




























































 electronics
electronicsSimilar presentations:










Архитектура вычислительных систем реального времени
1.
В.И. ЖабинАРХИТЕКТУРА ВЫЧИСЛИТЕЛЬНЫХ
СИСТЕМ РЕАЛЬНОГО ВРЕМЕНИ
Киев ТОО "ВЕК +"
2003
2.
ББК 84Р7Ж12
УДК 681.3
Ответственный за выпуск Стиренко С.Г.
Рецензенты: Жуков И.А., доктор технических наук, профессор,
заведующий кафедрой вычислительной техники Национального авиационного университета Украины;
Тарасенко В.П., доктор технических наук, профессор,
заведующий кафедрой специализированных компьютерных систем Национального технического университета
Украины "КПИ"
Жабин В.И.
Ж12 Архитектура вычислительных систем реального времени / В.И. Жабин, — К.: ВЕК +, 2003. – 176 с., ил.
ISBN 966–7140–21–0
Рассматриваются вопросы повышения эффективности мультипроцессорных вычислительных систем реального времени. Предложен комплексный подход к организации параллельных вычислительных процессов и
масштабирования производительности систем с использованием концепции
модульной организации аппаратніх средств. Проанализированы возникающие при этом проблемы и предложены пути их решения. Показана эффективность совместного использования классической и потоковой моделей
вычислений при реализации параллельных алгоритмов. Приведены примеры организации модульных вычислительных систем.
Для научных работников и специалистов, занимающихся вопросами организации вычислительных процессов в параллельных системах.
ББК 84Р7
ISBN 966–7140–21–0
Жабин В.И., 2003
3.
ГЛАВА 2КЛАССИФИКАЦИЯ И ЯЗЫКИ ОПИСАНИЯ
АРХИТЕКТУРЫ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
2.1. Классификация параллельных систем
В процессе развития ВС было предложено много разнообразных параллельных структур, часть из которых была реализована. По мере увеличения числа и разнообразия структур их классификация становится важным этапом при разработке новых проектов. Она позволяет выявить недостатки и определить пути повышения эффективности систем.
Как отмечалось в разделе 1.2, одной из наиболее широко известных и
часто используемых является классификация Флинна [22]. Данная классификация учитывает только характер взаимодействия в системе потоков
команд и данных. В связи с этим в один класс попадают системы, которые
существенно отличаются по архитектуре, не говоря о структурных отличиях и способах взаимодействия устройств. В ряде работ классы по Флинну
рассматириваются более детально. Например, классификация по Джонсону
[35] разделяет класс MIMD на четыре подкласса в зависимости от организации памяти и способа передачи данных между процессорами:
общая память – разделяемые переменные (GMSV);
распределенная память – разделяемые переменные (DMSV);
распределенная память – передача сообщений (DMMP);
общая память – передача сообщений (GMMP).
Другой подход к классификации, претендующий на универсальность,
связан с количественными характеристиками систем.
Классификация систем по Фенгу [36] использует две характеристики:
количество параллельно обрабатываемых слов (m);
число разрядов данных (n), которые обрабатываются параллельно
в устройстве обработки данных.
Тип системы в этом случае отображается точкой на плоскости. По
осям координат откладываются значения m и n. Возможна запись в виде
формулы СИСТЕМА=(m,n). Например, 16-процессорная система C.mmp, в
которой каждый процессор обрабатывает 16-разрядные слова, отображается точкой (16, 16). Это записывается в виде C.mmp=(16, 16). Матричный
процессор ILLIAC-IV можно определить как ILLIAC-IV=(64, 64). Классификация дает только общее представление о структуре и степени параллелизма, но не отражает организацию коммуникационной среды и ряда
структурных особенностей систем, в том числе, наличие конвейерной обработки. Например, система TIASC содержит 4 конвейера на 8 этапов и 64
разряда каждый. Это отображается в виде TIASC(64, 2048). Число 2048
4.
Глава 2. Классификация и языки описания архитектуры систем17
получено как произведение 4 8 64, но оно может быть получено и другим
образом, например, 8 8 32.
Классификация Хендлера [37] основана на рассмотрении трех характеристик:
количество устройств управления (c);
число арифметико-логических устройств (a);
количество логических секций (w), каждая из которых обрабатывает один разрядный срез слов данных в арифметико-логическом
устройстве.
В данном случае система представляется точкой в трехмерном пространстве и записывается в форме СИСТЕМА=(c,a,w). Характеристика a
показывает, сколько арифметико-логических устройств связано с одним
устройством управления. Учитывая это, получим C.mmp=(16, 1, 16) и
ILLIAC-IV=(1, 64, 64). В отличие от классификации Фенга параллельные
структуры описываются более подробно. Появляется возможность указать
число устройств обработки данных, которые работают под управлением
одного потока команд (одного устройства управления). Однако отразить
особенности коммуникационной среды и наличие конвейера на рассматриваемых уровнях также не представляется возможным.
Для отображения наличия конвейерной обработки информации на различных уровнях Валяхом предложено расширить классификацию Хандлера
введением дополнительных характеристик на соответствующих уровнях
обработки информации, а именно: c’, a’ и w’ [15]. Каждая из введенных
характеристик показывает число этапов конвейера на данном уровне. В
этом случае системы отображаются в виде СИСТЕМА(c c’, a a’, w w’).
Например, систему TIASC, в которой используется конвейерная обработка,
можно теперь охарактеризовать более полно, а именно – TIASC(1, 4, 64 8).
Тем не менее, данная классификация дает только общее представление о
структуре систем, причем, возникают трудности при описании неоднородных систем.
Одной из ранних попыток классификации систем в соответствии с их
структурой можно считать работу Шора [38]. В соответствии с указанной
классификацией различают шесть классов систем (базовых машин), представленных на рис. 2.1. Системы отличаются способом соединения основных устройств, в качестве которых рассматриваются устройства управления (УУ), операционные устройства (ОУ) и память. При этом память с УУ
обменивается словами, а с ОУ – словами (вертикальный доступ) или разрядными срезами слов (горизонтальный доступ). В связи с этим память
рассматривается раздельно для команд (ПК) и данных (ПД).
Машины класса I соответствуют классу SISD по Флинну. Это архитектура фон Неймана с одним УУ и одним ОУ. Никаких ограничений на внутреннюю организацию ОУ не накладывается. В связи с этим, например,
конвейерную машину CDC 7600 относят к данному классу.
5.
18Архитектура вычислительных систем реального времени
Машины II – это модификация класса машин I, касающаяся обработки
данных. В таких машинах ОУ реализуют методы последовательной арифметики. Представителем данного класса является система STARAN. К
классу III относят машины, которые могут обрабатывать как считываемые
из ПД слова, так и разрядные срезы слов (комбинация машин I и II). ПД
должна быть организована в виде двухмерного массива.
ПК
УУ
ПК
ПК
ОУ
УУ
УУ
ОУ
ПД
ОУ
ОУ
ПД
I
ПД
II
УУ
ОУ
ОУ
III
УУ
ОУ
ОУ
ОУ
УУ
ОУ
ОУ
ПД
ПД
ПД
IV
ПД
ПД
ПД
V
ПД
VI
Рис. 2.1. Схематическое представление классов систем
Машины IV и V являются фактически разновидностями класса SIMD
по Флинну. Все ОУ (процессорные элементы) управляются одним УУ.
Один поток команд реализует преобразование нескольких потоков данных
в разных ОУ. Машины V обладают более широкими функциональными
возможностями, поскольку в них предусмотрен обмен информацией между
соседними ОУ. К классу IV относится система PEPE, а в классу V –
ILLIAC-IV.
Машины класса VI имеют память данных, которая выполняет функции
среды обработки информации (память со встроенной логикой, функциональная память). К данному классу относятся, в частности, ассоциативные
процессоры.
Данная классификация, хотя и учитывает некоторые структурные признаки систем, ограничивает круг систем проектами, которые были известны на момент разработки классификации. Кроме того, существуют системы, которые нельзя однозначно отнести к одному классу, а некоторые системы остаются вообще вне данной классификации. В первую очередь это
относится к системам MIMD, представляющим в настоящее время многочисленный класс параллельных систем.
К издержкам универсальности рассмотренных классификаций можно
отнести то, что в один класс попадает множество структур, отличающихся
6.
Глава 2. Классификация и языки описания архитектуры систем19
способом обмена информацией между компонентами систем, организацией
коммуникационной среды и рядом других структурных особенностей.
2.2. Структурная классификация систем
с магистральной топологией
Рассмотрим классификацию систем MIMD с шинной топологией.
Учитывая, что современный подход к проектированию систем предполагает максимальное применение готовых компонентов (off-the-shelf), основное
внимание будем уделять взаимодействию компонентов, а не их внутренней
организации (наличие уровней конвейерной обработки, построение арифметико-логических цепей, внутренней памяти и т.д.). Эффективность МВС,
зависит не только от количества тех или иных устройств и их характеристик. На эффективность реализации вычислительных процессов существенное влияние оказывают такие структурные признаки систем:
принцип управления (централизованный или децентрализованный);
число магистралей (каналов, шин) обмена информацией;
распределение адресного пространства процессоров;
способы доступа к различным областям памяти процессоров;
способы синхронизации процессов при обмене информацией между процессорами и доступе к общему системному ресурсу.
Классификация систем, учитывающая указанные признаки, может
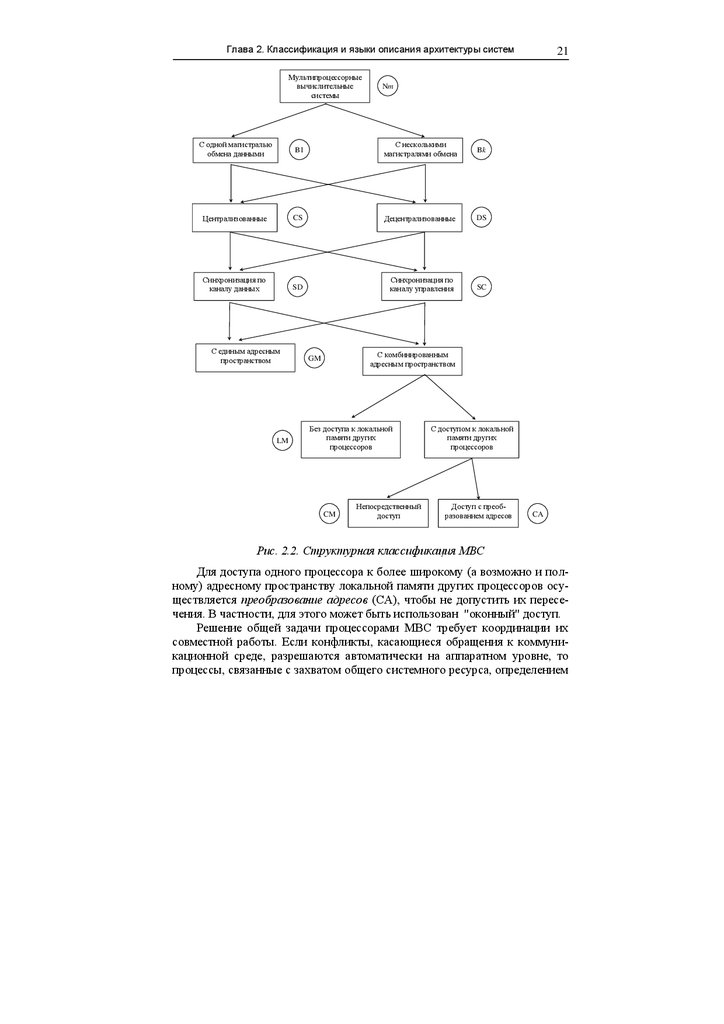
быть представлена в виде дерева (рис. 2.2). Классификация рассматривает
организацию систем на функциональном уровне, на котором видны укрупненные компоненты (процессоры, модули памяти и другие устройства).
Способы реализации самих компонентов систем могут уточняться на более
низких уровнях описания.
Прежде всего, мультипроцессорные системы характеризуются числом
процессоров (Nm) (см. обозначения на рис. 2.2).
В системах с несколькими магистралями обмена информацией (Bk)
имеется возможность совмещения во времени передачи информации между
различными устройствами. В системах с одной магистралью (B1) в один
момент времен в качестве источника информации может быть только одно
устройство, а приемником информации может быть одно или несколько
устройств.
В централизованных системах (CS) функции управления процессом
обработки информации возлагаются на один управляющий (master) процессор. К основным функциям управляющего процессора можно отнести:
планирование и распределение работ между подчиненными (slave)
процессорами;
7.
Архитектура вычислительных систем реального времени20
синхронизация процессов при использовании общего системного
ресурса;
организация взаимодействия между подчиненными (slave) процесссорами;
обработка прерываний, в том числе от подчиненных процессоров;
реконфигурация системы и перераспределение процессов в случае
выхода из строя ресурсов.
В децентрализованных системах (DS) функции управления распределяются между всеми процессорами. Задачи синхронизации процессов решаются процессорами совместно.
Совокупность всех адресов, которые может генерировать процессор,
составляет его адресное пространство. При этом не имеют значения способы адресации, которые используются в процессоре (прямая, косвенная,
относительная, сегментная, страничная и др.), а также физическая организация памяти (плоская память или иерархическая когерентная структура,
включающая несколько уровней, в том числе уровни кэш-памяти).
В системах с единым адресным пространством имеется только общая
память (GM), к которой имеет доступ каждый процессор. В этой памяти,
кроме общей системной информации, хранятся программы, которые выполняются разными процессорами. В этом случае существенно возрастает
число конфликтов при обращении к общей памяти.
В системах с комбинированным адресным пространством, кроме общей памяти, доступной для всех процессоров, каждый процессор имеет
свою собственную локальную память. Способ доступа к локальному и общему адресному пространству физически реализуется различным образом.
При обращении к общему адресному пространству каждый раз осуществляется арбитраж с учетом приоритетов процессоров. Наличие локальной
памяти позволяет хранить в ней программу для данного процессора, что
обеспечивает одновременное выполнение ветвей алгоритмов в разных процессорах практически независимо друг от друга. Каждый процессор обращается за командами в свою локальную память. Общая память используется в основном для обмена данными и хранения общей системной информации.
В системах с локальной памятью (LM) может быть разрешен или запрещен доступ одного процессора к локальной памяти другого. В системах
без доступа к локальной памяти других процессоров межпроцессорный
обмен осуществляется исключительно через общую память.
В системах с разрешением доступа к локальной памяти других процессоров часть локальной памяти каждого процессора выделяется в общее
адресное пространство системы. Обычно такая память называется коммуникационной (CM) и используется в основном для обмена данными между
процессорами.
8.
Глава 2. Классификация и языки описания архитектуры системМультипроцессорные
вычислительные
системы
Nm
С одной магистралью
обмена данными
B1
С несколькими
магистралями обмена
Bk
Централизованные
CS
Децентрализованные
DS
Синхронизация по
каналу данных
SD
Синхронизация по
каналу управления
SC
С единым адресным
пространством
LM
21
С комбинированным
адресным пространством
GM
Без доступа к локальной
памяти других
процессоров
CM
Непосредственный
доступ
С доступом к локальной
памяти других
процессоров
Доступ с преобразованием адресов
CA
Рис. 2.2. Структурная классификация МВС
Для доступа одного процессора к более широкому (а возможно и полному) адресному пространству локальной памяти других процессоров осуществляется преобразование адресов (CA), чтобы не допустить их пересечения. В частности, для этого может быть использован "оконный" доступ.
Решение общей задачи процессорами МВС требует координации их
совместной работы. Если конфликты, касающиеся обращения к коммуникационной среде, разрешаются автоматически на аппаратном уровне, то
процессы, связанные с захватом общего системного ресурса, определением
9.
22Архитектура вычислительных систем реального времени
готовности данных к обмену требуют дополнительных средств синхронизации.
Синхронизация по каналам данных (SD) связана с применением таких
примитивов синхронизации, как флаги и семафоры, которые хранятся в
памяти системы. Обращение к указанным примитивам осуществляется с
помощью команд обращения к памяти, то есть они пересылаются в процессоры по каналам данных.
Согласование работы процессоров может осуществляться также с помощью синхронизации по каналам управления (SC). В этом случае процессоры обмениваются сигналами синхронизации по шине управления (сигналы блокировок, прерывания и т.д.).
Приведенные обозначения можно использовать в качестве структурной нотации. Например, запись СИСТЕМА(N4,B1,DS,SC,LM) соответствует четырехпроцессорной децентрализованной системе с одной системной
шиной, локальной памятью для каждого процессора, причем, синхронизация процессов в системе осуществляется по шине управления.
Предлагаемая классификация может быть полезна не только для характеристики систем, но и в процессе их проектирования, в частности, на
этапе выбора архитектуры. Она позволяет выявить большое число вариантов организации мультипроцессорных систем (различных путей в представленном на рис. 2.2 классификационном дереве). Сопоставительный
анализ вариантов дает возможность выявить архитектуры, которые в большей степени соответствуют предъявляемым требованиям.
Для наглядного представления конфигурации компонентов системы с
учетом рассмотренных классификационных признаков целесообразно использовать язык описания архитектуры на функциональном уровне.
2.3. Языки описания архитектуры
вычислительных систем
Основной целью различных способов описания систем является эффективная передача идей в рассматриваемой области. Язык описания должен быть однозначным и понятным, а уровень детализации – достаточным
для сравнения и оценки эффективности принятых технических решений.
