




















 electronics
electronicsSimilar presentations:
")









Архитектуры мультикомпьютеров и мультипроцессоров
1.
2.
1. Классификация систем параллельнойобработки данных
Вычислительной системой (ВС) называется совокупность вычислительных
средств, включающих не менее двух ЭВМ или процессоров с автоматическим
обменом информацией между ними и предназначенных для автоматической
обработки информации в соответствии с заданным алгоритмом.
Вычислительные
возможности
любой
ВС
достигают
наивысшей
производительности
благодаря
двум
факторам:
использованию
высокоскоростных элементов и параллельному выполнению большого числа
операций. Существует несколько вариантов классификации систем параллельной
обработки данных.
Самой ранней и наиболее известной является классификация архитектур ВС,
предложенная в 1966 году М. Флинном. Она базируется на понятии потока, под
которым понимается последовательность элементов (команд или данных),
обрабатываемая процессором. На основе числа потоков команд и потоков данных
выделяются четыре класса архитектур.
1
3.
Классификация на понятии потоковSISD (Single Instruction/Single Data) - одиночный поток команд и одиночный поток данных
(ОКОД). К этому классу относятся классические ЭВМ фон-Неймановского типа. В них только
один поток команд, которые обрабатываются последовательно друг за другом, и каждая из
них инициирует одну операцию с одним потоком данных. Не имеет значения, если для
увеличения скорости обработки команд и выполнения арифметических операций процессор
будет использовать конвейерную обработку. Машины данного класса фактически не
относятся к параллельным системам.
SIMD (Single Instruction/Multiple Data) - одиночный поток команд и множественный поток
данных (ОКМД). МПВК типа SIMD состоят из большого числа идентичных процессоров,
имеющих собственную память и выполняющих одну и ту же программу. Это позволяет
выполнять одну арифметическую операцию сразу над многими данными - элементами
вектора. К этому классу относятся векторные и матричные МПВК
MISD (Multiple Instruction/Single Data) - множественный поток команд и одиночный поток
данных (МКОД). Определение подразумевает наличие в архитектуре многих процессоров,
обрабатывающих один и тот же поток данных. Ряд исследователей к данному классу
относят конвейерные машины.
MIMD (Multiple Instruction/Multiple Data) - множественный поток команд и множественный
поток данных (МКМД). Этот класс предполагает, что в системе есть несколько устройств
обработки команд, объединенных в единый комплекс и работающих каждое со своим
потоком команд и данных, и кроме того эпизодически обращающихся к разделяемым
данным. В такой системе каждый процессор выполняет свою программу достаточно
независимо от других процессоров
2
4.
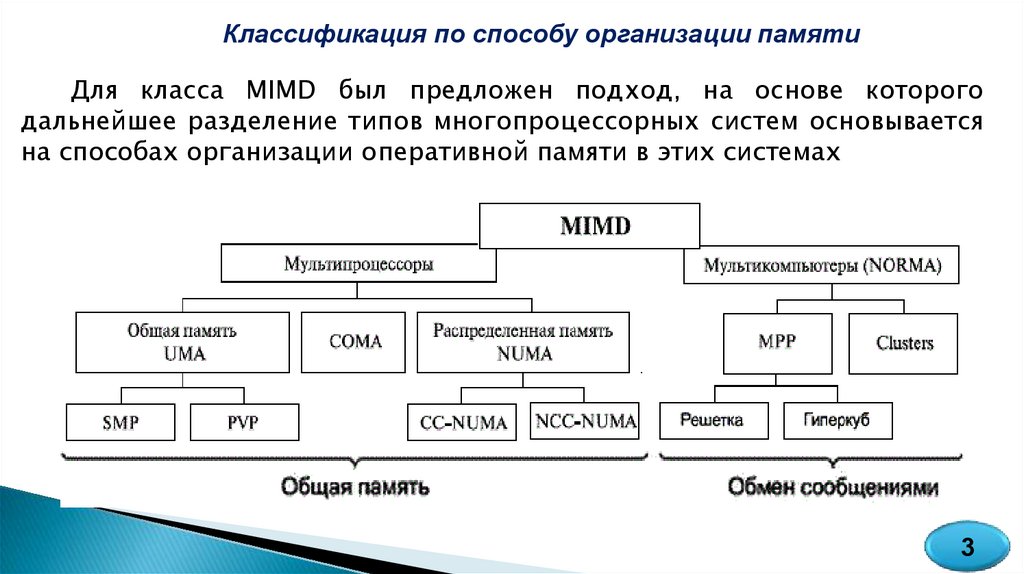
Классификация по способу организации памятиДля класса MIMD был предложен подход, на основе которого
дальнейшее разделение типов многопроцессорных систем основывается
на способах организации оперативной памяти в этих системах
3
5.
Данныйпоход
позволяет
различать
два
важных
типа
многопроцессорных систем - мультипроцессоры (машины с общей или
разделяемой памятью) и мультикомпьютеры (машины с распределенной
памятью
и
обменом
сообщениями).
