


















 internet
internet programming
programmingSimilar presentations:










RDMA, GPUDirect, NVLink, NCCL
1.
Понятие об RDMA,GPUDirect, NVLink, NCCL
Сучков Егор Петрович
2.
What is RDMAA (relatively) new method for interconnecting
platforms in high-speed networks that
overcomes many of the difficulties encountered
with traditional networks such as TCP/IP over
Ethernet.
– new standards
– new protocols
– new hardware interface cards and switches
– new software
3.
Remote Direct Memory AccessRemote
– data transfers between nodes in a network
Direct
– no Operating System Kernel involvement in transfers
– everything about a transfer offloaded onto Interface Card
Memory
– transfers between user space application virtual memory
– no extra copying or buffering
Access
– send, receive, read, write, atomic operations
4.
RDMA BenefitsHigh throughput
Low latency
High messaging rate
Low CPU utilization
Low memory bus contention
Message boundaries preserved
Asynchronous operation
5.
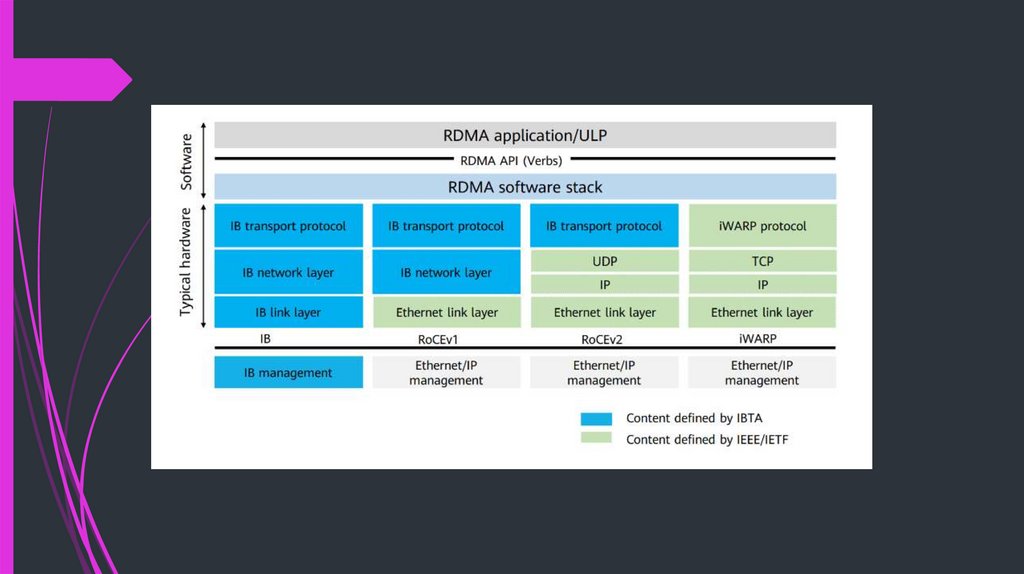
RDMA TechnologiesInfiniBand – (41.8% of top 500 supercomputers)
– SDR 4x – 8 Gbps
– DDR 4x – 16 Gbps
– QDR 4x – 32 Gbps
– FDR 4x – 54 Gbps
iWarp – internet Wide Area RDMA Protocol
– 10 Gbps
RoCE – RDMA over Converged Ethernet
– 10 Gbps
– 40 Gbps
6.
