записей, соответствующая записям исходнойтаблицы, упорядочивается по значениям первичного ключа.
• Логические записи объединяются в блоки (по k записей в блоках).
• Значением ключа блока является минимальное значение ключа у
записей, входящих в блок. Последовательность блоков представляет
собой последний уровень В-дерева.
• Строится индекс предыдущего уровня. Записи этого уровня содержат
значение ключа блока следующего уровня и указатель-адрес связи
соответствующего блока; записи этого уровня также объединяются в
блоки (по k записей).
• Затем аналогично строится индекс более высокого уровня и т.д., пока
количество записей индекса на определенном уровне будет не
более k.
205. Пример
• файл экземпляров логических записей, ключи которыхпринимают значения 2, 7, 8, 12, 15, 27, 28, 40, 43,
50. k=2 (в блок объединяем по 2 экземпляра записей).
В-дерево
на уровне 4 представлены только ключи логических
записей и не представлены значения других полей этих
записей
206. Реализация основных операций.
Поиск и чтение записи с заданным значением ключа• Читается верхний индекс. Сравниваем заданное значение ключа со
значением ключа последней записи индекса. Если заданное значение
ключа больше, чем значение ключа очередной записи индекса (если
такая запись имеется), или равно ему, то по адресу связи, указанному
в текущей записи, читается блок записей индекса следующего уровня.
Далее процесс повторяется.
Считаем, что все блоки расположены в ВП. Тогда число обращений к
ВП при поиске информации будет равно числу уровней дерева. Число
уровней дерева равно минимальному значению l, при котором
выполняется условие kl >= N ( N – число логических записей).
207.
Модификация (корректировка) записи• После поиска и чтения записи изменяются
корректируемые поля. Если корректируется не ключ
записи, то измененная запись заносится на свое место.
Если изменено значение ключа, то старая запись
удаляется (в соответствующем блоке появляется "пустая"
запись), а измененная запись заносится так же, как вновь
добавляемая
Удаление записи
• После поиска найденная запись удаляется (в
соответствующий блок на место этой записи заносится
"пустая" запись).
208.
Добавление записи• Прежде всего определяется, где должна быть
расположена добавляемая запись с заданным значением
ключа. Процедура поиска блока, где должна быть
расположена эта запись, аналогична вышеописанной
процедуре поиска записей с заданным значением ключа.
Если в найденном блоке низшего уровня есть "пустая"
запись, добавляемая запись заносится в этот блок (с
необходимым переупорядочением записей внутри блока).
209.
• Если в соответствующем блоке низшего уровня нет пустого места,блок делится на два блока. В первый из них заносится [k/2]записей, во
второй заносятся остальные. Значением ключа каждого из указанных
блоков будет являться, как и описано ранее, минимальное значение
ключей у записей, входящих в блок. Добавляемая запись заносится в
тот блок, значение ключа которого меньше значения ключа
добавляемой записи. Появление нового блока с новым значением
ключа обусловливает необходимость формирования
соответствующей новой записи в индексе на предыдущем уровне. Эта
запись содержит новое значение ключа нового блока и указатель на
его месторасположение. Процедура добавления такой записи
аналогична описанной выше. Находится блок предыдущего уровня,
куда должна быть помещена эта запись. Если в блоке есть пустое
место, запись добавляется в блок, если блок полон, он делится на два
блока, запись заносится в один из блоков, формируется запись
индекса предыдущего уровня и т.д.
210. Пример
Добавление записи с ключом 10
1. Сравнение на первом уровне.
2<10<43
Движение по левой ветви.
2. Сравнение на втором уровне.
2<10<15
Движение по левой ветви.
3. Сравнение на третьем уровне.
2<8<10
Движение по правой ветви.
Искомый блок
4. Блок заполнен.
Он делится на 2 блока
Сравнение 8<10<12.
Запись с ключом 10 заносится в
блок 1
Пример
211.
На низшем уровне появилась новая запись с значением ключа 12. Необходимо добавление
новой записи с ключом 12 и указателем на запись низшего уровня к индексу предыдущего
уровня.
5. Запись с ключом 12 уровня 3 должна добавляться в блок
. Блок полон, он делится
на два блока
Сравнение 8<12.
Запись добавляется во второй блок
6. На уровне 3 появился блок с новым ключом 8. Необходимо добавление новой записи с
ключом 8 и указателем на соответствующий блок уровня 3 на уровне 2.
7. Запись с ключом 8 уровня 2 должна добавиться в блок . Блок полон, он делится на два блока.
2<8<15
Запись добавляется в блок 1 .
8. На уровне 2 появился блок с новым ключом 15, необходимо добавление новой записи с
ключом 15 и указателем на соответствующий блок уровня 2 на уровне 1.
9. Запись с ключом 15 уровня 1 должна добавляться в блок
. Блок полон, он
делится на два блока.
2<15<43
Запись с ключом 15 добавляется в первый блок
10. Необходимо сформировать еще один уровень дерева .
212.
Исходное В-деревоВ-дерево после добавления элемента
213. РАЗРАБОТКА БАЗ ДАННЫХ С ПОМОЩЬЮ MICROSOFT OFFICE ACCESS
214. Создание БД
215. Создание таблиц (режим конструктора)
216. Создание таблиц (режим просмотра)
217. Работа со схемой данных
218.
• В режиме каскадного удаления связанных записей приудалении записи из главной таблицы будут автоматически
удаляться все связанные записи в подчиненных таблицах.
При удалении записи из главной таблицы выполняется
каскадное удаление подчиненных записей на всех
уровнях, если этот режим задан на каждом уровне.
• В режиме каскадного обновления связанных полей при
изменении значения ключевого поля в записи главной
таблицы Access автоматически изменит значения в
соответствующем поле в подчиненных записях.
219. Создание форм
Формы представляют собой интерфейсный элемент, который позволяетосуществлять взаимодействие между пользователем и базой данных. В
формах пользователи осуществляют навигацию, редактирование и
удаление данных.
220. Визуальное конструирование запросов
221. Разработка запросов Назначение и виды запросов
• включить в результирующую таблицу запроса заданныепользователем поля;
• выбрать записи, удовлетворяющие условиям отбора;
• произвести вычисления в каждой из полученных записей;
• сгруппировать записи, которые имеют одинаковые значения в одном
или нескольких полях, в одну запись и одновременно для других
полей образовавшихся групп выполнить одну из статистических
функций;
• произвести обновление полей в выбранном подмножестве записей;
• создать новую таблицу базы данных, используя данные из
существующих таблиц;
• удалить выбранное подмножество записей из таблицы базы данных;
• добавить выбранное подмножество записей в другую таблицу.
222. Создание запросов (конструктор)
223. Запрос на выборку в режиме просмотра
SELECT Студенты.Имя, Дисциплина.Наименование, Результат.Рейтинг,Результат.ДатаОценки, Дисциплина.Направление
FROM Студенты INNER JOIN (Дисциплина INNER JOIN Результат ON
Дисциплина.НомерДисц = Результат.НомерДисц) ON Студенты.Номер =
Результат.НомерСтуд
WHERE (((Результат.Рейтинг)>80))
ORDER BY Дисциплина.Наименование DESC;
224. Виды запросов
• запрос на выборку• запрос на создание таблицы
• запросы на обновление, добавление,
удаление —запросы действия
225. Бланк запроса
• в строку Поле (Field) включается имя поля, используемогов запросе;
• в строке Сортировка (Soft) выбирается порядок
сортировки записей результата;
• в строке Вывод на экран (Show) отмечаются поля, которые
должны быть включены в результирующую таблицу;
• в строке Условие отбора (Criteria) задаются условия
отбора записей;
• в строке или (or) задаются альтернативные условия отбора
записей
226. Условия отбора записей
• операторы сравнения (=, <, >, о, <=, >=,Between, In , Like , And, Or, Not).
• операнды:
– Литералы (числа, строковые значения, даты),
– Константы (Истина (True), Ложь (False), Null),
– идентификаторы ([Имя таблицы] ! [Имя
поля]).
227. Примеры
• Between 10 And 100• In("Математики";"Информатики";"Истории"
)
• Like "Иванов*" (ANSI-89) Like "Иванов%"
(ANSI-92)
228. Пример БД
229. Использование логических операций в условии отбора
Выбрать товары, цена которых не более1000 руб. или более 2500 руб.
230. Выбрать товары, цена которых не более 1000 руб. и НДС не более 10%, а также товары, цена которых более 2500 руб.
231. Вычисляемые поля, выражения
• сортировка,• задание условий отбора
• расчет итоговых значений.
• Выражение1: [Цена]*[Количество]
• с заголовком всего: [Цена]*[Количество]
232.
233. Функции
• Функции даты и времени• Функции обработки текста
• Функции преобразования типа данных
• Математические и тригонометрические
функции
• Финансовые функции
• Статистические функции
234.
235. Ввод параметра через диалоговое окно
236.
237. Использование групповых операций в запросах Назначение групповых операций
• sum — сумма значений некоторого поля для группы;• Avg — среднее от всех значений поля в группе;
• мах, Min — максимальное, минимальное значение поля в
группе;
• count — число значений поля в группе без учета пустых
значений;
• StDev — среднеквадратичное отклонение от среднего
значения поля в группе;
• var — дисперсия значений поля в группе;
• First и Last — значение поля из первой или последней
записи в группе.
238. Порядок создания запроса с использованием групповых операций
239.
Добавлена группировка поСРОК_ПОСТ
240. Запрос с функцией Count
241. Задание условий отбора в запросах с групповыми операциями
Суммируются операции сСуммв_Накл >10000
242.
Сравните с предыдущим243. Структурированный язык запросов SQL
244. История SQL
В начале 1970-х годов в одной из исследовательских лабораторийкомпании IBM была разработана экспериментальная
реляционная СУБДIBM System R, для которой затем был создан
специальный язык SEQUEL, позволявший относительно просто управлять
данными в этой СУБД. Аббревиатура SEQUEL расшифровывалась
как Structured English QUEry Language — «структурированный английский
язык запросов». Позже по юридическим
соображениям[4] язык SEQUEL был переименован в SQL. Когда в 1986
году первый стандарт языка SQL был принят ANSI (American National
Standards Institute), официальным произношением стало [,es kju:' el] —
эс-кью-эл. Несмотря на это, англоязычные специалисты зачастую
продолжают читать SQL как сиквел (по-русски часто говорят «эс-ку-эль»)
245. История стандартов SQL
ГодНазвание
Иное название
Изменения
Первый вариант стандарта, принятый институтом ANSI и
одобренный ISO в 1987 году.
1986
SQL-86
SQL-87
1989
SQL-89
FIPS 127-1
Немного доработанный вариант предыдущего стандарта.
1992
SQL-92
SQL2, FIPS 127-2
Значительные изменения (ISO 9075); уровень Entry
Level стандарта SQL-92 был принят как стандарт FIPS 127-2.
SQL3
Добавлена поддержка регулярных
выражений, рекурсивных запросов, поддержка триггеров,
базовые процедурные расширения, нескалярные типы
данных и некоторые объектноориентированные возможности.
1999
SQL:1999
2003
SQL:2003
Введены расширения для работы с XML-данными, оконные
функции (применяемые для работы с OLAP-базами данных),
генераторы последовательностей и основанные на них типы
данных.
2006
SQL:2006
Функциональность работы с XML-данными значительно
расширена. Появилась возможность совместно
использовать в запросах SQL и XQuery.
2008
SQL:2008
Улучшены возможности оконных функций, устранены
некоторые неоднозначности стандарта SQL:2003[7]
246. Основы языка SQL
• Язык Structured Query Language (SQL — языкструктурированных запросов; аббревиатура, произносится
примерно как "сикуэл")
• SQL — это мощный язык программирования,
ориентированный на применение в базах данных.
• Программируя в Access, для хранения информации вы
можете использовать, помимо инструментов Access, и
средства иных серверов баз данных — скажем, MS SQL
Server. SQL Server и другие "большие" системы управления
базами данных обычно размещаются на отдельных
компьютерах, гораздо более мощных и производительных
по сравнению с персональными станциями
пользователей.
247. Литература по SQL
• http://bookwebmaster.narod.ru/mysql.htmlбесплатные книги
• Мартин Грубер. Понимание SQL
• Бейли Л. Изучаем SQL. — СПб.: Питер,
2012. — 592 с.: ил.
• Бен Форта SQL 10 минут урок
248. Структура оператора SELECT
249. Использование выражения SELECT
SELECT СписокПолей FROM ИмяТаблицы• В соответствии с общепринятым
соглашением служебные слова SQL
вводятся в верхнем регистре
• SELECT и FROM — это служебные слова
250. Таблица компьютеров, в иллюстративном примере (файл ПримерыЗапросовSQL, табл. PC)
PCprice
speed
hd
ram
cd
model
code
670
600
20
256
24x
1121
600
500
20
256
48x
1234
1
700
500
30
512
52x
1333
1
850
750
40
512
50x
1456
2
450
600
10
256
50x
1782
1
920
800
160
1024
50x
2431
price – в этом столбце хранится числовая информация о стоимости компьютера,
speed – представляет собой столбец с числовой информацией о частоте работы
микропроцессора,
hd – содержит числовую информацию о размере жесткого диска,
ram – в этом столбце хранится размер оперативной памяти компьютера в
числовом виде,
cd – столбец с текстовой информацией о скорости работы CD-ROM,
model – столбец, в котором хранится уникальный код конфигурации компьютера
в числовом виде.
251. Выборка данных
Простейший оператор SELECT, осуществляющийвыборку всех строк из таблицы:
SELECT *
FROM PC
Чтобы упорядочить столбцы, их следует
перечислить через запятую:
SELECT price, speed, hd, ram, cd, model
FROM PC
252.