Существует
три
типа
мультипроцессоров. Они отличаются друг от друга механизмом
доступа к общей памяти и называются:
UMA (Uniform Memory Access – однородный доступ к памяти),
NUMA (Nonuniform Memory Access – неоднородный доступ к памяти)
СОМА (Cache Only Memory Access – доступ только к кэш-памяти).
Такое разбиение на подкатегории имеет смысл, поскольку в больших
мультипроцессорах память обычно делится на несколько модулей. В UMA-машинах
каждый процессор имеет одно и то же время доступа к любому модулю памяти. Иными
словами, каждое слово может быть считано из памяти с той же скоростью, что и любое
другое слово. Если это технически невозможно, самые быстрые обращения замедляются,
чтобы соответствовать самым медленным, поэтому программист не заметит никакой
разницы. Это и значит "однородный" доступ. Такая однородность делает
производительность предсказуемой, а этот фактор очень важен для создания эффективных
программ.
4
6.
NUMA-машина, напротив, не обладает свойством однородности.Обычно у каждого процессора есть один из модулей памяти, который
располагается к нему ближе, чем другие, поэтому доступ к этому модулю
памяти происходит гораздо быстрее, чем к другим. В этом случае с точки
зрения производительности очень важно, где окажутся программа и
данные. В этом классе ВС обычно выделяют два подкласса, а именно
Системы, в которых обеспечивается однозначность (когерентность)
локальной кэш памяти разных процессоров (CC-NUMA – cache-coherent
NUMA). Примером таких систем являются SGI Origin2000, Sun HPC 10000,
IBM/Sequent NUMA-Q 2000.
Системы, в которых обеспечивается общий доступ к локальной
памяти разных процессоров без поддержки на аппаратном уровне
когерентности кэша (NCC-NUMA – non-cache coherent NUMA). К данному
типу относится, например, система Cray T3E.
5
7.
По своей структуре близкими к этому типу ВС являются и системы, вкоторых для представления данных используется только локальная кэш
память имеющихся процессоров (COMA – cache-only memory access).
Доступ к СОМА-машинам тоже оказывается неоднородным, но по другой
причине. Примерами таких систем являются, например, KSR-1 и DDM.
Вторую категорию MIMD-машин составляют мультикомпьютеры, которые
в отличие от мультипроцессоров не имеют общей памяти на
архитектурном уровне. Как уже отмечалось, хотя пользовательские
программы могут обращаться к другим модулям памяти, но эта
способность не подкреплена аппаратно, иллюзию создает операционная
система. Разница незначительна, но очень важна. Мультикомпьютеры не
имеют непосредственного доступа к удаленным модулям памяти и
поэтому их относят к категории NORMA (NO Remote Memory Access –
отсутствие удаленного доступа к памяти), в которой выделяют две
дополнительные категории:
6
8.
К категории МРР (Massively Parallel Processor – процессор с массовымпараллелизмом) относятся дорогостоящие суперкомпьютеры, которые
состоят
из
большого
количества
процессоров,
связанных
высокоскоростной внутренней коммуникационной сетью.
Вторая категория включает обычные ПК или рабочие станции (иногда
смонтированные в стойки), которые связываются в соответствии с той
или иной коммерческой коммуникационной технологией. Такие
системы называют сетями рабочих станций (NOW – Network Of
Workstations), кластерами рабочих станций (COW – Cluster Of
Workstations), или просто кластерами (Cluster).
Принципиальной разницы здесь нет, но мощный суперкомпьютер стоимостью в миллионы
долларов безусловно используется иначе, чем собранная конечными пользователями
компьютерная сеть, которая обходится во много раз дешевле любой МРР-машины. К разряду
МРР-систем относятся IBM RS/6000 SP2, Intel PARAGON/ASCI Red, транспьютерные системы
Parsytec и др. Примерами кластеров являются, например, системы AC3 Velocity и NCSA/NT
Supercluster
7
9.
2. Архитектуры мультипроцессоров. Основныенаправления в организации параллельных вычислений
Трудно построить компьютер на одном процессоре со временем цикла в
0,001 нс, но реально построить систему с 1000 процессорами со временем цикла
1 нс. И хотя быстродействие процессоров мало, но теоретически получим
требуемую производительность системы. Системы параллельного действия — это
одно из основных направлений в компьютерной индустрии. При этом
параллелизм может быть организован на разных уровнях:
На самом низком уровне его можно организовать в процессоре за счет
конвейеризации и суперскалярной архитектуры с несколькими функциональными
блоками.
Скрытого параллелизма можно добиться путем значительного удлинения
слов в командах или посредством дополнительных функций "научить" процессор
одновременно обрабатывать группу программных потоков.
Наконец, можно установить на одной микросхеме несколько процессоров.
8
10.
