


































 russian
russianSimilar presentations:
")









Графематический анализ
1.
Графематический анализ1
2.
Синтаксическая сегментацияВыделение синтаксических групп (частичный
синтаксический анализ, syntactic chunking):
именных, глагольных и др.
читать книгу, о бедном гусаре, синий-синий
презеленый красный шар, лежать дрожа
Выделение простых предложений в составе
сложных для проведения их независимого
синтаксического анализа (на основе слов:
который, когда, потому что и пр.)
После дождя дети ждали радугу, но дождь не
собирался останавливаться.
более глубокая лингвистическая обработка
2
3.
Макросинтаксическийанализ
Выделение композиционных элементов:
• абзацев и заголовков
• разделов/подразделов
• эпиграфов, грифов
• вставок, комментариев
• сносок, примечаний и пр.
Установление иерархии абзацев, заголовков,
предложений
учитывает стандарты оформления текстов
(распоряжение, инструкция, договор и т.д.)
по-другому называется композиционный анализ
подходы к решению сходны с подходами к
сегментации нижнего уровня
3
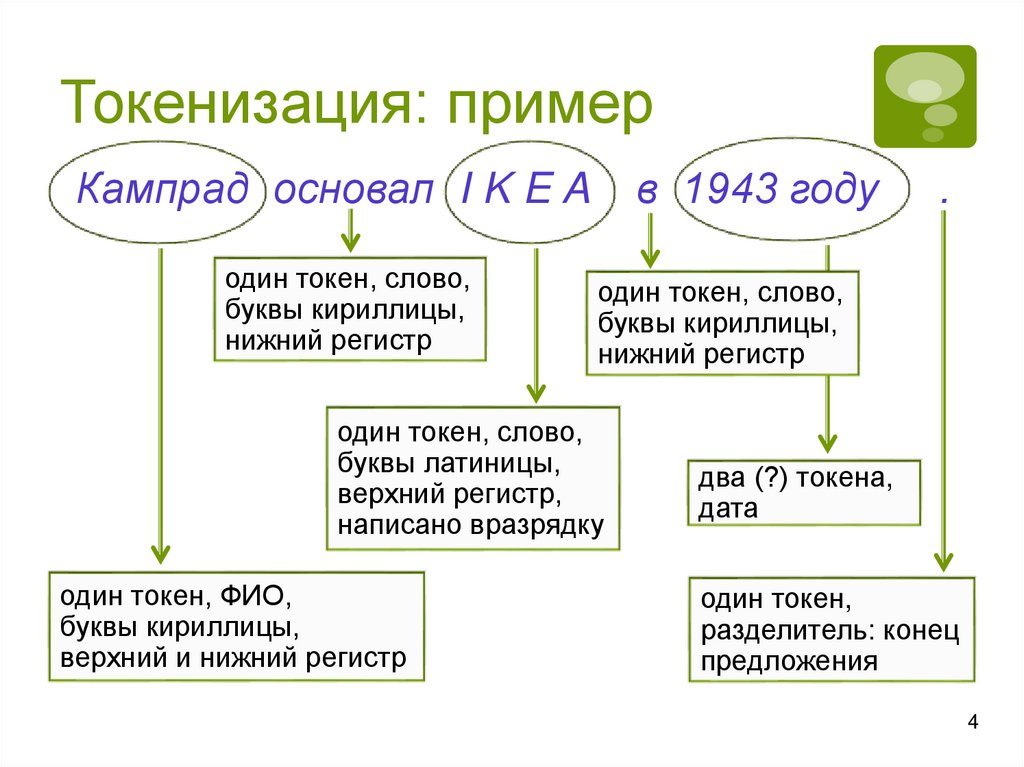
4.
Токенизация: примерКампрад основал I K E A
один токен, слово,
буквы кириллицы,
нижний регистр
в 1943 году
один токен, слово,
буквы кириллицы,
нижний регистр
один токен, слово,
буквы латиницы,
верхний регистр,
написано вразрядку
один токен, ФИО,
буквы кириллицы,
верхний и нижний регистр
.
