



































")
![Фильтрация данных Задания [1/2]](https://cf2.ppt-online.org/files2/slide/f/FjkBtnOhsgfxlM8VpJuW3cAzQRDyY2Ie1PdKib/slide-38.jpg "Фильтрация данных Задания [1/2]")
![Фильтрация данных Задания [2/2]](https://cf2.ppt-online.org/files2/slide/f/FjkBtnOhsgfxlM8VpJuW3cAzQRDyY2Ie1PdKib/slide-39.jpg "Фильтрация данных Задания [2/2]")




")



















")
")
")









")
")














")
")
")







![Задания (INSERT) [1/2]](https://cf2.ppt-online.org/files2/slide/f/FjkBtnOhsgfxlM8VpJuW3cAzQRDyY2Ie1PdKib/slide-102.jpg "Задания (INSERT) [1/2]")
![Задания (INSERT) [2/2]](https://cf2.ppt-online.org/files2/slide/f/FjkBtnOhsgfxlM8VpJuW3cAzQRDyY2Ie1PdKib/slide-103.jpg "Задания (INSERT) [2/2]")
![Задания (DELETE) [1/1]](https://cf2.ppt-online.org/files2/slide/f/FjkBtnOhsgfxlM8VpJuW3cAzQRDyY2Ie1PdKib/slide-104.jpg "Задания (DELETE) [1/1]")
![Задания (UPDATE) [1/1]](https://cf2.ppt-online.org/files2/slide/f/FjkBtnOhsgfxlM8VpJuW3cAzQRDyY2Ie1PdKib/slide-105.jpg "Задания (UPDATE) [1/1]")

 database
databaseSimilar presentations:

")








Основы Transact-SQL
1. Основы Transact-SQL
Плешанков АндрейВедущий технический консультант
apleshankov@gmcs.ru
v1.2
rev.201707251355
2. Содержание
Введение3
1: Архитектура SQL Server
7
2: Типы данных
18
3: Инструкция SELECT
20
4: Фильтрация данных
30
5: Сортировка данных
41
6: Типы данных (продолжение)
45
7: Функции и выражения
51
8: Суммирование и группировка данных 68
9: Выбор данных из нескольких таблиц
77
10: Управление данными
92
2
3. ВВЕДЕНИЕ
SQL• История SQL
• DML, DDL, DCL
SQL EVERYWHERE
ВВЕДЕНИЕ
4. Введение | История SQL
SQL – Structured Query Language (язык структурированных запросов)Это стандартный язык, который был разработан для формирования запросов и
управления данными в системах управления реляционными базами данных (СУРБД)
СУРБД – система управления базой данных, основанная на реляционной модели
В начале 70-х годов прошлого века корпорация IBM разработала язык SEQUEL
(сокращение от Structured English QUEry Language) для своей СУРБД System R. Позже
название языка изменили с SEQUEL на SQL из-за споров по поводу торговой марки.
Сначала в 1986 г. появился стандарт ANSI языка SQL, а затем в 1987 г. и стандарт ISO.
Начиная с 1986 г. ANSI и ISO выпускали релизы стандарта языка каждые несколько лет.
До настоящего времени были выпущены следующие стандарты языка: SQL-86 (1986),
SQL-89 (1989), SQL-92 (1992), SQL:1999 (1999), SQL:2003 (2003), SQL:2006 (2006),
SQL:2008 (2008), SQL:2011 (2011).
4
5. Введение | DML, DDL, DCL
У языка SQL есть несколько категорий инструкций:Data Manipulation Language (DML, язык манипулирования данными)
Data Definition Language (DDL, язык описания данных)
Data Control Language (DCL, язык управления данными).
Язык DML позволяет запрашивать и изменять
данные и включает такие команды,
как SELECT, INSERT, UPDATE, DELETE и MERGE.
DDL имеет дело с определениями
и включает такие команды, как
CREATE, ALTER и DROP.
Язык DCL связан с правами доступа или полномочиями и включает такие команды, как
GRANT и REVOKE. Эта книга посвящена DML.
5
6. 1: Архитектура SQL Server
Экземпляры
Базы данных
Схемы и объекты
Целостность данных
1: Архитектура SQL Server
7. Экземпляры
Экземпляр SQL Server — это установка службыбазы данных SQL Server. На одном компьютере
можно установить несколько экземпляров SQL
Server.
Один из экземпляров, установленных на
компьютере, может быть задан как экземпляр по
умолчанию, а остальные должны быть
именованными экземплярами.
7
8. Базы данных
База данных – можно представить как контейнер для хранения объектов, таких кактаблицы, представления, хранимые процедуры и т.п.
master – хранит все данные системного уровня для экземпляра SQL Server.
msdb - используется агентом SQL Server для планирования предупреждений и
задач.
model - используется в качестве шаблона
для всех баз данных, создаваемых в
экземпляре SQL Server.
tempdb - рабочее пространство для
временных объектов или взаимодействия
результирующих наборов.
8
9. Базы данных
Физическая структура базы данных9
10. Схемы и объекты
Схема - представляет собой именованный контейнер для объектов базы данных,позволяющий группировать объекты по отдельным пространствам
имен. Например, образец базы данных AdventureWorks содержит схемы для
Production, Sales и HumanResources.
Четырехкомпонентный синтаксис ссылок на объекты указывает имя схемы:
Server.Database.DatabaseSchema.DatabaseObject
10
11. Схемы и объекты
Таблицы (Tables)Все данные в SQL содержатся в объектах, называемых
таблицами. Таблицы представляют собой совокупность
каких-либо сведений об объектах, явлениях,
процессах реального мира. Никакие
другие объекты не хранят данные, но они могут
обращаться к данным в таблице. Таблицы содержат:
Cтроки - каждая строка (или запись) представляет
собой совокупность атрибутов (свойств) конкретного
экземпляра объекта ;
Столбцы - каждый столбец (поле) представляет собой
атрибут или совокупность атрибутов. Поле строки
является минимальным элементом таблицы. Каждый
столбец в таблице имеет определенное имя, тип
данных и размер.
11
12. Схемы и объекты
Представления (Views)Представлениями называют виртуальные таблицы,
содержимое которых определяется запросом.
Подобно реальным таблицам, представления
содержат именованные столбцы и строки с данными.
Для конечных пользователей представление
выглядит как таблица, но в действительности оно не
содержит данных, а лишь представляет данные,
расположенные в одной или нескольких таблицах.
Информация, которую видит пользователь через
представление, не сохраняется в базе данных как
самостоятельный объект.
12
13. Схемы и объекты
Хранимые процедуры (Stored procedures)Хранимые процедуры представляют собой группу команд
SQL, объединенных в один модуль. Такая группа команд
компилируется и выполняется как единое целое.
Функции (Functions)
Функции в языках программирования – это конструкции,
содержащие часто исполняемый код. Функция выполняет
какие-либо действия над данными и возвращает
некоторое значение.
Триггеры (Triggers)
Триггерами называется специальный класс хранимых
процедур, автоматически запускаемых при добавлении,
изменении или удалении данных из таблицы.
13
14. Схемы и объекты
Индексы (Indexes)Индекс – структура, связанная с таблицей или представлением и предназначенная
для ускорения поиска информации в них. Индекс определяется для одного или
нескольких столбцов, называемых индексированными столбцами. Он содержит
отсортированные значения индексированного столбца или столбцов со ссылками
на соответствующую строку исходной таблицы или представления. Повышение
производительности достигается за счет сортировки данных. Использование
индексов может существенно повысить производительность поиска, однако для
хранения индексов необходимо дополнительное пространство в базе данных.