Уровень описания систем определяется степенью абстракции представления ее составляющих (аппаратных и программных). Сложная система может быть разбита на объекты или модули, причем этот процесс можно повторяться до обеспечения требуемого уровня детализации.
Различные уровни описания систем отличаются видимыми на данном
уровне компонентами (программными и аппаратными) и операциями, которые выполняются компонентами или над компонентами.
Из всего многообразия уровней описания систем наиболее часто применяют следующие: виртуальный, функциональный и логический.
10.
Глава 2. Классификация и языки описания архитектуры систем23
На виртуальном уровне видимыми объектами являются процессы,
структуры данных, с которыми работают эти процессы, языковые примитивы, с помощью которых процессы манипулируют с данными и взаимодействуют между собой. Функции, выполняемые компонентами, описываются, как правило, с помощью языков параллельного программирования и
моделирования поведенческих функций систем.
Виртуальный уровень показывает возможности виртуальной машины
и программного обеспечения, но физическая машина на этом уровне не
видна. Современная технология позволяет аппаратную интерпретацию
программ высокого уровня, что делает виртуальный уровень возможным
для общения с системным пользователем. Тенденция такого рода проявляется в проектах іАРХ 432 [39], SWARD [40]. Однако этот уровень не является достаточным для разработчиков систем.
Функциональный уровень позволяет в качестве объектов рассматривать
устройства системы, в том числе, процессоры, память, устройства вводавывода, системы коммутации и т.д. Рассматриваемые объекты взаимодействуют в основном на уровне команд и протоколов обмена информацией.
Могут рассматриваться дополнительные характеристики устройств
(например, форматы команд и данных, разрядность устройств, объем и организация памяти). На функциональном уровне видна архитектура систем,
что позволяет при дальнейшей детализации модулей перейти к логическому уровню.
На логическом уровне может быть достигнута любая степень детализации проекта. Видимыми на этом уровне могут быть типовые узлы и элементы (при необходимости могут учитываться технологические и конструктивные особенностей их реализации). Функции составных частей системы и их взаимодействие отображают с помощью аппарата теории автоматов, специальных языков описания аппаратных средств, в том числе,
схем, таблиц, микроалгоритмов и т.д.
К описаниям систем на этапе проектирования архитектуры можно
предъявить следующие требования:
возможность представления общей архитектуры систем, абстрагируясь от конкретной элементной базы;
описание способов взаимодействия модулей, их особенности и
возможности;
сравнение эффективности различных технических решений с учетом определенных характеристик.
Данным требованиям виртуальный уровень соответствует менее всего.
Поэтому основным является функциональный и логический уровни. На
начальной стадии разработки систем обычно используют функциональный
уровень, а затем – логический уровень. Окончательная стадия проекта регламентируется действующими стандартами и фактически сводится к разработке технической документации.
11.
24Архитектура вычислительных систем реального времени
Для описания систем на функциональном уровне используются различные языки, выбор которых определяется начальным уровнем детализации и целевой функцией проектирования. В ряде работ предлагается рассматривать архитектуру систем в виде совокупности базовых элементов. В
работе [41] предлагается рассматривать архитектуру любого компьютера,
как абстрактную структуру, состоящую из четырех базовых элементов:
процессор команд (IP – Instruction Processor);
процессор данных (DP – Data Processor);
иерархия памяти (IM – Instruction Memory, DM – Data Memory);
элемент коммутации.
В работе [42] предлагается иерархическое описание архитектуры на
основе семи базовых элементов:
iM – память, из которой можно выбрать несколько единиц информации за один цикл обращения;
sM – память, из которой можно выбрать одну единицу информации за
цикл обращения;
C – кэш-память;
sI – простой (неконвейерный) процессор для подготовки команды к
выполнению;
pI – конвейерный процессор для подготовки команды к выполнению;
sX – простой процессор для выполнения команды;
pX – конвейерный процессор для выполнения команды.
Более подробно такой подход к описанию систем рассмотрим на примере нотации Хокни-Джессхоупа [43], в которой используется большее
число базовых элементов. Элементы обозначаются следующим образом:
I – устройство управления, декодирующее одиночный поток команд;
E – устройство обработки данных, манипулирующее с одиночным потоком данных, которое может подразделяться на устройства B и F;
B – устройство обработки данных с фиксированной запятой;
F – устройство обработки данных с плавающей запятой;
M – устройство памяти с одномерной выборкой;
O – устройство памяти с ортогональной (двумерной) выборкой;
P – процессорный элемент (включает E, но не включает I);
IO – устройство ввода-вывода;
C – система (компьютер) в целом.
Конвейерная обработка обозначается строчной буквой p. Например, Ip
и Ep – соответственно конвейерные устройства I и E. Наличие векторных
команд отмечается буквой v (Ipv – конвейерное устройство управления с
векторными командами). Для отражения сложных иерархических структур
используется подстановка обобщенных символов, которые описываются
отдельно. Дублирование элементов обозначается чертой над символом,
группы устройств заключаются в фигурные скобки. С помощью подстрочных индексов возле символов устройств указывается число разрядов, с ко-
12.
Глава 2. Классификация и языки описания архитектуры систем25
торыми устройство оперирует, а надстрочные индексы могут использоваться для уточнения временных характеристик устройств. После скобок
надстрочные символы определяют степень связности между устройствами
(0-nn – нет связи между соседями, 1-nn – есть связь между ближайшими
соседями). Подстрочные символы в этом случае показывают тип управления (в частности, l – синхронное управление). Способы соединения
устройств обозначаются дополнительными символами, в том числе различными линиями, стрелками и т.д. В круглых скобках могут уточняться типы
используемых устройств. После точки с запятой возможны комментарии. В
качестве примера приведем предлагаемые авторами описания нескольких
систем.
C(IBM 7090) = I[F36 – M];
C(IBM 360/195) = Ip54[2C – 32M1160(1 KB) – 16M2800];
C(TIASC(2IPU, 4 конвейера)) = 2Ipv[2 F ] – 8M – 8 P ;
C(ILLIAC-IV (4 квадранта)) = С1[4C280[64 P ]l1-nn]; P =
400
I600
64 – M 2K*64 ;
C(PEPE) = C1 [3I[288{ 3E - M }]l0-nn]; C1 = C(CDC 7600).
Нотация позволяет описывать как последовательные, так и параллельные системы. Кроме того, формуле можно поставить в соответствие граф,
определяющий топологию связей, но особенности взаимодействия базовых
компонентов и способы синхронизации процессов отобразить при этом не
представляется возможным.
Для описания поведенческих функций систем применяется аппарат
теории массового обслуживания, стохастические сети Петри, цепи Маркова
и другие методы моделирования поведения взаимосвязанных автоматов.
При этом фактически рассматривается система массового обслуживания
(СМО), в которой исследуются потоки заявок. Указанные средства исследования базируются на знании информационных и управляющих потоков в
системе, то есть их применению должна предшествовать разработка архитектуры системы. Для этого необходимы средства описания систем, которые бы отображали взаимодействие информационных и управляющих потоков. Наиболее удобными с этой точки зрения являются графические языки описания систем.
2.4. Графический язык описания архитектуры систем
Известны графические языки описания архитектуры ВС [44]. Один из
первых языков, базирующихся на графическом представлении элементов
системы, получил название PMS (processor, memory, switch). Язык обеспе-
13.
26Архитектура вычислительных систем реального времени
чивает общее описание структуры системы и соединений между ее компонентами. Основным недостатком является то, что в данном случае не рассматривается взаимодействие управляющих потоков, что существенно затрудняет разработку поведенческих моделей системы. Больше информации
о системе представляет графический язык MSBI (master, slave, bus,
interface). Описание систем в данном случае составляется из четырех видов
модулей, соответствующих названию метода. Связи между компонентами
ориентированы в направлении передачи управляющих воздействий от активных устройств к пассивным, что делает описание более информативным, в том числе, и для исследования поведенческих функций систем. Однако возникает целый ряд проблем, ограничивающих применение графических моделей. К ним можно отнести, например, невозможность отображения доступа к общему ресурсу с преобразованием параметров, передачи
управляющих воздействий активным элементам, отображения структуры
адресного пространства процессоров. Все это не дает возможности исследовать эффективность различных способов синхронизации процессов и
обмена данными между устройствами.
Рассмотрим графический язык описания архитектуры систем, являющийся развитием языка MSBI и позволяющий устранить ряд его недостатков [45].
Будем использовать две формы отображения архитектуры, а именно:
графическое описание с использованием унифицированных функциональных обозначений;
карту распределения адресного пространства.
Эти формы взаимно дополняют друг друга, но могут использоваться и
самостоятельно при рассмотрении различных аспектов функционирования
систем.
Графическое описание архитектуры представляется ориентированным (возможно взвешенным) графом G=(E, C, F), где E – множество вершин, соответствующих компонентам архитектуры; C – множество дуг, соответствующих направлению управляющих потоков; F – функциональные
правила построения графа.
Множество E={Ea, Ep, Ec} включает вершины трех типов:
Ea – вершины, соответствующие активным элементам архитектуры
(процессорам, устройствам прямого доступа);
Ep – вершины, соответствующие пассивным элементам (модулям памяти, внешним устройствам);
Ec – вершины, соответствующие компонентам коммуникационной
среды системы (магистралям передачи информации).
Множество C может включать различные типы дуг, причем, каждый
тип соответствует определенному потоку управляющих воздействий,
обеспечивающему выполнение заданного действия. В данном случае будет
14.
Глава 2. Классификация и языки описания архитектуры систем27
достаточным рассмотрение множества C={Cm, Cc, Cw, Ca}, включающего
дуги четырех типов:
Cm – дуги, соответствующие управляющим потокам стандартных циклов обращения к собственному адресному пространству (доступ к ресурсу
без арбитража);
Cc – дуги, соответствующие управляющим потокам стандартных циклов обращения к общему адресному пространству, когда доступ сопровождается процедурой арбитража;
Cw – дуги, соответствующие управляющим потокам с преобразованием
параметров доступа (например, преобразование адресов для “оконного”
доступа);
Ca – дуги, соответствующие передаче управляющего воздействия активному элементу.
Функциональные правила F включают следующие требования:
1. Правила должны определять функцию инцидентности I:C E E.
2. Дуги должны быть ориентированы в направлении от активного элемента, который является инициатором действия, к элементу, с которым
это действие должно осуществляться. При этом направление ответных
управляющих сигналов и направление передачи данных может не совпадать с ориентацией дуг. Например, инициатором чтения информации
из памяти является процессор (вырабатывает сигнал READ), а данные
пересылаются из памяти в регистр процессора. Процессор также принимает ответный сигнал подтверждения готовности памяти.
3. Сложные взаимодействия представляются составными дугами. Например, доступу к общему ресурсу с одновременным преобразованием адресов соответствует составная дуга.
4. Дуги, соответствующие передаче управляющего воздействия активному элементу, изображаются пунктирной линией, а остальные – сплошной.
Таким образом, графическое описание архитектуры является графом,
который отображает основные компоненты систем и потоки управляющей
информации, которые определяют способ их взаимодействия. Управляющий поток, направленный к пассивному элементу, вызывает соответствующий информационный поток (команд или данных), а к активному – изменяет режим работы последнего.
Граф составляется с использованием функциональных обозначений,
представленных на рис. 2.3.
Основным активным элементом является процессор. Он может с помощью команд обращаться к адресному пространству памяти или адресному пространству внешних устройств. В первом случае выполняются стандартные циклы чтение, запись или чтение-модификация-запись, а во втором – ввод или вывод. Адресное пространство внешних устройств может
быть включено в адресное пространство памяти.
15.
28Архитектура вычислительных систем реального времени
Пассивные элементы не могут быть инициаторами событий. Примерами таких устройств являются модули памяти и внешние устройства. Пассивные устройства представлены в адресном пространстве процессоров
совокупностью адресов, которым соответствуют ячейки памяти, порты или
регистры внешних устройств.
— активный
элемент (Ea)
— доступ к ресурсу без
— пассивный
— доступ к общему ресурсу
арбитража (Cm)
с арбитражем (Cc)
элемент (Ep)
— доступ к ресурсу
— комбинированный
с преобразованием
параметров (Cw)
элемент (Ea, Ep)
— элемент коммуника-
ционной среды (Ec)
i
— управляющее воздействие
на активный элемент (Ca)
Рис.2.3. Функциональные обозначения
Комбинированные устройства могут одновременно выполнять функции активных и пассивных элементов. Такими устройствами, например,
являются контроллеры прямого доступа к памяти. Они, как и процессоры,
могут обращаться к памяти, но, в то же время, процессоры могут обращаться к ним в программном режиме как к пассивным устройствам.
Элемент коммуникационной среды используется для обозначения магистрали (шины, канала) передачи данных совместно с интерфейсами
устройств, которые подключены к данной магистрали.
К собственному адресному пространству процессор обращается путем
выполнения стандартных циклов обращения (чтения, записи и т.д.).
Доступ к общему аппаратному ресурсу требует наличия арбитров для
разрешения конфликтов при одновременном обращении к ресурсу нескольких активных устройств. Конфликты при попытках одновременного
доступа разрешаются с учетом определенных дисциплин обслуживания
запросов.
Доступ с преобразованием параметров требует наличия в системе специального устройства. Например, это может быть устройство преобразования адресов, которое позволяет осуществить «оконный» доступ к адресно-
16.
Глава 2. Классификация и языки описания архитектуры систем29
му пространству другого процессора. Предварительно это устройство
должно быть настроено процессором путем записи в него определенной
информации. При необходимости на дугах можно использовать обозначения, поясняющие характер преобразования параметров.
Примером управляющего воздействия на активный элемент может
служить запрос на прерывание программы процессора или перевод процессора в режим ожидания. Если на активный элемент действуют различные
сигналы, то соответствующие дуги могут отмечаться различными буквами
(например, сигнал прерывания можно обозначить через i (interrupt), как на
рис. 2.3).
Ориентация функциональных элементов на графе может быть произвольной. На изображения функциональных элементов могут наноситься
буквенные обозначения.
В дальнейшем, в качестве основных, будем использовать такие обозначения:
P – процессор;
GM – общая (глобальная) память;
LM – собственная (локальная) память;
IO – устройство ввода-вывода;
GB – системная (глобальная) магистраль;
LB – внутренняя (локальная) магистраль.
Каждой дуге графа может быть приписан вес, соответствующий времени выполнения заданного действия в определенных условных единицах.
Взвешенные графы используются для сравнительной оценки временных
параметров различных систем.
Карта распределения адресного пространства отображает память
всей системы и распределение ее между активными архитектурными элементами (процессорами, сопроцессорами и т.д.). Процессор при этом рассматривается как совокупность регистров, которые не включаются в адресное пространство, но могут участвовать в пересылках информации.
Пример описания архитектуры двухпроцессорной системы показан на
рис. 2.4. Он отражает общую организацию системы и разные варианты доступа процессоров к пассивным элементам.
Процессоры P1 и P2 имеют собственную локальную память (LM1 и
LM2), а также общую (глобальную) память GM. Как следует из карты распределения памяти (рис. 2.4 б), Адресное пространство каждого процессора
включает M адресов. Старшие M-L адресов образуют общее адресное пространство, а L младших – локальное пространство каждого процессора.
Доступ к общей памяти возможен для каждого процессора. Конфликты
разрешаются с помощью системы арбитража. Адреса внешних устройств в
данном примере включены в адресное пространство соответствующей памяти. Устройства IO1 и IO2 доступны только первому процессору. С
устройствами IO3 и IO4 могут работать оба процессора.
17.
30Архитектура вычислительных систем реального времени
Процессору P1 также доступна память LM2 второго процессора. Для
этого используется механизм «оконного» доступа, который обеспечивается
специальным устройством (на функциональном уровне описания архитектуры отображаются только функции этого устройства). Для работы с «окном» в общем адресном пространстве выделена область W, через которую
процессор P1 обращается к LM2.
Первый процессор может воспринимать сигналы внешних прерываний
от устройства IO1 и от второго процессора. Если процессор P 2 не имеет отдельных выходов для формирования внешних управляющих сигналов (как
в данном примере), то он может формировать сигнал прерывания путем
обращения к определенному адресу I собственного адресного пространства. В интерфейсе шины процессора LB 2 селектор данного адреса может
исполнить роль формирователя сигнала прерывания.
Граф управляющих потоков на рис. 2.4,а является взвешенным. Такой
граф можно использовать для определения времени доступа процессоров к
различным ресурсам системы. Каждой дуге графа приписан определенный
вес, который выражает длительность выполнения соответствующих действий, а именно:
tm – длительность цикла обращения к памяти;
tw – длительность инициализации «окна»;
tal – длительность арбитража локальной магистрали;
tag– длительность арбитража системной магистрали.
Временные параметры можно оценивать через определенные условные единицы времени, например, через длительность цикла обращения к
памяти, цикла процессора и т.д.
Времени доступа к определенному ресурсу соответствует сумма весов
всех дуг графа, соединяющих вершины процессора и этого ресурса.
Например, для рассматриваемой архитектуры время одного обращения
первого процессора к общей памяти (ТОП) и к локальной памяти другого
процессора (ТЛП2) можно отобразить соответственно в виде
ТОП = ta g + tm,
ТЛП2 = ta g + tw + ta l + tm.
