









 software
softwareSimilar presentations:










Основы методологии поиска источников данных и подготовки данных для анализа
1.
Основы методологии поиска источников данныхи подготовки данных для анализа
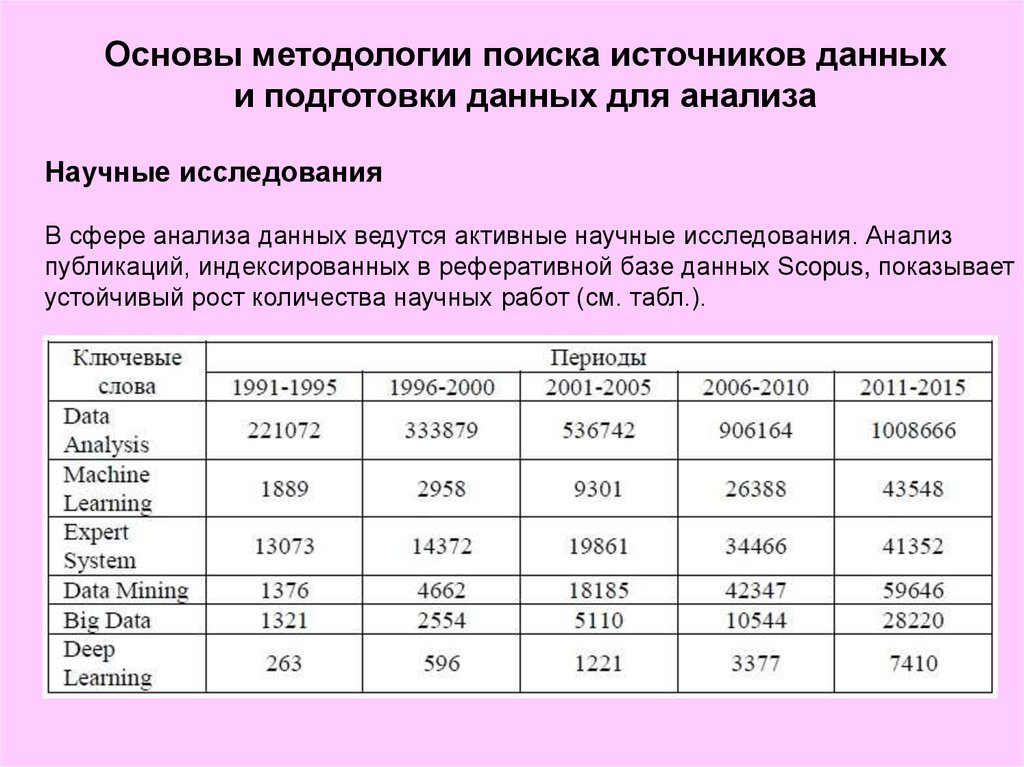
Научные исследования
В сфере анализа данных ведутся активные научные исследования. Анализ
публикаций, индексированных в реферативной базе данных Scopus, показывает
устойчивый рост количества научных работ (см. табл.).
2.
Программное обеспечениеВ основе систем анализа данных лежит программное обеспечение. При
проектировании систем анализа данных могут быть использованы следующие
подходы:
- использование «коробочного» программного обеспечения общего назначения
(например Microsoft Excel);
- использование программного обеспечения, ориентированного на
математические задачи (например Matlab, Octave, R);
- разработка специализированного программного обеспечения с использованием
готовых библиотек, включающих наборы специальных функций обработки
данных.
При разработке специализированного ПО рекомендуется использовать готовые
библиотеки функций обработки данных. Так, для нейросетевого анализа можно
применить библиотеку FANN, имеющую версии для языков программирования
С#, С++, Java, Python, R, Matlab, а для решения задач обработки изображений –
библиотеку OpenCV, имеющую версии для языков Python, Java, Ruby, Matlab и
др.
3.
Построение системы анализа данныхМожно предложить следующий общий алгоритм построения системы анализа
данных:
1 Постановка задачи.
2 Определение источников данных.
3 Выбор метода и алгоритма обработки данных.
4 Выбор аппаратной платформы.
5 Выбор или разработка программного обеспечения.
