


 поиска")









 поиска")






")








")














 programming
programmingSimilar presentations:





")



. Лекция 6 по основам программирования")
Поиск. Лекция 2
1. Поиск
Лекция 22. Задача поиска
• Поиском называется процедуравыделение из множества записей
некоторого его подмножества, записи
которого удовлетворяют заданному
условию.
3. Задача поиска
• В алгоритмах поиска обычно задан аргументпоиска Key, и задача состоит в нахождении
записи, имеющей Key своим ключом.
Существует две возможности окончания поиска:
либо поиск оказался удачным, т.е. была
найдена запись с ключом Key, либо он оказался
неудачным, т.е. ключ Key не был найден ни в
одной из записей. Если все сравниваемые
ключи уникальны, то речь идет о поиске только
одной записи (или одного элемента) массива.
4. Алгоритмы последовательного (линейного) поиска
• Алгоритм последовательного поискав неупорядоченном массиве
• Алгоритм оптимального,
последовательного поиска в
неупорядоченном массиве
• Алгоритм оптимального,
последовательного поиска в
упорядоченном массиве
5. Алгоритм последовательного поиска
• Пусть имеется массив K={ki}, состоящийиз N элементов (i=0,N-1) (ключей,
записей). Все ключи уникальны. Данные
расположены в произвольном порядке.
Очевидный подход – простой
последовательный просмотр массива
6. Алгоритм последовательного поиска в неупорядоченном массиве
• Начало алгоритма.• i=0.
• Пока i<N и К[i] != Key выполнять i=i+1.
• Если i<N, то ключ найден по адресу i,
иначе – совпадение не обнаружено.
• Конец алгоритма.
7. Алгоритм последовательного поиска в неупорядоченном массиве
• Максимальное число сравнений приудачном и неудачном поиске равно N.
Среднее число сравнений при удачном
поиске равно (N+1)/2.
• Сложность рассмотренного алгоритма:
O(n)
8.
• В алгоритме последовательного поиска(внутри цикла – на шаге 3) имеются две
проверки: на выход значения индекса за
пределы массива и на совпадение
ключей.
• Если гарантировать, что ключ всегда
будет найден, то без первого условия
можно обойтись. Для этого достаточно в
конце массива поместить
дополнительный элемент - «барьер»,
присвоив ему значение искомого
ключа Key.
9. Алгоритм оптимального, последовательного поиска в неупорядоченном массиве
• Начало алгоритма.• i=0
• K[N]=Key.
• Пока К[i]!=Key выполнять i=i+1
• Если i<N, то Key найден по адресу i,
иначе – поиск неудачен.
• Конец алгоритма.
10.
• Таким образом, ключ всегда будетнайден в записи с индексом i. При i==N
(индекс достиг барьера) поиск
неудачен. В противном случае (при i<N)
– поиск удачен.
• Такой подход позволяет исключать в
среднем (N+1)/2 сравнений.
11. Алгоритм оптимального, последовательного поиска в упорядоченном массиве
• Начало алгоритма.• i=0
• K[N]=Key+1.
• Пока К[i]<Key выполнять i=i+1
• Если i<N и K[i]==Key, то элемент найден
по адресу i, иначе – совпадение не
обнаружено.
• Конец алгоритма.
12.
• В отличие от поиска в неупорядоченноммассиве просмотр элементов
упорядоченного массива заканчивается
в тот момент, когда первый раз
перестает выполняться
условие Ki < Key.
• Если K==K[i] – поиск удачен. В
противном случае, искомого элемента
нет в массиве.
13.
• В случае удачного результата алгоритмпоиска в упорядоченном массиве не
лучше алгоритма поиска в
неупорядоченном массиве. Однако
отсутствие нужного ключа этот
алгоритм позволяет обнаружить в два
раза быстрее.