14
15. Целостность данных
Ограничения целостности – механизм, обеспечивающий автоматический контрольсоответствия данных установленным условиям (или ограничениям)
Ограничение PRIMARY KEY – первичный ключ, обеспечивает уникальность строк и
запрещает значения NULL.
- В таблице возможно наличие только одного ограничения по первичному ключу.
- Все столбцы с ограничением PRIMARY KEY должны иметь признак NOT NULL.
Ограничение UNIQUE – так же обеспечивает уникальность строк, давая
возможность реализовать концепцию альтернативных ключей. Позволяет
определить несколько ограничений в одной таблице.
15
16. Целостность данных
Ограничение FOREIGN KEY – внешний ключ, обеспечивает ссылочную целостность.Ограничение CHECK – позволяет определить логическое выражение (предикат),
которому должна удовлетворять строка для того, чтобы быть включенной в таблицу
или измененной.
Ограничение DEFAULT – связано с конкретным атрибутом, представляет собой
выражение применяемое по умолчанию.
16
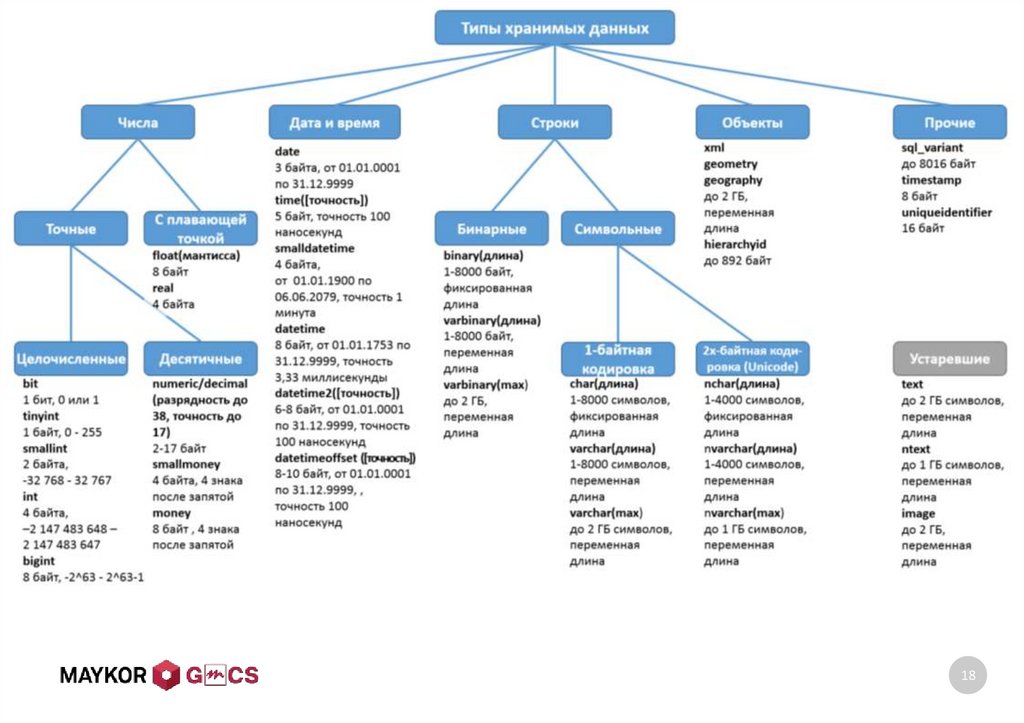
17. 2: ТИПЫ ДАННЫХ
• Обзор типов данных2: ТИПЫ ДАННЫХ
18.
1819. 3: Инструкция SELECT
Логический порядок обработки инструкций
Литералы
Получение данных
Select-list
Удаление повторяющихся строк
Ограничение возвращаемого
набора данных
• Задания
3: Инструкция SELECT
20. Логический порядок обработки инструкции
Порядок обработки:1. FROM
2. WHERE
3. GROUP BY
4. HAVING
5. SELECT
6. ORDER BY
Правильная запись запроса:
Логическая последовательность обработки:
20
21. Инструкция SELECT
В отличие от всех других ключевых слов, SELECT является единственнымоператором извлечения информации из баз данных.
SELECT – отвечает на любой вопрос типа: кто, что, где, когда, что если и сколько.
21
22. Инструкция SELECT Литералы
Литерал (англ. literal ) — запись в исходном коде компьютерной программы,представляющая собой фиксированное значение. Литералами также называют
представление значения некоторого типа данных.
22
23. Инструкция SELECT Получение данных из таблиц
Для получения данных из таблиц и представлений используется ключевое слово FROM23
24. Инструкция SELECT Select-list
Для получения всех полей таблицы можно использовать символ * (астериск, звезда)Допускается смешивание литералов и название полей в одном выражении:
24
25. Инструкция SELECT Select-list
Для именования полей допускается использовать – двойные кавычки, одинарныекавычки, квадратные скобки:
Ключевое слово AS опционально и может быть опущено.
25
26. Удаление повторяющихся строк DISTINCT
Структура реляционных баз данных такова, что столбцы очень часто содержатодинаковые значения в разных строках. Поэтому вполне естественно желать от
произвольного запроса такого результата, в котором каждая строка была бы
уникальной. Для устранения этого неудобства служит ключевое слово DISTINCT.
Синтаксис:
SELECT [ALL | DISTINCT] <column1>,<column2>
FROM <table>
ALL – значение по умолчанию, выводит все наборы строк
DISTINCT – выводит уникальный набор строк
26
27. Ограничение возвращаемого набора данных
При необходимости ограничить результирующий набор данных используйтеключевое слово TOP.
Синтаксис:
SELECT [ TOP (expression) [PERCENT] [WITH TIES] ]
expression – числовое выражение, которое задает количество возвращаемых строк
PERCENT – ключевое слово, указывает, что значение expression указано в процентах
WITH TIES – ключевое слово, указывает, что будут возвращены дополнительные
строки, у которых повторяется набор отсортированный в ORDER BY.
Ключевое слово TOP допустимо использовать с предложениями SELECT, INSERT,
DELETE, UPDATE
27
28. Инструкция SELECT Задания
1.Напишите инструкцию SELECT, в которой перечислен список клиентов вместе с их
идентификационными номерами (CustomerID). Включают StoreID и AccountNumber
из таблицы Sales.Customer
2.
Напишите инструкцию SELECT, в которой содержится список имен (Name), номер
продукта (ProductNumber) и цвет (Color) каждого продукта из таблицы
Production.Product
Напишите инструкцию SELECT, в которой содержится список идентификаторов клиентов
(CustomerID) и идентификаторы заказов на продажу (SalesOrderId) из таблицы
Sales.SalesOrderHeader
Ответьте на вопрос: Почему вы должны указывать имена колонок, а не использовать
символ * (звездочка) при написании запроса?
Напишите запрос используя таблицу Sales.SalesOrderDetail для отображения списка
заказанных товаров (ProductId) удалив повторения.
Выведите первые 9 процентов записей из таблицы Production.Product.
3.
4.
5.
6.