6 Верификация построенной системы.
Отметим, что шаги 3 - 5 тесно связаны друг с другом: например, изменение
аппаратной платформы может повлечь необходимость повторной разработки
программного обеспечения.
4.
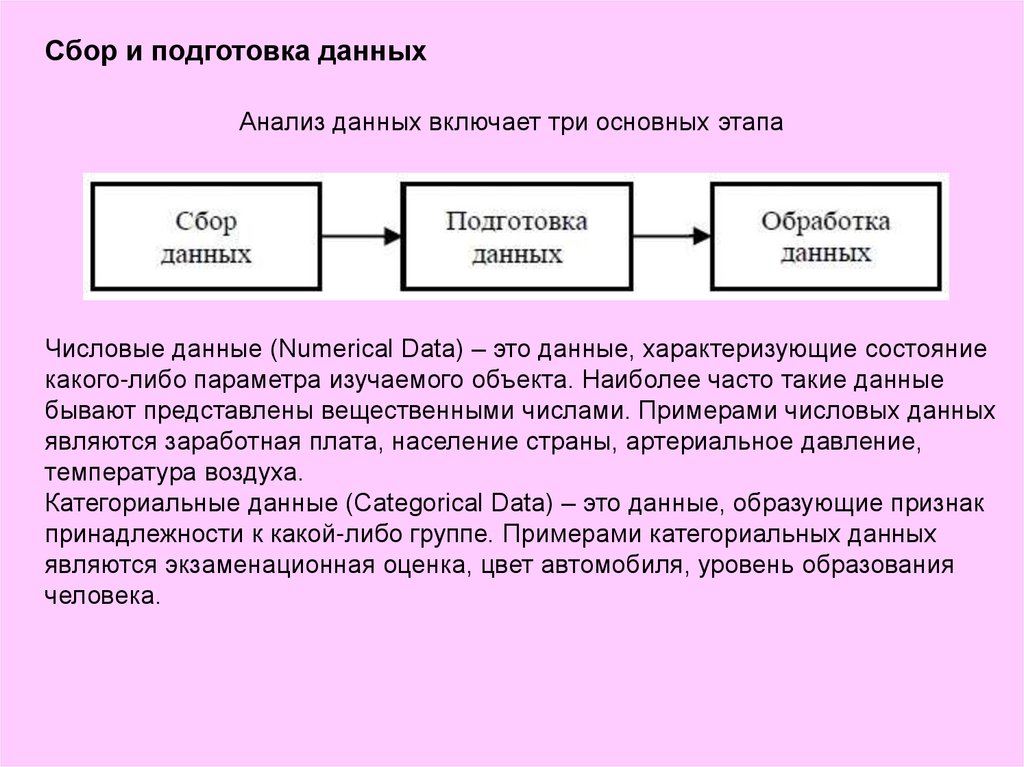
Сбор и подготовка данныхАнализ данных включает три основных этапа
Числовые данные (Numerical Data) – это данные, характеризующие состояние
какого-либо параметра изучаемого объекта. Наиболее часто такие данные
бывают представлены вещественными числами. Примерами числовых данных
являются заработная плата, население страны, артериальное давление,
температура воздуха.
Категориальные данные (Categorical Data) – это данные, образующие признак
принадлежности к какой-либо группе. Примерами категориальных данных
являются экзаменационная оценка, цвет автомобиля, уровень образования
человека.
5.
Источники данныхВ настоящее время в открытом доступе есть большое количество баз данных,
содержащих самые разнообразные сведения. Так, самым большим источником
данных по разнообразным показателям стран мира в целом можно считать базу
данных Всемирного банка, содержащую годовые значения 331 показателя стран
мира за период с 1960 по 2014 годы в форматах HTML, XLS и XML.
По состоянию на 23 декабря 2015 года самым большим источником открытых
данных по Российской Федерации является «Портал открытых данных
Российской Федерации», содержащий более 4,1 тыс. наборов данных.
Предполагается, что предоставление свободного доступа к отдельным данным
может способствовать повышению качества государственного, регионального и
муниципального управления. Принцип открытости получил отдельное название
– «открытые данные» (Open Data). В Российской Федерации концепция
открытых данных упоминается в Федеральном законе «Об информации,
информационных технологиях и о защите информации».
