













 pedagogy
pedagogySimilar presentations:




 на уроках химии и во внеурочной деятельности")




Мы верим в дружбу и помним добро!
1.
Мы верим в дружбуи помним добро!
2.
К моменту начала работы над вторым циклом в нашейкоманде уже было десять человек:
1. Егоров Евгений
2. Лисковец Ярослав
3. Лосев Святослав
4. Марченко Арина
5. Мичурин Андрей
6. Мотовников Константин
7. Полтавцев Константин
8. Родыгин Андрей
9. Семенов Егор
10.Трубников Фёдор
3.
Руководитель студии и администратор сообщества социальной сети «ВК»:• Мичурин Андрей
Связь с общественностью, проведение опросов, работа с тестовыми
группами в рамках опросов:
• Лисковец Ярослав
• Лосев Святослав
• Полтавцев Константин
Проведение обработки данных, ведение расчетов, составление диаграмм,
автоматизация расчетов посредством программирования:
• Егоров Евгений
• Родыгин Андрей
Ведение сопроводительной документации и отчетности:
• Семенов Егор
• Марченко Арина
Медийное сопровождение (фото/видео) работы студии:
• Трубников Фёдор
• Мотовников Константин
4.
Тему мы выбирали посредством голосования. Наша команда дружнособралась и путём голосования решила, что нам больше остальных
подходит тема:
«Выделение ключевых слов в вербальных и
невербальных паттернах».
Нам захотелось подтвердить результаты данного исследования, и при
выборе темы у нас уже возникли некоторые идеи по его реализации
5.
В первую же встречу после выбора темы былиназначены ребята, вызвавшиеся для поиска текстов.
Тексты было решено выбрать из разных тематических
областей, несложные для понимания учениками
разных возрастов.
Мы нашли 3 темы хорошо подходящие под
уроки биологии, истории и географии:
1. «IT-технологии в медицине»;
2. «Извержение вулкана: как это происходит»;