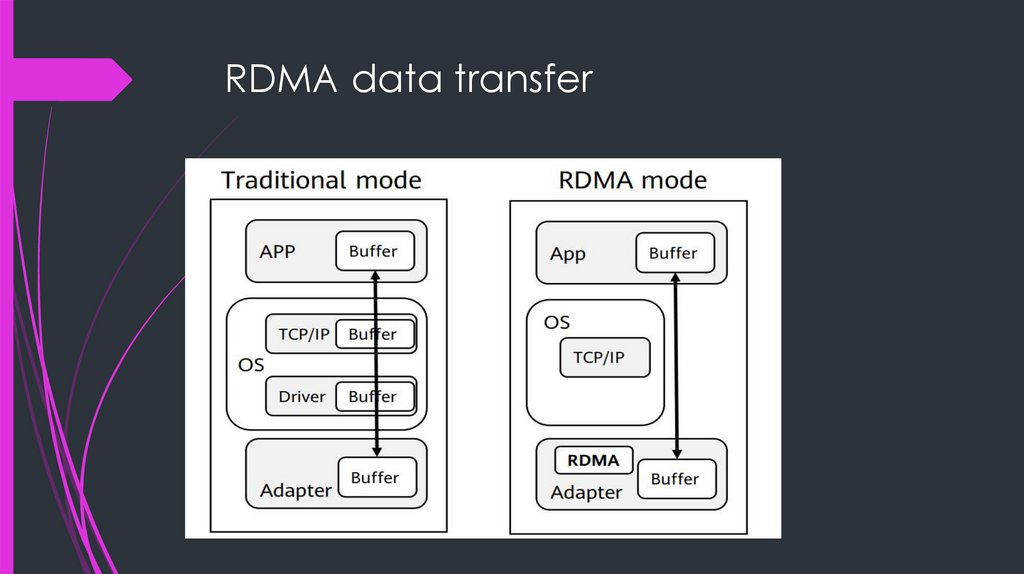
RDMA data transfer7.
8.
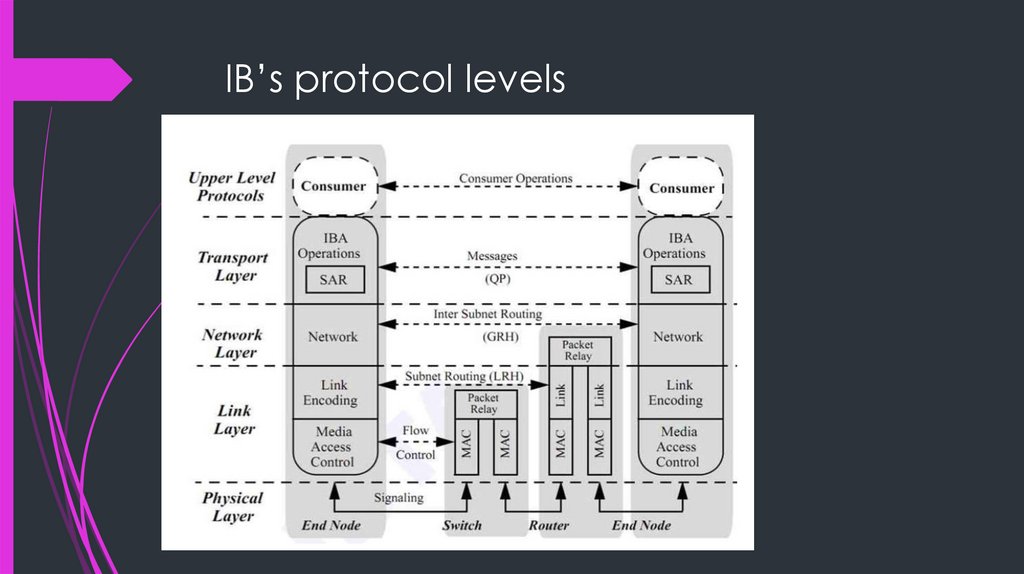
IB’s protocol levels9.
Similarities between TCP and RDMABoth utilize the client-server model
Both require a connection for reliable transport
Both provide a reliable transport mode
– TCP provides a reliable in-order sequence of bytes
– RDMA provides a reliable in-order sequence of messages
10.
How RDMA differs from TCP/IP“zero copy” – data transferred directly from
virtual memory on one node to virtual memory
on another node
“kernel bypass” – no operating system
involvement during data transfers
asynchronous operation – threads not blocked
during I/O transfers
11.