Запрос ВертВыборкаВертикальную выборку
таблицы РC можно
получить, если
перечислить только
необходимые столбцы
SELECT hd, ram
FROM PC
Запрос ВертВыборкаУник
Если требуется получить
уникальные строки, то можно
использовать ключевое слово
DISTINCT
SELECT DISTINCT hd, ram
FROM PC
253. Вид в конструкторе запросов
254. Предложение ORDER BY
SELECT DISTINCT hd,ram
FROM PC
ORDER BY ram DESC
SELECT speed, hd
FROM PC
ORDER BY speed
DESC, hd ASC
ЗапросУпоряд2
ЗапросУпоряд1
hd
speed
ram
hd
800
160
750
40
160
1024
30
512
600
10
40
512
600
20
10
256
500
20
20
256
500
30
255. В режиме конструктора
256. Горизонтальная выборка, предложение WHERE
Простой предикатSELECT DISTINCT hd,
ram
FROM PC
WHERE hd < 100
ORDER BY 2 DESC
Составной предикат
SELECT model, speed, hd
FROM PC
WHERE speed >= 500 AND
price < 800
ЗапросПростойПредикат
ЗапросСоставнойПредикат
hd
model
ram
speed
hd
30
512
1121
600
20
40
512
1234
500
20
10
256
1333
500
30
20
256
1782
600
10
257. В режиме конструктора
258. Переименование столбцов с помощью ключевого слова AS
SELECT ram*1024AS Kb, 'Kb' AS Size
FROM PC
WHERE cd = '50x'
ЗапросПереименование
Kb
Size
524288 Kb
262144 Kb
1048576 Kb
259. Предикат LIKE
SELECT model, speed, cdFROM PC
WHERE cd LIKE '5*'
ЗапросLIKE
model
speed
cd
1333
500 52x
1456
750 50x
1782
600 50x
2431
800 50x
260. Работа с нулевыми (NULL) значениями Оператор NULL
• Когда значение поля равно NULL, это означает, что программа базыданных специально промаркировала это поле как не имеющее
никакого значения для этой строки (или записи).
• Предположим, что вы получили нового заказчика, который еще не
был назначен продавцу. Чем ждать продавца, к которому его нужно
назначить, вы можете ввести заказчика в базу данных теперь же, так
что он не потеряется при перестановке.
• специальный оператор IS
• Ничего не выводится
261. Агрегатные функции COUNT, MIN и MAX
1. SELECTMIN(price) AS Min_price, MAX(price) AS Max_price FROM PC
2. SELECT COUNT(*) AS Qty
FROM PC
WHERE cd IN ('50x', '52x')
3. SELECT COUNT(DISTINCT cd) AS Qty
FROM PC
WHERE cd IN ('50x', '52x')
4. SELECT AVG(hd) AS Avg_hd
FROM PC
WHERE cd = '50x'
262. В режиме конструктора
SELECT Min(([price])) AS Min_price,Max(([price])) AS Max_price
FROM PC;
ЗапросАгрегатФункции
Min_price
Max_price
450
920
263. Группировка данных
SELECT ram,COUNT(ram) AS
Qty_ram, AVG(price) AS
Avg_price
FROM PC
GROUP BY ram
264. Применение предложения HAVING
SELECT ram, AVG(price) ASAvg_price
FROM PC
GROUP BY ram
HAVING ram IN (256, 512)
SELECT ram, COUNT(ram) AS
Qty_ram, AVG(price) AS
Avg_price
FROM PC
GROUP BY ram
HAVING AVG(price) > 700
Если предложение WHERE
определяет предикат для фильтрации
строк, то предложение HAVING
применяется после группировки для
определения аналогичного предиката,
фильтрующего группы по значениям
агрегатных функций.
265. Условный оператор
SELECT price, model,CASE WHEN price >= 700
THEN 'Дорого'
ELSE 'Дешево' END AS
comment
FROM PC
SELECT price, model,
IF(price >= 700, 'Дорого',
'Дешево') AS comment
FROM PC
266. Соединение таблиц
Запрос1Простое соединение (декартово произведение)
SELECT PC.model, Sale.comment
FROM PC, Sale;
model
comment
1234
продажа
1234
резерв
1234
заказ
1333
продажа
1333
резерв
1333
заказ
1456
продажа
1456
резерв
1456
заказ
1782
продажа
1782
резерв
1782
заказ
2212
продажа
2212
резерв
2212
заказ
267. Соединения строк из разных таблиц
SELECT PC.model,Sale.comment
FROM PC, Sale
WHERE
(((PC.[code])=[type]));
ЗапросСоединениеСтрок
model
comment
1234 продажа
1333 продажа
1456 резерв
1782 продажа
268. Конструктор
269. Явная операция соединения двух и более таблиц
SELECT model,comment
FROM PC inner
JOIN Sale ON
PC.code =
Sale.type
ORDER BY model;
Запрос_inner JOIN
model
comment
1234 продажа
1333 продажа
1456 резерв
1782 продажа
270. В конструкторе
271. соединение LEFT JOIN
PCSELECT model,
comment
FROM PC LEFT JOIN Sale
ON PC.code = Sale.type
ORDER BY model;
означает, что помимо
строк, для которых
выполняется условие
предиката, в
результирующий набор
попадут все остальные
строки из первой таблицы
(левой), отсутствующие
значения столбцов из
правой таблицы будут
заполнены NULLзначениями
sale
model
code
type
1121
comment
1 продажа
1234
1
2 резерв
1333
1
3 заказ
1456
2
1782
1
2431
ЗапросLEFT_JOIN
model
comment
1121
1234 продажа
1333 продажа
1456 резерв
1782 продажа
2431
272. Конструктор
273. Соединение RIGHT JOIN
PCsale
model
code
type
comment
1121
обратно соединению
LEFT JOIN, то есть в
результирующий
набор попадут все
строки из второй
таблицы
SELECT model, comment
FROM PC RIGHT JOIN
Sale ON PC.code =
Sale.type
ORDER BY model;
1 продажа
1234
1
2 резерв
1333
1
3 заказ
1456
2
1782
1
2431
Запрос_RIGHT_JOIN
model
comment
заказ
1234
продажа
1333
продажа
1456
резерв
1782
продажа
274. Конструктор
275. Переименование таблиц и полей в запросе
SELECT DISTINCT A.model ASm1, B.model AS m2
FROM PC1 AS A, PC1 AS B
WHERE ABS(A.price - B.price)
<= 100 AND A.model <
B.model
ЗапросПереимТаблСтрок
m1
m2
1121
1234
1121
1333
1234
1333
1456
2431
PC1
price
speed
hd
ram
cd
model
670
600
20
256 24x
1121
600
500
20
256 48x
1234
700
500
30
512 52x
1333
850
750
40
512 50x
1456
450
600
10
256 50x
1782
920
800
160
1024 50x
2431
276. Конструктор
277. Вложенные подзапросы
Вложенный подзапрос создан для того, чтобы при отборе строк таблицы,сформированной основным запросом, можно было использовать
данные из других таблиц
Применяются с ключевыми словами:
• В инструкции SELECT;
• В инструкции FROM;
• В условии WHERE.
Подзапрос может быть вложен в инструкции SELECT, INSERT, UPDATE или
DELETE, а также в другой подзапрос;
Подзапрос обычно добавляется в условие WHERE оператора SQL SELECT;
Можно использовать операторы сравнения, такие как >, <, или =. IN, ANY
или ALL;
Подзапрос также называется внутренним запросом. Оператор,
содержащий подзапрос, также называется внешним;
Внутренний запрос выполняется перед родительским запросом, чтобы
результаты его работы могли быть переданы внешнему.
278. Рекомендации по использованию
• Подзапрос должен быть заключен в круглые скобки;• Подзапрос должен указываться в правой части оператора
сравнения;
• Подзапросы не могут обрабатывать свои результаты,
поэтому в подзапрос не может быть добавлено условие
ORDER BY;
• Используйте однострочные операторы с однострочными
подзапросами;
• Если подзапрос возвращает во внешний запрос значение
null, внешний запрос не будет возвращать никакие строки
при использовании операторов сравнения в условии
WHERE.
279. Вложенные и коррелированные запросы
Простые вложенные подзапросы обрабатываются системой «снизувверх». Первым обрабатывается вложенный подзапрос самого нижнего
уровня. Множество значений, полученное в результате его выполнения,
используется при реализации подзапроса более высокого уровня и т. д.
Коррелированные вложенные подзапросы обрабатываются системой в
обратном порядке. Сначала выбирается первая строка рабочей таблицы,
сформированной основным запросом, и из нее выбираются значения тех
столбцов, которые используются во вложенном подзапросе (вложенных
подзапросах). Если эти значения удовлетворяют условиям вложенного
подзапроса, то выбранная строка включается в результат. Затем
выбирается вторая строка и т. д., пока в результат не будут включены все
строки, удовлетворяющие вложенному подзапросу (последовательности
вложенных подзапросов).
280. Применение подзапроса в предложении WHERE
SELECT model, priceFROM PC1
WHERE price > (SELECT
AVG(price) FROM PC1)
ЗапросWHERE
model
price
1456
850
1333
700
2431
920
281. Применение подзапроса в предложении FROM
SELECT ram, Avg_priceFROM
(SELECT ram, AVG(price) AS
Avg_price
FROM PC1 GROUP BY ram)
WHERE Avg_price > 700
Запрос11
ram
Avg_price
512
775
1024
920
282. Операции над множествами
Оператор UNION объединяет выходные строки каждого из запросов водин набор. Если определен параметр ALL, то сохраняются все дубликаты
выходных строк, иначе остаются только уникальные строки
SELECT model, speed,cd
ЗапроcUNION
FROM PC1
model
speed cd
WHERE price > 800
1456
750 50x
UNION ALL SELECT model, speed,cd
2431
800 50x
FROM PC1
1456
750 50x
WHERE cd = '50x';
1782
600 50x
2431
800 50x
283. Условия использования оператора UNION
• количество выходных столбцов каждого иззапросов одинаково;
• выходные столбцы каждого из запросов
должны быть одного типа;
• в выборке используются имена столбцов,
заданные в первом запросе;
• операция сортировки применяется к
результату соединения.
284. Использование предиката существования EXISTS
Квантор EXISTS (существует) - понятие, заимствованное изформальной логики. В языке SQL предикат с квантором
существования представляется выражением EXISTS (SELECT *
FROM ...).
Такое выражение считается истинным только тогда, когда
результат вычисления "SELECT * FROM ..." является непустым
множеством, т.е. когда существует какая-либо запись в
таблице, указанной во фразе FROM подзапроса, которая
удовлетворяет условию WHERE подзапроса. (Практически
этот подзапрос всегда будет коррелированным множеством.)
285.
Пересечение исходного множества смножеством компьютеров, у которых
размер оперативной памяти такой же,
но существуют еще модели с меньшим
размером жесткого диска
SELECT DISTINCT model, ram, hd
FROM PC1 AS [Comp]
WHERE ram < 1024 AND
EXISTS
(SELECT model FROM PC1
WHERE hd < Comp.hd AND ram =
Comp.ram);
ЗапросEXIST
model ram
hd
1121
256
1234
1456
256
512
20
20
40
286. Разность
Разность исходного множества смножеством компьютеров, у которых
размер оперативной памяти такой
же, но существуют еще модели с
меньшим размером жесткого диска
SELECT DISTINCT model, ram, hd
FROM PC1 AS [Comp]
WHERE ram < 1024 AND NOT EXISTS
(SELECT model FROM PC1
WHERE hd < Comp.hd AND ram =
Comp.ram);
ЗапросРазность
model
ram
hd
1333
512
30
1782
256
10
287. Пересечение и разность в объединении дают исходную таблицу
ЗапросEXISTmodel
ram
hd
1121
256
20
1234
256
20
1456
512
40
ЗапросРазность
model
ram
hd
1333
512
30
1782
256
10
288. Запросы на добавление
INSERT INTO <имя таблицы>[(<имястолбца>,...)]
{VALUES (< значение столбца>,…)}
| <выражение запроса>|
289. Добавление данных в указанные поля
INSERT INTO ИмяТаблицы (ИмяПоля! [,ИмяПоля2, ...]) VALUES (Значение! [,
Значение2, ...])
290.
Список столбцов в данном операторе не является обязательным. В томслучае, если он отсутствует, список вставляемых значений должен быть
полный:
INSERT INTO PC VALUES (980, 900, 80, 1024, '52x', 3355)
price
speed
hd
ram
cd
model
670
600
20
256 24x
1121
600
500
20
256 48x
1234
700
500
30
512 52x
1333
850
750
40
512 50x
1456
450
600
10
256 50x
1782
920
800
160
1024 50x
2431
price
speed
hd
ram
cd
model
600
500
20
256 48x
1234
850
750
40
512 50x
1456
700
500
30
512 52x
1333
450
600
10
256 50x
1782
670
600
20
256 24x
1121
920
800
160
1024 50x
2431
980
900
80
1024 52x
3355
291. Вставка строк с пустыми полями
INSERT INTO PC ( model, price, speed )VALUES (3355, 980, 900);
price
speed
hd
ram
cd
model
600
500
20
256 48x
1234
850
750
40
512 50x
1456
700
500
30
512 52x
1333
450
600
10
256 50x
1782
670
600
20
256 24x
1121
920
800
160
1024 50x
2431
980
900
80
1024 52x
3355
980
900
3355
292. Добавление записи с помощью SELECT
INSERT INTO ИмяТаблицыПриемника(ИмяПоля! [, ИмяПоля2, ...])
SELECT ИмяТаблицыИсточника.ИмяПоля! [,
ИмяТаблицыИсточника.ИмяПоля2, ...] FROM
ИмяТаблицыИсточника
перечни полей SELECT и INSERT INTO должны
совпадать по типам и количеству элементов.
293.
INSERT INTO PC ( model, price, speed )SELECT model, price, speed
FROM Computer
WHERE hd =10;
PC
price
speed
hd
ram
cd
model
670
600
20
256 24x
1121
600
500
20
256 48x
1234
700
500
30
512 52x
1333
850
750
40
512 50x
1456
450
600
10
256 50x
1782
920
800
160
1024 50x
2431
450
600
1782
Computer
price
speed
hd
ram
cd
model
670
600
20
256
24x
1121
600
500
20
256
48x
1234
700
500
30
512
52x
1333
850
750
40
512
50x
1456
450
600
10
256
50x
1782
294.
INSERT INTO PCSELECT *
FROM Computer
WHERE hd=10;
PC
price
speed
hd
ram
cd
model
670
600
20
256 24x
1121
600
500
20
256 48x
1234
700
500
30
512 52x
1333
850
750
40
512 50x
1456
450
600
10
256 50x
1782
920
800
160
1024 50x
2431
450
600
450
600
1782
10
256 50x
1782
295. Обновление данных
UPDATE ИмяТаблицыSET ИмяПоля1 = Значение1 [, ИмяПоля2 = Значение2, ...]
[WHERE Предложение]
• Предложение SET должно включать, по меньшей мере,
один предикат вида ИмяПоля = Значение, и их количество
не ограничено.
• С помощью одного оператора могут быть заданы значения
для любого количества столбцов. Однако, в одном
операторе UPDATE можно вносить измене- ния в каждый
столбец указанной таблицы только один раз.