• Таким образом, среднее число
сравнений и при удачном, и при
неудачном поиске равно (N+1)/2.
14. Алгоритмы последовательного (линейного) поиска
временная сложностьO(n)
• Алгоритм последовательного поиска
в неупорядоченном массиве
• Алгоритм оптимального,
последовательного поиска в
неупорядоченном массиве
• Алгоритм оптимального,
последовательного поиска в
упорядоченном массиве
15. Алгоритмы двоичного поиска
• Алгоритм двоичного (или бинарного)поиска в упорядоченном массиве
• Алгоритм оптимального бинарного
поиска в упорядоченном массиве
16. Алгоритм бинарного поиска
• 1. Начало алгоритма.2. L=0. Левая граница массива.
3. R=N-1. Правая граница массива.
4. Пока L<=R выполнять 4-7.
5. i=(L+R)/2.
6. Если K[i]==Key, то ключ найден
(завершить поиск, перейти к 9)
7. Если K[i]<Key, то L=i+1, иначе R=i-1.
8. Совпадение не обнаружено.
9. Конец алгоритма.
17. Алгоритм оптимального бинарного поиска
• 1. Начало алгоритма.2. L=0. Левая граница массива.
3. R=N-1. Правая граница массива.
4. Пока L<R выполнять 4-6.
5. i=(L+R)/2.
6. Если K[i]<Key, то L=i+1, иначе R=i.
7. Если K[R]==Key, то элемент найден по
адресу R, иначе - совпадение не
обнаружено.
8. Конец алгоритма.
18. Алгоритмы двоичного поиска
временная сложностьO( log2n )
• Алгоритм двоичного (или бинарного)
поиска в упорядоченном массиве
• Алгоритм оптимального бинарного
поиска в упорядоченном массиве
19. Алгоритмы поиска в тексте
• Работа в текстовом редакторе, поисковыезапросы в базе данных, задачи в
биоинформатике, лексический анализ
программ требуют эффективных
алгоритмов работы с текстом. Задачи
поиска слова в тексте используются в
криптографии, различных разделах
физики, сжатии данных, распознавании
речи и других сферах человеческой
деятельности.
20.
• Алфавит – конечное множество символов.• Строка (слово) – это последовательность
символов из некоторого алфавита. Длина
строки – количество символов в строке.
• Строку будем обозначать символами
алфавита, например X=x[1]x[2]...x[n] – строка
длиной n, где x[i] – i -ый символ строки Х,
принадлежащий алфавиту. Строка, не
содержащая ни одного символа, называется
пустой.
21. Поиск строки в таблице (массиве строк)
• При поиске в таблице ключом поиска можетявляться строка символов. Для того чтобы
найти заданную строку X необходимо
последовательно сравнить её с
соответствующими строками (полями) Y всех
структур, имеющихся в таблице.
• Таким образом, сравнение строк X и Y
сводится к поиску их несовпадающих частей.
Если неравных частей нет, то строки равны.
22.
• Отношение порядка на множестве строкможет быть определено следующим образом.
Пусть даны две строки X и Y длины m.
23. Алгоритм сравнения строк
• Пусть заданы две строки X и Y длины m.Необходимо определить, равны ли эти строки
между собой.
• Начало
• i=0
• Пока (i<=m) и (Xi==Yi) выполнять i=i+1
• Выход
• После выхода из цикла, если Xi>Yi, то X>Y,
если Xi<Yi, то X<Y в противном случае X==Y
24.
Для большинства практическихприложений желательно исходить из
того, что строки имеют переменный
размер.
