






 programming
programming software
softwareSimilar presentations:




")
")
")


")
Работа с документами, созданными в форматах Word и PDF. Тема 6
1. Тема 6: Работа с документами, созданными в форматах Word и PDF
Дисциплина:Программирование
Тема 6: Работа с
документами, созданными в
форматах Word и PDF
Преподаватель: канд. техн. наук, доцент
Кромина Людмила Александровна
2.
Основные понятия при работе сдокументами PDF в Python
PDF-файлы являются одними из наиболее важных и широко используемых.
PDF расшифровывается как Portable Document Format.
Он использует расширение .pdf
PyPDF2 – это библиотека Python, созданная в
виде инструментария PDF.
ОН СПОСОБЕН НА:
Модуль PyPDF2
1. Извлечение информации о документе
(название, автор, …)
2. Разделение документов постранично
3. Слияние документов страница за страницей
4. Обрезка страниц
5. Объединение нескольких страниц в одну
страницу
6. Шифрование и дешифрование файлов PDF
и более!
Данный модуль не поставляется вместе с
Python, поэтому его предварительно нужно
установить:
cmd
Cd C:\Python 38>pip install PyPDF2
3.
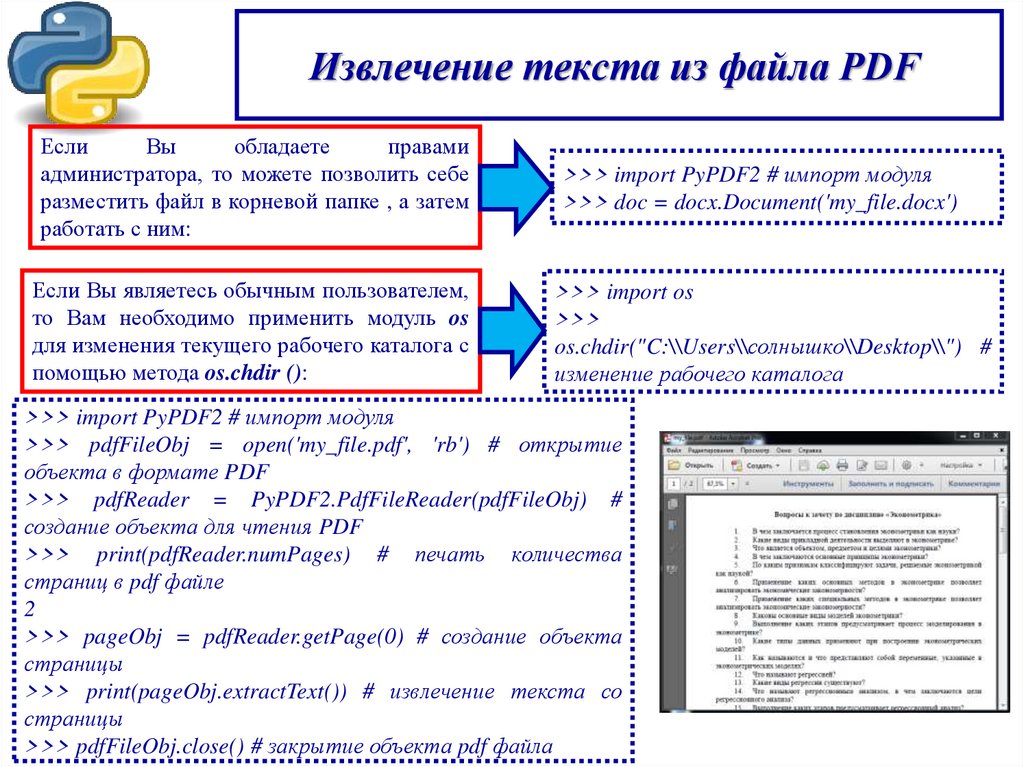
Извлечение текста из файла PDFЕсли
Вы
обладаете
правами
администратора, то можете позволить себе
разместить файл в корневой папке , а затем
работать с ним:
>>> import PyPDF2 # импорт модуля
>>> doc = docx.Document('my_file.docx')
Если Вы являетесь обычным пользователем,
то Вам необходимо применить модуль os
для изменения текущего рабочего каталога с
помощью метода os.chdir ():
>>> import os
>>>
os.chdir("C:\\Users\\солнышко\\Desktop\\") #
изменение рабочего каталога
>>> import PyPDF2 # импорт модуля
>>> pdfFileObj = open('my_file.pdf', 'rb') # открытие
объекта в формате PDF
>>> pdfReader = PyPDF2.PdfFileReader(pdfFileObj) #
создание объекта для чтения PDF
>>> print(pdfReader.numPages) # печать количества
страниц в pdf файле
2
>>> pageObj = pdfReader.getPage(0) # создание объекта
страницы
>>> print(pageObj.extractText()) # извлечение текста со
страницы
>>> pdfFileObj.close() # закрытие объекта pdf файла
4.