296.
UPDATE PC SET hd=10 WHERE (hd Is Null);price
speed
hd
ram
cd
model
670
600
20
256 24x
1121
600
500
20
256 48x
1234
700
500
30
512 52x
1333
850
750
40
512 50x
1456
450
600
10
256 50x
1782
920
800
160
1024 50x
2431
450
600
450
600
10
256 50x
1782
670
600
20
256 24x
1121
600
500
20
256 48x
1234
700
500
30
512 52x
1333
850
750
40
512 50x
1456
450
600
10
256 50x
1782
920
800
160
1024 50x
2431
450
600
10
450
600
10
1782
1782
256 50x
1782
297.
Разрешается значения одних столбцов присваивать другим:UPDATE PC
SET hd = ram / 2 WHERE hd is NULL
price
speed
hd
ram
cd
model
670
600
20
256
24x
1121
600
500
20
256
48x
1234
700
500
30
512
52x
1333
850
750
40
512
50x
1456
450
600
128
256
50x
1782
920
800
160
1024
50x
2431
450
600
450
600
price
speed
256
128
hd
256
ram
1782
50x
cd
1782
model
670
600
20
256
24x
1121
600
500
20
256
48x
1234
700
500
30
512
52x
1333
850
750
40
512
50x
1456
450
600
128
256
50x
1782
920
800
160
1024
50x
2431
450
600
128
256
450
600
128
256
1782
50x
1782
298. Удаление записей
DELETE FROM <имя таблицы > [WHERE<предикат>]
299. DELETE FROM PC WHERE ram <= 256
DELETE FROM PCWHERE ram <= 256
price
speed
hd
ram
cd
model
670
600
20
256
24x
1121
600
500
20
256
48x
1234
700
500
30
512
52x
1333
850
750
40
512
50x
1456
450
600
128
256
50x
1782
920
800
160
1024
50x
2431
450
600
128
256
450
600
128
256
price
speed
hd
ram
1782
50x
cd
1782
model
700
500
30
512
52x
1333
850
750
40
512
50x
1456
920
800
160
1024
50x
2431
300. DELETE * FROM PC WHERE model NOT IN (SELECT model FROM Computer);
PCprice
speed
hd
ram
cd
model
670
600
20
256
24x
1121
600
500
20
256
48x
1234
700
500
30
512
52x
1333
850
750
40
512
50x
1456
450
600
10
256
50x
1782
920
800
160
1024
50x
2431
Computer
price
speed
hd
ram
cd
model
670
600
20
256
24x
1121
600
500
20
256
48x
1234
700
500
30
512
52x
1333
850
750
40
512
50x
1456
450
600
10
256
50x
1782
301. БД MySQL
302. Книга по HTML и CSS «Основы Самостоятельного Сайтостроения»
Книга по HTML и CSS «Основы
Самостоятельного Сайтостроения»
Урок 1 – «Структура HTML документа. Основные теги»
Урок 2 – «Форматирование текста в html»
Урок 3 – «Работа с ссылками и с изображениями в html»
Урок 4 – «HTML списки»
Урок 5 – «HTML таблицы»
Урок 6 – «Каскадные таблицы стилей(CSS)»
Урок 7 – «Продолжаем CSS»
Урок 8 – «Свойства таблиц стилей (css)»
Урок 9 – «HTML формы»
Урок 10 – «Работа со звуковыми файлами»
Урок 11 – «Дополнительные элементы HTML»
Урок 12 – «Управление над видимостью объекта»
Урок 13 – «Создание сайта с помощью блоков»
Урок 14 – «Фреймы»
Вы можете получить книгу совершенно бесплатно:
Скачать книгу
303. Программирование на PHP
PHP (рекурсивный акроним словосочетания PHP: HypertextPreprocessor) - это распространенный язык
программирования общего назначения с открытым
исходным кодом. PHP специально сконструирован для вебразработок и его код может внедряться непосредственно в
HTML.
PHP-скрипты выполняются на сервере и генерируют HTML,
который посылается клиенту
https://www.php.net/manual/ru/
http://slusar.su/uroki/web-vse-uroki/
304. Основные области применения PHP
Создание скриптов для выполнения на стороне сервера. PHP традиционно и
наиболее широко используется именно таким образом. Для этого вам будут
необходимы три вещи. Интерпретатор PHP (в виде программы CGI или
серверного модуля), веб-сервер и браузер. Для того чтобы можно было
просматривать результаты выполнения PHP-скриптов в браузере, нужен
работающий веб-сервер и установленный PHP. Просмотреть вывод PHPпрограммы можно в браузере, получив PHP-страницу, сгенерированную
сервером. В случае, если вы просто экспериментируете, вы вполне можете
использовать свой домашний компьютер вместо сервера.
Создание скриптов для выполнения в командной строке. Вы можете создать
PHP-скрипт, способный запускаться без сервера или браузера.
Создание оконных приложений, выполняющихся на стороне клиента.
Возможно, PHP является не самым лучшим языком для создания подобных
приложений, но, если вы очень хорошо знаете PHP и хотели бы использовать
некоторые его возможности в своих клиентских приложениях, вы можете
использовать PHP-GTK для создания таких приложений. PHP-GTK является
расширением PHP и не поставляется вместе с основным дистрибутивом PHP.
305. Установка OpenServer.
OpenServer – набор программ, платформа для локальнойработы с сайтами. Включает в себя:
• Apache;
• Nginx;
• MySQL;
• MariaDB;
• MongoDB;
• PostgreSQL;
• PHP;
• PHPMyAdmin.
И ряд компонентов и скриптов, с помощью которых
создается полноценный сайт. Затем сайт переносят на
хостинг. Платформа OpenServer подойдет и вебразработчикам.
306. Источники информации
1. Open Server. Установка и работа с серверомwebformyself.com/open-server-ustanovka-i-rabota-sserverom/
2. Open Server. Руководство пользователя
https://ospanel.io/docs/
3. Веб-сервер XAMPP. Установка и настройка
webformyself.com/veb-server-xampp-ustanovka-inastrojka/
4. Документация по MySQL http://www.mysql.ru/docs/
5. MySQL - справочное руководство на
русскомhttps://phpclub.ru/mysql/doc/
6. Справочное руководство по
MySQLhttp://www.mysql.ru/docs/man/Reserved_words.
html
307. Видеоуроки по Open Server
• https://drive.google.com/open?id=1YplhQg7XGFgPgxZu5MvJXj6pe6x_zBxc
308. Установка Open Server
Open Server является портативным программным комплексом ине требует установки. Сборку можно разместить на внешнем
жёстком диске, это позволит использовать Open Server на любом
компьютере, который отвечает системным требованиям.
Не стоит размещать Open Server на USB-флеш накопителе ввиду
крайне медленной работы флеш-памяти при параллельных
запросах на чтение/запись и её быстрого износа.
Дистрибутив представляет собой самораспаковывающийся архив в
формате RAR (расширение .exe). Запустите исполняемый файл
дистрибутива и выберите путь для распаковки файлов.
309. Системные требования
Поддерживаемые операционные системы:Windows 7 SP1 x64 и все более новые версии;
Минимальные аппаратные требования: 500 МБ
свободной RAM и 4 ГБ свободного места на HDD;
Требуется наличие Microsoft Visual C++ 20052008-2010-2012-2013-2015-2019 Redistributable
Package;
Устаревшие системы XP/Vista и 32-разрядные
версии Windows не поддерживаются.
310. Дистрибутив
• https://ospanel.io/download/ВЕРСИЯ
FULL
BASIC
Базовые модули
Есть
Есть
ImageMagick
Есть
Есть
MongoDB
Есть
Нет
PostgreSQL +
PhpPgAdmin
Есть
Нет
Программы для вебразработчика
Есть
Нет
Размер до/после
распаковки
835 МБ / 5.81 ГБ
366 МБ / 3.48 Г
311. Настройки
После запуска может появиться сообщение Порт 80 используется. Внастройках поменяйте HTTP на 81 или другой
312.
• Будет запрос на установку Visual C++• Настройки Windows 10
Перезагрузить
313. Запуск
• Логин root• Пароль root
314. mySQL
• MySQL - это торговая марка MySQL АВ.• Программное обеспечение MySQL (TM) представляет собой очень
быстрый многопоточный, многопользовательский надежный SQLсервер баз данных.
• Сервер MySQL предназначен как для критических по задачам
производственных систем с большой нагрузкой, так и для встраивания
в программное обеспечение массового распространения.
• Программное обеспечение MySQL имеет двойное лицензирование.
Это означает, что пользователи могут выбирать, использовать ли ПО
MySQL бесплатно по общедоступной лицензии GNU General Public
License (GPL) или приобрести одну из стандартных коммерческих
лицензий MySQL AB.
315. Клиент-серверная технология
• ПО MySQL является системой клиент-сервер, котораясодержит многопоточный SQL-сервер, обеспечивающий
поддержку различных вычислительных машин баз
данных, а также несколько различных клиентских
программ и библиотек, средства администрирования и
широкий спектр программных интерфейсов (API).
• Сервер MySQL также поставляется в виде многопоточной
библиотеки, которую можно подключить к
пользовательскому приложению и получить компактный,
более быстрый и легкий в управлении продукт.
316. Команды и функции
Команды и функции
Полная поддержка операторов и функций в SELECT- и WHERE- частях
запросов.
– Например:
– mysql> SELECT CONCAT(first_name, " ", last_name)
– -> FROM tbl_name
– -> WHERE income/dependents > 10000 AND age > 30;
Полная поддержка для операторов SQL GROUP BY и ORDER BY с выражениями
SQL. Поддержка групповых функций (COUNT(), COUNT(DISTINCT ...), AVG(),
STD(), SUM(), MAX() и MIN()).
Поддержка LEFT OUTER JOIN и RIGHT OUTER JOIN с синтаксисом ANSI SQL и
ODBC.
Разрешены псевдонимы для таблиц и столбцов в соответствии со стандартом
SQL92.
DELETE, INSERT, REPLACE, and UPDATE возвращают число строк, которые были
изменены. Вместо этого можно задать возвращение совпавших строк. Для
этого следует установить флаг при соединении с сервером.
Имена функций не конфликтуют с именами таблиц и столбцов. Например, ABS
является корректным именем столбца. Для вызова функции существует
только одно ограничение: между именем функции и следующей за ним
открывающей скобкой `(' не должно быть пробелов. В одном и том же
запросе могут указываться таблицы из различных баз данных (с версии 3.22).
317. Масштабируемость и ограничения
• Управляет очень большими базами данных. Компания MySQL ABиспользует MySQL для работы с несколькими базами данных, которые
содержат 50 миллионов записей, кроме того, известны пользователи,
использующие MySQL для работы с 60000 таблицами, включающими
около 5000000000 строк.
• Для каждой таблицы разрешается иметь до 32 индексов. Каждый
индекс может содержать от 1 до 16 столбцов или частей столбцов.
Максимальная ширина индекса 500 бит (это значение может быть
изменено при компиляции MySQL). Для индекса может
использоваться префикс поля CHAR или VARCHAR.
318. Размеры таблиц
• MySQL версии 3.22 имеет предел по размеру таблиц 4 Гб.В MySQL версии 3.23, где используется новый тип таблиц,
максимальный размер таблицы доведен до 8 миллионов
терабайтов (2 ^ 63 bytes).
• Однако следует заметить, что операционные системы
имеют свои собственные ограничения по размерам
файлов.
• По умолчанию MySQL-таблицы имеют максимальный
размер около 4 Гб.
• Для любой таблицы можно проверить/определить ее
максимальный размер с помощью команд SHOW TABLE
STATUS или myisamchk -dv table_name.
319. Управление учетными записями пользователей MySQL
Команды GRANT и REVOKE позволяют системным администраторам создавать
пользователей MySQL, а также предоставлять права пользователям или
лишать их прав на четырех уровнях привилегий:
Глобальный уровень
– Глобальные привилегии применяются ко всем базам данных на указанном
сервере. Эти привилегии хранятся в таблице mysql.user.
Уровень базы данных
– Привилегии базы данных применяются ко всем таблицам указанной базы данных.
Эти привилегии хранятся в таблицах mysql.db и mysql.host.
Уровень таблицы
– Привилегии таблицы применяются ко всем столбцам указанной таблицы. Эти
привилегии хранятся в таблице mysql.tables_priv.
Уровень столбца
– Привилегии столбца применяются к отдельным столбцам указанной таблицы. Эти
привилегии хранятся в таблице mysql.columns_priv.
320. Использование безопасных соединений
MySQL поддерживает шифрованные SSL-соединения.
По умолчанию в MySQL используются незашифрованные соединения между
клиентом и сервером. Это означает, что просматривать все данные,
передаваемые между клиентом и сервером, может кто угодно. На практике
можно даже изменять данные во время передачи их от клиента к серверу и
наоборот. Помимо того, иногда возникает необходимость передать
действительно секретные данные через общедоступную сеть - в таких случаях
использование незашифрованных соединений просто неприемлемо.
В протоколе SSL используются различные алгоритмы шифрования,
обеспечивающие безопасность для данных, передаваемых через
общедоступные сети. Этот протокол содержит средства, позволяющие
обнаруживать любые изменения, потери и повторы данных. В протоколе SSL
также применяются алгоритмы для проведения идентификации при помощи
стандарта X509.
321. Резервное копирование баз данных
• Поскольку таблицы MySQL хранятся в виде файлов, то резервноекопирование выполняется легко. Чтобы резервная копия была
согласованной, выполните на выбранных таблицах LOCK TABLES, а
затем FLUSH TABLES для этих таблиц.
• При этом требуется блокировка только на чтение; поэтому другие
потоки смогут продолжать запросы на таблицах в то время, пока будут
создаваться копии файлов из каталога базы данных.
• Команда FLUSH TABLE обеспечивает гарантию того, что все активные
индексные страницы будут записаны на диск прежде, чем начнется
резервное копирование.