• Размер неявно указывается путем
добавления концевого символа, больше
этот символ нигде не употребляется '\0'
• Размер явно хранится в качестве
первого элемента массива
25. Прямой поиск подстроки в строке
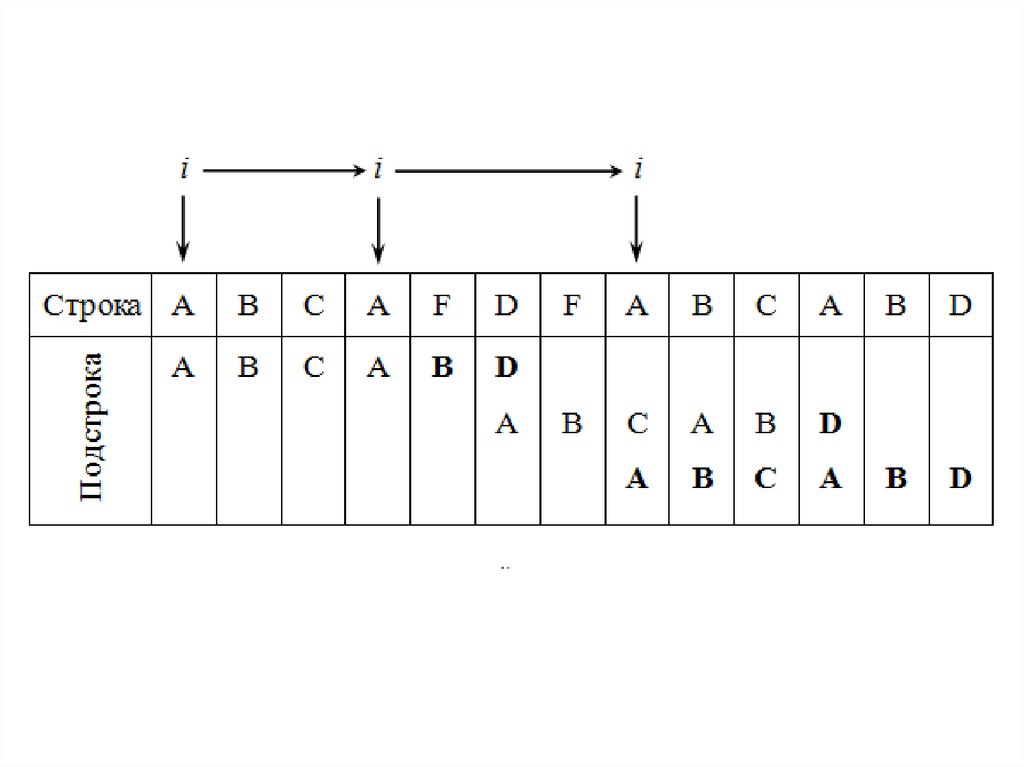
• Основная идея алгоритма прямым поискомзаключается в посимвольном сравнении строки с
подстрокой. В начальный момент происходит
сравнение первого символа строки с первым
символом подстроки, второго символа строки со
вторым символом подстроки и т. д. Если произошло
совпадение всех символов, то фиксируется факт
нахождения подстроки. В противном случае
производится сдвиг подстроки на одну позицию
вправо и повторяется посимвольное сравнение, то
есть сравнивается второй символ строки с первым
символом подстроки, третий символ строки со
вторым символом подстроки и т. д.