Основные понятия при работе сдокументами Word в Python
Для работы с Word файлами из Python применяют
модуль (библиотеку):
python-docx
Модуль python-docx
Данный модуль не поставляется вместе с
Python, поэтому его предварительно нужно
установить:
cmd
Cd C:\Python 38>pip install python-docx
При установке модуля надо вводить pythondocx, а не docx. В то же время при
импортировании модуля python-docx следует
использовать import docx, а не import pythondocx
5.
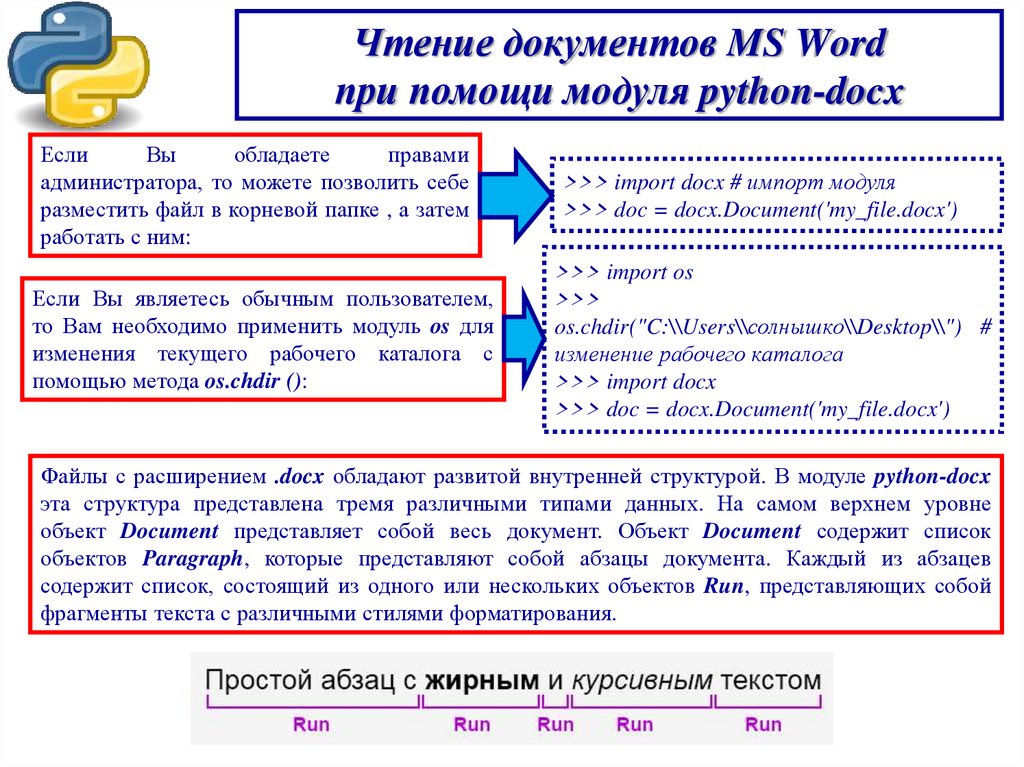
Чтение документов MS Wordпри помощи модуля python-docx
Если
Вы
обладаете
правами
администратора, то можете позволить себе
разместить файл в корневой папке , а затем
работать с ним:
>>> import docx # импорт модуля
>>> doc = docx.Document('my_file.docx')
Если Вы являетесь обычным пользователем,
то Вам необходимо применить модуль os для
изменения текущего рабочего каталога с
помощью метода os.chdir ():
>>> import os
>>>
os.chdir("C:\\Users\\солнышко\\Desktop\\") #
изменение рабочего каталога
>>> import docx
>>> doc = docx.Document('my_file.docx')
Файлы с расширением .docx обладают развитой внутренней структурой. В модуле python-docx
эта структура представлена тремя различными типами данных. На самом верхнем уровне
объект Document представляет собой весь документ. Объект Document содержит список
объектов Paragraph, которые представляют собой абзацы документа. Каждый из абзацев
содержит список, состоящий из одного или нескольких объектов Run, представляющих собой
фрагменты текста с различными стилями форматирования.