два (?) токена,
дата
один токен,
разделитель: конец
предложения
4
5.
Обработка сложныхтокенов (1)
● Различение тире, знака переноса и истинного
дефиса, разбиение сложносоставных слов:
он – гений, сбор-ка, девица-красавица
● Сборка слов, написанных вразрядку:
Заявление → заявление
● Нормализация (приведение к одному формату)
дат и других особых токенов: 3 PM → 15.00,
сто двадцать три → 123
● Определение регистра букв и восстановление
правильного (truecase): МОСКВА, москва – Москва
5
6.
Обработка сложныхтокенов (2)
● Свертка сложносоставных предлогов и устойчивых
неизменяемых оборотов (не имеющих
словоизменительных вариантов):
в связи с, так сказать, таким образом
● Обработка сокращений слов и словосочетаний
(неразрывных и разрывных):
they’re, г. Москва, д/з
● Выделение полного имени (фамилия, имя, отчество):
К.А. Петров, Анастасия Дорохова
Требуется анализ контекста знаков и
лингвистическая и лексическая информация:
правила преобразования, словари (предлогов,
словосочетаний, имен собственных) и пр.
6
7.
Сложности обработкипредложений
Встречаются сокращения, имена, числа, цитаты
Разное оформления, например, прямой речи
Возможны пропуски и неверное использование знаков
Требуется анализ локального контекста маркеров
15.03 я смотрел на Кота Б. Б. Кот смотрел на меня.
Я живу на ул. Ленина и меня зарубает время от
времени.
Я сказала: «Это Анин кот!». – I said: «It’s Ann’s cat!»
Парсеp, Разбей эти... буквы, знаки и т.п. на
предложения. И покажи пож. как со словом
S.T.A.L.K.E.R. получится.
а ты знаешь что делать с субтитрами на ютьюб
даже не представляю а ты
7
8.
Примеры графематическиханализаторов (ГА) NLTK
8
9.
ГА в NLTKhttps://vc.ru/newtechaudit/309131-obzor-tokenizatorovvhodyashchih-v-sostav-biblioteki-nltk
В NLTK есть 19 ГА в классе tokenize
Умеют делить на тематические блоки из
нескольких абзацев, предложения, токены
Разные разработчики, разные языки, разные
подходы:
регулярные выражения
правила и словари
обучение без учителя (только один!)
ГА также есть в Keras, Gensim и пр.
9
10.
ГА в NLTK: из интересногоЕсть ГА
делящие слова на слоги
проверяющие правильность арифметического
выражения (баланс скобок)
Есть TweetTokenizer
создан для обработки сообщений Twitter
можно настроить на другую задачу, задав новый
список регулярных выражений
Примеры ГА:
wordpunct_tokenize – текст на токены по
пробельным символам и знакам пунктуации
sent_tokenize – текст на предложения
word_tokenize – текст на токены по правилам
10
11.
Примеры ГА (1)TextTilingTokenizer
делит текстовые документы на блоки,
представляющие собой подтемы
опирается на статистические характеристики
употребления слов
PunktSentenceTokenizer
делит текст на список предложений
использует алгоритм обучения без учителя для
определения слов-сокращений и слов/
словосочетаний, с которых начинаются
предложения
при отсутствии готовой модели требует обучения
на большом наборе текстов
11
12.
Примеры ГА (2)«Простые» (simple) ГА SpaceTokenizer,
TabTokenizer и LineTokenizer разделяют строки с
помощью строкового метода split()
RegexpTokenizer
разбивает текст на токены
использует передаваемое ему регулярное
выражение
есть подклассы, использующих заранее
определенные регулярные выражения:
WhitespaceTokenizer, BlanklineTokenizer,
WordPunctTokenizer
12
13.