322. Работа с БД MySQL с использованием phpMyAdmin
• #1 Введение и основные понятия, Базы данных MySQL• #2 Установка локального сервера и запуск phpMyAdmin, Базы данных
MySQL
• #3 Типы полей в MySQL, Базы данных MySQL
• #4 Пользователи и привилегии в phpMyAdmin, Базы данных MySQL
• #5 Основные операции с базами данных в phpMyAdmin, Базы данных
MySQL
• #6 Всё про Таблицы и операции с ними в phpMyAdmin, Базы данных
MySQL
• #7 Всё про Записи в таблицах в phpMyAdmin, Базы данных MySQL
• #8 Индекс и первичный ключ в phpMyAdmin на MySQL, Базы данных
MySQL
• #9 Экспорт и Импорт в phpMyAdmin на MySQL, Базы данных MySQL
https://drive.google.com/drive/folders/1ZJLIkpn50NSJEnV1BXy4GYJJjjcfUUTh
?usp=share_link
323. Работа с БД MySQL через язык PHP
• Устанавливаем Open Server• Настраиваем Open Server
• Создаем БД средствами phpMyAdmin
• Пишем код на языке PHP
• Смотрим результат
324. Установка OPEN Server
• Скачиваем дистрибутив• Раскрываем его на выбранном внутреннем
или съемном диске
• Устанавливаем библиотеки MS Visual C++
• Запускаем OPEN Server
Имеется альтернатива WAMP — это сокращение от Windows, Apache,
MySQL и PHP. Это программный стек, который означает, что установка
WAMP устанавливает Apache, MySQL и PHP в вашей операционной
системе (Windows в случае WAMP).
325. Настройка Open Server
• Попытка запустить OS• Настройка портов, если не запускаетя через
меню OS настройка
326. Создание БД через phpMyAdmin Настройка модулей
327. Проверка работы PHP
• Запускаем OS 5.3.7• Папка с проектами
<?php
phpinfo();
?>
328.
Запускаем OS 5.3.7, Мои проекты, Localhosthttps://drive.google.com/open?id=1YplhQg
7XGFgPgxZu5MvJXj6pe6x_zBxc
329. Создаем БД Users
в левом меню выбираем «Создать БД» и вводим такие данные : users иutf8_general_ci и жмем Создать
330. Создание таблицы USER
CREATE TABLE `users`.`user` ( `id` INT NOT NULL AUTO_INCREMENT , `fname`VARCHAR(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL ,
`lname` VARCHAR(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT
NULL , `age` INT NOT NULL , PRIMARY KEY (`id`)) ENGINE = InnoDB;
331. Определяем привилегии
вводим логин нашего админа базы данных bdAdmin, имя хоста (обычно этоlocalhost) и пароль bdpass с подтверждением. В разделе Глобальные
привилегии ставим галочку Отметить все.
332. Заполняем БД
333. Создаем приложение PHP
• Создаем папку dbcon.loc в domains• Копируем в нее index.php и func.php из
https://docs.google.com/document/d/1sLTWE
jd5JGuhxPfvldXvUrWMIdkNC4NF/edit?usp=sh
are_link&ouid=102090967101572525189&rtp
of=true&sd=true
• В них размещены коды PHP для работы с
базой данных
334. Демонстрация результата
Запускаем из OS Мои проекты. DBCON335. Программирование на PHP операций с БД
• Редактор для работы с HTML c возможностьюавтоподстановки кодов языка
https://www.sublimetext.com/3
• Справочник по HTML http://htmlbook.ru/html
• http://htmlbook.ru/css - справочник по CSS (Cascading Style
Sheets) — это код, который вы используете для стилизации
вашей веб-страницы
• https://ru.000webhost.com - бесплатный хостинг
336. МНОГОПОЛЬЗОВАТЕЛЬСКИЙ ДОСТУП К ДАННЫМ
На однопроцессорной ЭВМ запросы выполняются не одновременно, апараллельно. Для каждого запроса выделяется некоторое количество
процессорного времени (квант времени), по истечении которого выполнение
запроса приостанавливается, он ставится в очередь запросов, а на выполнение
запускается следующий по очереди запрос. Т.о., процессорное время делится
между запросами, и создаётся иллюзия, что запросы выполняются
одновременно.
При параллельном доступе к данным запросы на чтение не мешают друг другу.
Наоборот, если один запрос считал данные в оперативную память (в буфер
данных), то другой запрос не будет тратить время на обращение к диску за
этими данными, а получит их из буфера данных. Проблемы возникают в том
случае, если доступ подразумевает внесение изменений. Для того чтобы
исключить нарушения логической целостности данных при
многопользовательском доступе, используется механизм транзакций.
337. Транзакция
Это упорядоченная последовательностьоператоров обработки данных, которая
переводит базу данных из одного
согласованного состояния в другое.
Все команды работы с данными выполняются
в рамках транзакций. Для каждого сеанса
связи с БД в каждый момент времени может
существовать единственная транзакция или
не быть ни одной транзакции
338. Свойства транзакций
1. Логическая неделимость (атомарность, Atomicity) означает, что выполняются либо все
операции (команды), входящие в транзакцию, либо ни одной. Система гарантирует
невозможность запоминания части изменений, произведённых транзакцией. До тех пор, пока
транзакция не завершена, её можно "откатить", т.е. отменить все сделанные командами
транзакции изменения. Успешное выполнение транзакции (фиксация) означает, что все
команды транзакции проанализированы, интерпретированы как правильные и безошибочно
исполнены.
• 2. Согласованность (Consistency): транзакция начинается на согласованном множестве данных и
после её завершения множество данных согласовано. Состояние БД является согласованным,
если данные удовлетворяют всем установленным ограничениям целостности и относятся к
одному моменту в состоянии предметной области.
• 3. Изолированность (Isolation), т.е. отсутствие влияния транзакций друг на друга. (На самом деле
это влияние существует и регламентируется стандартом: см. раздел "Уровни изоляции
транзакций").
• 4. Устойчивость (Durability): результаты завершённой транзакции не могут быть потеряны.
Возврат БД в предыдущее состояние может быть достигнут только путём запуска
компенсирующей транзакции.
Транзакции, удовлетворяющие этим свойствам, называют ACID-транзакциями (по первым буквам
названий свойств).
339. Операторы управления транзакциями в SQL
• фиксация транзакции (запоминаниеизменений): COMMIT [WORK];
• откат транзакции (отмена изменений):
ROLLBACK [WORK];
• создание точки сохранения: SAVEPOINT
<имя_точки_сохранения>;
340. Точки фиксации и отката
Для фиксации или отката транзакции система создаёт неявные точки фиксации иотката. По команде rollback система откатит транзакцию на начало (на неявную точку
отката), а по команде commit – зафиксирует всё до неявной точки фиксации, которая
соответствует последней завершённой команде в транзакции. Если в транзакции из
нескольких команд во время выполнения очередной команды возникнет ошибка, то
система откатит только эту ошибочную команду, т.е. отменит её результаты и
сохранит прежнюю неявную точку фиксации.
Для обеспечения целостности транзакции СУБД может откладывать запись
изменений в БД до момента успешного выполнения всех операций, входящих в
транзакцию, и получения команды подтверждения транзакции (commit). Но чаще
используется другой подход: система записывает изменения в БД, не дожидаясь
завершения транзакции, а старые значения данных сохраняет на время выполнения
транзакции в сегментах отката.
341. Сегмент отката
Сегмент отката (rollback segment, RBS) – это специальная область памяти надиске, в которую записывается информация обо всех текущих (незавершённы х)
изменениях. Обычно записывается "старое" и "новое" содержимое изменённых
записей, чтобы можно было восстановить прежнее состояние БД при откате
транзакции (по команде rollback) или при откате текущей операции (в случае
возникновения ошибки). Данные в RBS хранятся до тех пор, пока транзакция,
изменяющая эти данные, не будет завершена. Потом они могут быть
Перезаписаны данными более поздних транзакций.
Команда savepoint запоминает промежуточную "текущую копию" состояния
базы данных для того, чтобы при необходимости можно было вернуться к
состоянию БД в точке сохранения: откатить работу от текущего момента до
точки сохранения (rollback to <имя_точки>) или зафиксировать работу от начала
транзакции до точки сохранения (commit to <имя_точки>). На одну транзакцию
может быть несколько точек сохранения (ограничение на их количество зависит
от СУБД).
342. Журнал транзакций
Журнал транзакций – это часть БД, в которую поступают данные обо всехизменениях всех объектов БД. Журнал недоступен пользователям СУБД и
поддерживается особо тщательно (иногда ведутся две копии журнала,
хранимые на разных физических носителях). Форма записи в журнал
изменений зависит от СУБД. Но обычно там фиксируется следующее:
1. Изменения, внесённые транзакцией, помечаются как постоянные.
2. Уничтожаются все точки сохранения для данной транзакции.
3. Если выполнение транзакций осуществляется с помощью блокировок,
то освобождаются объекты, заблокированные транзакцией (см. раздел
5.5).
4. В журнале транзакций транзакция помечается как завершенная,
уничтожаются системные записи о транзакции в оперативной памяти. А
при откате транзакции вместо п.1 обычно выполняется считывание из
сегмента отката прежних значений данных и переписывание их обратно
в БД (остальные пункты сохранятся без изменений). Поэтому откат
транзакции практически всегда занимает больше времени, чем
фиксация.
343. Взаимовлияние транзакций
Транзакции в многопользовательской БД должны быть изолированы друг отдруга, т.е. в идеале каждая из них должна выполняться так, как будто
выполняется только она одна. В реальности транзакции выполняются
одновременно и могут влиять на результаты друг друга, если они обращаются
к одному и тому же набору данных и хотя бы одна из транзакций изменяет
данные.
В общем случае взаимовлияние транзакций может проявляться в виде:
• потери изменений;
• чернового чтения;
• неповторяемого чтения;
• фантомов
344. Потеря изменений
Потеря изменений могла бы произойти при одновременном обнов-лениидвумя и более транзакциями одного и того же набора данных. Транзакция,
закончившаяся последней, перезаписала бы результаты изменений,
внесённых предыдущими транзакциями, и они были бы потеряны.
Представим, что одновременно начали выполняться две транзакции:
транзакция 1 – UPDATE СОТРУДНИКИ SET Оклад = 39200 WHERE Номер =
1123;
транзакция 2 – UPDATE СОТРУДНИКИ SET Должность = "старший экономист"
WHERE Номер = 1123;
Обе транзакции считали одну и ту же запись (1123, "Рудин В.П.", "экономист", 28300) и внесли каждая свои изменения: в бухгалтерии изменили
оклад (транзакция 1), в отделе кадров – должность (транзакция 2).
Результаты транзакции 1 будут потеряны.
345. Черновое чтение
Ситуация чернового чтения возникает, когда транзакция считываетизменения, вносимые другой (незавершенной) транзакцией. Если эта
вторая транзакция не будет зафиксирована, то данные, полученные в
результате чернового чтения, будут некорректными. Транзакции,
осуществляющие черновое чтение, могут использоваться только при
невысоких требованиях к согласованности данных: например, если
транзакция считает статистические показатели, когда отклонения
отдельных значений данных слабо влияют на общий результат. При
повторяемом чтении один и тот же запрос, повторно выполняемый
одной транзакцией, возвращает один и тот же набор данных (т.е.
игнорирует изменения, вносимые другими завершёнными и
незавершёнными транзакциями).
346.
347. Неповторяемое чтение
Неповторяемое чтение являетсяпротивоположностью повторяемого, т.е.
транзакция "видит" изменения, внесённые
другими (завершёнными!) транзакциями.
Следствием этого может быть
несогласованность результатов запроса, когда
часть данных запроса соответствует
состоянию БД до внесения изменений, а
часть – состоянию БД после внесения и
фиксации изменений.
348.
349. Фантомы
Фантомы – это особый тип неповторяемого чтения. Возникновениефантомов может происходить в ситуации, когда одна и та же транзакция
сначала производит обновление набора данных, а затем считывание
этого же набора.
Если считывание данных начинается раньше, чем закончится их
обновление, то в результате чтения можно получить несогласованный (не
обновлённый или частично обновлённый) набор данных. При
последующих запросах это явление пропадает, т.к. на самом деле
запрошенные данные после завершения обновления будут
согласованными в соответствие со свойствами транзакции.
Для разграничения двух пишущих транзакций и предотвращения
потери изменений СУБД используют механизмы блокировок или
временных отметок, а для разграничения пишущей и читающих
транзакций – специальные правила поведения транзакций, которые
называются уровнями изоляции транзакций.
350.
351. Уровни изоляции транзакций
Стандарт ANSI/ISO для SQL устанавливает различные уровни изоляции дляопераций, выполняемых над БД, которые работают в многопользовательском
режиме. Уровень изоляцииопределяет, может ли читающая транзакция
считывать ("видеть") результаты работы других одновременно выполняемых
завершённых и/или незавершённых пишущих транзакций. Использование
уровней изоляции обеспечивает предсказуемость работы приложений.
352.
По умолчанию в СУБД обычно установлен уровень ReadCommited.
Уровень изоляции позволяет транзакциям в большей или
меньшей степени влиять друг на друга: при повышении
уровня изоляции повышается согласованность данных, но
снижается степень параллельности работы и,
следовательно, производительность системы.
353. Блокировки
Блокировка – это временное ограничение доступа к данным,участвующим в транзакции, со стороны других транзакций..
Блокировка относится к пессимистическим алгоритмам, т.к.
предполагается, что существует высокая вероятность одновременного
обращения нескольких пишущих транзакций к одним и тем же данным.
Различают следующие типы блокировок:
• по степени доступности данных: разделяемые и исключающие;
• по множеству блокируемых данных: строчные, страничные, табличные;
• по способу установки: автоматические и явные.
354. Строчные, страничные и табличные блокировки
Строчные, страничные и табличные блокировкинакладываются соответственно на строку таблицы, страницу
(блок) памяти и на всю таблицу целиком. Табличная
блокировка приводит к неоправданным задержкам
исполнения запросов и сводит на нет параллельность
работы. Другие виды блокировки увеличивают параллелизм
работы, но требуют накладных расходов на поддержание
блокировок: наложение и снятие блокировок требует
времени, а для хранения информации о наложенной
блокировке нужна дополнительная память (для каждой
записи или блока данных).
355. Разделяемая блокировка
Разделяемая блокировка, установленная на определённыйресурс, предоставляет транзакциям право коллективного
доступа к этому ресурсу.
Обычно этот вид блокировок используется для того, чтобы
запретить другим транзакциям производить необратимые
изменения. Например, если на таблицу целиком наложена
разделяемая блокировка, то ни одна транзакция не сможет
удалить эту таблицу или изменить её структуру до тех пор,
пока эта блокировка не будет снята. (При выполнении
запросов на чтение обычно накладывается разделяемая
блокировка на таблицу.)
356. Исключающая блокировка
Исключающая блокировка предоставляет право намонопольный доступ к ресурсу. Исключающая
(монопольная) блокировка таблицы накладывается,
например, в случае выполнения операции ALTER TABLE, т.е.
