












 programming
programmingSimilar presentations:










Интерпретация моделей машинного обучения
1.
Интерпретация моделеймашинного обучения.
Библиотека ModelXplain
Серебренников Александр, Балашов Евгений
Август, 2021
1
2.
Проблематика• Модели машинного обучения
продолжают получать все большее
распространение как инструмент
принятия бизнес-решений
“В апреле 2021 года Еврокомиссия предложила
ограничить использование ИИ с “высокими
рисками” для общества”
РБК, 13 мая 2021
• Низкое качество моделей ведет к
финансовым и иным потерям, что
порождает у заказчиков вопросы
доверия к модели
• Мы можем ответить на эти вопросы,
интерпретируя модели и объясняя их
“Сбербанк в результате ошибок
искусственного интеллекта (ИИ) потерял
миллиарды рублей”
Герман Греф
РБК, 26 февраля 2019
2
©2021 Teradata
3.
Интерпретация простых моделей• Относительно простыми для интерпретации
моделями можно назвать модели линейной и
логистической регресси и одиночные деревья
решений.
• Есть несколько возможностей их интерпретировать:
• Использовать структуру самой модели
• Воспользоваться статистическими методами для
моделей регрессии
• Воспользоваться встроенными методами
3
©2021 Teradata
4.
Актуализация• Интерпретация ансамблевых моделей
вышеописанными методами либо крайне
трудозатратна, либо невозможна
• На данный момент существуют методы для
интерпретации сложных моделей, однако некоторые из
них или имеют реализацию в виде отдельных функций,
либо имели ограниченное применение (например PDP
от sсikit-learn) или не имели реализацию вовсе
• Это привело к потребности в создании единой и
удобной в промышленом использовании библиотеки,
проводящей анализ модели как черного ящика
4
©2021 Teradata
5.
Библиотека ModelXplain• Разработан прототип библиотеки, представляющий из
себя комбинацию существующих методов
интерпретаци и написанных с нуля.
• В ходе работы были рассмотрены наиболее
популярные техники интерпретации комплексных
моделей машинного обучения, которые разделяются на
три класса :
• Интерпретация важности признаков модели: PFI
и LOCO
• Методы оценки частичного влияния признаков:
PDP и ICE
• Объяснение скоринга отдельно взятых объектов:
LIME и SHAP
5
©2021 Teradata
6.
PFI (Permutation Feature Importances) иLOCO (Leave-One-Covariative-Out)
• Оба метода рассчитывают важность фичей, используя предсказания обученной модели при
подаче измененного датасета (с перемешанной колонкой фичи для PFI и удаленной колонкой
для LOCO) для рассчета ошибки. Рост ошибки на измененном датасете отображает важность
признака.
• Достоинства:
• Интуитивно понятны даже непрофессионалам
• Позволяют проверить причинно-следственную связь между фичей и прогнозом
• Недостатки:
• Результат работы алгоритмов напрямую зависит от качества модели
• (PFI) Из-за перемешивания колонки в датасете, результаты работы алгоритма могут
различаться от использования к использованию
• (LOCO) Чувствителен к кореллирующим фичам.
• (LOCO) Требует переучивания модели при каждом удалении колонки
6
©2021 Teradata
7.
Примеры использования (1)• PFI
• Исследуем модель GradientBoostingRegressor
из библиотеки sklearn обученную на данных о
жилых помещениях в Калифорнии
• На данном примере по значениям важности
фичей можно увидеть следующее:
• Несмотря на некоторые различия в
степени важности отдельных фичей,
оба метода сходятся в общей оценке
важных и не важных фичей
• В первом случае наиболее важными
фичами считаются MedInc, Latitude и
Longtitude; Во втором случае ниболее
важными считаются Longtitude, Latitude
и MedInc
7
©2021 Teradata
• LOCO
8.