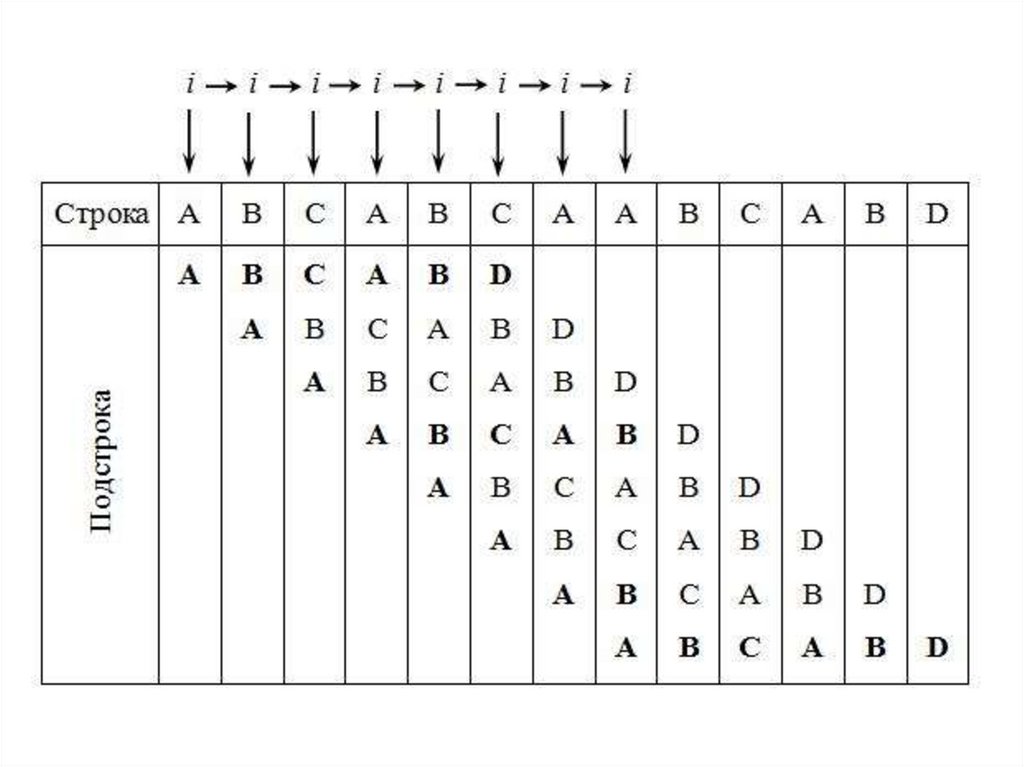
26. Прямой поиск подстроки в строке
• Пусть задан массив (строка) S из Nсимволов и массив Р из М символов,
причем 0 <= М < N.
Char s[N-1], P[M-1];
Поиск строки обнаруживает первое
вхождение Р в S. Поставленная задача
позволяет оформить поиск как
повторяющееся сравнение :
27.
• 1. Начало алгоритма.2. i=-1;
3. Повторять цикл 1 (пункты 4-6).
4. i=i+1; j=0;
5. Пока (j<M) and (S[i+j]=P[j]) выполнять j=j+1;
6. Если (j==M) OR (i==N-M), то перейти к 7,
иначе к 3.
7. Если (j==M), тогда поиск успешен, иначе –
нет.
8. Конец алгоритма.
28.
29.
• Рассматриваемые сдвиги подстрокиповторяются до тех пор, пока конец
подстроки не достиг конца строки или
не произошло полное совпадение
символов подстроки со строкой, то есть
найдется подстрока.
30. Анализ алгоритма
• Анализ алгоритма прямого поиска в строкепоказывает, что этот алгоритм работает
достаточно эффективно, если допустить, что
несовпадение пары символов происходит, по
крайней мере, после всего лишь нескольких
сравнений во внутреннем цикле. При большой
длине строки это достаточно частый случай.
• Худшим является следующий случай. Строка
S состоит из N-1 символов «А» и
единственного символа «В». Подстрока
(образ) содержит М-1 символов «А» и символ
«В».
• Чтобы обнаружить совпадение в конце строки,
требуется произвести порядка N*M сравнений.