изменения структуры таблицы. На отдельные записи (блоки)
монопольная блокировка накладывается тогда, когда эти
записи (блоки) подвергаются модификации.
357. Автоматическая и явная блокировка
Блокировка может быть автоматической и явной. Если запускается новаятранзакция, СУБД сначала проверяет, не заблокирована ли другой
транзакцией строка, требуемая этой транзакции: если нет, то строка
автоматически блокируется и выполняется операция над данными; если
строка заблокирована, транзакция ожидает снятия блокировки. Явная
блокировка, накладываемая командой LOCK TABLE языка SQL, обычно
используется тогда, когда транзакция затрагивает существенную часть
отношения. Это позволяет не тратить время на построчную блокировку
таблицы. Кроме того, при большом количестве построчных блокировок
транзакция может не завершиться (из-за возникновения взаимных
блокировок, например), и тогда все сделанные изменения придётся
откатить, что снизит производительность системы.
Явную блокировку также можно наложить с помощью ключевых слов for
update, например: for update, например: SELECT * FROM <имя_таблицы>
WHERE <условие> for update;
При этом блокировка будет накладываться на те записи, которые
удовлетворяют <условию>.
358.
И явные, и неявные блокировки снимаются при завершении транзакции.Блокировки могут стать причиной бесконечного ожидания и тупиковых
ситуаций. Бесконечное ожидание возможно в том случае, если не
соблюдается очерёдность обслуживания транзакций и транзакция,
поступившая раньше других, всё время отодвигается в конец очереди.
Решение этой проблемы основывается на выполнении правила FIFO (first
input – first output): "первый пришел – первый ушел".
359. Тупиковые ситуации
Тупиковые ситуации (deadlocks) возникают при взаимных блокировкахтранзакций, которые выполняются на пересекающихся множествах
данных. Здесь приведён пример взаимной блокировки трех транзакций
Ti на отношениях Rj. Транзакция T1 заблокировала данные B1 в
отношении R1 и ждёт освобождения данных B2 в отношении R2, которые
заблокированы транзакцией T2, ожидающей освобождения данных B3 в
отношении R3, заблокированных транзакцией T3, которая не может
продолжить выполнение из-за транзакции T1. Если не предпринимать
никаких дополнительных действий, то эти транзакции никогда не
завершатся, т.к. они вечно будут ждать друг друга.
360. Стратегии разрешения проблемы
Существует много стратегий разрешения проблемы взаимнойблокировки, в частности:
1. Транзакция запрашивает сразу все требуемые блокировки. Такой
метод снижает степень параллелизма в работе системы. Также он не
может применяться в тех случаях, когда заранее неизвестно, какие
данные потребуются, например, если выборка данных из одной таблицы
осуществляется на основании данных из другой таблицы, которые
выбираются в том же запросе.
2. СУБД отслеживает возникающие тупики и отменяет одну из транзакций
с последующим рестартом через случайный промежуток времени. Этот
метод требует дополнительных накладных расходов.
3. Вводится таймаут (time-out) – максимальное время, в течение которого
транзакция может находиться в состоянии ожидания. Если транзакция
находится в состоянии ожидания дольше таймаута, считается, что она
находится в состоянии тупика, и СУБД инициирует её откат с
последующим рестартом через случайный промежуток времени.
361. Временные отметки
Временная отметка – это уникальный идентификатор,который СУБД создаёт для обозначения относительного
момента запуска транзакции. Временная отметка может
быть создана с помощью системных часов или путём
присвоения каждой следующей транзакции очередного
номера (SCN – system change number). Каждая транзакция Тi
имеет временную отметку ti, и каждый элемент данных в БД
(запись или блок) имеет две отметки: tread(x) – временная
отметка транзакции, которая последней считала элемент x, и
twrite(x) – временная отметка транзакции, которая
последней записала элемент x.
362.
При выполнении транзакции Тi система сравнивает отметку ti иотметки tread(x) и twrite(x)элемента x для обнаружения конфликтов:
1. для читающей транзакции Тi: если ti <twrite(x), то элемент
данных х перезаписан более поздней транзакцией, и его значение может
оказаться несогласованным с теми данными, которые эта транзакция уже
успела прочитать.
2. для пишущей транзакции:
• если ti < tread(x), то элемент данных х считан более поздней транзакцией.
Если транзакция Т изменит значение элемента х, то в другой транзакции
может возникнуть ошибка.
• если ti < twrite(x), то элемент х перезаписан более поздней транзакцией, и
транзакция Т пытается поместить в БД устаревшее значение элемента х.
Во всех случаях обнаружения конфликта система перезапускает текущую
транзакцию Тi с более поздней временной отметкой. Если конфликта нет, то
транзакция выполняется. Очевидно следующее: если разные транзакции часто
обращаются к одним и тем же данным одновременно, то транзакции часто
будут перезапускаться, и эффективность такого механизма будет невелика.
363. Многовариантность
Для увеличения эффективности выполнения запросов некоторыеСУБД используют алгоритм многовариантности. Этот алгоритм
позволяет обеспечивать согласованность данных при чтении, не
блокируя эти данные. Согласованность данных для операции
чтения заключается в том, что все значения данных должны
относиться к тому моменту, когда начиналась эта операция. Для
этого можно предварительно запретить другим транзакциям
изменять эти данные до окончания операции чтения, но это
снижает степень параллельности работы системы. При
использовании алгоритма многовариантности каждый блок
данных хранит номер последней транзакции, которая
модифицировала данные, хранящиеся в этом блоке (SCN – system
change number). И каждая транзакция имеет свой SCN.
364.
При чтении данных СУБД сравнивает номер транзакции иномер считываемого блока данных:
• если блок данных не модифицировался с момента начала
чтения, то данные считываются из этого блока;
• если данные успели измениться, то система обратится к
сегменту отката и считает оттуда значения данных,
относящиеся к моменту начала чтения.
Недостатком этого метода является возможность
возникновения ошибки при чтении данных, если старые
значения данных в сегменте отката будут переза писаны.
При этом будет выдано сообщение об ошибке и операцию
чтения придётся перезапускать вручную. Для устранения
подобных проблем можно увеличить размер сегмента отката
или разбить одну большую операцию чтения на несколько
(но при этом согласованность данных обеспечиваться не
будет).
365. ЗАЩИТА ДАННЫХ В БАЗАХ ДАННЫХ
Защита данных – это организационные, программные итехнические методы и средства, направленные на
удовлетворение ограничений, установленных для типов
данных или экземпляров типов данных.
Реализация защиты включает:
• контроль достоверности данных с помощью ограничений
целостности;
• обеспечение безопасности данных (физической
целостности данных);
• обеспечение секретности данных.
366. Обеспечение целостности данных
Обеспечение целостности данных касаетсязащиты от внесения непреднамеренных
ошибок и предотвращения последних. Оно
достигается за счёт проверки ограничений
целостности – условий, которым должны
удовлетворять значения данных.
367. Типы ограничений целостности в языке SQL
1. Уникальность значения первичного ключа (PRIMARY KEY).2. Уникальность ключевого поля или комбинации значений ключевых
полей:
UNIQUE(A),
где A – один или несколько атрибутов, указанных через запятую.
(1,2 – явные структурные ограничения целостности.)
3. Обязательность/необязательность значения (NOT NULL/NULL).
4. Задание диапазона значений атрибута Field:
CHECK(field BETWEEN min_value AND max_value)
5. Задание взаимоотношений между значениями атрибутов Field1 и Field2:
CHECK (field1 @ field2), где @ – оператор отношения (например, знак
">").
6. Задание списка возможных значений (констант) для атрибута Field:
CHECK (field IN (value1, value2,…, valueN)).
368.
7. Определение формата атрибута Field (даты, числа и др.). Например:CHECK (field LIKE '_ _ _-_ _-_ _') -- формат телефонного номера
8. Определение домена атрибута на основе значений другого атрибута
Определение формата атрибута Field (даты, числа и др.). Например:
множество значений некоторого атрибута отношения является
подмножеством значений другого атрибута этого или другого отношения
(внешний ключ, FOREIGN KEY)./
(3.-8. – явные ограничения целостности на значения данных.)
9.Ограничения на обновление данных (например, каждое следующее
значение атрибута должно быть больше предыдущего). В SQL напрямую
не реализуется, требует использования специальных возможностей СУБД
(триггеров).
10.Ограничения на параллельное выполнение операций (механизм
транзакций) и проверка ограничений целостности после окончания
внесения взаимосвязанных изменений.
Реализация ограничений целостности возлагается на СУБД или
выполняется с помощью специальных программных модулей.
369. Обеспечение безопасности данных
Под функцией безопасности (или физической защиты)данных подразу-мевается предотвращение разрушения или
искажения данных в результате программного или
аппаратного сбоя. Обеспечение безопасности является
внутренней задачей СУБД, поскольку связано с её
нормальным функционированием, и решается на уровне
СУБД.
Цель восстановления базы данных после сбоя – обеспечить,
чтобы результаты всех подтверждённых транзакций были
отражены в восстановленной БД, и вернуться к нормальному
продолжению работы как можно быстрее, изолируя
пользователей от проблем, вызванных сбоем.
370. Виды сбоев
В СУБД предусмотрены специальные механизмы, призванные нивелироватьпоследствия сбоев в работе базы данных. Рассмотрим наиболее типичные сбои
и способы защиты от них:
1. Сбой предложения.
Сбой происходит при логической ошибке предложения во время его обработки
(например, предложение нарушает ограничение целостности таблицы). Когда
возникает сбой предложения, СУБД автоматически откатывает результаты этого
предложения, генерирует сообщение об ошибке и возвращает управление
пользователю (приложению пользователя).
2. Сбой пользовательского процесса.
Это ошибка в процессе (приложении), работающем с БД, например, аварийное
разъединение или прекращение процесса. Сбившийся процесс пользователя не
может продолжать работу, тогда как СУБД и процессы других пользователей
могут. Система автоматически откатывает неподтверждённые транзакции
сбившегося пользовательского процесса и освобождает все ресурсы, занятые
этим процессом.
371.
3. Сбой процесса сервера. Такой сбой вызван проблемой, препятствующейпродолжению работы сервера. Это может быть аппаратная проблема, такая
как отказ питания, или программная проблема, такая как сбой операционной
системы. Восстановление после сбоя процесса сервера может потребовать
перезагрузки БД, при этом автоматически происходит откат всех
незавершённых транзакций.
4. Сбой носителя (диска). Эта ошибка может возникнуть при попытке записи
или чтения файла, необходимого для работы базы данных (файла БД, файла
журнала транзакций и проч.). Типичным примером является отказ дисковой
головки, который приводит к потере всех файлов на данном устройстве. В
этой ситуации сервер БД не может продолжать работу, и для восстановления
базы данных требуется участие человека (обычно, администратора базы
данных - АБД).
5. Ошибка пользователя. Например, пользователь может случайно удалить
нужные записи или таблицы. Ошибки пользователей могут потребовать
участия человека (АБД) для восстановления базы данных в состояние на
момент возникновения ошибки. Таким образом, после некоторых сбоев
система может восстановить БД автоматически, а ошибка пользователя или
сбой диска требуют участия в восстановлении человека.
372. Средства физической защиты данных
В качестве средств физической защиты данных чаще всего применяютсярезервное копирование и журналы транзакций.
Резервное копирование означает периодическое сохранение файлов БД
на внешнем запоминающем устройстве. Оно выполняется тогда, когда
состояние файлов БД является непротиворечивым. Резервная копия (РК)
не должна создаваться на том же диске, на котором находится сама БД,
т.к. при аварии диска базу невозможно будет восстановить. В случае сбоя
(или аварии диска) БД восстанавливается на основе последней копии.
Полная резервная копия включает всю базу данных (все файлы БД, в том
числе вспомогательные, состав которых зависит от СУБД). Частичная
резервная копия включает часть БД, определённую пользователем.
Резервная копия может быть инкрементной: она состоит только из тех
блоков (страниц памяти), которые изменились со времени последнего
резервного копирования.
Создание инкрементной копии происходит быстрее, чем полной, но оно
возможно только после создания полной резервной копии.
373.
Создание частичной и инкрементной РК выполняется средствами СУБД, асоздание полной РК – средствами СУБД или ОС (например, с помощью
команды copy). В резервную копию, созданную средствами СУБД, обычно
включаются только те блоки памяти, которые реально содержат данные (т.е.
пустые блоки, выделенные под объекты БД, в резервную копию не входят).
Периодичность резервного копирования определяется администратором
системы и зависит от многих факторов: объём БД, интенсивность запросов к
БД, интенсивность обновления данных и др. Как правило, технология
проведения резервного копирования такова:
• раз в неделю (день, месяц) осуществляется полное копирование;
• раз в день (час, неделю) – частичное или инкрементное копирование.
Все изменения, произведённые в данных после последнего резервного
копирования, утрачиваются; но при наличии архива журнала транзакций их
можно выполнить ещё раз, обеспечив полное восстановление БД на момент
возникновения сбоя. Дело в том, что журнал транзакций содержит сведения
только о текущих транзакциях. После завершения транзакции информация о
ней может быть перезаписана. Для того чтобы в случае сбоя обеспечить
возможность полного восстановления БД, необходимо вести архив журнала
транзакций, т.е. сохранять копии файлов журнала транзакций вместе с
резервной копией базы данных.
374. Восстановление базы данных
В том случае, если нельзя восстановить БД после сбоя автоматически,восстановление БД выполняется в два этапа:
1. перенос на рабочий диск резервной копии базы данных (или той её части,
которая была повреждена);
2. перезапуск сервера БД с повторным проведением всех транзакций,
зафиксированных после создания резервной копии и до момента
возникновения сбоя.
Если в системе есть архив транзакций, то повторное проведение транзакций
может проходить автоматически или под управлением пользователя.
Если произошёл сбой процесса сервера, то требуется перезагрузка сервера для
восстановления БД. При перезагрузке СУБД может по содержимому системных
файлов узнать, что произошёл сбой, и выполнить восстановление
автоматически (если это возможно). Восстановление БД в этой ситуации
означает приведение всех данных в БД в согласованное состояние, т.е. откат
незавершённых транзакций и проверку того, что все изменения, внесённые
завершёнными транзакциями, попали на диск.
375.