TreebankWordTokenizerВ качестве эталона использует разделение, принятое
в Penn Treebank – корпусе текстов с размеченной
синтаксической и семантической структурой
предложений
Опирается на регулярные выражения и правила,
например:
разделяет стандартные сокращения (don’t – do n’t)
считает – отдельными токенами:
✓ большинство знаков препинания
✓ запятые и одинарные кавычки, если за ними
следует пробел
✓ точки в конце строк
13
14.
MWETokenizerБерет обработанную строку и повторно анализирет ее,
объединяя нескольких токенов в отдельные
txt = 'Президент России посетил Липецкую область.'
tok = tokenize.WordPunctTokenizer()
text_words = tok.tokenize(txt)
print(text_words)
['Президент', 'России', 'посетил', 'Липецкую',
'область','.']
tok = tokenize.MWETokenizer(separator=' ')
tok.add_mwe(('Липецкую', 'область'))
tok.add_mwe(('Президент', 'России'))
print(tok.tokenize(text_words))
['Президент России', 'посетил', 'Липецкую
область','.']
14
15.
Морфология: морфемика иморфосинтаксис
15
16.
Функции морфологииОписание формальных свойств слов и значений,
выражаемых внутри них
Словообразование (в языке) – создание новых слов
путем добавления/изменения морфем
Словообразовательная парадигма:
делать – переделать – сделать – недоделать – дело
– деловой – …
Словоизменение (в тексте) – выражение нужной
грамматической информации
Словоизменительная парадигма:
делать – делаю – делала – делай – делающий – делая
Парадигма (греч.) – образец, пример (лингвистика:
система форм)
16
17.
Морфология: морфемикаСлова состоят из морфов – минимальных значащих
единиц ЕЯ
Корень (корневой) – носитель основного смысла
Аффикс – служебный, придает дополнительный смысл:
✓ префикс (приставка), суффикс: сход, буровой,
✓ флексия (окончание): начальный, shoes
✓ интерфикс (соединительная гласная): паровоз
✓ постфикс: частица ся, сь
Префиксоиды и суффиксоиды – промежуточные виды
морфов: равновеликий, пятиэтажный
Использование:
разбиение на морфы/слоги
лемматизация и стемминг
исправление ошибок: здал; дипломат – дипломант
17
18.
Морфология:морфосинтаксис
Морфосинтаксис изучает
функции слова в предложении
вытекающее из этих функций изменение
формы слова
Для удобства изучения слова разделяются на
части речи – группы слов, объединенные
обобщенным значением
морфологическими признаками/параметрами
(у которые есть значения)
синтаксической ролью в
словосочетании/предложении
Примеры?
18
19.
Словарные и бессловарныемодели
19
20.
Грамматический словарь русскогоязыка, Зализняк А.А., 1977
● Основа большинства морфоанализаторов РЯ
● Системный подход к описанию морфологических
парадигм РЯ, включает ударения
● 100 тыс. словарных входов (лексем)
● Много старых слов, нет новых
20
21.
Словари словоформВ словаре содержатся все словоформы
с указанием значений МП, части речи и леммы
Неизменяемые слова также включены в
словарь
Задача морфопроцессора: поиск заданной
словоформы в словаре и выдача приписанной
ей информации
2609577 96056
одухотворяющие
прич
дст, но, од, нст, им, мн
2609578 96056
одухотворяющих
прич
дст, но, од, нст, рд, мн
2609579 96056 одухотворяющим
прич
дст, но, од, нст, дт, мн
21
22.