Также большой объем открытых статистических данных содержится в банке
данных Федеральной службы государственной статистики.
6.
Источники данныхВ настоящее время в открытом доступе есть большое количество баз данных,
содержащих самые разнообразные сведения. Так, самым большим источником
данных по разнообразным показателям стран мира в целом можно считать базу
данных Всемирного банка, содержащую годовые значения 331 показателя стран
мира за период с 1960 по 2014 годы в форматах HTML, XLS и XML.
По состоянию на 23 декабря 2015 года самым большим источником открытых
данных по Российской Федерации является «Портал открытых данных
Российской Федерации», содержащий более 4,1 тыс. наборов данных.
Предполагается, что предоставление свободного доступа к отдельным данным
может способствовать повышению качества государственного, регионального и
муниципального управления. Принцип открытости получил отдельное название –
«открытые данные» (Open Data). В Российской Федерации концепция открытых
данных упоминается в Федеральном законе «Об информации, информационных
технологиях и о защите информации».
Также большой объем открытых статистических данных содержится в банке
данных Федеральной службы государственной статистики.
7.
Подготовка данныхДля использования в системах анализа данные должны быть представлены в
определенном, как правило, табличном виде. Однако зачастую наборы данных
имеют следующие особенности:
- отличную от табличной форму представления;
- пропуски отдельных данных;
- некорректные значения;
- большие числовые значения;
- текстовые данные.
Перечисленные особенности могут либо привести к затруднениям в процессе
дальнейшей обработки данных, либо сделать её невозможной.
Для устранения отмеченных несоответствий могут быть применены следующие
операции:
- структурирование – приведение данных к табличному (матричному) виду;
- отбор – исключение записей с отсутствующими или некорректными значениями;
- нормализация – приведение числовых значений к определенному диапазону,
например к диапазону 0...1;
- кодирование – это представление категориальных данных в числовой форме.
Например, при бинарной классификации один из классов можно представить
числом «0», а другой класс – числом «1». При множественной классификации
система кодирования несколько усложняется: создается несколько числовых
полей по количеству классов в выборке данных, каждый класс кодируется
проставлением числа «1» в соответствующем поле.
8.
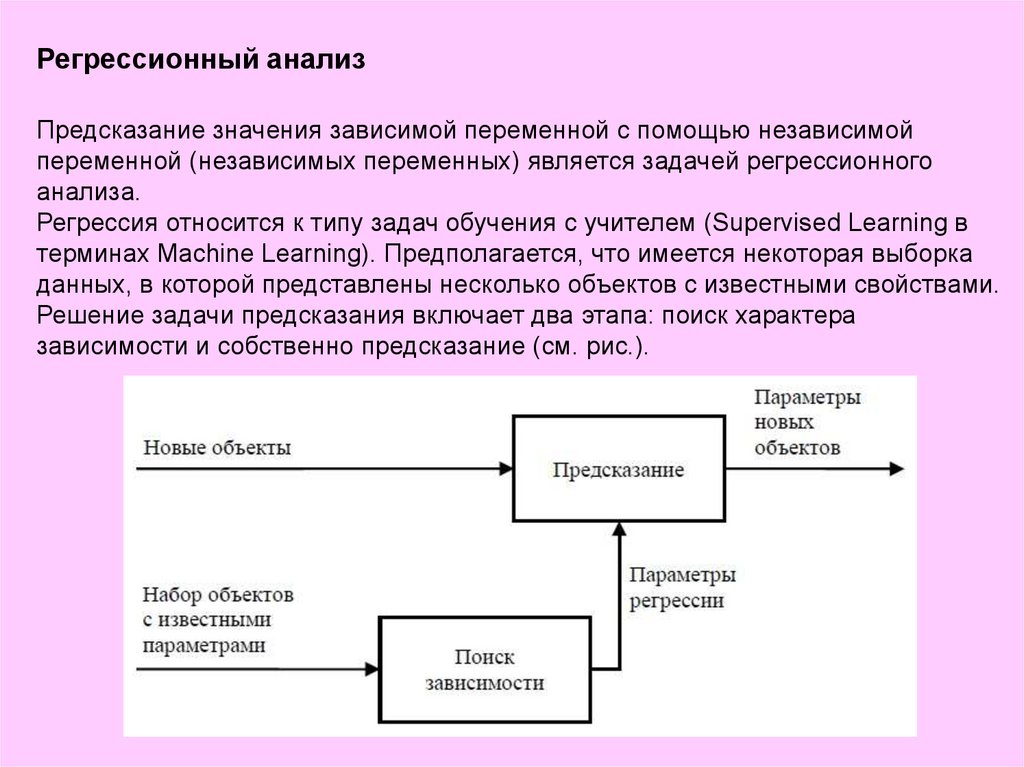
Регрессионный анализПредсказание значения зависимой переменной с помощью независимой
переменной (независимых переменных) является задачей регрессионного
анализа.