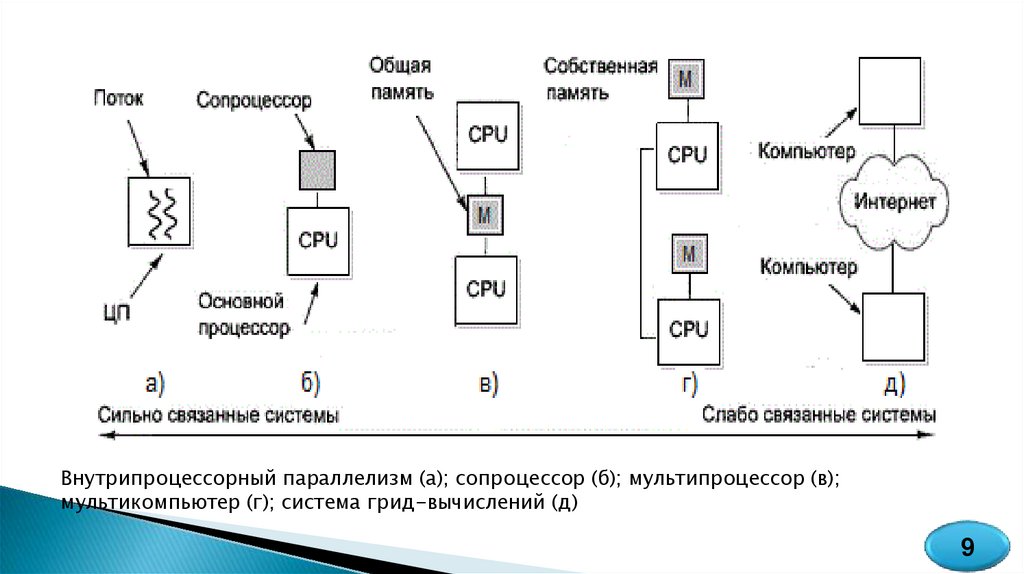
Внутрипроцессорный параллелизм (а); сопроцессор (б); мультипроцессор (в);мультикомпьютер (г); система грид-вычислений (д)
9
11.
На следующем уровне организации параллелизма доступновнедрение
в
систему
внешних
плат
специализированных
сопроцессоров, которые реализуют такие специфические функции, как
обработка сетевых пакетов, мультимедийных данных, криптография и т.
д. Производительность специализированных приложений за счет этих
функций может быть повышена в 5-10 раз.
Чтобы повысить производительность в сто, тысячу или миллион раз,
необходимо свести воедино многочисленные процессоры и обеспечить
их эффективное взаимодействие. Этот принцип реализуется в виде
больших мультипроцессорных систем и мультикомпьютеров.
Наконец, в последнее время появилась возможность интеграции
через Интернет, как отдельных компьютеров, так и корпоративных
сетей. Из них формируют слабо связанные распределенные
вычислительные сетки, или решетки. Такие системы только начинают
развиваться, но их потенциал весьма высок.
10
12.
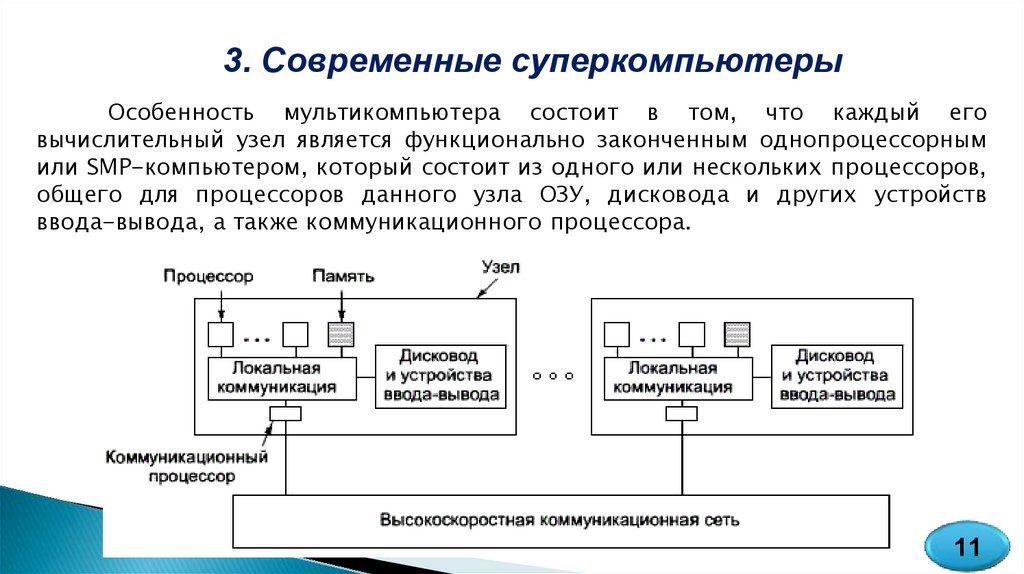
3. Современные суперкомпьютерыОсобенность мультикомпьютера состоит в том, что каждый его
вычислительный узел является функционально законченным однопроцессорным
или SMP-компьютером, который состоит из одного или нескольких процессоров,
общего для процессоров данного узла ОЗУ, дисковода и других устройств
ввода-вывода, а также коммуникационного процессора.
11
13.
Мультикомпьютеры в отличие от мультипроцессоров не имеютобщей памяти на архитектурном уровне, но пользовательские
программы могут обращаться к другим модулям памяти. И хотя эта
возможность не подкреплена аппаратно, иллюзию создает ОС.
Программы процессоров одного узла не могут получить доступ к
памяти другого узла командами Load и Store. Как уже отмечалось, они
взаимодействуют друг с другом с помощью примитивов Send и Receive,
которые
используются
для
передачи
сообщений.
