



























 mathematics
mathematicsSimilar presentations:










Кластерный анализ экспериментальных данных
1.
План лекцииЛекция 5. Кластерный анализ экспериментальных данных……………81
5.1. Кластерный анализ: цели и задачи…………..…………………..82
5.2. Меры сходства признаков в общем наборе данных…………….83
5.3. Процедуры кластерного анализа данных.………..……….…….94
5.3.1. Классификация процедур кластерного анализа данных.………..…94
5.3.2. Агломеративная процедура кластеризации по расстоянию…..…96
5.3.3. Метод вроцлавской таксономии………………………...………..…98
5.3.4. Метод корреляционных плеяд…………………………...………..…101
5.3.5. Метод k-средних……………..…………………………...………..…104
Задания к практическому занятию ..…………………………..…….106
Контрольные вопросы..…………………………..…………………….107
1
2.
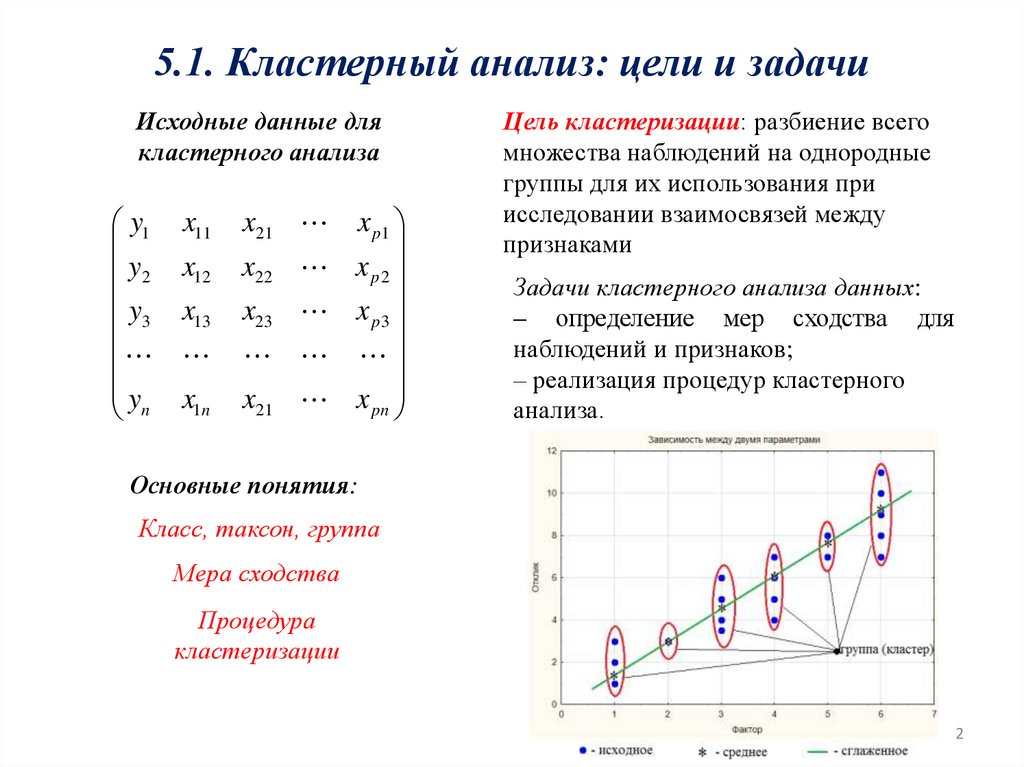
5.1. Кластерный анализ: цели и задачиИсходные данные для
кластерного анализа
y1
y2
y
3
y
n
x11
x12
x13
x1n
x21 x p1
x22 x p 2
x23 x p 3
x21 x pn
Цель кластеризации: разбиение всего
множества наблюдений на однородные
группы для их использования при
исследовании взаимосвязей между
признаками
Задачи кластерного анализа данных:
– определение мер сходства для
наблюдений и признаков;
– реализация процедур кластерного
анализа.
Основные понятия:
Класс, таксон, группа
Мера сходства
Процедура
кластеризации
2
3.