3. «Греческая мифология. 12 подвигов Геракла».
6.
7.
8.
9.
Тестируемые ученики получили на руки лист содержащий информацию подвум темам. На первой странице располагался текст по одной из тем, на
второй – инфографика по другой теме.
Название тем были условно зашифрованы от тестируемых, чтобы
исключить навязывание ключевых слов, которые им требовалось для себя
определить.
После ознакомления с предоставленной информацией тестируемым нужно
было перейти на Google-форму по QR-коду или по ссылке на первой
странице раздаточных материалов.
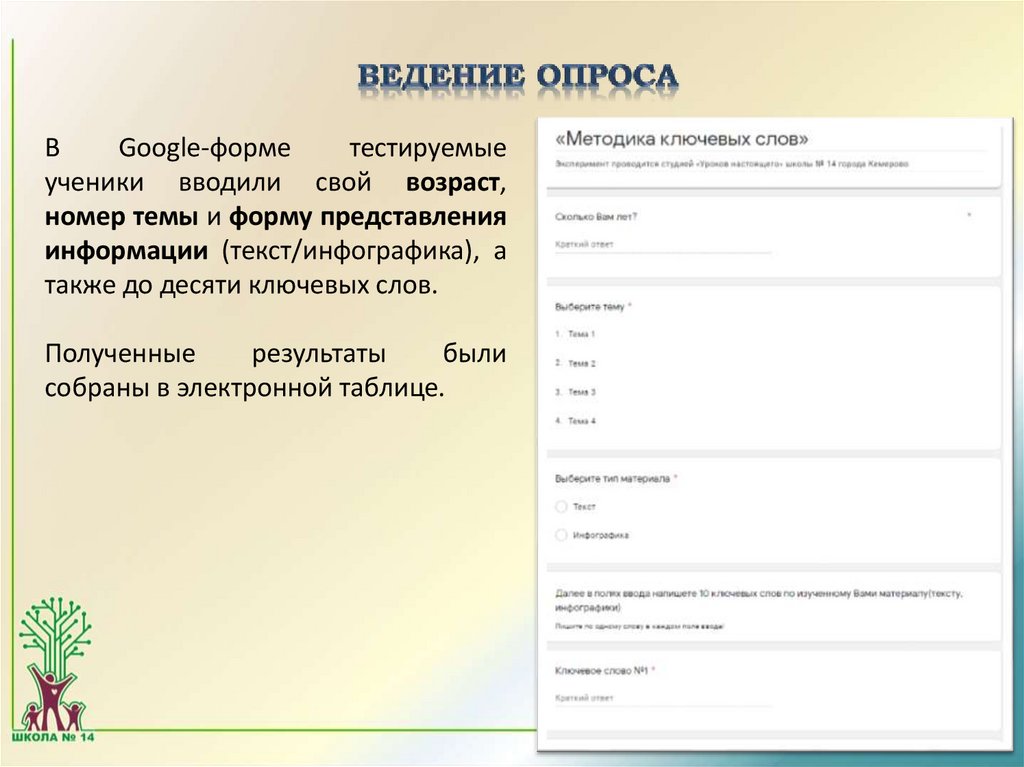
10.
ВGoogle-форме
тестируемые
ученики вводили свой возраст,
номер темы и форму представления
информации (текст/инфографика), а
также до десяти ключевых слов.
Полученные
результаты
были
собраны в электронной таблице.
11.
Все полученные сведения из-за их большого количества были распределены нашейкомандой среди 6 человек, которые занялись подсчетом ключевых слов, а также
подсчётом частоты их встречи (индексации) в ответах учеников. Подсчеты
производились посредством таблицы EXCEL (примерный вид ниже):
12.
По полученным результатам нашей командой было выбраны подесять слов из каждой темы, которые встречались наиболее
часто в тексте и инфографике вместе взятые. По данным словам
были построены диаграммы, по которым было бы удобно
сравнить полученные по выбранным словам значения их
индексации.
Помимо этого нами было подсчитано общее количество
различных слов, названных тестируемыми и по тексту, и по
инфографике.
13.
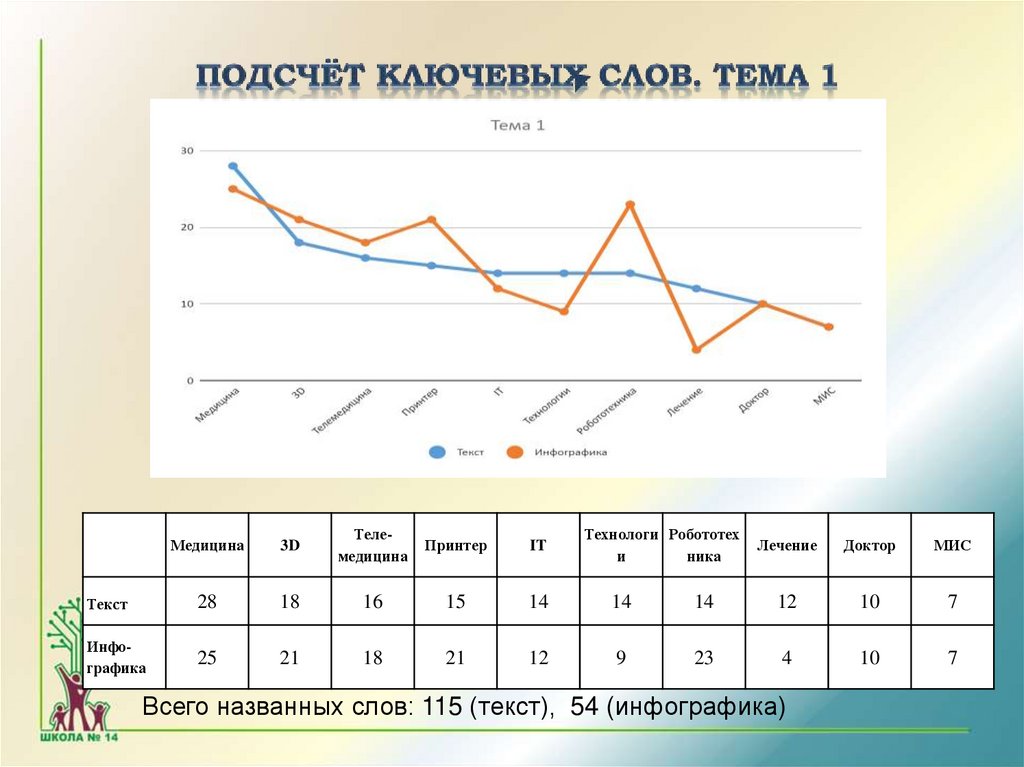
Медицина3D
Телемедицина
Принтер
IT
Технологи Робототех
и
ника
Текст
28
18
16
15
14
14
Инфографика
25
21
18
21
12
9
Лечение
Доктор
МИС
14
12
10
7
23
4
10
7
Всего названных слов: 115 (текст), 54 (инфографика)
14.
