






















 software
softwareSimilar presentations:
")









Распознавание текста на изображениях. Tesseract
1.
Распознавание текста наизображениях.
Tesseract.
2.
Использованные статьиДокументация Tesseract:
https://github.com/tesseract-ocr/docs
Вейвлет-преобразование:
http://www2.isye.gatech.edu/~brani/wp/kidsA.pdf
Приложение вейвлет-преобразования:
–
–
http://www.sciencedirect.com/science/article/pii/
S0262885605000107
http://link.springer.com/article/10.1007/s13042-011
-0049-5
3.
1985 – Hewlett-Packard, C, проприетарность
1996 – порт на Windows
1998 – переход от C к C++
2005 – открытый исходный код
2006 – Google
4.
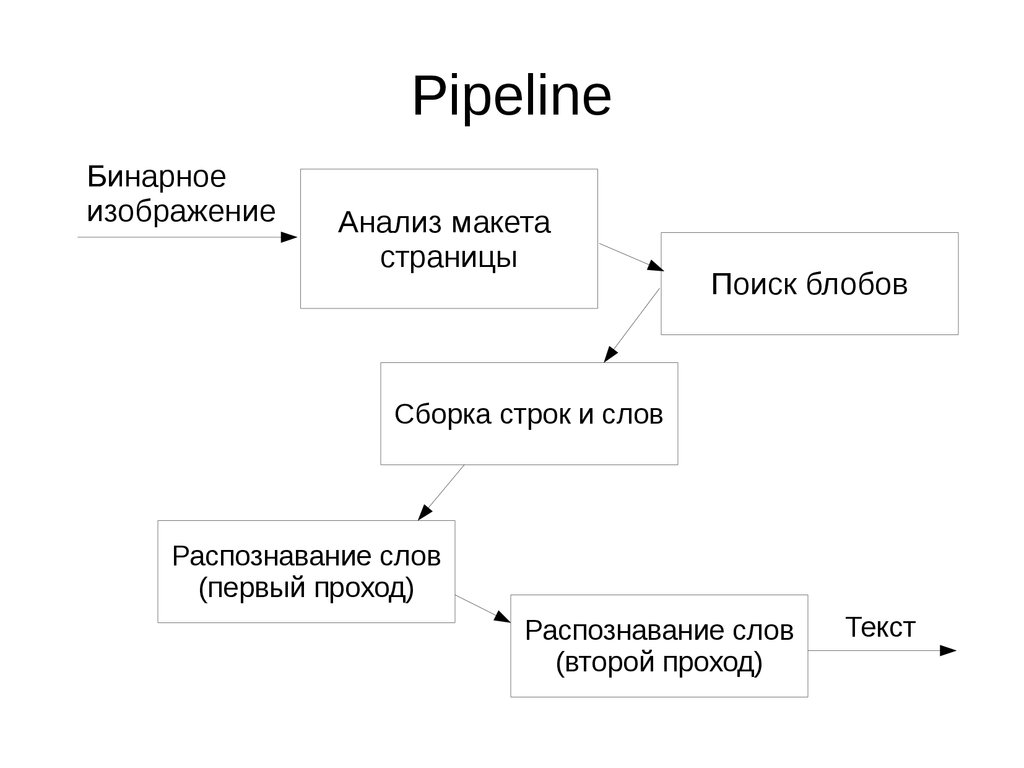
PipelineБинарное
изображение
Анализ макета
страницы
Поиск блобов
Сборка строк и слов
Распознавание слов
(первый проход)
Распознавание слов
(второй проход)
Текст
5.