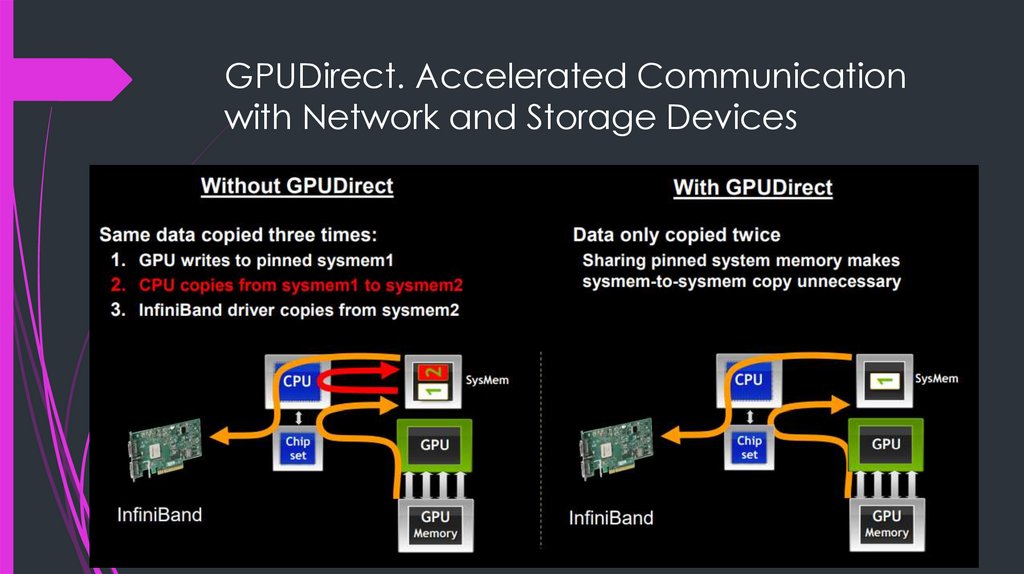
NVIDIA GPUDirect12.
GPUDirect. Accelerated Communicationwith Network and Storage Devices
13.
Using GPUDirectCUDA 4.0 and later:
Set the environment variable CUDA_NIC_INTEROP=1
Ensures access to CUDA pinned memory by third party drivers
All CUDA pinned memory will be allocated first in user-mode as pageable
memory
CUDA and third party driver pin and share the pages via get_user_pages()
Requires NVIDIA Drivers v270.41.19 or later
Requires Linux kernel 2.6.15 or later (no Linux kernel patch required)
Earlier releases:
Only necessary when using NVIDIA Drivers older than v270.41.19
Developed jointly by NVIDIA and Mellanox
