")



















































































 database
databaseSimilar presentations:
")

")




")


Основи інтелектуального аналізу даних. Консолідація даних
1. ОСНОВИ ІНТЕЛЕКТУАЛЬНОГО АНАЛІЗУ ДАНИХ (2015 р.)
МІНІСТЕРСТВО ОСВІТИ І НАУКИ, МОЛОДІ ТА СПОРТУ УКРАЇНИКРЕМЕНЧУЦЬКИЙ НАЦІОНАЛЬНИЙ УНІВЕРСИТЕТ
ІМЕНІ МИХАЙЛА ОСТРОГРАДСЬКОГО
ОСНОВИ ІНТЕЛЕКТУАЛЬНОГО АНАЛІЗУ ДАНИХ
(2015 р.)
Лекція 2. КОНСОЛІДАЦІЯ ДАНИХ
© 1995-2010 Компания BaseGroup TM Labs www.basegroup.ru
2.
21. Задача консолідації
1.1 Введення
1.2 Джерела даних
1.3 Основні задачі консолідації даних
3.
31.1 Введення
Цінність
і
достовірність
знань,
отриманих
в
результаті
інтелектуального аналізу бізнес-даних, залежить не тільки від
ефективності
використовуваних
аналітичних
методів
та
алгоритмів, але і від того, наскільки правильно підібрані і
підготовлені вихідні дані для аналізу.
По-перше, дані на підприємстві розташовані в різних джерелах
найрізноманітніших форматів і типів – в окремих файлах офісних
документів (Excel, Word, звичайних текстових файлах), в облікових
системах («1С: Підприємство», «Парус» та ін.), у базах даних (Oracle,
Access, dBase та ін.)
По-друге, дані можуть бути надлишковими або, навпаки,
недостатніми.
А по-третє, дані є «брудними», тобто містять фактори, що
заважають їх правильній обробці та аналізу (пропуски, аномальні
значення, дублікати і протиріччя).
4.
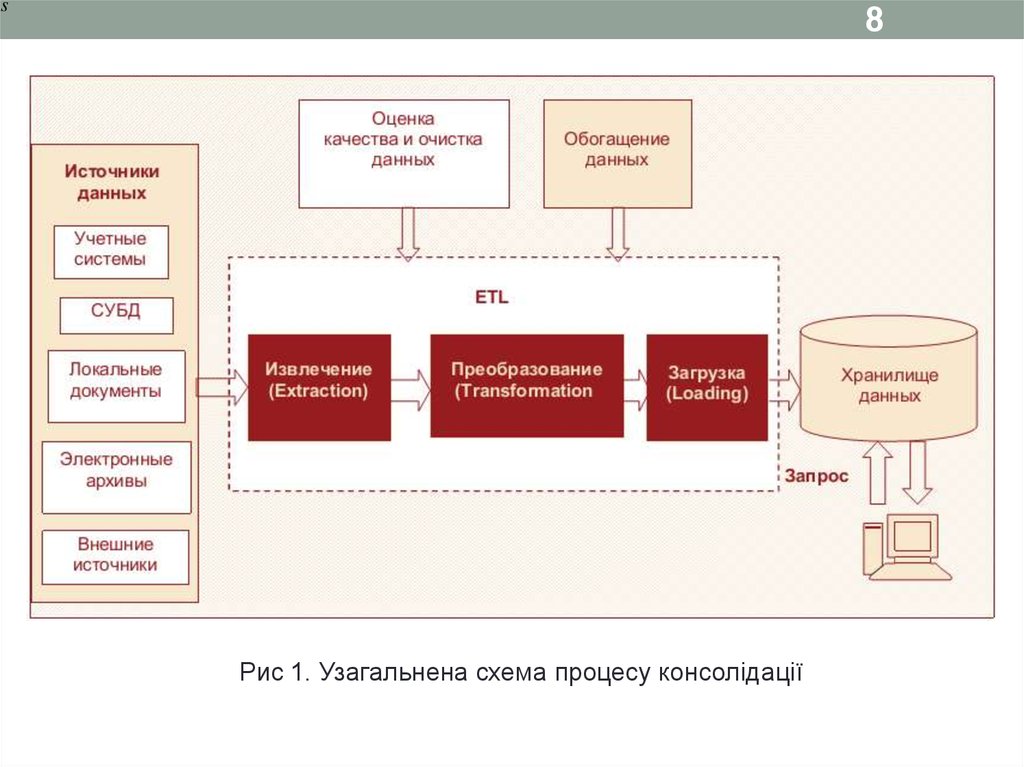
4Визначення_____________________________________
Консолідація – комплекс методів і процедур,
спрямованих на вилучення даних з різних джерел,
забезпечення необхідного рівня їх інформативності та
якості, перетворення в єдиний формат, в якому вони
можуть бути завантажені в сховище даних або аналітичну
систему.
Основні критерії оптимальності з точки зору консолідації
даних:
– забезпечення високої швидкості доступу до даних;
– компактність зберігання;
– автоматична підтримка цілісності структури даних;
– контроль несуперечності даних.
5.
51.2 Джерела даних
Ключовим поняттям консолідації є джерело даних – об'єкт,
що містить структуровані дані, які можуть виявитися
корисними для вирішення аналітичної задачі.
Необхідно, щоб аналітична платформа могла здійснювати
доступ до даних із цього об'єкта безпосередньо або після їх
перетворення в інший формат. В іншому випадку
очевидно, що об'єкт не може вважатися джерелом
даних.
Формування масивів даних для аналізу в більшості
випадків лягає на плечі замовників аналітичних рішень.
6.
61.3 Основні задачі консолідації даних
У процесі консолідації даних вирішуються наступні
завдання:
– вибір джерел даних;
– розробка стратегії консолідації;
– оцінка якості даних;
– збагачення;
– очищення;
– перенесення в сховищі даних (СД).
7.
7Визначення____________________________________
Очищення даних – комплекс методів і процедур,
спрямованих на усунення причин, що заважають коректній
обробці: аномалій, пропусків, дублікатів, протиріч, шумів
тощо.
Визначення_____________________________________
Збагачення – процес доповнення даних деякої інформацією,
що дозволяє підвищити ефективність вирішення аналітичних
задач.
8.
s8
Рис 1. Узагальнена схема процесу консолідації
8
9.
9Приклад________________________________________
Процес збирання, зберігання та оперативної обробки
даних на типовому підприємстві зазвичай містить кілька
рівнів. На верхньому рівні розташовуються реляційні
SQL-орієнтовані СУБД типу SQL Server, Oracle тощо.