6.
Чтение документов MS Wordпри помощи модуля python-docx
>>> import os
>>> os.chdir("C:\\Users\\солнышко\\Desktop\\") # изменение
рабочего каталога
>>> import docx
>>> doc = docx.Document('my_file.docx')
>>> print(len(doc.paragraphs)) # количество абзацев в
документе
5
>>> print(doc.paragraphs[0].text) # текст первого абзаца в
документе
ГЛАВА 1. ТЕОРЕТИЧЕСКИЕ ОСНОВЫ ЯЗЫКА
«PYTHON»
>>> print(doc.paragraphs[1].text) # текст второго абзаца
в документе
«Python»
–
это простой, но
мощный
язык
программирования,
представленный
удобными
высокоуровневыми структурами данных и эффективным
подходом
к
объектно-ориентированному
программированию.
>>> print(doc.paragraphs[1].runs[0].text) # текст первого
Run второго абзаца
«
Нумерация объектов Paragraph и
объектов Run начинается с нуля
>>> text = [] # получение всего
текста из документа:
>>> for paragraph in doc.paragraphs:
text.append(paragraph.text)
print('\n'.join(text))
7.
Стилевое оформление MS Wordпри помощи модуля python-docx
В документах MS Word применяются два типа стилей: стили абзацев, которые могут применяться к
объектам Paragraph, стили символов, которые могут применяться к объектам Run.
Как объектам Paragraph, так и объектам Run можно назначать стили, присваивая их
атрибутам style значение в виде строки. Этой строкой должно быть имя стиля. Если для стиля
задано значение None, то у объекта Paragraph или Run не будет связанного с ним стиля.
СТИЛИ АБЗАЦЕВ
Normal; Body Text; Body Text 2; Body Text 3; Caption; Heading 1; Heading 2; Heading 3; Heading 4; Heading 5;
Heading 6; Heading 7; Heading 8; Heading 9; Intense Quote; List; List 2; List 3; List Bullet; List Bullet 2; List Bullet 3;
List Continue; List Continue 2; List Continue 3; List Number; List Number 2; List Number 3; List Paragraph; Macro
Text; No Spacing; Quote; Subtitle; TOCHeading; Title
СТИЛИ СИМВОЛОВ
Emphasis; Strong; Book Title; Default Paragraph Font; Intense Emphasis; Subtle; Emphasis; Intense
Reference; Subtle Reference
АТРИБУТЫ ОБЪЕКТА RUN
Отдельные фрагменты текста, представленные объектами Run, могут подвергаться
дополнительному форматированию с помощью атрибутов. Для каждого из этих атрибутов может
быть задано одно из трех значений: True (атрибут активизирован), False (атрибут отключен)
и None (применяется стиль, установленный для данного объекта Run).
bold – Полужирное начертание; underline – Подчеркнутый текст; italic – Курсивное начертание;
strike – Зачеркнутый текст
8.
Стилевое оформление MS Wordпри помощи модуля python-docx
ИЗМЕНЕНИЕ СТИЛЕЙ ДЛЯ ВСЕХ
ПАРАГРАФОВ
>>> import docx
>>> doc = docx.Document('my_file.docx')
>>> for paragraph in doc.paragraphs: # изменение стилей для всех параграфов
paragraph.style = 'Normal‘
>>> doc.save('restyled.docx')
9.
Стилевое оформление MS Wordпри помощи модуля python-docx
ВОССТАНОВЛЕНИЕ НАЧАЛЬНЫХ СТИЛЕЙ
>>> import os
>>> os.chdir("C:\\Users\\солнышко\\Desktop\\")
>>> import docx
>>> doc1 = docx.Document('my_file.docx')
>>> doc2 = docx.Document('restyled.docx')
>>> styles = [] # получение из первого документа стилей всех абзацев
>>> for paragraph in doc1.paragraphs:
styles.append(paragraph.style)
>>> for i in range(len(doc2.paragraphs)): # применение стилей ко всем абзацам второго
документа
doc2.paragraphs[i].style = styles[i]
>>> doc2.save('restored.docx')
10.
