









































































")
")
")
")



 informatics
informaticsSimilar presentations:










Принципы сжатия звуковой информации
1. Цифровое представление звуковой информации Принципы сжатия звука
2. Введение
Виды аппаратной и программной реализации систем цифровой
обработки речевой и звуковой информации определяются их
исходными характеристиками, особенностями слухового восприятия и
требованиями к качеству воспроизведения
Речевая информация, образующая свойственные используемому языку
фонетические комбинации и формирующая те или иные смысловые
элементы, по своим физическим параметрам принципиально
отличается от звуковой информации, содержащей сочетание голосовых
данных с музыкальным сопровождением, особенности и отличия друг
от друга речевой и звуковой информации используются при их
цифровой обработке и сжатии
Основную информацию о звуковых колебаниях человек получает в
области частот примерно до 4 кГц, именно эти частоты задают
разборчивость и ясность аудиоинформации
Спектральный состав речи занимает полосу частот примерно от 50 до
7000-10000 Гц
В аналоговой телефонии используется полоса частот 0,3-3,4 кГц, что
ухудшает восприятие ряда звуков (например, шипящих), но
практически не отражается на разборчивости речи
3.
В цифровой телефонии отсчеты аналоговой речи приходится брать
согласно теореме Котельникова с частотой 8 кГц
Разрядность аналого-цифрового преобразования для речи – 8 или 16
бит на отсчет
Идея преобразовывать в цифровой вид не сам речевой сигнал, а его
параметры (количество переходов через ноль, спектральные
характеристики и др.), чтобы затем по этим параметрам выбирать
модель голосового тракта и синтезировать исходный сигнал, лежит в
основе синтезирующих кодеков или вокодеров
Принцип работы гибридных кодеков основан на модели кодирования с
использованием линейного предсказания и алгебраической кодовой
книги, при этом производится анализ речевого сигнала и выделяются
параметры модели (коэффициенты системы линейного предсказания,
индексы и коэффициенты усиления в адаптивной и фиксированной
кодовых книгах), далее эти параметры кодируются и передаются в
канал
Слуховой аппарат человека различает частотные составляющие звука
приблизительно в пределах от 30 Гц до 20 кГц; верхняя граница может
несколько отличаться в зависимости от возраста человека, условий
воспроизведения информации и др.
4.
Используемые для звука частоты дискретизации – 32, 44,1, 48, 96 кГц;
при этом цифровой поток продискретизированного сигнала может
изменяться от 32000•16/1024 = 500 кбит/с до 96000•24•6/(1024•1024) =
4,4 Мбит/с и даже 192000•32•24/(1024•1024) = 140,6 Мбит/с
5.
Используемые для звука частоты дискретизации – 32, 44,1, 48, 96 кГц;
при этом цифровой поток продискретизированного сигнала может
изменяться от 32000•16/1024 = 500 кбит/с до 96000•24•6/(1024•1024) =
4,4 Мбит/с и даже 192000•32•24/(1024•1024) = 140,6 Мбит/с
Для существенного сокращения избыточности аудиоинформации
применяются различные методы линейной и нелинейной обработки
звуковых сигналов, которые приводят к сжатию с потерями,
уменьшающими размер кодированной последовательности по
сравнению с оригинальным за счет удаления информации,
невоспринимаемой человеком; технология сжатия с потерями
недостаток человеческого слуха превращает в преимущество,
отбрасывая «ненужную» информацию; компромисс между малым
цифровым потоком и качеством воспроизводимого аудиосигнала
достигается путем изменения количества отбрасываемой информации
Дополнительные проблемы в кодировании аудиоинформации
возникают при обработке различных форматов – от стереофонического
сигнала до объемного многоканального звукового сигнала; в этих
случаях для существенного сокращения избыточности многоканальных
сигналов используются корреляционные связи между ними
6. Основные характеристики звуковой информации
Аналоговое представление звуковых сигналов основано на подобии
форм и основных характеристик соответствующих им электрических
сигналов
В терминах теории информации, количество информации в
электрическом сигнале в точности равно количеству информации в
сигнале исходном, и электрическое представление не содержит
избыточности, которая могла бы защитить переносимый сигнал от
искажений при хранении, передаче и усилении
Важные характеристики распространения звукового сигнала –
интерференция, дифракция, рефракция, ревеберация, эхо, резонанс,
диффузность, эффект Допплера и др.
Звуковой сигнал или его электрический эквивалент u(t) обычно считают
случайным процессом с распределением мгновенных значений,
которое характеризуется некоторой плотностью вероятностей W(u)
7. Основные характеристики звуковой информации
интерференция – усиление колебаний звука в одних точках пространства и
ослабление колебаний в других точках в результате наложения двух или
нескольких звуковых волн
рефракция – преломление, изменение направления движения звуковой
волны от границы раздела с иной средой, поглощение или переход в другую
среду
реверберация – отражения звуковых колебаний в замкнутом пространстве,
вызывающие специфический гул, изменяя тембральную окраску,
насыщенность, глубину воспринимаемого звука
дифракция – способность звуковых волн огибать препятствия
эхо – возникновение сдвинутых во времени и различаемых раздельно
повторов кратковременных звуковых колебаний
эффект резонанса – способность звуковой волны, создаваемой некоторым
колеблющимся телом, переносить энергию колебаний другому телу, которое
поглощая эту энергию само становится источником звука
индекс диффузности – фактор изотропности и однородности звукового
поля
звуковое давление – характеристика громкости звука, непосредственно
воспринимаемого ухом человека
эффект Допплера – изменение длины звуковых волн при изменении
скорости движения слушателя относительно источника звука
8. Сигналограммы фрагментов музыкальной записи и речи
9.
Уровень электрического эквивалента звукового сигнала обычно
характеризуют напряжением, формируемым на выходе квазипикового
детектора с малой величиной постоянной времени заряда (порядка 510 мс) и значительной величиной τ постоянной времени разряда (1-2 с)
Отношение усредненной величины выпрямленных мгновенных
значений сигнала U(t, τ) на выходе квазипикового детектора (или
выделяемой на нагрузке мощности P(t, τ) сигнала) к некоторой
условной величине U0 (или P0) определяют формулой:
U (t , )
P(t , )
N (t , ) 20 lg
10 lg
U0
P0
U0 – принятая за начало отсчета среднеквадратическая величина
электрического сигнала с эффективным напряжением 0,775 В на
нагрузке 600 Ом (выделяемая мощность – P0=1 мВт); выраженная в
децибелах эта величина определяет значение уровня, равное 0 дБ
10.
Интенсивность звука или звуковое давлениеИнтенсивность звука или звуковое давление оценивают либо в
Паскалях, либо в децибелах относительно некоторого порога, величина
которого принята равной р0 = 2·10‑5 Па = 20 мкПа и соответствует
порогу слышимости здорового молодого человека в диапазоне
звуковых частот 1-4 кГц
Для характеристики уровней звукового давления (SPL – Sound pressure
level) используется уравнение:
pk
SPL 20 lg
p0
р0 и рk – звуковое давление, выраженное, например, в Паскалях
11.
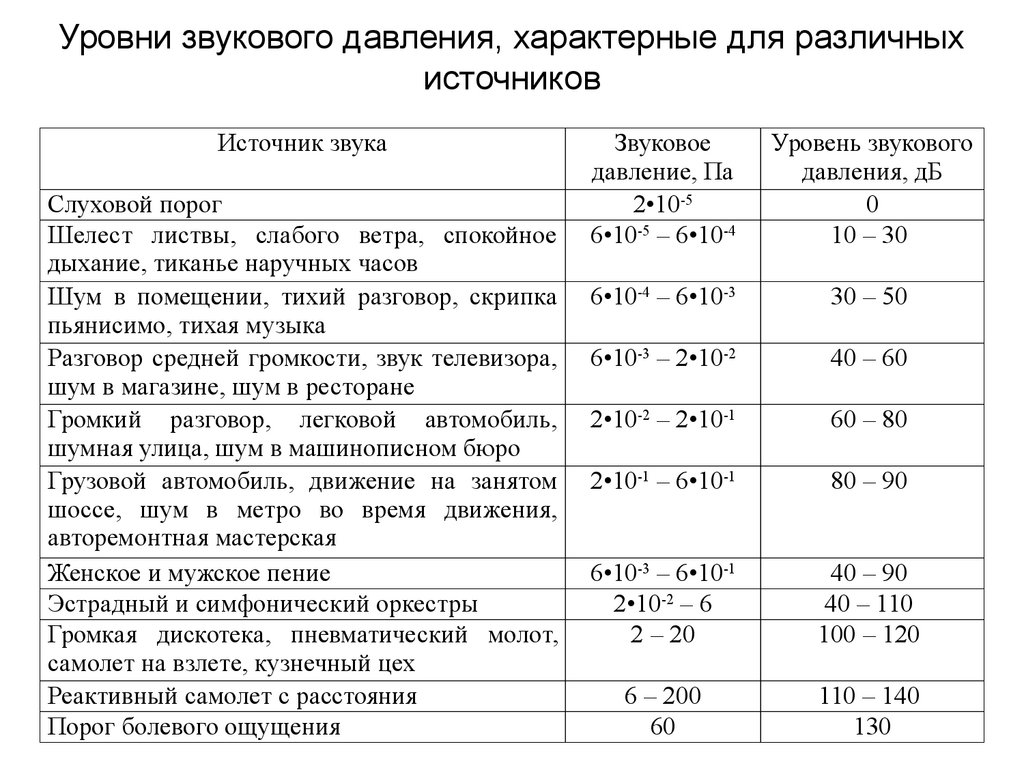
Уровни звукового давления, характерные для различныхисточников
Источник звука
Слуховой порог
Шелест листвы, слабого ветра, спокойное
дыхание, тиканье наручных часов
Шум в помещении, тихий разговор, скрипка
пьянисимо, тихая музыка
Разговор средней громкости, звук телевизора,
шум в магазине, шум в ресторане
Громкий разговор, легковой автомобиль,
шумная улица, шум в машинописном бюро
Грузовой автомобиль, движение на занятом
шоссе, шум в метро во время движения,
авторемонтная мастерская
Женское и мужское пение
Эстрадный и симфонический оркестры
Громкая дискотека, пневматический молот,
самолет на взлете, кузнечный цех
Реактивный самолет с расстояния
Порог болевого ощущения
Звуковое
давление, Па
2•10-5
6•10-5 – 6•10-4
Уровень звукового
давления, дБ
0
10 – 30
6•10-4 – 6•10-3
30 – 50
6•10-3 – 2•10-2
40 – 60
2•10-2 – 2•10-1
60 – 80
2•10-1 – 6•10-1
80 – 90
6•10-3 – 6•10-1
2•10-2 – 6
2 – 20
40 – 90
40 – 110
100 – 120
6 – 200
60
110 – 140
130
12.
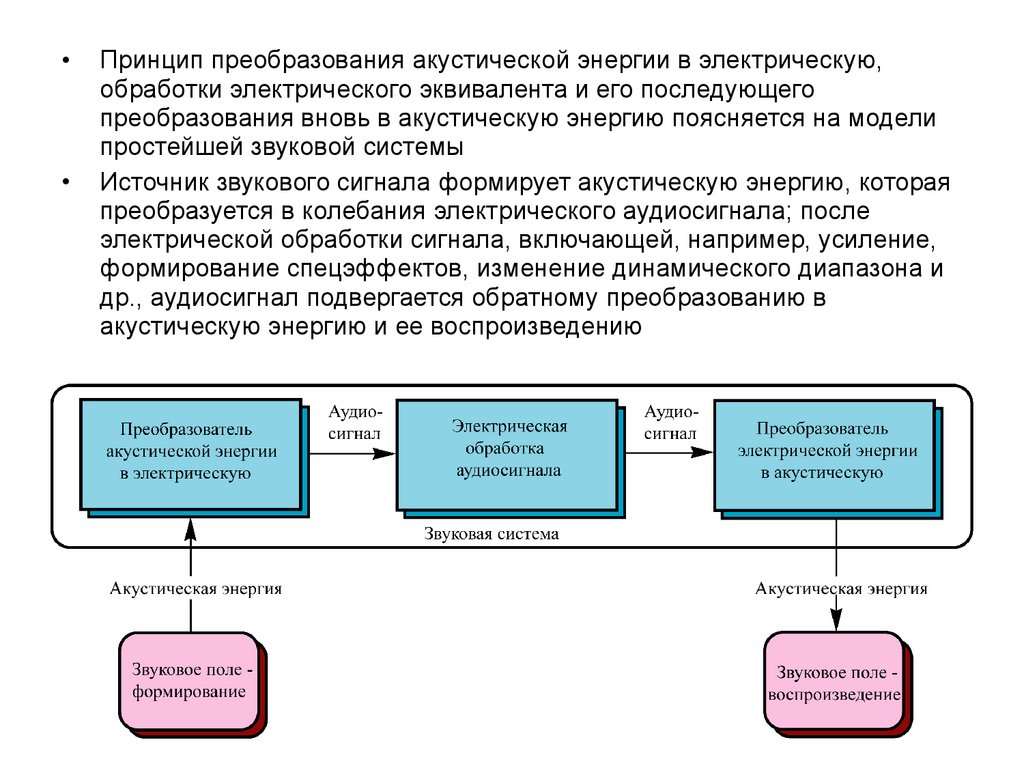
Принцип преобразования акустической энергии в электрическую,
обработки электрического эквивалента и его последующего
преобразования вновь в акустическую энергию поясняется на модели
простейшей звуковой системы
Источник звукового сигнала формирует акустическую энергию, которая
преобразуется в колебания электрического аудиосигнала; после
электрической обработки сигнала, включающей, например, усиление,
формирование спецэффектов, изменение динамического диапазона и
др., аудиосигнал подвергается обратному преобразованию в
акустическую энергию и ее воспроизведению
13.
Уровни электрического эквивалентазвуковой системы (N, дБ)
пропорциональны уровням
звукового давления (SPL, дБ)
При уровне SPL=120 дБ звукового
давления на входе преобразователя
звука в электрический эквивалент
максимальный уровень
электрического сигнала может
достигать величины N=+25 дБ
Соответствие этих величин
представлено на рисунке (между
величинами SPL и N имеется
линейная зависимость, если в
системе не применяется
компрессия, эквализация,
ограничение или отсечка сигналов)
Такое соотношение характерно для
вещательных систем любого типа,
звукоусиления, звукозаписи
14.
Требования к динамическому диапазону звуковой системы зависят от
ее назначения и области использования
Динамический диапазон системы в звуконепроницаемой студии
звукозаписи может быть большим, поскольку в таком случае шумы в не
превышают 10 – 15 дБ
Звуковая система, предназначенная для усиления симфонической
музыки, должна иметь запас динамического диапазона более 20 дБ,
так как пиковые значения, соответствующие звукам некоторых
инструментов (литавр, скрипок и др.) могут достигать 120 дБ
В системах, предназначенных только для воспроизведения речи или
предупреждающих сигналов, уровень звука можно контролировать и
удерживать в очень узком диапазоне
15.
