






 software
softwareSimilar presentations:


")




 данных")

")
Деление на выборки. Масштабирование признаков. Лабораторная работа 2
1.
Лабораторная работа 2: «Деление на выборки.Масштабирование признаков»
2.
3.
4.
5.
Разбиение на test и train выборкиКак известно, от сессии до сессии живут студенты весело. Однако в какой-то момент сессия все-таки
наступает, и перед учащимися встает вопрос подготовки к экзаменам. У них по большому счету есть
два варианта:
1.Первый вариант. Взять вопросы к экзамену у преподавателя, подготовить билеты и вызубрить их.
Преимуществом такого подхода будут относительно небольшие трудозатраты. Нужно выучить только
то, что написано в билетах. Недостатком будет то, что любой вопрос вне выученного конспекта
поставит экзаменуемого в тупик.
2.Второй вариант. Выучить сам предмет без привязки к билетам. Да, на вопросы билета человек
может отвечать менее бодро, зато у него будет целостная картина того материала, который он, как
надеются преподаватели, учил весь семестр.
Так вот при обучении модели у нас есть точно такой же выбор.
6.
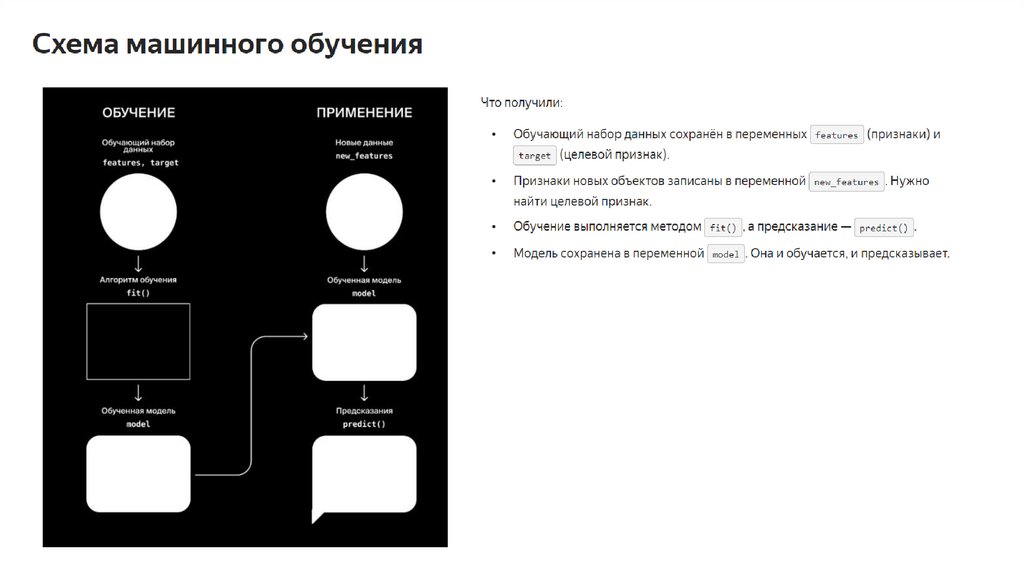
Обучающая и тестовая выборкиЕсли мы будем оценивать качество модели (например, с помощью корня из средней суммы расстояний,
RMSE) на тех же данных, на которых обучали модель, то будем по большому счету заучивать билеты. Когда
же нам встретятся новые данные, наш прогноз уже не будет таким замечательным.
Логичнее разделить данные на обучающую (training data) и тестовую (test data) выборки с тем, чтобы модель
«знала предмет в целом» и не «проваливала экзамен из-за неожиданных вопросов преподавателя», т.е. не
показывала низкого RMSE при встрече с новыми данными (новыми X и y).
Да, во втором случае мы скорее всего несколько снизим качество модели, потому что обучающая и тестовая
выборки будут отличаться. Выигрышем же будет то, что в целом наша модель сможет делать более точные
предсказания.