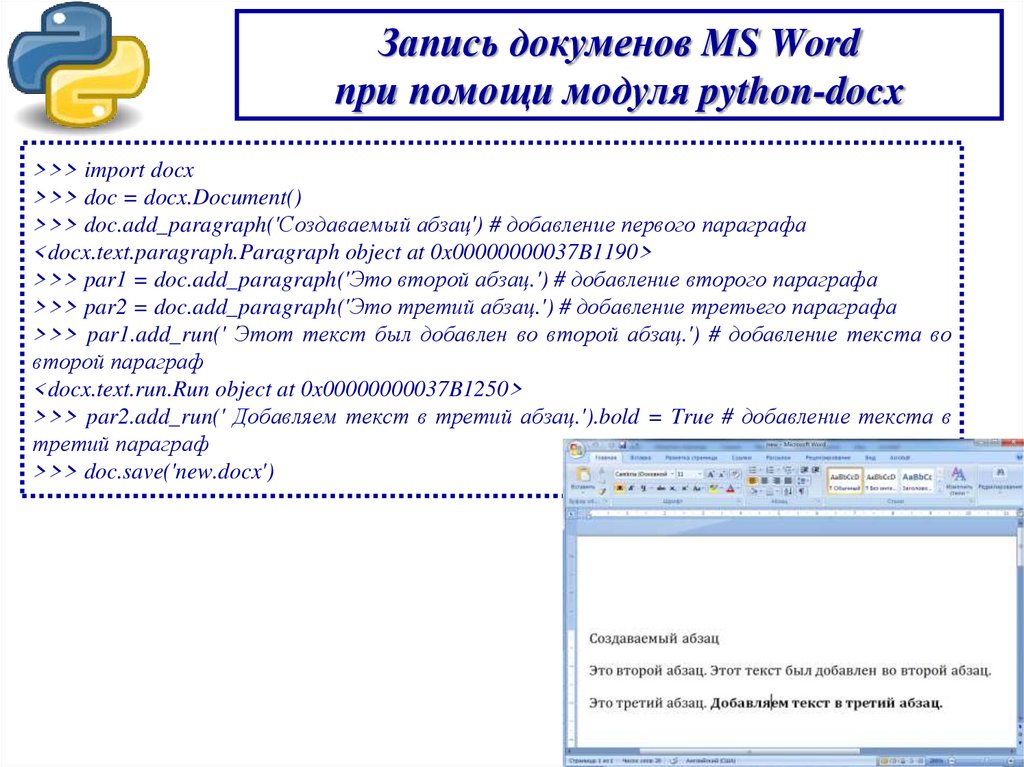
Запись докуменов MS Wordпри помощи модуля python-docx
>>> import docx
>>> doc = docx.Document()
>>> doc.add_paragraph('Создаваемый абзац') # добавление первого параграфа
<docx.text.paragraph.Paragraph object at 0x00000000037B1190>
>>> par1 = doc.add_paragraph('Это второй абзац.') # добавление второго параграфа
>>> par2 = doc.add_paragraph('Это третий абзац.') # добавление третьего параграфа
>>> par1.add_run(' Этот текст был добавлен во второй абзац.') # добавление текста во
второй параграф
<docx.text.run.Run object at 0x00000000037B1250>
>>> par2.add_run(' Добавляем текст в третий абзац.').bold = True # добавление текста в
третий параграф
>>> doc.save('new.docx')
11.