New interfaces in the CUDA and Mellanox drivers + Linux kernel patch
Installation instructions at http://developer.nvidia.com/gpudirect
Supported for Tesla M and S datacenter products on RHEL only
14.
GPUDirect. Peer-to-PeerCommunication
15.
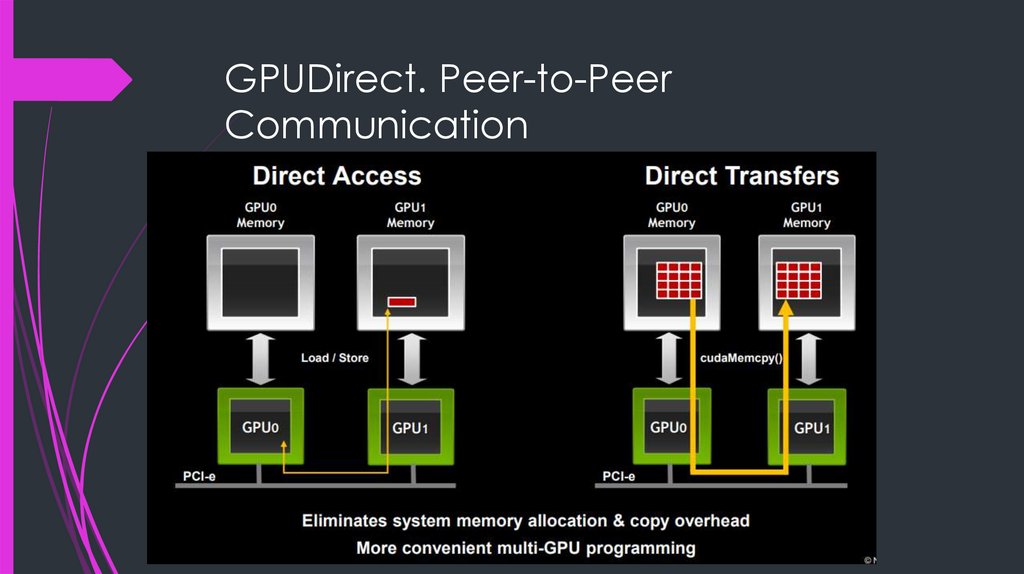
GPUDirect. Peer-to-PeerCommunication
Direct Access
GPU0 reads or writes GPU1 memory (load/store)
Data cached in L2 of the target GPU
Direct Transfers
cudaMemcpy() initiates DMA copy from GPU0 memory to GPU1
memory
Works transparently with CUDA Unified Virtual Addressing (UVA)
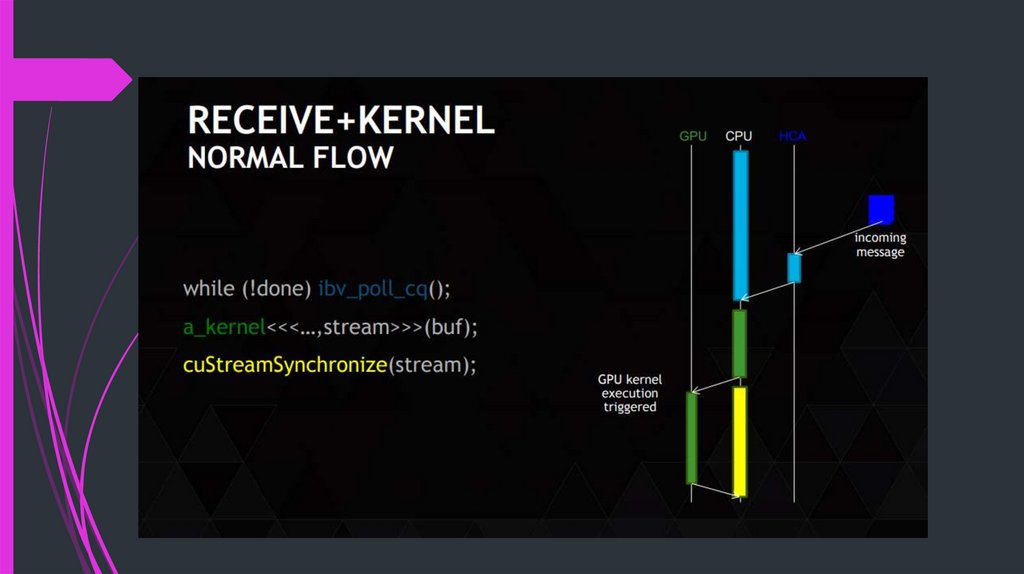
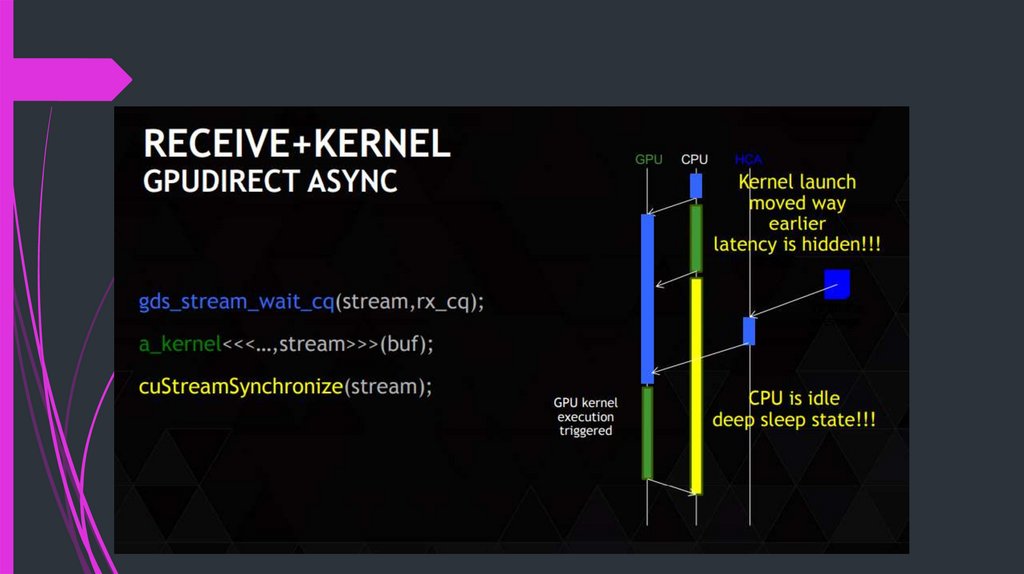
16.