Для представленной архитектуры характерной особенностью является
необходимость предварительной инициализации «окна» при обращении к
локальной памяти второго процессора. Однако при многократном обращении это осуществляется один раз. Если подряд выполняется M обращений,
то среднее время на инициализацию «окна» составляет tw/M. Следует также
учитывать, что время арбитража для разных магистральных протоколов в
общем случае различно. Оно определяется числом активных устройств и
дисциплинами обслуживания запросов, которые реализуют арбитры. Таким
образом, определение временных параметров систем в каждом конкретном
18.
Глава 2. Классификация и языки описания архитектуры систем31
случае обусловлено особенностями архитектуры. Ниже этот вопрос будет
рассмотрен более подробно.
P1
IO1
ti o
P2
LM1
IO2
ti o
LM2
tm
tm
LB1
LB2
ta g
ta l
ta l
ta g
tw
tm
GM
ti o
ti o
GB
IO4
IO3
а)
0
P1
P2
LM1
LM2
I
IO1
L-1
L
Адрес для
формирования
запроса на
прерывание
IO2
GM
W
Область
внешних
устройств
IO3
IO4
M-1
б)
Рис.2.4. Описание архитектуры двухпроцессорной системы (а – граф
управляющих потоков; б – карта распределения памяти)
Графическое описание архитектуры систем с использованием предлагаемого языка отображает существенные свойства и отношения изучаемого объекта и, следовательно, является моделью систем на функциональном уровне описания.
19.
32Архитектура вычислительных систем реального времени
Использование моделей позволяет на стадии проектирования архитектуры исследовать различные варианты взаимодействия процессоров между
собой и с внешними устройствами, абстрагируясь при необходимости от
конкретной элементной базы (спецификации системы команд, стандартов
магистралей, протоколов обмена и т.д.). В частности, модели дают возможность:
исследовать варианты синхронизации процессов обмена информацией между компонентами системы;
разработать способы доступа к общему системному ресурсу;
выбрать в соответствии с целевыми функциями проектирования
оптимальное распределение адресного пространства процессоров;
определить в относительных единицах длительности различных
процессов.
Такая возможность во многом обусловлена описанием взаимодействия
модулей системы через потоки управляющих (control) воздействий. По
аналогии с названием языка MSBI данный язык можно определить как
MSBC (master, slave, bus, control), а модели, описанные на этом языке – как
MSBC-модели.
К достоинствам языка следует также отнести то, что он позволяет
представить модель в форме, близкой к структурной схеме системы. Это
дает возможность проще передавать идеи в области организации структуры
системы и упрощает дальнейшую разработку проекта.
20.
ГЛАВА 3АРХИТЕКТУРА СИСТЕМ С МАГИСТРАЛЬНОЙ
ТОПОЛОГИЕЙ
3.1. Системы с единым адресным пространством
Рассмотрим типовые архитектуры МВС с общей магистралью, получившие наибольшее распространение. Для описания архитектуры систем
будем использовать MSBC-модели.
Наиболее простыми с точки зрения технической реализации являются
системы c общей памятью, архитектура которых поясняется рис. 3.1 [15,
25, 28, 46]. Все процессоры P 1–Pn имеют одно общее адресное пространство, включающее G адресов. Коммуникационной средой является общая
системная магистраль GB. Общая память GM и внешние устройства IO
являются общим аппаратным системным ресурсом, доступ к которому
осуществляется через магистраль GB. Внешние устройства могут иметь
собственное адресное пространство или им может быть выделена часть
пространства общей памяти, как показано на рис. 3.1,б. Системы с рассматриваемой архитектурой, построенные на базе одинаковых процессоров,
называют симметричными мультипроцессорами (symmetric multiprocessor)
или SMP-системами.
P1
...
P1
P1
P2
…
Pn
GM
G
Область
внешних
устройств
IO
GB
GM
Pn
IO
а)
б)
Рис. 3.1. Организация системы с единым адресным пространством
(а – граф управляющих потоков; б – карта распределения памяти)
В системах с единым адресным пространством общая память используется не только для хранения системной информации и обмена между
процессорами, но и для хранения программ процессоров. При выполнении
21.
34Архитектура вычислительных систем реального времени
программ процессоры обращаются к памяти за командами, что приводит к
большим затратам времени на ожидание доступа и разрешение конфликтов.
Наличие в каждом процессорном модуле кэш-памяти уменьшает число
конфликтов при обращении к общей памяти. Однако в этом случае возникают трудности с обеспечением когерентности данных, что усложняет взаимодействие процессоров.
В системах с такой организацией памяти используется небольшое число процессоров (например, SMP-серверы обычно строятся на основе 2, 4
или 8 процессоров).
Увеличение количества процессоров в системе связано с необходимостью уменьшения числа конфликтных ситуаций при обращении процессоров к общей памяти. Это может быть достигнуто за счет использования в
каждом процессорном модуле собственной локальной памяти.
Ниже рассматриваются архитектуры систем с комбинированным адресным пространством, особенностью которых является наличие локальной памяти в каждом процессорном модуле. Для определенности будем
считать, что адреса внешних устройств включены в адресное пространство
памяти.
3.2. Системы с локальной памятью
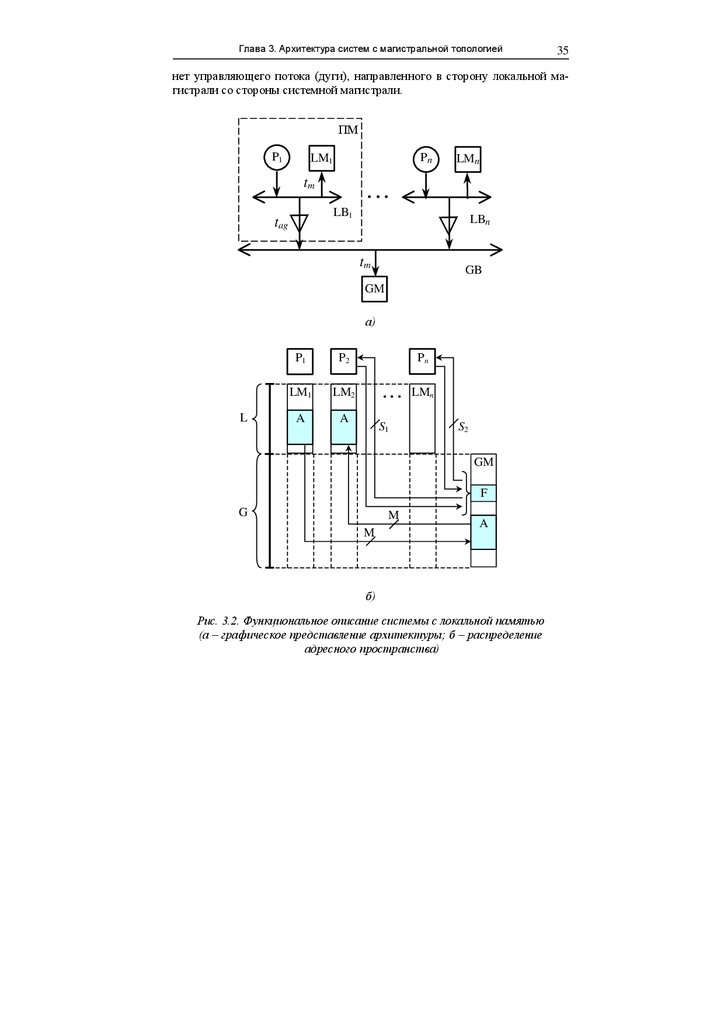
Широкое применение находят системы, в которых наряду с общей памятью каждый процессор имеет свою локальную память [15, 25, 44]. На
рис. 3.2 показана обобщенная модель системы с локальной памятью. Процессор Pi, локальная память LMi и интерфейсные схемы могут быть выполнены в виде процессорного модуля (ПМ). При выполнении программ
процессоры по локальной магистрали LBi обмениваются информацией со
своей локальной памятью, объемом L слов. При этом выполняются стандартные циклы обращения к памяти: "чтение", "запись", "чтениемодификация-запись". В связи с этим при обработке параллельных ветвей
алгоритмов процессоры работают независимо друг от друга до тех пор,
пока не наступает необходимость обратиться к общей памяти GM, объемом
G слов. Адресное пространство каждого процессора включает L+G=2 m адресов (m – длина адреса). Если процессор генерирует адрес, попадающий в
область GM, то селектор адреса в интерфейсе процессора формирует сигнал требования доступа к системной магистрали GB. После предоставления
арбитром доступа выполняется цикл обращения к общей памяти. Поскольку арбитраж осуществляется аппаратно, то на программном уровне доступ
осуществляется одинаково ко всему адресному пространству процессора.
В системе не предусмотрен непосредственный доступ одного процессора к локальной памяти другого процессора. Действительно, на рис. 3.2,а
22.
Глава 3. Архитектура систем с магистральной топологией35
нет управляющего потока (дуги), направленного в сторону локальной магистрали со стороны системной магистрали.
ПМ
P1
Pn
LM1
tm
LMn
...
LB1
tag
LBn
tm
GB
GM
а)
L
P1
P2
LM1
LM2
A
A
Pn
. . . LMn
S1
S2
GM
F
G
M
M
A
б)
Рис. 3.2. Функциональное описание системы с локальной памятью
(а – графическое представление архитектуры; б – распределение
адресного пространства)
23.
Архитектура вычислительных систем реального времени36
По карте распределения адресного пространства (рис. 3.2,б) видно, что
в адресном пространстве процессора не представлена локальная память
других процессоров. Какой бы адрес не генерировал процессор Pi, он будет
относиться либо к LMi, либо к GM, то есть локальная память другого процессора остается недоступной. Этот факт должен учитываться при разработке процедур взаимодействия процессоров.
Для синхронизации процессов обмена могут применяться примитивы
операционной системы, использующие общую память (например, флажки
и семафоры). В этом случае управление процессами осуществляется с использованием шины данных.
Повысить эффективность совместной работы процессоров можно за
счет синхронизации процессов по шине управления. На этой шине арбитраж
не производится, так как для каждого сигнала выделяется собственная линия, что обеспечивает большую скорость обмена управляющей информацией. Процессор, на который поступает управляющий сигнал, воспринимает его как внешнее прерывание и переходит на соответствующую подпрограмму обслуживания прерывания.
Модель трехпроцессорной системы с возможностью синхронизации
процессов по шине управления показана на рис. 3.3. Распределение памяти
в этом случае остается таким же, как показано на рис. 3.2,б. Выработка
сигналов прерывания может быть осуществлена специальным блоком, подключенным к локальной шине процессора. Для взаимодействия процессора
с блоком выделяются адреса в адресном пространстве ввода-вывода или
локальной памяти процессора. Записи слова по определенному адресу
обеспечивает выработку сигналов требования прерывания для других процессоров.
P1
P2
LM1
P3
LM2
LM3
3
LB2
LB1
LB3
GB
GM
Рис. 3.3. Организация системы с синхронизацией процессов
по шине управления
24.
Глава 3. Архитектура систем с магистральной топологией37
3.3. Системы с коммуникационной памятью
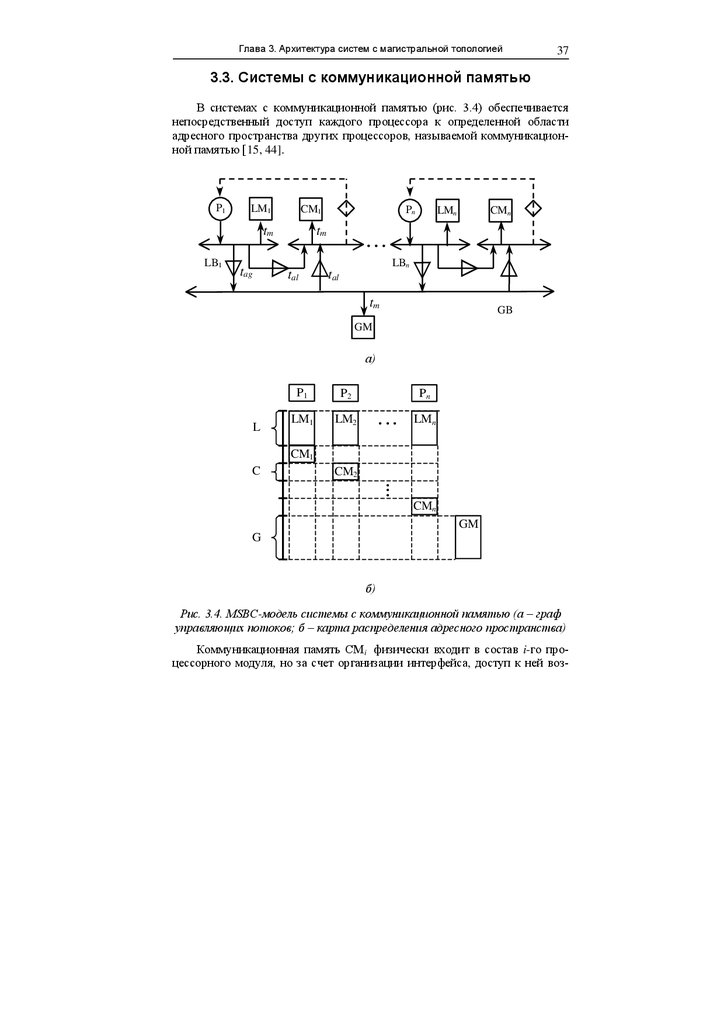
В системах с коммуникационной памятью (рис. 3.4) обеспечивается
непосредственный доступ каждого процессора к определенной области
адресного пространства других процессоров, называемой коммуникационной памятью [15, 44].
P1
LM1
CM1
tm
LB1
Pn
tm
LMn
CMn
...
LBn
tag
tal
tal
tm
GB
GM
а)
L
P1
P2
LM1
LM2
Pn
...
LMn
CM1
C
CM2
..
.
CMn
GM
G
б)
Рис. 3.4. MSBC-модель системы с коммуникационной памятью (а – граф
управляющих потоков; б – карта распределения адресного пространства)
Коммуникационная память CMi физически входит в состав i-го процессорного модуля, но за счет организации интерфейса, доступ к ней воз-
25.
Архитектура вычислительных систем реального времени38
можен как со стороны локальной, так и со стороны системной магистрали.
Коммуникационную память можно рассматривать как распределенные
между процессорами фрагменты общей памяти системы, объемом C слов.
Из приведенной MSBC-модели видно, что при обращении процессора
к последним G адресам своего адресного пространства арбитраж осуществляется один раз (управляющий поток представлен одной дугой, определяющей процесс арбитража). Доступ же со стороны i-го процессора к коммуникационной памяти j-го процессора осуществляется путем поочередного
захвата сначала системной магистрали, а потом и локальной магистрали jго процессора (двойной арбитраж).
В системах с коммуникационной памятью для синхронизации процессов могут применяться межпроцессорные прерывания, реализованные по
аналогии с рис. 3.3. В этом случае для передачи вектора прерывания системная магистраль не используется. Наличие коммуникационной памяти,
доступной другим процессорам, позволяет организовать прерывания более
экономично, как показано на рис. 3.4. В коммуникационной памяти процессора можно выделить адрес, обращение к которому со стороны другого
процессора вызывает инициализацию прерывания для данного процессора.
Идентификация источника прерывания может определяться словом, которое пересылается через системную магисталь по соответствующему адресу.
P1
LM1
CM1
Pn
LMn
CMn
...
LB1
LBn
GB
GM
Рис. 3.5. Система с двухпортовой коммуникационной памятью
Для уменьшения времени обращения к коммуникационной памяти используют двухпортовую память (рис. 3.5). Двухпортовая память организована таким образом, что возможно одновременное обращение к памяти со
стороны разных портов. Конфликт может возникнуть только при обращении к одному адресу. Такой конфликт разрешается интерфейсом самой памяти. При такой организации коммуникационной памяти длительность
доступа к ней в общем случае сокращается (не расходуется время на захват
локальной магистрали).
26.
Глава 3. Архитектура систем с магистральной топологией39
Возможность доступа к части адресного пространства локальной памяти позволяет процессорам более эффективно обмениваться информацией. Однако с увеличением числа процессорных модулей все больший объем
адресного пространства выделяется на блоки коммуникационной памяти, в
результате чего сокращается объем локальной памяти в каждом процессорном модуле.
3.4. Системы с «оконным» доступом
к локальной памяти
Для обеспечения доступа ко всему адресному пространству локальной
памяти каждого процессора со стороны других процессоров может быть
использован «оконный» механизм доступа [15]. Организация систем с таким доступом показана на рис. 3.6.
Возможны различные варианты построения «окна» (W). «Окно» может быть пассивным или активным устройством доступа к магистрали (рис.
3.6 соответствует пассивному устройству). От этого зависит и число адресов V, выделяемое каждому «окну». Структура пассивного «окна» показана
на рис. 3.7. Устройство подключается между системной (СМ) и локальной
(ЛМ) магистралями. В адресном пространстве общей памяти выделяется
два адреса для обращения к регистру адреса (РА) и регистру данных (РД).
Доступ к регистрам обеспечивается интерфейсом (ИСМ). В регистр адреса
записывается начальный адрес локальной памяти, к которой осуществляется доступ со стороны СМ. Передача данных (чтение или запись) осуществляется через РД. При обращении к РД интерфейс системной магистрали
(ИСМ) вырабатывает сигнал, который модифицирует адрес в РА (например, прибавляет или вычитает константу). Устройство доступа к локальной
магистрали (УДЛМ) осуществляет запись или чтение данных из локальной
памяти по адресу в РА. Обращение к ЛМ осуществляется в режиме прямого доступа (ПДП) с соблюдением протокола магистрали (режим DMA –
Direct Memory Access). Пассивное устройство фактически ретранслирует
стандартные циклы обращения к памяти, которые выполняет процессор,
осуществляющий доступ.