Речевой сигнал можно рассматривать как последовательность
импульсов, разделенных паузами, при которых уровень сигнала ниже
некоторого минимального уровня Nmin
τи1, τи2,… – интервалы последовательности импульсов
τп1, τп2,… – интервалы последовательности пауз
tи1, tи2,… – времена переходов от пауз к импульсам
tп1, tп2,… – времена переходов от импульсов к паузам
16.
Спектральные характеристики звуковых сигналовРеальные звуковые сигналы практически невозможно описать какойлибо математической функцией или эмпирической зависимостью. По
этой причине как правило анализируется лишь ограниченные во
времени фрагменты звукового сигнала, ограниченные некоторой
оконной функцией. При этом используется понятие «мгновенный
спектр»:
/ 2
F ( f , )
w(t ) u (t ) exp( j 2 ft )dt
/2
где u(t) – электрический эквивалент звукового сигнала, w(t) – оконная
функция, равная нулю вне пределов заданного интервала -τ/2 ≤ t ≤ τ/2, f
– текущая частота
Часто оценивают спектральную плотность мощности аудиосигнала с
применением относительно узкополосного фильтра с полосой
пропускания Δf:
f f / 2
2 0
2
G ( f 0 , )
F
(
f
,
)
df
f f 0 f / 2
Результат спектрального анализа выражают в децибелах (G0 –
значение, соответствующее нулю шкалы уровней):
G ( f 0 , )
N ( f 0 , ) 10 lg
G0
17.
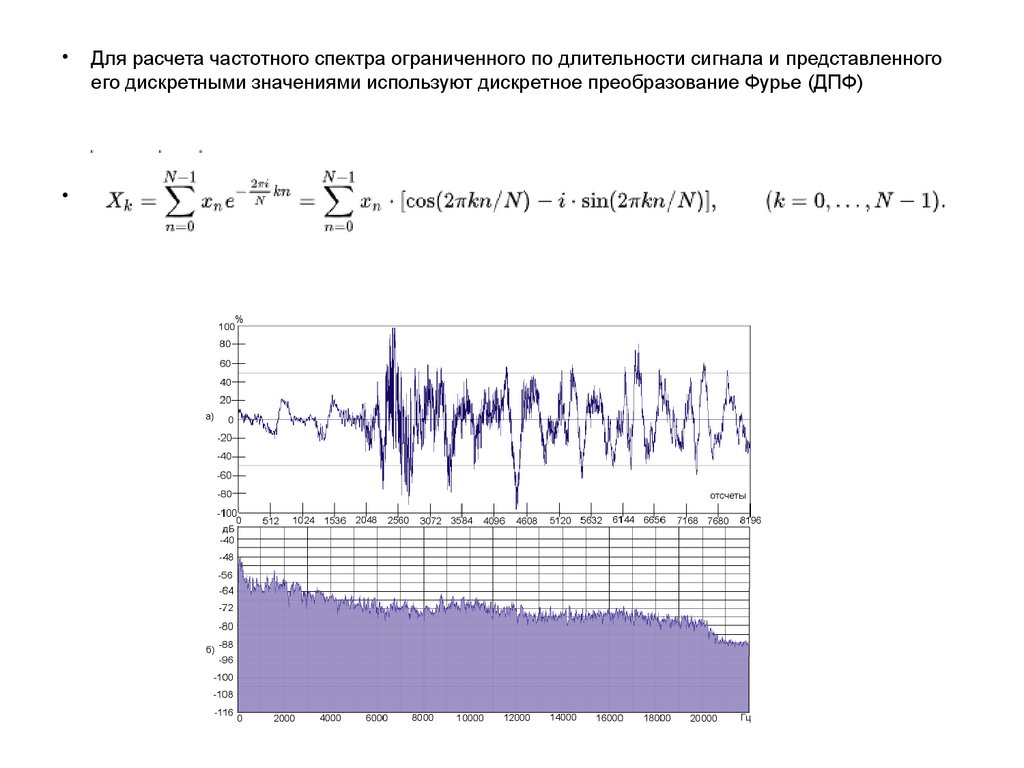
Для расчета частотного спектра ограниченного по длительности сигнала и представленного
его дискретными значениями используют дискретное преобразование Фурье (ДПФ)
или его разновидность – быстрое преобразование Фурье (БПФ)
18.
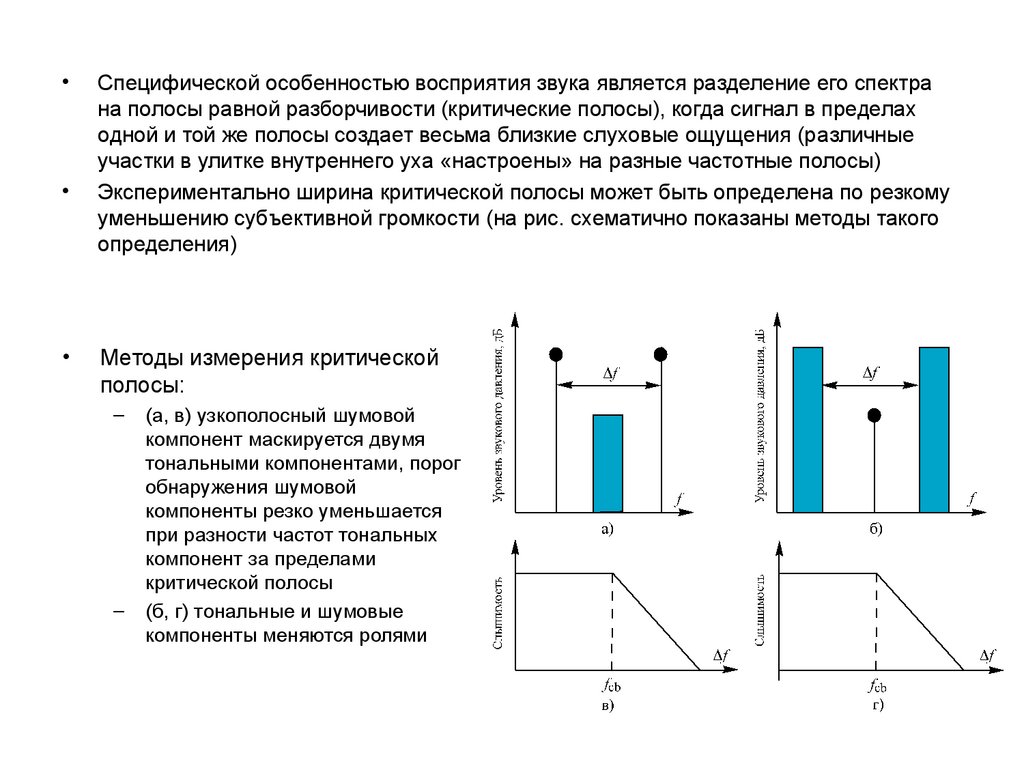
Специфической особенностью восприятия звука является разделение его спектра
на полосы равной разборчивости (критические полосы), когда сигнал в пределах
одной и той же полосы создает весьма близкие слуховые ощущения (различные
участки в улитке внутреннего уха «настроены» на разные частотные полосы)
Экспериментально ширина критической полосы может быть определена по резкому
уменьшению субъективной громкости (на рис. схематично показаны методы такого
определения)
Методы измерения критической
полосы:
–
–
(a, в) узкополосный шумовой
компонент маскируется двумя
тональными компонентами, порог
обнаружения шумовой
компоненты резко уменьшается
при разности частот тональных
компонент за пределами
критической полосы
(б, г) тональные и шумовые
компоненты меняются ролями
19.
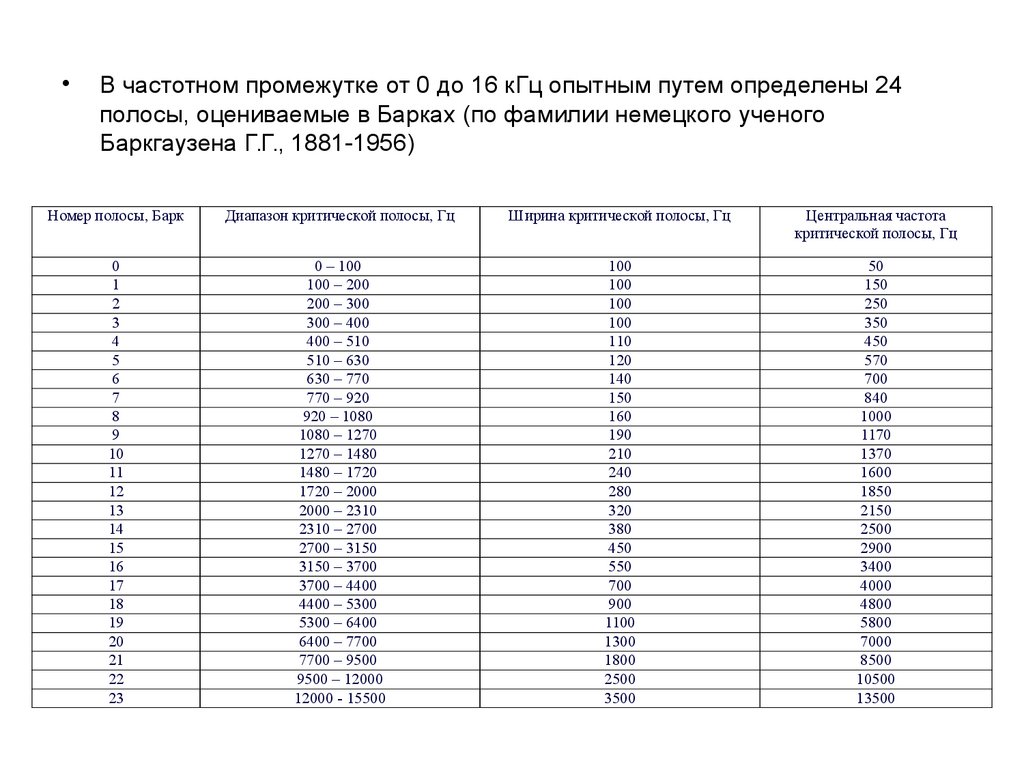
В частотном промежутке от 0 до 16 кГц опытным путем определены 24
полосы, оцениваемые в Барках (по фамилии немецкого ученого
Баркгаузена Г.Г., 1881-1956)
Номер полосы, Барк
Диапазон критической полосы, Гц
Ширина критической полосы, Гц
Центральная частота
критической полосы, Гц
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
0 – 100
100 – 200
200 – 300
300 – 400
400 – 510
510 – 630
630 – 770
770 – 920
920 – 1080
1080 – 1270
1270 – 1480
1480 – 1720
1720 – 2000
2000 – 2310
2310 – 2700
2700 – 3150
3150 – 3700
3700 – 4400
4400 – 5300
5300 – 6400
6400 – 7700
7700 – 9500
9500 – 12000
12000 - 15500
100
100
100
100
110
120
140
150
160
190
210
240
280
320
380
450
550
700
900
1100
1300
1800
2500
3500
50
150
250
350
450
570
700
840
1000
1170
1370
1600
1850
2150
2500
2900
3400
4000
4800
5800
7000
8500
10500
13500
20.
№
полос
ы
1
2
3
4
5
6
7
8
9
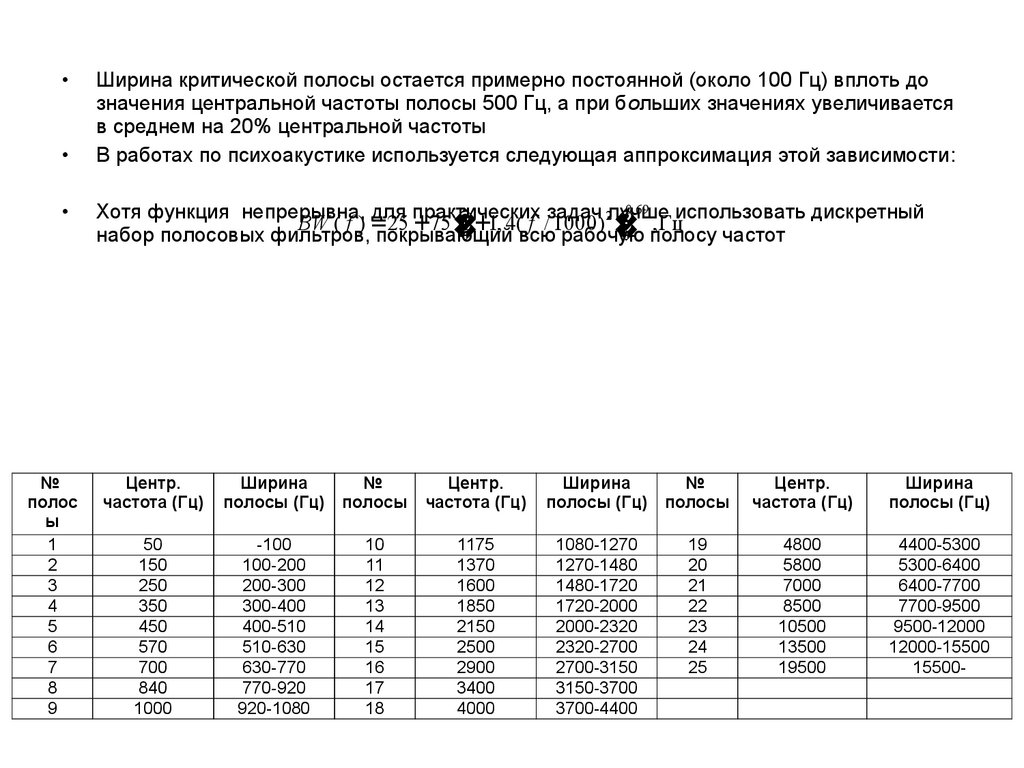
Ширина критической полосы остается примерно постоянной (около 100 Гц) вплоть до
значения центральной частоты полосы 500 Гц, а при больших значениях увеличивается
в среднем на 20% центральной частоты
В работах по психоакустике используется следующая аппроксимация этой зависимости:
0,69
Хотя функция непрерывна, для практических
задач 2лучше
использовать дискретный
BW ( f ) =25 +75
1
+
1,
4(
f
/
1000)
,Гц
полосу частот
набор полосовых фильтров, покрывающий
всю рабочую
Центр.
частота (Гц)
Ширина
полосы (Гц)
№
полосы
Центр.
частота (Гц)
Ширина
полосы (Гц)
№
полосы
Центр.
частота (Гц)
Ширина
полосы (Гц)
50
150
250
350
450
570
700
840
1000
-100
100-200
200-300
300-400
400-510
510-630
630-770
770-920
920-1080
10
11
12
13
14
15
16
17
18
1175
1370
1600
1850
2150
2500
2900
3400
4000
1080-1270
1270-1480
1480-1720
1720-2000
2000-2320
2320-2700
2700-3150
3150-3700
3700-4400
19
20
21
22
23
24
25
4800
5800
7000
8500
10500
13500
19500
4400-5300
5300-6400
6400-7700
7700-9500
9500-12000
12000-15500
15500-
21.