5.2. Меры сходства признаков в общем наборе данныхСходство между факторами
y1 x11
y2 x12
y x
13
3
y x
n 1n
S 00
S10
S
p0
x21 x p1
x22 x p 2
x23 x p 3
x21 x pn
S 01 S 0 p
S11 S1 p
S p1 S pp
Матрица сходства по факторам
Сходство между наблюдениями
y1
y2
y
3
y
n
x11
x12
x13
x1n
S11
S 21
S
n1
x21 x p1
x22 x p 2
x23 x p 3
x21 x pn
S12
S 22
Sn2
S1n
S2n
S nn
Матрица сходства по наблюдениями
3
4.
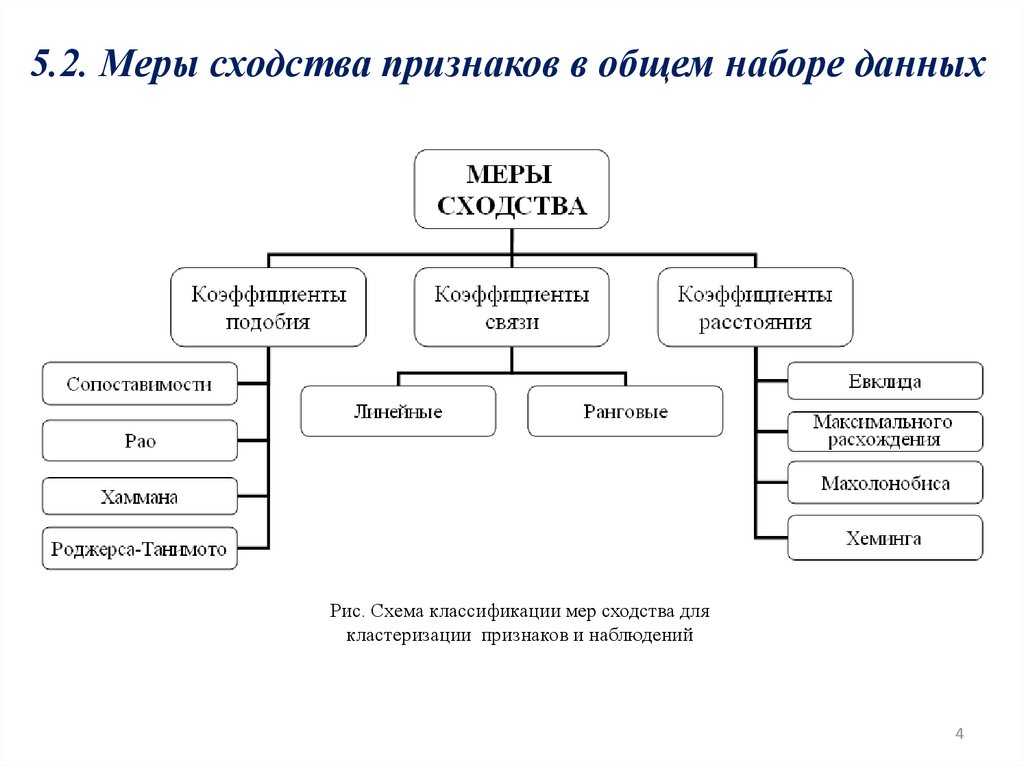
5.2. Меры сходства признаков в общем наборе данныхРис. Схема классификации мер сходства для
кластеризации признаков и наблюдений
4
5.
5.2. Меры сходства признаков в общем наборе данныхПорядок вычисления:
1. Подготовить матрицу исходных данных.
2. Перевести значения наблюдаемых
признаков в бинарный вид.
3. Выровнять количество бинарных
признаков во всех исходных данных
по длине максимального значения
в каждом столбце.
4. Выполнить расчет коэффициентов
подобия по соответствующей формуле
для каждой пары признаков или
наблюдений.
5. Записать вычисленные коэффициенты
на соответствующие места в матрице.
Формулы для вычисления:
Коэффициент совстречаемости
S kl
Pkl
S
Коэффициент Рао
S kl
Pkl1,1
S
Коэффициент Хаммана
S kl
Pkl Qkl
S
Коэффициент Роджерса и Танимото
S kl
Pkl1,1
Pk1,1 Pl1,1 Pkl1,1
Обозначение: S – количество сравниваемых
бинарных признаков; k, l – номера строк
(столбцов), выбранных для рассмотрения;
P – количество совпадений; Q – количество
несовпадений.
5
6.