На другому – файлові сервери з деякою системою
оперативної обробки або мережеві версії персональних
СУБД типу dBase, FoxPro, Paradox тощо. І нарешті, на
самому нижньому рівні розташовані локальні ПК
окремих користувачів з персональними джерелами даних.
Найчастіше інформація на них збирається у вигляді
файлів офісних додатків – Word, Excel, текстові файли
тощо.
10.
102 Сховища даних
2.1 Введення в сховища даних
2.2 Передумови появи СД
2.3 Основні особливості концепції СД
2.4 Основні вимоги до СД
11.
112 Сховища даних
2.1 Введення в сховища даних
До середини 80-х рр. XX ст. практично повністю
завершився перший етап оснащення бізнесу і державних
структур засобами обчислювальної техніки і почався період
бурхливого розвитку корпоративних інформаційних
систем для організації збору і збереження великих масивів
різного роду ділової та службової інформації, тобто, для
транзакційної обробки інформації – OLTP-систем
OLTP (On-Line Transaction Processing – оперативна,
тобто в режимі реального часу, обробка транзакцій).
12.
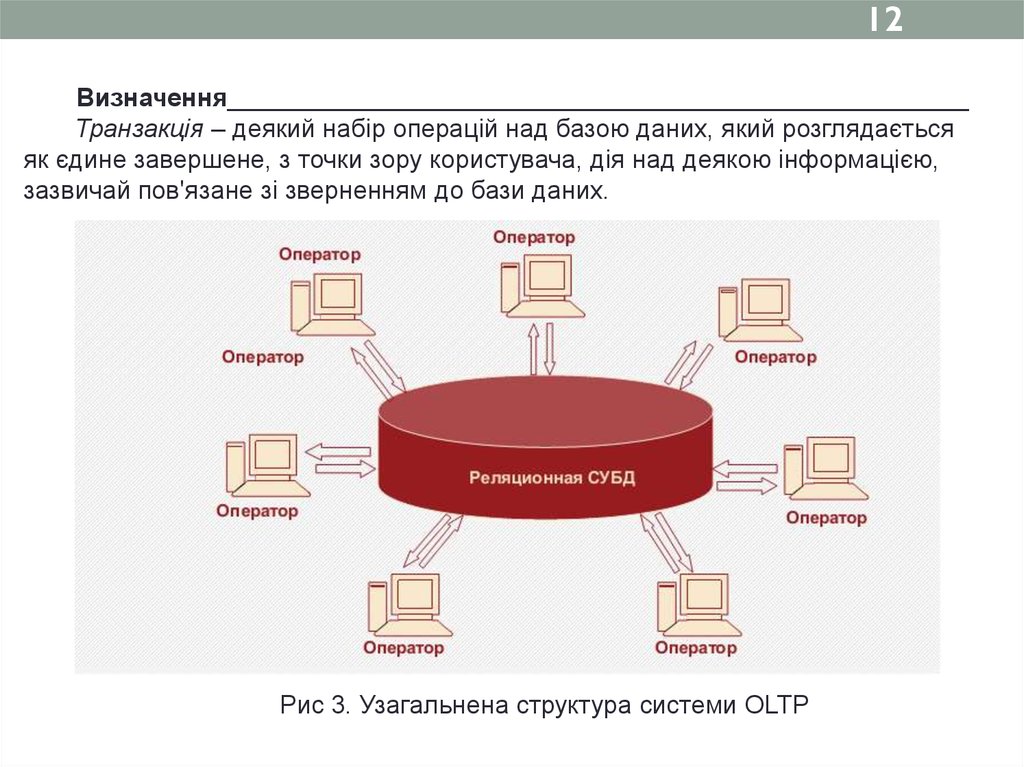
12Визначення____________________________________________________
Транзакція – деякий набір операцій над базою даних, який розглядається
як єдине завершене, з точки зору користувача, дія над деякою інформацією,
зазвичай пов'язане зі зверненням до бази даних.
Рис 3. Узагальнена структура системи OLTP
13.
13Приклад__________________________________________________________
Типовим прикладом застосування OLTP-систем є масове обслуговування клієнтів,
наприклад бронювання авіаквитків або оплата послуг телефонних компаній. Обидві ці
ситуації мають дві загальних властивості: дуже велике число клієнтів і безперервне
надходження інформації. При бронюванні авіаквитків з численних пунктів продажу
безперервно стікається інформація про вже проданих квитках, яку вводять зі своїх робочих
місць оператори-продавці. У тій же БД формується інформація про вільних місцях. З точки
зору даної задачі транзакція включає в себе набір наступних дій:
– запит оператора про наявність вільних місць на той чи інший рейс;
– відгук БД з наданням відповідної інформації;
– введення оператором інформації про клієнта, номері замовленого місця і оплаченої
суми (можливо, буде присутній ще яка-небудь службова допоміжна інформація);
– передача нової інформації в базу даних та внесення до неї відповідних змін;
– передача оператору підтвердження про те, що операція виконана успішно.
Такі транзакції виконуються тисячі разів на день в сотнях пунктів продажу.
Очевидно, що основним пріоритетом в даному випадку є швидкість і паралельність
обслуговування.
Розглянемо характерні риси даного процесу, властиві в тій чи іншій мірою усім OLTPсистемам.
– Запити і звіти повністю регламентовані. Оператор не може сформувати власний
запит, щоб уточнити або проаналізувати яку інформацію.
– Як тільки переліт завершився, інформація про обслуговування даного клієнта втрачає
сенс, стає неактуальною і підлягає видаленню, після певного часу (тобто історичні дані не
підтримуються).
– Операції здійснюються над даними з максимальним рівнем деталізації, тобто по
кожному клієнту окремо.
14.
142.2 Передумови появи СД
Наприкінці 90-их з'явилася потреба в інформаційних
системах, які дозволяли б проводити глибоку аналітичну
обробку, для чого необхідно вирішувати такі завдання, як
пошук прихованих структур і закономірностей у масивах
даних, виведення з них правил, яким підкоряється дана
предметна область, стратегічне й оперативне планування,
формування нерегламентованих запитів, прийняття рішень і
прогнозування їх наслідків.