Для оптимизации регистрации изменений некоторые СУБД могут записывать вжурнал информацию о незавершённых транзакциях, предвидя их
завершение. Более того, не дожидаясь подтверждения транзакции, СУБД
переписывает на диск модифицированные блоки (при формировании
контрольной точки). Поэтому в каждый момент времени в журнале
транзакций и в БД может находиться небольшое число записей,
модифицированных незавершёнными транзакциями. Эти записи помечаются
соответствующим образом. С другой стороны, т.к. изменения сначала
попадают в журнал транзакций и только потом в файл базы данных, в любой
момент времени БД может не содержать блоков данных, модифицированных
подтверждёнными транзакциями. Поэтому в результате сбоя могут возникнуть
две потенциальные ситуации:
• Блоки, содержащие подтверждённые модификации, не были записаны в
файлы данных, так что эти изменения отражены лишь в журнале транзакций.
Следовательно, журнал транзакций содержит подтверждённые данные,
которые должны быть переписаны в файлы данных.
• Журнал транзакций и блоки данных содержат изменения, которые не были
подтверждены. Изменения, внесенные неподтверждёнными транзакциями,
во время восстановления БД должны быть удалены из файлов данных.
376.
Для того чтобы разрешить эти ситуации, СУБД автоматически выполняетдва этапа при восстановлении после сбоев: прокрутку вперед и
прокрутку назад.
1. Прокрутка вперед заключается в применении к файлам данных всех
изменений, зарегистрированных в журнале транзакций. После прокрутки
вперед файлы данных содержат все как подтверждённые, так и
неподтверждённые изменения, которые были зарегистрированы в
журнале транзакций.
2. Прокрутка назад заключается в отмене всех изменений, которые не
были подтверждены. Для этого используются журнал транзакций и
сегменты отката, информация из которых позволяет определить и
отменить те транзакции, которые не были подтверждены, хотя и попали
на диск в файлы БД.
После выполнения этих этапов восстановления БД находится в
согласованном состоянии и с ней можно работать.
377. Защита от несанкционированного доступа
Под функцией секретности данных понимается защита данных от преднамеренногоискажения и/или доступа пользователей или посторонних лиц. Для этого вся
информация делится на общедоступные данные и конфиденциальные, доступ к
которым разрешен только для отдельных групп лиц. Решение этого вопроса относится к
компетенции юридических органов или
администрации предприятия, для которого создаётся БД, и является внешней
функцией по отношению к БД.
Рассмотрим техническую сторону обеспечения защиты данных в БД от
несанкционированного доступа. Общий принцип управления доступом к базе
данных такой: СУБД не должна разрешать пользователю выполнение какой-либо
операции над данными, если он не получил на это права.
Санкционирование доступа к данным осуществляется администратором БД. В
обязанности администратора БД входит:
• назначение отдельным группам пользователей прав доступа (привилегий) к
отдельным группам данных в соответствии с правилами ПО;
• организация системы контроля доступа к данным;
• тестирование вновь создаваемых средств защиты данных;
• периодическое проведение проверок правильности работы системы защиты,
исследование и предотвращение сбоев в её работе.
378. Парольная идентификация
заключается в присвоении каждому пользователю двух параметров:имени (login) и пароля (password). При входе в систему она запрашивает у
пользователя его имя, а для подтверждения того, что это имя ввёл его
владелец, система запрашивает пароль. Имя выдаётся пользователю при
регистрации администратором, пароль пользователь устанавливает сам.
При задании пароля желательно соблюдать следующие требования:
• длина пароля должна быть не менее 6-и символов;
• пароль должен содержать комбинацию букв и цифр или специальных
знаков, пароль не может содержать пробелы;
• пароли должны часто меняться.
Для контроля выполнения этих требований обычно применяются
специальные программы.
379. Предоставление прав доступа (привилегий)
В системах, поддерживающих язык SQL, осуществляется с помощью двухкоманд:
1. GRANT – предоставление одной или нескольких привилегий
пользователю (или группе пользователей):
GRANT { <список привилегий> | ALL PRIVILEGES } ON <имя объекта> TO
{<список пользователей> | PUBLIC} [WITH GRANT OPTION];
где <список привилегий> – набор прав, которые необходимо
предоста вить, или ALL PRIVILEGES – все права на данный объект;
<имя объекта> – имя объекта БД, к которому предоставляется доступ;
<список пользователей> – перечень пользователей (или ролей, см.
дальше), которым будут предоставлены указанные права; PUBLIC –
предопределённый пользователь, привилегии которого доступны всем
пользователям БД. WITH GRANT OPTION – ключевые слова, дающие
возможность пользователям из списка пользователей предоставлять
назначенные права другим пользователям (т.е. передавать эти права).
380.
Права, подразумеваемые под словами ALL PRIVILEGES, зависят от типаобъекта. Примерный перечень прав в зависимости от типа объекта БД
приведён в табл. 6.1.
Таблица 6.1. Использование объектных привилегий
Привилег
ия
Операции
Таблицы
Представле
ния
Процедурн
ые
ALTER
изменение
определения
объекта
+
+
+
DELETE
удаление данных
+
+
...
EXECUTE
выполнение объекта
...
...
+
INSERT
добавление
+
+
...
SELECT
чтение данных
+
+
...
UPDATE
изменение данных
+
+
...
Примечание: процедурные объекты – это хранимые процедуры и
функции.
381. 2. REVOKE – отмена привилегий:
REVOKE [GRANT OPTION FOR] { <список привилегий> | ALL PRIVILEGES }ON <имяобъекта> FROM {<список пользователей> | PUBLIC} { RESTRICT |
CASCADE };
где [GRANT OPTION FOR] – отмена права передачи привилегий;
CASCADE – при отмене привилегий у пользователя отменяются все
привилегии, которые он передавал другим пользователям;
RESTRICT – если при отмене привилегий у пользователя необходимо
отменить переданные другим пользователям привилегии, то операция
завершается с ошибкой.
Другие ключевые слова имеют то же значение, что и в команде GRANT.
382. Роль
Для того чтобы упростить процесс управления доступом, многие СУБДпредоставляют возможность объединять пользователей в группы или
определять роли. Роль – это совокупность привилегий, предоставляемых
пользователю и/или другим ролям. Такой подход позволяет предоставить
конкретному пользователю определённую роль или отнести его к
определённой группе пользователей, обладающей набором прав в
соответствии с задачами, которые на неё возложены.
383. Системные привилегии
Кроме привилегий на доступ к объектам СУБД ещё может поддерживатьтакназываемые системные привилегии: это права пользователя на
создание/изменение/удаление (create/alter/drop) объектов различных
типов. Внекоторых системах такими привилегиями обладают только
пользователи, включённые в группу АБД. Другие СУБД предоставляют
возможностьназначения дифференцированных системных привилегий
любому пользователюв случае такой необходимости. Например, в СУБД
Oracle права на созданиетаблиц и представлений пользователю manager
можно предоставить с помощьютой же команды GRANT, только без
указания объекта:
GRANT create table, create view TO manager;
384. ПЕРСПЕКТИВЫ РАЗВИТИЯ ТЕХНОЛОГИИ БАЗ ДАННЫХ
Вот уже более 50-и лет базы данных являются одной из одной из наиболее широко востребованныхинформационных технологий.
Некоторые авторы утверждают, что появление баз данных стало самым важным достижением в
области программного обеспечения.
Системы баз данных коренным образом изменили работу многих организаций, и практически нет
такой области деятельности, которую они не затронули. К числу наиболее важных и перспективных
направлений развития БД
следует отнести следующие:
Хранилища данных и OLAP-обработка.
Хранилище данных – это предметно-ориентированный, интегрированный, привязанный ко
времени и неизменяемый набор данных, предназначенный для поддержки принятия решений.
Хранилище данных позволяют сохранять исторические данные с целью анализа и прогнозирования
развития ситуаций. При правильном проектировании хранилище данных даёт высокую отдачу за
счёт более качественного управления работой организации (предприятия). Данные в хранилище
данных обрабатываются с помощью OLAP (online analytical processing) – инструментов оперативной
аналитической обработки данных. OLAP позволяет быстро производить расчёты над огромными
объёмами данных, в том числе, с целью выявления динамики изменения различных параметров
(параметры задаются аналитиком).
385.
Работа с неточными данными.Информация в базах данных часто содержит ошибки или является неполной. Результаты
запроса по такой БД могут сильно отличаться от реального положения дел.
Процессор запросов, работающий с вероятностями, коэффициентами доверия,
коэффициентами полноты и т.д. позволил бы учитывать степень достоверности данных при
принятии решений на основе этих данных.
Новые пользовательские интерфейсы.
Это одно из наиболее актуальных направлений современных информационных технологий.
Конечные пользователи не знают язык запросов (SQL), и для получения информации из БД
вынуждены пользоваться интерфейсами, которые для них создают программисты. В
приложения обычно включают некоторый набор готовых запросов и возможность
сформулировать произвольный запрос с помощью некоего конструктора. Но для того, чтобы
воспользоваться конструктором, пользователь должен знать структуру базы данных и хорошо
разбираться в предложенном ему формализме ПО. Наиболее естественным видом является
запрос к БД, сформулированный на естественном языке (ЕЯ). Но для таких запросов
характерны неточности и неоднозначность. Решение этой задачи невозможно без
использования знаний о предметной области и о структуре языка. Одним из вариантов
решения этой проблемы являются онтологии. Под онтологией понимается определённым
образом формализованная система знаний о предметной области, описывающая,
классифицирующая и увязывающая между собой понятия этой ПО. Интеграция онтологий и
баз данных позволит пользователям задавать запросы в собственной терминологии с
использованием ограниченного естественного языка. Это упростит создание и сопровождение
приложений и повысит эффективность использования БД.
386.
Проблемы оптимизации запросов.Помимо остающейся актуальной задачи поиска новых способов оптимизации, можно выделить
ещё две серьёзные проблемы оптимизации: обработка неструктурированных запросов (возможно,
на ограниченном естественном языке), и оптимизация группы запросов. Работа с
неструктурированными запросами особенно актуальна в свете использования баз данных в
поисковых системах (в том числе, при поиске в Internet). А оптимизация группы одновременно
выполняющихся запросов позволит улучшить характеристики СУБД с точки зрения быстродействия.
Интеграция разнородных и слабо формализованных данных.
Изначально базы данных предназначались для хранения и обработки фактографических хорошо
структурированных данных. Но огромное количество данных представлено в различных
графических и мультимедийных форматах. Включение в СУБД способов обработки подобных
данных позволяет использовать технологии баз данных в таких сферах, как, например, ГИС
(геоинформационные системы), издательские системы (с поддержкой вёрстки номеров издания),
САПР (системы автоматизации проектирования) и т.д.
Организация доступа к базам данных через Internet.
Многие web-сайты содержат динамическую информацию, например, о товарах и ценах в Internetмагазинах. В локальных системах такая информация традиционно хранится в базах данных.
Интеграция
СУБД в web-среду позволяет сохра-нить все преимущества баз данных для использования в webприложениях. Основными задачами здесь являются:
a. организация эффективного интерфейса, рассчитанного на неподготовленного пользователя;
b. оптимизация запросов, направленная на уменьшение сетевого трафика;
c. повышение производительности СУБД в многопользовательском режиме работы.
387.
Самоадаптация.Современные СУБД имеют широкие возможности по на-стройке баз данных под
конкретную предметную область и аппаратные средства. Но использование этих
возможностей – достаточно сложная задача, которая требует наличия
высококвалифицированного администратора БД. Для
упрощения настройки и сопровождения БД СУБД должна брать на себя большинство
функций настройки и выполнять их в автоматическом или автоматизированном режиме.
Использование GRID.
GRID – это концепция объединения вычислительных ресурсов в единую сеть. В качестве
аналогии здесь можно привести электрические сети: при возникновении потребности
пользователь просто подключается к сети и получает электричество. Точно так же при
возникновении потребности в вычислениях пользователь должен просто подключаться к
GRID и получать вычислительные ресурсы. Преимущества этого подхода очевидны:
возможность решать более ресурсоёмкие задачи и
перераспределять нагрузку на узлы сети. Но и нерешённых проблем здесь тоже достаточно,
поэтому это задача будущего. Тем не менее, первые промышленные GRID-системы уже
существуют, но поддерживают они только базы данных систем Oracle G (G – это сокращение
от GRID). Они динамически выделяют ре-сурсы для выполнения задач пользователя по
доступу к БД Oracle и перераспределяют нагрузку на узлы сети с целью оптимизации
использования вычислительных ресурсов и повышения общей производительности
системы.
388.
Сохранность данных.Количество накопленных цифровых данных в мире огромно. Но со временем устаревают и
форматы хранения данных, и средства доступа к ним. Происходит также старение
носителей: размагничиваются магнитные ленты и диски, изменяются оптические и
физические свойства носителя. Поэтому даже архивированные данные могут стать
недоступными, особенно если нет устройства для чтения устаревшего носителя или
отсутствует возможность запустить приложение, которое может читать устаревший формат.
Решить эту проблему могут средства, обеспечивающие миграцию данных в новые
форматы с сохранением их описания (т.е. метаданных).
Технологии разработки данных и знаний (data mining и knowledge mining).
Технологии разработки данных предназначены для поиска неочевидных тенденций и
скрытых закономерностей в больших объёмах данных. А knowledge mining – это извлечение
знаний из баз данных (или из хранилища данных). Здесь используются как формальные
методы (регрессионный,
корреляционный и другие виды статистического анализа), так и методы интеллектуальной
обработки данных, основанные на моделировании познавательных механизмов –
индукции, дедукции, абдукции.
Абдукция (от лат. ab- «c, от» + лат. dūcere «водить») — познавательная процедура
выдвижения гипотез, иногда называемая также «выведение наилучшего объяснения»;
метод логического мышления, цель которого — дать максимально правдоподобную
интерпретацию тому, что считается истинным.
389. PostgreSQL
PostgreSQL — наиболее полнофункциональная,свободно распространяемая СУБД с открытым
кодом.
Разработанная в академической среде, за долгую
историю сплотившая вокруг себя широкое
сообщество разработчиков, эта СУБД обладает
всеми возможностями, необходимыми большинству
заказчиков.
PostgreSQL активно применяется по всему миру для
создания критичных бизнес-систем, работающих
под большой нагрузкой.
390. История
Cовременный PostgreSQL ведет происхождение от проекта POSTGRES,который разрабатывался под руководством Майкла Стоунбрейкера
(Michael Stonebraker), профессора Калифорнийского университета в
Беркли.