Разница
незначительна, но очень важная, так как полностью меняет модель
программирования.
Мультикомпьютер — вычислительная система без общей памяти,
состоящая из большого числа взаимосвязанных компьютеров, у каждого
из которых имеется собственная память. Процессоры мультикомпьютера
отправляют друг другу сообщения (используется сетевые топологии
двух-, трехмерной решетки, дерева или кольца).
12
14.
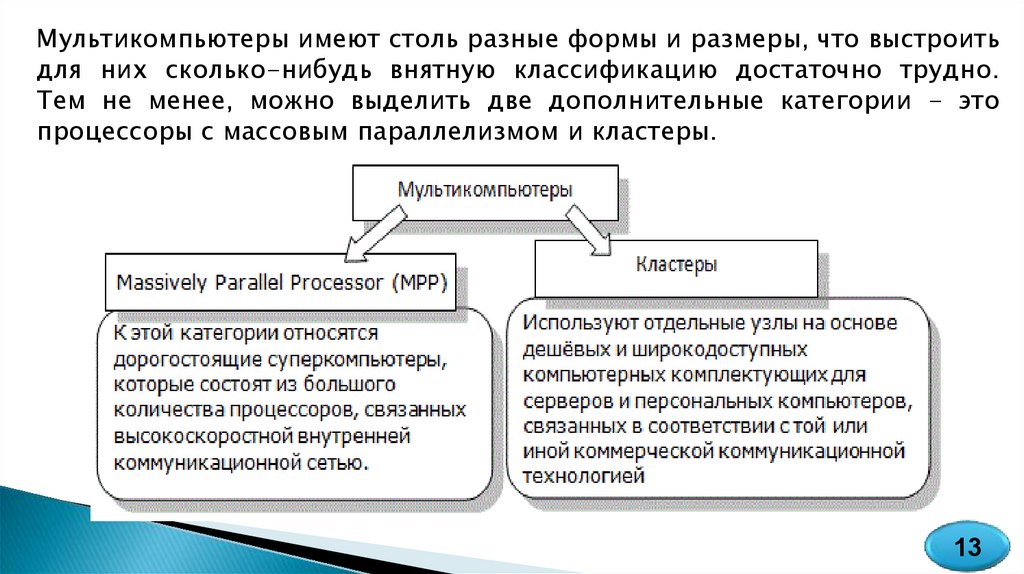
Мультикомпьютеры имеют столь разные формы и размеры, что выстроитьдля них сколько-нибудь внятную классификацию достаточно трудно.
Тем не менее, можно выделить две дополнительные категории - это
процессоры с массовым параллелизмом и кластеры.
13
15.
Суперкомпьютер — это вычислительная машина, которая значительно превосходит по своимтехническим параметрам большинство существующих компьютеров. Следует особо отметить,
что та или иная архитектура не может считаться признаком принадлежности к классу
суперкомпьютеров.
Этапы развития суперкомпьютеров
На заре развития ЭВМ это были обычные машины, оснащённые лишь быстрыми для
своего времени скалярными процессорами, скорость работы которых была в несколько
десятков раз выше, чем у других компьютеров.
Большинство суперкомпьютеров 70-х оснащалось векторными процессорами, а в начале
80-х небольшое число (от 4 до 16) параллельно работающих векторных процессоров
практически стало стандартным суперкомпьютерным решением.
В начале 90-х годов сменилось магистральное направление развития суперкомпьютеров
от векторно-конвейерной обработки к большому и сверхбольшому числу параллельно
соединённых скалярных процессоров.
В конце 90-х годов высокая стоимость специализированных суперкомпьютерных
решений и нарастающая потребность разных слоёв общества в доступных вычислительных
ресурсах привели к широкому распространению компьютерных кластеров.
В настоящее время суперкомпьютерами принято называть компьютеры с огромной
вычислительной мощностью, которые используются для работы с приложениями,
требующими наиболее интенсивных вычислений. Например, прогнозирование погодноклиматических условий, моделирование ядерных испытаний и т. п.
14
16.
Системы с массивно-параллельной архитектурой (Massively ParallelProcessor, МРР) используются в различных отраслях науки и техники для
выполнения сложных вычислений, обработки большого числа
транзакций в секунду, управления большими базами данных, и т. д.
Изначально это были суперкомпьютеры, предназначенные в основном
для научных расчетов, но сейчас многие из них находят применение и в
коммерции.
Основные причины появления систем с МРР-архитектурой:
- необходимость построения систем с гигантской производительностью;
стремление раздвинуть границы производства вычислительных систем в
большом диапазоне, как по производительности, так и по стоимости;
для систем, в которых количество процессоров может меняться в
широких пределах, всегда реально подобрать конфигурацию с заранее
заданной вычислительной мощностью и финансовыми вложениями.
Количество процессоров в МРР-системах может меняться и можно
выбрать конфигурацию с необходимой вычислительной мощностью
15
17.