Словари основ/псевдооснов● В словаре содержатся возможные в ЕЯ основы слов с
морфологической информацией
объем словаря ≈ числу лексем в ЕЯ
● Он связан со вспомогательными словарями:
списком окончаний (флексий), для каждого –
возможные флективные классы (ФК) и
соответствующие наборы значений МП
информации об особенностях словоизменения, в
частности о чередовании букв, о беглых гласных
информации о нерегулярном словоизменении
Служебные и неизменяемые слова могут храниться и
обрабатываться отдельно
22
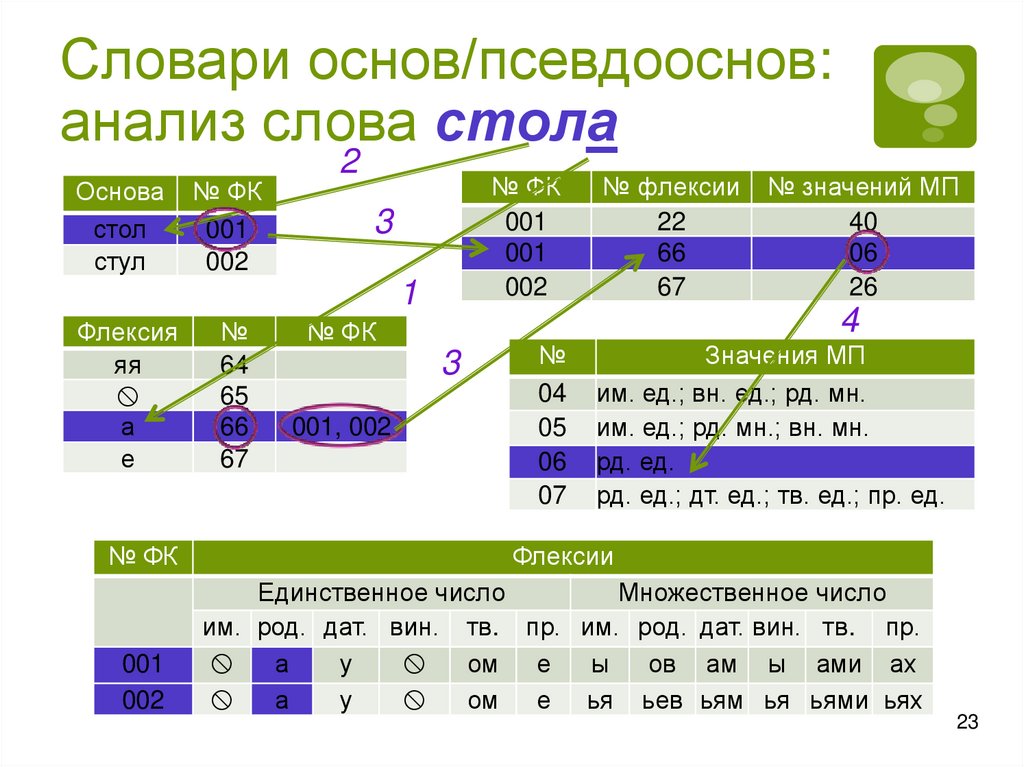
23.
Словари основ/псевдооснов:анализ слова стола
Основа
стол
стул
№ ФК
001
002
2
№ ФК
001
001
002
3
1
Флексия
яя
а
е
№
64
65
66
67
№ значений МП
40
06
26
4
№ ФК
3
001, 002
№ флексии
22
66
67
№
04
05
06
07
Значения МП
им. ед.; вн. ед.; рд. мн.
им. ед.; рд. мн.; вн. мн.
рд. ед.
рд. ед.; дт. ед.; тв. ед.; пр. ед.
№ ФК
Флексии
001
002
Единственное число
Множественное число
им. род. дат. вин. тв. пр. им. род. дат. вин. тв. пр.
а
у
ом е
ы
ов ам ы ами ах
а
у
ом е ья ьев ьям ья ьями ьях
23
24.
Дополнительные функцииморфопроцессоров
24
25.
Анализ незнакомых словНезнакомые слова – отсутствующие в словаре
Для обработки используются
предсказание по окончанию: поиск словарной
словоформы, с которой анализируемое слово
имеет максимальное число общих конечных букв,
но не вкладывается в нее: курить – банить
предсказание по префиксу: поиск словарной
словоформы, с которой после отсечения префикса
(не более 5 букв) совпадает оставшаяся часть
анализируемого слова (на менее 4 букв)
[квази]отношения – отношения
При этом незнакомое слова разбирается по образцу
найденной в словаре словоформы
Корректность: 90-95%
25
26.
Морфологическая омонимияСитуация, когда одной словоформе/лемме
соответствует несколько наборов значений
морфологических признаков (включая ЧР)
женщины
потом
МН. Ч., ИМ. П.