Работа над проектом началась в 1985 году, и до 1988 года был
опубликован ряд научных статей, описывающих модель данных, язык
запросов POSTQUEL (в то время SQL еще не был общепризнанным
стандартом) и устройство хранилища данных.
POSTGRES иногда относят к так называемым постреляционным СУБД.
Ограниченность реляционной модели всегда была предметом критики,
хотя и являлась обратной стороной ее простоты и строгости.
Проникновение компьютерных технологий во все сферы жизни привело
к появлению новых классов приложений и потребовало от баз данных
поддержки нестандартных типов данных и таких возможностей, как
наследование, создание сложных объектов и управление ими.
391. История
Первая СУБД была выпущена в 1989 году. База данныхсовершенствовалась на протяжении нескольких лет, а в 1993 году, когда
вышла версия 4.2, проект был закрыт.
В 1996 году было выбрано новое имя — PostgreSQL, которое отражает
связь и с оригинальным про ектом POSTGRES, и с переходом на SQL.
Надо признать, что название получилось сложновыговариваемым, но
тем не менее: PostgreSQL следует произносить как «постгрес-куэль» или
просто «постгрес», но только не «постгре».
Новая версия стартовала как 6.0, продолжая исходную нумерацию.
Проект вырос, и управление им взяла на себя поначалу небольшая
группа инициативных пользователей и разработчиков, которая получила
название Глобальной группы разработки PostgreSQL (PostgreSQL Global
Develop ment Group).
Все основные решения о планах развития и выпусках новых версий
принимаются Управляющим комитетом (Core team), состоящим сейчас из
семи человек.
392. История
Вклад российских разработчиков в PostgreSQL весьма значителен. Это,пожалуй, самый крупный глобальный проект с открытым исходным
кодом с таким широким российским представительством.
Глобальная группа разработки PostgreSQL выполняет поддержку
основных версий системы в течение пяти лет с момента выпуска. Эта
поддержка, как и координация разработки, осуществляется через списки
рассылки. Корректно оформленное сообщение об ошибке имеет все
шансы на скорейшее решение: нередки случаи, когда исправления
ошибок выпускаются в течение суток.
Помимо поддержки сообществом разработчиков, ряд компаний по
всему миру осуществляет коммерческую поддержку PostgreSQL. В России
такой компанией является Postgres Professional (postgrespro.ru),
предоставляя услуги по поддержке в режиме 24x7.
Используется в Сбере, Институте технической физики (Саров), Фирма
«1С», Ростелеком
393. Современное состояние
PostgreSQL является одной из самых популярных баз данных. За своюболее чем 20-летнюю историю развития на прочном фундаменте,
заложенном академической разработкой, PostgreSQL выросла в
полноценную СУБД уровня предприятия и составляет реальную
альтернативу коммерческим базам данных.
Позволяет
• настраивать горячее резервирование, восстановление на заданный
момент времени в прошлом, различные виды репликации
• создание и управление пользователями и групповыми ролями,
разграничение доступа к объектам БД на уровне как отдельных
пользователей, так и групп; детальное управление доступом на
уровне отдельных столбцов и строк;
• по мере развития стандарта ANSI SQL его поддержка постоянно
добавляется в PostgreSQL. Это относится ко всем версиям стандарта от
SQL-92 до самой последней SQL:2016;
• PostgreSQL обеспечивает полную поддержку свойств ACID и
обеспечивает эффективную изоляцию транзакций;
394.
• всевозможные языки серверного программирования: встроенный PL/pgSQL(удобный своей тесной интеграцией с SQL), C для критичных по
производительности задач, Perl, Python, Tcl, а также JavaScript, Java и другие;
• PostgreSQL эффективно использует современную архитек туру
многоядерных процессоров — производительность СУБД растет практически
линейно с увеличением количества ядер;
• для горизонтального масштабирования PostgreSQL предоставляет
возможности репликации, как физической, так и логической. Это позволяет
строить на базе PostgreSQL кластеры для решения задач отказоустойчивости,
высокой производительности, географической распределенности;
• PostgreSQL работает на операционных системах семейства Unix, включая
серверные и клиентские разновидности Linux, FreeBSD, Solaris и macOS, а
также на Windows;
• либеральная лицензия PostgreSQL, сходная с лицензиями BSD и MIT,
разрешает неограниченное использование СУБД, модификацию кода, а
также включение в состав других продуктов, в том числе закрытых и
коммерческих;
• tgreSQL не принадлежит ни одной компании и развивается международным
сообществом, в том числе и российскими разработчиками.
395. Установка под Windows
• Описана вhttps://postgrespro.ru/wi
ndows
При установке PostgreSQL в
вашей системе
регистрируется служба
«postgresql-14». Она
запускается автоматически
при старте компьютера под
учетной записью Network
Service (Сетевая служба).
При необходимости вы
можете изменить
параметры службы с
помощью стандартных
средств Windows.
396. Подключение с помощью psql
Это терминальный клиент psql, работа с которым происходитинтерактивно в режиме командной строки.
• psql — стандартный клиент, он входит в любую сборку PostgreSQL и
поэтому всегда под рукой.
• psql действительно удобен для решения повседневных задач по
администрированию баз данных, для написания небольших запросов
и автоматизации процессов
• если вы привыкли работать с графическими пользовательскими
интерфейсами, попробуйте pgAdmin:
wiki.postgresql.org/wiki/Community_Guide_to_PostgreSQL_GUI_Tools
397. Таблицы
В реляционных СУБД данные представляются в виде таблиц. Заголовоктаблицы определяет столбцы; собственно данные располагаются в
строках. Данные не упорядочены (в частности, нельзя полагаться на то,
что строки хранятся в порядке их добавления в таблицу).
Для каждого столбца устанавливается тип данных; значения
соответствующих полей строк должны удовлетворять этим типам.
PostgreSQL располагает большим числом встроенных типов
(postgrespro.ru/doc/datatype) и возможностями для создания новых
Давайте создадим таблицу дисциплин, читаемых в вузе:
test=# CREATE TABLE courses(
test(# c_no text PRIMARY KEY,
test(# title text,
test(# hours integer
test(# );
CREATE TABLE
398.
Обратите внимание, как меняется приглашение psql: этоподсказка, что ввод команды продолжается на новой строке.
В дальнейшем для удобства мы не будем дублировать
приглашение на каждой строке.
Кроме столбцов и типов данных мы можем определить
ограничения целостности, которые будут автоматически
проверяться — СУБД не допустит появление в базе
некорректных данных. В нашем примере мы добавили
ограничение PRIMARY KEY для столбца c_no, которое говорит
о том, что значения в этом столбце должны быть
уникальными, а неопределенные значения не допускаются.
Точный синтаксис команды CREATE TABLE можно посмотреть
в документации, а можно прямо в psql:
test=# \help CREATE TABLE
399. Наполнение таблиц
Добавим в созданную таблицу несколько строк:test=# INSERT INTO courses(c_no, title, hours)
VALUES ('CS301', 'Базы данных', 30),
('CS305', 'Сети ЭВМ', 60);
INSERT 0 2
Если вам требуется массовая загрузка данных из внешнего
источника, команда INSERT — не лучший выбор; посмотрите
на специально предназначенную для этого команду COPY:
postgrespro.ru/doc/sql-copy
400. Таблицы для примеров
Для дальнейших примеров нам потребуется еще две таблицы: студентыи экзамены. Для каждого студента будем хранить его имя и год
поступления; идентифицироваться он будет числовым номером
студенческого билета.
test=# CREATE TABLE students(
s_id integer PRIMARY KEY,
name text,
start_year integer
);
CREATE TABLE
test=# INSERT INTO students(s_id, name, start_year)
VALUES (1451, 'Анна', 2014),
(1432, 'Виктор', 2014),
(1556, 'Нина', 2015);
INSERT 0 3
401.
Экзамен содержит оценку, полученную студентом по некоторойдисциплине. Таким образом, студенты и дисциплины связаны друг с
другом отношением «многие ко многим»: один студент может сдавать
экзамены по многим дисциплинам, а экзамен по одной дисциплине
могут сдавать много студентов.
Запись в таблице экзаменов идентифицируется совокупностью номера
студбилета и номера курса. Такое ограничение целостности, относящее
сразу к нескольким столбцам, определяется с помощью фразы
CONSTRAINT:
test=# CREATE TABLE exams(
s_id integer REFERENCES students(s_id),
c_no text REFERENCES courses(c_no),
score integer,
CONSTRAINT pk PRIMARY KEY(s_id, c_no)
);
CREATE TABLE
402.
кроме того, с помощью фразы REFERENCES мы определили дваограничения ссылочной целостности, называемые внешними ключами.
Такие ограничения показывают, что значения в одной таблице ссылаются
на строки в другой таблице.
403.
Теперь при любых действиях СУБД будет проверять, что всеидентификаторы s_id, указанные в таблице экзаменов, соответствуют
реальным студентам (то есть записям в таблице студентов), а номера
c_no — реальным курсам. Таким образом, будет исключена возможность
оценить несуществующего студента или поставить оценку по
несуществующей дисциплине — независимо от действий пользователя
или возможных ошибок в приложении.
Поставим нашим студентам несколько оценок:
test=# INSERT INTO exams(s_id, c_no, score)
VALUES (1451, 'CS301', 5),
(1556, 'CS301', 5),
(1451, 'CS305', 5),
(1432, 'CS305', 4);
INSERT 0 4
404. Простые запросы
Чтение данных из таблиц выполняется оператором SQL SELECT.Например, выведем только два столбца из таблицы courses:
test=# SELECT title AS course_title, hours
FROM courses;
course_title
| hours
--------------+------Базы данных
| 30
Сети ЭВМ
| 60
(2 rows)
Конструкция AS позволяет переименовать столбец, если это необходимо.
Чтобы вывести все столбцы, достаточно указать символ звездочки:
test=# SELECT * FROM courses;
c_no
| title
| hours
-------+-------------+------CS301 | Базы данных | 30
CS305 | Сети ЭВМ
| 60
(2 rows)
405.
В результирующей выборке мы можем получить несколько одинаковыхстрок. Даже если все строки были различны в исходной таблице,
дубликаты могут появиться, если выводятся не все столбцы:
test=# SELECT start_year FROM students;
start_year
-----------2014
2014
2015
(3 rows)
Чтобы выбрать все различные года поступления, после SELECT надо
добавить слово DISTINCT:
test=# SELECT DISTINCT start_year FROM students;
start_year
-----------2014
2015
(2 rows)
406.
Обычно при выборке данных требуется получить не все строки, а толькоте, которые удовлетворят какому-либо условию. Такое условие
фильтрации записывается во фразе WHERE:
test=# SELECT * FROM courses WHERE hours > 45;
c_no | title | hours
-------+----------+------CS305 | Сети ЭВМ | 60
(1 row)
Условие должно иметь логический тип. Например, оно может содержать
отношения =, <> (или !=), >, >=, <, <=; может объединять более простые
условия с помощью логических операций AND, OR, NOT и круглых скобок
— как в обычных языках программирования.
407.
Тонкий момент представляет собой неопределенное значение NULL. Врезультирующую таблицу попадают только те строки, для которых
условие фильтрации истинно; если же значение ложно или не
определено, строка отбрасывается.
Учтите:
• результат сравнения чего-либо с неопределенным значением не
определен;
• результат логических операций с неопределенным значением, как
правило, не определен (исключения: true
OR NULL = true, false AND NULL = false);
• для проверки определенности значения используются специальные
отношения IS NULL (IS NOT NULL) и IS DISTINCT FROM (IS NOT DISTINCT
FROM), а также бывает удобно воспользоваться функцией coalesce.
408. Соединения
Грамотно спроектированная реляционная база данных не содержит избыточныхданных. Например, таблица экзаменов не должна содержать имя студента,
потому что его можно найти в другой таблице по номеру студенческого билета.
Получим оценки по всем дисциплинам, сопоставляя курсы с теми экзаменами,
которые проводились именно по данному курсу:
test=# SELECT courses.title, exams.s_id, exams.score
FROM courses, exams
WHERE courses.c_no = exams.c_no;
title
| s_id | score
-------------+------+------Базы данных
| 1451 | 5
Базы данных
| 1556 | 5
Сети ЭВМ
| 1451 | 5
Сети ЭВМ
| 1432 | 4
(4 rows)
409.
В результат не включаются строки исходной таблицы, для которых не нашлосьпары в другой таблице: хотя условие наложено на дисциплины,
но при этом исключаются и студенты, которые не сдавали экзамен по данной
дисциплине. Чтобы в выборку попали все студенты, надо использовать
внешнее соединение:
test=# SELECT students.name, exams.score
FROM students
LEFT JOIN exams
ON students.s_id = exams.s_id
AND exams.c_no = 'CS305';
name | score
--------+------Анна | 5
Виктор | 4
Нина |
(3 rows)
410. Подзапросы
Оператор SELECT формирует таблицу, которая может быть выведена в качестверезультата, а может быть использована в другой конструкции языка SQL в любом
месте, где по смыслу может находиться таблица. Такая вложенная команда
SELECT, заключенная в круглые скобки, называется подзапросом. Если подзапрос
возвращает ровно одну строку и ровно один столбец, его можно использовать
как обычное скалярное
выражение:
test=# SELECT name,
(SELECT score
FROM exams
WHERE exams.s_id = students.s_id
AND exams.c_no = 'CS305')
FROM students;
name | score
--------+------Анна | 5
Виктор | 4
Нина |
411.
Если подзапрос возвращает ровно одну строку и ровно один столбец, егоможно использовать как обычное скалярное выражение:
test=# SELECT name,
(SELECT score
FROM exams
WHERE exams.s_id = students.s_id
AND exams.c_no = 'CS305')
FROM students;
name | score
--------+------Анна | 5
Виктор | 4
Нина |
(3 rows)
Если скалярный подзапрос, использованный в списке выражений SELECT, не
содержит ни одной строки, возвращается неопределенное значение (как в
последней строке результата примера). Поэтому скалярные подзапросы можно
раскрыть, заменив их на соединение, но обязательно внешнее.
412.
В запросе одна и та же таблица может участвовать два раза, или вместотаблицы в предложении FROM мы можем использовать безымянный
подзапрос. В этих случаях после подзапроса можно указать произвольное имя,
которое называется псевдонимом (alias).
Псевдонимы можно использовать и для обычных таблиц. Выведем имена
студентов и их оценки по предмету «Базы данных»:
test=# SELECT s.name, ce.score
FROM students s
JOIN (SELECT exams.*
FROM courses, exams
WHERE courses.c_no = exams.c_no
AND courses.title = 'Базы данных') ce
ON s.s_id = ce.s_id;
name | score
------+------Анна | 5
Нина | 5
(2 rows)
413.