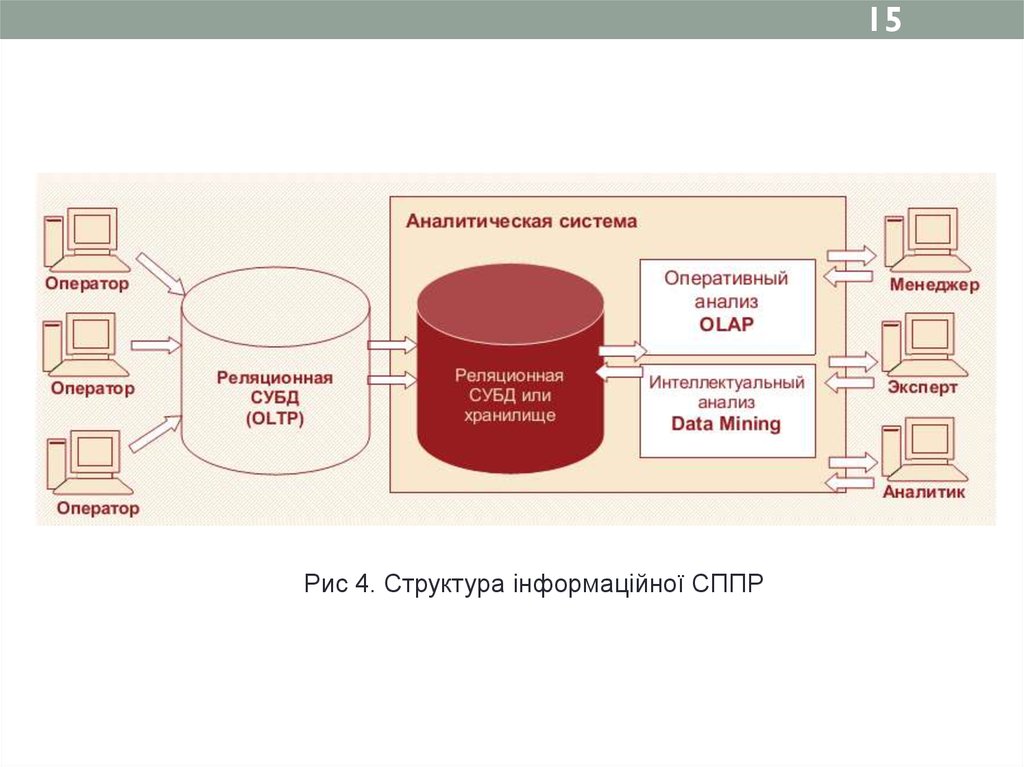
Це призвело до появи нового класу систем –
інформаційних систем підтримки прийняття
рішень (інформаційних СППР), орієнтованих на
аналітичну обробку даних з метою отримання знань,
необхідних для розробки рішень в області управління.
15.
15Рис 4. Структура інформаційної СППР
16.
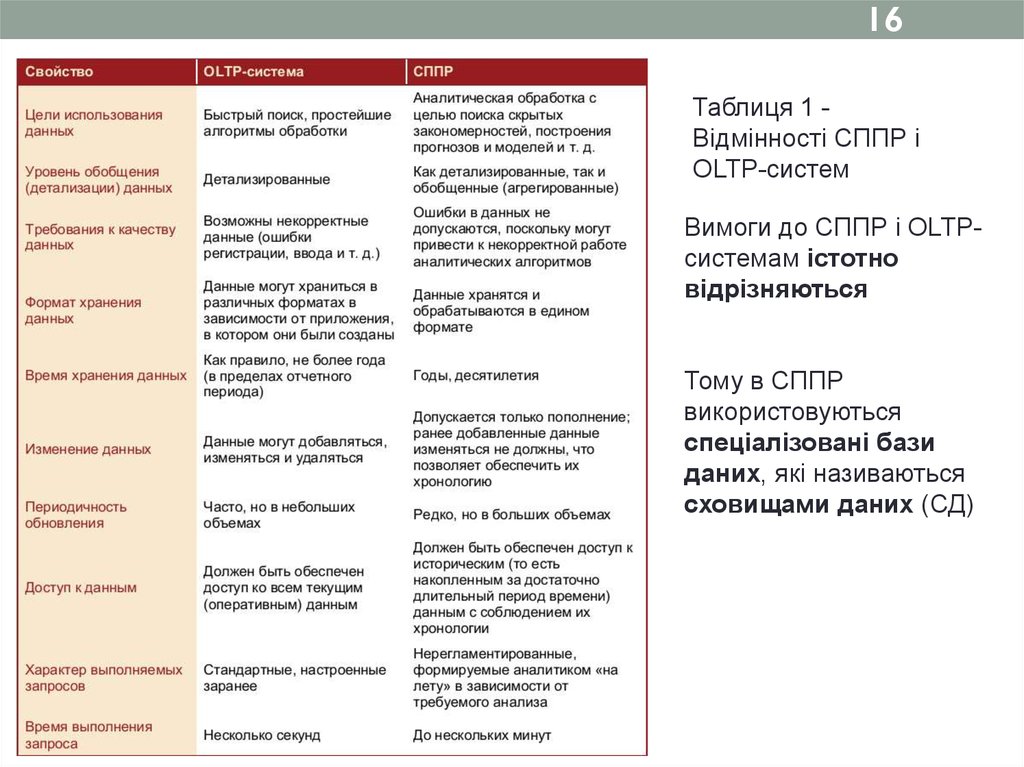
16Таблиця 1 Відмінності СППР і
OLTP-систем
Вимоги до СППР і OLTPсистемам істотно
відрізняються
Тому в СППР
використовуються
спеціалізовані бази
даних, які називаються
сховищами даних (СД)
17.
172.3 Основні особливості концепції СД
Визначення_______________________________________
Сховище даних – різновид систем зберігання, орієнтована
на підтримку процесу аналізу даних, що забезпечує
цілісність, несуперечність і хронологію даних, а також
високу швидкість виконання аналітичних запитів.
Типове СД суттєво відрізняється від звичайних систем
зберігання даних:
-різні цілі;
- різна динаміка зміни даних.
18.
182.4 Основні вимоги до СД
Вимоги, сформульовані Р. Кімболом:
- висока швидкість отримання даних зі сховища;
- автоматична підтримка внутрішньої несуперечності
даних;
- можливість отримання і порівняння зрізів даних;
- наявність зручних засобів для перегляду даних у
сховищі;
- забезпечення цілісності та достовірності збережених
даних.
19.
193 Основні концепції сховищ даних
3.1 Основні положення концепції СД
3.2 Задачі, що розв’язує СД
3.3 Деталізовані і агреговані дані
3.4 Метадані
3.5 Способи використання СД
3.6 Короткий огляд архітектури СД
20.
203 Основні концепції сховищ даних
3.1 Основні положення концепції СД
Технічний директор компанії Prism Solutions Білл Інмон на початку
1990-х р. опублікував ряд робіт, в яких сформулював основні
положення концепції СД:
- інтеграція та узгодження даних з різних джерел, таких як
звичайні системи оперативної обробки, бази даних, облікові системи,
офісні документи, електронні архіви, розташовані як усередині
підприємства, так і в зовнішньому оточенні;
- поділ наборів даних, використовуваних системами виконання
транзакцій і СППР.