НАРЕЧИЕ
ЕД. Ч., РОД. П.
СУЩ., ЕД. Ч., ТВ. П.
Cнятие (разрешение) омонимии облегчает
последующие этапы обработки текста:
сокращается объем хранимой информации и
увеличивается скорость ее обработки
уменьшается количество деревьев разбора на
синтаксическом этапе
сокращается число различных значений слова на
семантическом этапе
26
27.
Подход к снятию омонимииОсновная идея – учет контекста словоформы
По улице шли женщины…
Нет женщины прекраснее…
Методы, основанные на (контекстных) правилах,
составляемых экспертами-лингвистами
Методы, основанные на (контекстных) правилах,
выводимых из текстов (с управляемым и с
неуправляемым обучением)
Методы, основанные на вероятностных моделях (с
управляемым и с неуправляемым обучением)
Методы, основанные на нейронных сетях
Гибридные методы
Точность определения МП – до 95%, точность
определения лемм – до 96%
27
28.
Примеры правилВ виде правил фиксируются допустимые
синтаксические связи слов
1. Из {Сущ., Гл.} выбрать Сущ., если до него
стоит Пр. => посмотреть в стекло => стекло –
Сущ.
2. Если словоформы W1 и W2 связаны союзом
и/да/либо/или, и у них есть совпадающие
варианты разбора, то оставить как результат
разбора только их => в комнату зашли врач и
больной => больной – СУЩ., М. РОД, ЕД. ЧИСЛО,
ИМ. ПАДЕЖ
Сейчас чаще используют другие подходы
28
29.
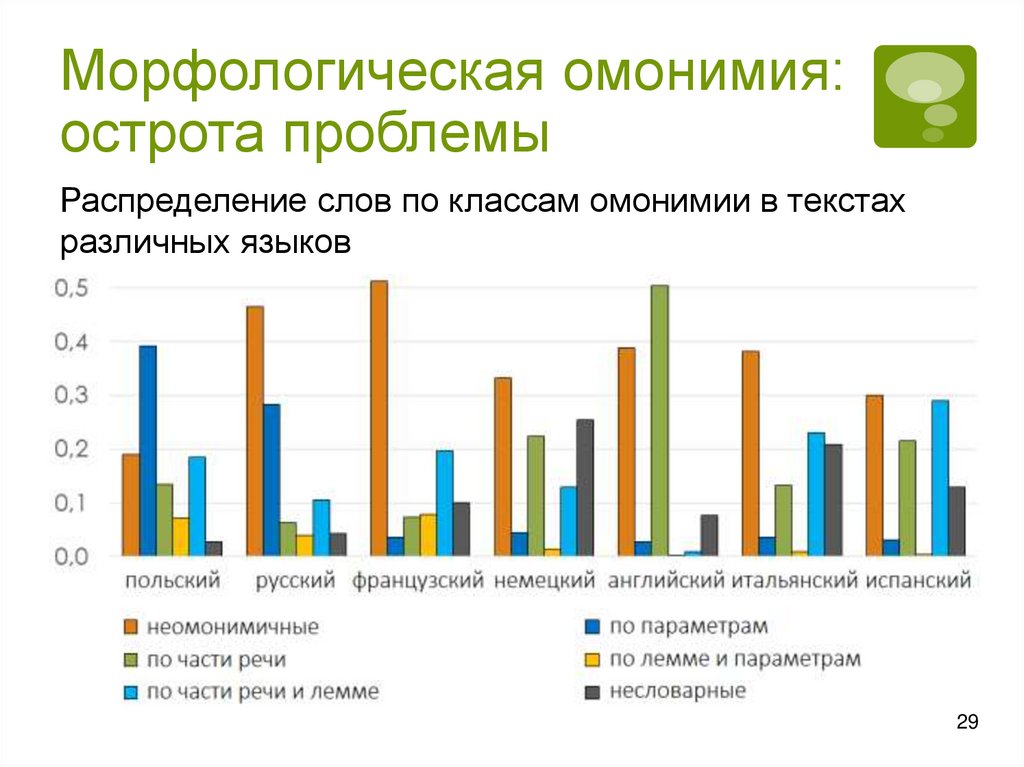
Морфологическая омонимия:29 острота проблемы
Распределение слов по классам омонимии в текстах
различных языков
29
30.
