









 database
databaseSimilar presentations:


")




")


ETL - извлечение данных
1.
Курс«Хранилища данных»
Тема:
ETL - извлечение данных
Барабанщиков
Игорь Витальевич
2.
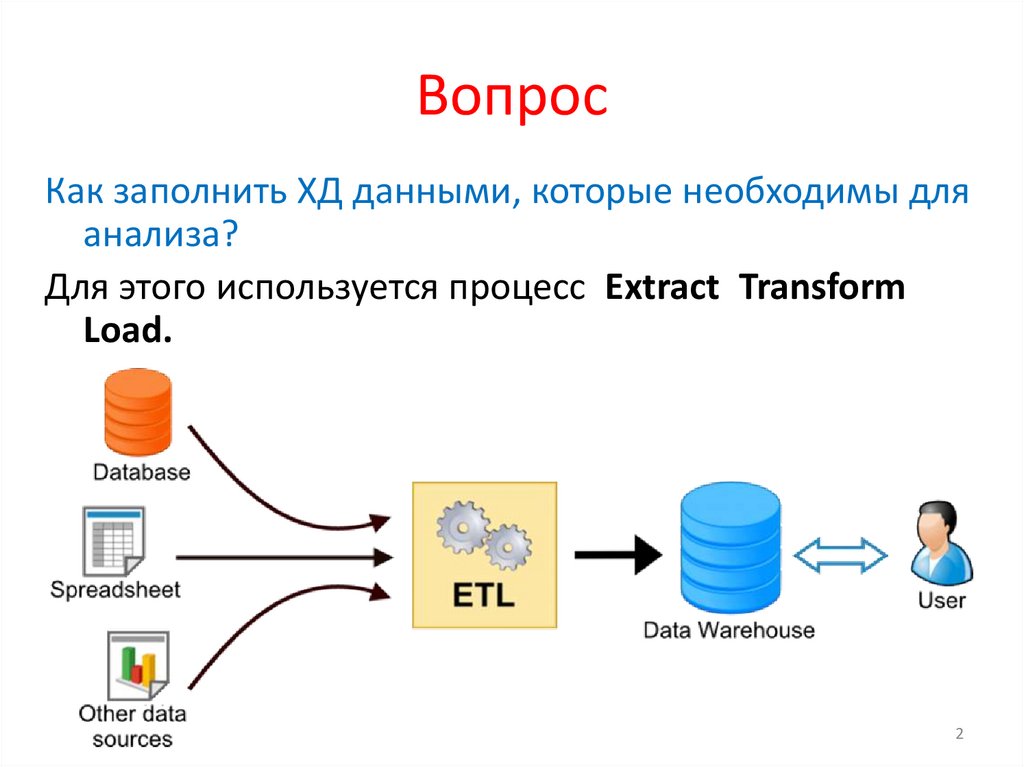
ВопросКак заполнить ХД данными, которые необходимы для
анализа?
Для этого используется процесс Extract Transform
Load.
2
3.
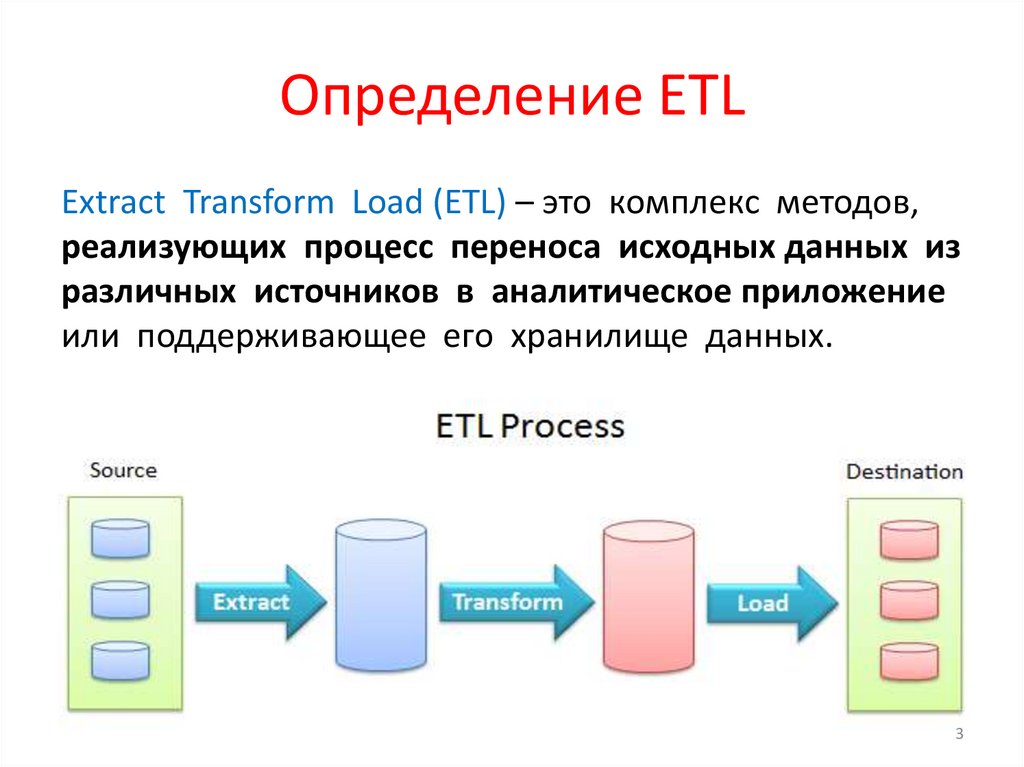
Определение ETLExtract Transform Load (ETL) – это комплекс методов,
реализующих процесс переноса исходных данных из
различных источников в аналитическое приложение