Активное “окно” является более сложным устройством, которое может
самостоятельно пересылать данные из локальной памяти одного процессора в локальную память другого. В данном случае процессор выполняет
инициализацию “окна”, передавая ему начальные адреса, объем пересылаемого массива и команду. После этого активное устройство самостоятельно
осуществляет пересылку массива. Для организации “окна” выпускаются
специальные микросхемы (в частности, фирмой DEC).
27.
Архитектура вычислительных систем реального времени40
P1
LM1
Pn
...
LMn
tm
LB1
tag
LBn
tal
tal
tw
tm
GB
GM
а)
L
P1
P2
LM1
LM2
Pn
...
LMn
Wn
..
.
V
W2
W1
GM
G
б)
Рис. 3.6. Организация системы с “оконным” доступом к локальной памяти
процессоров (а – граф потоков управления; б – карта распределения памяти)
Таким образом, рассматриваемая архитектура обеспечивает полный
доступ к локальной памяти каждого процессора со стороны других процессоров. Если порты внешних устройств включены в адресное пространство
локальной памяти, то с помощью механизма «окна» другим процессорам
становятся доступны и эти устройства.
28.
Глава 3. Архитектура систем с магистральной топологией41
ЛМ
УДЛМ
РА
РД
ИСМ
СМ
Рис. 3.7. Структура “окна”
Когда в процессе обмена информацией к одному "окну" могут обращаться несколько процессоров, то перед обращением процессор должен
предварительно захватить "окно" (запретить доступ к нему другим процессорам) с использованием определенных примитивов операционной системы (например, семафоров).
3.5. Сравнительная характеристика систем
с общей магистралью
Для сравнительной оценки архитектур МВС на функциональном
уровне будем использовать следующие характеристики:
рабочий объем памяти;
время обращения к памяти;
коэффициент эффективности использования системной магистрали.
Архитектуры систем с локальной памятью, коммуникационной памятью и «оконным» доступом для удобства обозначим соответственно цифрами I, II и III.
Под рабочим объемом памяти будем понимать объем памяти, который
используется для хранения информации, связанной непосредственно с решением задач (системные и пользовательские программы, данные и т.д.). В
МВС часть адресного пространства процессора может выполнять служебные функции, связанные с обеспечением доступа к различным ресурсам и,
следовательно, не может быть использована для хранения программ и данных.
Для определенности будем считать, что системы являются однородными, то есть построены на одинаковых процессорах. Каждый процессор
29.
Архитектура вычислительных систем реального времени42
характеризуется длиной адреса – m и данных – d. Таким образом, адресное
m
пространство каждого процессора составляет 2 адресов, причем, адрес
генерируется процессором за один цикл обращения к магистрали.
Каждой архитектуре соответствует определенное распределение адресного пространства. В связи с этим при одинаковой длине адреса каждая
архитектура отличается рабочим объемом памяти. Для определенности
будем полагать, что объем общей памяти G одинаков для всех систем, а для
архитектур II и III соответственно объемы памяти C и V одинаковы для
всех процессоров. Введем обозначения:
MР – суммарный рабочий объем памяти системы;
MЛ – рабочий объем локальной памяти одного процессора;
MД – дополнительный рабочий объем памяти, который физически принадлежит локальной памяти других процессоров, но данный процессор
имеет к нему доступ.
Анализируя MSBC-модели на рис. 3.2, 3.4 и 3.6, получаем для рассматриваемых архитектур значения рабочих объемов памяти (в числе
слов), которые сведены в табл. 3.1.
Из табл. 3.1 видно, что архитектура I обеспечивает максимальный рабочий объем локальной памяти каждого процессора и суммарный физический объем памяти системы, но при этом отсутствует возможность доступа
процессора к локальной памяти других процессоров. Архитектура II характеризуется самым малым объемом эффективной памяти, а архитектура III
занимает промежуточное положение. При этом два последних варианта
построения систем дают возможность обращаться процессорам к локальной памяти других процессоров. Так как при работе с «окном» начальный
адрес массива передается по шине данных, то максимальный дополнительный объем памяти MД для архитектуры III ограничивается величиной
(n-1)2d.
Табл. 3.1
Рабочий объем памяти
Архитектура
Суммарный объем
памяти (MР)
Объем локальной
памяти (MЛ)
Дополнительный
объем памяти (MД)
I
2mn-(n-1)G
2m-G
Нет
II
2mn-(n-1)(nC+G)
2m-(n-1)C-G
(n-1)C
III
m
2 n-(n-1)(nV+G)
m
2 -nV-G
(n-1)(2m-nV-G)
Время обращения к памяти. Применение MSBC-моделей позволяет
сравнивать длительность обращения к памяти для различных архитектур.
Для определения временных характеристик используется взвешенный граф
управляющих потоков. Каждой дуге придается вес, который определяется
30.
Глава 3. Архитектура систем с магистральной топологией43
временем выполнения соответствующего действия. Длительность обращения к аппаратному ресурсу определяется весами всех дуг графа, соединяющих вершины, соответствующие процессору и этому ресурсу. Введем
обозначения:
tm – длительность цикла обращения к модулю памяти (без учета времени ожидания доступа);
tal – время ожидания доступа к локальной магистрали;
tag– время ожидания доступа к системной магистрали;
tw – длительность инициализации «окна».
Например, в соответствии с рис. 3.4 для архитектуры II длительность
обращения к собственной локальной памяти, к собственной коммуникационной памяти (с учетом времени ожидания доступа), к коммуникационной
памяти других процессоров (к дополнительной памяти) и общей памяти
будет определяться соответственно выражениями:
ТЛП = tm ,
ТКП = tm + tal,
ТДП = tm + tal+ tag,
ТОП = tm + tag.
Задача определения времени ожидания доступа к различному ресурсу
относится к задачам теории массового обслуживания. Время ожидания доступа зависит от многих факторов, в том числе, от количества процессоров,
интенсивности запросов на доступ, длительности и дисциплин обслуживания запросов. Как будет показано ниже, в многопроцессорных системах
наиболее эффективными являются арбитры, реализующие бесприоритетную дисциплину обслуживания FIFO, а также дисциплину с динамическим
изменением приоритетов (когда каждый из процессоров после очередного
доступа к ресурсу автоматически получает низший приоритет). Потоки
запросов можно считать стационарными пуассоновскими. Тогда среднее
время ожидания обслуживания, которое одинаково для всех процессоров,
можно определить по формуле [47]
n
tср
(1 v
j 1
j
j
2(1 R)
2
j
)
,
где j – загрузка ресурса обслуживанием запросов
j-го процессора;
n
R k – суммарная загрузка ресурса; j – средняя длительность цикла
k 1
обращения к ресурсу j-м процессором; j - коэффициент вариации, определяющий отношение среднеквадратического отклонения длительности обслуживания к его математическому ожиданию.
Для систем реального времени, как правило, имеет место ситуация, когда определена максимальная продолжительность преобразования инфор-
31.
Архитектура вычислительных систем реального времени44
мации, превышение которой недопустимо. В этом случае необходимо учитывать максимальные временные параметры. При указанных дисциплинах
обслуживания заявок любому процессору гарантирован доступ к магистрали через (n-1) максимальных по длительности циклов обращения к ней со
стороны других процессоров, где n – число процессоров, участвующих в
арбитраже. Так как арбитраж локальной магистрали осуществляется только
между двумя процессорами, то максимальное время ожидания равно одному циклу. При обращении к системной магистрали, к которой подключены
n процессоров, время ожидания доступа не превышает (n-1) циклов. Заметим, что для архитектуры II при обращении процессора к однопортовой
коммуникационной памяти другого процессора вначале осуществляется
доступ к системной магистрали, а затем – к локальной, то есть выполняется
двойной арбитраж.
Характерной особенностью архитектуры III является необходимость
предварительной инициализации «окна» при обращении к локальной памяти других процессоров. Если к "окну" могут обращаться несколько процессоров, то инициализация включает захват "окна" (запрет доступа к ресурсу
другим процессорам) и его настройку. Захват может быть осуществлен с
использованием семафоров в общей памяти. Если "окно" используется другими процессорами, то для проверки семафора может понадобиться несколько попыток (обозначим максимальное значение количества попыток
через P). Настройка "окна", в свою очередь, требует одного обращения к
системной магистрали для записи начального адреса массива. Инициализация "окна" осуществляется один раз в процессе пересылки массива слов за
время tW. Следовательно, на каждое передаваемое слово приходится tW/M
времени инициализации (М – длина массива). Если к "окну" может обращаться только один процессор (например, при централизованном управлении процессом пересылки информации), то захватывать "окно" нет необходимости.
Табл. 3.2
Время обращения к памяти
Архитектура
TЛП, tm
TКП, tm
TОП, tm
TДП, tm
I
1
–
n
–
II
1
2
n
2n
III
2
–
n
2n+(P+1)( 2n-1)/M
Для сравнения различных архитектур временные параметры необходимо привести к единой условной единице времени. В качестве такой
условной единицы (с приемлемой на этапе разработки архитектуры погрешностью) можно принять, например, длительность tm цикла обращения
32.
Глава 3. Архитектура систем с магистральной топологией45
к модулю памяти (без учета длительности ожидания доступа). Для рассматриваемых архитектур максимальные значения временных характеристик приведены в табл. 3.2.
Из табл. 3.2 следует, что архитектура I обеспечивает минимальное
время доступа ко всему адресному пространству собственной локальной
памяти. По отношению к общей памяти все архитектуры одинаковы. К памяти других процессоров обращение осуществляется быстрее в системах с
архитектурой II.
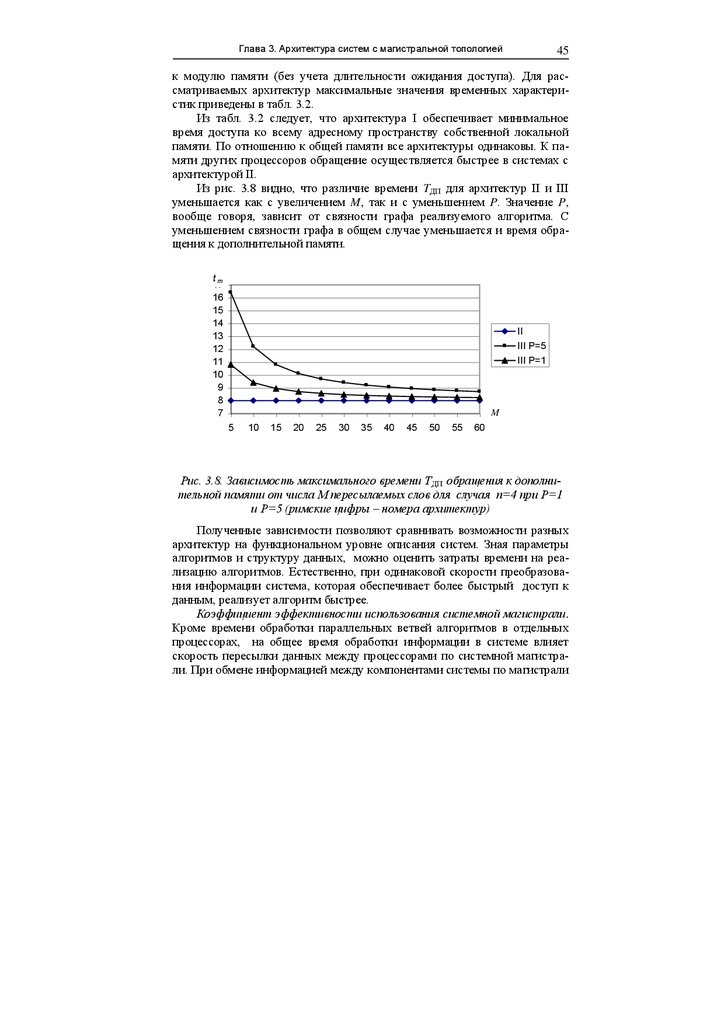
Из рис. 3.8 видно, что различие времени TДП для архитектур II и III
уменьшается как с увеличением M, так и с уменьшением P. Значение P,
вообще говоря, зависит от связности графа реализуемого алгоритма. С
уменьшением связности графа в общем случае уменьшается и время обращения к дополнительной памяти.
t
m
tm
17
16
15
14
13
12
11
10
9
8
7
II
III P=5
III P=1
M
5
10
15
20
25
30
35
40
45
50
55
60
Рис. 3.8. Зависимость максимального времени TДП обращения к дополнительной памяти от числа M пересылаемых слов для случая n=4 при P=1
и P=5 (римские цифры – номера архитектур)
Полученные зависимости позволяют сравнивать возможности разных
архитектур на функциональном уровне описания систем. Зная параметры
алгоритмов и структуру данных, можно оценить затраты времени на реализацию алгоритмов. Естественно, при одинаковой скорости преобразования информации система, которая обеспечивает более быстрый доступ к
данным, реализует алгоритм быстрее.
M
Коэффициент эффективности использования системной магистрали.
Кроме времени обработки параллельных ветвей алгоритмов в отдельных
процессорах, на общее время обработки информации в системе влияет
скорость пересылки данных между процессорами по системной магистрали. При обмене информацией между компонентами системы по магистрали
33.
46Архитектура вычислительных систем реального времени
кроме полезной информации (непосредственно данных) передается, как
правило, служебная информация, которая обеспечивает инициализацию и
синхронизацию процессов обмена информацией. Непроизводительные затраты времени обусловлены особенностями архитектуры.
Для сравнительной оценки эффективности использования системной
магистрали в различных системах будем использовать коэффициент KСМ,
который определяется по формуле
NS ND
(3.1)
,
M
где NS – число обращений к системной магистрали для инициализации и
синхронизации процедур обмена (непроизводительные затраты времени);
ND – число обращений к системной магистрали для передачи непосредственно данных; M – число передаваемых слов.
Коэффициент KСМ определяет среднее число обращений к системной
магистрали для передачи одного слова между компонентами системы. При
равной скорости обработки параллельных ветвей алгоритмов система с
меньшим значением KСМ будет затрачивать и меньше времени на решение
задач за счет более быстрого межпроцессорного обмена.
Непроизводительные затраты времени зависят от способов инициализации и синхронизации процессов. Инициализация и синхронизация может
осуществляться как по шине управления (например, с применением прерываний), так и по шине данных (с использованием флажков и семафоров).
Управление пересылкой информации по системной магистрали может быть
централизованным и децентрализованным. В первом случае обменом
управляет один процессор, который имеет доступ к памяти других процессоров. При децентрализованном управлении в синхронизации обмена данными принимает участие в определенной мере каждый процессор. Время
использования магистрали для систем с разной архитектурой и разным
способом управления при передаче данных может отличаться. Рассмотрим
организацию обмена данными в системах с разной архитектурой. Процессы
обмена будем рассматривать на уровне команд процессоров, а не операторов языков высокого уровня. При таком подходе более наглядно проявляются особенности архитектуры систем.
Определение KСМ в общем случае является нетривиальной задачей и
требует разработки программ (если известна система команд) или, по крайней мере, алгоритмов синхронизации и пересылки данных.
Вначале рассмотрим реализацию обмена информацией, когда синхронизация процессов осуществляется по шине данных. Возможный подход к
определению коэффициента эффективности KСМ покажем на примере децентрализованного обмена данными в системе с архитектурой I (рис. 3.2).
Будем считать, что необходимо передать массив данных из локальной памяти одного процессора в локальную память другого процессора. АрхитекK СМ
34.
Глава 3. Архитектура систем с магистральной топологией47
тура I позволяет осуществлять обмен информацией между процессорами
только через общую память.
Пересылка данных осуществляется после выполнения процессором
определенного задания, в результате которого в локальной памяти получен
массив данных для пересылки другому процессору.
Синхронизация обмена может быть осуществлена с использованием
механизма флажков. Флажок – примитив синхронизации процессов. Будем
считать, что флажок устанавливается в единицу, когда процесс передачи
массива в общую память закончен. Если же флажок равен нулю, то информация в общей памяти для обмена не готова. Флажок F располагается в
общей памяти GM и доступен как передающему, так и принимающему информацию процессору (рис. 3.2,б). Для процедур обмена между разными
процессорами используются разные флажки.
Для обмена данными в памяти процессоров выделяются фиксированные области. В общем случае к непроизводительным затратам времени
следует добавить загрузку в память процессоров информации о начальных
адресах и размерах массивов. Однако в системах реального времени такая
загрузка производится, как правило, только при инициализации кадра
управления, причем, это осуществляться без ограничений по времени.
Траектории пересылок информации при передаче одномерного массива А длиной М слов из LM2 в LMn показаны на карте распределения памяти
(рис. 3.2,б) сплошными линиями со стрелками. Количество пересылок указано на линиях. Ниже приводятся возможные варианты программ на ассемблере для передачи массива из 30 слов.
; Программа передачи данных из локальной памяти в общую память
VERSION
M510
; директива для совместимости с MASM 5.10
LP
LDATA
SEGMENT USE16
dw 30 dup (?)
ENDS
; сегмент данных в локальной памяти
; 30 слов
GP
FLAG
GDATA
SEGMENT USE16
dw 0
dw 30 dup (?)