Б. Інмон дав наступне визначення СД: предметно-орієнтований,
інтегрований, незмінний і підтримуючий хронологію набір даних,
призначений для забезпечення прийняття управлінських рішень.
2
21.
21Використання концепції СД у СППР і аналізі даних
сприяє досягненню таких цілей, як:
- своєчасне забезпечення аналітиків і керівників всією
інформацією, необхідної для вироблення обґрунтованих і
якісних управлінських рішень;
- створення єдиної моделі представлення даних в
організації;
- створення інтегрованого джерела даних, що надає
зручний доступ до різнорідної інформації і гарантує
отримання однакових відповідей на однакові запити з
різних аналітичних додатків.
22.
223.2 Задачі, що розв’язує СД
Рис 5. Концептуальна схема СД
Основними
завданнями, які потрібно
вирішити в процесі
розробки СД, є:
- вибір структури
зберігання даних, що
забезпечує високу
швидкість виконання
запитів і мінімізацію
обсягу оперативної
пам'яті;
- початкове
заповнення і подальше
поповнення сховища;
- забезпечення
єдиної методики
роботи з різнорідними
даними і створення
зручного інтерфейсу
користувача.
23.
233.3 Деталізовані і агреговані дані
Дані в СД зберігаються як в деталізованому, так і в
агрегованому вигляді.
Процес узагальнення деталізованих даних називається
агрегуванням, а самі узагальнені дані - агрегованими
(іноді - агрегатами)
3.4 Метадані
Слово «метадані» (від грец. Meta і лат. Data) буквально
перекладається як «дані про дані».
24.
24Приклад________________________________________________
Всім добре відомо, що в будь-якій книзі крім власне тексту
міститься значну кількість додаткової інформації. Мета її полягає в
тому, щоб, по-перше, допомогти читачеві швидше ознайомитися з
вмістом книги і осмислити його, по-друге, описати структуру книги для
більш ефективного пошуку потрібної інформації. Для вирішення
першого завдання служать такі елементи, як анотація, коментарі,
глосарій, примітки і т. ін. Для пошуку потрібної інформації
використовуються зміст, назви розділів, параграфів і розділів, номери
сторінок, колонтитули, предметний покажчик і т. ін. Крім цього,
читачеві можуть знадобитися відомості про авторів або про
видавництво. Вся ця інформація, яка не є частиною книги, а служить
для підвищення ефективності роботи з нею, і являє собою метадані. У
бібліотеці метадані застосовуються для пошуку потрібних видань та
відстеження їх переміщень, наприклад, систематичний або
алфавітний каталоги, в яких використовуються назви книг, прізвища
авторів, рік видання і т. ін. Таким чином, метадані мають дуже велике
значення при роботі з різного роду інформацією.
25.
25Визначення___________________________________
Метадані - високорівневі засоби відображення
інформаційної моделі та опису структури даних,
використовуваної в СД. Метадані повинні містити опис
структури даних сховища і структури даних імпортованих
джерел. Метадані зберігаються окремо від даних в так
званому репозитарії метаданих.
Можна виділити два рівня метаданих - технічний
(адміністративний) і бізнес-рівень.
Технічний рівень містить метадані, необхідні для
забезпечення функціонування сховища (статистика
завантаження даних та їх використання, опис моделі даних
і т. ін.).
Бізнес-метадані являють собою опис предметної
області, для роботи в якій створюється аналітична система
або СД.
26.
263.5 Способи використання СД
Можна виділити три основні підходи до
використання СД:
- регулярні звіти - підготовка звітів стандартних
форм, одержуваних багаторазово з певною
періодичністю;
- нерегламентовані запити - можливість отримувати
відповіді на нестандартні, сформовані «на вимогу»
питання;
- інтелектуальний аналіз даних - підтримка процесу
інтелектуального аналізу великих масивів даних з метою
виявлення прихованих закономірностей, структур та
об'єктів, побудови моделей, прогнозів і т. ін.
27.
273.6 Короткий огляд архітектури СД
Типи архітектур сховищ - реляційні, багатовимірні, гібридні і
віртуальні.
Реляційні CД використовують класичну реляційну
модель, характерну для оперативних реєструючих OLTPсистем. Дані зберігаються в реляційних таблицях, але
утворюють спеціальні структури, що емулюють
багатовимірне представлення даних. Така технологія
позначається абревіатурою ROLAP - Relational OLAP.
28.
28Багатовимірні СД реалізують багатовимірне
представлення даних на фізичному рівні у вигляді
багатовимірних кубів. Дана технологія отримала назву
MOLAP - Multidimensional OLAP.
Гібридні СД поєднують у собі властивості як реляційної, так
і багатовимірної моделей даних. У гібридних СД
деталізовані дані зберігаються в реляційних таблицях, а
агрегати - у багатовимірних кубах. Така технологія побудови
СД називається HOLAP - Hybrid OLAP
Усі СД можна розділити на одноплатформенні і
крос-платформенні.
Одноплатформні СД будуються на базі тільки одного
СУБД, а крос-платформні можуть будуватися на базі
декількох СУБД.
29.
294 Багатовимірні сховища даних
4.1 Основи багатовимірного представлення
даних
4.2 Вимірювання і факти – базові поняття
багатовимірної моделі даних
4.3 Структура багатовимірного куба
4.4 Робота з вимірюваннями
30.
304 Багатовимірні сховища даних
Призначення багатомірних сховищ даних (БСД) –
підтримка систем, орієнтованих на аналітичну обробку
даних, оскільки такі сховища краще справляються з
виконанням складних нерегламентованих запитів.
Багатовимірна модель даних, що лежить в основі
побудови багатомірних сховищ даних, спирається на
концепцію багатовимірних кубів, або гіперкубів - OLAPкубів (абревіатура OLAP розшифровується як On-Line
Analytical Processing – оперативна аналітична обробка).
31.
314.1 Основи багатовимірного представлення даних
Доведено, що реляційна модель не є оптимальною
з точки зору завдань аналізу, оскільки припускає
високий ступінь нормалізації, в результаті чого
знижується швидкість виконання запитів.
Вихід
розробка
багатовимірної
моделі
представлення даних, яка реалізується за допомогою
багатовимірних кубів.
32.
324.2 Вимірювання і факти – базові поняття
багатовимірної моделі даних
В основі багатовимірного подання даних лежить їх поділ на
дві групи – виміри і факти.