Проект по составлению рейтинга и описаний 500 самых мощныхизвестных компьютерных систем мира был запущен в 1993 году. Он
дважды в год (в июне и ноябре) публикует актуальный список
суперкомпьютеров и направлен на отслеживание тенденций в области
высокопроизводительных вычислений. Основа рейтинга — это
результаты исполнения теста LINPACK, решающего большие системы
линейных арифметических уравнений. В качестве единицы измерения
производительности служит FLOP/s (англ. FLoating point OPerations per
second) — количество арифметических операций, выполняемых за
секунду.
16
18.
Начиная с 2010 года долгое время рейтинг возглавляла система Tianhe-2,разработанная в Китайском Национальном университете оборонных технологий. С
китайского языка «Тяньхэ» переводится как «Млечный Путь». Tianhe-2 содержит шестнадцать
тысяч вычислительных узлов, в каждом из которых расположено по два процессора Intel Xeon
E5-2692 и по три векторных сопроцессора Intel Xeon Phi 31S1P. На каждый процессор
выделяется по 32 ГБ оперативной памяти стандарта DDR3 с коррекцией ошибок, а на каждый
сопроцессор — по 8 ГБ памяти стандарта GDDR5. Суммарный объём всех модулей памяти
составляет тысячу терабайт.
Самой мощной в Европе стала система Cray XC30. Названная Piz Daint, в честь одного
из пиков Швейцарских Альп, она установлена в Швейцарском национальном центре
суперкомпьютерных вычислений. Эта система занимает 6 место в TOP500, достигнув
отметки в 6.2 петафлопс на тесте LINPACK.
Россия на ноябрь 2014 года занимала 8 место по количеству эксплуатируемых
вычислительных систем. Всего 9 суперкомпьютеров, работающих в России присутствует в
списке TOP500, а самый мощный из них, установленный в Научно-исследовательском
вычислительном центре МГУ T-Platforms A-Class, занимает 22 место в рейтинге.
Согласно этой же редакции рейтинга в первую десятку производителей
суперкомпьютеров вошла российская группа компаний РСК. Она занимает 9-е место в мире
среди ведущих поставщиков суперкомпьютеров.
17
19.
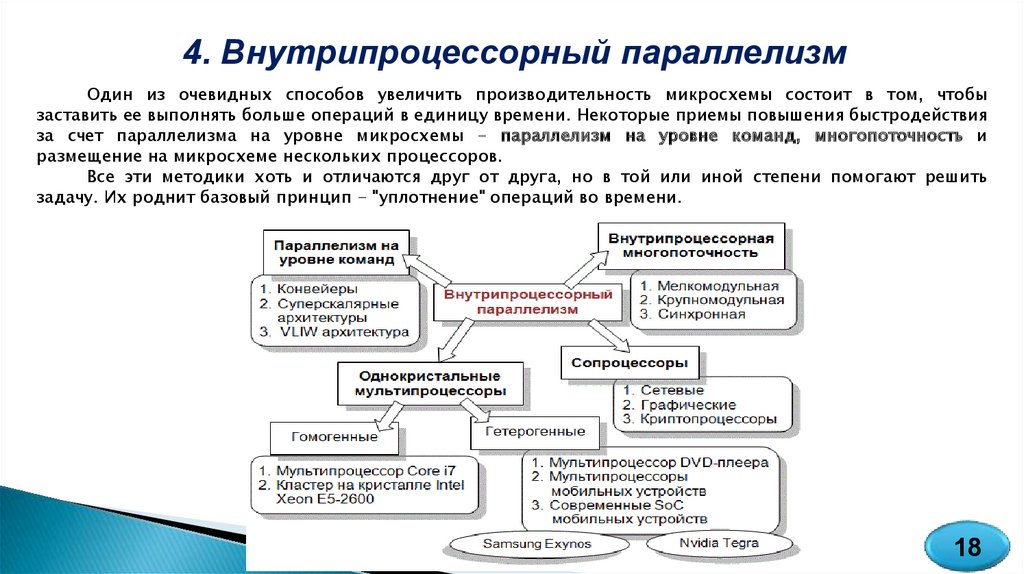
4. Внутрипроцессорный параллелизмОдин из очевидных способов увеличить производительность микросхемы состоит в том, чтобы
заставить ее выполнять больше операций в единицу времени. Некоторые приемы повышения быстродействия
за счет параллелизма на уровне микросхемы - параллелизм на уровне команд, многопоточность и
размещение на микросхеме нескольких процессоров.
Все эти методики хоть и отличаются друг от друга, но в той или иной степени помогают решить
задачу. Их роднит базовый принцип - "уплотнение" операций во времени.