ENDS
; сегмент в общей памяти системы
; флажок готовности массива
; 30 слов
_STACK SEGMENT STACK USE16
DB 100 DUP (?)
ENDS
CODE
; сегмент стека
; резервирование 100 байт
SEGMENT USE16
; сегмент кода
ASSUME CS:CODE,DS:LP,ES:GP,SS:_STACK
; метка начала исполняемого кода
; инициализация сегментных регистров
START:
MOV
AX,LP
35.
Архитектура вычислительных систем реального времени48
MOV
MOV
MOV
MOV
MOV
DS,AX
AX,GP
ES,AX
AX,_STACK
SS,AX
; Подготовка массива данных в локальной памяти
;______________________________________________________
LBLP1_1:
;
.
;
.
;______________________________________________________
; Пересылка данных из локальной памяти в общую память
mov
mov
mov
cld
LBLP1_2:
jnz
rep
cx, 30
si, offset LDATA
di, offset GDATA
; размерность массива
; смещение массива в локальной памяти
; смещение массива в общей памяти
; назначить инкремент регистров SI и DI
test
FLAG, 0ffffh
; проверка флажка готовности
LBLP1_2
; массива в общей памяти
movsw
mov
ES:FLAG, 1
; пересылка массива из 30 слов
; установка флажка готовности массива
jmp
LBLP1_1
; перейти к формированию массива
ENDS
END STAR
; Программа приема данных из общей памяти в локальную память
VERSION
M510
; директива для совместимости с MASM 5.10
LP
LDATA
SEGMENT USE16
dw 30 dup (?)
ENDS
; сегмент данных в локальной памяти
; 30 слов
GP
FLAG
GDATA
SEGMENT USE16
dw 0
dw 30 dup (?)
ENDS
; сегмент в общей памяти системы
; флажок готовности массива
; 30 слов
_STACK SEGMENT STACK USE16
DB 100 DUP (?)
ENDS
CODE
; сегмент стека
; резервирование 100 байт
SEGMENT USE16
; сегмент кода
ASSUME CS:CODE,DS:GP,ES:LP,SS:_STACK
; метка начала исполняемого кода
; инициализация сегментных регистров
START:
MOV
AX,GP
36.
Глава 3. Архитектура систем с магистральной топологиейMOV
MOV
MOV
MOV
MOV
49
DS,AX
AX,LP
ES,AX
AX,_STACK
SS,AX
; Пересылка данных из общей памяти в локальную память
; размерность массива
; смещение массива в общей памяти
; смещение массива в локальной памяти
; назначить инкремент регистров SI и DI
LBLP2_1 mov
mov
mov
cld
cx, 30
si, offset GDATA
di, offset LDATA
LBLP2_2:
jz
test
FLAG, 0ffffh
; проверка флажка
LBLP2_2
; готовности массива
rep
movsw
mov
FLAG, 0
; пересылка массива (из DS:SI в ES:DI)
; сброс флажка готовности
; Обработка полученного массива данных в локальной памяти
;_________________________________________________________
;
.
;
.
;
.
jmp
LBLP2_1
; переход на проверку готовности массива
;_________________________________________________________
ENDS
END START
В рассматриваемом случае процесс непосредственной передачи информации требует выполнения ND=2M циклов обращения к системной магистрали. (Команды обращения к общей памяти выделены в программах
жирным шрифтом). Число обращений к общей памяти для синхронизации
(для анализа и установки флажка) составляет NS=2+S1+S2 (см. рис. 3.2,б).
Следовательно, в соответствии с (3.1) получим
2 S1 S2
KСМ 2
.
M
Число обращений к общей памяти для проверки флажков может изменяться в широком диапазоне. Это зависит от количества процессоров,
начального состояния процесса обмена данными, дисциплин обслуживания
запросов на доступ к системной магистрали, интенсивности потока запросов и т.д. Взаимодействие двух процессоров при передаче массива данных
иллюстрируется с помощью сети Петри на рис. 3.8. Позиции сети соответствуют состояниям двух процессоров: a1 и b1 – проверка флажка; a2 и b2 –
пересылка массива; a3 и b3 – установка флажка. Можно показать, что при
определенных исходных состояниях (например, как показано фишками)
сумма S может достигать M и более. Тогда для передачи слова из одного
37.
Архитектура вычислительных систем реального времени50
процессорного модуля в другой необходимо обратиться к системной магистрали более трех раз.
Очевидно, что синхронизация процессов с использованием флажков в
общей памяти может привести к большим непроизводительным затратам
времени при пересылке данных.
a1
t1
a2
t2
a3
t3
F
t4
F
c1
t8
b2
t5
F
b3
b1 t 7
t6
c2
F
Рис. 3.8. Сеть Петри взаимодействия процессоров: { t1 , t8 } – множество
вершин переходов; {a1,a2,a3} – множество вершин позиций принимающего
процессора; {b1,b2,b3} – множество вершин позиций передающего процессора; с1 и c2 – согласующие вершины
Полученные аналогичным образом значения KСМ для различных архитектур при синхронизации процессов обмена по шинам данных сведены
в табл. 3.3.
Табл. 3.3
Эффективность использования системной магистрали
Архитектура
I
II
III
Коэффициент эффективности KСМ
Децентрализованный
обмен
2 (2 S1 S2 ) / M
Централизованный
обмен
—
1 2 / M
1 ( P1 P2 4) / M
2 4/ M
2 ( P1 P2 8) / M
В системах с архитектурой I централизованный обмен невозможен,
так как ни один процессор не может обратиться к локальной памяти других
38.
Глава 3. Архитектура систем с магистральной топологией51
процессоров, то есть управляющий процессор не может самостоятельно
осуществлять пересылку данных между другими процессорными модулями.
В системах с коммуникационной памятью (архитектура II) передаваемый массив формируется процессором в своей коммуникационной памяти. При децентрализованном обмене процессор, для которого подготовлен
массив данных, самостоятельно переписывает массив в свою локальную
память, так как коммуникационная память другого процессора ему доступна (см. рис. 3.4). Следовательно, пересылка массива требует ND= М обращений к системной магистрали. Для синхронизации процесса пересылки
можно использовать флажки, которые находится в коммуникационной памяти каждого процессора. Проверка и сброс флажка в этом случае выполняется в памяти каждого процессора без обращения к системной магистрали, а установка флажка – в коммуникационной памяти другого процессора.
Для установки флажков системная магистраль захватывается только два
раза, то есть NS =2.
При централизованном управлении передачу массива между двумя
процессорами осуществляет управляющий процессор. В этом случае для
передачи массива необходимо ND=2M обращений к магистрали. Синхронизация процессов требует четырех обращений к магистрали (NS =4). Два обращения требуются для установки в памяти управляющего процессора
двух флажков подчиненными процессорами, готовыми к обмену, а еще два
– для установки управляющим процессором флажков в памяти подчиненных после завершения передачи массива. Таким образом, архитектура II
при централизованном управлении уступает в скорости обмена системам с
децентрализованным обменом.
К непроизводительным затратам при использовании механизма «окна»
(архитектура III, рис.3.6) добавляется необходимость инициализации “окна”. В децентрализованных системах для синхронизации процессов можно
использовать флажки в локальной памяти процессоров. Это позволяет при
работе с флажками уменьшить число обращений к системной магистрали.
Флажки проверяются в своей локальной памяти, а устанавливаются в локальной памяти другого процессора. Для доступа одного процессора к локальной памяти другого процессора производится настройка "окна" путем
записи начального адреса массива. Предварительно необходимо оградить
“окно” от других процессоров с помощью семафора в общей памяти. Пересылка массива после настройки "окна" выполняется одним процессором за
ND=М обращений к магистрали. По окончании пересылки массива процессоры поочередно устанавливают флажки в локальной памяти других процессоров. Для вспомогательных операций магистраль используется в общей сложности NS P1 P2 4 раз, где P1 и P2 – число обращений к магистрали для проверки и установки семафоров каждым из процессоров. Если
39.
Архитектура вычислительных систем реального времени52
"окно" не занято другим процессором, то достаточно одного обращения к
семафору.
В централизованных системах процесс обмена данными осуществляет
управляющий процессор, который имеет доступ к локальной памяти каждого процессора. Непосредственно пересылка массива требует ND=2М обращений к системной магистрали. Для управляющего процессора отпадает
необходимость ограждения «окна» от других процессоров и его инициализация будет сводиться в простейшем случае к выполнению одной команды
занесения начального адреса. Однако процессоры, между которыми пересылается информация, должны поочередно установить флажки в локальной
памяти управляющего процессора. В общей сложности для синхронизации
магистраль используется NS = P1+P2+8 раз. Критические значения числа
попыток захвата семафоров нетрудно определить исходя из конкретных
параметров графа межпроцессорного обмена. Для этого достаточно иметь
информацию о максимальном числе конкурирующих процессоров и продолжительности использования "окна" каждым процессором.
На рис. 3.9 представлена диаграмма изменения максимального значения KСМ при увеличении длины массива для систем с различной архитектурой в предположении P1+P2=20. (Информация для систем с архитектурой I
не представлена ввиду неэффективности данной архитектуры из-за возможных больших затрат времени на синхронизацию процессов обмена
данными). С точки зрения эффективности обмена информацией системы с
централизованным управлением уступают системам с децентрализованным
управлением. При увеличении M приведенное число обращений к магистрали для пересылки одного слова стремится к единице для децентрализованных систем и к двум для централизованных.
K CM
8
7
6
II Д
II Ц
III Д
III Ц
5
4
3
2
1
0
M
5
10
15
20
25
30
35
40
45
50
55
60
Рис. 3.9. Диаграмма зависимости коэффициента KСМ от длины M массива : Д – децентрализованные системы; Ц – децентрализованные системы
(римские цифры – номера архитектур)
40.
Глава 3. Архитектура систем с магистральной топологией53
Очевидно, что с увеличением длины пересылаемых массивов различие
в значении коэффициента KСМ для архитектур II и III уменьшается. Однако,
при небольших массивах архитектура III существенно уступает в эффективности обмена архитектуре II.
Сократить число обращений к системной магистрали при межпроцессорном обмене позволяет синхронизация обмена данными по шине управления. При необходимости передать управляющую информацию процессор
обращается к своему блоку формирования сигналов прерывания. Для этого
процессор выполняет стандартный цикл записи (вывода). Адрес, по которому осуществляется обращение, может определять процессор, а пересылаемое слово – тип прерывания. Процессор, на который поступает управляющий сигнал, воспринимает его как требование внешнего прерывания и
переходит на соответствующую подпрограмму обслуживания прерывания.
Синхронизация с использованием прерываний снижает нагрузку на системную магистраль (табл. 3.4).
Табл. 3.4
Эффективность использования системной магистрали при синхронизации процессов по шине управления
Архитектура
Коэффициент эффективности KСМ
I
II
Децентрализованный
обмен
2
1
III
1 ( P 1) / M
Централизованный
обмен
—
2 2/ M
2 6/ M
Сравнивая табл. 3.3 и 3.4, нетрудно заметить, что в рассматриваемом
случае число обращений к шине данных для всех систем уменьшилось.
Однако в системах с "окнами" при централизованном обмене сохраняется
необходимость настройки двух "окон", а при децентрализованном – захвата
и настройки одного "окна".
Прерывания между процессорами могут быть реализованы с использованием как централизованных, так и распределенных контроллеров прерываний, реализующих приоритетную цепочку. Первая схема более гибкая, но для ее реализации требуется большое число линий запросов прерываний. При n процессорах число линий равно n2-n, что, например, для n=16
составляет 240. Естественно, что в системах с такой организацией прерываний увеличение числа процессоров резко увеличивает сложность шины
управления.
В системах II и III централизованный обмен можно организовать так,
чтобы запросы прерывания формировали только подчиненные процессоры.
При этом с целью уменьшения аппаратурных затрат целесообразно исполь-
41.
54Архитектура вычислительных систем реального времени
зовать распределенный контроллер (приоритетную цепочку). Для реализации распределенного контроллера прерываний в простейшем случае между
процессорами требуется только две линии управления. Вектор прерывания
в этом случае передается по шинам данных, то есть возникает необходимость дополнительного обращения к системной магистрали (в табл. 3.4
данные для централизованного обмена представлены с учетом этого факта).
Организация прерываний с распределенным контроллером соответствует требованию модульного принципа построения систем с открытой
архитектурой. В данном случае существенно упрощается задача наращивания числа процессорных модулей. За счет введения небольшой аппаратурной избыточности в системе могут быть использованы однотипные модули.
(Построение контролеров прерываний рассматривается подробнее в разделе 7).
Использование MSBC-моделей позволяет учесть особенности различных архитектур при выборе варианта построении системы. Выбор архитектуры зависит от многих факторов, которые определяются особенностями
реализуемых алгоритмов. При этом учитывается требуемый объем памяти,
связность графа межпроцессорного обмена, интенсивность обмена, длины
передаваемых массивов и т.д.
Характеристики MР, MЛ и MД позволяют оценить возможность использования той или иной архитектуры в зависимости от требуемого объема
памяти для хранения программ и данных. Характеристики ТЛП, ТКП, ТОП и
ТДП дают возможность сравнивать время реализации параллельных ветвей
алгоритмов. С помощью коэффициента K СМ можно оценить возможности
коммуникационной сети систем с различной архитектурой.
Проведенный анализ показал необходимость повышения эффективности обмена в централизованных системах, а также в децентрализованных
системах с «оконным» доступом к памяти других процессоров.
Кроме того, в рассмотренных архитектурах МВС не предусмотрены
средства для ускорения процедур передачи данных трансляционного типа,
хотя такой тип передач, в частности, для систем управления является весьма распространенным.
42.
ГЛАВА 6АРХИТЕКТУРА ПОТОКОВЫХ ВЫЧИСЛИТЕЛЬНЫХ
СИСТЕМ
6.1. Модель вычислений под управлением
потока данных
Время преобразования информации в параллельных системах определяется не только архитектурными особенностями систем, в частности, производительностью и количеством процессоров, но и эффективностью планирования вычислений. Задача планирования параллельных процессов
включает разбиение всего объема работ на отдельные задания, распределение заданий между узлами системы, синхронизацию обмена данными между параллельными ветвями вычислительного процесса [57]. Для систем
реального времени основным критерием эффективности средств планирования является минимизация длительности преобразования информации.
Для этого при разработке указанных средств особое внимание уделяется
сокращению запаздывания, которое вносит в процесс вычислений операционная система [58, 59].
Существуют универсальные, архитектурно ориентированные и специализированные программные средства, предназначенные для статического
или динамического планирования вычислительных процессов в параллельных системах [60 – 63].
Задачи статического планирования решаются до начала вычислений
[64,65]. Для создания и синхронизации параллельных процессов при статическом планировании могут быть использованы языки параллельного программирования (например, ADA, HPF, OCCAM, CSP, FORTRAN-HEP),
средств поддержки параллельного программирования (OpenMP, PVM,
MPI), низкоуровневые коммуникационные средства, предоставляемые операционной системой (socket, COM, CORBA). Данный подход возлагает решение задачи синхронизации и обмена данными между параллельными
участками программы на программиста. Эффективность статического планирования во многом определяется квалификацией программиста. С ростом сложности задач возрастает и трудоемкость их подготовки, вследствие чего увеличивается вероятность того, что при выявлении параллелизма будут допущены ошибки. Для конкретных систем существуют специализированные компиляторы, которые преобразуют линейную программу в параллельную. Эффективность таких средств, как правило, ограничивается рамками низкоуровневого параллелизма [66].
Другим подходом к распараллеливанию вычислений является динамическое планирование, при котором формирование, распределение заданий,
43.
96Архитектура вычислительных систем реального времени
а также синхронизация параллельных процессов осуществляется системой
на этапе решения задачи [57, 58, 67, 68]. По сравнению со статическим
планированием это дает возможность выполнять вычисления, не имея полной информации о состоянии процесса, что зачастую является весьма важным для систем реального времени. При динамическом планировании
необходимо учитывать много факторов, связанных с особенностями системы и характеристиками задач (количество и функциональные возможности
процессоров, трудоемкость и сложность выполнения работ и т.д). Поскольку задачи динамического планирования решаются средствами самой системы, то уменьшение непроизводительных расходов времени и ресурсов
является одной из важнейших проблем построения высокопроизводительных систем.
Для реализации параллельных вычислительных процессов, в том числе
обладающих неявным параллелизмом, были предложены модели вычислений под управлением потока данных (data flow). К первым в этой области
следует отнести работы [69, 70], которые оказали существенное влияние на
дальнейшие исследования потоковой модели вычислений [71 – 84].
Основными структурными компонентами систем, управляемых потоком данных, являются вычислительные модули и среда, которая формирует
команды для этих модулей. Для потоковых систем отсутствует понятие
программы как связанного списка команд, выполняемых в определенной
последовательности под управлением счетчика команд, что присуще классической модели вычислений. Определяющим в данном случае является не
порядок выполнения команд, а доступность данных для команды. Для машин такого класса программа представляется списком управляющих слов
(акторов) и данных, которые через устройства ввода поступают в среду
формирования команд. Из этих компонентов на аппаратурном или микропрограммном уровне формируются команды. Готовые команды передаются
в вычислительные модули, которые работают независимо друг от друга
(асинхронно). При наличии свободного вычислителя команда в идеальном
случае немедленно выполняется, генерируя выходные данные, которые, в
свою очередь, могут активизировать следующую команду. Окончательные
результаты передаются в устройства вывода данных. При наличии нескольких вычислителей процесс автоматически распараллеливается на
аппаратном или микропрограммном уровне (без участия операционной
системы).