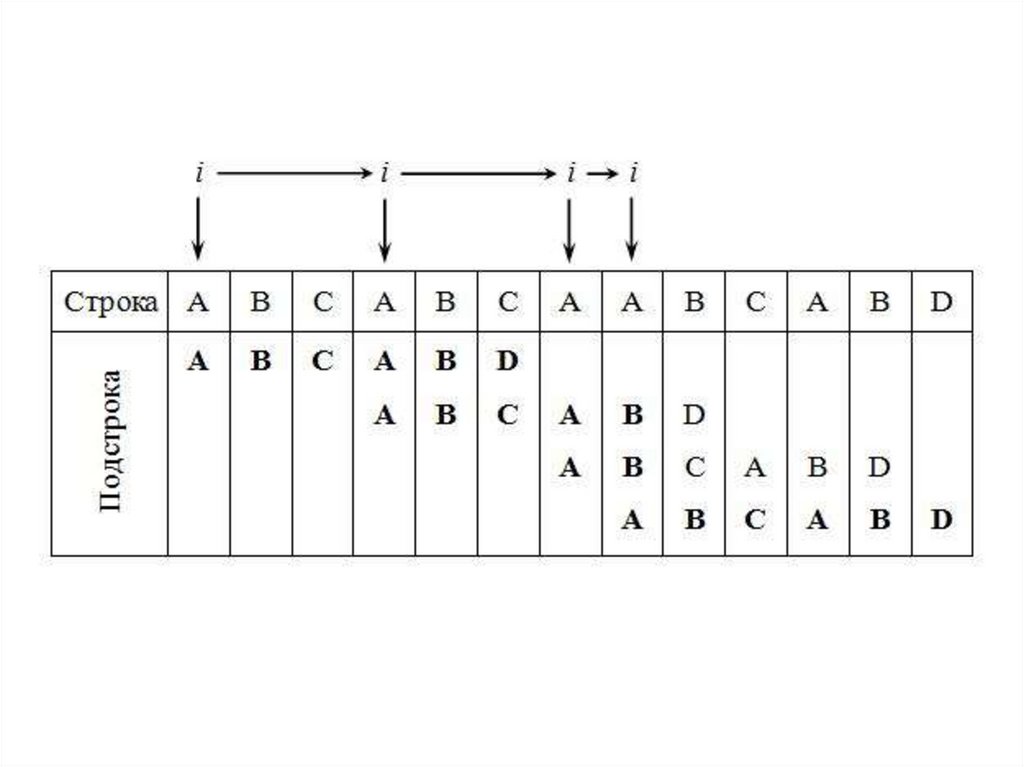
31. Алгоритм Кнута, Мориса и Пратта (КМП)
• В 1970 году Д. Кнут, Д. Морис и В. Пратт разработалиалгоритм, требующий только N сравнений.
• Основным отличием алгоритма Кнута, Морриса и
Пратта от алгоритма прямого поиска заключается в
том, что сдвиг подстроки выполняется не на один
символ на каждом шаге алгоритма, а на некоторое
переменное количество символов.
• Следовательно, перед тем как осуществлять
очередной сдвиг, необходимо определить величину
сдвига. Для повышения эффективности алгоритма
необходимо, чтобы сдвиг на каждом шаге был бы как
можно большим.
• Если совпадения вообще нет, то сравнение
начинается со следующей позиции в строке.
32.
33.
34. Анализ алгоритма КМП
• Данный алгоритм дает выигрыш в техслучаях, когда несовпадению
предшествует некоторое число
совпадений, так как в этом случае
образ сдвигается сразу на несколько
позиций. Но это бывает не так часто,
поэтому выигрыш, по сравнению с
прямым поиском, не всегда значителен.
• Сложность этого алгоритма O(t)~ M+N.
35.
• Для работы алгоритма вводитсядополнительный массив для вычисления
сдвига на очередном шаге – D.
• Этот массив может быть получен на основе
анализа образа Р и зависит только от
содержимого подстроки. До начала самого
поиска подстроки в строке можно вычислить
значения сдвигов, которые используются в
дальнейшем поиске.
• Причем в массив D помещается значение = -1,
если производится сдвиг на целый образ. Чем
меньше значение D, тем на большее число
позиций производится сдвиг по строке. Сдвиг
для ячейки j вычисляется как j-d[j].
36.
• Наибольший эффект от такого подхода будетпри M<<N. Если в образе Р нет совпадений с
его началом, то массив D не нужен.
Рассмотрим примеры формирования величин
сдвигов по образу Р.
• P: AAAAA – сдвиг возможен на 1 позицию.
• P: ABAB - сдвиг на 2.