МА в других языках30
31.
Примеры морфоанализадля других ЕЯ
Немецкий язык – необходимо делить на слова:
Donaudampfschifffahrtskapitän – капитан рейса,
выполняемого пароходом по Дунаю
Турецкий язык – нужно выделять аффиксы:
Muvaffak – успешный
Muvaffakiyet – успех
Muvaffakiyetsiz – неуспешный
Muvaffakiyetsizleş – стать неуспешным
Muvaffakiyetsizleştiricileştiriveremeyeebileceklerimizdenmişsinizcesine –
как будто бы ты оказался среди тех, кого нам непросто будет
сделать теми, кто делает кого-то неуспешными
31
32.
Морфологическиепроцессоры
32
33.
Морфопроцессоры в NLTKВ NLTK есть 11 (?) морфологических процессоров в
классе stem
Теггер для английского языка
Отдельные стеммеры
✓ для арабского (возвращают корень) 3 стеммера
✓ для немецкого
✓ для португальского
✓ для английского 3 стеммера
Стеммер для нескольких языков (Arabic, Danish, Dutch,
English, Finnish, French, German, Hungarian, Italian,
Norwegian, Portuguese, Romanian, Russian, Spanish
and Swedish)
WordNetLemmatizer – лемматизатор и теггер для
английского, основанный на словаре (единственный)
33
34.
Морфопроцессорpymorphy2 (1)
34
Код: https://github.com/kmike/pymorphy2
Документация: pymorphy2.rtfd.org
Открытый проект (код полностью открыт), автор –
Михаил Коробов
Существует с 2012, поддерживается, улучшается
Язык программирования – python
Обрабатываемые языки – русский, украинский
Предоставляет все функции морфологического
анализа и синтеза словоформ
Использует словарь OpenCorpora
(http://opencorpora.org/), который включает 250 тыс.
лемм, открыт, регулярно пополняется
34
35.
Морфопроцессорpymorphy2
(2)
35
При анализе pymorphy2 возвращает псевдооснову,
лемму и определяет все морфологические
характеристики
При синтезе возвращает как все словоформы, так и
словоформа с заданными характеристиками
Реализует несколько методов для анализа
незнакомых слов (попытка отсечения префикса,
разбор по окончанию)
Разрешение омонимии на основе корпусной
статистики. Если слово имеет несколько вариантов
разбора, то среди них выбирается наиболее
вероятный
35
36.
МорфопроцессорMyStem (1)
36
Код: https://yandex.ru/dev/mystem/
Yandex, код – полностью закрыт
Первая версия – 90-е годы, с тех пор
существенные изменения, поддерживается
Есть консольное приложение для разных
операционных систем
Обрабатываемый язык – русский
Полный морфологический анализ, синтеза нет
Использует словарь НКРЯ (ruscorpora.ru),
который включает 200 тыс, лемм
36
37.
МорфопроцессорMyStem (2)
37
Для разрешения морфологической омонимии
(в зависимости от входных данных) может
учитывать контекст (опирает на машинное
обучение)
Проводит разбор незнакомых слов (опирает
на машинное обучение)
Позволяет подключать собственные словари
Анализирует текст целиком значительно
быстрее, чем по одному слову
37
38.
SnowballЯзык программирования для создания алгоритмов
стемминга
В основе – алгоритм Портера, 1980 г.
Изначально создан для английского языка,
но разработаны модификации для различных ЕЯ
Приблизительно 60 правил преобразования входной
словоформы, применяемых последовательно
Правила имеют вид:
<условие> <окончание> <новое окончание>
(m>0) E E D E E – если в словоформе есть хотя бы
одна гласная и словоформа имеет окончание -eed, то
оно заменяется на -ee (agreed agree)
Используется специальная таблица исключений
(например, для неправильных глаголов)
38