Список указанных слов составляется на основании графа вычислительного процесса. Вершинам графа соответствуют функциональные операторы (акторы), а дугам – данные. При этом граф строится без учета числа
вычислительных модулей в системе.
В обобщенном виде актор может быть представлен множеством
L = {K, F, I, P},
44.
Глава 6. Архитектура потоковых вычислительных систем97
где К – тип слова (актор или данные); F – функция действия актора (код
операции); I – множество имен акторов (собственное и для рассылки результата); Р – множество признаков операндов.
Данные (операнды), в свою очередь, представляются множеством
D = {K, N, I, P},
где N – значение операнда.
Элементы указанных множеств представляются в виде битов, полей,
слов. Система реализует определенное множество акторов, среди которых
имеются акторы ветвления процессов, преобразования информации, размножения данных, вывода результатов и т.д.
Для выполнения i-й команды (активизации i-го актора) необходимо
выполнение условия, которое можно записать в виде
Ci = CiD & CiR ,
CiD
(6.1)
CiR
где
– условие готовности данных;
– условие готовности ресурсов,
необходимых для выполнения i–й команды.
Проверка условия готовности ресурсов является более простой задачей
и может быть выполнена соответствующим устройством управления. Число акторов может значительно превосходить число вычислительных модулей. В связи с этим проверка условия готовности данных технически решается более сложно, чем проверка готовности ресурсов. Условие готовности
данных можно записать как
n 1
CiD
=
&c
j 1
i
j
,
где cij – признаки наличия актора и всех n операндов для i-й команды (оператора).
При наличии необходимого числа операндов актор активизируется. Из
элементов актора и данных формируется команда (командный пакет). При
выполнении условия (6.1) команда поступает в вычислительный модуль и
начинает выполняется. Данные между вычислительными модулями и средой формирования команд передаются через коммуникационную среду в
определенном формате и с соблюдением определенного протокола.
Рассмотрим возможную структуру слов акторов и данных [85] на примере вычисления функции
Z
N 1N 2 N 3 N 4
,
N 5N 6 N 7 N 8
где все операнды положительные, причем, N1, N2, N3 и N5 имеют тип real, а
остальные – integer.
Будем считать, что вычислительные модули реализуют только двухоперандные команды. Для вычисления функции используются операции
45.
Архитектура вычислительных систем реального времени98
умножения (MUL), деления (DIV), сложения (ADD) и извлечения квадратного корня (SQRT). Вывод результата осуществляется командой вывода
(OUT).
Граф вычислений представлен на рис. 6.1, где I1,...,I9 – имена акторов.
Операнды N9 и N10 одноместных операций являются фиктивными и предназначены только для активизации соответствующих акторов.
N1
N2 N3
MUL
I1
N4
MUL
N5
I2
N6 N7
MUL
I3
N8
MUL
I5
N9
N 10
I4
I6
ADD
ADD
DIV
I7
SQRT
I8
OUT
I9
Z
Рис. 6.1. Граф алгоритма вычисления функции
В соответствии с графом на рис. 6.1 составлены списки акторов и
данных (табл. 6.1 и 6.2). Для акторов тип слова принят 1, а для данных – 0.
Номер операнда имеет значение, когда для операции не выполняется свойство коммутативности. В данном случае это операция деления (делимое
имеет номер 0, а делитель – 1). Аналогично определяются действительные
и фиктивные аргументы для одноместных операций извлечения корня и
вывода.
В системе одновременно могут выполняться несколько алгоритмов.
Момент инициализации выполнения каждого алгоритма осуществляется
независимо друг от друга. Никакой настройки конфигурации связей на выполнение алгоритма определенного вида производить не требуется. Кроме
46.
Глава 6. Архитектура потоковых вычислительных систем99
того, данные для каждого алгоритма подготавливаются независимо как от
других алгоритмов, так и от числа вычислительных устройств в системе.
Не допускается только повторение имен акторов. Увеличение количества
вычислительных модулей может автоматически привести к уменьшению
времени вычислений.
Табл. 6.1.
Список акторов
K
Тип
слова
1
1
1
1
1
1
1
1
1
I
Имя актора, имя
следующего актора
I 1, I 5
I 2, I 5
I 3, I 6
I 4, I 6
I 5, I 7
I 6, I 7
I 7, I 8
I 8, I 9
I9
P
Тип данных,
номер операнда
Real, –
Real, –
Real, –
Integer, –
Real, 0
Real, 1
Real, 0
Real, 0
Real
F
Операция
MUL
MUL
MUL
MUL
ADD
ADD
DIV
SQRT
OUT
Табл. 6.2.
Список данных
K
Тип
слова
0
0
0
0
0
0
0
0
0
0
I
Имя актора
I1
I1
I2
I2
I3
I3
I4
I4
I8
I9
P
Тип данных,
номер операнда
Real, –
Real, –
Real, –
Integer, –
Real, –
Integer, –
Integer, –
Integer, –
–, 1
–, 1
N
Операнд
N1
N2
N3
N4
N5
N6
N7
N8
N9
N 10
47.
100Архитектура вычислительных систем реального времени
6.2. Архитектура потоковых процессоров
Архитектура систем, управляемых потоком данных (потоковых процессоров), в основном отличается способами организации среды формирования команд [77, 79, 80, 84]. Среда формирования команд может быть общей для всех вычислительных модулей или распределенной между ними.
Активизация акторов может производиться с использованием и без использования ассоциативной памяти. Наиболее наглядно указанные структурные
особенности проявляются в базовых системах, которые были реализованных на практике в числе первых и оказали существенное влияние на развитие потоковых систем.
На рис. 6.2 показана организация потокового процессора, разработанного в Массачусетском технологическом институте [71, 83, 84]. Готовность команды в этой системе определяется на основании локального критерия в специализированных ячейках, которые образуют своеобразную
память для хранения потоковой программы (блок командных ячеек).
Вычислительные
модули
Логические
модули
Функциональное
устройство
Управляющая
сеть
Командная ячейка
Распределительная сеть
Блок командных
ячеек
Селекторная сеть
Командная ячейка
Рис. 6.2. Структура потокового процессора с командными ячейками
В процессоре функциональное устройство содержит вычислительные
и управляющие модули. В качестве вычислительных модулей могут применяться специализированные или универсальные процессоры. Результатом работы вычислительных модулей являются данные, а логические мо-
48.
Глава 6. Архитектура потоковых вычислительных систем101
дули формируют логические переменные (TRUE и FALSE), которые через
управляющую сеть изменяют ход вычислительного процесса.
Потоковая программа в виде множества акторов записывается в блок
командных ячеек (цепи записи условно не показаны). Командная ячейка
состоит из трех регистров и схемы управления. В одном регистре находится актор, а в два других регистра через распределительную сеть поступают
данные. Факт поступления данных фиксируется флажками. При наличии
актора и поступлении двух операндов формируется команда. В зависимости от кода операции команда поступает через селекторную сеть в соответствующий модуль функционального устройства. Селекторная сеть позволяет одновременно передавать несколько команд в различные модули
функционального устройства.
После выполнения команды результат отсылается через распределительную сеть в соответствующую командную ячейку. Результат одной команды может служить операндом для одной или нескольких последующих
команд потоковой программы. Каждая команда комплектуется независимо
от других после выполнения всех команд, генерирующих для нее операнды.
Число модулей в функциональном устройстве значительно меньше количества командных ячеек. Следовательно, готовых команд может быть
больше, чем свободных модулей. В связи с этим в процессоре предусмотрены средства для формирования очередей готовых команд.
Интенсивность потоков информации через распределительную и селекторную сеть в идеальном случае должна обеспечивать максимальную
пропускную способностью функционального устройства. Чрезмерное
ускорение передачи информации приводит только к увеличению очередей.
В связи с этим в сетях используется передача данных последовательным
кодом. На выходах селекторной сети последовательный код преобразуется
в параллельный. В этом виде он поступает в функциональное устройство. В
распределительной сети поступающий на входы параллельный код преобразуется в последовательный. Таким способом минимизируется количество
линий связи в сетях.
К недостаткам рассмотренной системы следует отнести сложность ее
реализации. Практически все устройства, кроме вычислительных модулей,
являются специфическими и, практически, не находят применения в системах с классической архитектурой. Сложность коммуникационной сети не
позволяет свободно варьировать числом модулей в функциональном
устройстве. При необходимости использования специализированных вычислителей с разными функциональными возможностями еще более возрастет сложность селекторной сети, поскольку понадобиться обеспечить
коммутацию выходов командных ячеек не с двумя, а с большим числом
типов модулей.
49.
102Архитектура вычислительных систем реального времени
Примером использования ассоциативной памяти для активизации акторов является потоковый процессор, разработанный в Манчестерском
университете [72, 74, 78]. Процессор состоит из устройств, связанных однонаправленными магистралями передачи данных с высокой пропускной
способностью, и базовой машины, обеспечивающей операции вводавывода (рис. 6.3). Каждое из устройств имеет собственное управление и
синхронизацию. Передача данных между устройствами выполняется в
асинхронном режиме. В памяти команд хранятся акторы, определяющие
операцию и имена других акторов, для которых предназначен результат
выполнения операции.
Согласующее
устройство
Буферная
память
Память
команд
Вычислительные
модули
Коммутатор
Базовая
машина
Рис. 6.3. Потоковый процессор с ассоциативным поиском данных
Согласующее устройство предназначено для подбора пар операндов,
необходимых для формирования команды. Для этого используется ассоциативный механизм поиска. Наиболее эффективно механизм реализуется на
базе ассоциативного запоминающего устройства. Информация в согласующее устройство поступает из буферной памяти, в которой создается очередь из промежуточных результатов и исходных данных. Промежуточные
результаты формируются в вычислительных модулях, а исходные данные
пересылаются из базовой машины.
Необходимое переключение потоков данных обеспечивает коммутатор. Ширина шины передачи информации по кольцу составляет 96 разрядов, что превышает ширину шины данных базовой машины. Для преобразования длины слов используются входные и выходные буферы.
Обрабатывающая подсистема состоит из одинаковых вычислительных
модулей, построенных на базе микропроцессорного комплекта Am2900.
Каждый модуль предназначен для обработки 24-разрядных целых чисел и
32-разрядных чисел с плавающей запятой.
50.
Глава 6. Архитектура потоковых вычислительных систем103
Основным недостатком рассмотренного способа формирования команд является необходимость использования ассоциативной памяти.
Сложность реализации ассоциативного запоминающего устройства большой емкости зачастую приводит к необходимости ее эмуляции, например,
с применением технологии хеширования данных. Такой подход повышает
функциональные возможности системы, но снижает ее производительность, поскольку указанный способ эмуляции требует больших временных
затрат, чем реализация алгоритмов активизации акторов с использованием
ассоциативных запоминающих устройств.
Примером использования распределенной среды формирования команд может служить система, разработанная фирмой Texas Instruments [76,
84].
ПЭ
И
ПЭ
И
ПЭ
И
И
Базовая
машина
Рис. 6.4. Система фирмы Texas Instruments: ПЭ – процессорный элемент;
И – интерфейс
Система состоит из процессорных элементов и базовой машины, объединенных в кольцо (рис. 6.4). Базовая машина выполняет функции управления и ввода-вывода.
Внутренняя организация процессорного элемента изображена на рис.
6.5. Каждый процессорный элемент содержит вычислительный модуль,
контроллер, память (32К слов по 32 разряда) и очередь готовых команд,
функционирующую по принципу FIFO.
Потоковая программа в виде множества акторов и данных вводится в
кольцевую магистраль с помощью базовой машины. При этом акторы распределяются между ПЭ. В процессе работы контроллер принимает данные
либо из коммуникационной среды, либо из своего вычислительного модуля. Поступающие данные проверяются на соответствие именам акторов,
которые находятся в данном ПЭ. В результате проверки данные могут быть
возвращены в кольцевую магистраль или записаны в нужное место памяти.
Когда для актора получены все операнды, командный пакет пересылается в
очередь готовых команд. Вычислительный модуль выполняет команды в
порядке их записи в очередь.
51.
104Архитектура вычислительных систем реального времени
Модульная организация архитектуры обеспечивает простоту наращивания ПЭ.
К коммуникационной среде
Результаты
Вычислительный
модуль
Контроллер
Память
Очередь готовых
команд
Рис. 6.5. Организация процессорного элемента
К основным недостаткам системы следует отнести непроизводительные затраты времени при формировании команд, связанные с возможностью многоэтапной пересылки слов по кольцевой магистрали и поочередной проверкой соответствия имен акторов и данных в разных ПЭ. Это, в
свою очередь, увеличивает длительность преобразования информации, что
может оказаться недопустимым при управлении быстрыми процессами в
реальном времени. Кроме того, дублирование аппаратуры активизации акторов в каждом ПЭ увеличивает суммарный объем оборудования системы.
Реализованные на практике потоковые системы в большинстве случаев
являются специализированными или проблемно ориентированными [73, 77,
84]. Недостаточное внимание промышленности к универсальным системам,
управляемым потоком данных, объясняется рядом причин. Прежде всего,
это необходимость создания огромного объема нового программного обеспечения. Учитывая, что спрос на системы с классической архитектурой не
снижается, огромное число фирм разрабатывает и поставляет для этих систем программное обеспечение, представляется весьма сомнительным бурное развитие универсальных потоковых систем со специфическим программным обеспечением. Заметим, что на это также влияет, хотя и в меньшей степени, необходимость изменения стратегии проектирования и производства аппаратных средств.
Однако, не обязательно рассматривать потоковую модель вычислений
как альтернативу классической модели. Потоковая модель вычислений может быть использована для улучшения определенных характеристик параллельных систем, построенных на базе процессоров с классической архитектурой, то есть управляемых потоком команд (инструкций). При этом
в указанных системах могут применяться традиционные программные и
аппаратные средства.
52.
Глава 6. Архитектура потоковых вычислительных систем105
Ниже будет рассмотрено несколько вариантов комплексного использования классической и потоковой моделей вычислений. Особенность каждого варианта состоит в следующем.
1. В состав МВС вводится специализированный вычислитель, управляемый потоком данных. Вычислитель обеспечивает быструю реализацию
алгоритмов с "мелкозернистым" параллелизмом, которые неэффективно
выполнять в универсальных процессорах на программном уровне.
2. В состав МВС вводится специализированный потоковый вычислитель, который благодаря особому набору команд выполняет ряд функций
ядра операционной системы.
3. В состав МВС включается устройство автоматического распределения заданий между процессорами системы. Формирование заявок на выполнение заданий осуществляется под управлением дескрипторов данных.
Предполагается, что в МВС потоковый вычислитель используется
всеми процессорами в качестве общего аппаратного ресурса. Обмен информацией с другими процессорами осуществляется через стандартную
для системы коммуникационную среду под управлением стандартной операционной системы.
При таком подходе к организации архитектуры систем принцип организации вычислений в потоковом вычислителе может оставаться скрытым
для операционной системы. Этот принцип учитывается только на этапе
разработки потокового вычислителя. Интерфейс вычислителя можно построить таким образом, чтобы он выглядел со стороны других устройств
системы как стандартное устройство. Благодаря этому в параллельных системах можно использовать классические программные и аппаратные средства. Следовательно, устраняются препятствия использования потоковой
модели вычислений для повышения эффективности параллельных систем.
Рассмотренные подходы к организации вычислений в потоковых систем приводят к весьма сложным техническим системам. В связи с этим
актуальной задачей является разработка потоковой модели вычислений,
обеспечивающей простоту технической реализации систем.
6.3. Потоковый процессор с адресным поиском
информации в среде формирования команд
Системы, управляемые потоком данных, могут быть эффективно использованы для реализации алгоритмов с "мелкозернистой" структурой,
которые характеризуются большой связностью графа. Распараллеливать
алгоритмы с указанными характеристиками между процессорами МВС на
уровне программных модулей нецелесообразно. Это сопряжено с потерями
времени за счет инерционности операционной системы и, кроме того, увеличения интенсивности обмена информацией между процессорами. На вычислители, работающие в составе МВС, целесообразно возлагать задачи
53.
106Архитектура вычислительных систем реального времени
интерполяции, преобразования координат, вычисления функциональных
зависимостей и т.д. Вычисления такого рода, как правило, базируются на
реализации двухместных алгебраических операций и одноместных функций. Как известно, на базе одно- и двухместных операций достаточно легко
сформировать алгоритмически полную и достаточно компактную систему
команд.
Для реализации "мелкозернистых" алгоритмов неэффективно применять системы с распределенной средой формирования команд из-за больших затрат времени на пересылку информации между модулями. Системы
с общей для всех вычислителей средой формирования команд содержат
более простые вычислительные модули и отличаются меньшими временными издержками при формировании команд. Основная сложность таких
систем обусловлена организацией среды формирования команд.
Уменьшение сложности и, следовательно, повышение надежности систем может быть достигнуто за счет использования в среде формирования
команд запоминающих устройств с произвольным доступом (RAM –
random access memory), которые широко применяются для организации
оперативной памяти компьютерных систем. В таких устройствах обращение к ячейкам памяти осуществляется по адресам. По сравнению с ассоциативными запоминающими устройствами они обладают более высоким
быстродействием и меньшей стоимостью при одинаковой емкости.