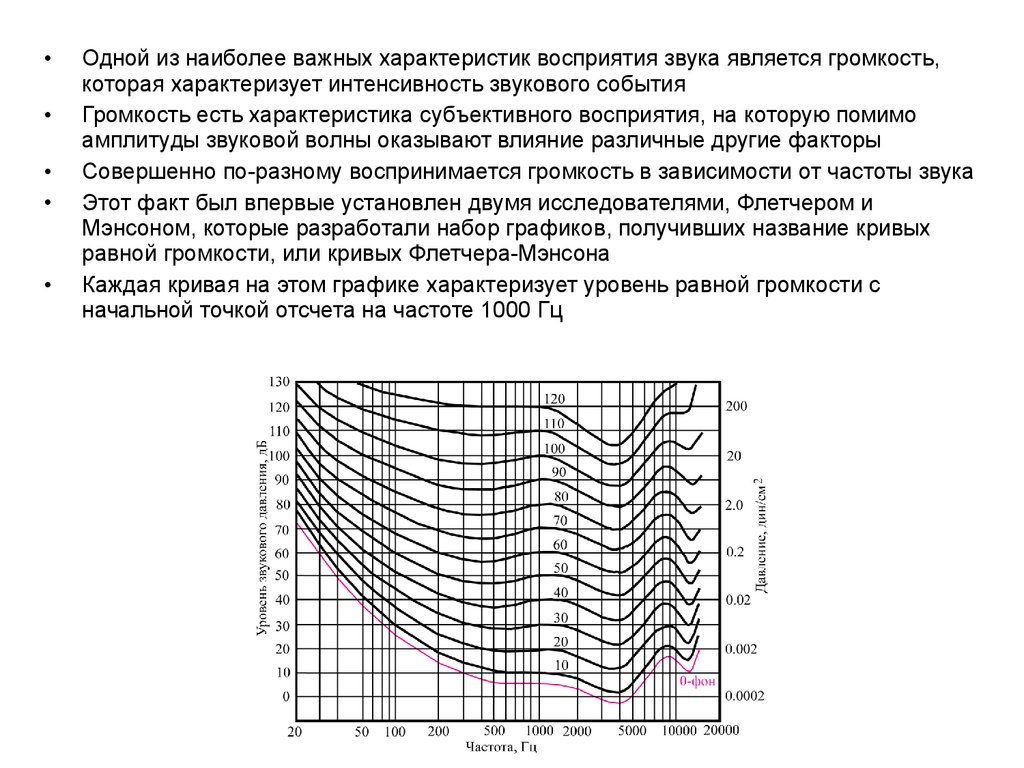
Одной из наиболее важных характеристик восприятия звука является громкость,
которая характеризует интенсивность звукового события
Громкость есть характеристика субъективного восприятия, на которую помимо
амплитуды звуковой волны оказывают влияние различные другие факторы
Совершенно по-разному воспринимается громкость в зависимости от частоты звука
Этот факт был впервые установлен двумя исследователями, Флетчером и
Мэнсоном, которые разработали набор графиков, получивших название кривых
равной громкости, или кривых Флетчера-Мэнсона
Каждая кривая на этом графике характеризует уровень равной громкости с
начальной точкой отсчета на частоте 1000 Гц
22.
Кривые равной громкости (изофоны) были получены учеными Флетчером и Мэнсоном в результате обработки данных большого
числа экспериментов, проведенных ими среди нескольких сотен посетителей Всемирной выставки 1931 года в Нью-Йорке
В настоящее время в международном стандарте ISO 226 (1987 г.) приняты уточненные данные измерений, полученные в 1956 году
Изофоны представляют собой графики зависимостей уровня звукового давления от частоты при заданном уровне громкости
Фон - единица для оценки уровня громкости звука
С помощью этих кривых можно определить уровень громкости чистого тона какой-либо частоты, зная уровень создаваемого им
звукового давления
Самая нижняя кривая примерно соответствует громкости 3 фон и описывает абсолютный порог слышимости (ATH[1000 Гц] = 3,369
дБ SPL)
Кривые равной громкости показывают, какая требуется разница в уровне звукового давления, чтобы звуки всех частот
воспринимались с такой же громкостью, как референсный синусоидальный сигнал с частотой 1 кГц
Числа, находящиеся над каждой кривой, представляют собой меру громкости, выраженную в фонах, на референсной частоте 1
кГц фоны равны децибелам, т.е. y чистого тона с частотой 1 кГц уровень в фонах численно равен уровню звукового давления в
децибелах
К примеру, при очень низком уровне громкости 30 фон (30 дБ SPL на частоте 1 кГц) басовый тон 50 Гц должен воспроизводиться с
уровнем 60 дБ SPL, чтобы он воспринимался с такой же громкостью, как звук 30 дБ SPL с частотой 1 кГц, т.е. ухо человека менее
чувствительно в области низких и высоких частот, нежели на средних частотах
23.
Уровень громкости может измеряться также в сонах
Преимущество оценки уровней в сонах состоит в том, что для звука из нескольких
компонентов, сильно разнесенных по частоте, общий уровень громкости в сонах,
равен сумме уровней каждой из компонентов
Существует однозначная связь между уровнями громкости чисто тонального звука в
сонах и фонах
На рис. показана зависимость уровня громкости в сонах тонального звука частоты 1
кГц (сплошная линия) и белого шума (точечная линия) от уровня звукового
давления
Уровень 1 сон соответствует громкости чистого тона частоты 1000 Гц с уровнем 40
дБ
При увеличении уровня громкости
на 10 фонов громкость звука в
сонах возрастает в 2 раза, это
значит, что уровням громкости 40,
50 и 60 фон соответствуют
громкости 1, 2 и 4 сон
На уровнях ниже 40 фон,
изменение уровня в сонах
происходит намного быстрей,
уровень 3 фон, соответствующий
абсолютному порогу слышимости,
равен 0 сон
24.
Разновидности шумов и их спектрыВ профессиональной литературе рассматриваются несколько различных по
спектру разновидностей шумов
•Белый шум обладает постоянной спектральной плотностью на всей
протяженности спектра
•Розовый шум, спектральная плотность которого уменьшается на 3 дБ с каждой
последующей октавой
•Оранжевый шум, спектральная плотность которого квазипостоянна и имеет
полоски нулевой энергии, рассеянные на всей протяженности спектра; такие
полоски располагаются около частот, соответствующих музыкальным нотам
•Зеленый шум подобен розовому шуму с усиленной областью в районе 500 Гц
•Синий шум, спектральная плотность которого увеличивается на 3 дБ с каждой
последующей октавой
•Фиолетовый шум или дифференцированный белый шум, спектральная плотность
которого увеличивается на 6 дБ с каждой последующей октавой
•Серый шум, спектр имеет форму, аналогичную графику психоакустической кривой
порога слышимости
•Коричневый шум, спектральная плотность которого уменьшается на 6 дБ с
каждой последующей октавой
•Тональный шум, в спектре которого имеются слышимые дискретные тоны
•Черный шум имеет постоянную конечную спектральную плотность за пределами
частотного порога слышимости, равного 20 кГц
25.
Частотное (одновременное) маскированиеС механизмом критических полос слуха человека связаны свойства межполосового и
внутри полосового частотного маскирования
Под маскированием понимают ситуацию, при которой один звук становится
неслышимым из-за присутствия другого звука (см. рис.)
С целью оптимального расчета порога маскирования следует различать два вида
частотного маскирования: тон-шум и шум-тон
В первом случае тональный сигнал, расположенный в центре критической полосы,
маскирует шум в пределах ширины полосы или некоторой ее окрестности
Во втором случае, наоборот, маскирующим сигналом является шум, а маскируемым –
тон
26.
Частотное (одновременное) маскированиеЭффект маскирования упрощенно можно объяснить тем, что сильный тональный или
шумовой маскер создает очаг возбуждения на участке базилярной мембраны,
соответствующем критической полосе, это возбуждение препятствует ощущению
более слабого сигнала
Порог маскирования снижается при увеличении разницы частот маскирующего и
маскируемого сигналов
Данное явление называют распространением маскирования, в алгоритмах
кодирования часто моделируется треугольной функцией распространения (Spreading
Function, SF) с наклоном +25 и -10 дБ/барк
Для более точного представления функции распространения используется
выражение (x – разность частот маскируемого и маскирующего сигналов в [барк]):
SF ( x) =15,81 +7,5( x +0, 474) - 17,5 1 +( x +0, 474) 2 ,дБ
27.
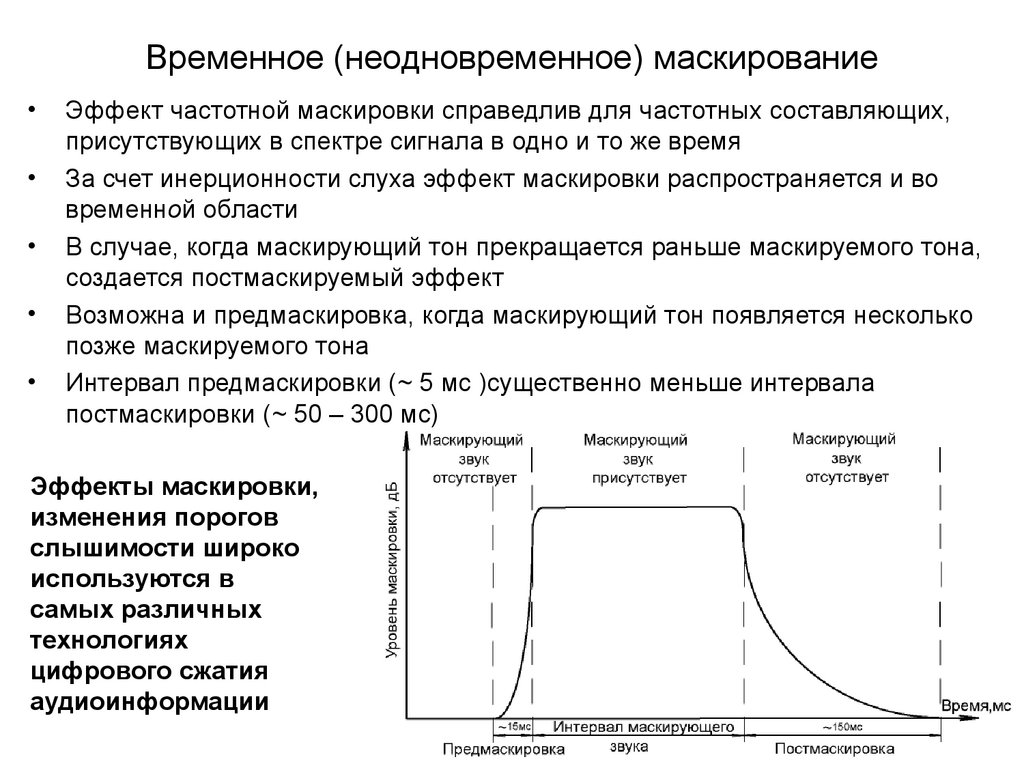
Временное (неодновременное) маскированиеЭффект частотной маскировки справедлив для частотных составляющих,
присутствующих в спектре сигнала в одно и то же время
За счет инерционности слуха эффект маскировки распространяется и во
временной области
В случае, когда маскирующий тон прекращается раньше маскируемого тона,
создается постмаскируемый эффект
Возможна и предмаскировка, когда маскирующий тон появляется несколько
позже маскируемого тона
Интервал предмаскировки (~ 5 мс )существенно меньше интервала
постмаскировки (~ 50 – 300 мс)
Эффекты маскировки,
изменения порогов
слышимости широко
используются в
самых различных
технологиях
цифрового сжатия
аудиоинформации
28.
Огибающая и мгновенная частота звуковых сигналовПо форме огибающей и изменению мгновенной частоты звуковых сигналов
производится анализ переходных процессов в преобразователях
акустической энергии в ее электрический эквивалент, при обработке и
восстановлении аудиосигналов
Оценка этих характеристик звуковых сигналов осуществляется с
использованием двух сигналов: исходного u(t) и сопряженного с ним по
Гильберту uГ(t):
1 u ( )
1 u Г ( )
u Г (t )
d ; u (t )
d
t
t
Пусть функция u(t) ограничена по спектру частотой fгр и определена
дискретными отсчетами u(nT), 0 ≤ n ≤ N-1. Положим также, что интервал
между отсчетами в соответствии с теоремой Котельникова определяется
соотношением Т = tn+1-tn ≤ 1/2fгр. Тогда форму сигнала и его спектр можно
представить в виде:
N 1
N 1
sin v(t , n)
u (t ) u (nT )
; Fu ( f ) ( f ) u (nT ) exp[ 2 j Tfn]
v(t , n)
n 0
n 0
1, 0 f f гр ;
v(t , n) (t n T ); t ; ( f ) 1 / 2,
f f гр ;
T
f f гр .
0,
29.
Форма преобразованного по Гильберту сигнала и его спектра в данном
случае определяются следующими соотношениями:
N 1
1 cos v(t , n)
u Г (t ) u (nT )
; Fu Г ( f ) jFu ( f )
v(t , n)
n 0
Огибающая и изменение фазы звукового сигнала рассчитываются по
формулам:
u (t )
U ог (t ) u 2 (t ) u Г2 (t ) ; (t ) Arctg Г
u (t )
Мгновенная частота определяется производной фазы:
du Г (t )
1 d (t )
1 u (t ) u Г (t ) u (t ) u Г (t )
du (t )
f мгн (t )
u
(
t
)
;
u
(
t
)
Г
2 dt
2
dt
dt
u 2 (t ) u Г2 (t )
Производные исходного и сопряженного по Гильберту сигналов и их спектры
определяются следующими формулами:
N 1
cos v(t , n) sin v(t , n)
u (t ) u (nT )
2
; Fu ( f ) 2 j fT Fu ( f )
v (t , n)
n 0
v(t , n)
N 1
sin v(t , n) 1 cos v(t , n)
u Г (t ) u (nT )
; Fu Г ( f ) 2 fT Fu ( f )
2
v (t , n)
n 0
v(t , n)
30.
Приведенные преобразования сигналов и их спектров можно использовать
для расчетов огибающей и мгновенной частоты звукового сигнала с
применением быстрых прямого и обратного преобразований Фурье (БПФ и
ОБПФ)
В данном случае с помощью БПФ формируются спектральные отсчеты Fu(m)
дискретного сигнала u(n). Затем спектральные отсчеты производной
исходного сигнала, гильбертовой составляющей и ее производной
формируются путем перемножения Fu(m) на соответствующие
коэффициенты, формирование всех необходимых сигналов осуществляется
с использованием ОБПФ
31.
В качестве примера приведена диаграмма обозначенного синим цветом сигнала,
состоящего из пяти косинусоидальных колебаний различных частот с различными
начальными фазами и имитирущего небольшой отрезок речи; на этом же рисунке
красным цветом изображена сопряженная по Гильберту составляющая этого сигнала
Ниже приведены диаграммы огибающей этого сигнала и изменения мгновенной
частоты
Если уровень огибающей сигнала близок к нулю, то изменение мгновенной частоты
приобретает скачок значительной величины, что практически не может ощущаться на
слух; по этой причине при расчете мгновенной частоты квадрат огибающей
ограничивается некоторой величиной (в данном случае v=0,02)
u 2 (t ) u Г2 (t ), U ог2 (t ) v;
U (t )
2
v
,
U
(t ) v,
ог
2
ог
Большие выбросы
мгновенной частоты и ее
отрицательные значения
возникают в минимумах
огибающей звукового
сигнала
32.