28
29. 4: ФИЛЬТРАЦИЯ ДАННЫХ
Предложение WHERE
Операторы сравнения
Операторы BETWEEN, LIKE, IN
Комбинирование условий
Работа с Неизвестным
Задания
4: ФИЛЬТРАЦИЯ ДАННЫХ
30. Предложение WHERE Операторы сравнения
Для фильтрации возвращаемого набора данных добавляется не обязательноепредложение WHERE. Оператор WHERE содержит выражения – предикаты, которые
возвращает TRUE, FALSE или Неизвестно (NULL):
SELECT <column1>,<column2>
FROM <schema>.<table>
WHERE <column> = <value>;
>
<
=
!<
Операторы сравнения:
(больше)
>= (больше или равно)
(меньше)
<= (меньше или равно)
(равно)
<> (не равно) или !=
(не меньше чем)
!> (не больше чем)
30
31. Оператор BETWEEN и NOT BETWEEN
Оператор BETWEENПрименяют для того, чтобы определить, находится или нет значение в пределах
выбранного диапазона.
Синтаксис:
SELECT <column1>,<column2>
FROM <schema>.<table>
WHERE <column> [ NOT ] BETWEEN <low_value> AND <high_value>;
-
BETWEEN работает со строками символов, числами и значениями даты и
времени
Эквивалентная запись:
WHERE column >= low_value AND column <= high_value;
Оператор BETWEEN можно инвертировать оператором NOT
31
32. Сравнение по шаблону оператором LIKE
Оператор LIKEСинтаксис:
SELECT <column1>,<column2>
FROM <schema>.<table>
WHERE match_expression [ NOT ] LIKE pattern [ ESCAPE escape_character ] ;
match_expression – любое текстовый столбец или текстовое выражение
pattern – текстовая строка представляющая собой образец, задающий правило
поиска (иногда называют Шаблоном, Маской)
escape_character – cимвол, помещаемый перед символом-шаблоном, чтобы
символ-шаблон рассматривался как обычный символ, а не как шаблон.
- Оператор LIKE можно инвертировать оператором NOT
32
33. Сравнение по шаблону оператором LIKE
СимволDescription
шабло
н
%
Любая строка, содержащая ноль или более
символов.
_
Любой одиночный символ.
(подче
ркиван
ие)
Пример Результат
‘A%’
‘%s’
‘%in%’
‘Anonymous’, ‘AC/DC’
‘DMBSes’, ‘Victoria Walls’
‘in’, ‘inch’, ‘Pine’, ‘linchpin’
'_ _ _ _‘ 'АБВГ', 'Я ем‘, 'Jack‘, ‘1234’
'Qua_ _' 'Quack', 'Quaff‘, 'Quake'
[]
Любой одиночный символ, содержащийся в ‘De[a-c]’ ‘Dea’, ‘Deb’, ‘Dec’
диапазоне ([a-f]) или наборе ([abcdef]).
‘[DW]ell’ ‘Dell’, ‘Well’
[^]
Любой одиночный символ, не
содержащийся в диапазоне ([^a-f]) или
наборе ([^abcdef]).
‘H[^eo]ll ‘Hall’, ‘Hill’, но не ‘Hell’, ‘Holl’
33
34. Оператор IN
Оператор INЧтобы определить, соответствует ли определенное значение какому-либо значению
из произвольного списка, применяют оператор IN.
Синтаксис:
SELECT <column1>,<column2>
FROM <schema>.<table>
WHERE match_expression [ NOT ] IN (<value1>, <value2>, … <valueN>);
-
работает со строками символов, числами и значениями даты и времени;
представляет собой одно или несколько неупорядоченных значений,
разделенных запятыми и заключенных в круглые скобки;
оператор IN можно инвертировать оператором NOT;
34
35. Комбинирование условий AND OR NOT
Оператор AND- объединяет два условия и принимает значение true (истина) тогда и только
тогда, когда каждое из этих условий принимает значение true;
- с помощью нужного количества операторов AND можно объединить любое
количество условий, и для того, чтобы произвольная строка была включена в
итоговый результат, каждое из этих условий должно принять значение true;
AND
True
False
Unknown
True
True
False
Unknown
False
False
False
Flase
Unknown
Unknown
False
Unknown
35
36. Комбинирование условий AND OR NOT
Оператор OR- объединяет два условия и принимает значение true (истина) тогда и только
тогда, когда хотя бы одно из этих условий принимает значение true;
- с помощью соответствующего количества операторов OR можно объединить
любое количество условий так, чтобы результирующее условие приняло
значение true тогда и только тогда, когда хотя бы одно составляющее условие
приняло значение true;
OR
True
False
Unknown
True
True
True
True
False
True
False
Unknown
Unknown
True
Unknown
Unknown
36
37. Комбинирование условий AND OR NOT
Оператор NOT- в отличие от операторов AND и OR, не связывает двух условий, а инвертирует
одно-единственное условие;
- в сравнениях следует ставить оператор NOT перед именем столбца или
выражением, значение которого предполагается инвертировать, но не перед
соответствующим оператором (например, WHERE NOT state = 'CA'
скомпоновано правильно, а предложение WHERE state NOT = 'CA' – неверно,
хотя и читается «естественнее»);
Условие
True
False
Unknown
Инверсия
False
True
Unknown
37
38. Работа с Неизвестным (Unknown)
NULL означает отсутствие, неизвестность информации. Значение NULL не являетсязначением в полном смысле слова: по определению оно означает отсутствие
значения и не принадлежит ни одному типу данных. Поэтому NULL не равно ни
логическому значению FALSE, ни пустой строке, ни нулю. При сравнении NULL с
любым значением будет получен результат NULL, а не FALSE и не 0. Более того, NULL
не равно NULL!
Оператор IS NULL
- работает со столбцами любых типов данных;
- его можно инвертировать в оператор IS NOT NULL;
- можно объединять условия IS NULL с другими условиями операторами AND и
OR.
38
39. Фильтрация данных Задания [1/2]
1.2.
3.
4.
5.
6.
7.
Напишите запрос с использование предложения WHERE, который выберет всех
сотрудников из таблицы HumanResources.Employee с должностями «Research and
Development Manager» или начинающиеся с «Vice». Выведите поля BusinessEntityID,
LoginID и JobTitle.
Выберите из таблицы Person.Person все записи, где MiddleName соответствует букве J.
Вывести BusinessEntityID, FirstName, MiddleName, LastName.
Выберите из таблицы Production.ProductCostHistory записи, которые были изменены 17
июня 2007 года.
Изменить запрос по заданию №1 таким образом, чтобы отобразить сотрудников
должности которых не являются «Research and Development Manager» и не начинаются с
«Vice»
Выберите все продукты из таблицы Production.Product названия которых начинаются со
слова «Chain» или содержат слово «helmet»
Выберите заказы из таблицы Sales.SalesOrderHeader оформленные в сентябре 2005 года
(OrderDate) и полная стоимость (total due) которых превышает 1000$.
Измените запрос №6 таким образом, чтобы дата заказа была с 1 по 3 сентября 2005
года. Решите данную задачу тремя способами.
39
40. Фильтрация данных Задания [2/2]
8. Измените один из запросов №7 оставив только те записи, у которых идентификаторзаказчика (SalesPersonID) соответствует 279 или идентификатор территории (TerritoryID)
соответствует 4 или 6.
9. Выберите продукты из таблицы Production.Product которые имеют цвет отличный от
голубого (blue), включите в выборку продукты у которых не указан цвет.
10. Выберите продукты из таблицы Production.Product у которых заполнено хотя бы одно из
полей Style, Size или Color.
