









 informatics
informaticsSimilar presentations:










Информационная безопасность
1. Тема проекта
Бакшаева Ксения Б21-525Штанденко Илья Б21-565
Руководитель:
Нурматов Салим Рашидович
2. АКТУАЛЬНОСТЬ
Информационная безопасность - одно из самых динамично развивающихсянаправлений ИТ. Это обусловлено большой ролью человеческого фактора - он
вносит большое разнообразие и спонтанность в реализацию атак. В связи с этим мы
имеем дело с большим количеством хаотичных данных, которое не позволяет
выделять и различать разные угрозы - а следовательно, и бороться с ними. И тут на
помощь приходит машинное обучение.
3. ЦЕЛЬ ПРОЕКТА
Провести исследование на основесуществующих вариантов програмного
решения, которые будут иметь достаточный
диапазон и степень достоверности данных об
опасности тех или иных аномалий трафика.
4. Классификаторы машинного обучения
Метод k-ближайших соседей (K-Nearest Neighbors);
Метод опорных векторов (Support Vector Machines);
Классификатор дерева решений (Decision Tree
Classifier) / Случайный лес (Random Forests);
Изоляционный лес (Isolation forest)
Наивный байесовский метод (Naive Bayes);
Линейный дискриминантный анализ (Linear Discriminant
Analysis);
Логистическая регрессия (Logistic Regression);
5. С чем мы работаем
Для наших операций используем языкпрограммирования Python со
специализированными библиотеками.
Генерируем датасет с фиксированными
параметрами
Вводим классификацию аномалий:
нормальное распределение имеет один
пик, аномальное два.
6. Выбор алгоритма
Анализируя f1-score, выявляем, чтоOneClassSVM, Isolation forest и Random
Forest сами по себе не справляются с
поставленной задачей
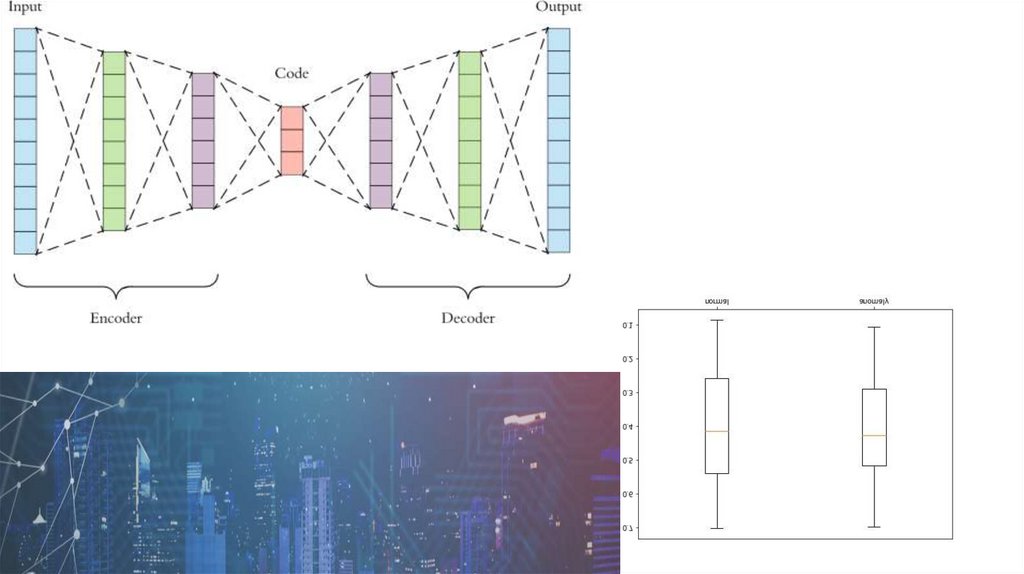
Таким образом, мы решили использовать
автокодировщик. Принцип его действия
представлен на рисунке ниже.
7.
8. Устранение недостатков модели
Обучая модель, мы сталкиваемся с неразличимостьювосстановленных после сжатия данных для аномального и
нормального распределений. Заметив, что аномальное
распределение до сжатия характеризуется пиком, мы вводим
функцию разницы, которая значительно улучшает детекцию.
В итоге в работе была использована связка автоенкодер +
функция разницы + случайный лес. Отметим важность порядка –
при перестановке последних двух шагов случайный лес
“загрязнит” данные, и работа модели будет некорректной.
9.
Представление результатов исследованияНаблюдающийся пик в score’-ах натолкнул нас на использование
гистограмм (см.рис). Чётко выделяется дополнительная “ступенька” в
аномальном распределении. Заключаем, что наша модель пригодна для
детекции аномалий.
10. Итоги
Детекция аномалий требует тщательного подбора инструментов машинногообучения для каждой конкретной задачи, а иногда и комбинированного подхода,
как в нашем случае. Также немаловажным оказалась вторичная обработка
датасета с помощью вспомогательной функции, позволившей многократно
повысить точность индикации отличия рассматриваемых выборок.
Также не стоит забывать о формате визуального представления результатов (в
нашем случае хорошо подошла гистограмма). Именно оно в конечном счёте
показывает успешность модели.
Таким образом, хорошее решение должно содержать проработку всех этапов
работы с данными, а также опираться на их качественную интеграцию друг с
другом.
11. Спасибо за внимание!
Бакшаева Ксения Б21-525Штанденко Илья Б21-565
Руководитель:
Нурматов Салим Рашидович