Регрессия относится к типу задач обучения с учителем (Supervised Learning в
терминах Machine Learning). Предполагается, что имеется некоторая выборка
данных, в которой представлены несколько объектов с известными свойствами.
Решение задачи предсказания включает два этапа: поиск характера
зависимости и собственно предсказание (см. рис.).
9.
Наиболее часто используется линейная функция гипотезыС учетом того, что наборы значений и по сути являются векторами, выражение
(1) для удобства записывают в виде произведения векторов: θ x
В зависимости от характера функции гипотезы регрессию подразделяют на
линейную и нелинейную. В зависимости от числа независимых переменных
регрессию подразделяют на парную и множественную.
10.
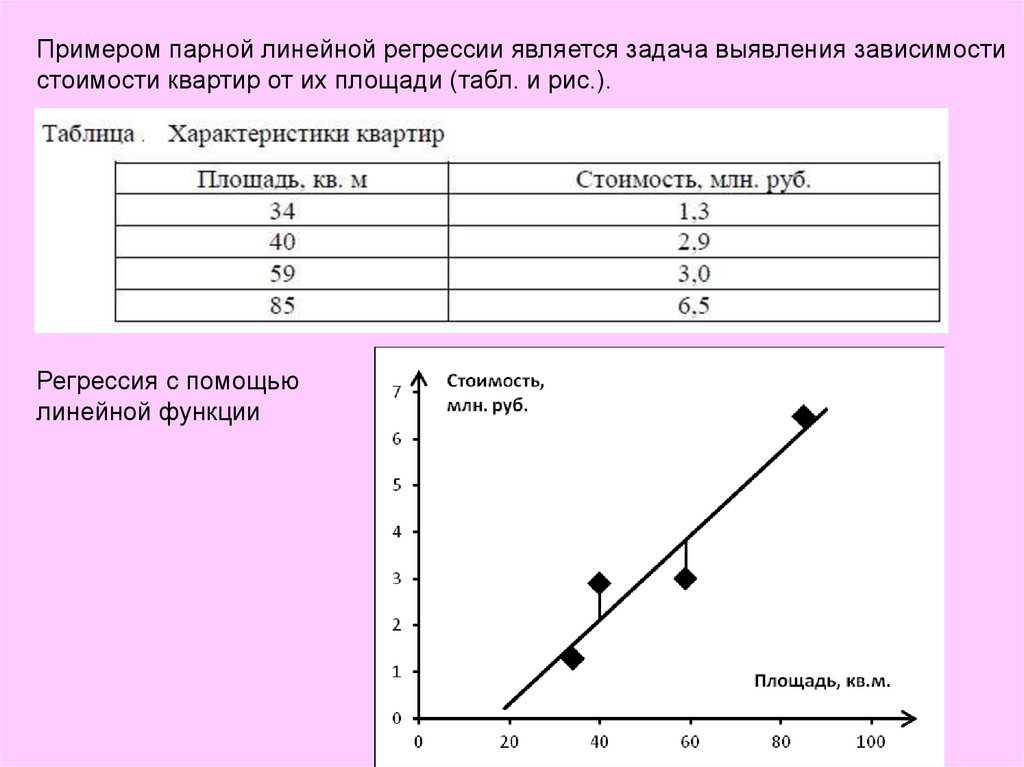
Примером парной линейной регрессии является задача выявления зависимостистоимости квартир от их площади (табл. и рис.).