Пространственное восприятие звуковых сигналовЛокационные способности восприятия звука, так называемый
бинауральный эффект, объясняются фазовым смещением звуковых волн,
неодинаковым уровнем звуковых давлений в ушах, особенностями тембров
знакомых источников звуков и их изменений
При неподвижном источнике звука слух способен определить направление
движения звуковых волн по горизонтали не точнее 12 градусов, а по
вертикали - 17...20 градусов
Бинауральный эффект практически отсутствует на частотах ниже 300 Гц, на
частотах от 300 до 1000 Гц становится заметным сдвиг фаз звуковых волн,
попадающих в правое и левое ухо, при частотах более 1000 Гц сдвиг фаз
становится очень небольшим и поиск направления осуществляется за счет
сравнения силы звука, приходящего с разных сторон
33.
На рис. поясняется эффект интегральной локализации восприятия информации от двух
источников звука
Два одинаковых источника (1 и 2), расположенные на расстоянии 2L y один от другого, а на
расстоянии Lx расположен слушатель, уши которого находятся на расстоянии r 1 и r2 от
соответствующих источников
Если на оба источника излучают звуковую энергию одинаковой мощности, то звук от каждого
источника достигнет ушей одновременно и идентичность звуков не позволит слуху разделить
их в пространстве, например, на левый и правый; при этом возникает иллюзия: виртуальный
(кажущийся) источник звука как бы находится в середине между источниками звука
Если уменьшить мощность излучения одного из источников, то это воспринимается как
перемещение кажущегося источника в сторону второго источника; таким образом, варьируя
громкость звучания левого и правого источника, можно вызывать и поддерживать иллюзию
перемещения виртуального источника звука
Аналогичная иллюзия перемещения виртуального источника возникает, если создать
запаздывание звука в одного из источников
Оба эти эффекта широко используются при цифровой обработке и записи музыки
34.
При задержках одного из сигналов на время более 50 мс наличие
запаздывающего сигнала ощущается как помеха в виде эха. Опережающий
сигнал при одинаковом уровне с задержанным в этом случае подавляет
(маскирует) последний. Повышая уровень запаздывающего сигнала, можно
добиться того, что оба источника звука будут восприниматься раздельно
даже при запаздывании менее 50 мс
На рисунке показано необходимое превышение уровня ( N, дБ)
запаздывающего сигнала в зависимости от временной задержки.
При t = 15...20 мс уровень задержанного сигнала должен быть повышен на 11
дБ, чтобы оба источника звука воспринимались раздельно. При t < 50 мс для
этого эффекта достаточно превышение уровня всего на 6 дБ.
При t < 5 мс наблюдается неустойчивый режим: виртуальный источник звука
как бы перепрыгивает из одного источника в другой, совпадая то с
источником опережающего, то с источником задержанного сигнала
35.
Для качественного восприятия реального пространственного звучания
музыкальных программ использование двухканальной (стереофонической)
системы воспроизведения звуковых сигналов не всегда является
достаточным
Основная причина этого кроется в том, что стерео сигнал, приходящий к
слушателю от двух физических источников звука, определяет расположение
мнимых источников лишь в той плоскости, в которой расположены реальные
физические источники звука
Поэтому в последние десятилетия стали развиваться системы
многоканального воспроизведения звука, реализующие так называемый
трансуральный эффект
Для воссоздания более или менее реалистичного, действительно объемного
звучания прибегают к применению сложных приемов, моделирующих
особенности слуховой системы человека, а также физические особенности и
эффекты передачи звуковых сигналов в пространстве. Главная проблема
заключается в том, чтобы создать такой сигнал, который бы при помощи двух
или более источников звука воспринимался слушателем как трехмерный
36.
Основные принципы цифровых преобразованийзвуковых сигналов
Преобразование аналогового звукового сигнала путем временной дискретизации и
квантования выбранных дискретных его значений неизбежно приводит к
невозможности его абсолютно точного восстановления
Если предположить, что аналоговый сигнал строго ограничен по спектру, то в
соответствии с теоремой Котельникова он полностью определяется дискретной
последовательностью своих мгновенных значений, взятых с частотой выборки fд как
минимум вдвое превышающей граничную частоту спектра: fд ≥ 2fгр
Квантование дискретных отсчетов сигнала вызывает шумовые искажения, величина
которых зависит от разрядности аналого-цифрового преобразователя (АЦП), типа
преобразуемого сигнала и формы шкалы квантователя
Следует заметить, что при дискретизации сигнала с частотой fд > 2fгр спектр шума
квантования распространяется вплоть до частоты fд/2 и при восстановлении сигнала с
помощью ФНЧ с граничной частотой примерно равной fгр, уровень шума может быть
уменьшен
При равномерной дискретизации сигнала с числом уровней квантования 2 N отношение
сигнал/шум (динамический диапазон АЦП) оценивают в дБ по формуле (C –
константа, зависящая от формы преобразуемого сигнала):
fд
f
С 6 N 10 lg д С
2 f грсинусоидального
2 fсигнала
гр
При преобразовании
C = 1,7 дБ, для звуковых сигналов
S 20 N lg 2 10 lg
константа C изменяется от -15 дБ до 2 дБ
37.
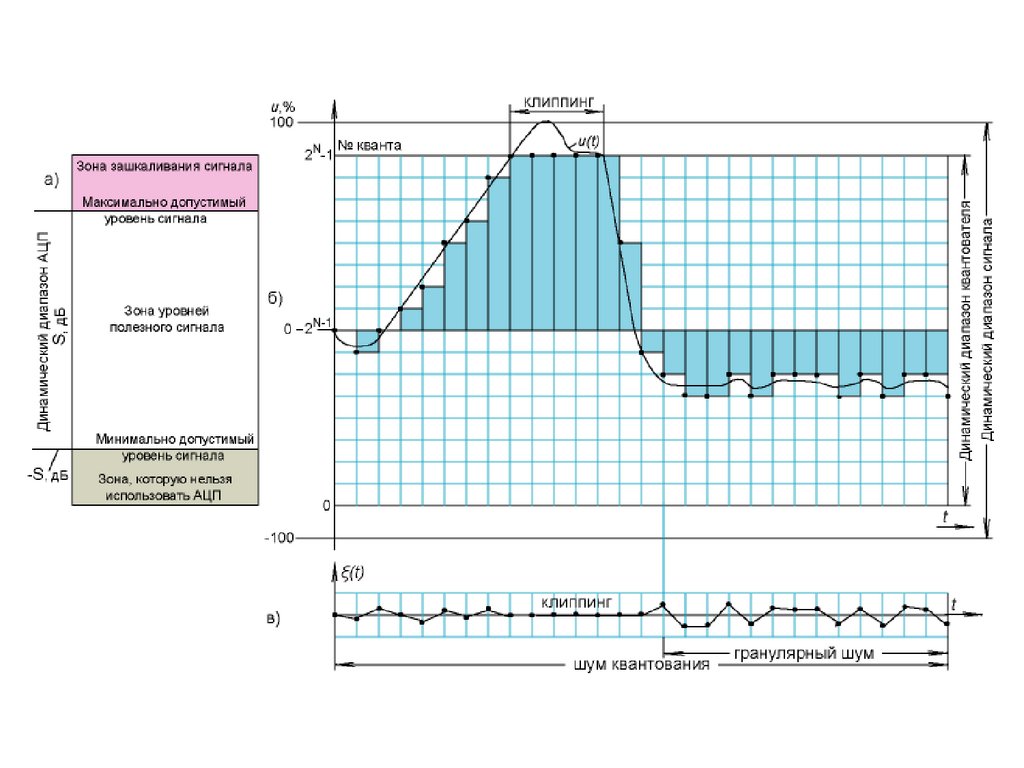
Принято, что в звуковой аппаратуре максимально допустимый уровень
сигнала соответствует 0 дБ. В связи с этим величина –S характеризует
уровень шумов квантования и одновременно минимально возможный
уровень полезного сигнала. Из приведенного выше соотношения следует, что
при fд = 4fгр интенсивность шума уменьшится на 3 дБ
На рисунке приведена диаграмма уровней сигнала при аналого-цифровом
преобразовании. Очевидно, что отсчеты сигнала не должны превышать
некоторого заданного максимально допустимого уровня. В противном случае
квантователь «обрезает» сигнал. Это явление называют клиппингом (англ.
сlipping). На рисунке иллюстрируется также формирование шума
квантования. При цифровом преобразовании аналогового сигнала u(t)
различия между его истинными значениями в точках дискретизации и
цифровыми отсчетами и определяют шум квантования. Специфическим
видом шума квантования является гранулярный шум (granular noise),
проявляющийся в следствие нестабильности операции округления, когда
уровень аудиосигнала незначительно изменяется и располагается
приблизительно посредине между двумя ближайшими уровнями квантования
j и j+1
38.
39.
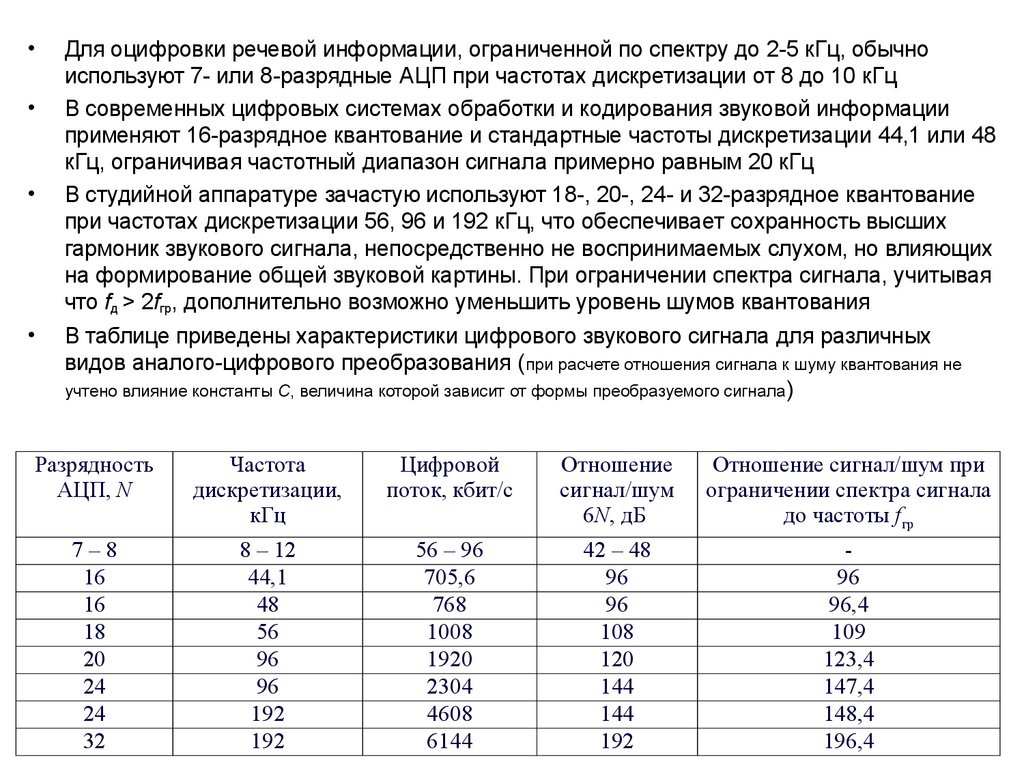
Для оцифровки речевой информации, ограниченной по спектру до 2-5 кГц, обычно
используют 7- или 8-разрядные АЦП при частотах дискретизации от 8 до 10 кГц
В современных цифровых системах обработки и кодирования звуковой информации
применяют 16-разрядное квантование и стандартные частоты дискретизации 44,1 или 48
кГц, ограничивая частотный диапазон сигнала примерно равным 20 кГц
В студийной аппаратуре зачастую используют 18-, 20-, 24- и 32-разрядное квантование
при частотах дискретизации 56, 96 и 192 кГц, что обеспечивает сохранность высших
гармоник звукового сигнала, непосредственно не воспринимаемых слухом, но влияющих
на формирование общей звуковой картины. При ограничении спектра сигнала, учитывая
что fд > 2fгр, дополнительно возможно уменьшить уровень шумов квантования
В таблице приведены характеристики цифрового звукового сигнала для различных
видов аналого-цифрового преобразования (при расчете отношения сигнала к шуму квантования не
учтено влияние константы C, величина которой зависит от формы преобразуемого сигнала )
Разрядность
АЦП, N
Частота
дискретизации,
кГц
Цифровой
поток, кбит/с
Отношение
сигнал/шум
6N, дБ
Отношение сигнал/шум при
ограничении спектра сигнала
до частоты fгр
7–8
16
16
18
20
24
24
32
8 – 12
44,1
48
56
96
96
192
192
56 – 96
705,6
768
1008
1920
2304
4608
6144
42 – 48
96
96
108
120
144
144
192
96
96,4
109
123,4
147,4
148,4
196,4
40.
В таблице приведены параметры цифрового потока импульсно-кодовой модуляции
(ИКМ) монофонического сигнала. При преобразовании стереофонического или
квадрофонического звукового сигнала величина цифрового потока должна быть
увеличена в два или четыре раза соответственно
Очевидно, чтобы влияние шумов квантования было не очень большим, необходимо
максимально использовать весь динамический диапазон АЦП, поддерживая уровень
преобразуемого аналогового сигнала в определенных границах. Этот процесс
реализуется путем использования компандеров, обеспечивающих обработку динамично
изменяющегося уровня звукового сигнала. Однако этот метод не всегда приводит к
положительным результатам, особенно в тех случаях, когда в течение некоторого
времени звуковая информация попеременно изменяется от тихой к громкой. В этих
случаях прибегают к иным методам уменьшения влияния шума квантования
Один из них, называемый дизерингом (от англ. «dithering» - «дрожание») используется в
тех случаях, когда шум существенно зависит от преобразуемого сигнала и проявляется
на слух в виде специфической мешающей помехи (что практически всегда имеет место).
Принцип дизеринга заключается в добавлении к преобразованному сигналу
псевдослучайной последовательности малого по уровню (не более двух дискретных
значений) шума, реализуя тем самым практически полную независимость шума от
исходного сигнала, что для слуха является более приемлемым
Другой принцип снижения влияния связанных с формой сигнала шумов квантования,
называемый методом формовки шума (noise shaping), заключается в преобразовании
спектра шума таким образом, чтобы большая часть его энергии располагалась в менее
заметных для слуха областях спектра в соответствии с формой кривых равной
громкости
41.
Применение рассмотренных методов преобразования шумов квантования не
всегда рационально, особенно в случаях необходимости дальнейшей
обработки аудиосигналов
Поэтому чаще всего для уменьшения влияния шумов квантования обработку
аудиосигналов производят с применением АЦП с большей разрядностью при
более высокой частоте дискретизации
При этом чем выше частота дискретизации, тем большие требования
предъявляются к ее стабильности, поскольку несовершенства
преобразующей аппаратуры, приводящие к случайным временным
отклонениям дискретизирующих импульсов вызывают эффект джиттера (от
англ. «jitter» - «дрожание»)
Для борьбы с джиттером применяются высокостабильные кварцевые
генераторы
42.