Виміри – категоріальні атрибути, найменування і властивості об'єктів,
що беруть участь у деякому бізнес-процесі. Значеннями вимірювань є
найменування товарів, назви фірм-постачальників і покупців, ПІБ
людей, назви міст і т. ін. Виміри можуть бути і числовими, якщо якійнебудь категорії (наприклад, назві товару) відповідає числовий код.
Виміри якісно описують досліджуваний бізнес-процес.
Факти – дані, що кількісно описують бізнес-процес, безперервні за
своїм характером, тобто вони можуть набувати нескінченної множини
значень.
Приклади фактів - ціна товару або виробів, їх кількість, сума продажу
або закупівель, зарплата співробітників, сума кредиту, страхової
винагороди і т. ін.
33.
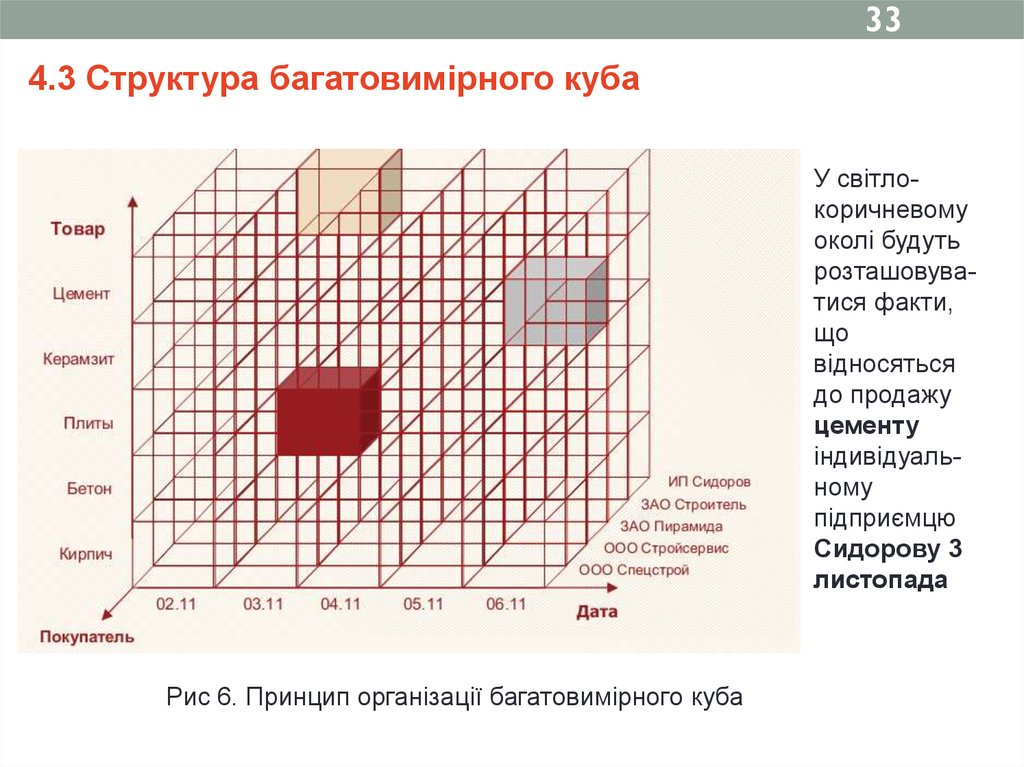
334.3 Структура багатовимірного куба
У світлокоричневому
околі будуть
розташовуватися факти,
що
відносяться
до продажу
цементу
індивідуальному
підприємцю
Сидорову 3
листопада
Рис 6. Принцип організації багатовимірного куба
34.
34Багатомірний
погляд на
вимірювання
Дата, Товар і
Покупець
представлений на
рис.
Рис 7. Вимірювання та факти в багатовимірному кубі
Фактами в даному випадку можуть бути Ціна, Кількість, Сума. Тоді
виділений сегмент буде містити інформацію про те, скільки плит, на яку
суму і за якою ціною придбала фірма ЗАТ «Будівельник» 3 листопада.
35.
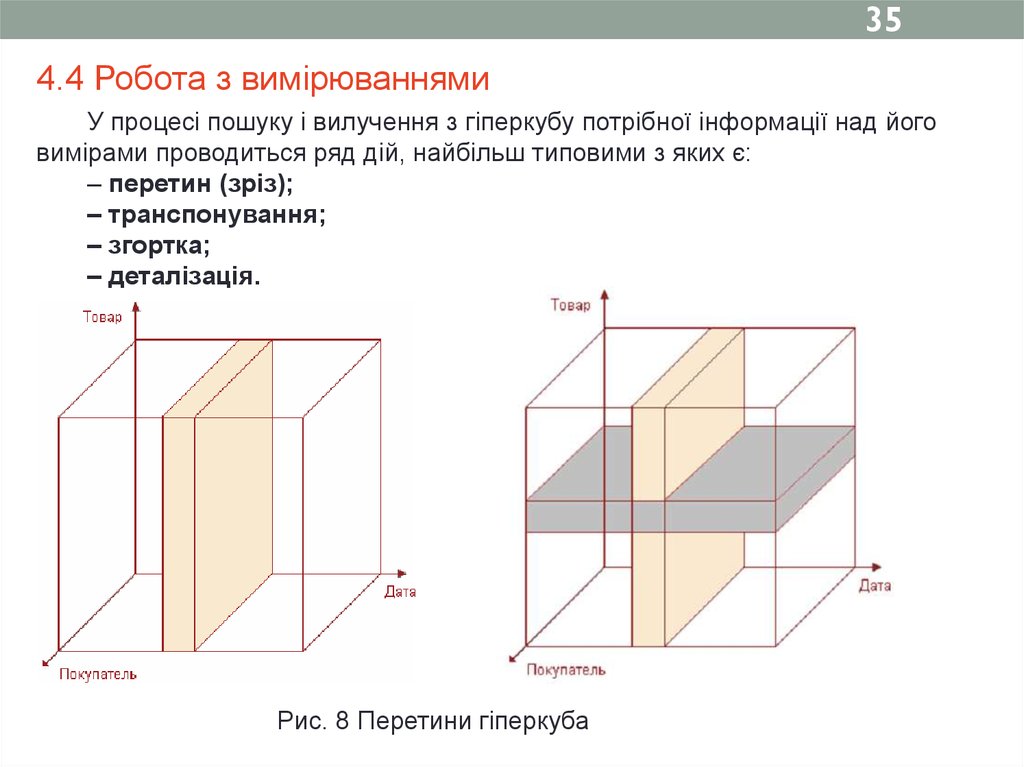
354.4 Робота з вимірюваннями
У процесі пошуку і вилучення з гіперкубу потрібної інформації над його
вимірами проводиться ряд дій, найбільш типовими з яких є:
– перетин (зріз);
– транспонування;
– згортка;
– деталізація.