Регрессия с помощью
линейной функции
11.
Подбор параметров регрессионной функции обычно осуществляется покритерию минимума суммы квадратов отклонений:
При этом выражение
называется функцией штрафа (cost function, CF; либо loss function, LF).
В формулировке (3) задача нахождения параметров регрессионной функции
является оптимизационной. Существует два основных подхода к решению
задачи регрессии в постановке (1): аналитический и численный. Следует
отметить, что решения регрессионной задачи, полученные разными методами,
могут различаться.
12.
Аналитическое решениеИзвестно аналитическое решение задачи линейной регрессии в постановке (1):
где X – матрица, содержащая значения независимых переменных;
y – вектор, содержащий значений зависимых переменных.
Для вышеприведенного набора данных (табл. 9) матрица Х и вектор y примут
вид
При исходных данных (3) выражение (2) дает результат
13.
Аналитический метод характеризуется следующими особенностями:1 Относительно низкая устойчивость к отдельным сочетаниям данных. Так,
дублирование какой-либо строки в наборе данных приведет к сбою в
вычислениях при операции нахождения обратной матрицы.
2 Большая вычислительная сложность. Относительно большие наборы данных,
содержащие порядка тысячи и более строк, будут обрабатываться относительно
медленно.
3 Чувствительность к большим значениям. Для наборов данных, в отдельных
столбцах которых содержатся большие значения, может потребоваться