или поддерживающее его хранилище данных.
3
4.
Заполнение ХДЗаполнение хранилища данными включает в
себя задачи:
• Получение данных от рабочей системыисточника.
• Очистку данных.
• Преобразованием данных в нужный формат и
нужную степень детализации.
• Загрузку данных в хранилище.
• Подготовку данных к использованию в
аналитических целях.
4
5.
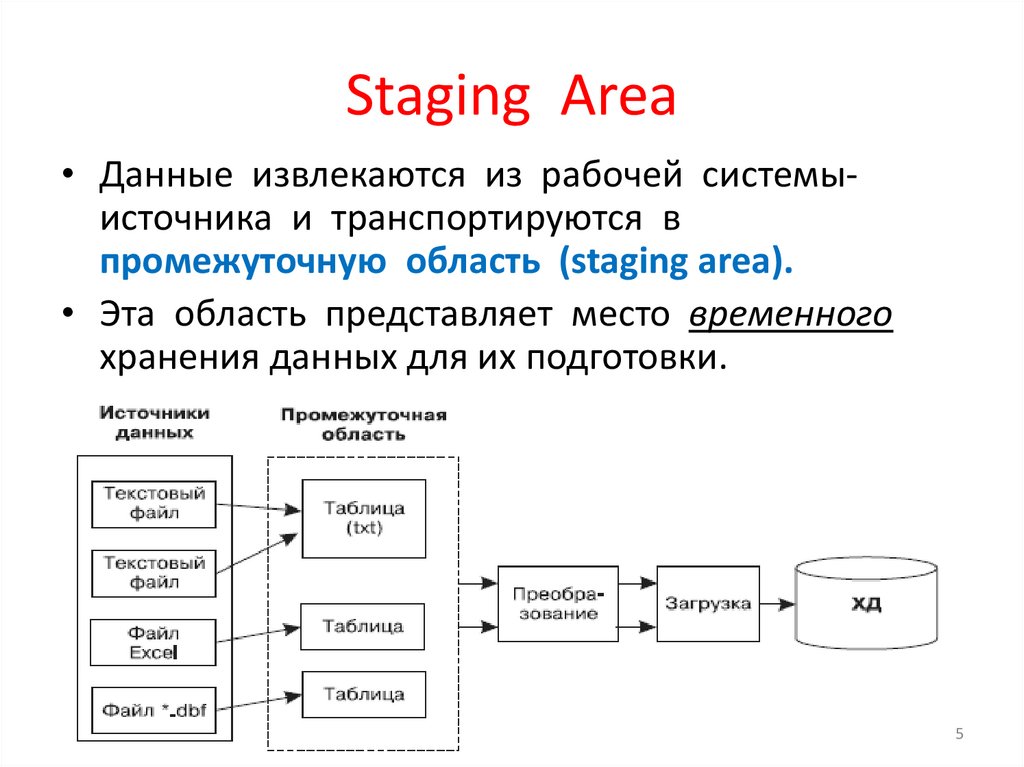
Staging Area• Данные извлекаются из рабочей системыисточника и транспортируются в
промежуточную область (staging area).
• Эта область представляет место временного
хранения данных для их подготовки.