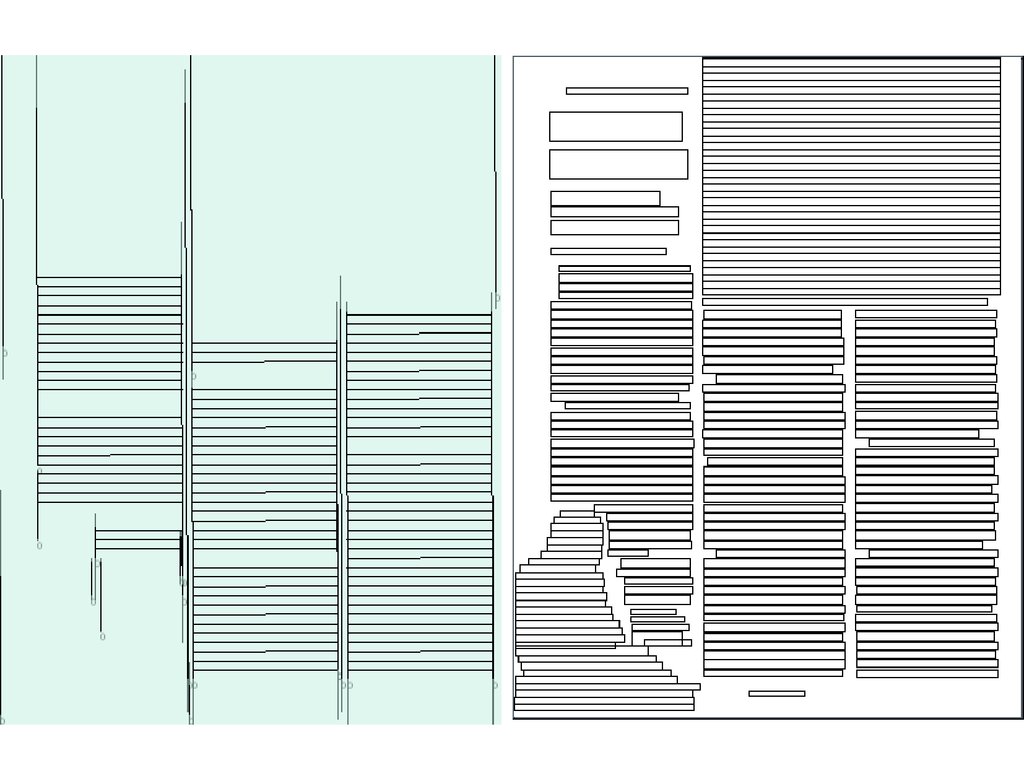
Анализ макета страницы6.
7.
8.
9.
10.
11.
Поиск блобов12.
Поиск строк13.
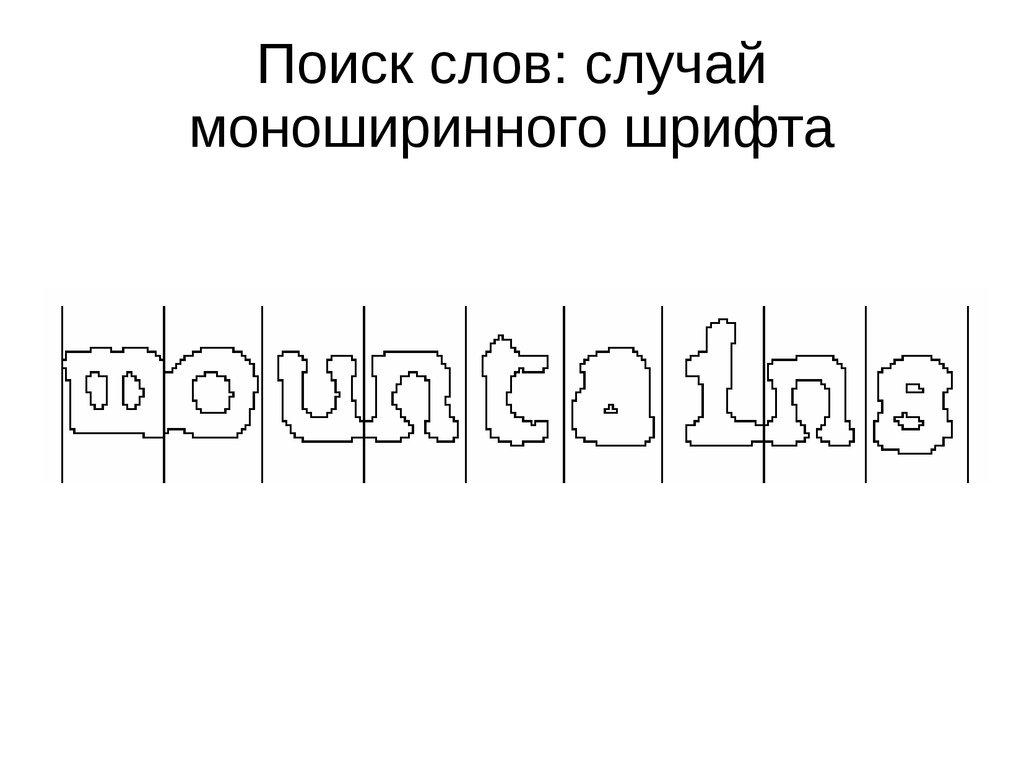
Поиск слов: случаймоноширинного шрифта
14.
Поиск слов: случайпропорционального шрифта
15.
Поиск слов: случайпропорционального шрифта
Лишний
пробел
Нет пробела
16.
Поиск слов: случайпропорционального шрифта
“Fuzzy”
space
17.
Разрезание и объединениесимволов
18.