PDP (Partial Dependence Plot) иICE (Individual Condition Expectation)
• Методы используют обученную модель для рассчета предсказания при различных значениях
фичи (в датасет поочередно подставляются значения фичи от меньшего к большему с
некоторым шагом), предсказания при каждом значении усредняются (PDP), или нет (ICE)
• Достоинства:
• Интуитивно понятны даже непрофессионалам
• Если тестируемая фича не коррелирует с другими,
тогда есть точное представление, как она влияет на прогноз в среднем
• Недостатки:
• Требуется независимость тестируемой переменной
• Гетерогенные эффекты могут быть скрыты из-за усреднения (недостаток может быть
компенсирован за счет анализа ICE-линий)
8
©2021 Teradata
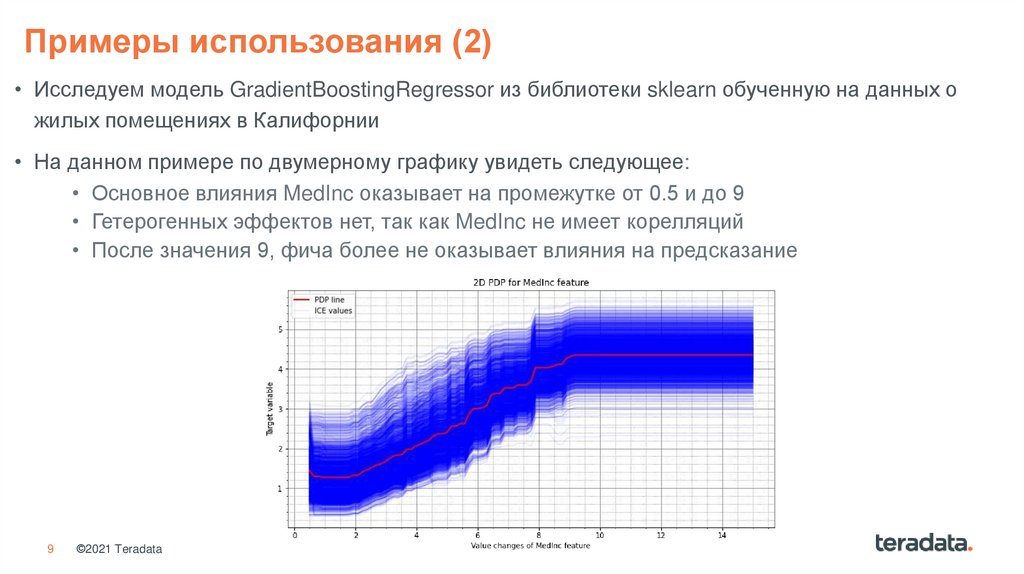
9.
Примеры использования (2)• Исследуем модель GradientBoostingRegressor из библиотеки sklearn обученную на данных о
жилых помещениях в Калифорнии
• На данном примере по двумерному графику увидеть следующее:
• Основное влияния MedInc оказывает на промежутке от 0.5 и до 9
• Гетерогенных эффектов нет, так как MedInc не имеет корелляций
• После значения 9, фича более не оказывает влияния на предсказание
9
©2021 Teradata
10.
LIME (Local Interpretable Model-Agnostic Explanations)• Метод использует более простую интерпретируемую модель для объяснения
конкретного предсказания. Основная модель производит предсказания для небольших
изменений «вокруг» рассматриваемого предсказания, а затем на готовом датасете
обучает более простую и интерпретируемую модель.
• Достоинства:
• Хорошо и понятно интерпретируется
• Один из немногих методов, который работает и
с табличными данными, и с текстом, и с изображениями
• Недостатки:
• Недостаточен для полного объяснения модели
10
©2021 Teradata
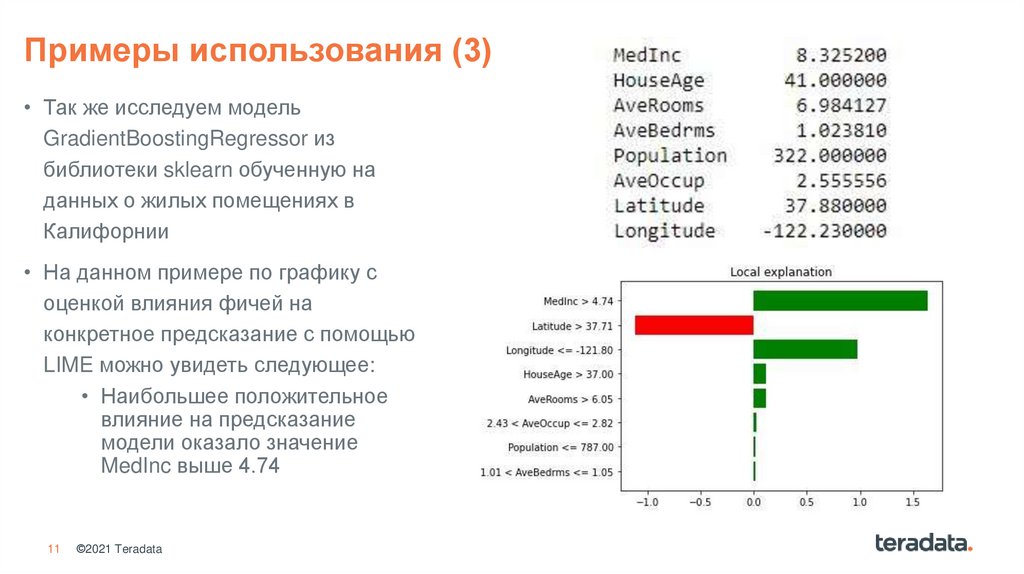
11.