18
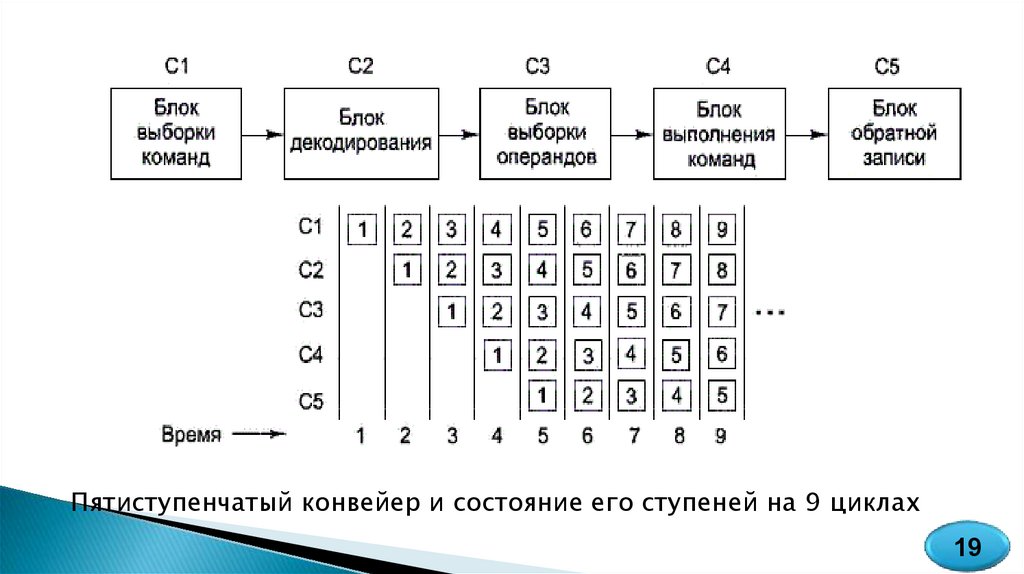
20.
Пятиступенчатый конвейер и состояние его ступеней на 9 циклах19
21.
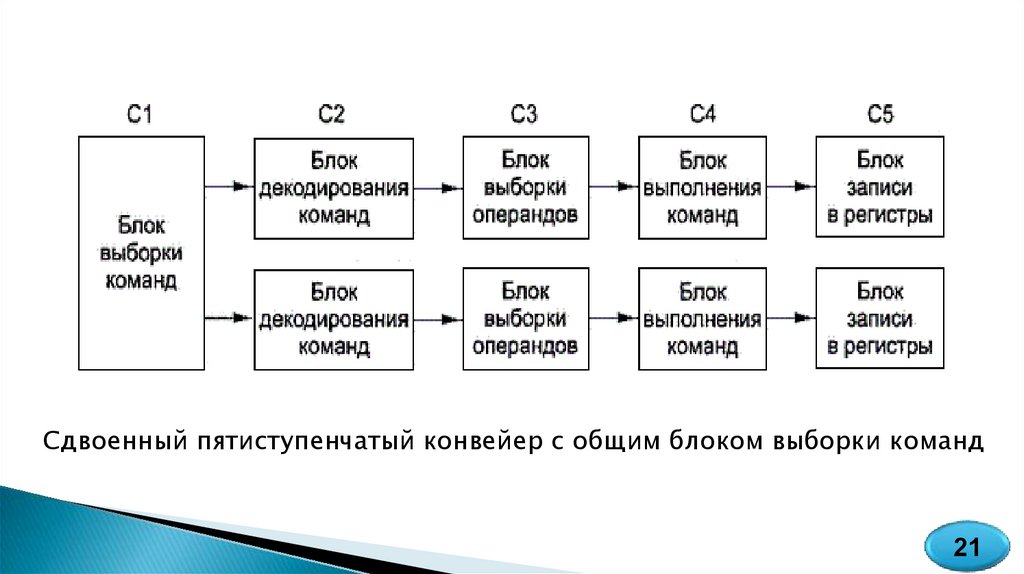
Суперскалярные архитектурыВ основе лежит сдвоенный конвейер. Общий блок выборки команд вызывает
из памяти сразу по две команды и помещает каждую из них в один из
конвейеров. Каждый конвейер содержит АЛУ для параллельных операций.
Чтобы две команды выполнялись параллельно, они не должны конфликтовать
из-за ресурсов (например, регистров), и ни одна из них не должна зависеть от
результата выполнения другой. Для этого, либо компилятор должен
гарантировать отсутствие нештатных ситуаций, либо необходима дополнительная
аппаратура, которая выявляет конфликты и устраняет их непосредственно в ходе
выполнения команд.
Конвейеры в процессорах компании Intel появились, только начиная с модели
486. Процессор 486 имел один пятиступенчатый конвейер, a Pentium - два таких
конвейера. Главный конвейер (u-конвейер) мог выполнять произвольные
команды, а второй конвейер (v-конвейер) мог выполнять только простые команды
с целыми числами.
20
22.
Сдвоенный пятиступенчатый конвейер с общим блоком выборки команд21
23.