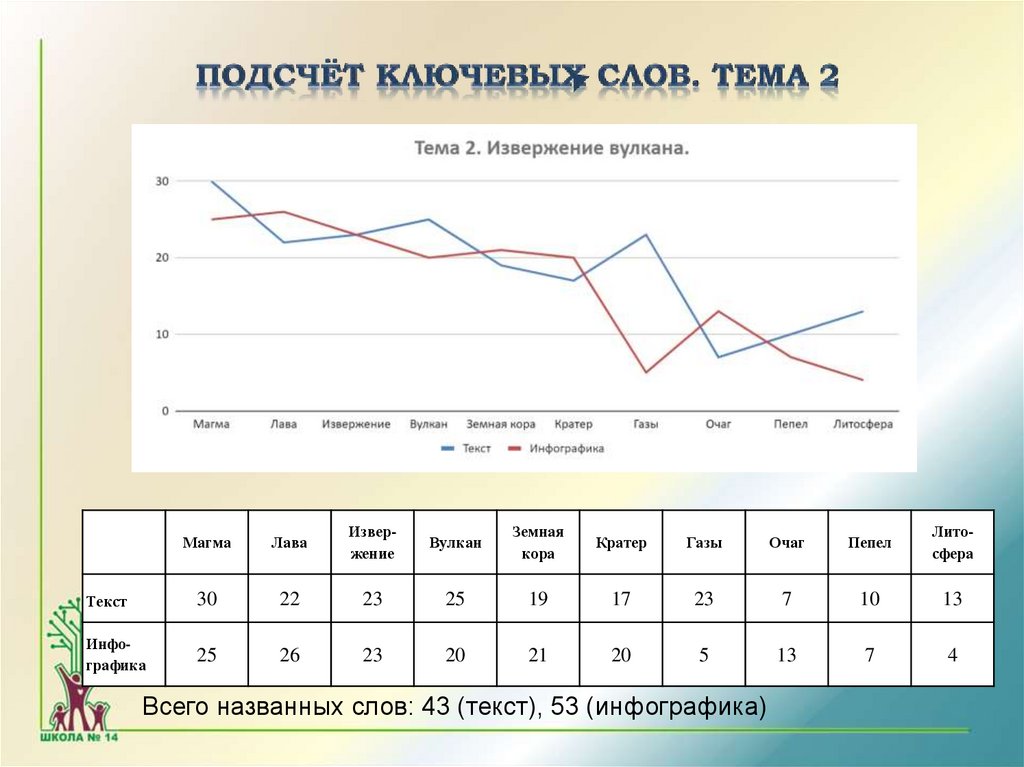
МагмаЛава
Извержение
Вулкан
Земная
кора
Кратер
Газы
Очаг
Пепел
Литосфера
Текст
30
22
23
25
19
17
23
7
10
13
Инфографика
25
26
23
20
21
20
5
13
7
4
Всего названных слов: 43 (текст), 53 (инфографика)
15.