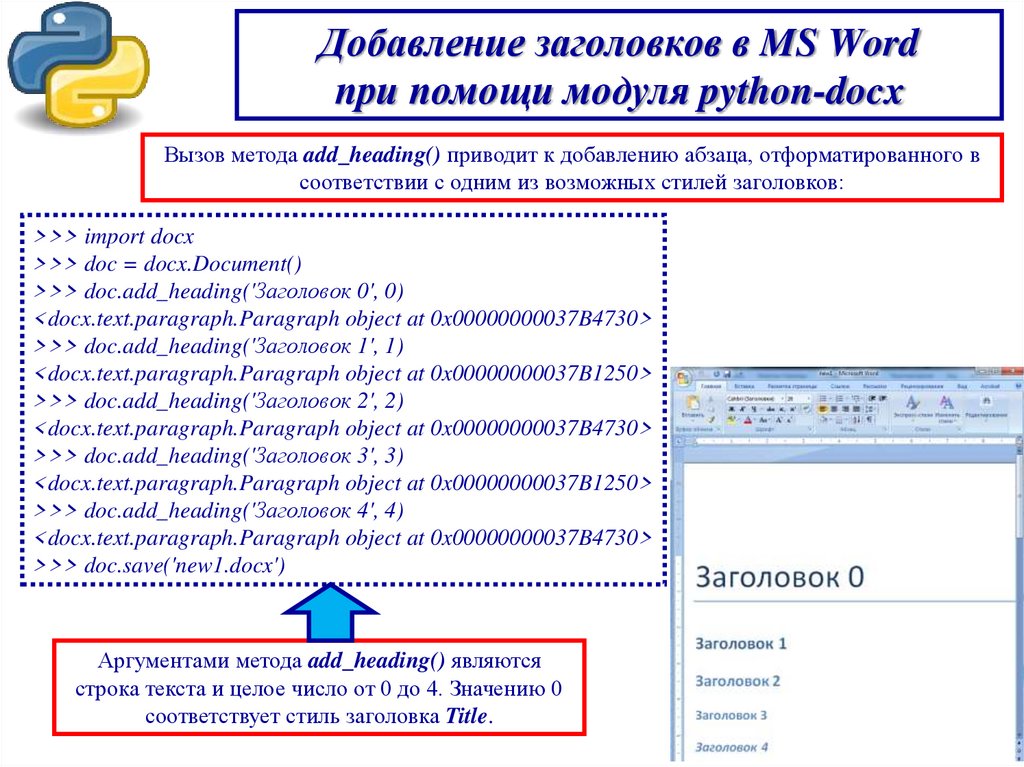
Добавление заголовков в MS Wordпри помощи модуля python-docx
Вызов метода add_heading() приводит к добавлению абзаца, отформатированного в
соответствии с одним из возможных стилей заголовков:
>>> import docx
>>> doc = docx.Document()
>>> doc.add_heading('Заголовок 0', 0)
<docx.text.paragraph.Paragraph object at 0x00000000037B4730>
>>> doc.add_heading('Заголовок 1', 1)
<docx.text.paragraph.Paragraph object at 0x00000000037B1250>
>>> doc.add_heading('Заголовок 2', 2)
<docx.text.paragraph.Paragraph object at 0x00000000037B4730>
>>> doc.add_heading('Заголовок 3', 3)
<docx.text.paragraph.Paragraph object at 0x00000000037B1250>
>>> doc.add_heading('Заголовок 4', 4)
<docx.text.paragraph.Paragraph object at 0x00000000037B4730>
>>> doc.save('new1.docx')
Аргументами метода add_heading() являются
строка текста и целое число от 0 до 4. Значению 0
соответствует стиль заголовка Title.
12.
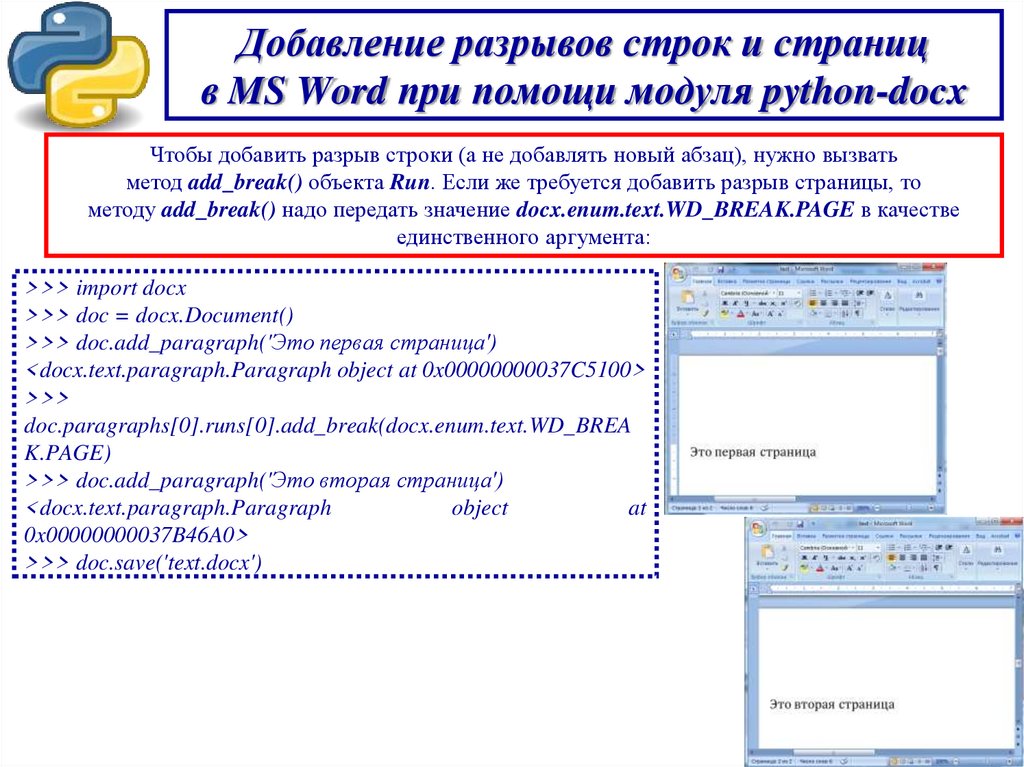
Добавление разрывов строк и страницв MS Word при помощи модуля python-docx
Чтобы добавить разрыв строки (а не добавлять новый абзац), нужно вызвать