Примеры использования (3)• Так же исследуем модель
GradientBoostingRegressor из
библиотеки sklearn обученную на
данных о жилых помещениях в
Калифорнии
• На данном примере по графику с
оценкой влияния фичей на
конкретное предсказание с помощью
LIME можно увидеть следующее:
• Наибольшее положительное
влияние на предсказание
модели оказало значение
MedInc выше 4.74
11
©2021 Teradata
12.
SHAP (SHapley Additive exPlanations)• Метод использует вектор значений Шепли, который показывает распределение
«выигрыша» (т.е. вклад) между всеми фичами.
• Достоинства:
• Хорошая интерпретируемость
• Несмотря на применение локальное работает довольно быстро, что позволяет
применять его для глобального объяснения моделей
• Недостатки:
• Недостаточен для полного объяснения модели
12
©2021 Teradata
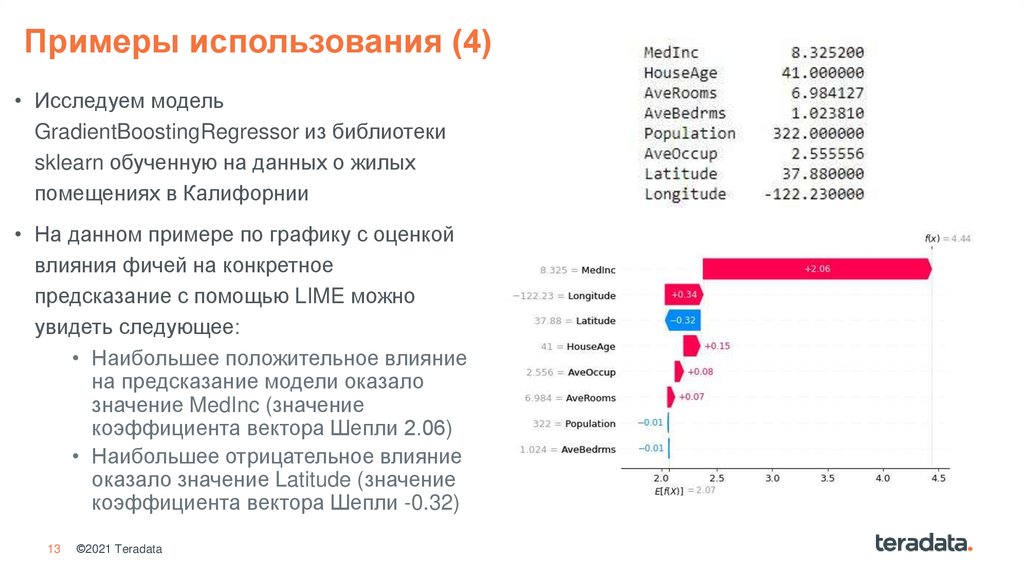
13.
Примеры использования (4)• Исследуем модель
GradientBoostingRegressor из библиотеки
sklearn обученную на данных о жилых
помещениях в Калифорнии
• На данном примере по графику с оценкой
влияния фичей на конкретное
предсказание с помощью LIME можно
увидеть следующее:
• Наибольшее положительное влияние
на предсказание модели оказало
значение MedInc (значение
коэффициента вектора Шепли 2.06)
• Наибольшее отрицательное влияние
оказало значение Latitude (значение
коэффициента вектора Шепли -0.32)
13
©2021 Teradata
14.
Видеодемонстрация14
©2021 Teradata
15.
Резюме• В ходе работы были изучены методы
интерпретации моделей машинного
обучения
• Представлены достоинства и
недостатки использования
рассмотренных методов
• Создана библиотека, состоящая из
методов независимой от
анализируемой модели
15
©2021 Teradata
16.
Дальнейшее развитие• Все методы реализованы на языке
Python.
• Функции LIME и SHAP используют
функции сторонних библиотек «lime» и
«shap» соответственно
• PDP-функции, PFI и LOCO написаны
самостоятельно, с нуля и могут быть
реализованы на других языках
программирования
16
©2021 Teradata
17.
ThankThank you.
you.
©2018 Teradata
Teradata
©2018
17