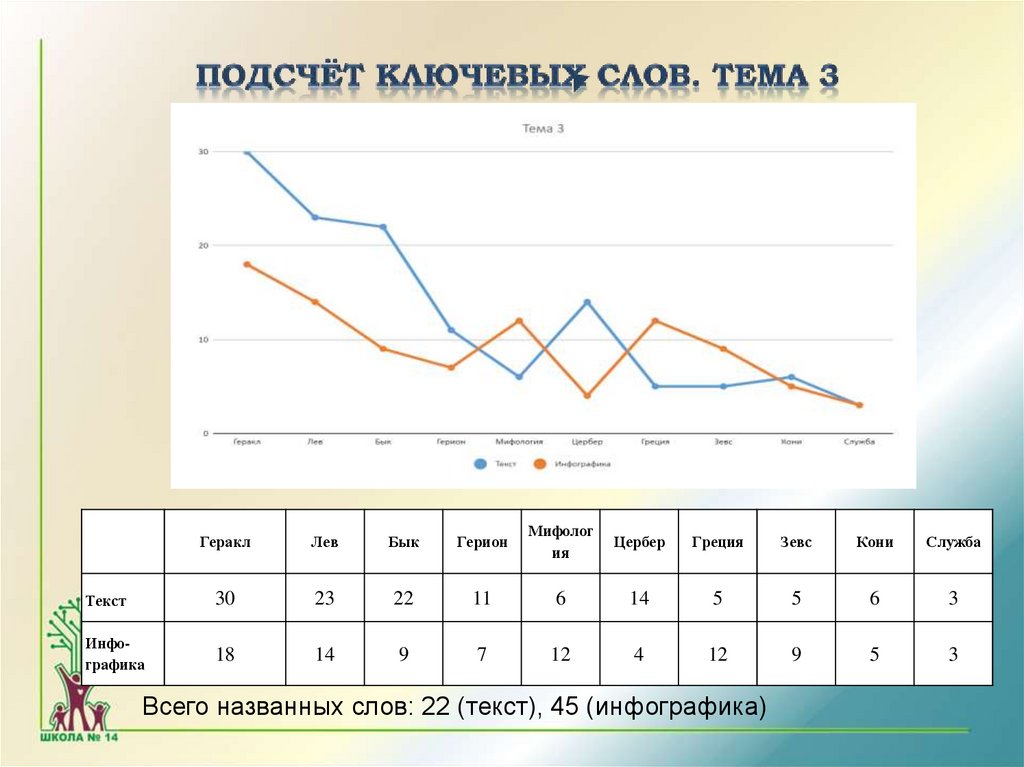
ГераклЛев
Бык
Герион
Мифолог
ия
Цербер
Греция
Зевс
Кони
Служба
Текст
30
23
22
11
6
14
5
5
6
3
Инфографика
18
14
9
7
12
4
12
9
5
3
Всего названных слов: 22 (текст), 45 (инфографика)
16.