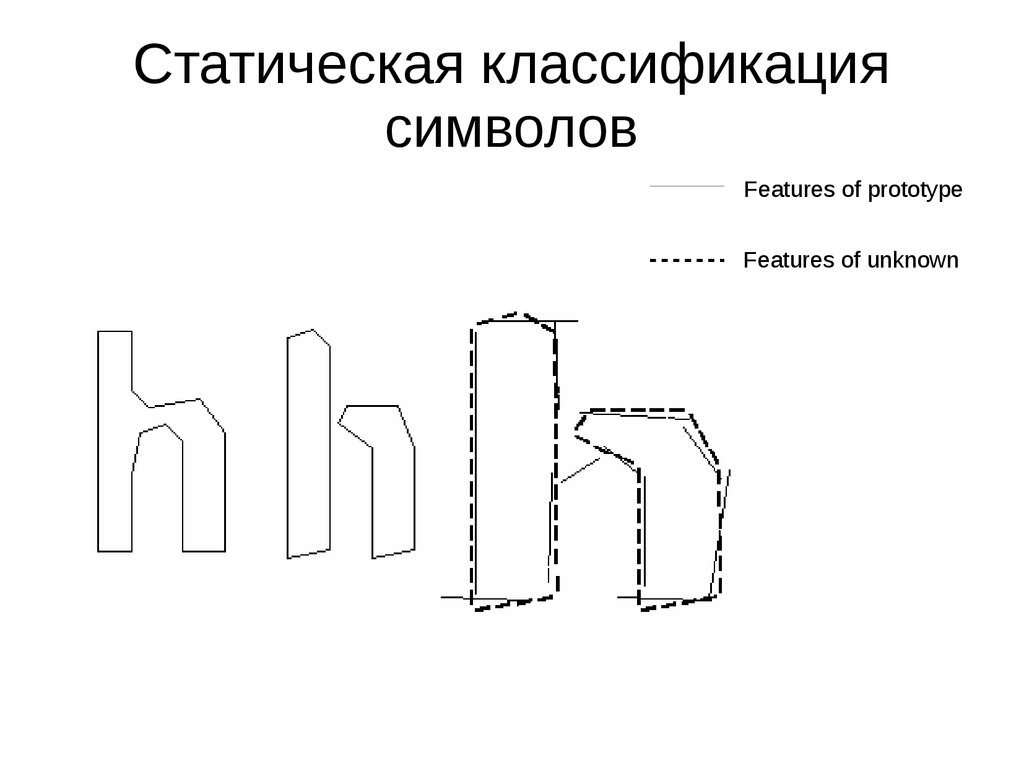
Статическая классификациясимволов
Features of prototype
Features of unknown
19.
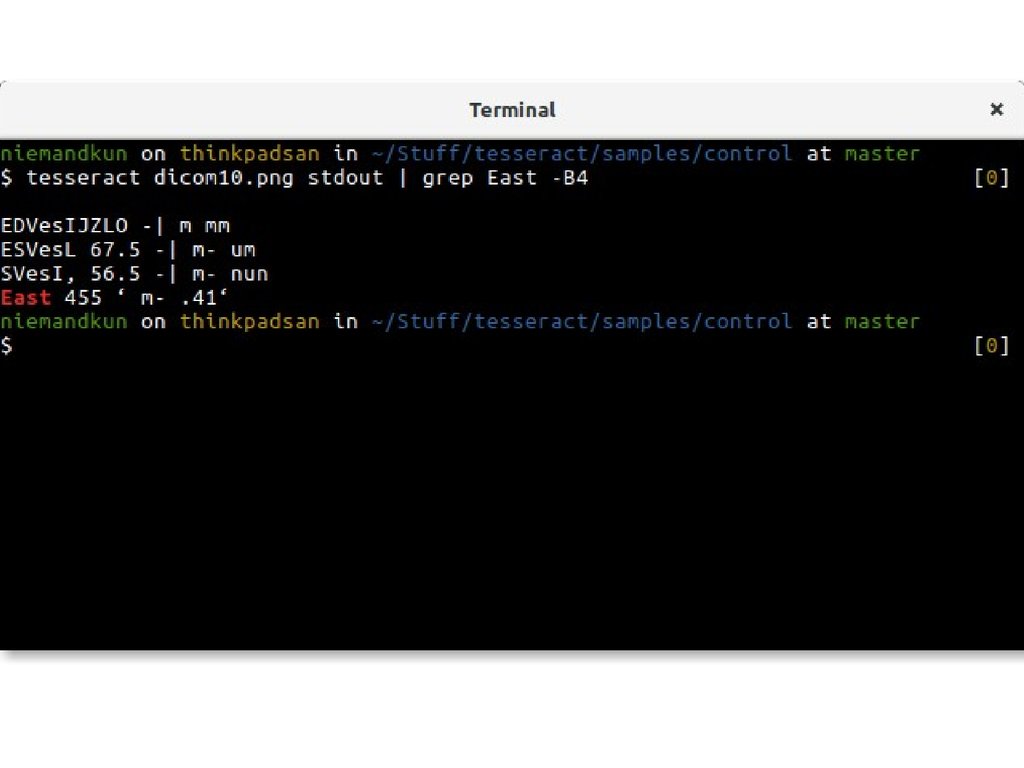
И что, это работает?20.