40
41. 5: СОРТИРОВКА ДАННЫХ
• Предложение ORDER BY• Ограничение возвращаемого
набора данных
5: СОРТИРОВКА ДАННЫХ
42. Предложение ORDER BY
Синтаксис:SELECT <column1>, <column2>
FROM <schema>.<table>
ORDER BY <column1> [<sort direction>], <column2> [<sort direction>]
<sort direction> - направление сортировки, указывается для каждой колонки,
принимает значения ASC и DESC
ASC (по умолчанию) [ascend] – сортировка по возрастанию
DESC [descend] – сортировка по убыванию
В качестве выражения сортировки допускается использовать:
- Имя столбца
- Псевдоним (алиас) столбца
- Положительное число, указывающее на позицию сортируемой колонки в Selectlist
42
43. Ограничение возвращаемого набора данных
Синтаксис:ORDER BY <column1> [<sort direction>], <column2> [<sort direction>]
OFFSET n ROWS
[ FETCH NEXT n ROWS ONLY ] ;
OFFSET n ROWS – ограничивает возвращаемый набор данных, пропуская n записей
сначала
FETCH NEXT n ROWS ONLY – ограничивает набор данных, оставляя только первые n
записей
43
44. Сортировка данных Задания
1.2.
3.
Выберите все записи из таблицы Person.Person отсортировав по полям
LastName, FirstName, и MiddleName в порядке убывания каждого поля.
Измените запрос в задании №1 таким образом, чтобы отобразить только 10
записей начиная с 20.
Напишите запрос, который выведет список победителей акции, проведенной в
магазине. По условиям акции победителями считаются те покупатели, которые
сделали заказ во втором полугодии 2006 года (OrderDate), при этом сумма
покупки (TotalDue) должна быть от 300 до 500 долларов. В акции не участвуют
заказы которые были сделаны в другой валюте (заполнено поле
CurrencyRateID). Под акцию выделено 10 денежных призов, для тех, кто сделал
самую крупную покупку(TotalDue), в случае если участников больше 10, то
учтите и их. Используйте таблицу Sales.SalesOrderHeader, результат должен
содержать поля SalesOrderID, OrderDate, CustomerID, TotalDue.
44
45. 6: ТИПЫ ДАННЫХ (продолжение)
• Функции преобразованиятипов данных
• Таблица преобразования
типов данных
• Приоритет типов данных
• Усечение и округление
результатов
• Стили даты и времени
6: ТИПЫ ДАННЫХ
(продолжение)
46. Функции преобразования типов данных
В реализациях языка SQL может быть выполнено неявное преобразование типов.Так, например, в SQL Server при сравнении или комбинировании значений типов
smallint и int, данные типа smallint неявно преобразуются к типу int.
Для явного преобразования типов в SQL Server доступно две
функции CAST и CONVERT
Синтаксис:
CAST ( expression AS data_type [ ( length ) ] )
CONVERT ( data_type [ ( length ) ] , expression [ , style ] )
expression – любое допустимое выражение
data_type – целевой тип данных
length – целое число, обозначающее длину целевого типа данных, умолчание – 30
style – целое число, определяющее, как функция CONVERT преобразует выражение
46
47.
4748. Приоритет типов данных
Если оператор связывает два выражения различных типов данных, то по правиламприоритета типов данных определяется, какой тип данных имеет меньший
приоритет и будет преобразован в тип данных с большим приоритетом. Если
неявное преобразование не поддерживается, возвращается ошибка. Если оба
операнда выражения имеют одинаковый тип данных, результат операции будет
иметь тот же тип данных.
Приоритет
1
2
3
4
5
6
7
8
9
10
Тип данных
определяемые пользователем типы
данных (высший приоритет)
sql_varian t
xml
datetimeoffset
datetime2
datetime
smalldatetime
date
time
float
Приоритет Тип данных Приоритет
11
12
13
14
15
16
17
18
19
20
real
decimal
money
smallmoney
bigint
int
smallint
tinyint
bit
ntext
21
22
23
24
25
26
27
28
29
30
Тип данных
text
image
timestamp
uniqueidentifier
nvarchar (включая nvarchar(max))
nchar
varchar (включая varchar(max))
char
varbinary (включая varbinary(max))
binary (низший приоритет)
48
49. Усечение и округление результатов
При преобразовании символьных или двоичных выражений (char, nchar, nvarchar,varchar, binary или varbinary) к выражению другого типа данных данные могут быть
усечены, отображаться только частично или вызывать ошибку, так как результат
слишком мал для отображения. Результаты преобразований в char, varchar, nchar,
nvarchar, binary и varbinary усекаются всегда, за исключением случаев,
перечисленных в таблице ниже.
Из типа данных
int, smallint или tinyint
money, smallmoney, numeric,
decimal, float или real
В тип данных
Результат
char
varchar
nchar
nvarchar
char
varchar
*
*
Ошибка
Ошибка
Ошибка
Ошибка
nchar
Ошибка
nvarchar
Ошибка
49
50. Стили даты и времени
5051. 7: ФУНКЦИИ И ВЫРАЖЕНИЯ
Соединение строк
Обработка Неизвестных значений
Математические операции
Строковые функции
Функции даты
Математические функции
Системные функции
Задания
7: ФУНКЦИИ И ВЫРАЖЕНИЯ
52. Соединение строк
Соединение (конкатенация) строкОператор «+» сложение позволяет соединять строки.
Синтаксис:
<строка или колонка таблицы> + <строка или колонка таблицы >
Соединение (конкатенация) строк с NULL
Внимание! При соединении любых значений с NULL всегда возвращается NULL.
CONCAT – возвращает строку которая является результатом соединения двух и
более строк. Функция CONCAT самостоятельно обрабатывает значения NULL.
Синтаксис:
CONCAT ( string_value1, string_value2 [, string_valueN ] )
52
53. Обработка Неизвестных значений
В SQL Server реализовано две функции позволяющие заменить NULL значения.ISNULL – заменяет значение NULL указанным значением.
Синтаксис:
ISNULL(<value>, <replacement>)
COALESCE – возвращает первое выражение из списка аргументов, не равное NULL.
Синтаксис:
COALESCE(<value1>, <value2>,..., <valueN>)
NULLIF – Возвращает NULL если переданные выражения равны.
Синтаксис:
NULLIF ( expression , expression )
53
54. Математические операции
Вы можете использовать математические операторы для выполнения простыхвычислений.
Арифметические операторы:
+ сложение
expression + expression
- вычитание
expression - expression
* умножение
expression * expression
/ деление
expression / expression
% остаток от деления
expression % expression
54
55. Строковые функции
RTRIM и LTRIM – удаляют пробелы справа (RTRIM) или слева (LTRIM)Синтаксис:
LTRIM (expression)
RTRIM (expression)
expression – строковое выражение
LEFT и RIGHT – возвращают указанное количество символов с левой или правой
стороны строки соответственно.
Синтаксис:
LEFT (expression, length)
RIGHT (expression, length)
expression – строковое выражение
length – количество возвращаемых символов
55
56. Строковые функции
LEN и DATALENGTH – применяются для получения количества символов в строках(LEN) и для получения размера строки в байтах (DATALENGTH)
Синтаксис:
LEN (expression)
DATALENGTH (expression)
expression – строковое выражение
CHARINDEX – ищет в выражении другое выражение и возвращает его начальную
позицию, если оно найдено.