предварительная нормализация.
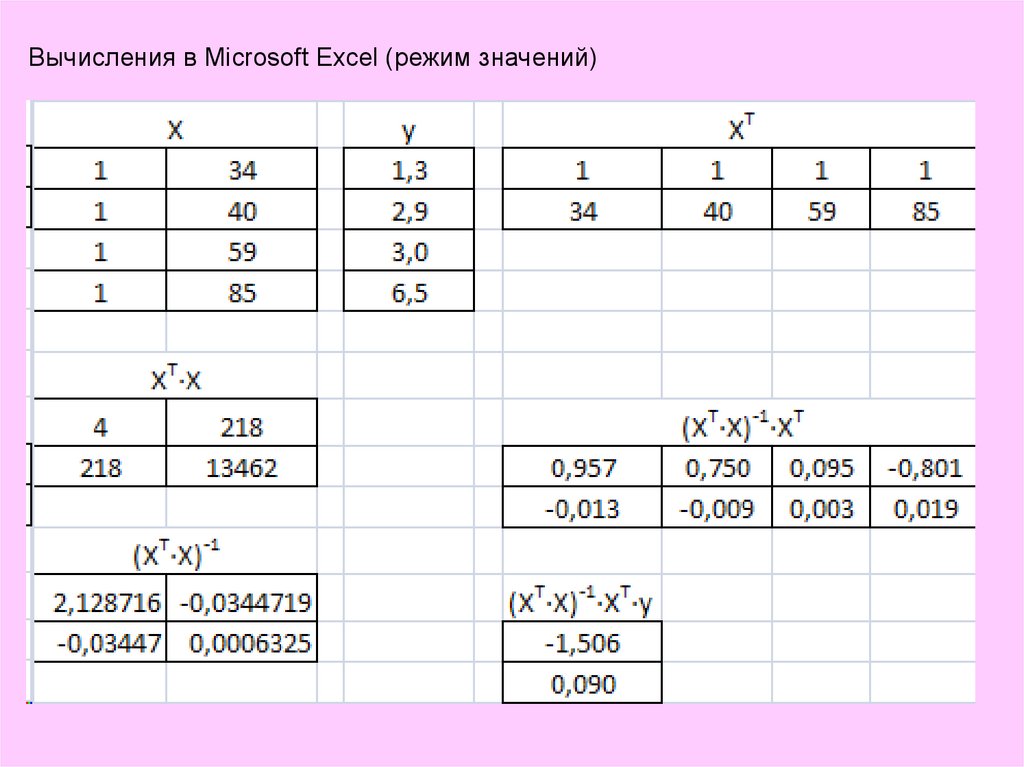
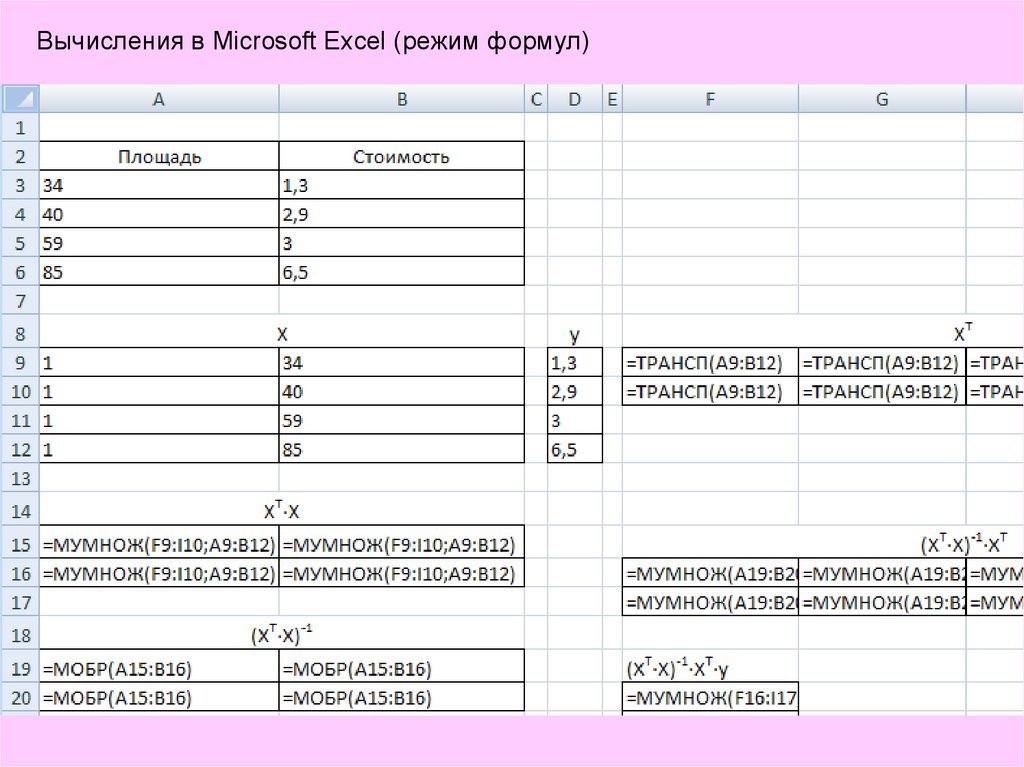
Для вычисления выражений вида (2) удобно использовать специализированное
математическое программное обеспечение, например Matlab, Octave. Однако
широко распространенное ПО Microsoft Excel также имеет инструменты для
решения подобных задач. Так, для умножения матриц используется функция
МУМНОЖ, для транспонирования матриц – функция ТРАНСП, а для нахождения
обратной матрицы – МОБР.
14.
Вычисления в Microsoft Excel (режим значений)15.
Вычисления в Microsoft Excel (режим формул)16.
Численное решениеДля линейной регрессии задача в формулировке (1) имеет единственное
решение, что позволяет без каких-либо оговорок применять численные методы.
Например, можно использовать метод Ньютона либо метод сопряженных
градиентов. Оба этих метода представлены в инструменте «Поиск решения» ПО
Microsoft Excel.
Численное решение регрессионной задачи включает следующие шаги:
1) подготовку данных;
2) задание функции гипотезы, в том числе начальных значений её параметров;
3) задание целевой функции;
4) решение оптимизационной задачи каким-либо численным методом.
Рассмотрим численное решение задачи регрессии на основе данных о стоимости
квартир (табл. 9) с помощью программного обеспечения Microsoft Excel.
Для удобства запишем выражение для функции гипотезы в следующей форме:
Также запишем формулировку оптимизационной задачи:
17.