Аналого-цифровое и цифро-аналоговое преобразованиезвуковых сигналов
Кодирующее и декодирующее устройства на входе и выходе оперируют с
аналоговыми сигналами, преобразование которых в цифровой код и их
восстановление являются важнейшими этапами обработки информации.
Сигналы на выходе декодера даже при отсутствии линейной и нелинейной
обработки информации практически никогда не совпадают по форме с
сигналами, поступающими на вход кодера. Ниже приводятся наиболее
широко используемые варианты преобразования звуковых сигналов:
Импульсно-кодовая модуляция (ИКМ)
Дифференциальная импульсно-кодовая модуляция (ДИКМ)
–
–
–
дельта-модуляция
адаптивная дельта-модуляция
адаптивная относительная импульсно-кодовая модуляция
Сигма-дельта модуляция (СДМ)
43.
Импульсно-кодовая модуляция (ИКМ)ИКМ – наиболее простой способ преобразования сигналов, обычно
содержащий в кодере многоразрядный АЦП (чаще с линейной шкалой
квантования) и в декодере ЦАП, имеющий такую же разрядность
Если число N – разрядность АЦП, а частота дискретизации сигнала равна fд,
то формируемый цифровой поток определяется их произведением N∙ fд
кбит/с
На выходе ЦАП при этом последовательно с частотой дискретизации fд
выделяются импульсные дискретные значения звукового сигнала. Каждый из
этих почти прямоугольных импульсов длительностью τ=1/ fд обладает sincспектром , плавно изменяющимся от 1 на частоте f = 0 до 2/π на частоте fд/2
sin f / f д
F ( f ) sin c f / f д
f / f д
Если частота дискретизации мало отличается от удвоенной величины
граничной частоты преобразуемого сигнала fд ≈ 2 fгр, то спектральные
составляющие сигнала в области граничной частоты оказываются
значительно ослабленными. Устранение этого эффекта возможно либо
путем использования ФНЧ с соответствующим подъемом частотной
характеристики в области граничной частоты сигнала, либо с применением
sinc-предкоррекции дискретных отсчетов АЦП
44.
Sinc-предкоррекцияФорма частотной характеристики предкорректирующей цепи
определяется формулой:
f / f д
Fпр ( f )
a0 2 ai cos( 2i f / f д )
sin f / f д
i 1
где
4
4
a 0 G , ai G
( 1) k
,
2
k 0 ( 2k 1)
i 1
( 1) k
G
0,915965594... - постоянная Каталана
2
k 0 ( 2k 1)
Ряд достаточно быстро сходится, по этой причине можно ограничиться
конечным числом его членов. С точностью выше 0,1 % процесс
предварительной коррекции реализуется в соответствии с соотношением:
4
u (n) a0 u (n) ak [u (n k ) u (n k )]
k 1
где a0 = 1,1662, a1 = -0,1070, a2 = 0,0345, a3 = -0,0165, a4 = 0,0095.
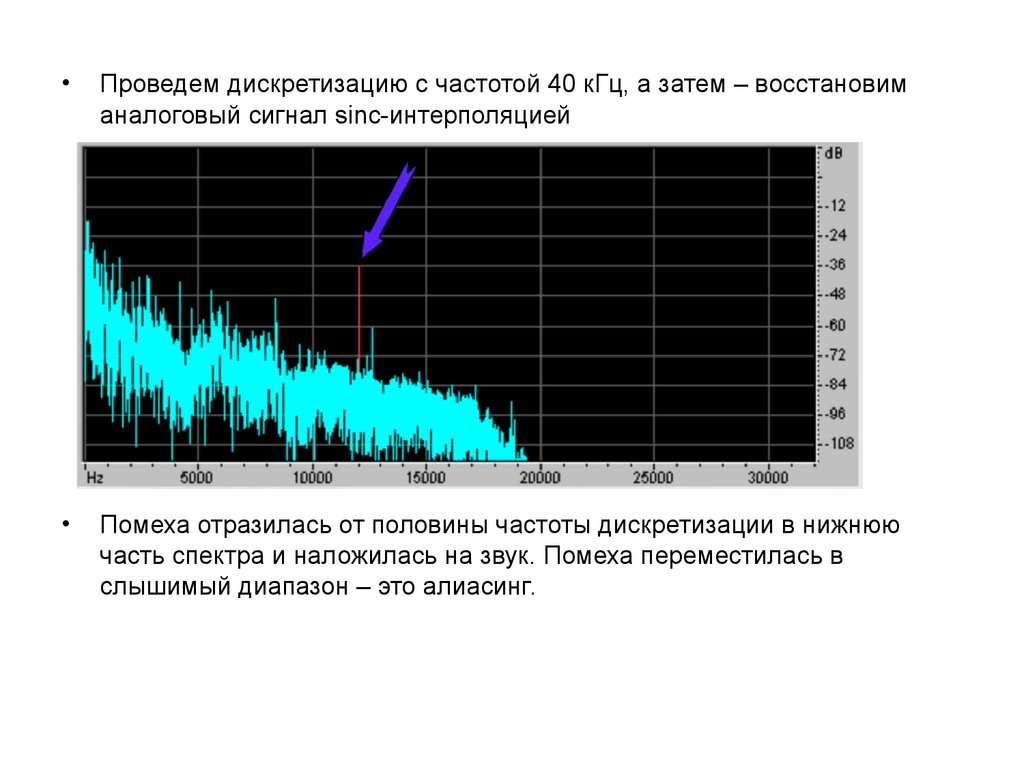
45. Алиасинг
Пусть звук не содержит частот выше 20 кГц. Тогда, по теореме
Котельникова, можно выбрать частоту дискретизации 40 кГц.
Пусть в звуке появилась помеха с частотой 28 кГц. Условия теоремы
Котельникова перестали выполняться.
46.
Проведем дискретизацию с частотой 40 кГц, а затем – восстановим
аналоговый сигнал sinc-интерполяцией
Помеха отразилась от половины частоты дискретизации в нижнюю
часть спектра и наложилась на звук. Помеха переместилась в
слышимый диапазон – это алиасинг.
47.
• Как избежать алиасинга? Применить передоцифровкой анти-алиасинговый фильтр. Он подавит
все помехи выше половины частоты дискретизации
(выше 20 кГц) и пропустит весь сигнал ниже 20 кГц.
• После этого условия теоремы Котельникова будут
выполняться и алиасинга не возникнет.
Следовательно, по цифровому сигналу можно будет
восстановить исходный аналоговый сигнал.
48.
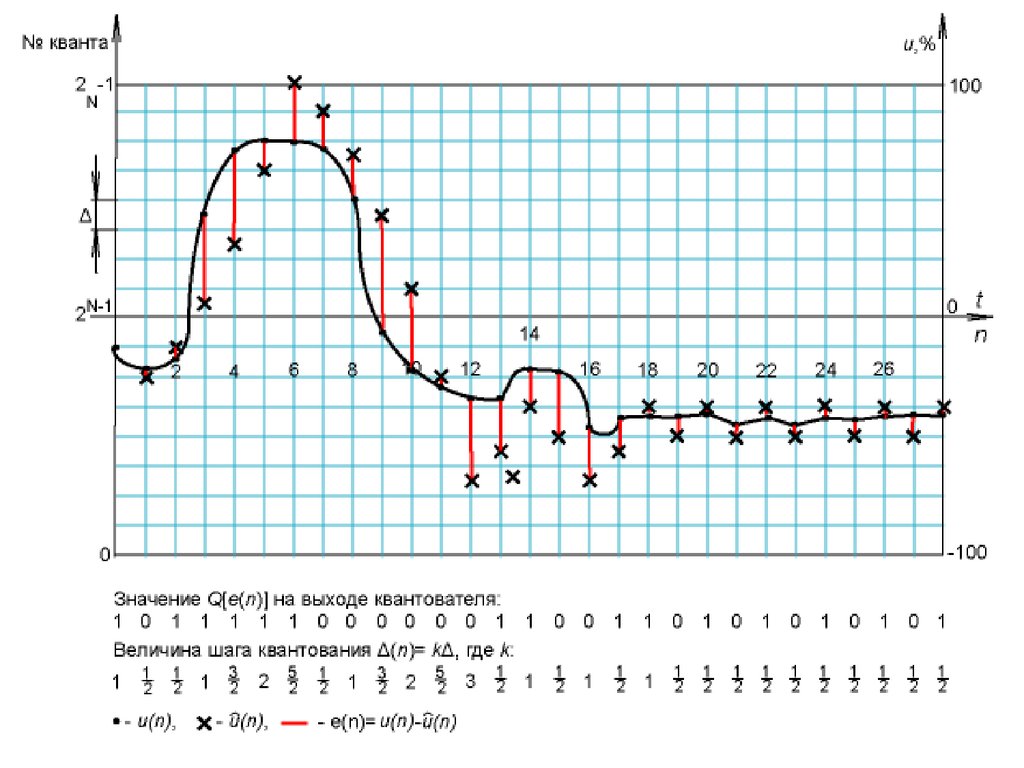
Дифференциальная импульсно-кодовая модуляция (ДИКМ)На вход квантователя последовательно подаются отсчеты не исходного
сигнала, а разность между его текущим значением и предсказанной
~
величиной e(n) u (n) u (n)
При использовании метода линейного предсказания величина u~ (n)
K
определяется соотношением
~
u (n) ak uˆ (n k )
k 1
где K и ak – порядок и коэффициенты предсказания, uˆ (n k ) – отсчеты
сигнала, полученные на предыдущих шагах преобразования исходных
величин u(n-k)
Формирование величин uˆ (n) определяется принципом кодирования
информации о разностной величине e(n) и с учетом поправки Q[e(n)]
uˆ (n) u~ (n) Q[e(n)]
Величины коэффициентов предсказания зависят от корреляционных свойств
преобразуемой аудиоинформации и подбираются опытным путем.
Например, при оцифровке речевой информации может быть использован
предсказатель пятого порядка с коэффициентами
a1=0,86; a2=0,64; a3=0,40; a4=0,26; a5=0,20
49.
Наиболее простым способом кодирования с предсказанием является
дельта-модуляция (ДМ), реализуемая с помощью однобитного
квантователя. Ошибка предсказания e(n) и поправка Q[e(n)] определяются
соотношениями:
1, при e(n) 0;
e(n) u (n) uˆ (n 1); Q[e(n)]
0, при e(n) 0.
Принцип формирования сигнала на выходе декодирующего устройства
заключается в следующем:
- если величина Q[e(n)]=1, то значение отчета выходного сигнала
вычисляется по формуле uˆ (n) uˆ (n 1) , где Δ – некоторое дискретное
приращение сигнала;
- при Q[e(n)]=0 результат преобразования отсчета имеет вид uˆ (n) uˆ (n 1)
Применение такого вида преобразования приводит к двум видам искажений
– перегрузке крутизны (или наклонной перегрузке), связанной с
неспособностью кодирующего устройства реагировать на быстрые
изменения величин отсчетов аудиосигнала, и появлению гранулярного
шума. В связи с этим использование дельта-модуляции эффективно при
высокой корреляции соседних отсчетов сигнала и применяется при
повышенных частотах дискретизации звуковых сигналов
50.
51.
Более эффективно использование адаптивной дельта-модуляции (АДМ),
при которой в зависимости от характера поступающих на вход кодирующего
устройства отсчетов сигнала изменяется шаг квантования
Наиболее простой способ изменения шага квантования поясняется следующим
примером
На начальном этапе преобразования в качестве исходного шага квантования
принимаются значение поправки Q[e(n)]=1 и величина шага квантования Δ(0)=Δ
Последующее изменение шага квантования осуществляется, например, в
соответствии с формулой:
(n 1) / 2, если Q[e(n)] Q[e(n 1)];
(n)
Кроме того,
(n 1) / 2, если Q[e(n)] Q[e(n 1)].
Рисунок иллюстрирует
(n) / 2 более эффективное кодирование быстро
изменяющегося сигнала и частичную компенсацию нежелательного эффекта
перегрузки крутизны. Гранулярный шум также компенсируется за счет
автоматического уменьшения шага квантования на каждом новом этапе
преобразования
52.
53.
Еще большая эффективность кодирования аудиоинформации может быть
получена при квантователе, использующем предсказание более высокого
порядка и реализуемом адаптивной относительной импульсно-кодовой
модуляции АОИКМ
Пример одно из вариантов АОИКМ:
Шаг квантования Δ(n) зависит от результата кодирования на предыдущем
шаге Δ(n)=M·Δ(n-1), а функция квантования Q[e(n)] зависит от величины Δ(n)
и передается на декодер тремя битами
Значение коэффициента М, увеличивающего или уменьшающего шаг
квантования определяется следующим соотношением:
0,5
1,5
M
2,5
3,5
при
0 e(n 1) (n 1);
при
(n 1) e(n 1) 2 (n 1);
при
2 (n 1) e(n 1) 3 (n 1);
при
3 (n 1) e(n 1) .
Данная схема эффективна, весьма проста и легко реализуется в цифровом
виде. Существуют более сложные и более эффективные схемы реализации
АОИКМ с многобитной функцией квантования Q[e(n)]
54.
Сигма-дельта модуляция (СДМ)Основой сигма-дельта модуляции является не анализ приращений сигнала, а
кодирование уровней самого преобразуемого сигнала, как при ИКМ
Структурная схема сигма-дельта модулятора приведена на рисунке
На вход модулятора подаются дискретные отсчеты сигнала u(n),
относительные уровни которых могут изменяться в пределах от –1 до +1
55.
Кодер содержит однобитовый квантователь, на выходе которого
формируется сигнал:
1, если v2 (n) 0;
Q( n)
1, если v2 (n) 0,
где v2(n) – дискретные отсчеты сигнала на входе квантователя,
формируемые следующим образом:
вычитатель, включенный на входе устройства обеспечивает формирование
разности отсчетов входного сигнала u(n) и выходного сигнала квантователя
Q(n): v1(n) = u(n) – Q(n);
отсчеты разностного сигнала v1(n) подаются на сумматор с выхода которого
отсчеты сигнала v2(n) поступают параллельно на входы квантователя и блока
памяти БП1;
с выхода блока БП1 с задержкой на такт отсчеты сигнала подаются на вход
блока памяти БП2, на выходе которого выделяются отсчеты сигнала
предыдущего такта v2(n - 1), которые поступают на второй вход сумматора;
таким образом, на вход квантователя подается сигнал v2(n) = v1(n) + v2(n - 1).
Формирователь кода, включенный на выходе квантователя, создает
цифровую последовательность в соответствии с соотношением:
1, если Q (n) 1;
N ( n)
0, если Q (n) 1.