Синтаксис:
CHARINDEX ( expressionToFind ,expressionToSearch [ , start_location ] )
expressionToFind - последовательность символов, которую надо найти.
expressionToSearch - строка, в которой производится поиск
start_location - целое число, определяющее позицию, с которой начинается поиск
56
57. Строковые функции
SUBSTRING – возвращает часть символьного, двоичного, текстовогоСинтаксис:
SUBSTRING ( expression, start , length )
expression – строковое выражение
start – начальная позиция возвращаемых символов
length – количество возвращаемых символов
CHOOSE – возвращает элемент по указанному индексу из списка значений
Синтаксис:
CHOOSE ( index, val_1, val_2 [, val_n ] )
index – целочисленное выражение, которое представляет отсчитываемый от
единицы индекс в списке элементов, следующих за ним
val_1 … val_n – список значений любого типа данных с разделителями-запятыми
57
58. Строковые функции
UPPER и LOWER – возвращают символьные выражение, в котором символыпреобразованы в символы верхнего или нижнего регистра соотвественно
Синтаксис:
UPPER ( character_expression )
LOWER ( character_expression )
character_expression – строковое выражение
REPLACE – заменяет все вхождения указанного строкового значения другим
строковым значением.
Синтаксис:
REPLACE ( string_expression , string_pattern , string_replacement )
string_expression – строковое выражение, в котором выполняется поиск.
string_pattern – подстрока для поиска
string_replacement – Строка замещения
58
59. Функции даты
GETDATE – возвращает текущую системную временную метку базы данных в видезначения datetime без смещения часового пояса базы данных.
SYSDATETIME – возвращает значение типа datetime2(7), которое содержит дату и
время компьютера, на котором запущен экземпляр SQL Server.
Синтаксис:
GETDATE ( )
SYSDATETIME ( )
SYSDATETIME имеет большую точность в долях секунды, чем GETDATE.
59
60. Функции даты
DATEADD – возвращает дату, полученную как сумму исходной даты date иинтервала number (целое число со знаком), добавленного к заданному компоненту
datepart даты date
Синтаксис: DATEADD (datepart , number , date )
DATEDIFF – возвращает количество границ даты и времени, пересекающихся у двух
указанных дат
Синтаксис: DATEDIFF (datepart , startdate , enddate)
DATENAME – возвращает символьную строку, содержащую определенную часть
указанной даты
Синтаксис: DATENAME (datepart , date)
DATEPART – возвращает целое число, представляющее определенную часть
указанной даты
Синтаксис: DATEPART (datepart , date)
DAY, MONTH, и YEAR - являются частными случаями функции DATEPART и
возвращают День, Месяц и Год соответственно
60
61. Функции даты
Допустимые значения параметра datepart и их сокращенияdatepart
Сокращения
year
yy, yyyy
quarter
qq, q
month
mm, m
dayofyear
dy, y
day
dd, d
week
wk, ww
weekday
dw
hour
hh
minute
mi, n
second
ss, s
millisecond
ms
Обозначение
Год
Квартал
Месяц
День года
День
Неделя
День недели
Час
Минута
Секунда
Миллисекунда
61
62. Математические функции
ABS – возвращает абсолютное (положительное) значение указанного выраженияСинтаксис: ABS ( numeric_expression )
POWER – вычисляет значение указанного выражения в степени y
Синтаксис: POWER ( numeric_expression, y )
SQUARE – возвращает квадрат указанного числа с плавающей точкой.
Синтаксис: SQUARE ( float_expression )
SQRT – возвращает квадратный корень указанного числа с плавающей точкой.
Синтаксис: SQRT ( float_expression )
ROUND – возвращает числовое значение, округленное до указанной длины или
точности
Синтаксис: ROUND (numeric_expression, length [, function ] )
numeric_expression – округляемое числовое выражение
length – точность округления, положительное значение указывает, что
округляется десятичная часть, отрицательные – слева от точки
function – 0 – округление, любое число отличное от нуля – усечение значения.
62
63. Системные функции
Выражение CASEВыражение CASE имеет два формата:
- простое выражение CASE для определения результата сравнивает выражение с
набором простых выражений;
- поисковое выражение CASE для определения результата вычисляет набор
логических выражений.
Оба формата поддерживают дополнительный аргумент ELSE.
Выражение CASE может использоваться в любой инструкции или предложении,
которые допускают допустимые выражения.
Синтаксис простого CASE:
CASE <test expression>
WHEN <comparison expression1> THEN <return value1>
WHEN <comparison expression2> THEN <return value2>
[ELSE <value3>] END
63
64. Системные функции
Выражение CASEСинтаксис поискового CASE:
CASE WHEN <test expression1> THEN <value1>
WHEN <test expression2> THEN <value2>
[ELSE <value3>] END
64
65. ФУНКЦИИ И ВЫРАЖЕНИЯ Задания (1)
1.2.
3.
4.
5.
6.
Вывести список адресов из таблицы Person.Address в формате «AddressLine1
(City PostalCode)»
Из таблицы Production.Product выбрать продукты в названии которых (Name)
встречается слово «Road» (любая позиция). Вывести Код продукта (ProductId),
Цвет (Color) заменив неопределенные значения на «No color», Название (Name)
Изменить запрос №2 добавив поле Описание (Description) в формате «Name:
Color», для не указанных цветов вывести «Name».
Вывести записи из таблицы Production.Product в формате «ProductId: Name»
(обратите внимание на типы данных).
Вычислить разницу полей MaxQty и MinQty в таблице Sales.SpecialOffer, вывести
идентификатор предложения (SpecialOfferID), описание Description и
вычисленную разницу (Diff).
В таблице Sales.SalesOrderDetail вычислить конечную стоимость строки
умножив количество (OrderQty) на цену (UnitPrice).
65
66. ФУНКЦИИ И ВЫРАЖЕНИЯ Задания (2)
7.Напишите запрос, который выведет первые 10 символов столбца AddressLine1
из таблицы адресов Person.Address, укажите алиас нового столбца.
8. Из таблицы адресов Person.Address выберите записи отобразив в столбце
AddressLine1 символы с 10 по 15ый
9. Номер продукта (ProductNumber) из таблицы Production.Product содержит
дефис разделяющий название на код и номер (CA-1234, X-45454). Напишите
запрос выводящий номера продуктов следующие за знаком дефис.
10. Напишите запрос вычисляющий количество дней между датой заказа
(OrderDate) и датой отправки (ShipDate) в таблице Sales.SalesOrderHeader.
Дополнительно включите в выборку SalesOrderId, OrderDate и ShipDate.
11. Напишите запрос отображающий только дату (отбросить время) для полей дата
заказа (OrderDate) и дата отгрузки (ShipDate) в таблице Sales.SalesOrderHeader.
12. Для каждой записи в таблице Sales.SalesOrderHeader увеличьте дату заказа на 6
месяцев.
66
67. ФУНКЦИИ И ВЫРАЖЕНИЯ Задания (3)
13. Выберите из таблицы Sales.SalesOrderHeader заказы оформленные в 2007 году(OrderDate). В выборке выведите SalesOrderID, год (OrderYear), месяц
(OrderMonth). Используйте функция извлечения части даты.
14. Для все заказов в таблице Sales.SalesOrderHeader выведетие номер заказа
(SalesOrderId) и подитог (SubTotal) округленный до двух знаков после запятой.
15. Для каждого сотрудника в таблице HumanResources.Employee определить
является ли его идентификатор (BusinessEntityID) четным. Используйте
целочисленное деление и выражение CASE для вывода информации.
16. Выберите все детализации заказов из таблицы sales.SalesOrderDetail напротив
каждой детализации выведите информацию о количестве заказов (OrderQty).
'Менее 10‘, 'Между 10 и 19‘, 'Между 20 и 29‘, 'Между 30 и 39‘, 'Более 40‘ в
столбец Range
67
68. 8: Суммирование и группировка данных
Агрегатные функции
Предложение GROUP BY
Предложение GROUP BY и ORDER BY
Предложение GROUP BY и WHERE
Предложение GROUP BY и HAVING
CUBE и ROLLUP
Задания
8: Суммирование и
группировка данных
69. Агрегатные функции
Агрегатные функции являются специальным типом запросов используемых длягруппирования и суммирования данных. Данный тип функций оперирует наборами
данных.