5.2. Меры сходства признаков в общем наборе данныхПоложение
коэффициента
в матрице
l
k 0,55
S kl
P
kl
S
S kl
Pkl1,1
S
S kl
P Qkl
kl
S
S kl
Pkl1,1
Pk1,1 Pl1,1 Pkl1,1
Для каждого вида коэффициентов строится новая матрица!
6
7.
5.2. Меры сходства признаков в общем наборе данныхЛинейный коэффициент корреляции
является количественной оценкой
линейной взаимосвязи между двумя
выбранными объектами, в частном
случае – столбцами или строками
данных.
Z iT Z j
1 n
rij Z ki Z kj
n k 1
n
Z1i
Z
Z i 2i
Z
ni
Z ki
X ki X i
i
i, j 1, p; k 1, n;
Матрица парной корреляции:
ryy
rx1 y
...
rx y
p
ryx1
rx1 x1
...
rx p x1
ryx p
... rx1 x p
... ...
... rx p x p
...
Свойства коэффициентов:
а) rkl [-1;1];
б) если rkl=0, то выбранные признаки не
зависимы, при условии наличия нормального
распределения;
в) если |rkl|=1, то между выбранными величинами
существует функциональная зависимость, при
условии наличия нормального распределения;
г) если rkl<0, то между выбранными зависимость
убывающая, если rkl>0, то между выбранными
зависимость возрастающая;
д) rkk=1, k=0, 1, 2, …, p;
е) для остальных возможных значений
коэффициента корреляции между признаками
существует стохастическая (вероятностная
зависимость).
Свойства матрицы:
1. Если из этой матрицы удалить строку и
столбец соответствующие функции
отклика, то будет получена матрица
межфакторной корреляции.
2. Матрицы симметричная относительно
главной диагонали.
7
8.
5.2. Меры сходства признаков в общем наборе данных*
*
*
Обозначения: 1 – область сильной линейной зависимости; 2 – область значимой линейной зависимости; 3 – область слабой
8
линейной зависимости; rкр – критическое значение линейного коэффициента корреляции.
9.
5.2. Меры сходства признаков в общем наборе данныхАлгоритм проверки:
Пример оценки значимости:
1) выдвигается гипотеза H0 о том, что
линейный коэффициент корреляции
попадает в область значимости;
2) рассчитывается величина t-статистики:
tфакт
r n 2
1 r2
3) проверяется неравенство
tфакт tтабл ,
4) если неравенство истинно, то нет
оснований отвергать выдвинутую
гипотезу.
Гипотеза проверяется для каждого
коэффициента в матрице парной
корреляции, за исключением главной
диагонали.
Дано: r=0,34; n=127; p=5; =5%.
Определить: значимость r.
Решение:
Выдвинем гипотезу H0 о том, что
линейный коэффициент корреляции
попадает в область значимости.
Рассчитаем величину t-статистики
tфакт
r n 2
1 r 2
0,34 127 2
1 0,34 2
0,34 15
5,42
0,94
Находим табличное значение:
tтабл , tтабл 5%,125 1,97.
Проверяем неравенство:
5,42 1,97.
Вывод: неравенство истинно, нет оснований
отвергать гипотезу на 5 %-ом уровне
значимости.
9
10.
5.2. Меры сходства признаков в общем наборе данныхПод ранговой корреляцией понимается
статистическая связь между ранжировками.
Исходные данные представлены ранжировками т
экспертов n альтернатив в виде матрицы
rij
rl rl1 ,..., rln
rk rk1 ,..., rkn
где i = 1, ..., m, j = 1, ..., n, где rij – ранговая оценка i-го
эксперта для j-й альтернативы.
Коэффициент ранговой корреляцией
1 3
Спирмена
n n S 2 T T
lk
lk
6
S rlj rkj
j 1
2
k
1 H 3
Ti hd hd
2 d 1
lk
2
1 lk
t ,n 2
2
n 2
где t(Q, ) – 100 Q%-ная точка распределения
Стьюдента с степенями свободы, Q = /2.
1 3
1 3
n n 2Tl n n 2Tk
6
6
m
2
lk
l
Проверка статистически значимого
отличия от нуля рангового
коэффициента корреляции проводится
при «не слишком малых» n (n> 10) и
заданном уровне значимости критерия
с помощью неравенства
где Тi – показатель связанных рангов в i-и ранжировке; Hi
– число групп равных рангов в i-и ранжировке; hd –
число равных рангов в d-й группе связанных рангов в i-и
ранжировке.