21.
22.
Как сделать, чтобы заработало?Текст упорядочен в один или несколько
столбцов
Нет посторонних изображений
Нет сильных искажений и шума
Высота символов >= 20 пикселей
Бинарное изображение на входе
(иначе тессеракт сам его бинаризует)
23.
Использованные пакетыTesseract для Python: pytesseract
Обработка изображений: scikit-image
Вейвлеты: PyWavelets
Нейронные сети: PyBrain
24.
25.
26.
27.
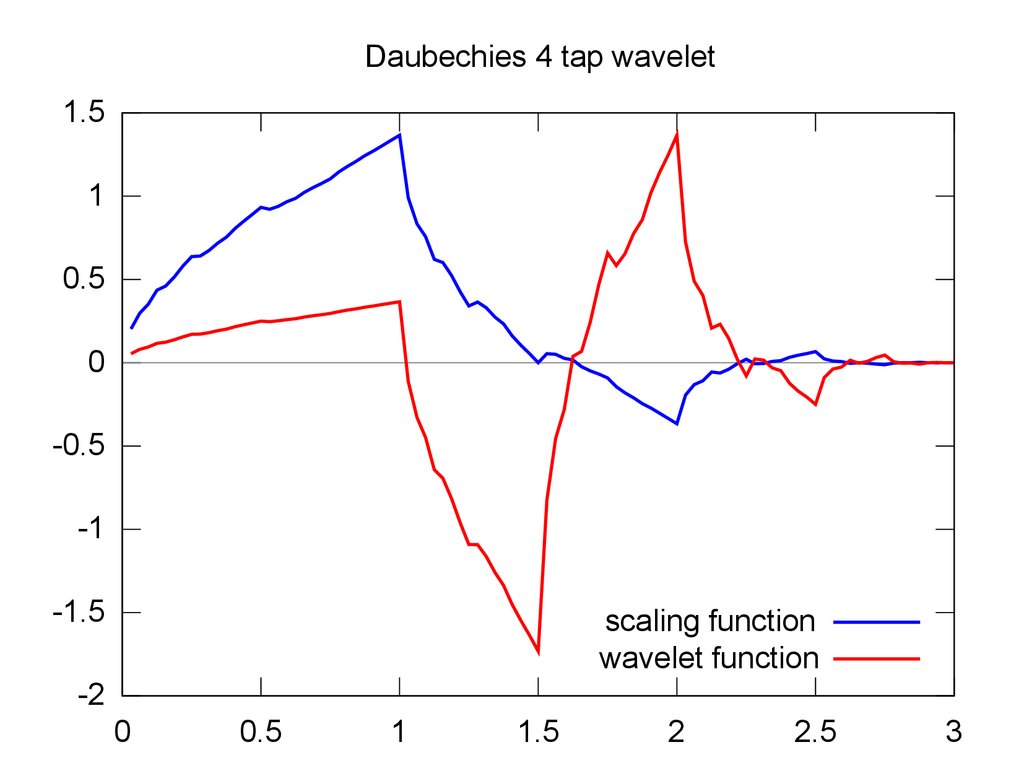
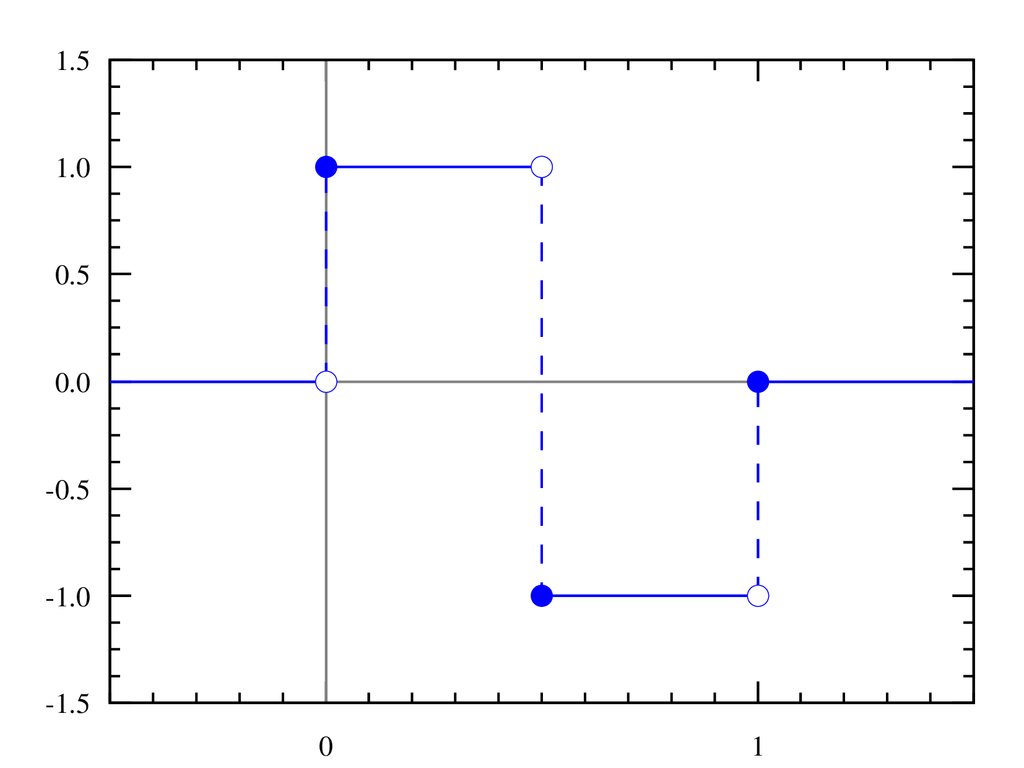
Daubechies 4 tap wavelet1.5
1
0.5
0
-0.5
-1
-1.5
scaling function
wavelet function
-2
0
0.5
1
1.5
2
2.5
3
28.
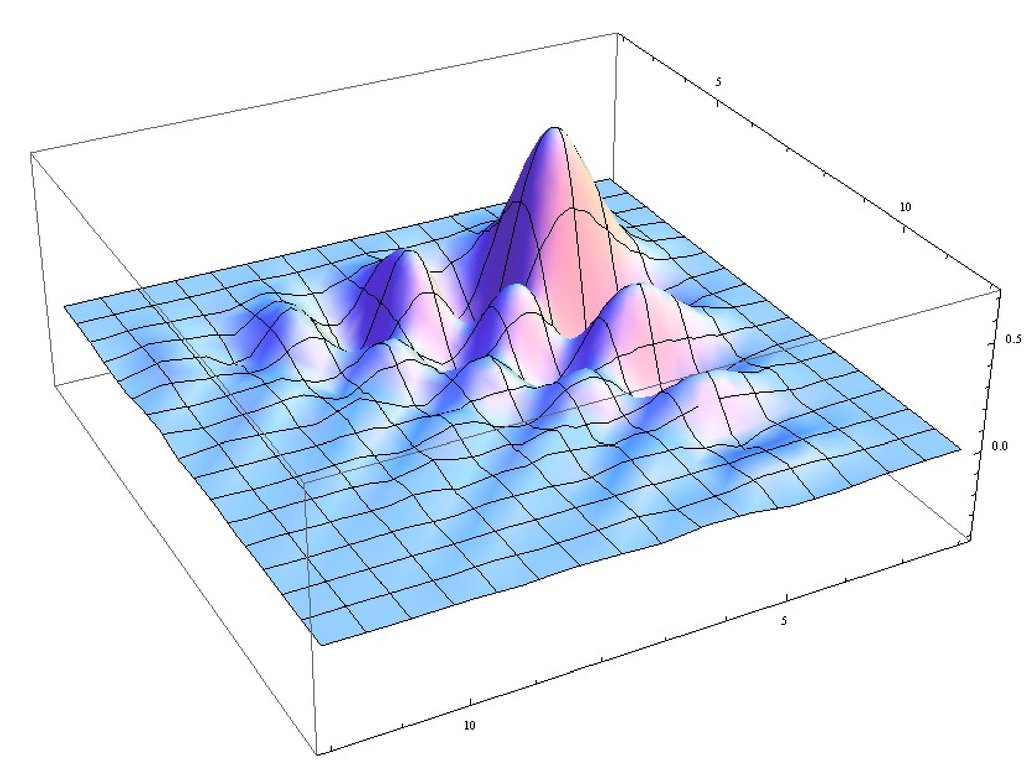
29.
1.51.0
0.5
0.0
0.5
1.0
1.5
0
1