Рис. 8 Перетини гіперкуба
36.
36Транспонування застосовується до плоских таблиць, отриманих, наприклад, у
результаті зрізу, і дозволяє змінити порядок стовпчиків і рядків
Вихідна таблиця
Результат згортки вихідної таблиці за виміром «Товар»
37.
375 Реляційні сховища даних
5.1 Схеми побудови РСД
5.2 Переваги і недоліки РСД
38.
385 Реляційні сховища даних
Визначення___________________________________________________
Реляційна БД (relational database) – сукупність відношень, котрі містять
всю інформацію, яка повинна зберігатися в базі. Фізично це виражається в
тому, що інформація зберігається у вигляді двовимірних таблиць,
пов'язаних з допомогою ключових полів.
Застосування реляційної моделі при створенні СД у ряді випадків
дозволяє отримати переваги над багатовимірної технологією, особливо в
частині ефективності роботи з великими масивами даних і
використання пам'яті комп'ютера. На основі реляційних СД (РСД)
будуються ROLAP-системи, і ця ідея теж належить Кодду.
В основі технології РСД лежить принцип, відповідно до якого виміри
зберігаються в плоских таблицях так само, як і в звичайних реляційних
СУБД, а факти (дані, що агрегуються) – в окремих спеціальних таблицях
цієї ж БД. При цьому таблиця фактів є основою для пов'язаних з нею
таблиць вимірів. Вона містить кількісні характеристики об'єктів і подій,
сукупність яких передбачається надалі аналізувати.
39.
395.1 Схеми побудови РСД
На логічному рівні розрізняють дві схеми побудови РСД – «зірка» і «сніжинка».
-Центральною є
таблиця фактів,
з якою пов'язані
всі таблиці
вимірів;
-інформація про
кожному виміру
розташовується в
окремій таблиці
Рис. 9 Схема побудови РСД «зірка»
40.
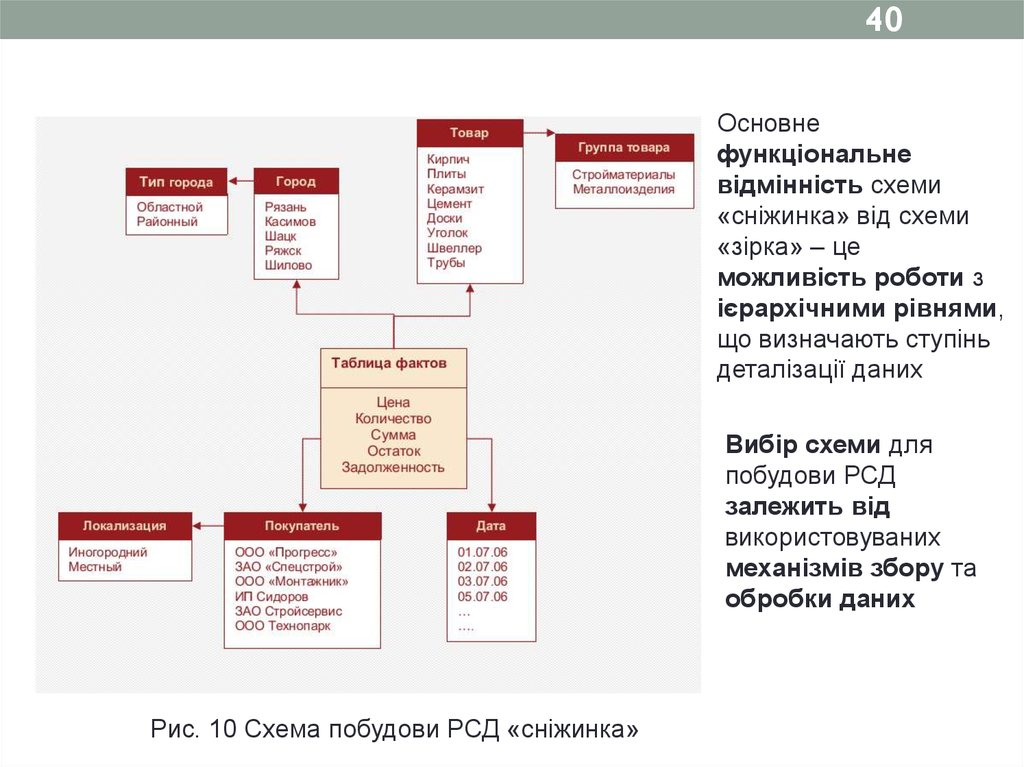
40Основне
функціональне
відмінність схеми
«сніжинка» від схеми
«зірка» – це
можливість роботи з
ієрархічними рівнями,
що визначають ступінь
деталізації даних
Вибір схеми для
побудови РСД
залежить від
використовуваних
механізмів збору та
обробки даних
Рис. 10 Схема побудови РСД «сніжинка»
41.
415.2 Переваги і недоліки РСД
Основні переваги РСД:
– практично необмежений обсяг збережених даних;
– оскільки реляційні СУБД лежать в основі побудови багатьох
систем оперативної обробки (OLTP), які зазвичай є головними
джерелами даних для СД, використання реляційної моделі дозволяє
спростити процедуру завантаження та інтеграції даних у СД;
– при додаванні нових вимірів даних немає необхідності
виконувати складну фізичну реорганізацію сховища на відміну,
наприклад, від багатовимірних СД;
– забезпечуються високий рівень захисту даних і широкі
можливості розмежування прав доступу.
Головний недолік - при використанні високого рівня узагальнення
даних та ієрархічності вимірів починають «розмножуватися»
таблиці агрегатів. У результаті швидкість виконання запитів
сповільнюється.
42.
42Вибір реляційної моделі при побудові СД доцільний:
– Значний обсяг збережених даних (багатовимірні СД
стають неефективними).
– Ієрархія вимірювань нескладна (іншими словами,
небагато агрегованих даних).
– Потрібна часта зміна розмірності даних. При
використанні реляційної моделі можна обмежитися
додаванням нових таблиць, а для багатовимірної моделі
доведеться виконувати складну перебудову фізичної
структури сховища.
43.