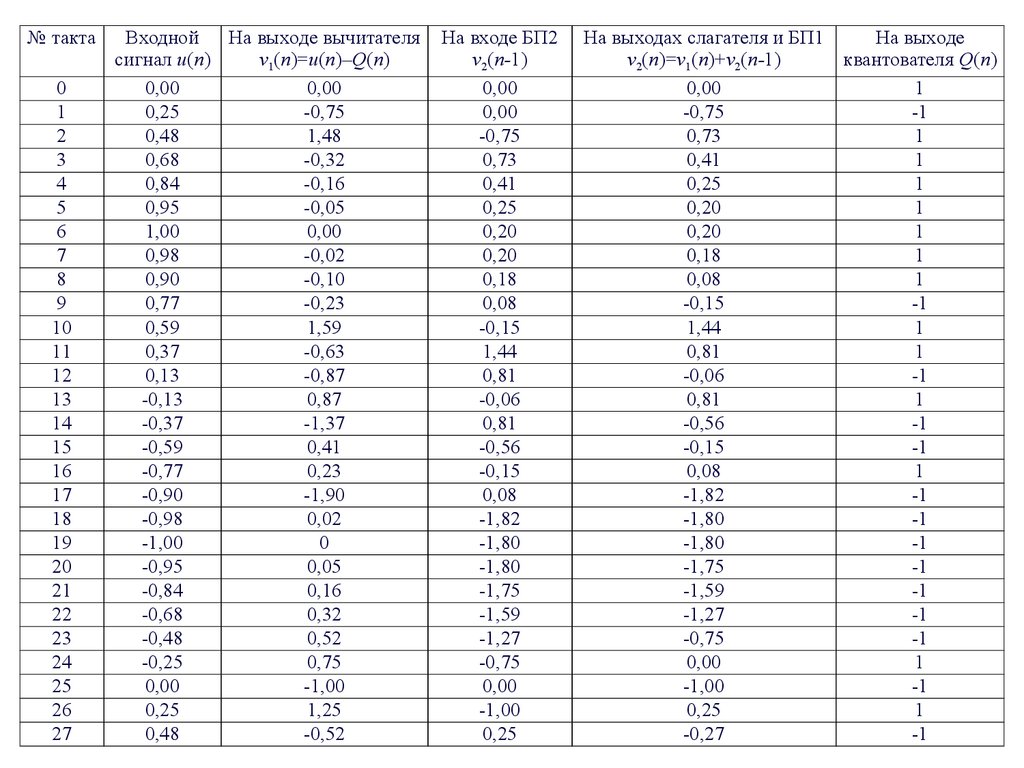
56.
№ такта0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
Входной На выходе вычитателя
сигнал u(n)
v1(n)=u(n)–Q(n)
0,00
0,00
0,25
-0,75
0,48
1,48
0,68
-0,32
0,84
-0,16
0,95
-0,05
1,00
0,00
0,98
-0,02
0,90
-0,10
0,77
-0,23
0,59
1,59
0,37
-0,63
0,13
-0,87
-0,13
0,87
-0,37
-1,37
-0,59
0,41
-0,77
0,23
-0,90
-1,90
-0,98
0,02
-1,00
0
-0,95
0,05
-0,84
0,16
-0,68
0,32
-0,48
0,52
-0,25
0,75
0,00
-1,00
0,25
1,25
0,48
-0,52
На входе БП2
v2(n-1)
0,00
0,00
-0,75
0,73
0,41
0,25
0,20
0,20
0,18
0,08
-0,15
1,44
0,81
-0,06
0,81
-0,56
-0,15
0,08
-1,82
-1,80
-1,80
-1,75
-1,59
-1,27
-0,75
0,00
-1,00
0,25
На выходах слагателя и БП1
На выходе
v2(n)=v1(n)+v2(n-1)
квантователя Q(n)
0,00
1
-0,75
-1
0,73
1
0,41
1
0,25
1
0,20
1
0,20
1
0,18
1
0,08
1
-0,15
-1
1,44
1
0,81
1
-0,06
-1
0,81
1
-0,56
-1
-0,15
-1
0,08
1
-1,82
-1
-1,80
-1
-1,80
-1
-1,75
-1
-1,59
-1
-1,27
-1
-0,75
-1
0,00
1
-1,00
-1
0,25
1
-0,27
-1
57.
58.
• Преимущества СДМ:– Простая техническая реализация (по сравнению с ИКМ с линейным многобитным
квантователем)
– Вследствие применения более высоких частот дискретизации, по сравнению с
ИКМ, шум квантования простирается на более широкую полосу
44,1 кГц / 16 бит – шум в полосе до 22,05 кГц
СДМ 705,6 кГц – шум в полосе до 352,8 кГц (44,1х16=705,6)
• Недостатки СДМ
– Высокая частота дискретизации для достижения высокого качества кодирования
• СДМ также называют модуляцией плотностью импульсов (PDM –
pulse density modulation)
• Формат СДМ легко может быть преобразован в формат ИКМ
• Стандарт SADC (Super Audio CD) (Sony, Phillips, 1997): частота
дискретизации – 2,8224 МГц на канал
59.
Принципы кодирования речевой и звуковой информацииОцифрованный аудиосигнал в форме одной из вариаций ИКМ является
практически точной копией, но не компактной формой записи исходного
аналогового сигнала. Поэтому преобразование относительно больших
объемов аудиоданных, гарантирующих необходимое качество
воспроизведения различных видов звуковой информации, требует
применения различных методов кодирования, позволяющих существенно
уменьшить избыточность информации для ее хранения или передачи по
каналам связи
Принципы кодирования речевой информации, основным требованием к
которой является разборчивость воспроизводимого сигнала, и звуковой
информации, гарантирующей достаточно хорошее качество звучания
музыкальных и голосовых передач, существенно отличаются друг от друга
60. Частота дискретизации
Частота дискретизации (или частота сэмплирования) - частота, с которой происходит
оцифровка, хранение, обработка или конвертация сигнала из аналога в цифру.
Дискретизация по времени означает, что сигнал представляется рядом своих отсчетов
(сэмплов), взятых через равные промежутки времени.
Выбранная частота дискретизации будет определять максимальную частоту
воспроизведения, и, как следует из теоремы Котельникова, для того, чтобы полностью
восстановить исходный сигнал, частота дискретизации должна в два раза превышать
наибольшую частоту в спектре сигнала.
Есть ряд причин для выбора более высокой частоты дискретизации, хотя может
показаться, что воспроизводить звук вне диапазона человеческого слуха – пустая трата
сил и времени. При этом среднестатистическому слушателю будет вполне достаточно
44,1 – 48 кГц для качественного решения большинства задач.
61. Разрядность
Разрядность – это количество бит цифровой информации для
кодирования каждого сэмпла. Проще говоря, разрядность определяет
«точность» измерения входного сигнала. Чем больше разрядность, тем
меньше погрешность каждого отдельного преобразования величины
электрического сигнала в число и обратно. С минимальной возможной
разрядностью есть только два варианта измерения точности звука: 0
для полной тишины и 1 для звучания в полном объеме. Если
разрядность равна 8, то при измерении входного сигнала может быть
получено 28= 256 различных значений.
Разрядность закреплена в кодеке PCM, но для кодеков, которые
предполагают сжатие (например, MP3 и AAC) этот параметр
рассчитывается при кодировании и может меняться от сэмпла к сэмплу.
62. Битрейт
63. Типы битрейта MP3
CBR (Constant Bit Rate) - постоянный битрейт, который задаётся пользователем и не
изменяется при кодировании произведения. Таким образом, каждой секунде
произведения соответствует одинаковое количество закодированных бит данных
(даже при кодировании тишины).
VBR (Variable Bit Rate) - изменяющийся битрейт или переменный битрейт, который
динамически изменяется программой-кодером при кодировании в зависимости от
насыщенности кодируемого аудиоматериала и установленного пользователем
качества кодирования. Минусом данного метода кодирования является то, что VBR
считает «незначительной» звуковой информацией более тихие фрагменты, таким
образом получается, что если слушать очень громко, то эти фрагменты будут
некачественными.
ABR (Average Bit Rate) - усредненный битрейт, который является гибридом VBR и
CBR: битрейт в кбит/c задаётся пользователем, а программа варьирует его,
постоянно подгоняя под заданный битрейт. Таким образом, кодек будет с
осторожностью использовать максимально и минимально возможные значения
битрейта, так как рискует не вписаться в заданный пользователем битрейт. Это
является явным минусом данного метода, так как сказывается на качестве
выходного файла, которое будет немного лучше, чем при использовании CBR, но
хуже, чем при использовании VBR (при том же размере файла) .
64. Частота дискретизации, разрядность и битрейты в реальной жизни.
Аудио CD-диски, одни из первых наиболее популярных изобретений
для простых пользователей для хранения цифрового аудио,
использовали частоту 44,1 кГц (20 Гц – 20 кГц, диапазон человеческого
уха) и разрядность 16-бит. Данные значения были выбраны, чтобы при
хорошем качестве звука иметь возможность сохранять как можно
больше аудио на диске.
Когда к аудио добавилось видео и появились DVD, а позднее Blu-Ray
диски, был создан новый стандарт. Записи для DVD и Blu-Rays обычно
используют линейный формат PCM с частотой 48 кГц (стерео) или 96
кГц (звук 5.1 Surround) и разрядность 24. Эти значения были выбраны в
качестве идеального варианта, чтобы сохранять аудио с
синхронизацией с видео и при этом получать максимально возможное
качество с использованием дополнительного доступного дискового
пространства.
65.
Принципы кодирования речевой информацииВ качестве международного стандарта для передачи речи принято использование
полосы частот от 300 до 3400 Гц, достаточной для воспроизведения передаваемой
информации. На основе этого стандарта построена всемирная сеть телефонной связи.
В этом случае для описания формы сигнала его дискретизацию следует проводить с
частотой порядка 8 кГц, а для получения нормального качества воспроизведения речи
при равномерной шкале квантования необходимо использовать 13/14-и разрядный
квантователь
Указанное линейное квантование оказывается необходимым потому, что уровни
аналоговых речевых сигналов могут изменяться в диапазоне 60 дБ. Но так как
восприятие сигналов органами слуха человека пропорционально логарифму уровня
сигнала, то сигналы высокого уровня целесообразно квантовать более грубо, а низкого
уровня - более точно. Применяя нелинейное квантование с использованием
логарифмического закона, можно обойтись восемью разрядами на отсчет, сохранив
почти такое же качество передачи. При этом используются соответствующие этой
шкале соотношения A-Law и μ-Law. 13-ти разрядное квантование A-Law принято в
Европе, а 14-ти разрядное μ-Law – в Америке и Японии. В результате скорость
передачи двоичных данных равна 64 кбит/с
По сравнению с более эффективными методами сжатия речевой информации
приведенное кодирование максимально нечувствительно к ошибкам в канале при
достаточно высоком качестве восстановления. Поэтому данный алгоритм
рекомендован для большинства систем цифровой передачи речи в качестве метода
предварительного аналого-цифрового преобразования
66.
Дальнейшим усовершенствованием системы кодирования речи является
применение адаптивной дифференциальной импульсно-кодовой модуляции
(АДИКМ). Преобразование и передача лишь разницы между реальным и
предсказанным значениями сигнала позволяет уменьшить формируемый
цифровой поток до 16 – 32 кбит/с и заметно снизить требования к
широкополосности канала. Следует иметь в виду, что метод не лишен
серьезных недостатков: уровень шумов, связанный с квантованием сигнала,
выше; а при резких изменениях уровня сигнала, превышающих диапазон
АЦП, возможны серьезные искажения
Для обеспечения эффективного кодирования используют разделение
речевой информации на сигнальные фрагменты:
– так называемую частоту основного тона (ОТ) — периодическую подпитку энергией
голосового тракта человека, который представляет собой объемный резонатор;
– формируемую голосовым трактом спектральную окраску речи, или ее формантную
структуру, содержащую усиленные частотные области данного звука,
позволяющие отличить его при слуховом восприятии от других звуков;
– переходные процессы при изменениях ОТ и формантных структур;
– паузы, средняя продолжительность которых составляет примерно 16% времени
воспроизведения речи и порядка 50% времени при диалоге.
67.
При передаче речи в цифровой форме каждый тип сигнала при одной и той же
длительности и одинаковом качестве требует различного числа бит для
кодирования и передачи. Следовательно, скорость передачи разных типов
сигнала также может быть различной, что обусловливает применение кодеков с
переменной скоростью. В основе кодека речи с переменной скоростью лежит
классификатор входного сигнала, определяющий степень его информативности
и, таким образом, задающий метод кодирования и скорость передачи речевых
данных.
Наиболее простым классификатором речевого сигнала является детектор
активной речи (VAD – Voice Activity Detector), который выделяет во входном
речевом сигнале активную речь и паузы. При этом фрагменты сигнала,
классифицируемые как активная речь, кодируются каким-либо из известных
алгоритмов (как правило, на базе метода АДИКМ) с базовой скоростью 4 – 8
кбит/с. Фрагменты, классифицированные как паузы, кодируются и передаются с
низкой скоростью порядка 0,1 – 0,2 кбит/с, либо не передаются вообще. Эта
стратегия позволяет оптимизировать скорость кодирования до 2 – 4 кбит/с при
достаточном качестве синтезируемой речи. Для особо критичных фрагментов
речевого сигнала выделяется большая скорость передачи, для менее
ответственных - меньшая.
Вокодер вносит дополнительную задержку, возникающую за счет использования
буфера для накопления сигнала и учёта статистики последующих отсчётов
(алгоритмическая задержка) и выполнения алгоритмических преобразований
речевого сигнала (вычислительная задержка).
68.
В интервалы, когда в речи активного участника беседы наступает период
молчания, терминалы слушающих могут просто отключить воспроизведение
звука, но при этом в трубке может возникнуть "гробовая тишина" и
слушающему кажется, что соединение по каким-то причинам нарушилось.
Избежать такой неприятный эффект позволяет применение генератора
комфортного шума (CNG – Comfort Noise Generator), параметры которого
могут передаваться во время пауз.
Для того, чтобы синтезировать речь на приемном конце системы связи, нужны
генератор звуковой частоты с богатым спектром, генератор белого шума,
набор формантных фильтров (их число невелико, так как гласных звуков
немного, а каждый из них достаточно хорошо определяется двумя
формантами) и модулирующие схемы. Располагая таким комплектом
аппаратуры на приемном конце, можно передавать по каналу связи не
речевой сигнал, а лишь команды, управляющие процессом синтеза речи.
Таким образом, практическая задача сводится к тому, чтобы найти способ
генерирования нужных команд.
Скорости передачи речевой информации, которую предусматривают
используемые сегодня узкополосные кодеки, лежат в пределах 1,2 – 64 кбит/с.
От этого параметра прямо зависит качество воспроизводимой речи.
Искажения оценивают путем опроса разных групп людей по пятибалльной
шкале единицами субъективной оценки MOS (Mean Opinion Score). Для
прослушивания экспертам предъявляются разные звуковые фрагменты.
69.