Ассоциативный поиск можно заменить адресным поиском, если именам акторов и операндов поставить в соответствие физические адреса оперативной памяти и осуществлять сортировку данных в соответствии с их
именами на входе среды формирования команд. Указанный механизм формирования команд рассмотрим на примере потокового процессора, разработанного в Киевском политехническом институте [86].
Предлагаемая структура показана на рис. 6.6. Вычислительные модули
выполняют одно- и двухместные операции. С целью обеспечения регулярности алгоритмов формирования команд и, следовательно, упрощения аппаратуры управления однооперандные команды обрабатываются так же,
как и двухоперандные. Для выполнения однооперандных команд в систему вводится второй фиктивный операнд.
В качестве устройств ввода и вывода может быть использована одна
базовая машина или несколько процессоров мультипроцессорной системы.
Буферная память реализует безадресный доступ к данным в соответствии с
алгоритмом FIFO ("первым пришел – первым вышел"). Входной и выходной арбитры образуют коммуникационную среду со схемами управления
процессами обмена данными между устройствами.
Среда формирования команд построена на базе памяти акторов и памяти данных. В качестве имен акторов и данных используются их физические адресами в памяти. При формировании команд в системе выполняют-
54.
Глава 6. Архитектура потоковых вычислительных систем107
ся только операции адресного чтения и записи. Благодаря этому отпадает
необходимость применения ассоциативной памяти.
Устройства
ввода
Входной арбитр
Буферная память данных
Данные
Адрес (имя)
Память
данных
Память
акторов
Буферная память команд
Выходной арбитр
Устройства
вывода
Вычислительные
модули
Рис. 6.6. Потоковый процессор с адресным поиском информации
При функционировании системы можно выделить три процесса:
ввод акторов и данных из устройств ввода и прием результатов из вычислительных модулей через входной арбитр в буферную память данных;
прием слов из буферной памяти данных, разделение каждого слова на
информационную и адресную часть, формирование команд и засылка
их в буферную память команд;
распределение команд из буферной памяти данных между вычислительными модулями и устройствами вывода данных.
Каждым процессом можно управлять независимо, что позволяет совмещать процессы во времени. Рассмотрим возможные алгоритмы их реализации.
При вводе информации вначале проверяется наличие свободного места в буфере данных, а затем производится запись (сигналы и аппаратура
управления на рис.6.6 условно не показаны). Описанный процесс повторя-
55.
108Архитектура вычислительных систем реального времени
ется циклически. В буферной памяти данных всегда резервируются ячейки
для результатов операций в вычислительных модулях. Если в буфере остается только необходимое число резервных ячеек, то прием информации из
устройств ввода блокируется. За счет этого исключается возможность возникновения тупиковой ситуации, когда вычислительный процесс не может
быть продолжен. Критическое число ячеек нетрудно рассчитать исходя из
числа результатов, которые могут быть получены при выполнении команд
в вычислительных модулях.
При формировании команды для вычислительных модулей из буфера
данных по адресу, роль которого исполняет имя актора, информация записывается в память данных или акторов (в зависимости от типа слова). Запись информации в ячейку памяти данных сопровождается установкой единицы в разряде признака наличия операнда (например, в старшем разряде
этой же ячейки). Если этот признак уже был установлен (это означает, что
для соответствующего актора в памяти данных уже имеется один операнд), готовая к выполнению команда записывается в буфер команд. Признак наличия операнда после этого сбрасывается, так как из памяти данных
операнд считан. Исключение составляют восстанавливаемые константы,
которые остаются в памяти до конца реализации заданного алгоритма. При
вводе актора признак наличия операнда всегда сбрасывается. Для формирования команды используются определенные поля актора и данных. Описанный процесс формирования команд повторяется циклически.
При распределении команд между вычислительными модулями и
устройствами вывода данных проверяется наличие информации в буфере
команд. Если готовые команды имеются, то анализируется код операции и
обеспечивается пересылка команды в заданное устройство вывода данных
или в один из свободных вычислительных модулей.
Для корректности вычислений необходимо обеспечить ряд требований:
актор должен быть введен в систему раньше, чем соответствующие ему
операнды:
в одной команде не может быть двух восстанавливаемых операндов;
восстанавливаемый операнд должен быть введен в систему после актора, но перед другим операндом.
Выполнение указанных требований, как правило, не вызывает особых
затруднений. Вполне естественно вначале ввести программу, а затем данные, которые обрабатываются этой программой.
Для организации вычислений необходима определенная форма представления информации (данных, акторов и команд). Возможные форматы
акторов и слов данных, которые могут обеспечить реализацию вычислений
в потоковом процессоре, иллюстрируются рис. 6.7 (сверху вниз показано
соответственно назначение, обозначение и разрядность полей).
56.
Глава 6. Архитектура потоковых вычислительных системТип
слова
ТС
1
Номер
актора
НА
m
Номер
операнда
НО
1
Признак
восстановления
ПВ
1
Код
операции
КОП
p
Номер
актора
НА
m
Номер
операнда
НО
1
Признак
восстановления
ПВ
1
Значение
операнда
ЗО
n
109
Номер следующего
актора
НСА
m
а)
Тип
слова
ТС
0
б)
Рис. 6.7. Форматы слов актора (а) и данных (б)
Разряд ТС позволяет устройству управления отличать акторы от данных. Для акторов ТС=1, а для данных ТС=0.
Для актора НА является его уникальным именем, которое определяет
размещение актора в памяти. Оно может исполнять роль адреса или признака.
Характер преобразования информации определяется полем КОП. Поле
НСА указывает, какому актору (оператору) предназначен результат операции. С помощью разрядов НО и ПВ уточняется соответственно номер входа оператора и возможность восстановления передаваемого данного на дуге следующего оператора. Восстанавливаемым данным соответствует
ПВ=1. Для коммутативных операций НО может иметь произвольное значение.
Для слов данных поле НА определяет актор, для которого предназначен операнд. Значение операнда и, возможно, его тип определяется полем
ЗО, а разряды НО и ПВ содержат дополнительную информацию об этом
операнде. Если предусмотрено выполнение операций с различными типами
данных, то целесобразно использовать самоопределяемые данные [40].
Когда условие активизации актора выполняется, в среде формирования команд из полей данных и актора составляется команда, которая передается для выполнения в вычислительный модуль.
Логика формирования команды поясняется рис. 6.8.
Значение результата определяется значениями исходных данных (полями ЗО) и полем КОП актора. Поля НО учитываются в операциях, для
которых не выполняется свойство коммутативности, например, в операциях вычитания и деления. В командах ветвления потоков, базирующихся на
операциях сравнении, порядок операндов так же строго определен.
57.
110Архитектура вычислительных систем реального времени
Актор
Данное 0
Данное 1
ТС=1
ТС=0
ТС=0
НА
НА
НА
НСА
НО=0
НО=1
НО
ПВ
ПВ
ПВ
ЗО
ЗО
КОП
НСА
НО
ПВ
КОП
НО
ТС=0
НА
НО
ПВ
ЗО
ЗО
НО
ЗО
Команда
Результат
Рис. 6.8. Схема формирования слов команды и результата
Непосредственного участия в преобразовании информации поля, обозначенные пунктиром, не принимают. Эти поля присоединяются к полученному результату, формируя стандартный формат данных.
Рассмотренный способ организации потоковой модели вычислений
требует использования памяти с адресным доступом, которая по сравнению
с ассоциативной памятью является менее сложной. При этом суммарный
объем памяти для хранения акторов и операндов уменьшается, так как в
оперативной памяти сохраняется только актор и один операнд (подробнее
этот вопрос рассмотрен в следующем разделе).
Кроме того, на активизацию акторов не требуется и больших затрат
времени, что присуще системам с полной эмуляцией ассоциативной памяти
(например, с применением технологии хеширования). Действительно, для
приема актора в память требуется выполнение только одного цикла записи.
При записи операнда выполняется один цикл чтения памяти данных для
проверки признака наличия операнда и один цикл для записи операнда.
Команда переписывается в буфер команд при поступлении второго операнда. Для формирования непосредственно команды выполняется цикл чтения
для проверки признака наличия одного операнда в памяти данных и опережающей выборки актора, а затем запись команды в буферную память. Таким образом, команда формируется за два цикла, причем, второй цикл безадресной записи в буфер выполняется быстрее первого. Заметим, что цикл
58.
Глава 6. Архитектура потоковых вычислительных систем111
ассоциативного обращения обычно превышает цикл адресного обращения
к памяти.
Наличие очереди готовых команд в потоковых системах дает дополнительные возможности для вычислительных модулей. Все команды в буферной памяти команд независимы друг от друга (в потоковых системах
очередь не может быть отменена какой-либо командой). Поэтому вычислительные модули могут осуществлять опережающую выборку команд из
очереди на любую глубину и выполнять их в конвейерном режиме.
Для процессора разработаны средства повышения отказоустойчивости
[87], предусматривающие повторное выполнение команд в случае отказа
вычислительных модулей.
Заметим также, что все блоки потокового процессора построены с использованием стандартной для компьютерных систем аппаратуры. Все это
создает предпосылки для повышения быстродействия и уменьшения стоимости потоковых систем.
Более подробная сравнительная оценка сложности систем с разной архитектурой с учетом особенностей синхронизации процессов приведена в
разделе 7.6.
59.
ЛИТЕРАТУРА1. Байков В.Д., Вашкевич С.Н. Решение траекторных задач в микропроцессорных системах ЧПУ.–Л.: Машиностроение, 1986.– 105 с.
2. Журавлев Ю.П. Системное проектирование управляющих ЦВМ. –
М: Сов.радио, 1974. – 368 с.
3. Мазилкин И.Г., Петров Г.А., Пулкис Г. О реализации устройств числового программного управления на многопроцессорных системах// Автоматика и вычислительная техника. – 1981. – N5. – С. 33–36.
4. Сосонкин В.Л. Микропроцессорные системы числового программного управления.– М.: Машиностроение, 1985.– 288 с.
5. Фритч В. Применение микропроцессоров в системах управления. –
М.: Мир, 1984. – 464 с.
6. Ратмиров В.А. Управление станками гибких производственных систем. – М.: Машиностроение, 1987. – 272 с.
7. Ратмиров В.А. Основы программного управления станками.– М.:
Машиностроение, 1978. – 240 с.
8. Сосонкин В.Л. Задачи числового программного управления и их архитектурная реализация// Станки и инструмент. – 1988. – №10. – С. 39 – 40.
9. Сосонкин В.Л., Мартинов Г.М. Принципы построения систем ЧПУ с
открытой архитектурой// Приборы и системы управления. – 1996. – №8. –
С. 18 – 21.
10. Сосонкин В. Л., Мартинов Г. М. Современное представление об
архитектуре систем ЧПУ типа PCNC. <http://www.osp.ru>.
11. Бюшгенс Г.С., Студнев Р.В. Аэродинамика самолета: Динамика
продольного и бокового движения. – М: Машиностроение, 1979.– 352 с.
12. Микропроцессорные средства производственных систем//
В.Н.Алексеев, А.М.Коновалов, В.Г.Колосов и др./ Под общ. ред.
В.Г.Колосова. – Л.: Машиностроение, 1987. – 20 с.
13. SIFT: Design and analysis of a fault-tolerant computer for aircraft
control/ J.H.Wensley, L.Lamport, J.Goldberg, M.W.Green, K.N.Levitt,
P.M.Melliar-Smith, R.E.Shostak, C.B.Weinstock// Proc. of the IEEE. – 1978. –
Vol. 66, N 10. – P. 1240 – 1255.
14. Танкелевич Р.Л. Моделирующие микропроцессорные системы. –
М.: Энергия, 1979. – 120 с.
15. Валях Е. Последовательно-параллельные вычисления. – М.: Мир,
1985. – 456 с.
16. Молчанов И.Н. Введение в алгоритмы параллельных вычислений.
– Киев: Наукова думка, 1990. – 128 с.
17. Pradhan D.K. Dynamically restructurable faulttolerant processor network architectures// IEEE Trans. Comput. – 1985. – Vol. 34, N 5. – P. 434 –
447.
60.
Литература167
18. Разработка вычислительных средств на базе микропроцессоров для
систем числового программного управления: Отчет по НИР (научн. рук.
В.И.Жабин), Киевский политехнический институт/ № ГР 01830078443, инв.
№ 02890031296. – Киев, 1989. – 253 с.
19. Дмитриев Ю.К., Хорошевский В.Г. Вычислительные системы из
мини-ЭВМ. – М.: Радио и связь, 1982. – 304 с.
20. Миренков Н.Н. Параллельное программирование для многомодульных вычислительных систем. – М.: Радио и связь, 1989. – 320 с.
21. Хорошевский В.Г. Инженерный анализ функционирования вычислительных машин и систем. – М.: Радио и связь, 1987. – 256 с.
22. Flynn M. Some Computer Organisations and Their Effectiveness// IEEE
Trans. Computers. – 1972. – Vol. 21, N 9. – P. 948 – 960.
23. Вашенчук И.М., Черкасский Н.В. Алгоритмические операционные
устройства и суперЭВМ. – Киев: Техніка, 1990. – 197 с.
24. Головкин Б.А. Параллельные вычислительные системы. – М:
Наука, 1980. – 519 с.
25. Мультипроцессорные системы и параллельные вычисления./ Под.
ред. Ф.Г.Энслоу. – М.: Мир, 1976. – 383 с.
26. Прангишвили И.В., Виленкин С.Я., Медведев И. Л. Параллельные
вычислительные системы с общим управлением. – М.: Энергоатомиздат,
1983. – 312 с.
27. Самофалов К.Г., Луцкий Г.М. Структуры и организация ЭВМ и
систем. – Киев: Вища школа, 1978. – 391 с.
28. Корнеев В.В. Параллельные вычислительные системы. – М.: “Нолидж”, 1999. – 320 с.
29. Информационно-аналитический центр по параллельным вычислениям. <http://parallel.ru>.
30. Top 500. <http://www.top500.org>.
31. Миренков Н.Н. Параллельное программирование для многомодульных вычислительных систем. – М.: Радио и связь, 1989. – 320 с.
32. OpenMP Application Program Interface (API). <http://www.openmp.
org>.
33. Amdahl G. Validity of the single-processor approach to achieving largescale computing capabilities // AFIPS Conf. – 1967. – Vol. 30. – P. 483 – 485.
34. Лощилов И.Н. Перспективы роста производительности ЭВМ // Зарубежная радиоэлектроника. – 1978. – №5. – С. 3 – 24.
35. Johnson E. E. Completing an MIMD multiprocessor taxonomy// Computer Architecture News. – 1988. – Vol. 16, N 2. – P. 44-48.
36. Feng T. Some characteristics of assotiative parallel processing// Proc.
Sagamore Computing Conf. – 1972. – P. 5 – 16.
37. Handler W. The impact classification schemes on computer architecture// Proc. Conf. on Parallel Processing. – 1977. – P. 7 – 15.
61.
168Архитектура вычислительных систем реального времени
38. Shore J.E. Second thoughts on parallel processing // Comput. Elect.
Eng. – 1973. – N 1. – P. 95 – 109.
39. Органик Э. Организация системы Интел 432: Пер. с англ. – М.:
Мир, 1987. – 446 с.
40. Майерс Г. Архитектура современных ЭВМ: В 2-кн. Кн. 1. Пер. с
англ. – М.: Мир, 1985. – 364 с.
41. Skillicorn D. A Taxonomy for Computer Architectures// Computer. –
1988. – Vol. 21, N 11. – P. 46 – 57.
42. Dasgupta S. A hierarchical taxonomic system for computer// Computer.
– 1990. – Vol. 23, N 3. – P. 64 – 74.
43. Хокни Р., Джессхоуп К. Параллельные ЭВМ. Архитектура, программирование и алгоритмы: Пер. с англ. – М.: Радио и связь, 1986. – 392 с.
44. Conte G., Del Corco D. Multimicroprocessors systems for real-time applications. – D. Reidel Publ. Co, 1985. – 180 p.
45. Жабин В.И. Графическое описание архитектуры вычислительных
систем// Вiсник Нацiонального технiчного унiверситету України “Київський полiтехнiчний iнститут”. Iнформатика, управлiння та обчислювальна
технiка. – 2001. – № 36. – С. 80 – 88.
46. Головкин Б.А. Параллельные вычислительные системы. – М:
Наука, 1980. – 519 с.
47. Основы теории вычислительных систем/ Под ред. С.А.Майорова. –
М.: "Высш. школа", 1978. – 408 с.
48. Устройство для сопряжения процессоров с общей шиной мультипроцессорной системы: А. с. №1571606 СССР, МКИ G 06 F 15/16 /
В.И.Жабин, Г.В.Гончаренко, В.В.Макаров, В.И.Савченко, В.В.Ткаченко
(СССР). – №4473002/24 – 24; заявлено 11.08.88; опубл. 15.06.90. Бюл. №22.
– 9 с.
49. Устройство обработки данных для многопроцессорной системы: А.
с. №1683039 СССР, МКИ G 06 F 15/76, 15/16 / В.В.Васильев,
Г.В.Гончаренко, В.И.Жабин, В.В.Макаров, В.И.Савченко, В.В.Ткаченко
(СССР). – №4653165/24; заявлено 24.11.88; опубл. 07.10.91. Бюл. №37. –
3 с.
50. Дек. пат. №38850 України, МКВ G 06 F 15/76, 15/16. Пристрій для
обробки даних багатопроцесорної системи/ В.І.Жабін, Р.Л.Антонов (Україна). – №2000116175: заявлено 01.11.2000; опубл. 15.05.2001. Бюл. №4. –
14 с.