7.
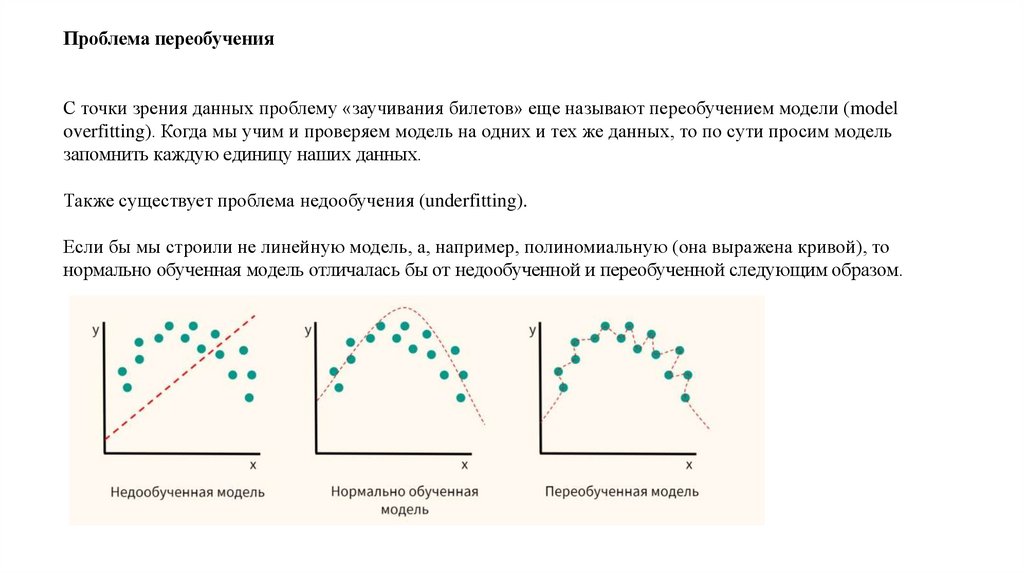
Проблема переобученияС точки зрения данных проблему «заучивания билетов» еще называют переобучением модели (model
overfitting). Когда мы учим и проверяем модель на одних и тех же данных, то по сути просим модель
запомнить каждую единицу наших данных.
Также существует проблема недообучения (underfitting).
Если бы мы строили не линейную модель, а, например, полиномиальную (она выражена кривой), то