17.
18.
19.
20.
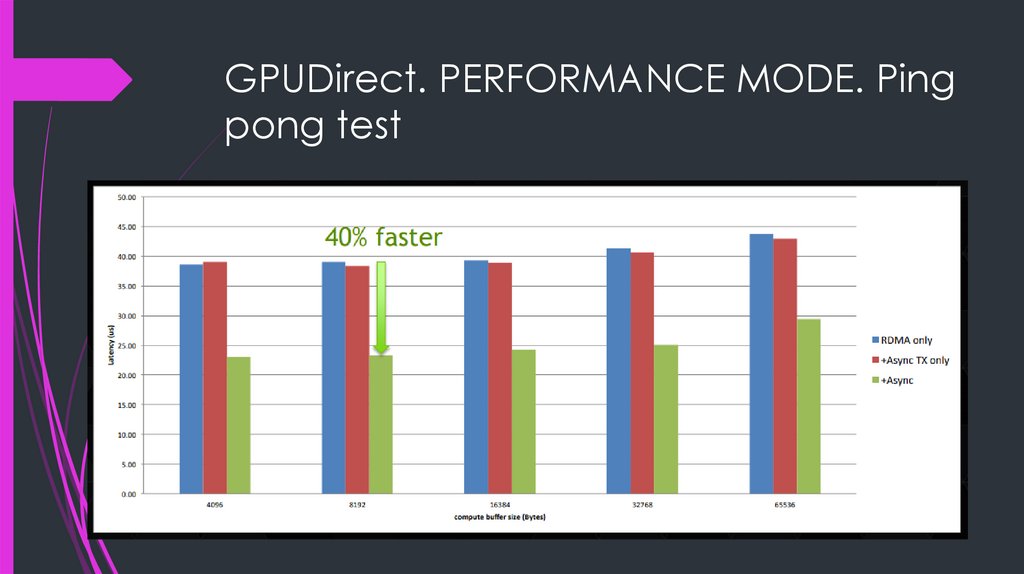
GPUDirect. PERFORMANCE MODE. Pingpong test
21.
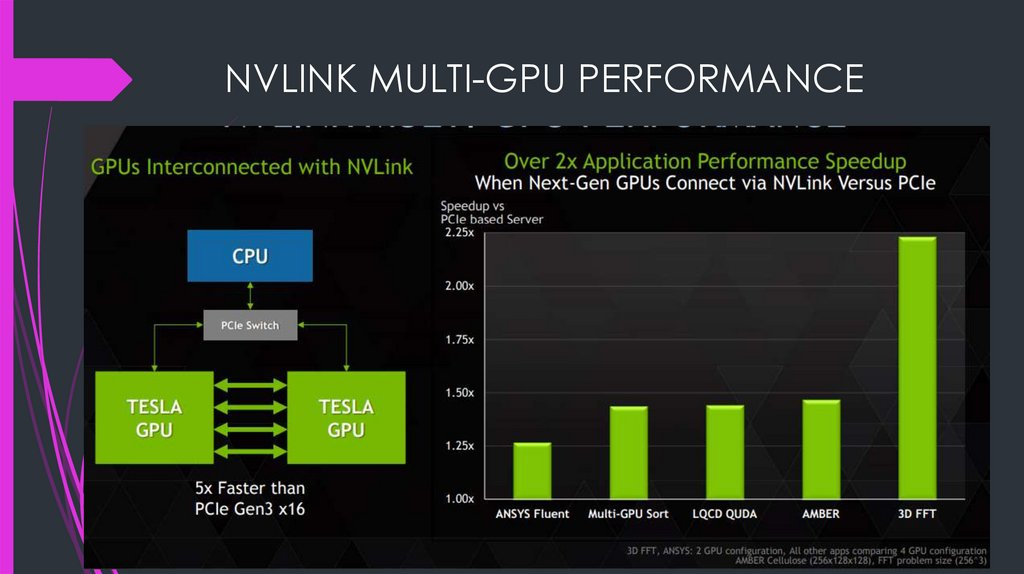
NVLink22.