5
6.
Способы извлечения данных• Есть прямой доступ к системе-источнику
данных:
- доступ через шлюз
- доступ через ODBC (малый объем данных)
- прямое соединение с БД (своя программа)
- ETL-средства разных поставщиков
• Нет прямого доступа к системе-источнику
данных:
- выгрузка данных из БД в файлы
6
7.
Извлечение данных• Чтобы свести к минимуму влияние на
производительность базы-источника данные,
как правило, выкачиваются без применения
преобразований.
• Часто администраторы рабочих систем не
дают разработчикам ХД прямого доступа к
своим системам, но предоставляют
периодические выгрузки данных.
• Эти выгрузки обычно имеют форму простых,
последовательных файлов рабочей системы,
которые и представляют собой промежуточную
область.
7
8.
Выявление изменившихся данных• После первоначальной загрузки данных в
хранилище, по мере того, как меняются
исходные данные, данные в хранилище надо
обновлять на регулярной основе, чтобы они
отражали происходящие изменения.
• Надо установить механизм, позволяющий
отслеживать и фиксировать интересующие
изменения в рабочих системах.
• В хранилище данных надо вносить
изменение, а не перестраивать всё
хранилище.
8
9.
Методы выявления новых данных• Установка временной отметки при
изменении строки данных в рабочей
системе.
• В реляционной БД для выявления
изменений можно использовать триггеры.
• Сравнение файлов.
• Технология Oracle Streams.
9
10.
Установка отметки времени• При изменении строки данных в рабочей
системе в нее записывается отметка времени.
• Программа извлечения данных отбирает
данные на основе отметки времени
транзакции и извлекает все строки, которые
обновились с момента последнего
извлечения.
• Пример: при перемещении данных из системы
обработки заказов в ХД строки отбираются на
основе значения даты покупки.
10
11.
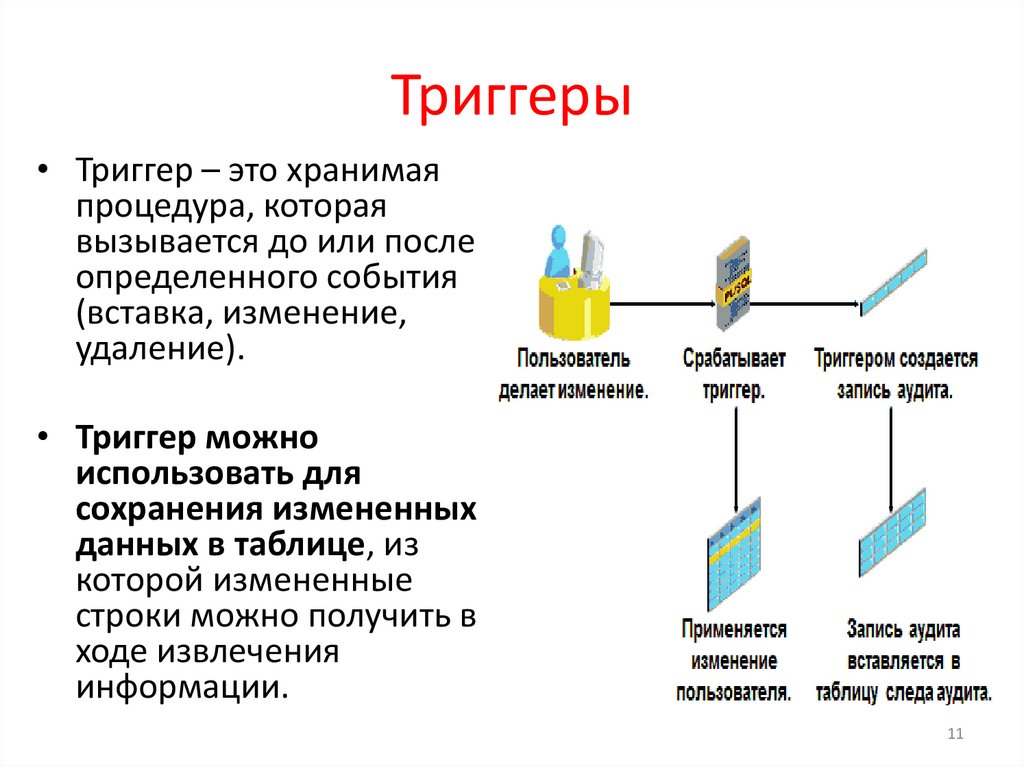
Триггеры• Триггер – это хранимая
процедура, которая
вызывается до или после
определенного события
(вставка, изменение,
удаление).