нормально обученная модель отличалась бы от недообученной и переобученной следующим образом.
8.
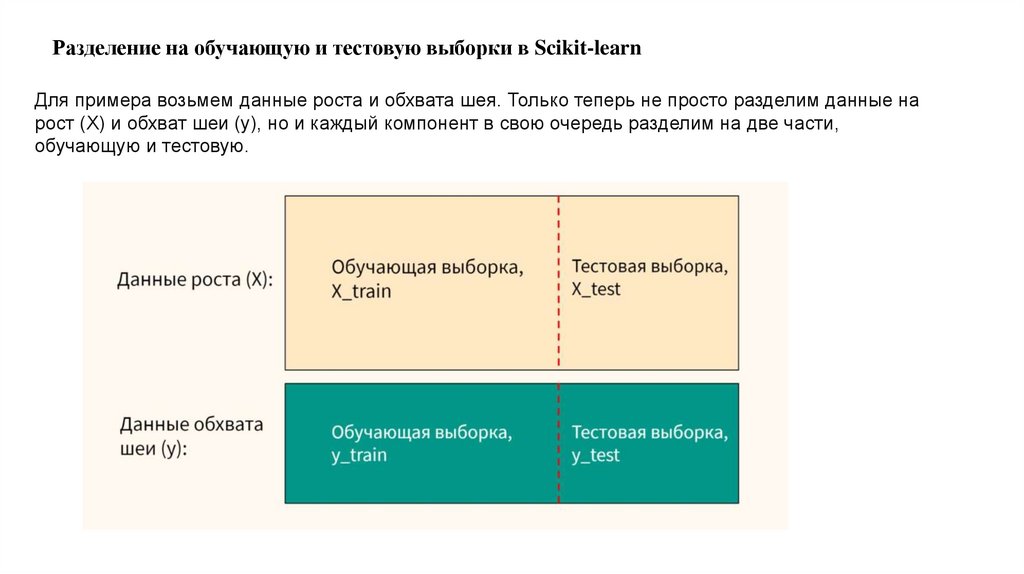
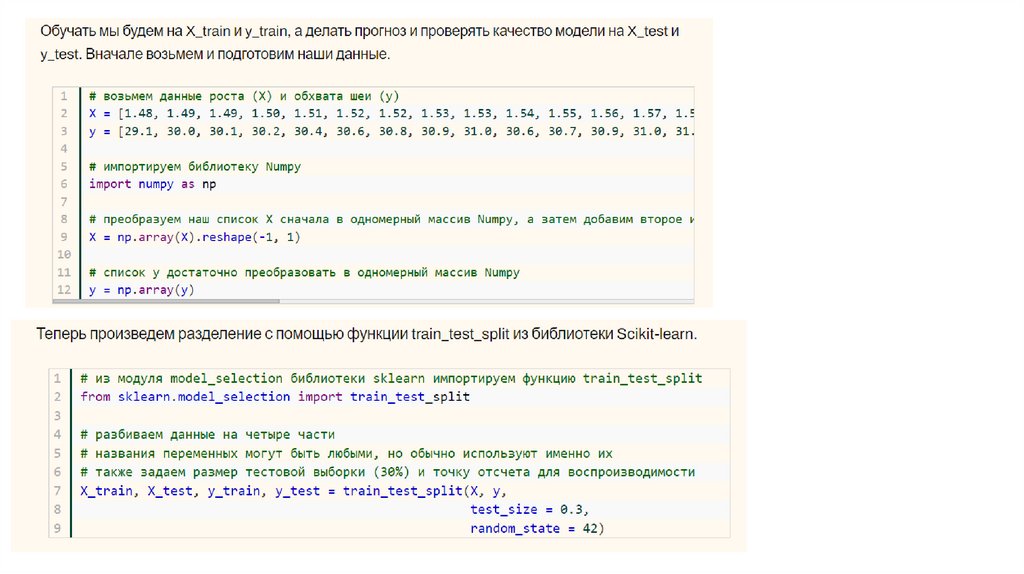
Разделение на обучающую и тестовую выборки в Scikit-learnДля примера возьмем данные роста и обхвата шея. Только теперь не просто разделим данные на
рост (X) и обхват шеи (y), но и каждый компонент в свою очередь разделим на две части,
обучающую и тестовую.
9.
10.