метод add_break() объекта Run. Если же требуется добавить разрыв страницы, то
методу add_break() надо передать значение docx.enum.text.WD_BREAK.PAGE в качестве
единственного аргумента:
>>> import docx
>>> doc = docx.Document()
>>> doc.add_paragraph('Это первая страница')
<docx.text.paragraph.Paragraph object at 0x00000000037C5100>
>>>
doc.paragraphs[0].runs[0].add_break(docx.enum.text.WD_BREA
K.PAGE)
>>> doc.add_paragraph('Это вторая страница')
<docx.text.paragraph.Paragraph
object
at
0x00000000037B46A0>
>>> doc.save('text.docx')
13.
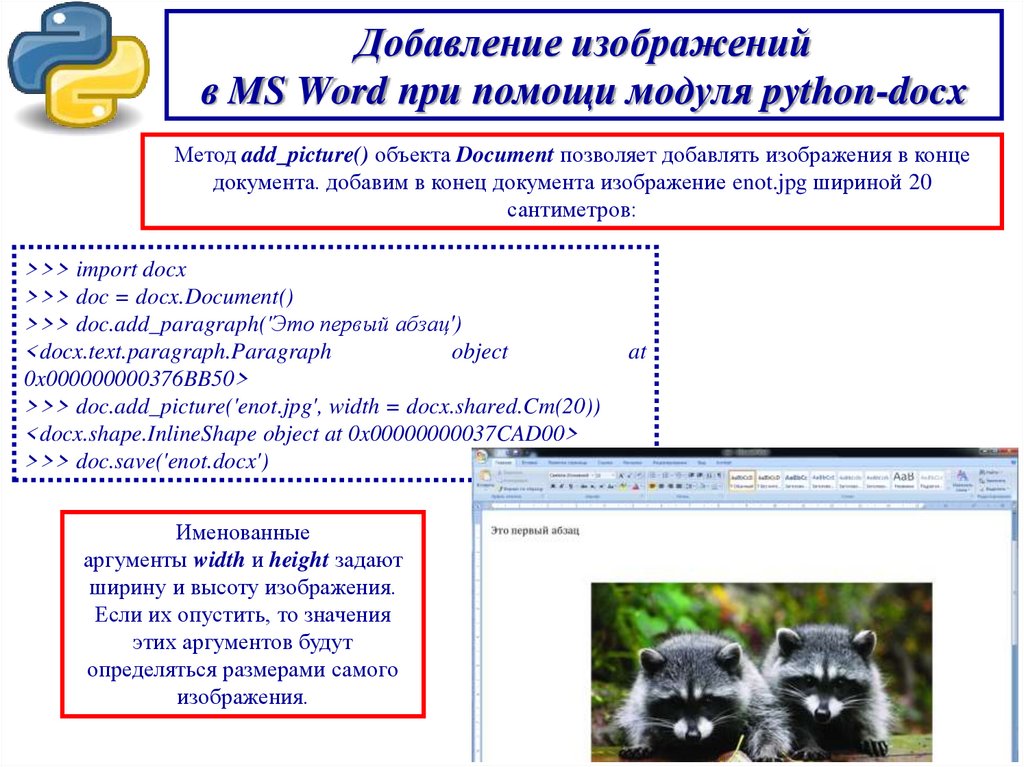
Добавление изображенийв MS Word при помощи модуля python-docx
Метод add_picture() объекта Document позволяет добавлять изображения в конце
документа. добавим в конец документа изображение enot.jpg шириной 20
сантиметров:
>>> import docx
>>> doc = docx.Document()
>>> doc.add_paragraph('Это первый абзац')
<docx.text.paragraph.Paragraph
object
0x000000000376BB50>
>>> doc.add_picture('enot.jpg', width = docx.shared.Cm(20))
<docx.shape.InlineShape object at 0x00000000037CAD00>
>>> doc.save('enot.docx')
Именованные
аргументы width и height задают
ширину и высоту изображения.