Здесь s — псевдоним таблицы, а ce — псевдоним подзапроса.Псевдонимы обычно выбирают так, чтобы они были короткими, но
оставались понятными.
414. Транзакции
Потребуем, чтобы у каждой группы в обязательном порядке былстароста.
Для этого создадим таблицу групп:
test=# CREATE TABLE groups(
g_no text PRIMARY KEY,
monitor integer NOT NULL REFERENCES students(s_id)
);
CREATE TABLE
Здесь мы использовали ограничение целостности NOT NULL, которое
запрещает неопределенные значения.
415.
Теперь в таблице студентов нам необходим еще один столбец — номергруппы, о котором мы не подумали сразу. К счастью, в уже существующую
таблицу можно добавить новый столбец:
test=# ALTER TABLE students
ADD g_no text REFERENCES groups(g_no);
ALTER TABLE
С помощью команды psql всегда можно посмотреть, какие
столбцы определены в таблице:
test=# \d students
Table "public.students"
Column | Type | Modifiers
------------+---------+---------s_id
| integer
| not null
Name
| text
|
start_year
| integer
|
g_no
| text
|
...
416.
Также можно вспомнить, какие вообще таблицы присут ствуют в базе данных:test=# \d
List of relations
Schema | Name | Type | Owner
--------+----------+-------+---------public | courses | table | postgres
public | exams | table | postgres
public | groups | table | postgres
public | students | table | postgres
(4 rows)
Создадим теперь группу «A-101» и поместим в нее всех сту дентов, а
старостой сделаем Анну.
Тут возникает затруднение. С одной стороны, мы не можем создать группу, не
указав старосту. А с другой, как мы можем назначить Анну старостой, если она
еще не входит в группу? Это привело бы к появлению в базе данных логически
некорректных, несогласованных данных.
417.
Мы столкнулись с тем, что две операции надо совершить одновременно,потому что ни одна из них не имеет смысла без другой. Такие операции,
составляющие логически неделимую единицу работы, называются
транзакцией.
Начнем транзакцию:
test=# BEGIN;
BEGIN
Затем добавим группу вместе со старостой. Поскольку мы не помним наизусть
номер студенческого билета Анны, выполним запрос прямо в команде
добавления строк:
test=*# INSERT INTO groups(g_no, monitor)
SELECT 'A-101', s_id
FROM students
WHERE name = 'Анна';
INSERT 0 1
«Звездочка» в приглашении напоминает о незавершенной транзакции.
418.
Откройте теперь новое окно терминала и запустите еще один процессpsql: это будет сеанс, работающий параллельно с первым. Чтобы не
запутаться, команды второго сеанса мы будем показывать курсивом.
Увидит ли второй сеанс сделанные изменения?
postgres=# \c test
You are now connected to database "test" as user
"postgres".
test=# SELECT * FROM groups;
g_no | monitor
------+--------(0 rows)
Нет, не увидит, ведь транзакция еще не завершена.
Теперь переведем всех студентов в созданную группу:
test=*# UPDATE students SET g_no = 'A-101';
UPDATE 3
419.
И снова второй сеанс видит согласованные данные, актуальные наначало еще не оконченной транзакции:
test=# SELECT * FROM students;
s_id | name | start_year | g_no
------+--------+------------+-----1451 | Анна | 2014 |
1432 | Виктор | 2014 |
1556 | Нина | 2015 |
(3 rows)
А теперь завершим транзакцию, зафиксировав все сделанные
изменения:
test=*# COMMIT;
COMMIT
420.
И только в этот момент второму сеансу становятся доступны всеизменения, сделанные в транзакции, как будто они появились
одномоментно:
test=# SELECT * FROM groups;
g_no | monitor
-------+--------A-101 | 1451
(1 row)
test=# SELECT * FROM students;
s_id | name | start_year | g_no
------+--------+------------+------1451 | Анна | 2014 | A-101
1432 | Виктор | 2014 | A-101
1556 | Нина | 2015 | A-101
(3 rows)
421. Полезные команды psql
\? Справка по командам psql.\h Справка по SQL: список доступных команд или
синтаксис конкретной команды.
\x Переключает традиционный табличный вывод (столбцы и строки) на расширенный
(каждый столбец на отдельной строке) и обратно.
Удобно для просмотра нескольких «широких» строк.
\l Список баз данных.
\du Список пользователей.
\dt Список таблиц.
\di Список индексов.
\dv Список представлений.
\df Список функций.
\dn Список схем.
\dx Список установленных расширений.
\dp Список привилегий.
\d имя Подробная информация по конкретному объекту базы данных.
\d+ имя И еще более подробная информация по конкретному объекту.
\timing on Показывать время выполнения операторов
422. Работа с JSON и JSONB
Реляционные базы данных, использующие SQL, создавались с большимзапасом прочности: первой заботой их потребителей была целостность и
безопасность данных, а объемы информации были несравнимы с
современными.
Когда появилось новое поколение СУБД — NoSQL, сообщество
призадумалось: куда более простая структура данных (вначале это были
прежде всего огромные таблицы с всего двумя колонками: ключзначение) позволяла ускорить поиск на порядки. Они могли
обрабатывать небывалые объемы информации и легко
масштабировались, вовсю используя параллельные вычисления. В
NoSQL-базах не было необходимости хранить информацию по строкам, а
хранение по столбцам для многих задач позволяло еще больше ускорить
и распараллелить вычисления.
423. Преимущества
Поскольку в реляционных СУБД изменение схемы данных связано сбольшими издержками, оказался как никогда кстати новый тип данных —
JSON. Изначально он предназначался для JS-программистов, отсюда JS в
названии. Он как бы брал сложность добавляемых данных на себя,
позволяя создавать линейные и иерархические структуры-объекты,
добавление которых не требовало пересчета всей базы.
424. JSON
JSON (англ. JavaScript Object Notation) — текстовый формат обменаданными, основанный на JavaScript. Но при этом формат независим от JS
и может использоваться в любом языке программирования.
В качестве значений в JSON могут быть использованы:
• JSON-объект
• Массив
• Число (целое или вещественное)
• Литералы true (логическое значение «истина»), false (логическое
значение «ложь») и null
• Строка
425. Пример
{"query": "Виктор Иван",
"count": 7
}
Объект заключен в фигурные скобки {}
JSON-объект — это неупорядоченное множество пар «ключ:значение».
Ключ — это название параметра, который мы передаем серверу. Он
служит маркером для принимающей запрос системы: «смотри, здесь у
меня значение такого-то параметра!».
Json-объект — это неупорядоченное множество пар «ключ:значение»,
заключённое в фигурные скобки «{ }». Ключ описывается строкой, между
ним и значением стоит символ «:». Пары ключ-значение отделяются друг
от друга запятыми.
426. JSON-массив
Это массив: [ "MALE", "FEMALE" ]Массив заключен в квадратные скобки []
Внутри квадратных скобок идет набор значений. Тут нет ключей, как в
объекте, поэтому обращаться к массиву можно только по номеру
элемента. И поэтому в случае массива менять местами данные внутри
нельзя. Это упорядоченное множество значений.
Внутри массива может быть все, что угодно:
• Цифры [ 1, 5, 10, 33 ]
• Строки [ "MALE", "FEMALE" ]
• Смесь [ 1, "Андрюшка", 10, 33 ]
• Объекты [1, {a:1, b:2}, "такой вот массивчик"]
427.
[{
"value": "Иванов Виктор",
"unrestricted_value": "Иванов Виктор",
"data": {
"surname": "Иванов",
"name": "Виктор",
"patronymic": null,
"gender": "MALE"
}
},
{
"value": "Иванченко Виктор",
"unrestricted_value": "Иванченко Виктор",
"data": {
"surname": "Иванченко",
"name": "Виктор",
"patronymic": null,
"gender": "MALE"
}
},
]
428. JSON vs XML
В SOAP можно применять только XML, там без вариантов.В REST можно применять как XML, так и JSON. Разработчики отдают
предпочтение json-формату, потому что он проще воспринимается и меньше
весит. В XML есть лишняя обвязка, название полей повторяется дважды
(открывающий и закрывающий тег).
SOAP (от англ. Simple Object Access Protocol — простой протокол доступа к
объектам) — протокол обмена структурированными сообщениями в
распределённой вычислительной среде. Протокол используется для обмена
произвольными сообщениями в формате XML, а не только для вызова
процедур.
REST (Representational State Transfer) — на самом деле архитектурный стиль, а
не протокол. В отличие от SOAP, REST не подкреплен официальным стандартом.
Фактически, он основывается на соглашениях. Веб-сервис, построенный с
учетом всех требований и ограничений архитектурного стиля, можно назвать
RESTful веб-сервисом.
REST не использует конвертацию данных при передаче, данные передаются в
исходном виде — это снижает нагрузку на клиент веб-сервиса, но увеличивает
нагрузку на сеть.
429. XML
<req><surname>Иванов</surname>
<name>Иван</name>
<patronymic>Иванович</patronymic>
<birthdate>01.01.1990</birthdate>
<birthplace>Москва</birthplace>
<phone>8 926 766 48 48</phone>
</req>
430. JSON
{"surname": "Иванов",
"name": "Иван",
"patronymic": "Иванович",
"birthdate": "01.01.1990",
"birthplace": "Москва",
"phone": "8 926 766 48 48"
}
431. Пример JSON
Допустим, в нашей демобазе студентов появилась возмож ностьввести личные данные: запустили анкету, расспросили
преподавателей. В анкете не обязательно заполнять все пункты, а
некоторые из них включают графу «другое» и «добавьте о себе
данные по вашему усмотрению».
Если бы мы добавили в базу новые данные в привычной манере,
то в многочисленных появившихся столбцах или дополнительных
таблицах было бы большое количество пустых полей. Но еще хуже
то, что в будущем могут появиться новые столбцы, а тогда
придется существенно переделывать всю базу.
432.
Создадим таблицу с объектами JSON:test=# CREATE TABLE student_details(
de_id int,
s_id int REFERENCES students(s_id),
details json,
CONSTRAINT pk_d PRIMARY KEY(s_id, de_id)
);
433.
test=# INSERT INTO student_details(de_id, s_id, details)
VALUES
(1, 1451,
'{ "достоинства": "отсутствуют",
"недостатки":
"неумеренное употребление
мороженого"
}'),
(2, 1432,
'{ "хобби":
{ "гитарист":
{ "группа": "Постгрессоры",
"гитары":["страт","телек"]
}
}
}'),
(3, 1556,
'{ "хобби": "косплей",
"достоинства":
{ "мать-героиня":
{ "Вася": "м",
"Семен": "м",
"Люся": "ж",
"Макар": "м",
"Саша":"сведения отсутствуют"
}
}
}'),
(4, 1451,
'{ "статус": "отчислена"
}');
434.
Cоединим таблицы student_details и studentsпри помощи конструкции WHERE, ведь в
новой таблице отсутствуют имена студентов:
test=# SELECT s.name, sd.details
FROM student_details sd, students s
WHERE s.s_id = sd.s_id
\gx
435.
-[ RECORD 1 ]-------------------------------------name | Аннаdetails | { "достоинства": "отсутствуют", +
| "недостатки": +
| "неумеренное употребление мороженого" +
|}
-[ RECORD 2 ]-------------------------------------name | Виктор
details | { "хобби": +
| { "гитарист": +
| { "группа": "Постгрессоры", +
| "гитары":["страт","телек"] +
|}+
|}+
|}
436.
-[ RECORD 3 ]-------------------------------------name | Нинаdetails | { "хобби": "косплей", +
| "достоинства": +
| { "мать-героиня": +
| { "Вася": "м", +
| "Семен": "м", +
| "Люся": "ж", +
| "Макар": "м", +
| "Саша":"сведения отсутствуют" +
|}+
|}+
|}
-[ RECORD 4 ]-------------------------------------name | Анна
details | { "статус": "отчислена" +
|
437.
Допустим, нас интересуют записи,содержащие информацию о достоинствах
студентов.
test=# SELECT s.name, sd.details
FROM student_details sd, students s
WHERE s.s_id = sd.s_id
AND sd.details ->> 'достоинства' IS NOT NULL
\gx
438.
-[ RECORD 1 ]-------------------------------------name | Аннаdetails | { "достоинства": "отсутствуют", +
| "недостатки": +
| "неумеренное употребление мороженого" +
|}
-[ RECORD 2 ]-------------------------------------name | Нина
details | { "хобби": "косплей", +
| "достоинства": +
| { "мать-героиня": +
| { "Вася": "м", +
| "Семен": "м", +
| "Люся": "ж", +
| "Макар": "м", +
| "Саша":"сведения отсутствуют" +
|}+
|}+
|}
439.
Мы убедились, что две записи имеют отношение кдостоинствам Анны и Нины, однако такой ответ нас вряд ли
удовлетворит: на самом деле достоинства Анны
«отсутствуют».
Скорректируем запрос:
test=# SELECT s.name, sd.details
FROM student_details sd, students s
WHERE s.s_id = sd.s_id
AND sd.details ->> 'достоинства' IS NOT NULL
AND sd.details ->> 'достоинства' != 'отсутствуют';
440.
Попробуем найти, на каких гитарах играет музыкант Витя:test=# SELECT sd.de_id, s.name, sd.details
FROM student_details sd, students s
WHERE s.s_id = sd.s_id
AND sd.details ->> 'гитары' IS NOT NULL
\gx
Запрос ничего не выдаст. Дело в том, что соответствующая
пара ключ-значение находится внутри иерархии JSON, вложена в пары
более высокого уровня:
name | Виктор
details | { "хобби":
+
|
{ "гитарист":
+
|
{ "группа": "Постгрессоры",
+
|
"гитары":["страт","телек"]
+
|
}
+
|
}
+
|}
441.
Чтобы добраться до гитар, воспользуемся оператором #> и спустимся с«хобби» вниз по иерархии:
test=# SELECT sd.de_id, s.name,
sd.details #> '{хобби,гитарист,гитары}'
FROM student_details sd, students s
WHERE s.s_id = sd.s_id
AND sd.details #> '{хобби,гитарист,гитары}'
IS NOT NULL
\gx
и убедимся, что Виктор фанат фирмы Fender:
de_id | name
| ?column?
-------+--------+------------------2
| Виктор
| ["страт","телек"]