Выполнение неравенства приводит к
необходимости отвергнуть гипотезу об
отсутствии статистически значимой
ранговой корреляционной связи, то
есть мнения двух экспертов
признаются согласованными.
10
11.
5.2. Меры сходства признаков в общем наборе данныхРасстояние Евклида между объектами обычно оценивается метрикой:
1 m
Z kj Zlj 2
d kl
m j 1
d kl
w Z
m
j 1
j
Z lj
2
kj
Рис. Схема расчета расстояния между объектами
Максимальное расхождение
(расстояние Чебышева)
Расстояние Махалонобиса
d kl2 Z k Z l R 1 Z k Z l T
d kl макс Z kj Z lj
1 j m
Расстояние Хемминга (расстояние городских кварталов или
Манхэттенское расстояние)
1 m
d kl Z kj Z lj
m j 1
11
12.
5.2. Меры сходства признаков в общем наборе данныхРис. 2. Цветовые
карты
Рис. 1. Настройка уровня значимости
Рис. 3. Матрица парной корреляции
12
13.
5.2. Меры сходства признаков в общем наборе данныхРис. 1. Настройка объектов и метода
для расчета расстояния
Рис. 2. Матрицы расстояний Евклида для строк и столбцов
13
14.
5.3. Процедуры кластерного анализа данныхРис. 1. Схема классификации процедур кластеризации
Рис. 2. Схема неиерархической
процедуры кластеризации
14
15.
5.3. Процедуры кластерного анализа данныхАгломеративная
Дивизимная
а
Комбинированная
б
в
Рис. Схемы иерархических процедур кластеризации
15
16.
5.3.2. Агломеративная процедура кластеризации порасстоянию
Алгоритм:
а) в исходной матрице сходства (расстояния)
находят два различных, но наиболее
подобных (ближайших) объекта (кластера) p
и q;
Методы расчета расстояния
между кластерами:
1) медианный:
p= q=½, = -¼, =0;
б) кластеры p и q объединяют в один общий
кластер r;
2) простого среднего:
p= q=½, = =0;
в) составляется новая матрица расстояний, в
которой сохраняются прежние, кроме p и q,
кластеры, но вводится новый кластер r,
причем расстояние от любого
сохранившегося кластера s до кластера r
определяется как
3) группового среднего:
d sr p d ps q d qs d pq d ps d qs
где dps, dqs, dpq – расстояния между
кластерами по предыдущей матрице, p, q,
, – параметры, определяемые методом
расчета.
p
np
n p nq
q
nq
n p nq
= =0, где n – число объектов в
соответствующей группе;
4) центроидный:
p
np
n p nq
nq
n p nq 2
q
nq
n p nq
=0
16
17.
5.3.2. Агломеративная процедура кластеризации порасстоянию
Требуется выполнить кластеризацию
методом простого среднего.
1
1
d 41 d 31 0 d 43 0 d 41 d 31
2
2
1
1
5
3 2 2,5;
2
2
2
1
1
d 26 d 42 d 32 0 d 43 0 d 42 d 32
2
2
1
1
7
4 3 3,5;
2
2
2
1
1
d 56 d 45 d 35 0 d 43 0 d 45 d 35
2
2
1
1
7
4 3 3,5.
2
2
2
Решение:
Новая матрица:
Пусть по результатам наблюдений
построена матрица расстояний
0
1
2
3
2
1
0
3
4
2
2
3
4 2
0 0,5 3
0,5 0 4
3
4 0
2
3
Определим минимальное расстояние
в матрице: d43=0,5.
Следовательно, p=4 и q=3.
Вводим новый кластер с номером s=6.
Выполним расчет всех остальных
расстояний:
d16
1
2 2,5
0
0
2 3,5
1
2
2
0 3,5
2,5 3,5 3,5 0
Первый кластер:
4
Процесс итерационный…
3
0,5
17
18.
5.3.3. Метод вроцлавской таксономииДендрит – это такая ломаная, которая может разветвляться, но не может
содержать замкнутых ломаных, и которой соединены две любые точки множества
признаков.
Алгоритм метода вроцлавской таксономии:
1. Из матрицы расстояний выбираются элементы с близкими
расстояниями. Поиск проводится путем нахождения
наименьших чисел в каждом столбце (или строке) матрицы
расстояний.