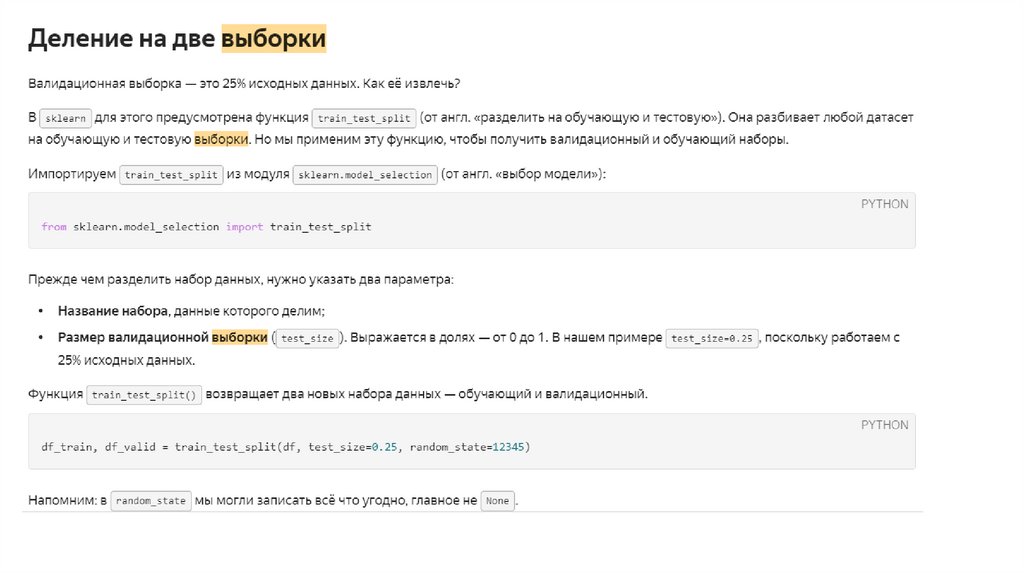
Ссылка на техническую документацию по разделению на тест и трейн выборкиhttps://scikit-learn.org/0.19/modules/generated/sklearn.model_selection.train_test_split.html
Следует отметить, что в решении задачи регрессии да и в любой другой модели перед обучением надо
выбрать ключевой признак, а именно столбец по которому мы будем делать предсказание т.е. если у нас
например стоит задача определить из таблицы уйдет ли клиент из банка или нет, то в технической
документации должно быть прописано, какой столбец является ключевым, например столбец education –
образование, тогда, перед разделением на train и test выборки мы должны выбрать столбец education как
ключевой, а затем убрать его из X выборки.
Ниже представлен пример реализации кода
y = data[[‘education']] # столбец образование выделим как ключевой
X = data.drop(‘education', axis = 1) # для X дропнем его
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33) # разделим на трейн и тест выборки
11.
12.
13.
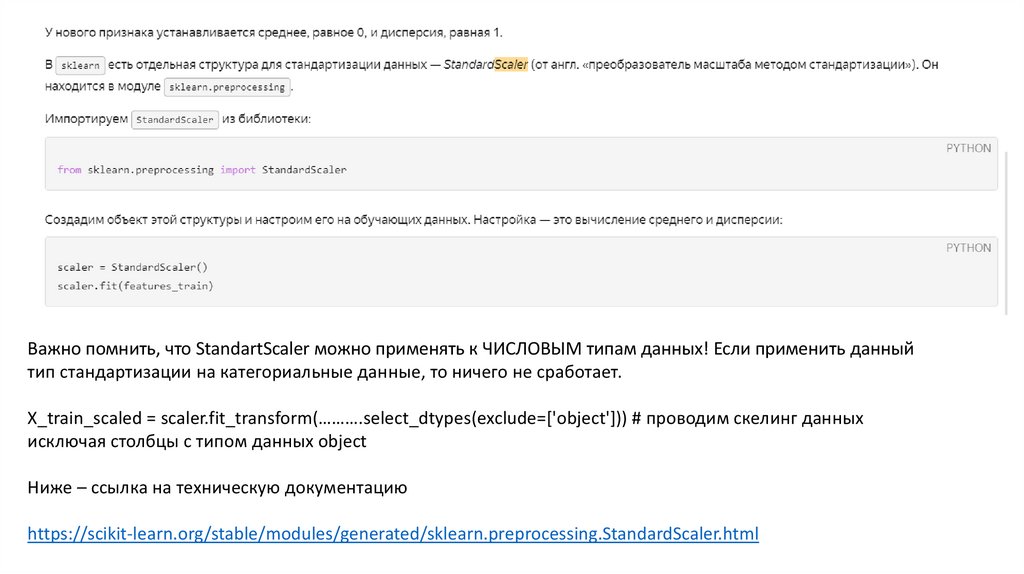
Важно помнить, что StandartScaler можно применять к ЧИСЛОВЫМ типам данных! Если применить данныйтип стандартизации на категориальные данные, то ничего не сработает.