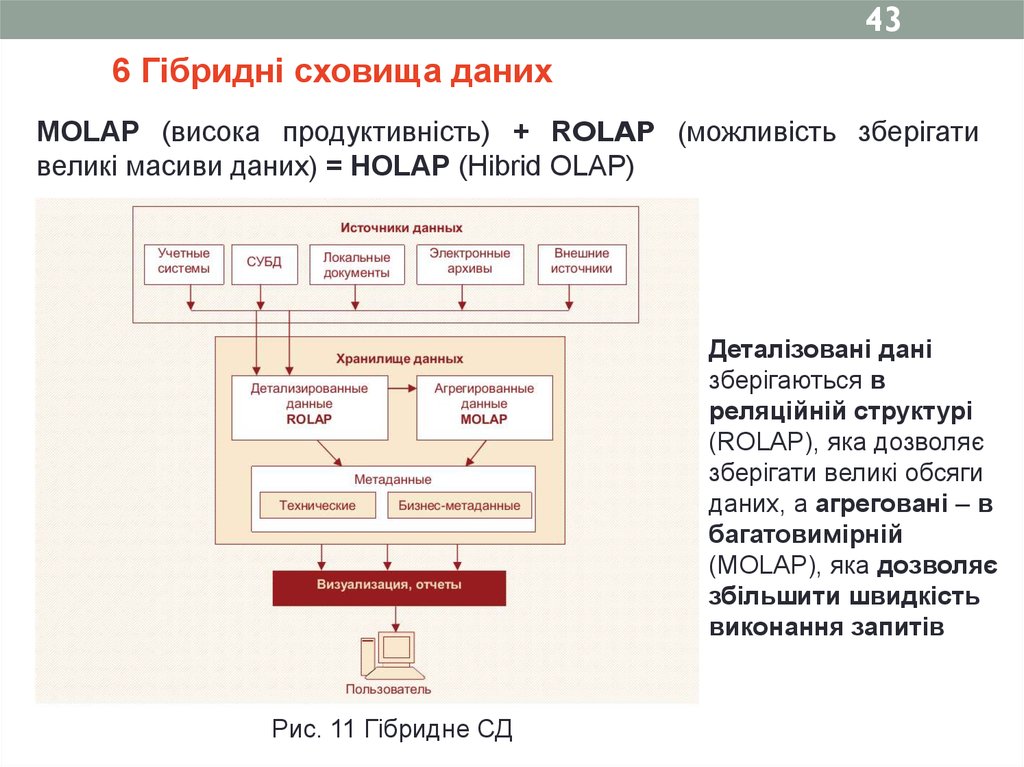
436 Гібридні сховища даних
MOLAP (висока продуктивність) + ROLAP (можливість зберігати
великі масиви даних) = HOLAP (Hibrid OLAP)
Деталізовані дані
зберігаються в
реляційній структурі
(ROLAP), яка дозволяє
зберігати великі обсяги
даних, а агреговані – в
багатовимірній
(MOLAP), яка дозволяє
збільшити швидкість
виконання запитів
Рис. 11 Гібридне СД
44.
44Приклад________________________________________
У супермаркеті, щодня обслуговуючому десятки тисяч
покупців, встановлено реєстраційну OLTP-систему. При
цьому максимальному рівню деталізації зареєстрованих
даних відповідає купівля за одним чеком, в якому
зазначаються загальна сума купівлі, найменування або
коди придбаних товарів і вартість кожного товару.
Оперативна інформація, яка складається із деталізованих
даних, консолідується в реляційній структурі СД. З
точки зору аналізу представляють інтерес узагальнені
дані, наприклад, за групами товарів, відділам або
деяким інтервалам дат. Тому вихідні деталізовані дані
агрегуються, і обчислені агрегати зберігаються в
багатовимірної структурі гібридного СД.
45.
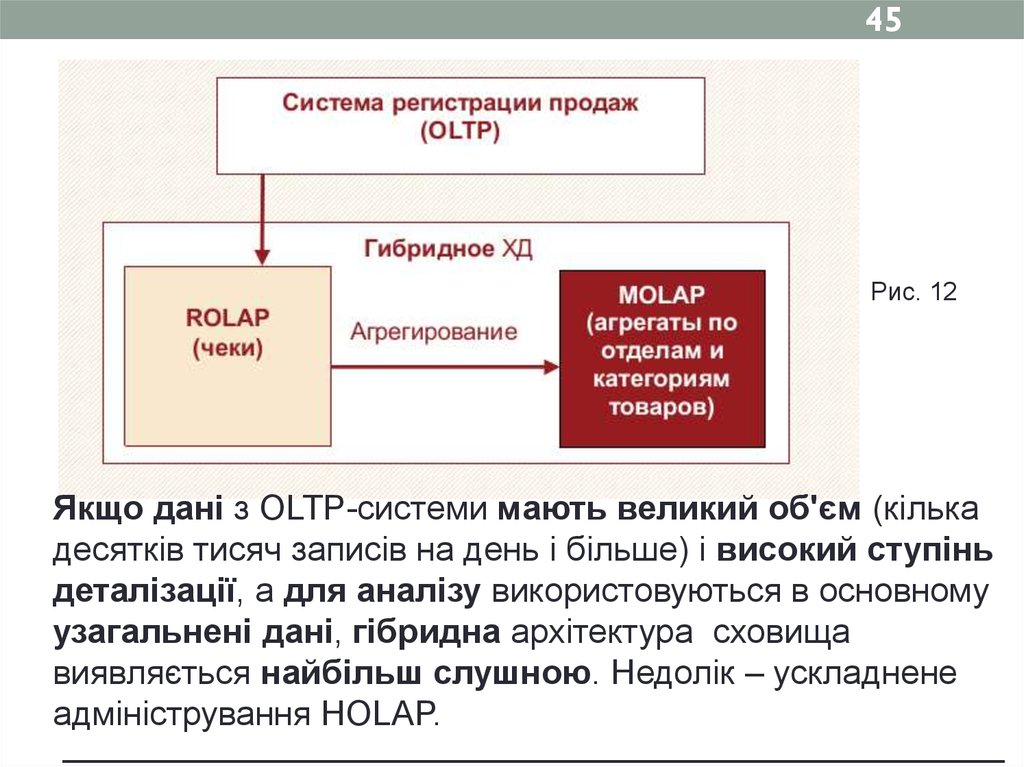
45Рис. 12
Якщо дані з OLTP-системи мають великий об'єм (кілька
десятків тисяч записів на день і більше) і високий ступінь
деталізації, а для аналізу використовуються в основному
узагальнені дані, гібридна архітектура сховища
виявляється найбільш слушною. Недолік – ускладнене
адміністрування HOLAP.
__________________________________________________________________
46.