NVLink Performance23.
NVLINK MULTI-GPU PERFORMANCE24.
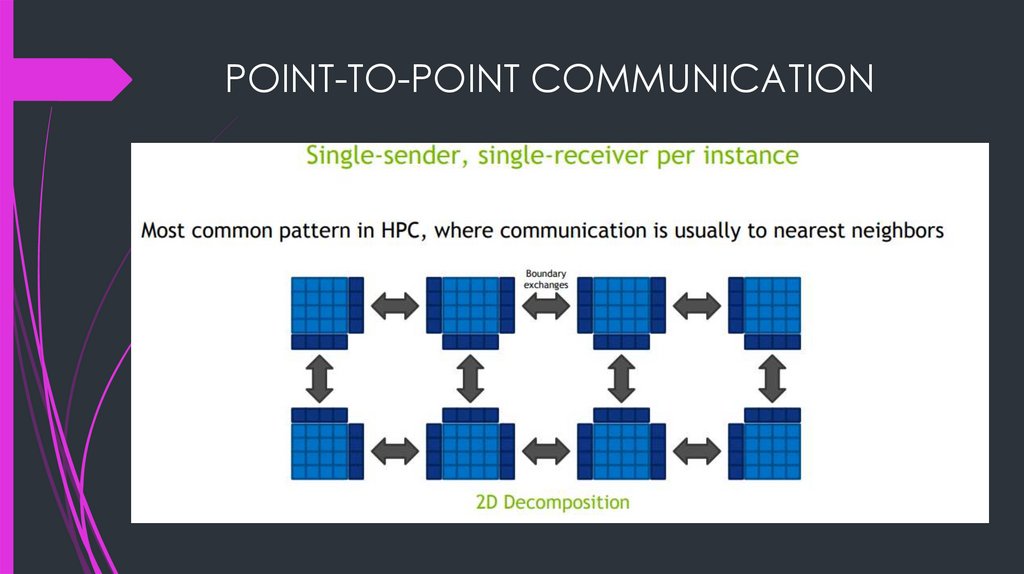
COMMUNICATION AMONG TASKSPoint-to-point communication
Single sender, single receiver
Relatively easy to implement efficiently
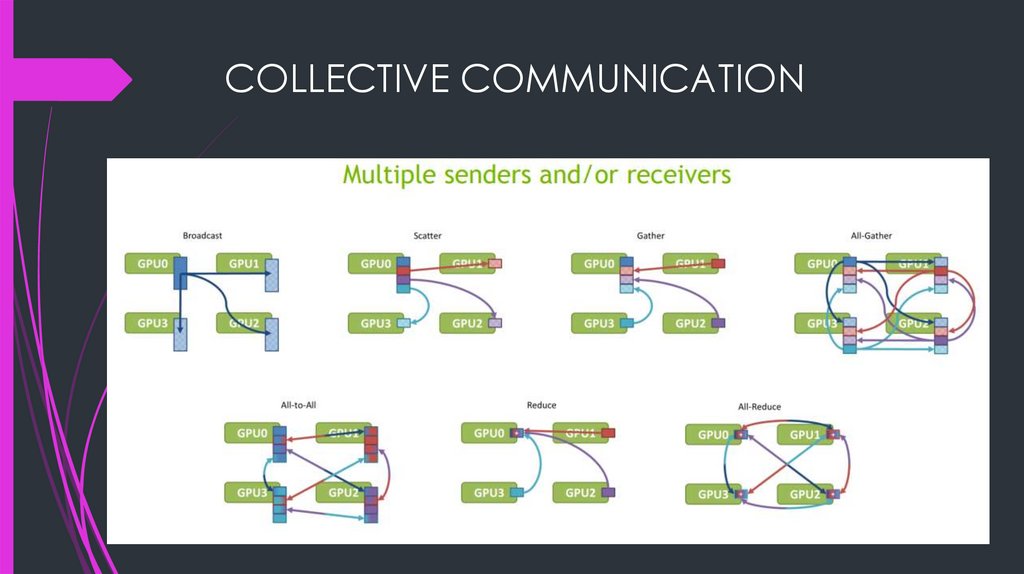