• P: ABCABC – сдвиг на 3.
• P: ABCDEF – сдвиг на 5.
37.
• 1. Начало алгоритма.2. j=0; k=-1; d[0]=-1;
3. Цикл 1 пока j < M-1 выполнять пункты 4-7.
4. Цикл 2 пока k>=0 и p[j]!=p[k] выполнять k=d[k].
5. j=j+1; k=k+1;
6. Если p[j]==p[k], тогда d[j]=d[k], иначе d[j]=k;
7. Продолжить цикл 1.
8. i=0; j=0; k=0;
9. Цикл 3 пока j < M и i<N выполнять пункты 10-13.
10. Цикл 4 пока k<=i вывести s[k] и k=k+1;
11. Цикл 5 пока j>=0 и s[i]!=p[j] выполнять j=d[j].
12. i=i+1; j=j+1;
13. Продолжить цикл 3.
14. Если j==M, тогда подстрока найдена, начиная с
позиции i-M, иначе подстроки нет.
15. Конец алгоритма.
38.
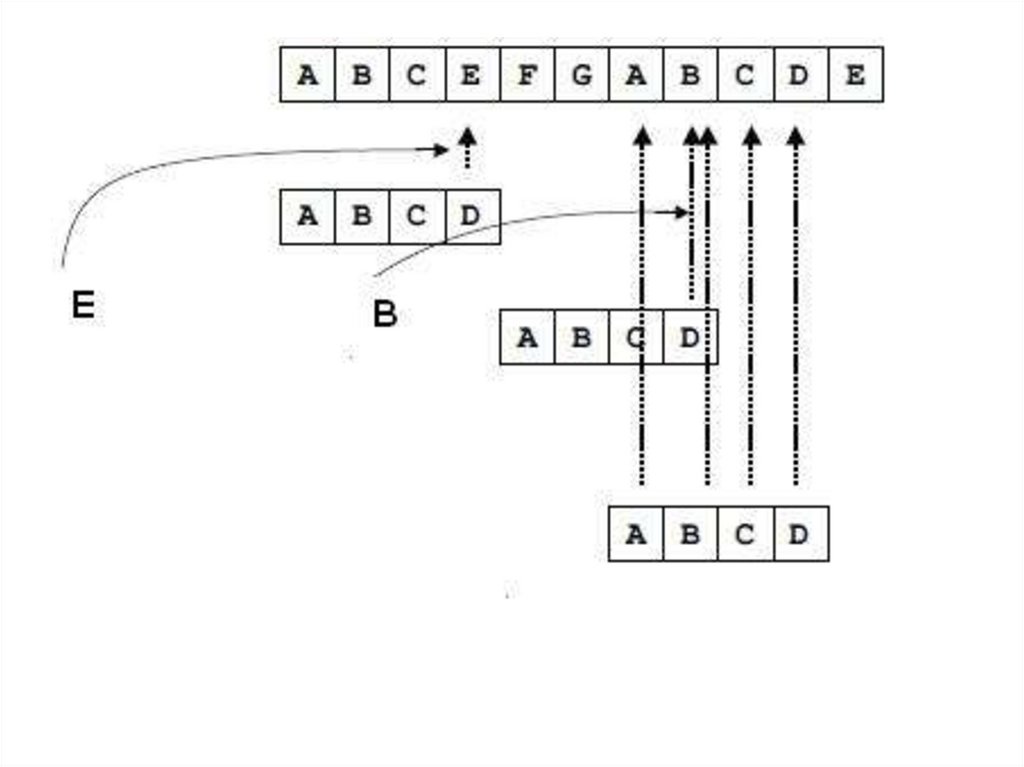
39. Алгоритм Бойера и Мура
• Алгоритм Бойера и Мура считается наиболеебыстрым среди алгоритмов, предназначенных для
поиска подстроки в строке.
• Разработан Р. Бойером и Д. Муром в 1977 году.