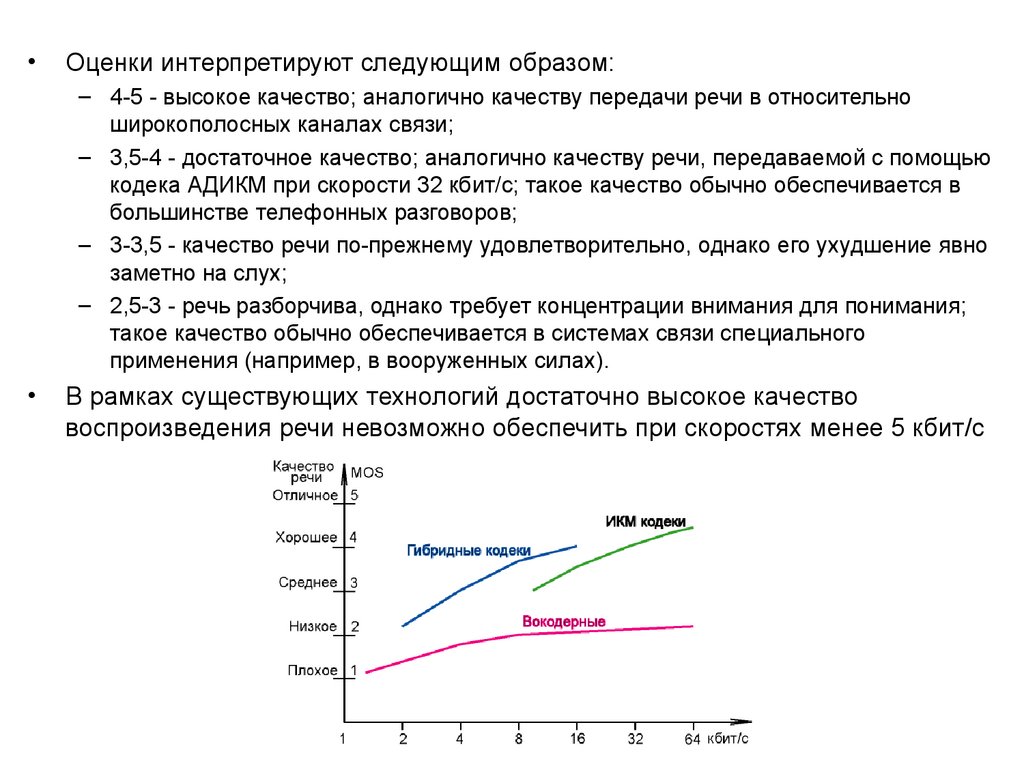
Оценки интерпретируют следующим образом:
– 4-5 - высокое качество; аналогично качеству передачи речи в относительно
широкополосных каналах связи;
– 3,5-4 - достаточное качество; аналогично качеству речи, передаваемой с помощью
кодека АДИКМ при скорости 32 кбит/с; такое качество обычно обеспечивается в
большинстве телефонных разговоров;
– 3-3,5 - качество речи по-прежнему удовлетворительно, однако его ухудшение явно
заметно на слух;
– 2,5-3 - речь разборчива, однако требует концентрации внимания для понимания;
такое качество обычно обеспечивается в системах связи специального
применения (например, в вооруженных силах).
В рамках существующих технологий достаточно высокое качество
воспроизведения речи невозможно обеспечить при скоростях менее 5 кбит/с
70.
Методы кодирования речиИКМ
Метод стандартной телефонии, обычно 64 кбит/сек
АДИКМ
40, 32, 24, 16 кбит/сек, используется комбинация
адаптивного квантования и адаптивного
предсказания
Вокодеры
Компактное описание голосового спектра в
нескольких частотных диапазонах, включая
выделение тонов
Адаптивное полосовое
кодирование
16, 8 кбит/сек, речь делится на частотные полосы, и
каждая кодируется в соответствии со свойствами
слуха и предсказанием спектра
Многоимпульсное
кодирование с линейным
предсказанием
8, 4 кбит/сек, необходимое количество импульсов
используется для оптимизации информации о
возбуждении для речевых сегментов, линейное
предсказание сегментов
Кодирование с линейным
предсказанием и
стохастическим
возбуждением
8 – 2 кбит/сек, кодер хранит набор кандидатов для
возбуждения, каждый состоит из стохастической
последовательности импульсов, выбирается
наилучший
71.
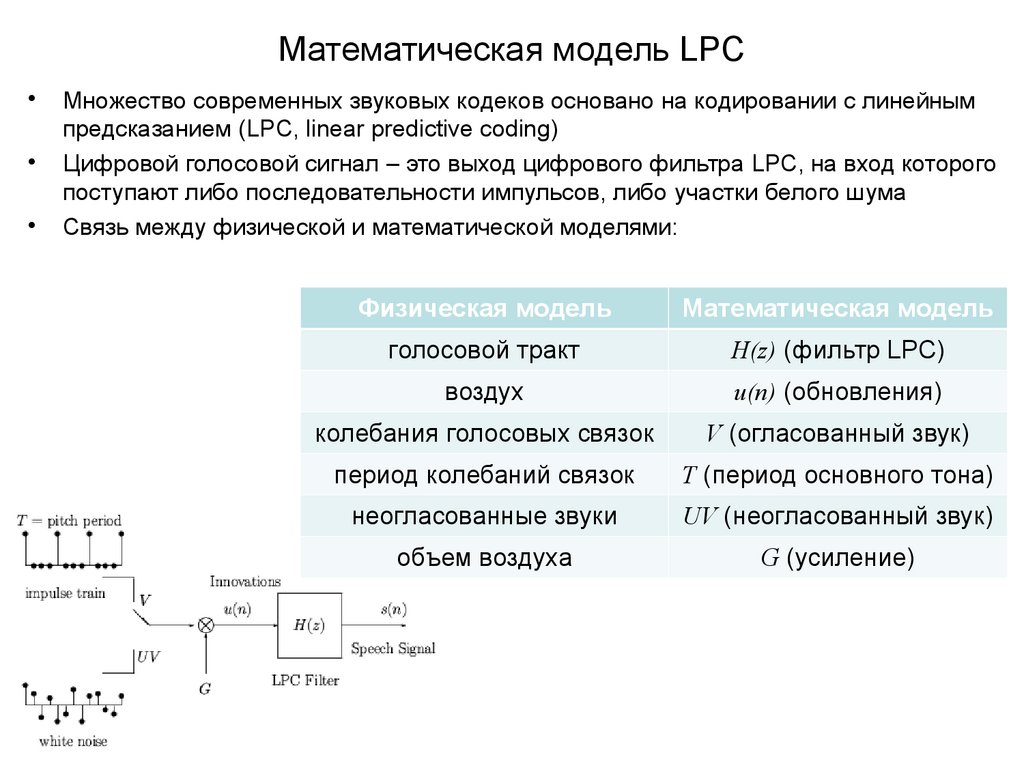
Математическая модель LPCМножество современных звуковых кодеков основано на кодировании с линейным
предсказанием (LPC, linear predictive coding)
Цифровой голосовой сигнал – это выход цифрового фильтра LPC, на вход которого
поступают либо последовательности импульсов, либо участки белого шума
Связь между физической и математической моделями:
Физическая модель
Математическая модель
голосовой тракт
H(z) (фильтр LPC)
воздух
u(n) (обновления)
колебания голосовых связок
V (огласованный звук)
период колебаний связок
T (период основного тона)
неогласованные звуки
UV (неогласованный звук)
объем воздуха
G (усиление)
72.
Математическая модель LPCФильтр LPC определяется формулой:
что эквивалентно следующей связи
входа и выхода фильтра:
Модель LPC представляется в виде вектора
Вектор А изменяется примерно каждые 20 мсек, что при частоте
дискретизации 8 кГц соответствует 160 отсчетам
Цифровой голосовой сигнал делится на кадры по 20 мсек (50 кадров/сек)
Таким образом, согласно модели, 160 отсчетов сигнала S компактно
представляются 13-ю значениями вектора А
Особенности восприятия:
Для звонких звуков - сдвиг импульсов
(нечувствительность к фазе)
Для неогласованных звуков – используются
различные шумовые последовательности
LPC синтез: получение S из А (фильтрация)
LPC анализ: оценка А по S
73.
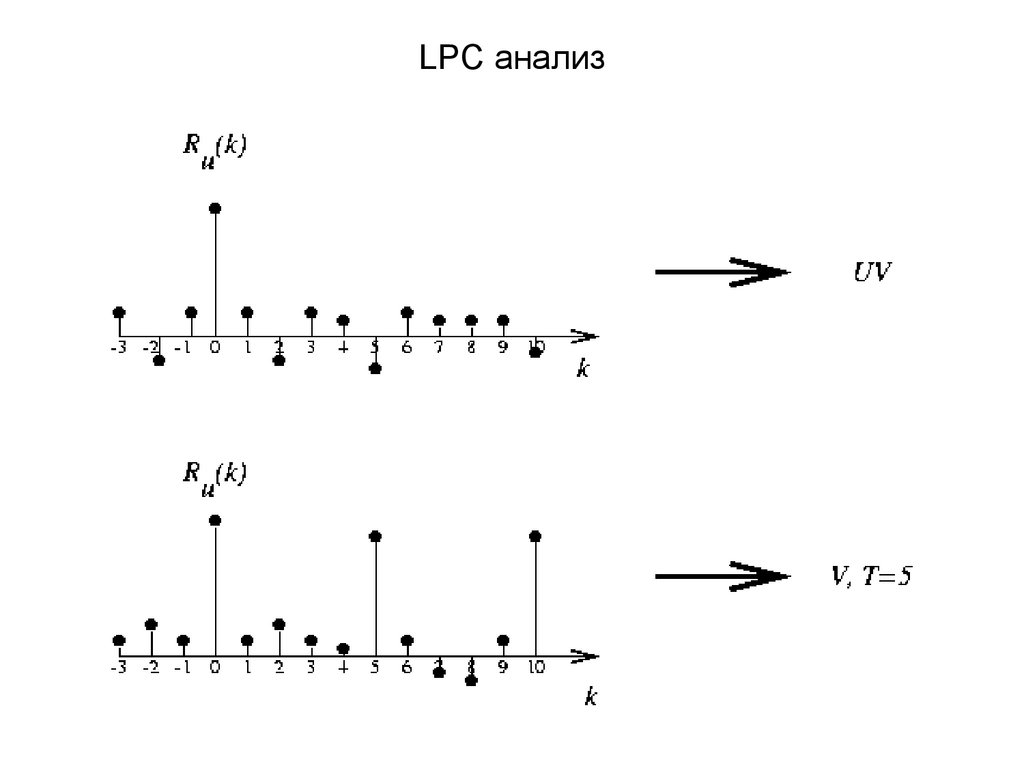
LPC анализРассмотрим один кадр голосового сигнала: S = (s(0), s(1), …, s(159))
Сигнал s(n) связан с обновлением u(n) линейным уравнением:
Десять параметров LPC (a1, a2, …, a10) выбираются так, чтобы
минимизировать энергию обновлений:
Стандартный подход - производные f по ai равны нулю:
Таким образом, получаем 10 линейных уравнений с 10-ю неизвестными:
74.
LPC анализПолученную систему уравнений можно решить следующими способами:
- метод Гаусса
- любой метод инвертирования матрицы
- рекурсия Левинсона-Дурбина:
Уравнения решаются для i = 1, 2, …, 10, а затем
Для получения оставшихся трех параметров (V/UV, G, T) решается
уравнение для обновлений:
Затем рассчитывают автокоррелляцию u(n):
Далее на основании автокорреляции принимается решение о виде звука
(огласованный или неогласованный)
75.
LPC анализ76.
LSP•Коэффициенты LPC представляются через линейные спектральные пары LSP
(line spectrum pair)
•LSP математически эквивалентны коэффициентам LPC, но лучше подходят
для процедуры квантования
•LSP вычисляются следующим образом:
•Факторизация этих уравнений дает:
- параметры LSP
•Параметры LSP упорядочены и ограничены:
•Они более коррелированы от кадра к кадру, чем коэффициенты LPC
77. Вокодер LPC 2,4 кбит/сек
Блок-схема вокодера:
Размер кадра – 20 мсек, то есть 50 кадров в сек.
2400 бит/сек соответствует 48 битам на кадр
Распределение бит представлено в таблице:
78. Вокодер LPC 2,4 кбит/сек
34 бита LSP распределены в соответствии с таблицей:
Для усиления G используется 7-битный
неоднородный скалярный квантователь
Для огласованной речи величины T
задаются в диапазоне от 20 до 146
V/UV, T совместно кодируются как показано в таблице:
79.
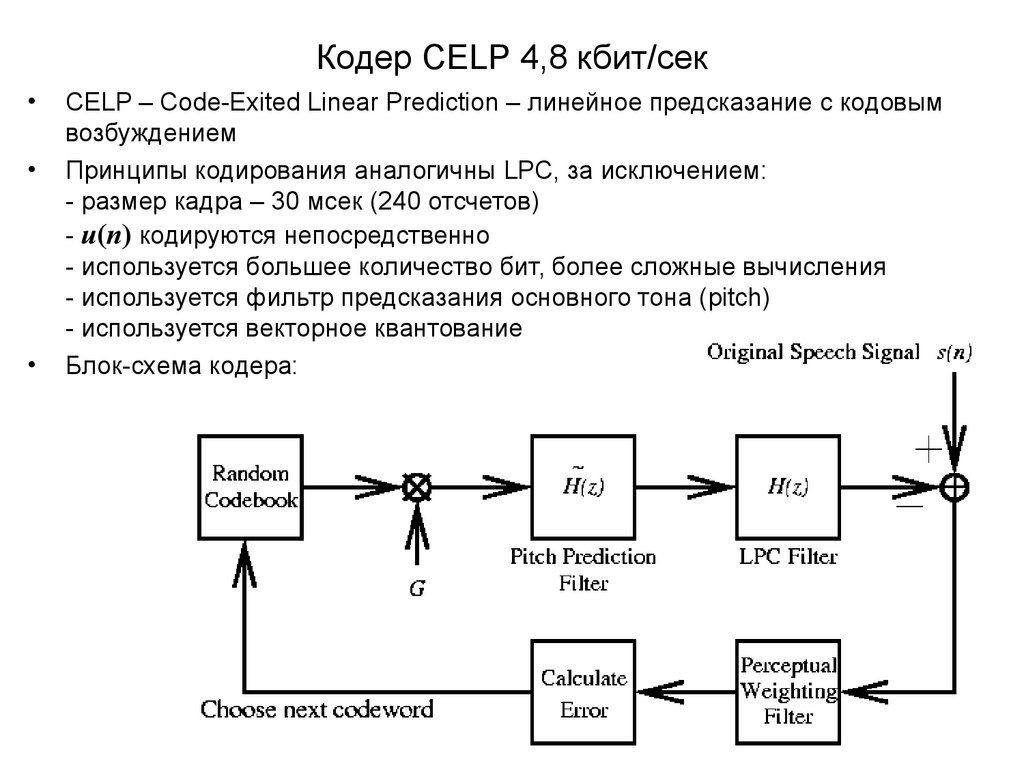
Кодер CELP 4,8 кбит/секCELP – Code-Exited Linear Prediction – линейное предсказание с кодовым
возбуждением
Принципы кодирования аналогичны LPC, за исключением:
- размер кадра – 30 мсек (240 отсчетов)
- u(n) кодируются непосредственно
- используется большее количество бит, более сложные вычисления
- используется фильтр предсказания основного тона (pitch)
- используется векторное квантование
Блок-схема кодера:
80.