51. Жабин В.И., Антонов Р.Л. Организация обмена информацией в
многопроцессорных системах с общей шиной// Вiсник Нацiонального технiчного унiверситету України. “Київський полiтехнiчний iнститут”. Iнформатика, управлiння та обчислювальна технiка. – 2000. – № 33. – С. 70 – 83.
52. Hockney R. Parallel computers: Architecture and performance// Proc. of
Int. Conf. Parallel Computing'85. – 1986. – P. 33 – 69.
53. Каган Б.М., Сташин В.В. Основы проектирования микропроцессорных устройств автоматики. – М.: Энергоатомиздат. – 1987. – 304 с.
62.
Литература169
54. Жабин В.И. Организация доступа к общей памяти в многопроцессорных системах// Вiсник Нацiонального технiчного унiверситету України
“Київський полiтехнiчний iнститут”. Iнформатика, управлiння та обчислювальна технiка. – 2002. – № 37. – С. 145 – 155.
55. Многопроцессорная система: А. с. №1798797 СССР, МКИ G 06 F
15/16 / В.И.Жабин, Г.В.Гончаренко, С.А.Гаврилов, В.Н.Дорожкин,
В.И.Савченко, В.Е.Ишутин, В.В.Макаров, В.В.Ткаченко (СССР). –
№4827609/24; заявлено 21.05.90; опубл. 28.02.93. Бюл. №8. – 4 с.
56. Жабін В.І. Реалізація динамічних пріоритетів у мультипроцесорних
системах з розподіленими контролерами переривань// Наукові вісті НТУУ
"КПІ". – 2003. – №1. – С. 50 – 54.
57. Поспелов Д.А. Введение в теорию вычислительных систем. – М.,
Сов. радио, 1972. – 280 с.
58. Chang Y.C., Shin K.G., Optimal load sharing in distributed real-time
systems// Journal of parallel and distributed computing. – 1993. –N19. – P. 38 –
50.
59. Baker T.P. Stack based scheduling of real-time processes// Journal on
real-time systems. – 1991. – Vol. 3, N 1. – Р. 67 – 99.
60. Casavant Thomas L., Shim K.G. A taxonomy of scheduling in generalpurpose distributed computing systems// IEEE Transactions on Software Engineering. – 1988/ – Vol. 14, N 2. – P. 141 – 154.
61. Симоненко В.П. Организация вычислительных процессов в ЭВМ,
комплексах, сетях и системах. – Киев: "Век +", 1997. – 304 с.
62. Liu Jie, Saletore Vikram A., and Lewis Ted G., Safe self-scheduling: A
parallel loop scheduling scheme for shared-memory multiprocessors// International Journal of Parallel Programming. – 1994. – Vol. 22, N 6. – P. 589 – 615.
63. Blazevicz J., Drozdowski M., and J. Weglarz, Scheduling multiprocessor tasks to minimize schedule length// IEEE Trans. Computer. – 1986. – Vol.
35. – P. 389 – 393.
64. Гери М.Р., Джонсон Д.С. Вычислительные машины и труднорешаемые задачи. — М.: Мир, 1982. – 416 с.
65. Eager D.L., Lazowska E.D., Zahorjan J., Adaptive load sharing in homogeneous distributed systems// IEEE Trans. on Software Engineering. – 1986.
– Vol. 12. – P. 662 – 675.
66. Roy L.J. Code generarations, evaluations and optimizations in multithreaded executions// Technical Report CS-yy-nnn, Colorado State University. –
1994. – N4. – P. 32 – 39.
67. Homayoun N., Ramanathan P., Dynamic priority scheduling of periodic
and aperiodic tasks in hard real-time systems// Journal on Real-Time Systems. –
1994. – Vol. 6, N1. – P. 207 – 232.
68. Elsadek A.A., Wells B.E. Heuristic model for task allocation in a heterogeneous distributed system// Pric. of PDPTA'96. – 1996. – Vol. 2. – P. – 659 –
671.
63.
170Архитектура вычислительных систем реального времени
69. Adams D.A. A computation model with data flow sequencing// Tech.
Rep. CS117, Comput. Sci.Dep., Stanford Univ., Stanford, CA. – 1968. – Dec.,
N 12.
70. Rodriguez J.E. A graph model for parallel computation// TR.ESL-R398, MAC-TR-64, Lab for Computer Science, MIT. – 1969. – Sep., N9.
71. Dennis J. B., Missunas D. P. A preliminary architecture for basic data
flow processor// Proc. 2nd Annual Symp. Comput. Stockholm, May 1975. N. Y.
IEEE. – 1975. – P. 126 – 132.
72. Silva J.G.D., Wood J.V. Design of processing subsystems for Manchester data flow computer // IEEE Proc. N.Y. – 1981. – Vol. 128, N 5. – P. 218 –
224.
73. Hogenauer E.B., Newbold R.F. Inn Y.T. DDSP – a data flow computer
for signal processing/ Proc. Int. Conf. Parall. Process. Ohio, August 1982. N.Y.//
IEEE. – 1982. – P. 126 – 133.
74. Watson R., Guard J. A practical data flow computer// Computer. – 1982.
– Vol. 15, N 2.– P. 51 – 57.
75. Arvind, Gostelow K.P. The U-interpreter // IEEE Computer. – 1982. –
Vol. 15, N 2. – P. 42 – 48.
76. Johnson D. Data flow machines thereaten the program counter// Electronic Design. – 1980. – N 22. – P. 255 – 258.
77. Gaudiot J.–L. Data-driven multicomputers in digital signal processing//
Proc. of the IEEE. – 1987. – Vol. 75, N 9. – P. 1220 – 1234.
78. Dipak G., Laxmi N.B. Performance evaluation of a dataflow architecture // IEEE Trans. Comput. – 1990. – Vol. 39, N 5. – P. 615 – 627.
79. СуперЭВМ. Аппаратная и программная реализация. Сборник статей./ Под ред. С. Фернбаха. – М.: Радио и связь, 1991. – 319 с.
80. Lee B., Hurson A.R., Dataflow architectures and multithreading// IEEE
Comput. – 1994. – N 8. – P. 27 – 39.
81. Guernic P. Le, Benveniste A., Bournai P., Gautier T. SIGNAL—A data
flow-oriented language for signal processing// IEEE Trans. Acoust., Speech,
Signal Processing. – 1986. –Vol. 34, N 4. – P. 362 – 374.
82. Kavi K.M., Arul J., Giorgi R. Execution and cache performance of the
scheduled dataflow architecture// Journal of Universal Computer Science, Special Issue on Multithreaded and Chip Multiprocessors. –2000. – N 10. – P. 948 –
967.
83. Майерс Г. Архитектура современных ЭВМ: Кн. 2 – Пер с англ. –
М.: Мир, 1985. – 312 с.
84. Функционально ориентированные процессоры/ Водяхо А.Н., Смолов В.Б., Плюснин В.У., Пузанков Д.В/ Под ред. В.Б.Смолова. – Л.: Машиностроение. Ленингр. отд-ние, 1988. – 224 с.
85. Жабин В.И. Организация вычислений в системах, управляемых потоком данных// Вiсник Нацiонального технiчного унiверситету України
“Київський полiтехнiчний iнститут”. Iнформатика, управлiння та обчислювальна технiка. – 1998. – № 31. – С. 44 – 51.
64.
Литература171
86. Вычислительная система: А. с. № 1709331 СССР, МКИ G06 F
15/16; 15/80 / В.И.Жабин, Г.В.Гончаренко, В.В.Ткаченко (СССР) – №
4797732/24; заявлено 28.02.90; опубл. 30.01.92, Бюл. № 4. – 17 с.
87. Пат. №2030785 РФ, МКИ G06 F 15/16. Вычислительное устройство/ В.И.Жабин, Г.В.Гончаренко, В.В.Макаров, В.В.Ткаченко (Украина) –
4867678/24; заявлено 21.09.90; опубл. 10.03.95, Бюл. № 7. – 14 с.
88. Жабин В.И. Синхронизация циклов в потоковых вычислительных
системах с коротким командным словом// Электронное моделирование. –
2003. – Т.25, №3. – С. 35 – 49.
89. Горшков В.Н. Надежность оперативных запоминающих устройств
ЭВМ. –Л.: Энергоатомиздат. Ленигр. отд-ние, 1987. – 168 с.
90. Гуревич Л.К., Дибнер В.Л. Методы интерполяции в системах ЧПУ
металлорежущим оборудованием. – М.: Машиностроение, 1987. – 48 с.
91. Кошкин В.Л. Аппаратные системы числового программного
управления. – М.: Машиностроение, 1989. – 248 с.
92. Многопроцессорная система: А. с. №1709330 СССР, МКИ G 06 F
15/16 / В.И.Жабин, В.И.Савченко, В.Е.Ишутин, Г.В.Гончаренко,
В.В.Ткаченко (СССР). – №4784455/24; заявлено 18.01.90; опубл. 30.01.92.
Бюл. №4. – 5 с.
93. Жабин В.И., Антонов Р.Л. Применение потоковых вычислителей в
системах реального времени// Проблемы создания новых машин и технологий. Научные труды Кременчугского государственного политехнического
института. – 2000. – Выпуск 1/2000 (8). – С. 368 – 375.
94. Жабин В.И., Антонов Р.Л. Аппаратная реализация некоторых
функций ядра операционных систем// Вiсник Нацiонального технiчного
унiверситету України “Київський полiтехнiчний iнститут”.Iнформатика,
управлiння та обчислювальна технiка. – 2001. – № 35. – С. 84 – 96.
95. Жабин В.И. Метод распараллеливания процессов в вычислительных системах// Вiсник Нацiонального технiчного унiверситету України
“Київський полiтехнiчний iнститут”. Iнформатика, управлiння та обчислювальна технiка. – 2000. – № 34. – С. 136 – 142.
96. Жабин В.И. Реализация вычислений под управлением потока дескрипторов данных в мультипроцессорных системах// Электронное моделирование. – 2003. – Т.25, №1. – С. 35 – 47.
97. Погребинский С.Б., Стрельников В.П. Проектирование и надежность моногопроцессорных ЭВМ. – М.: Радио и связь, 1988. – 168 с.
98. Диллон Б.,Сингх И. Инженерные методы обеспечения надежности
систем. – М: Мир, 1983. – 318 с.
99. Коваленко А.Е., Гула В.В. Отказоустойчивые микропроцессорные
системы. – К.: Технiка, 1986. – 150 с.
102. Лонгботтом Р. Надежность вычислительных систем. – М.: Энергоатомиздат, 1985. – 288 с.
65.
172Архитектура вычислительных систем реального времени
101. Avizienis A. Fault-tolerance: The survival attiribute of digital system//
Proc. of the IEEE. – 1978. –Vol. 66, N 10. – P. 1109 – 1125.
102. Hopkins A.L. Jr, Smith T.V. III, Lala J.H. FTMP – highly reliable
fault-tolerant multiprocessor for aircraft// Proc. of the IEEE. – 1978. –Vol. 66, N
10. – P. 1221 – 1239.
103. Пакулов Н.И., Уханов В.Ф., Чернышев П.Н. Мажоритарный
принцип построния надежных узлов и устройств ЦВМ. –М.: Сов. радио,
1974. – 184 с.
104. Pluribus – An operational fault-tolerant multiprocessor/ Katsuki D.,
Elsam E.S., Mann W.F., Roberts E.S., Robinson J.G., Skovronsky F.S., Wolf
E.W.// Proc. of the IEEE. – 1978. –Vol. 66, N 10. – P. 1146 – 1159.
105. Вычислительная структура: А.с. №744589 СССР, МКИ G06 F
15/16,11/00 / И.Н.Алексеева, М.А.Лапшин и др. – №2583456/18-24; заявлено 22.02.78; опубл. 10.05.80. – Бюл.№24. – 4 с.
106. Жабин В.И Программно-аппаратная реконфигурация отказоустойчивых вычислительных систем// Вiсник Нацiонального технiчного
унiверситету України “Київський полiтехнiчний iнститут”. Iнформатика,
управлiння та обчислювальна технiка. – 2002 – № 39. – С. 57 – 63.
107. Розробка високопродуктивних обчислювальних засобів для систем числового програмного управління: Звіт про НДР (наук. кер.
В.І.Жабін), Національний технічний університет України “Київський
політехнічний інститут”/ № ДР 01970017542, вихідн. № 434.24.12.97. –
Київ, 1997. – 75 с.
108. Мультипроцессорная система: А. с. №1524063 СССР, МКИ G 06
F 15/16, 11/00 / В.И.Жабин, Г.В.Гончаренко, В.В.Макаров, В.И.Савченко,
Л.В.Петровская, В.В.Ткаченко (СССР). – №4308768/24-24; заявлено
24.09.87; опубл. 23.11.89. Бюл. №43. – 14 с.
109. Мультипроцессорная система: А. с. №1732351 СССР, МКИ G 06
F 15/16 / Г.В.Гончаренко, В.И.Жабин, В.В.Ткаченко (СССР). –
№4827054/24; заявлено 21.05.92; опубл. 07.05.92. Бюл. №17. – 20 с.
110. Многопроцессорная вычислительная система: А. с. №1820391
СССР, МКИ G 06 F 15/16 / В.И.Жабин, Г.В.Гончаренко, В.В.Ткаченко,
В.И.Кожевников (СССР). – №4918384/24; заявлено 11.03.91; опубл.
07.06.93. Бюл. №21. – 6 с.
66.
ОГЛАВЛЕНИЕПредисловие ................................................................................................ 3
Глава 1. Проблемы повышения эффективности вычислительных
систем реального времени ................................................................................. 4
1.1. Особенности класса алгоритмов управления и требования к
вычислительным системам ............................................................................ 4
1.2. Исследование адекватности структур вычислительных
систем и алгоритмов ....................................................................................... 6
1.3. Влияние структуры алгоритмов и архитектурных
особенностей систем на эффективность параллельных вычислений ...... 13
Глава 2. Классификация и языки описания архитектуры
вычислительных систем ................................................................................... 16
2.1. Классификации параллельных систем ......................................... 16
2.2. Структурная классификация систем с магистральной
топологией ..................................................................................................... 19
2.3. Языки описания архитектуры вычислительных систем ............. 22
2.4. Графический язык описания архитектуры систем ...................... 25
Глава 3. Архитектура систем с магистральной топологией .................. 33
3.1. Системы с единым адресным пространством ............................. 33
3.2. Системы с локальной памятью ..................................................... 34
3.3. Системы с коммуникационной памятью ..................................... 37
3.4. Системы с «оконным» доступом к локальной памяти ............... 39
3.5. Сравнительная характеристика систем с общей магистралью .. 41
Глава 4. Методы ускорения межпроцессорного обмена
информацией в системах с общей магистралью ........................................... 55
4.1. Методы ускорения обмена информацией в централизованных
системах ......................................................................................................... 55
4.2. Метод ускорения обмена данными в децентрализованных
системах ......................................................................................................... 59
4.3. Метод ускорения обмена информацией в системах с
"оконным" доступом к памяти ..................................................................... 62
4.4. Дополнительные возможности повышения эффективности
обмена информацией в мультипрцессорных системах ............................. 65
Глава 5. Организация прерываний и доступа к общему системному
ресурсу ............................................................................................................... 69
5.1. Магистральные протоколы ........................................................... 69
5.2. Интерфейсы в системах с модульной организацией.................. 73
5.3. Арбитры доступа к общему аппаратному ресурсу ..................... 77
5.4. Метод доступа к общему ресурсу с динамическими
приоритетами ................................................................................................ 81
5.5. Сравнительная оценка эффективности методов доступа к
общей магистрали ......................................................................................... 83
67.
174Архитектура вычислительных систем реального времени
5.6. Контроллеры внешних прерываний ............................................. 86
5.7. Распределенные контроллеры прерываний с динамическими
приоритетами запросов ................................................................................ 92
Глава 6. Архитектура потоковых вычислительных систем .................. 95
6.1. Модель вычислений под управлением потока данных .............. 95
6.2. Архитектура потоковых процессоров ........................................ 100
6.3. Потоковый процессор с адресным поиском информации в
среде формирования команд...................................................................... 105
Глава 7. Организация вычислительных процессов в потоковых
системах........................................................................................................... 112
7.1. Язык графического описания программ для потоковых
систем .......................................................................................................... 112
7.2. Циклические конструкции в потоковых программах ............... 115
7.3. Модифицированный графический язык описания программ .. 117
7.4. Программирование последовательно-параллельных
процессов..................................................................................................... 119
7.5. Метод командной синхронизации циклических процессов .... 123
7.6. Сравнительная оценка сложности потоковых систем с
различной организацией вычислительных процессов ............................ 127
Глава 8. Методы повышения эффективности мультипроцессорных
систем за счет совместного использования классической и потоковой
моделей вычислений ...................................................................................... 131
8.1. Комбинированный метод реализации алгоритмов с
"мелкозернистой" структурой ................................................................... 131
8.2. Метод синхронизации процессов доступа к общему ресурсу
с использованием потокового вычислителя ............................................. 136
8.3. Метод динамического распределения заданий между
процессорами под управлением потока дескрипторов данных.............. 145
Глава 9. Отказоустойчивая система на однотипных процессорных
модулях ............................................................................................................ 154
9.1. Архитектура отказоустойчивой системы .................................. 154
9.2. Функционирование и реконфигурация системы....................... 160
Заключение .............................................................................................. 164
Литература............................................................................................... 166