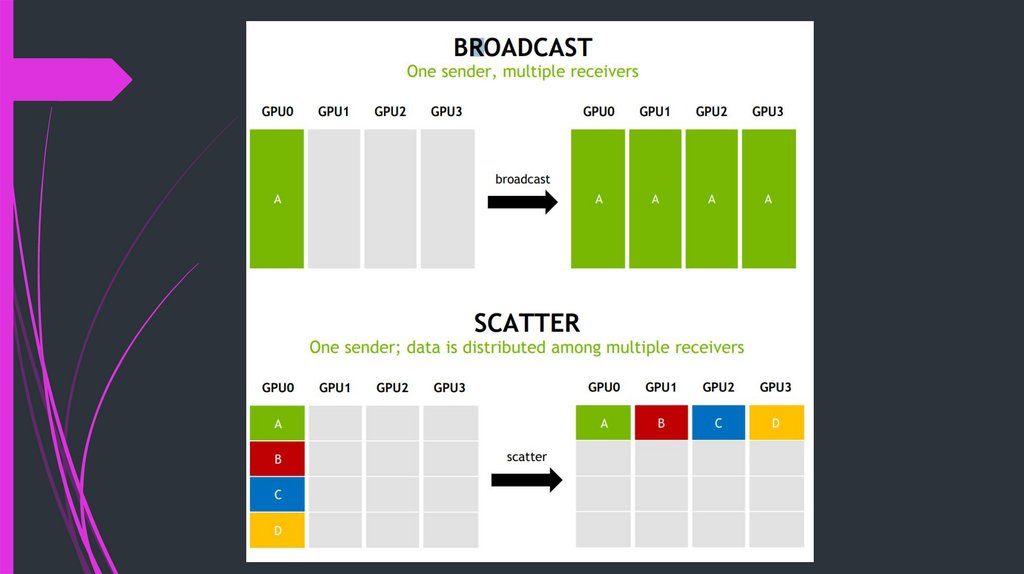
Collective communication
Multiple senders and/or receivers
Patterns include broadcast, scatter, gather, reduce, all-to-all, …
Difficult to implement efficiently
25.
POINT-TO-POINT COMMUNICATION26.