Если их опустить, то значения
этих аргументов будут
определяться размерами самого
изображения.
at
14.
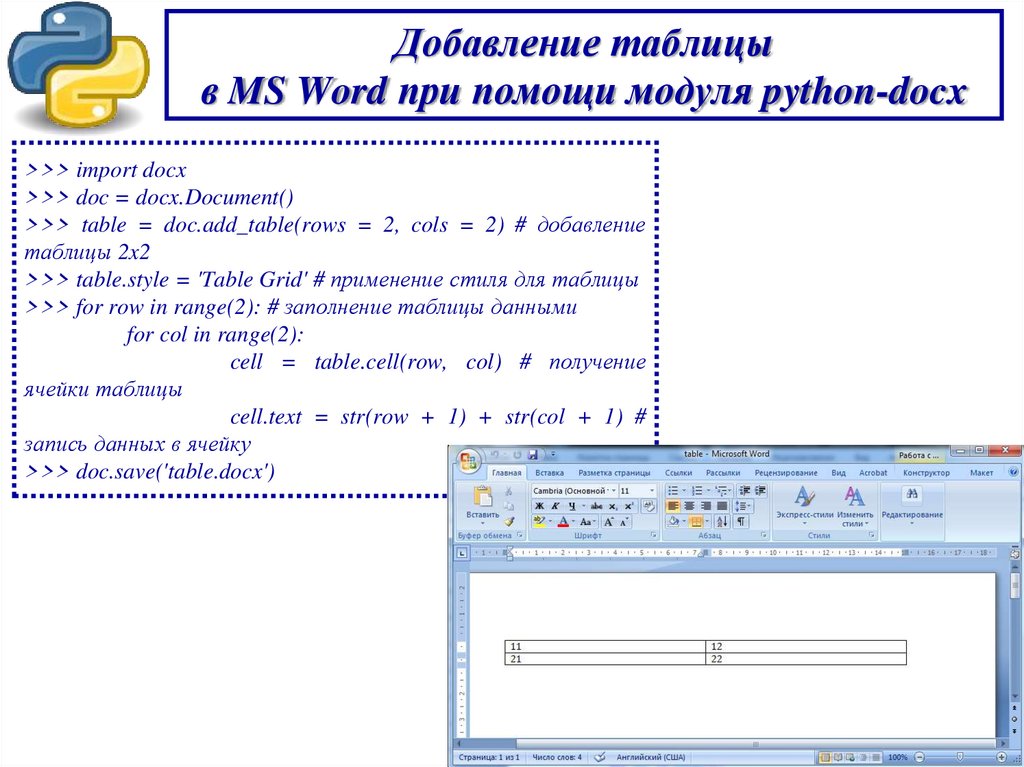
Добавление таблицыв MS Word при помощи модуля python-docx
>>> import docx
>>> doc = docx.Document()
>>> table = doc.add_table(rows = 2, cols = 2) # добавление
таблицы 2x2
>>> table.style = 'Table Grid' # применение стиля для таблицы
>>> for row in range(2): # заполнение таблицы данными
for col in range(2):
cell = table.cell(row, col) # получение
ячейки таблицы
cell.text = str(row + 1) + str(col + 1) #
запись данных в ячейку
>>> doc.save('table.docx')
15.
Считывание данных из таблицыMS Word при помощи модуля python-docx
>>> import os
>>> os.chdir("C:\\Users\\солнышко\\Desktop\\")
>>> import docx
>>> doc = docx.Document('table.docx')
>>> table = doc.tables[0] # получение таблицы из документа
>>> for row in table.rows: # считывание данных из таблицы
string = ''
for cell in row.cells:
string = string + cell.text + ' '
print(string)
11 12
21 22