Часто используемые агрегатные функции:
COUNT – подсчитывает количество строк или не NULL значений в столбце
SUM – вычисляет сумму значений, используется только с числовыми типами данных
AVG – вычисляет среднее значение
MIN и MAX – ищут минимальное или максимальное значение в наборе данных
Основные свойства агрегатных функций:
- AVG и SUM возможно использовать только с числовыми типами данных
- MIN, MAX и COUNT возможно использовать с числовыми и текстовыми типами
данных
- агрегатные функции игнорируют NULL значения
- все агрегатные функции, за исключением COUNT (*), игнорируют значения NULL
69
70. Агрегатные функции
COUNTСинтаксис: COUNT ( { [ [ ALL | DISTINCT ] expression ] | * } )
ALL – применяет агрегатную функцию ко всем значениям (по умолчанию)
DISTINCT – указывает, что нужно вернуть все уникальные не NULL значения
expression – выражение любого типа кроме text, image, ntext.
* – указывает, что все колонки должны быть агрегированы, возвращает количество
всех записей в таблице
MIN, MAX, AVG
Синтаксис: Fn ( [ ALL | DISTINCT ] expression )
ALL – применяет агрегатную функцию ко всем значениям (по умолчанию)
DISTINCT – указывает, что нужно вернуть все уникальные не NULL значения
expression – выражение над которым нужно выполнить вычисление
70
71. Предложение GROUP BY
Используя предложение GROUP BY можно указать по каким колонкам иливыражения необходимо сгруппировать данные, при этом агрегатные функции будут
работать в разрезе заданных групп.
Синтаксис:
SELECT <aggregate function>(<col1>), <col2>
FROM <table>
GROUP BY <col2>
Указанные колонки после предложения GROUP BY могут быть использованы в
Select-list.
71
72. Предложение GROUP BY и ORDER BY
Предложение GROUP BY допускает использование сортировки добавивпредложение ORDER BY в конце запроса.
Синтаксис:
SELECT <aggregate function>(<col1>), <col2>
FROM <table>
GROUP BY <col2>
ORDER BY <col2>
В предложении ORDER BY можно использовать колонки перечисленные в GROUP BY
, агрегатные функции, алиасы или порядковые номер столбцов из Select-list.
72
73. Предложение GROUP BY и WHERE
Для фильтрации данных можно добавить предложение WHERE при этомдопускается использовать любые предикаты, которые допускаются для не
группируемых запросов. Агрегатные функции в предложение WHERE недопустимы.
Синтаксис:
SELECT <aggregate function>(<col1>), <col2>
FROM <table>
WHERE <predicate>
GROUP BY <col2>
73
74. Предложение GROUP BY и HAVING
Для исключения записей основанных на агрегатных выражениях применяетсяпредложение HAVING. HAVING предложение допускает использование как
агрегатных функций так и не агрегируемые колонки, но указанные в GROUP BY
Синтаксис:
SELECT <aggregate function>(<col1>), <col2>
FROM <table>
GROUP BY <col2>
HAVING <aggregate function2>(<col3>) = <value>
74
75. CUBE и ROLLUP
Операторы ROLLUP и CUBE являются расширениями предложения GROUP BY.Применяя эти операторы можно сформировать такой же результирующий набор,
который получится в результате использования оператора UNION ALL для
объединения одиночных запросов группирования, однако использование одного из
операторов предложения GROUP BY обычно является более эффективным.
Синтаксис:
SELECT <aggregate function>(<col1>), <col2>
FROM <table>
GROUP BY <CUBE или ROLLUP> (<col1>, <col2>)
75
76. Предложение OVER
Определяет секционирование и упорядочение набора строк до примененияоконной функции.
Синтаксис:
SELECT <aggregate function>(<col1>)
OVER ( [ PARTITION BY value_expression] [ORDER BY value_expression] )
FROM <table>
PARTITION BY – Разделяет результирующий набор на секции. Оконная функция
применяется к каждой секции отдельно, и вычисление начинается заново для
каждой секции.
value_expression – Указывает столбец, по которому секционируется набор строк,
произведенный соответствующим предложением FROM
76
77. Суммирование и группировка данных Задания (1)
1.2.
3.
4.
5.
6.
Посчитайте количество заказчиков в таблице Sales.Customer
Посчитайте количество заказанных товаров (OrderQty) из таблицы
Sales.SalesOrderDetail
Выберите из таблицы детализации заказов Sales.SalesOrderDetail самую
высокую и низкую цену за товар.
Вычислите среднюю стоимость доставки (Freight) из таблицы
Sales.SalesOrderHeader
Вычислите количество заказанных продуктов (OrderQty) в разрезе каждого
продукта (ProductId) из таблицы Sales.SalesOrderDetail. Результат отсортируйте
в порядке убывания количества.
Для каждого заказа SalesOrderId из таблицы Sales.SalesOrderDetail вычислите
количество строк. Выведите 12 самых крупных заказов по количеству строк,
необходимо учесть заказы разделившие последнее место.
77
78. Суммирование и группировка данных Задания (2)
7.Напишите запрос для вычисления количества размещенных заказов в таблице
Sales.SalesOrderHeader по каждому клиенту (CustomerId) в разрезе года
размещения заказа (OrderDate). Отсортируйте результат по годам, в порядке
убывания количества заказов.
8. Из таблицы Sales.SalesOrderDetail выберите заказы (SalesOrderId) количество
строк по которым находится в интервале от 10 до 20. Отсортируйте результат по
количеству строк заказа.
9. Выберите заказы из таблицы Sales.SalesOrderDetail выбрав только те заказы
(SalesOrderId), сумма строк по которым превышает 1000$. Отсортируйте
результат в порядке убывания суммы за заказ.
10. Напишите запрос который группирует продукты по моделям (ProductModelID)
синего и красного цвета (Color) из таблицы Production.Product, отберите только
те модели по которым есть только один продукт каждого цвета.
11. Из таблицы Sales.SalesOrderDetail выберите количество уникальных заказанных
товаров (ProductID)
12. Из таблицы Sales.SalesOrderHeader посчитайте уникальное количество клиентов
(CustomerId) в разрезе территорий TerritoryID
78
79. 9: Выбор данных из нескольких таблиц
INNER JOINs
OUTER JOINs
Подзапросы
Объединения
9: Выбор данных из
нескольких таблиц
80. Использование соединений
Любой запрос, который выбирает данные из более чем одной таблицы, выполняеткакое-либо объединение.
Основные характеристики объединений:
- операнды объединения называют левой или правой таблицей относительно
оператора JOIN;
- таблицы всегда объединяются построчно при выполнении всевозможных
условий, определенных в запросе;
- строки, которые не соответствуют заданным условиям, могут быть как
включены в объединение, так и исключены из него, в зависимости от типа этого
объединения;
80
81. Типы соединений
Соединения можно разделить на следующие категории.• Внутренние соединения INNER JOIN
»
используют оператор сравнения для установки соответствия строк из двух таблиц
на основе значений общих столбцов в каждой таблице.
• Внешние соединения.
» Левое [внешнее] соединение LEFT JOIN или LEFT OUTER JOIN
Результирующий набор включает все строки из левой таблицы. Если строка в
левой таблице не имеет совпадающей строки в правой таблице, результирующий набор
строк содержит значения NULL для всех столбцов списка выбора из правой таблицы.