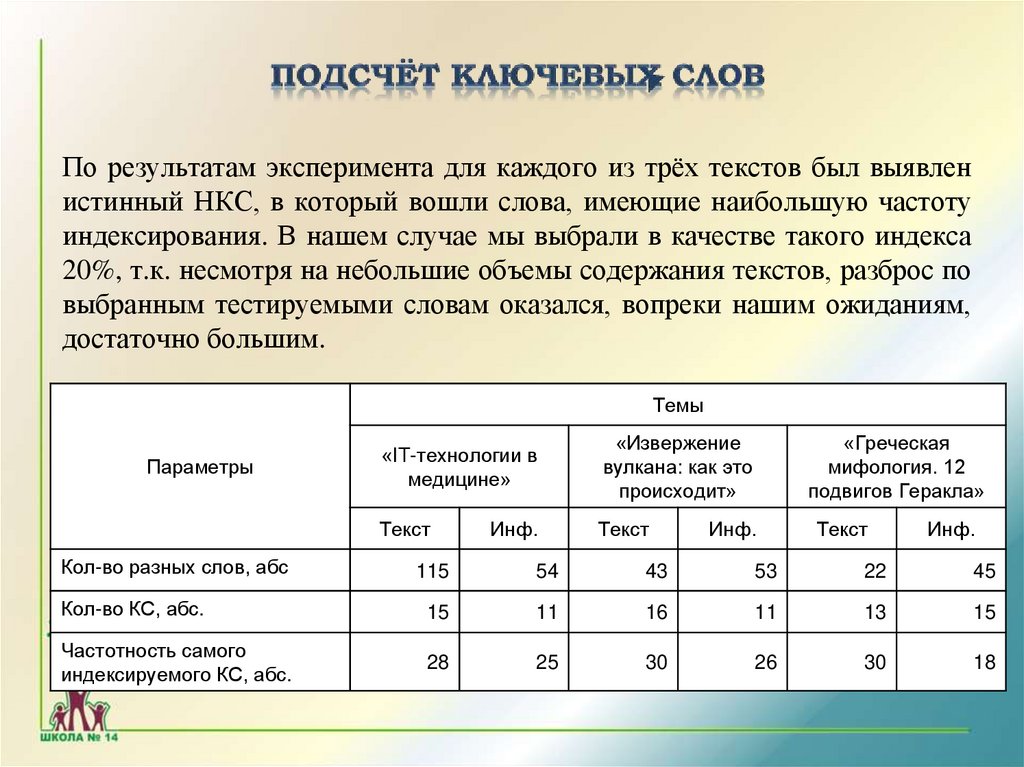
По результатам эксперимента для каждого из трёх текстов был выявленистинный НКС, в который вошли слова, имеющие наибольшую частоту
индексирования. В нашем случае мы выбрали в качестве такого индекса
20%, т.к. несмотря на небольшие объемы содержания текстов, разброс по
выбранным тестируемыми словам оказался, вопреки нашим ожиданиям,
достаточно большим.
Темы
Параметры
Кол-во разных слов, абс
«IT-технологии в
медицине»
«Извержение
вулкана: как это
происходит»
Текст
Текст
Инф.
«Греческая
мифология. 12
подвигов Геракла»
Инф.
Текст
Инф.
115
54
43
53
22
45
Кол-во КС, абс.
15
11
16
11
13
15
Частотность самого
индексируемого КС, абс.
28
25
30
26
30
18
17.
• На основании проведенного исследования мы установили, чтоинформация лучше воспринимается в вербальном (текстовом)
виде, т.е. по тексту учащимся легче выделить ключевые слова,
судя по меньшему количеству подобранных ими слов. Тема 1
«IT-технологии в медицине» противоречит данному выводу, но
мы связываем эту особенность с очень большим количеством
информации, заключенной в сравнительно небольшом фрагменте
текста.
• Индексация ключевых слов весьма схожа как в текстах, так и в
инфографике, что подтверждают диаграммы, построенные по
полученным подсчётам ответов тестируемых учеников. Это
говорит о том, что для человека не является решающим
фактором форма представления информации: текст или
инфографика.
18.
Трудности, с которыми мы столкнулись:1. Не удалось реализовать опрос учащихся в запланированном
объёме: было запланировано провести опрос среди примерно
400 учащихся (16 классов), было опрошено 243 человека,
выбрано ответов для проведения исследования - 224.
2. Не все тестируемые добросовестно отнеслись к заполнению
форм:
• забывали написать ключевые слова по одной из тем на руках;
• использовали термины, явно не относящиеся к полученным
ими темам;
• имело место быть некорректное заполнение форм из-за
невнимательности тестируемого
3. Из-за малого временного ресурса, не удалось провести
дополнительные исследования по определению зависимости
ответов учеников от их возраста.
19.
СПАСИБОЗА ВНИМАНИЕ!