2. Выполнить построение дендритов первого порядка.
3. Выполнить объединение скоплений дендритов первого
порядка в дендриты второго порядка. Объединение
выполняется до тех пор пока не будет получен единый
дендрит.
Рис. Вид дендрита
Преимущества:
Использует матрицу
расстояний, но не требует их
пересчета.
4. Упорядочить связи дендрита по убыванию длины
рассчитать отношение:
i2
d1
d
, i3 2 ,
d2
d3
…
in 1
d n 2
,
d n 1
5. Найти все k, для которого выполняется соотношение
ik-1<ik (для k=2, 3, ..., n-2) и выбрать из них минимальное.
6. Разорвать k-1 связь.
18
19.
5.3.3. Метод вроцлавской таксономииПусть по результатам наблюдений
построена матрица расстояний
0
1
2
3
2
1
0
3
4
2
2
3
4 2
0 0,5 3
0,5 0 4
3
4 0
2
1
1,0
3
Требуется выполнить кластеризацию
методом вроцлавской таксономии.
Решение:
Определим минимальное расстояние
в каждом столбце матрицы:
d21=1, d12=1, d43=0,5, d34=0,5, d15=2.
Получаем дендриты первого порядка
с учетом повторений:
3
2
1
2
4
0,5
5
Дендриты второго порядка:
1
2
3
2
1,0
0,5
4
Определяем минимальное
расстояние между
5
скоплениями:
Min{d13=2, d23=3, d53=3, d14=3, d42=4,
d45=4}=d13=2.
Объединяем 1 и 3 группу. Получаем
общий дендрит
1
2
1,0
4
0,5
3
2
2
5
19
20.
5.3.3. Метод вроцлавской таксономииУпорядочивание связей:
di
Sij
Значение
ik
Значение
d1
S15
2
d2
S13
2
i2
1
d3
S12
1
i3
2
d4
S34
0,5
i4
2
Количество кластеров: 3.
Количество разрываемых связей: 2.
Новые кластеры:
Состав групп:
1
2
4
0,5
3
i2<i3
2
5
1,0
2
Номер кластера
Состав кластера
1
1, 2
2
3, 4
3
5
Результат: новая матрица наблюдений и состав каждой группы
20
21.
5.3.4. Метода корреляционных плеядАлгоритм метода
корреляционных плеяд:
1. В матрице коэффициентов межфакторной
корреляции находится наибольший по абсолютной
величине коэффициент корреляции (не считая
диагональных) – rkj.
2. Строится дендрит первого уровня между
факторами с номерами k и j с указанием над связью
абсолютного значения |rkj|.
xk
|rkj|
xj
3. Находим наибольшие по абсолютному значению
коэффициенты корреляции в столбцах k и j, исключая
rkj и из выбранных находим наибольший по
абсолютному значению – |rkm|.
4. Строится дендрит второго уровня между
факторами с номерами k и g с указанием над связью
абсолютного значения |rkg|.
xg
|rkg|
xk
|rkj|
xj
5. Находим признаки, наиболее тесно связанные с
двумя последними рассмотренными, и, повторяя
процедуру
выбора,
выбираем
из
двух
соответствующих коэффициентов корреляции
наибольший по абсолютной величине.
6. Продолжая построение, на каждом шаге
находим признак, наиболее тесно связанный с
одним из двух признаков, отобранных на
предыдущем этапе. Построение чертежа
завершим, когда в нем окажется т кружков (т –
число признаков).
7. Выбираем пороговую величину h и исключаем
из схемы связи, соответствующие меньшим, чем
h коэффициентам парной корреляции, например
по
значимости
коэффициента
парной
корреляции.
8. Разрываем все связи с коэффициентом
корреляции ниже критического при заданном
уровне значимости.
9. Для факторов внутри группы достаточно
определить линейные взаимосвязи.
21
22.
5.3.4. Метода корреляционных плеядМатрица межфакторной корреляции – Итерация 1
Матрица межфакторной корреляции – Итерация 3
0,8
x1
x5
x4
0,7
0,8
x1
Матрица межфакторной корреляции – Итерация 2
x5
0,54
x6
Матрица межфакторной корреляции – Итерация 4
x4
0,7
0,8
x1
x5
22
23.