X_train_scaled = scaler.fit_transform(……….select_dtypes(exclude=['object'])) # проводим скелинг данных
исключая столбцы с типом данных object
Ниже – ссылка на техническую документацию
https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.StandardScaler.html
14.
15.
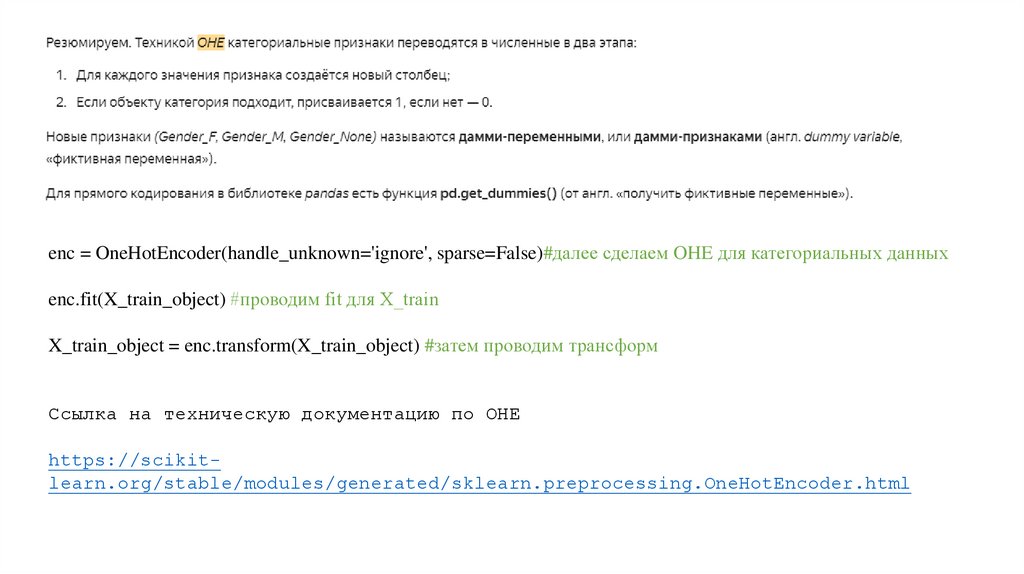
enc = OneHotEncoder(handle_unknown='ignore', sparse=False)#далее сделаем OHE для категориальных данныхenc.fit(X_train_object) #проводим fit для X_train
X_train_object = enc.transform(X_train_object) #затем проводим трансформ
Ссылка на техническую документацию по OHE
https://scikitlearn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html
16.
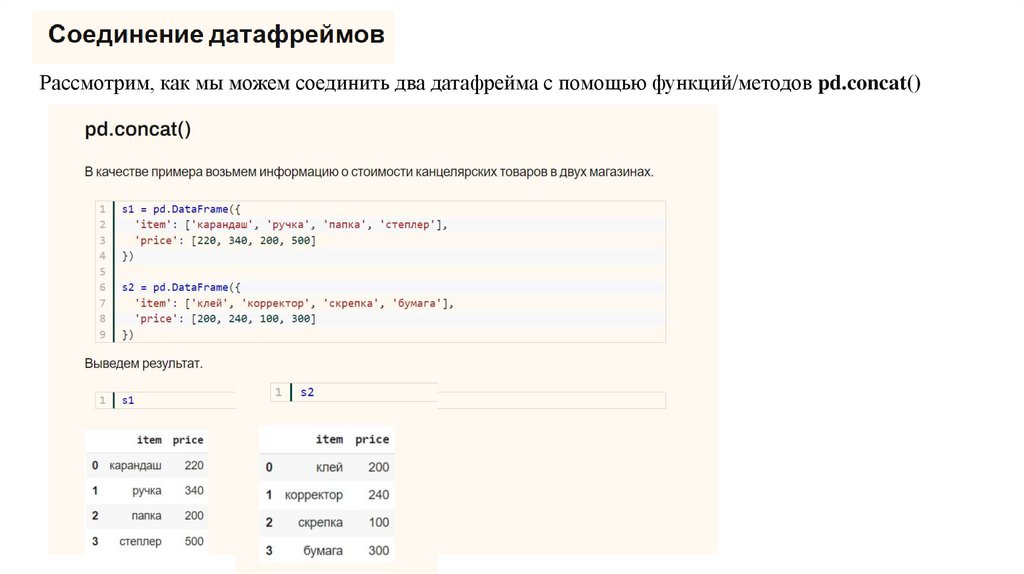
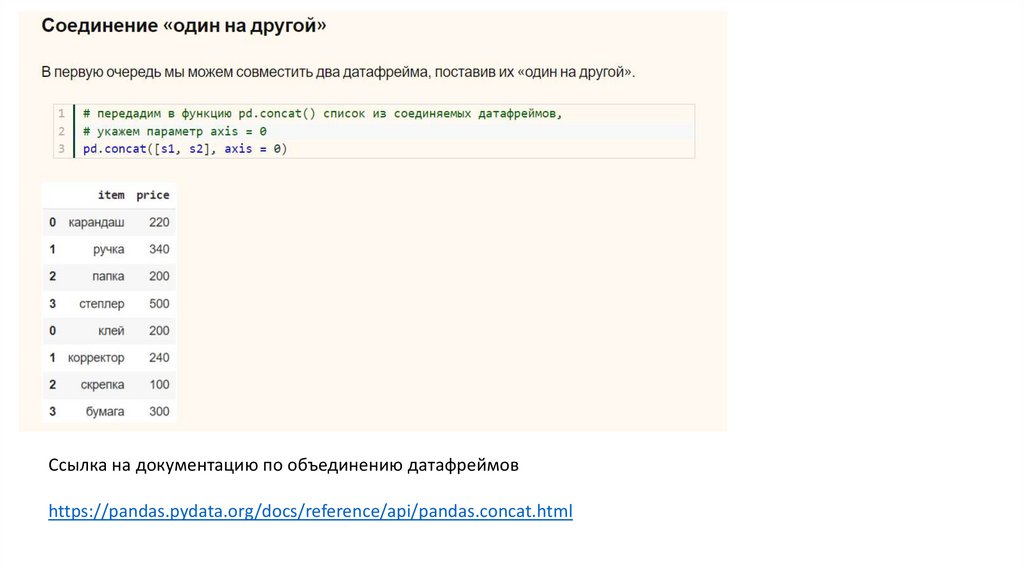
Рассмотрим, как мы можем соединить два датафрейма с помощью функций/методов pd.concat()17.
Cсылка на документацию по объединению датафреймовhttps://pandas.pydata.org/docs/reference/api/pandas.concat.html
18.
1.2.
3.
4.
5.
6.
7.
8.
9.
Задание
Продолжайте работу в тетрадке из 1 лабораторной работы
Удалите из датасета столбец City, информационной нагрузки он не несет, но представляет собой набор
множества уникальных значений, что влияет на качество обучения модели.
Столбец AQI Value выделите как ключевой
Для выборки X удалите столбец AQI Value
Разбейте на test и train выборки. Создавать отдельную переменную для этого не нужно.
Проведите Скеллинг данных для X_train и X_test выборки. Необходимо выполнить в два шага с созданием
отдельных переменных. Для X_test применить только transform. Выведите отскелиренные таблицы на экран
Провести OHE для X_train и X_test выборки. Также создаем разные переменные. Fit и transform для Train
проводим в два последовательных отдельных шага. Выведите таблицы после OHE на экран.Не забываем
выбирать тип данных. См пример скеллинга
Провести объединение датафрейма с помощью concat. X_train OHE с X_train Scaled и также для теста. По
итогу вывести на экран два датафрейма.
Сравните данные до проведения масштабирования и после. Что изменилось?