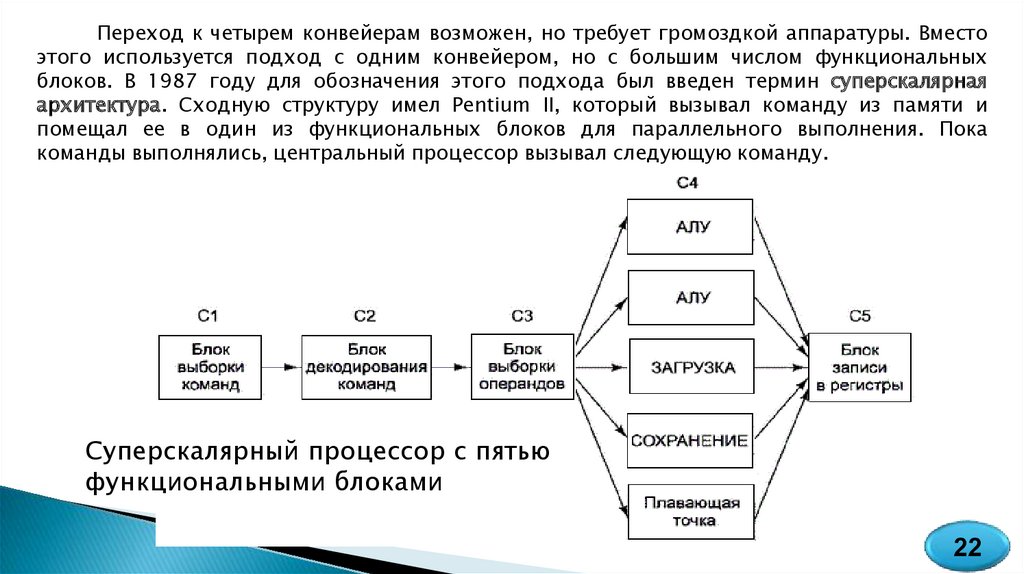
Переход к четырем конвейерам возможен, но требует громоздкой аппаратуры. Вместоэтого используется подход с одним конвейером, но с большим числом функциональных
блоков. В 1987 году для обозначения этого подхода был введен термин суперскалярная
архитектура. Сходную структуру имел Pentium II, который вызывал команду из памяти и
помещал ее в один из функциональных блоков для параллельного выполнения. Пока
команды выполнялись, центральный процессор вызывал следующую команду.
Суперскалярный процессор с пятью
функциональными блоками
22
24.
VLIW архитектура со сверхдлинным командным словомАрхитектура со сверхдлинными командами (VLIW, Very Long
Instruction Word) известна с начала 80-х из ряда университетских
проектов, но только с развитием технологии производства микросхем
она нашла свое достойное воплощение.
Идея VLIW состоит в том, что задача эффективного планирования
параллельного выполнения нескольких команд возлагается на
«разумный» компилятор. Такой компилятор на первом этапе исследует
исходную программу с целью обнаружить все команды, которые могут
быть выполнены одновременно, причем так, чтобы это не приводило к
возникновению конфликтов.
23
25.
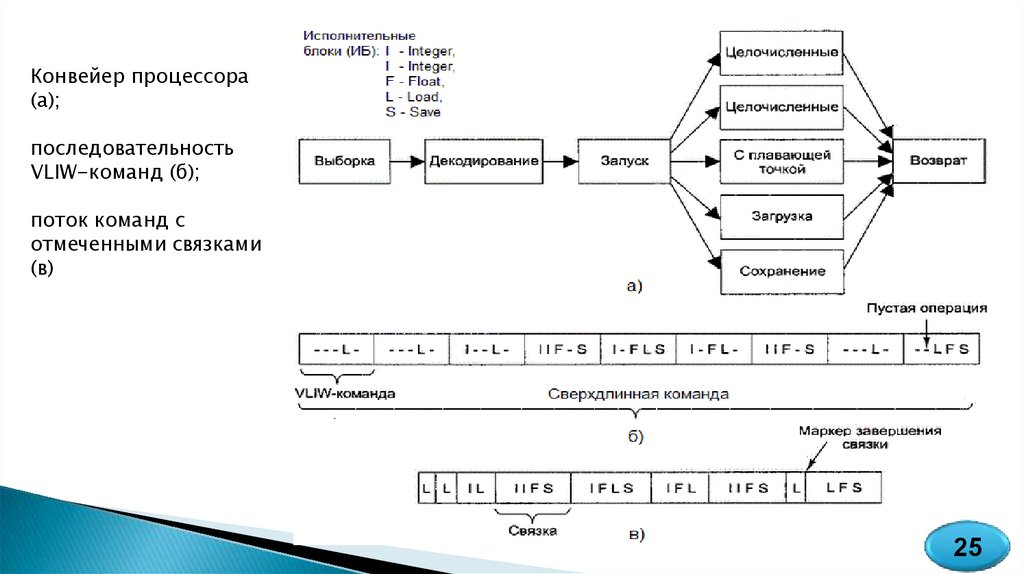
На следующем этапе компилятор пытается объединить такиекоманды в пакеты, каждый из которых рассматривается как одна
сверхдлинная команда. Объединение нескольких простых команд в одну
сверхдлинную производится по следующим правилам:
- количество простых команд, объединяемых в одну команду
сверхбольшой длины, равно числу имеющихся в процессоре
исполнительных блоков (ИБ);
- в сверхдлинную команду входят только такие простые команды,
которые исполняются разными ИБ, что обеспечивает одновременное
исполнение всех составляющих сверхдлинной команды.
Длина сверхдлинной команды обычно составляет от 256 до
1024 бит. Она содержит несколько полей, по числу образующих ее
простых команд, каждое из которых описывает операцию для
конкретного исполнительного блока. На рисунке показан возможный
формат сверхдлинной команды и взаимосвязь между ее полями и ИБ,
реализующими отдельные операции.
24
26.
Конвейер процессора(а);
последовательность
VLIW-команд (б);
поток команд с
отмеченными связками
(в)
25
27.