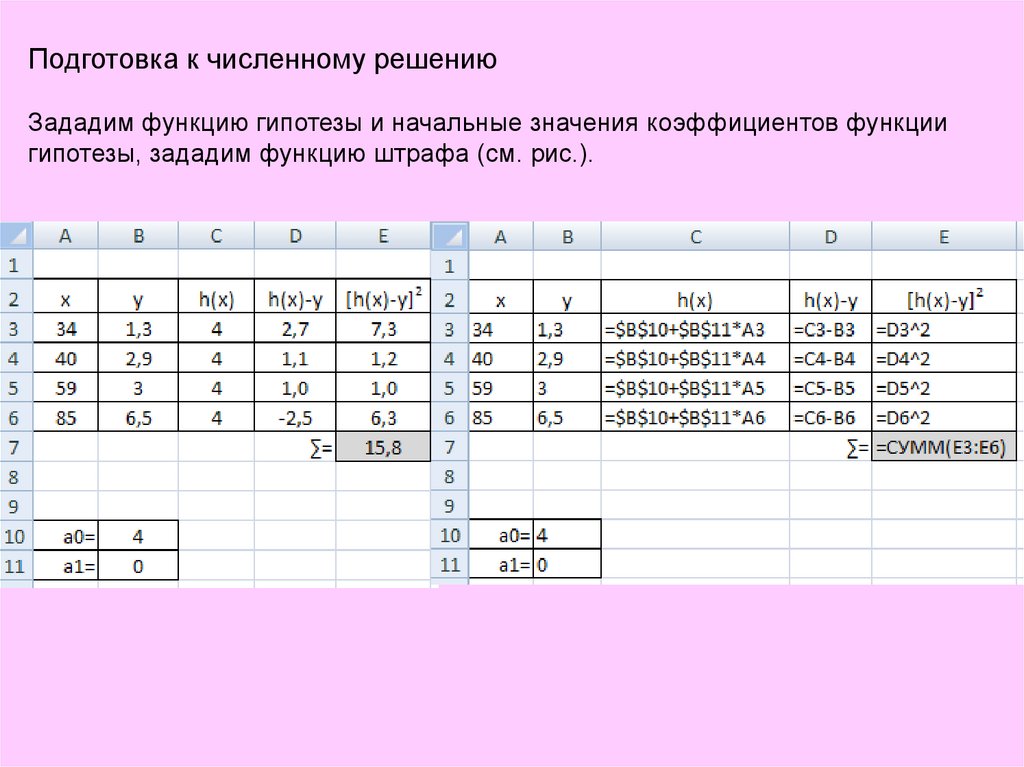
Подготовка к численному решениюЗададим функцию гипотезы и начальные значения коэффициентов функции
гипотезы, зададим функцию штрафа (см. рис.).
18.
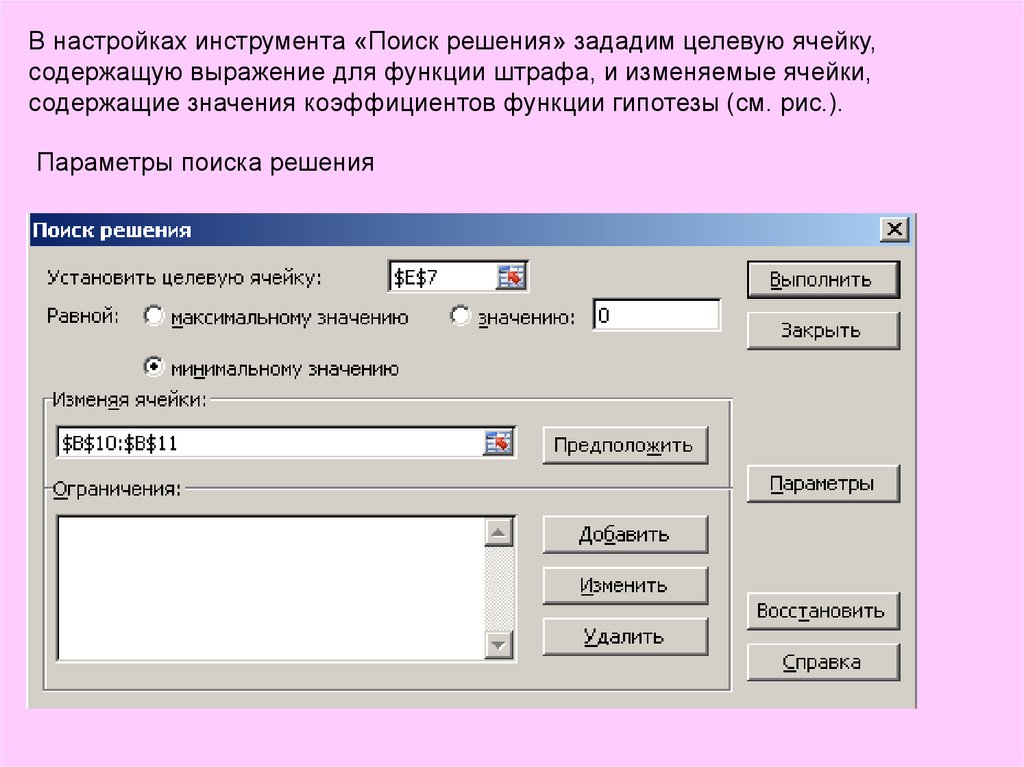
В настройках инструмента «Поиск решения» зададим целевую ячейку,содержащую выражение для функции штрафа, и изменяемые ячейки,
содержащие значения коэффициентов функции гипотезы (см. рис.).