5.3.4. Метода корреляционных плеядМатрица межфакторной корреляции – Итерация 4
Используем выражение критерия Стьюдента:
tфакт
r n 2
1 r 2
Выразим значение коэффициента корреляции:
r
x4
0,7
x1
0,8
0,6
x6
0,75
x5
x3
Примем количестве наблюдений равным 30.
Критическое значение t-статистики:
t(5%, 28)=1,17.
n 2 t2
Вычислим критическое значение коэффициента:
0,54
x2
t
r
1,17
30 2 1,17
2
0,21
Все факторы образуют один кластер.
Между факторами можно установить линейные
зависимости:
x4
x
5
x2
x
3
x1
f x1 1 ;
f x1 2 ;
f x6 3 ;
f x6 4 ;
f x6 5 .
23
24.
5.3.5. Метода k-средних или алгоритм ЛойдаАлгоритм метода k-средних:
1. Из исходного множества данных
случайным образом выбираются k записей,
которые будут служить начальными
центрами кластеров (центроидами или
эталонами).
Количество классов k
назначается исследователем.
Рис. Исходные данные и выбранные центроиды
2. Для каждой точки определяется
расстояние до центроида и выбирается
принадлежность к классу.
В качестве метрики чаще всего
используется расстояние Евклида.
Номер класса – это номер центроида
с минимальным расстоянием
до выбранной точки i:
24
25.
5.3.5. Метода k-средних или алгоритм Лойда3. Вычисляются внутригрупповая
дисперсия в каждом кластере:
1
D
kj
l
j
x μ .
kj
2
i 1
i
j
l – номер итерации, j – центроид класса j.
4. Вычисляются центры тяжести новых
кластеров, т.е. значение центроида в
новом кластере:
1
μj
kj
kj
5. Шаги 2, 3, 4 повторяются, пока не
будет найдена стабильная
конфигурация (то есть кластеры
перестанут изменяться) или число
итераций не превысит заданное
пользователем.
Особенности метода: результат
зависим от начального выбора
центроидов.
x .
i 1
i
Результаты кластеризации
Рис. Лучевая
диаграмма
Рис. Круги Эйлера
Рис. Дендрограмма 25
26.
5.3.5. Метода k-средних или алгоритм Лойдаа
в
б
Рис. Диалоговые окна для настройки
параметров кластеризации: а – выбор
процедура кластеризации; б –
определение исходных данных и
параметров; в – меню результатов
26
27.
5.3.5. Метода k-средних или алгоритм Лойдаа
б
в
Рис. Результаты кластеризации: а – расстояние Евклида между кластерами; б, в, г –
27
выборочные характеристики 1, 2 и 20 классов
г
28.
5.3.5. Метода k-средних или алгоритм Лойдаа
в
б
Рис. Результаты кластеризации: а – средние по классам; б – значение среднего в каждом
28
классе для одной переменной; в – состав групп; и – дисперсионный анализ групп
г
29.
Задания к практическому занятиюЗадание 1
Для исходных данных выполнить расчет матрицы коэффициентов сопоставимости по
факторам и наблюдениям, матрицы парной корреляции, матрицы расстояний (способ расчета
расстояния согласовать с ведущим преподавателем).
Задание 2
Выполнить кластеризацию факторов по методу корреляционных плеяд.
Задание 3
Выполнить кластеризацию наблюдений. Количество классов не должно быть менее 30.
Выбор процедуры кластеризации согласовать с ведущим преподавателем.
Задание 4
Оформить результат предварительной обработки данных в виде письменного отчета. В
отчете отобразить: исходные данные, матрицы мер сходства и их анализ, дендрит
кластеризации, состав групп, новую матрицу исходных данных.
29
30.
Контрольные вопросы1. Определите цели и задачи кластеризации.
2. Мера сходства, принципы расчета и построения матрицы коэффициентов.
3. Приведите классификацию мер сходства.
4. Коэффициенты подобия и порядок расчета.
5. Коэффициент корреляции: назначение, способы расчета и оценки значимости.
6. Показатели расстояния : назначение, способы расчета и оценки значимости.
7. Классификация процедур кластеризации и принцип их проведения.
8. Алгоритм процедура кластеризации по расстоянию.
9. Метод вроцлавской таксономии.
10. Метод корреляционных плеяд.
11. Метод k-средних.
12. Особенности реализации процедур кластеризации в пакете Statistica.
13. Дендрит и его назначение в процедурах кластеризации.
14. Основные результаты кластерного анализа.
30