• Преимущество этого алгоритма в том, что
необходимо сделать некоторые предварительные
вычисления над подстрокой, чтобы сравнение
подстроки с исходной строкой осуществлять не во
всех позициях – часть проверок пропускаются как
заведомо не дающие результата.
40.
41.
• Первоначально строится таблица смещений дляискомой подстроки.
• Далее идет совмещение начала строки и подстроки и
начинается проверка с последнего символа
подстроки. Если последний символ подстроки и
соответствующий ему при наложении символ строки
не совпадают, подстрока сдвигается относительно
строки на величину, полученную из таблицы
смещений, и снова проводится сравнение, начиная с
последнего символа подстроки.
• Если же символы совпадают, производится
сравнение предпоследнего символа подстроки и т.д.
42.
• Если все символы подстроки совпали сналоженными символами строки, значит, найдена
подстрока и поиск окончен.
• Если же какой-то (не последний) символ подстроки
не совпадает с соответствующим символом строки,
далее производим сдвиг подстроки на один символ
вправо и снова начинаем проверку с последнего
символа.
• Весь алгоритм выполняется до тех пор, пока либо не
будет найдено вхождение искомой подстроки, либо
не будет достигнут конец строки.
43.
44.
• Величина сдвига в случае несовпадения последнегосимвола вычисляется, исходя из следующего:
• Cдвиг подстроки должен быть минимальным, таким,
чтобы не пропустить вхождение подстроки в строке.
• Если данный символ строки встречается в
подстроке, то смещаем подстроку таким образом,
чтобы символ строки совпал с самым правым
вхождением этого символа в подстроке.
• Если же подстрока вообще не содержит этого
символа, то сдвигаем подстроку на величину, равную
ее длине, так что первый символ подстроки
накладывается на следующий за проверявшимся
символом строки.
45. Упрощенный алгоритм БМ
• 1. Начало алгоритма.2. i = 0.
• 3. Цикл 1 пока (i<256) выполнять d [i] =M, i = i+1.
• 4. j = 0.
• 5. Цикл 2 пока j < M – 2
выполнять d [p[j] ]= M – j – 1,
j = j+ 1.
• 6. i = M – 1 j = M - 1
• 7. Цикл 3 пока i < N & j >= 0 выполнять 8,10 .
8. k = i
• 9. Цикл 4 пока j >= 0 & p [j ] = s[ k ]
выполнять j = j – 1, k = k – 1
10. i = i + d [s[ i ] ], j = M - 1
• 11. Продолжить цикл 3.
• 12. Если j<0, тогда подстрока найдена, начиная с
позиции i-M+1, иначе подстроки нет.
13. Конец алгоритма.
46.
• Величина смещения для каждогосимвола подстроки зависит только от
порядка символов в подстроке, поэтому
смещения удобно вычислить заранее и
хранить в виде одномерного массива,
где каждому символу
алфавита соответствует смещение
относительно последнего символа
подстроки.
47. Анализ алгоритма БМ
• Алгоритм Бойера и Мура на хороших данных оченьбыстр, а вероятность появления плохих данных
крайне мала. Поэтому он оптимален в большинстве
случаев, когда нет возможности провести
предварительную обработку текста, в котором
проводится поиск.
• Таким образом, данный алгоритм является наиболее
эффективным в обычных ситуациях, а его
быстродействие повышается при увеличении
подстроки или алфавита. В наихудшем случае
трудоемкость рассматриваемого алгоритма O(m+n).
48.
• Существуют попытки совместить присущуюалгоритму Кнута, Морриса и Пратта эффективность в
"плохих" случаях и скорость алгоритма Бойера и
Мура в "хороших" – например, турбо-алгоритм,
обратный алгоритм Колусси и другие.
• Каждый алгоритм поиска позволяет эффективно
действовать лишь для своего класса задач, об этом
еще говорят различные узконаправленные
улучшения. Алгоритм поиска подстроки в строке
следует выбирать только после точной постановки
задачи, которые должна выполнять программа.