» Правое [внешнее] соединение RIGHT JOIN или RIGHT OUTER JOIN
Возвращаются все строки правой таблицы. Для левой таблицы возвращаются
значения NULL каждый раз, когда строка правой таблицы не имеет совпадающей строки
в левой таблице.
81
82. Типы соединений
» Полное [внешнее] соединение FULL JOIN или FULL OUTER JOINВозвращает все строки из правой и левой таблицы. Каждый раз, когда строка не
имеет соответствия в другой таблице, столбцы списка выбора другой таблицы содержат
значения NULL.
• Перекрестные с соединения CROSS JOIN
Возвращает все строки из левой таблицы. Каждая строка из левой таблицы
соединяется со всеми строками из правой таблицы. Перекрестные соединения
называются также декартовым произведением.
Таблицы или представления в предложении FROM могут указываться в
любом порядке с внутренним соединением или полным внешним
соединением. Однако важен порядок таблиц или представлений, заданных
при использовании левого или правого внешнего соединения.
82
83. Типы соединений
8384. Внутреннее соединение INNER JOIN
INNER JOINСинтаксис:
SELECT <select list>
FROM <table1>
[INNER] JOIN <table2> ON <table1>.<col1> = <table2>.<col2>
[INNER] JOIN <table2> ON <table1>.<col1> = <table2><col2>
AND <table1>.<col3> = <table2>.<col4>
В этом соединении связанными столбцами считаются те, которые заданы
условиями сравнения (чаще всего они в двух таблицах имеют одинаковые имена).
Объединяются те строки, в которых все значения связанных столбцов одной
таблицы попарно находятся в заданном оператором сравнения отношении с
соответствующими значениями связанных столбцов другой таблицы. Остальные
строки из объединения исключаются. Этот вид объединения используется
чаще всего.
84
85. Внешние соединения OUTER JOIN
LEFT [OUTER] JOINСинтаксис:
SELECT <select list>
FROM <table1>
LEFT [OUTER] JOIN <table2> ON <table1>.<col1> = <table2><col2>
LEFT [OUTER] JOIN <table3> ON <table2>.<col1> = <table3>.<col2>
AND <table2>.<col3> = <table3>.<col4>
В этом соединении сначала проводится сравнение значений связанных
столбцов. Но в результат объединения включаются все строки левой таблицы, а не
только те, для которых в правой таблице нашлись строки с удовлетворяющими
сравнению значениями связанных столбцов. Если некой строке слева не нашлось
ни одной строки справа, SQL Server объединяет ее с искусственной строкой,
состоящей из значений null.
85
86. Внешние соединения OUTER JOIN
RIGHT [OUTER] JOINСинтаксис:
SELECT <select list>
FROM <table1>
RIGHT [OUTER] JOIN <table2> ON <table1>.<col1> = <table2><col2>
RIGHT [OUTER] JOIN <table3> ON <table2>.<col1> = <table3>.<col2>
AND <table2>.<col3> = <table3>.<col4>
Является зеркальным отображением левого внешнего соединения, и в нем тоже
сначала проводится сравнение значений связанных столбцов. Но в результат
объединения теперь включаются все строки правой таблицы. Если же некой строке
справа не нашлось ни одной строки слева, SQL Server объединяет ее с
искусственной строкой, состоящей из значений null
86
87. Внешние соединения OUTER JOIN
FULL [OUTER] JOINСинтаксис:
SELECT <select list>
FROM <table1>
FULL [OUTER] JOIN <table2> ON <table1>.<col1> = <table2><col2>
Включает и все строки левой таблицы, и все строки правой таблицы. Если у
какой-либо строки (слева или справа) нет пары по связанным столбцам, SQL Server
объединяет ее с искусственной строкой, состоящей из значений null.
87
88. Перекрестное соединение CROSS JOIN
CROSS JOINСинтаксис:
SELECT <select list>
FROM <table1>
CROSS JOIN <table2>
Группирует строки таблиц по правилу «каждая с каждой». Первая строка
первой таблицы объединяется с первой строкой второй таблицы, потом первая
строка первой таблицы объединяется со второй строкой второй таблицы, и т.д. до
тех пор, пока в первой таблице не закончатся строки
88
89. Агрегация и соединения
Группировку и агрегатные функции возможно применять более чем к однойтаблице.
Синтаксис:
SELECT <select list>
FROM <table1> t1
[INNER | LEFT OUTER | RIGHT OUTER | FULL OUTER |CROSS] JOIN <table2> t2 ON …
[INNER | LEFT OUTER | RIGHT OUTER | FULL OUTER |CROSS] JOIN <table3> t3 ON …
GROUP BY t1.<col1>, t2.<col2>, t3.<col3>
89
90. Подзапросы
Подзапросы представляют собой вложенные запросы в основной запрос. Одна изпричин использования подзапросов – найти связанные записи в таблицах при этом
не соединяясь с другой таблицей.
Синтаксис:
SELECT <select list>
FROM <table1>
WHERE <col1> [NOT] IN (SELECT <col2> FROM <table2>)
SELECT <select list>
FROM <table1>
WHERE <col1> [NOT] IN (SELECT <col2> FROM <table2>
WHERE <table1>.<col1> = <table2>.<col1>)
90
91. Производные таблицы
Производная таблица — это результирующий набор, используемый в запросе вкачестве исходных таблиц.
Синтаксис:
SELECT <select list>
FROM <table1> AS A
[INNER] JOIN ( SELECT <select list>
FROM <table2>
GROUP BY <col3> ) AS B ON A.<col1> = B.<col2>
91
92. Объединения
Для объединения нескольких наборов (запросов) применяют оператор UNIONСинтаксис:
SELECT <col1>, <col2>,<col3> FROM <table1>
UNION [ALL]
SELECT <col4>, <col5>,<col6> FROM <table2>
Ограничения:
- Количество и порядок столбцов должны быть одинаковыми во всех запросах.
- Типы данных должны быть совместимыми.
Ключевое слово ALL указывает, что в результирующем наборе необходимо оставить
все строки. Если не указано, то дублирующиеся строки наборов будут удалены.
92
93. Соединение таблиц Задания (1)
1.2.
3.
4.
5.
В таблице HumanResources.Employee размещена информация о сотрудниках, но
в этой таблице нет данных о фамилиях. Присоедините таблицу Person.Person по
столбцу BusinessEntityID и выведите JobTitle, BirthDate, FirstName, LastName.
Имена поставщиков можно найти в таблице Person.Person, присоедините
таблицу поставщиков Sales.Customer по столбцам Person.BusinessEntityID и
Customer.PersonID. Выведите CustomerID, StoreID, TerritoryID, FirstName,
MiddleName, LastName
Расширьте запрос №2 присоединив таблицу Sales.SalesOrderHeader и выведети
из нее столбец SalesOrderid. Соединение выполните с таблицей Sales.Customer
по полю CustomerId
Описание (CatalogDescription) для каждого продукта хранится в таблице
Production.ProductModel. Выведите информацию об описании
(CatalogDescription), дополнив ее цветом (Color) и размером (Size) продукта из
таблицы Production.Product.
Напишите запрос который выведет информацию о клиентах (ФИО) и
наименовании продуктов, которые они приобрели. Необходимо соединить 5
таблиц.
93
94. Соединение таблиц Задания (2)
6.Выведите информацию о продуктах (Production.Product) идентификатор
продукта (ProductID), название (Name) и идентификатор заказа (SalesOrderID)
из таблицы Sales.SalesOrderDetail, если такие имеются.
7. Измените запрос №6 таким образом, чтобы отобразить только те продукты,
которые небыли заказаны.