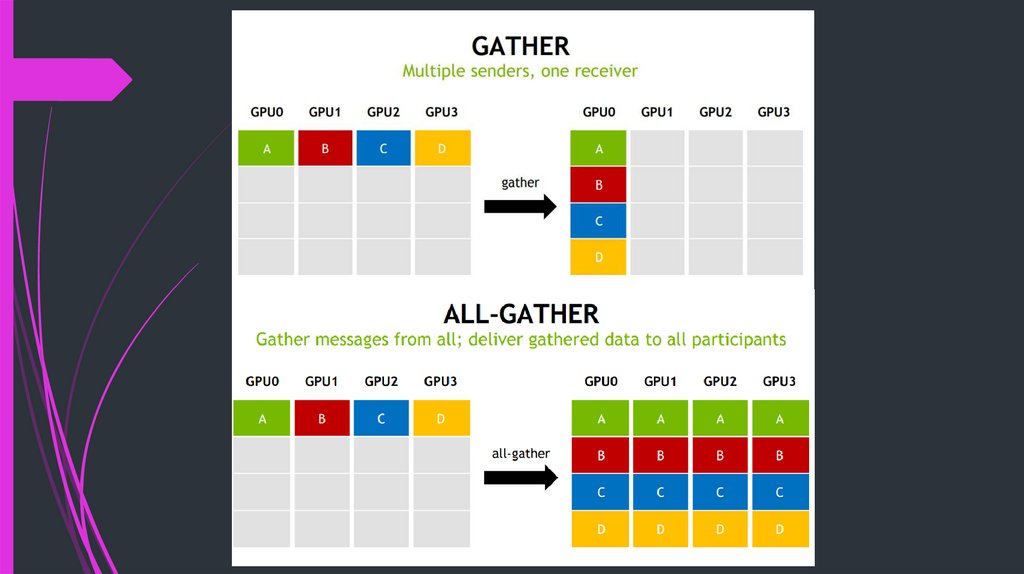
COLLECTIVE COMMUNICATION27.
28.
29.
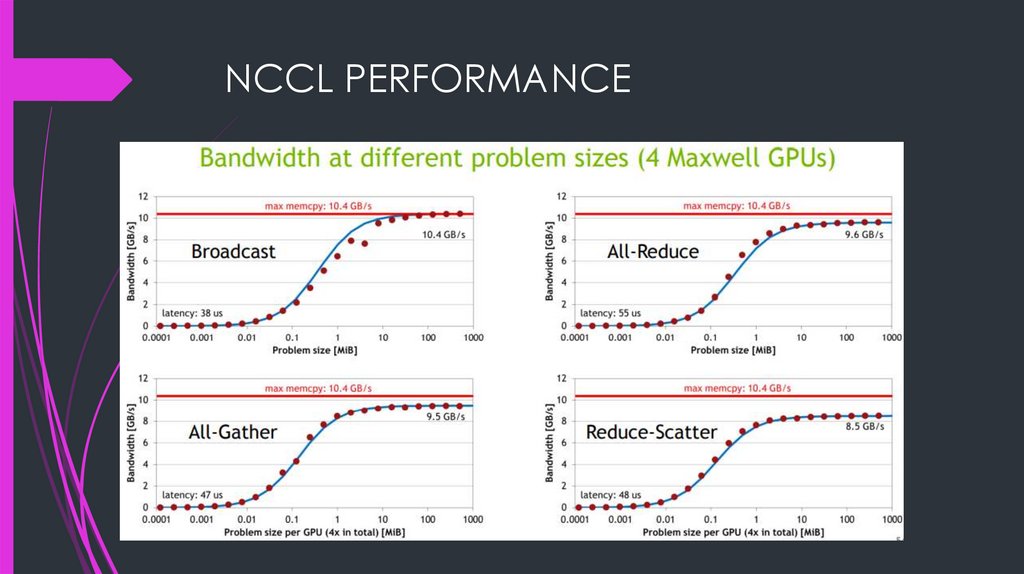
INTRODUCING NCCLGOAL:
Build a research library of accelerated collectives that is easily
integrated and topology-aware so as to improve the scalability
of multi-GPU applications
APPROACH:
Pattern the library after MPI’s collectives
Handle the intra-node communication in an optimal way
Provide the necessary functionality for MPI to build on top to
handle inter-node
30.
NCCL FEATURESCollectives
Broadcast
All-Gather
Reduce
All-Reduce
Reduce-Scatter
Scatter
Gather
All-To-All
Neighborhood
Key Features
Single-node, up to 8 GPUs
Host-side API
Asynchronous/non-blocking
interface
Multi-thread, multi-process
support
In-place and out-of-place
operation
Integration with MPI
Topology Detection
NVLink & PCIe/QPI* support
31.
NCCL IMPLEMENTATIONImplemented as monolithic CUDA C++ kernels
combining the following:
GPUDirect P2P Direct Access
Three primitive operations: Copy, Reduce, ReduceAndCopy
Intra-kernel synchronization between GPUs
One CUDA thread block per ring-direction