Кодер CELP 4,8 кбит/секФильтр предсказания основного тона:
Фильтр перцептуального взвешивания:
Каждый кадр разделен на 4 подкадра. В каждом подкадре кодовая книга
содержит 512 кодовых векторов
Усиление передается 5-ю битами в каждом подкадре
Параметры LSP передаются 34-мя битами аналогично вокодеру LPC
При 30 мсек на кадр 4,8 кбит/сек соответствует 144 битам на кадр,
распределенным следующим образом:
81. Международные стандарты компрессии речи
СтандартНазвание
fd,
кГц
Скорость,
Кбит/сек
Год
ITU-T G.711
ИКМ голосовых частот
8
64
1988
ITU-T G.711.0
Сжатие без потерь ИКМ G.711
8
ITU-T G.711.1
Широкополосное встроенное
расширение ИКМ G.711
8,
16
64, 80, 96
2008
ITU-T G.722
Кодирование звука 7 кГц в 64 кбит/сек
16
64
1988
Кодирование низкой сложности
16,
ITU-T G.722.1 24 и 32 кбит/с для работы hands-free в
32
системах с низкой скоростью потерь
24, 32, 48
2005
Широкополосное кодирование речи
ITU-T G.722.2
при скорости примерно 16 кбит/сек с
3GPP
использованием AMR-WB (adaptive
TS 26.190
multi-rate wideband)
16
16
2003
8
5.3, 6.3
2006
ITU-T G.723.1
Двухскоростной речевой кодер для
мультмедийных каналов
2009
82. Международные стандарты компрессии речи
СтандартНазвание
fd,
кГц
Скорость,
Кбит/сек
Год
ITU-T G.726
40, 32, 24, 16 кбит/сек АДИКМ,
8
16, 24, 32,
40
1990
ITU-T G.727
5, 4, 3, 2 бита вложенная АДИКМ
8
16, 24, 32,
40
ITU-T G.728
Кодирование речи на 16 кбит/сек с
использованием LD-CELP
8
16
1992
ITU-T G.729
Кодирование речи на 8 кбит/сек с
использованием CS-ACELP
8
8
2007
ITU-T G.729.1
Вложенный кодер G.729 с переменной
скоростью передачи
8
8-32
2006
GSM
Узкополосный кодек для систем
мобильной связи
8
6.5 (HR),
13 (FR)
1995
LPC-10
Речевой кодер 2.4 кбит/сек
8
2.4
1984
Speex
Свободный программный речевой
кодер
8-48 2-44
1990
2002
2009
83.
Принципы кодирования звуковой информацииДругие задачи возникают при кодировании широкополосных звуковых
сигналов, реализующих технологии для музыкального творчества
При первичном кодировании в студийном тракте обычно реализуется
равномерное квантование отсчетов аудиосигналов с разрешением от 16 до 24
(и даже 32) бит/отсчет при частотах дискретизации 44.1, 48, 96 (и даже 192) кГц
Считается, что в кодеках, использующих 16-битное линейное квантование
отсчетов при частоте дискретизации 48 кГц, удается практически «идеально»
преобразовывать аудиосигнал, обладающий спектром в полосе частот от 20 Гц
до 20 кГц и динамическим диапазоном до 54 дБ. Скорость передачи одного
такого сигнала составляет 48•16=768 кбит/с. При стереоформате или звуковом
формате 5.1 (или 3/2 плюс канал сверхнизких частот) цифровой поток может
составить соответственно 1,536 или 3,840 Мбит/с. Энтропийное кодирование
такой информации позволяет сократить статиститческую избыточность
цифрового потока. Однако, даже при использовании достаточно сложных
алгоритмов обработки информации уменьшение статистической избыточности
аудиосигналов позволяет уменьшить цифровой поток лишь на 20-50% по
сравнению с его исходным значением
Кодирование аудиоинформации без потерь зачастую используется при ее
хранении, но не способно обеспечить высокий уровень компрессии
84.
Органы слуха человека способны воспринимать информацию в объеме не
более 100 бит/с и, следовательно, можно говорить о значительной
избыточности закодированных без потерь звуковых цифровых сигналах. Это
свидетельствует о существенной психоаккустической избыточности
цифровых аудиосигналов и возможностях ее уменьшения
Цель сжатия аудиоинформации с потерями (Lossy Coding) заключается в
достижении максимально высокого коэффициента компрессии данных при
сохранении качества их звучания на приемлемом уровне. Кодирование с
потерями приводит к утрате некоторой части информации. Декодированный
сигнал при воспроизведении звучит похоже на оригинальный, но фактически
перестает быть ему идентичным
В основе большинства методов кодирования с потерями лежит
использование психоакустических свойств слуховой системы человека. В
частности, наиболее перспективными с этой точки зрения являются
алгоритмы, учитывающие такие свойства слуха, как различного рода
маскировка, выявление различных деталей звучания, которыми можно
пренебречь, эффективные алгоритмы переквантования и передискретизации
и др.
При кодировании звуковых сигналов наибольшее распространение получили
три психоакустические модели, использующие различные алгоритмы
обработки ИКМ аудиоинформации
85.
Звуковые кодерыMPEG-1, MPEG-2 Layer I, II, III
MPEG-4 AAC
MPEG-4 HE-AAC
Dolby AC3
3GPP AMR-WB+
WMA
CELT
FLAC
Vorbis
86.
Психоакустическая модель №1(MPEG-1, MPEG-2 Layer I, II)
Расчет энергетического спектра выборки звукового сигнала и его
нормирование (кадры по 1024 или 512 отсчетов, 24 или 12 мс)
Вычисление энергии сигнала выборки в субполосах кодирования
Выделение локальных максимумов спектра сигнала выборки
Формирование списков тональных и шумовых компонент
Прореживание спектра тональных и шумовых компонент
Расчет коэффициентов маскировки и индивидуальных кривых маскировки
для тональных и шумовых компонент спектра сигнала выборки
Расчет порогов маскировки для тональных и шумоподобных компонент
спектра сигнала выборки
Расчет глобального порога маскировки и отношения сигнал/маска SMR в
субполосах кодирования
87.
Психоакустическая модель №2(MPEG-1, MPEG-2 Layer III)
Расчет спектра выборки звукового сигнала
Вычисление предсказанных значений амплитуды и фазы спектральных
составляющих текущей выборки
Расчет меры непредсказуемости спектральных компонент текущей выборки
Вычисление энергии сигнала и взвешенного значения меры
непредсказуемости в полосах психоакустического анализа
Свертывание энергии сигнала и взвешенного значения меры
непредсказуемости с развертывающей функцией
Расчет коэффициента хаоса и индекса тональности в полосах
психоакустического анализа
Расчет отношения сигнал/шум в полосах психоакустического анализа
Расчет энергии шума на пороге его слышимости, приходящийся на один
коэффициент МДКП в полосе психоакустического анализа
Расчет глобального порога маскировки (допустимой энергии шума) в полосах
кодирования
Расчет энергии звукового сигнала в полосах кодирования
Расчет отношения сигнал/маска SMR в полосах кодирования
88.
Психоакустическая модель №3(Dolby AC-3)
Расчет МДКП для выборки звукового сигнала и формирование полос
психоакустического анализа
Расчет энергии звукового сигнала в полосах психоакустического анализа
Формирование обобщенной кривой маскировки
Расчет кривой глобального порога маскировки и отношения сигнал/маска
SMR
89.
Перцептуальное кодирование звуковых сигналовОбщая схема перцептуального аудиокодера:
Размер кадра обычно от 2 до 50 мсек
Частотно-временной анализ аппроксимирует временные и спектральные
возможности анализа человеческого слуха
Кадр звука трансформируется в набор параметров, которые могут быть
квантованы и закодированы в соответствии с метрикой перцептуальных
искажений
90.
Перцептуальное кодирование звуковых сигналовВ зависимости от целей и дизайна системы кодирования раздел частотновременного анализа может содержать:
- унитарное преобразование
- инвариантный во времени банк однородных полосовых фильтров
- адаптивный к сигналу (изменяющийся по длительности) банк неоднородных
полосовых фильтров
- гибридный анализатор сигнала (преобразование/банк фильтров)
- гармонический анализатор
- анализатор источника сигнала (LPC/многоимпульсное возбуждение)
Методология частотно-временного анализа всегда включает выбор между
частотным и временным разрешением
Психоакустическая модель позволяет определить пороги маскирования
Пороги количественно определяют максимальную степень искажения сигнала,
которую можно ввести в каждой точке частотно-временной плоскости при
квантовании и кодировании
Квантование и кодирование также может использовать статистическую
избыточность с помощью классических методов – ДИКМ, АДИКМ
Квантование может быть равномерным, оптимальным (Ллойда-Макса),
векторным
91.
Перцептуальное кодирование звуковых сигналовКвантованные значения параметров кодируются статистическими
энтропийными кодерами
Так как модель управления психоакустическими искажениями адаптивна к
сигналу, алгоритмы кодирования звука в основе своей имеют переменную
скорость выходного потока
Постоянная скорость достигается обычно буферизацией и обратной связью,
что, в свою очередь, приводит к дополнительной задержке кодирования
Исследование перцептуальной энтропии (PE) показало, что кодирование
почти без искажений возможно при скорости около 2 бит на отсчет звукового
сигнала для большинства высококачественных источников звука
(около 88 кбит/сек при частоте дискретизации 44,1 кГц)
92. Pulse-Code Modulation (PCM)
PCM – кодек, который используется компьютерами, CD-дисками,
цифровыми телефонами и иногда SACD-дисками. Источник сигнала
для PCM сэмплируется через равные интервалы, и каждый сэмпл
представляет собой амплитуду аналогового сигнала в цифровом
значении. PCM – это наиболее простой вариант для оцифровки
аналогового сигнала.
При наличии правильных параметров этот оцифрованный сигнал
может быть полностью реконструирован обратно в аналоговый без
каких-либо потерь. Но этот кодек, обеспечивающий практически
полную идентичность оригинальному аудио, к сожалению, не очень
экономичен, что выражается в очень больших объемах файлов, а такие
файлы не подходят для потокового вещания.
93. Waveform Audio File Format (WAVE, WAV)
Waveform Audio File Format (WAVE, WAV)Для того, чтобы записать звук, нам необходимо преобразовать его в
набор нулей и единиц. В случае с форматом WAV делается это
простейшим образом: входящий звуковой поток разбивается на
малейшие отрезки (кванты, отсюда термины «частота квантования»,
«частота выборки» или "частота дискретизации") и в каждый такой
отрезок времени пишется текущее значение аналогового сигнала в
двоичной форме. Файлы формата WAV могут быть записаны с
частотой дискретизации, к примеру, от 8 кГц до 192 кГц, но де-факто
стандартом считается частота выборки в 44.1 кГц.
Следует отметить, что WAV, как контейнер, поддерживает и другие
способы хранения аудио-информации: к примеру, АДИКМ, который
способен, в зависимости от полосы пропускания, кодировать аудиоданные с переменной частотой дискретизации.
94. FLAC (Free Lossless Audio Codec — свободный аудио-кодек без потерь)
FLAC (Free Lossless Audio Codec — свободный аудиокодек без потерь)Принцип кодирования: алгоритм пытается описать сигнал такой
функцией, чтобы полученный после её вычитания из оригинала
результат (называемый разностью, остатком, ошибкой) можно было
закодировать минимальным количеством битов.
Когда модель подобрана, алгоритм вычитает приближение из
оригинала, чтобы получить остаточный (ошибочный) сигнал, который
затем кодируется без потерь.
95. Сжатие с потерями (MP3, AAC, WMA, OGG)
Используется алгоритм сжатия с потерями, размер MP3-файла со средним
битрейтом 128 кбит/с примерно равен 1/11 от оригинального файла с аудио CD
(несжатое аудио формата CD-Audio имеет битрейт 1411,2 кбит/с). MP3 файлы
могут создаваться с высоким или низким битрейтом, что влияет на качество
результата.
Звуковой сигнал разбивается на равные по продолжительности отрезки,
каждый из которых после обработки упаковывается в свой фрейм (кадр).
Разложение в спектр требует непрерывности входного сигнала, в связи с этим
для расчётов используется также предыдущий и следующий фрейм.
В звуковом сигнале есть гармоники с меньшей амплитудой и гармоники,
лежащие вблизи более интенсивных — такие гармоники отсекаются, так как
среднестатистическое человеческое ухо не всегда сможет определить
присутствие либо отсутствие таких гармоник.
Также возможна замена двух и более близлежащих пиков одним усреднённым
(что, как правило, и приводит к искажению звука). Критерий отсечения
определяется требованием к выходному потоку.
Поскольку весь спектр актуален, высокочастотные гармоники не отсекаются, а
только выборочно удаляются, чтобы уменьшить поток информации за счёт
разрежения спектра. После спектральной «зачистки» применяются
математические методы сжатия и упаковка во фреймы.
96. Почему 44100?
Частота 44.1 кГц возникла в конце 1970-х, благодаря PCM адаптерам,
которые записывали звук на видеокассеты (U-Matic), в частности Sony
PCM-1600 (1979) и последующим моделям серии. Позже это стало
основой для CD-DA, описанного в стандарте Red Book (1980). В
дальнейшем это значение частоты также было включено в другие
стандарты 90-х/2000-x годов, вроде DVD, HDMI. Данная частота обычно
используется при кодировании в MP3 (и другие потребительские
форматы аудио) звука, извлеченного из Audio CD.
Частота дискретизации была выбрана в ходе дебатов между
разработчиками, в особенности Sony и Philips, а также благодаря
компании Sony, которая в результате активного использования этой
частоты практически сделала её стандартом де-факто. Само собой,
выбор имел определенное техническое обоснование.
Слышимый диапазон для человеческого уха лежит в пределе 20—
20000 Гц, по теореме Котельникова частота семплирования должна
быть как минимум в два раза больше максимальной частоты, которую
может потребоваться передать — более 40 кГц.
97.
Кроме того, сигнал перед семплированием должен пройти через НЧ
фильтр (иначе возникнет алиасинг) и, в то время как идеальный НЧ
фильтр абсолютно не пропускал бы частоты выше 20 кГц, но
полностью бы пропускал всё что ниже 20 кГц.
На практике необходима т.н. переходная полоса, в которой происходит
спад АЧХ (частотные составляющие подавляются лишь частично). Чем
шире эта полоса, тем проще создать антиалиазинговый фильтр.
Частота 44.1 кГц обеспечивает переходную полосу шириной 2.05 кГц.
В ранние годы цифровой звук записывался на пленку видеокассет, т.к.
это был единственный доступный носитель с ёмкостью достаточной
для более-менее продолжительной записи звука. Чтобы свести к
минимуму необходимые модификации оборудования, аудио
воспроизводилось на той же скорости, что и видео; также
использовалась практически идентичная схемотехника. Частота 44.1
кГц была признана наибольшей доступной.
98.
Данная частота рассчитывается следующим образом:•NTSC:
245 × 60 × 3 = 44100
245 активных линий/поле × 60 полей/с × 3 семпла/линию = 44100
семплов/с
(490 активных линий на один фрейм из 525 линий всего)
•PAL:
294 × 50 × 3 = 44100
294 активных линий/поле × 50 полей/с × 3 семпла/линию = 44100
семплов/с
(588 активных линий на один фрейм из 625 линий всего)