8. Напишите запрос который вернет все записи из таблицы Sales.SalesPerson и
соединив ее с Sales.SalesOrderHeader по столбцам BusinessEntityID и
SalesPersonID. Включите в выборку поля SalesYTD, SalesOrderID и SalesPersonID
9. Измените запрос №8 дополнив его информацией из таблицы о фамилиях и
именах покупателей.
10. Напишите запрос который выведет имена клиентов (FirstName, MiddleName,
LastName) из таблицы Person.Person и вычислит количество сделанных заказов
по каждому из этих клиентов
11. Для каждого товара вычислите проданное количество (OrderQty) и вырученную
сумму от продаж (LineTotal) в разрезе по годам (OrderDate). Выведите
идентификатор продукта (ProductID), название (Name), год продажи,
вырученная сумма, проданное количество
94
95. Соединение таблиц Задания (3)
Подзапросы:12. Выведите название номер и название продукта (ProductID, Name) из табилцы
Production.Product, для тех продуктов, которые были заказаны (проверить в
таблице Sales.SalesOrderDetail)
13. Измените запрос №10 оставив в результирующем наборе ни разу не
заказанные товары
14. Напишите запрос использую UNION объединив даты изменения записей
(ModifiedDate) из таблицы Person.Person и даты трудоустройства сотрудников
(HireDate) из таблицы HumanResources.Employee
15. * Определите сколько в среднем каждый год француженки тратят на товары
нашего магазина.
Подсказка: Sales.SalesOrderHeader – Заказы
Sales.Customer – Клиенты
Sales.vPersonDemographics – Расширенная информация о клиентах
Sales.SalesTerritory – Информация о территориях, где делали заказы
Sales.Customer и Sales.vPersonDemographics связывается по PersonID и BusinessEntityID
соответственно.
95
96. 10: Управление данными
Вставка данных
Удаление данных
Изменение данных
Задания
10: Управление данными
97. Вставка данных
Вставка строки с литералами в качестве значенийСинтаксис:
INSERT [INTO] <table1> [(<col1>,<col2>)] SELECT <value1>,<value2>;
INSERT [INTO] <table1> [(<col1>,<col2>)] VALUES (<value1>,<value2>);
Вставка множества строк
Синтаксис:
INSERT [INTO] <table1> [(<col1>,<col2>)]
SELECT <value1>,<value2> UNION [ALL] SELECT <value3>,<value4>;
INSERT [INTO] <table1> [(<col1>,<col2>)]
VALUES (<value1>,<value2>), (<value3>,<value4>), (<value5>,<value6>) ;
97
98. Вставка данных
Вставка строк из другой таблицыСинтаксис:
INSERT [INTO] <table1> [(<col1>,<col2>)]
SELECT <col1>,<col2>
FROM <table2>
WHERE … ;
Создание таблицы и вставка одновременно
Синтаксис:
SELECT <col1>,<col2>
INTO <table2>
FROM <table1>;
98
99. Вставка данных
Вставка строк со значениями по умолчаниюПри создании таблиц можно добавить ограничение DEFAULT на колонку, которое
будет использоваться в качестве значения по умолчанию. Для использования
значения по умолчанию оператор INSERT можно написать двумя способами:
- Не указывать колонку, со значением по умолчанию, в списке колонок;
- Использовать ключевое слово DEFAULT
99
100. Удаление данных
Предложение DELETEСинтаксис:
DELETE [FROM] <table1>
[WHERE … ];
Удаление используя соединения или подзапросы
DELETE <alias>
FROM <table1> AS <alias>
INNER JOIN <table2> ON <alias>.<col1> = <table2>.<col2>
[WHERE <condition>]
DELETE [FROM] <table1>
WHERE <col1> IN (SELECT <col2> FROM <table2>)
100
101. Удаление данных
Очистка таблицСинтаксис:
TRUNCATE TABLE <table1>;
Удаляет все строки в таблице, не записывая в журнал удаление отдельных
строк. Инструкция TRUNCATE TABLE похожа на инструкцию DELETE без
предложения WHERE, однако TRUNCATE TABLE выполняется быстрее и требует
меньших ресурсов системы и журналов транзакций.
Преимущества:
- Использует меньший объем журнала транзакций;
- Обычно использует меньшее количество блокировок (всегда блокирует
таблицу);
- Сохраняет структуру таблицы без изменений;
- Сбрасываются все счетчик идентификаторов.
101
102. Изменение данных
Простое изменение данныхСинтаксис:
UPDATE <table1>
SET <col1> = <new value1>,<col2> = <new value2>
[WHERE <condition>]
Изменение данных с использование соединений
Синтаксис:
UPDATE <alias>
SET <col1> = <expression>
FROM <table1> AS <alias>
INNER JOIN <table2> ON <alias>.<col2> = <table2>.<col3>
102
103. Задания (INSERT) [1/2]
1.2.
3.
4.
Напишите SELECT для получения первых двух записей из таблицы
Production.Product , отсортировав по полю StandardCost в порядке убывания. Из
полученных данных составьте два предложение INSERT для вставки в таблицу
dbo.demoProduct. Используемые поля: ProductID, Name, Color, StandardCost,
ListPrice, Size, Weight.
Расширьте результат выборки SELECT в задании №1 до 4х записей и две новые
строки вставьте в таблицу dbo.demoProduct используя только одно
предложение INSERT.
Напишите
предложение
INSERT
для
вставки
в
таблицу
dbo.demoSalesOrderHeader всех записей из таблицы Sales.SalesOrderHeader.
Используемые поля: SalesOrderID, OrderDate, CustomerID, SubTotal, TaxAmt,
Freight.
Напишите запрос используя предложение SELECT INTO для создания таблицы
dbo.tempCustomerSales и запишите в нее информацию о количестве сделанных
клиентом заказов, посчитайте сумму этих заказов. Результирующая таблица
должна содержать поля: CustomerID, CountOfOrders, TotalDue.
103
104. Задания (INSERT) [2/2]
5.Напишите запрос который вставит в таблицу dbo.demoProduct не достающие
записи из таблицы Production.Product. Ключ для проверки поле ProductID.
104
105. Задания (DELETE) [1/1]
1.2.
3.
Напишите запрос который удалит из таблицы dbo.demoCustomer все записи у
которых LastName начинается с буквы S.
Удалите из таблицы dbo.demoCustomer удалите тех клиентов, у которых не
было заказов либо сумма всех заказов (TotalDue) из таблицы
dbo.demoSalesOrderHeader была меньше 1000$.
Удалите записи из таблицы dbo.demoProduct все записи о продуктах которые
никогда
не
заказывались,
для
проверки
используйте
таблицу
dbo.demoSalesOrderDetail.
105
106. Задания (UPDATE) [1/1]
1.2.
3.
4.
Для всех записей в таблице dbo.demoAddress, у которых AddressLine2 имеет
неопределенно значение установите значение «N/A».
Обновите цену ListPrice в таблице dbo.demoProduct увеличив ее на коэфициент
1,1.
Обновите записи в таблице dbo.demoSalesOrderDetail установив значение
UnitPrice равную ListPrice связанных продуктов из таблицы demoProduct.
Измените данные в таблице dbo.demoSalesOrderHeader установив значение
поля SubTotal равное сумме LineTotal соответствующего заказа из таблицы
dbo.demoSalesOrderDetail.
106
107.
ЦЕНТРАЛЬНЫЙ ОФИС:119602, Г. МОСКВА УЛ. ПОКРЫШКИНА, Д. 7
+7 (495) 737 99 91 / INFO@GMCS.COM
WWW.GMCS.RU