Внутрипроцессорная многопоточностьДля
всех
современных
конвейеризованных
процессоров
характерна одна и та же проблема - если при запросе к памяти слово не
обнаруживается в кэшах первого и второго уровней, то на загрузку его в
кэш уходит длительное время, в течение которого конвейер простаивает.
Одна
из
методик
решения
этой
проблемы
называется
внутрипроцессорной многопоточностью (on-chip multithreading). Она
позволяет
процессору
одновременно
управлять
несколькими
программными потоками и тем самым маскировать простои. Вкратце
принцип многопоточности можно изложить так: если программный
поток 1 блокируется, процессор может обеспечить полную загрузку
аппаратуры, запустив программный поток 2. Основная идея проста, но
реализуется она разными способами.
26
28.
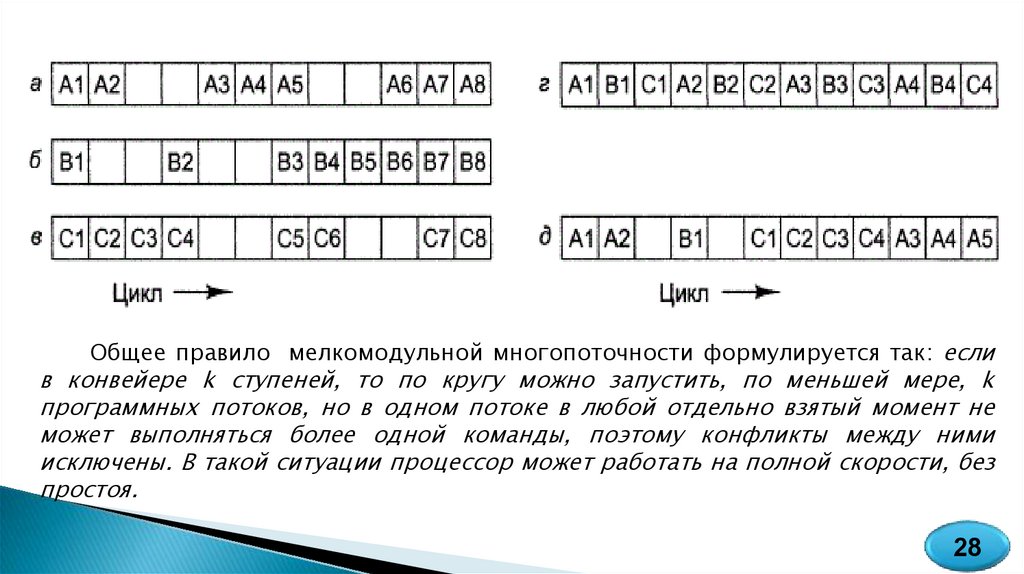
Мелкомодульная многопоточностьЭтот подход применительно к процессору, который способен
вызывать только одну команду за такт, иллюстрирует рисунок. В его
левой части изображено три программных потока (А, В, С),
соответствующих 12 машинным циклам.
В ходе первого цикла поток А выполняет команду А1. Поскольку
она завершается за один цикл, то на втором цикле запускается команда
А2. Ее обращение в кэш первого уровня было неудачным, и до
извлечения нужного слова из кэша второго уровня пройдет два цикла.
Поэтому выполнение потока А продолжится только на цикле 5.
Аналогичный процесс наблюдается и при раздельном выполнении
потоков В и С, которые также будут периодически простаивать. При
таком решении вызов последующей команды до завершения
предыдущей не осуществляется.
27
29.
Общее правило мелкомодульной многопоточности формулируется так: еслив конвейере k ступеней, то по кругу можно запустить, по меньшей мере, k
программных потоков, но в одном потоке в любой отдельно взятый момент не
может выполняться более одной команды, поэтому конфликты между ними
исключены. В такой ситуации процессор может работать на полной скорости, без
простоя.
28
30.
Крупномодульная многопоточностьНе всегда число потоков будет равно числу ступеней конвейера, поэтому ряд
разработчиков
используют
подход,
называемый
крупномодульной
многопоточностью (coarse-grained multithreading). В этом случае программный
поток А выполняется последовательно, вплоть до момента простоя. Теряется один
цикл и происходит переключение на первую команду В1 другого программного
потока. Но команда В1 сразу переходит в состояние простоя, опять теряется один
цикл, и в цикле 6 уже будет выполняться команда С1 из третьего программного
потока.
Многопоточность в сдвоенном процессоре:
мелкомодульная (а), крупномодульная (б) и
синхронная многопоточность (в)
29
31.
Синхронная многопоточностьВ суперскалярных процессорах используется еще один способ
организации многопоточности - синхронная многопоточность. Она
представляет собой усовершенствованный вариант крупномодульной
многопоточности, где каждый программный поток может запускать по
две команды за такт, но в случае простоя с целью обеспечения полной
загрузки процессора запускаются команды следующего потока.
При синхронной многопоточности полностью загружаются все
функциональные блоки. В случае невозможности запуска команды из-за
занятости функционального блока выбирается команда из другого
потока. На рисунке предполагается, что в цикле 11 простаивает
команда В8, поэтому в цикле 12 запускается команда С7.
30