Параметры поиска решения
19.
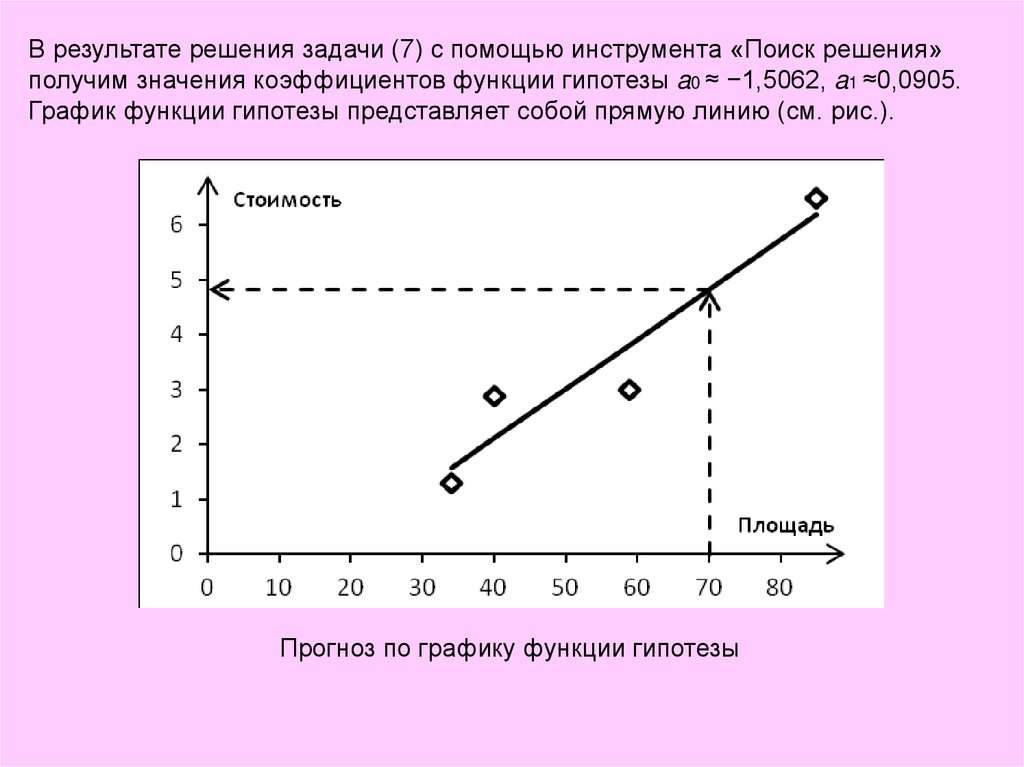
В результате решения задачи (7) с помощью инструмента «Поиск решения»получим значения коэффициентов функции гипотезы a0 ≈ −1,5062, a1 ≈0,0905.
График функции гипотезы представляет собой прямую линию (см. рис.).
Прогноз по графику функции гипотезы