• Триггер можно
использовать для
сохранения измененных
данных в таблице, из
которой измененные
строки можно получить в
ходе извлечения
информации.
11
12.
Сравнение файлов• Иногда нет возможности изменить схему и
добавить отметку времени или триггер.
• Система может быть сильно нагружена и вы не
хотите ухудшить ее производительность.
• Источником данных может быть традиционная
система, в которой триггеры отсутствуют.
• Для выявления изменений может
потребоваться сравнение файлов.
• Для этого нужно сохранять образцы файлов,
извлеченных на разных этапах (последний и
предыдущий).
12
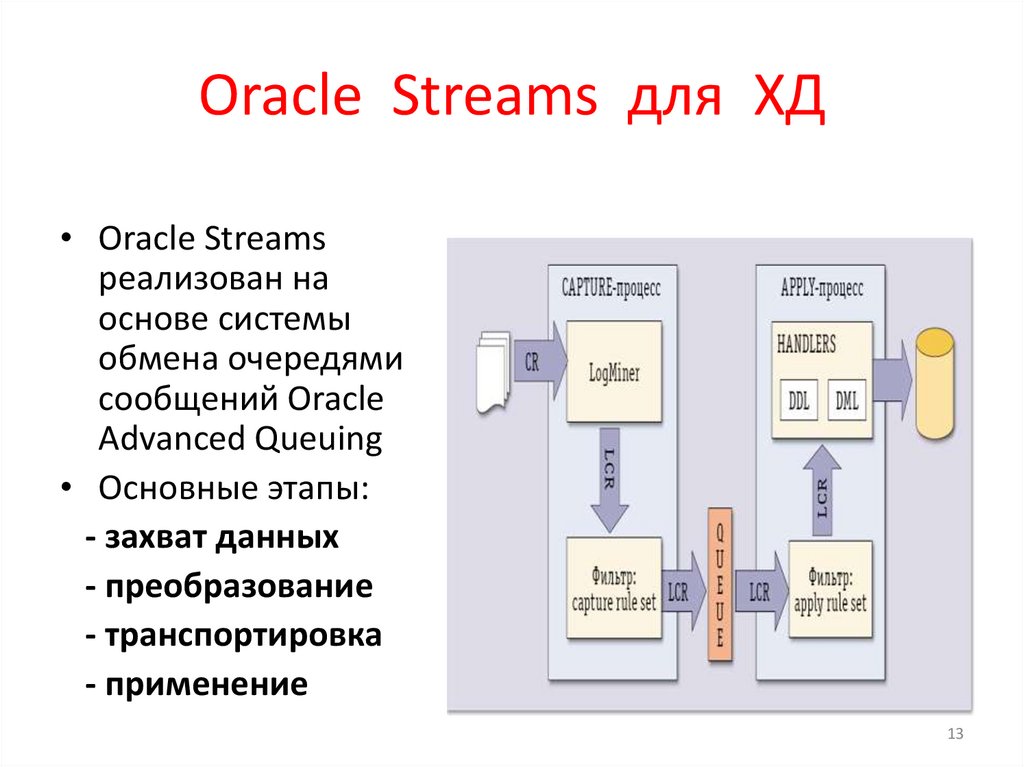
13.
Oracle Streams для ХД• Oracle Streams
реализован на
основе системы
обмена очередями
сообщений Oracle
Advanced Queuing
• Основные этапы:
- захват данных
- преобразование
- транспортировка
- применение
13
14.
Преимущества Oracle Streams• При помещении/извлечении из/в Staging Area можно
выполнить операции очистки и преобразования
данных.
• В случае Oracle Streams можно организовать
непрерывную подпитку хранилища или ODS “тонкой
струйкой” изменений, при этом отставание ODS или
хранилища от оперативной системы будет
минимальным и эту целевую БД можно использовать
для получения отчетов или анализа данных почти в
реальном времени.
• Поскольку изменения захватываются из журналов, нет
необходимости давать администраторам хранилища
или ODS доступ к оперативным системам, что очень
порадует администраторов оперативных систем.
14
15.
Итоги• Важным этапом создания ХД является
разработка ETL-процесса.
• Для реализации ETL можно использовать
специализированное ПО для интеграции
данных из разных источников.
• При использовании виртуальных ХД
можно отказаться от процесса ETL и
работать напрямую с источниками данных.
15