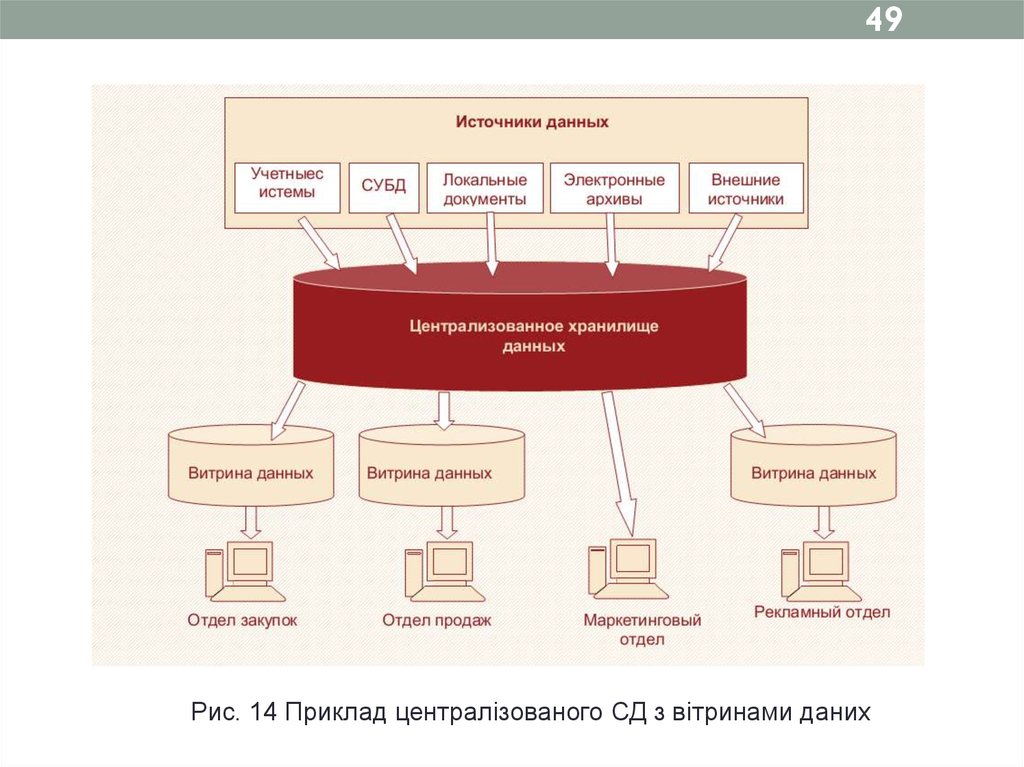
466.1 Вітрини даних
Концепція вітрини даних (data marts) полягає у
виділенні профільних даних, найчастіше використовуваних
за певним напрямом діяльності, в окремий набір і в
організації його зберігання в окремій багатовимірній БД,
підключеній до централізованого СД.
Найчастіше для побудови вітрин даних
використовується багатовимірна модель, хоча в деяких
випадках використовується і реляційна модель.
Визначення_____________________________________
Вітрина даних – спеціалізоване локальне тематичне
сховище, підключене до централізованого CД та яке
обслуговує окремий підрозділ організації або певний
напрям її діяльності.
________________________________________________
47.
47Рис. 13 Консолідація з використанням вітрин даних
48.
48Переваги вітрин даних:
– зміст даних, тематично орієнтованих на
конкретного користувача;
– відносно невеликий обсяг збережених даних, на
організацію і підтримку яких не потрібно значних витрат;
– поліпшені можливості в розмежуванні прав доступу
користувачів, так як кожен з них працює тільки зі своєю
вітриною і має доступ тільки до інформації, що
відноситься до певного напрямку діяльності.
49.
49Рис. 14 Приклад централізованого СД з вітринами даних
50.
507 Віртуальні сховища даних
Проблеми, пов’язані з фізичною реалізацією ідеї СД:
- Виникає необхідність аналізувати інформацію
протягом робочого дня відразу по мірі її надходження.
(СД поповнюється не частіше ніж один раз на добу)
- Надмірність даних. (Характерна як для реляційних, так
і для багатовимірних сховищ).
Наслідок - “вибухове“ зростання обсягів СД
Рішення проблеми - реалізація концепції віртуального
сховища даних (ВСД)
51.
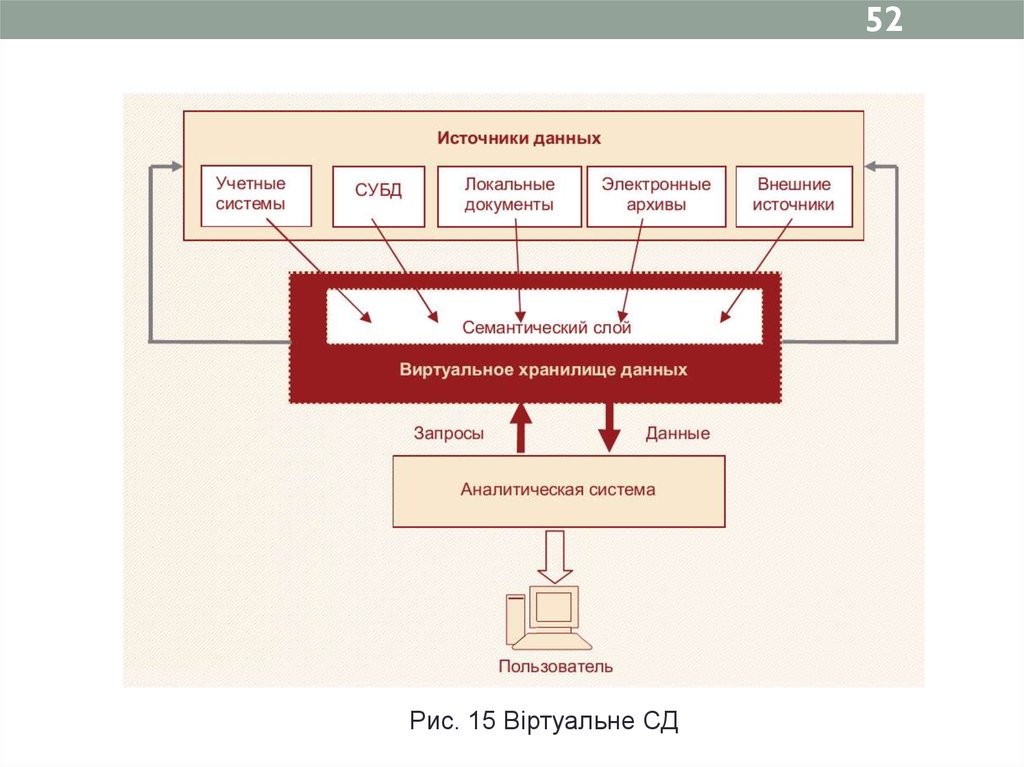
51Визначення_____________________________________
Віртуальним сховищем даних називається система, яка
працює з розрізненими джерелами даних і емулює роботу
звичайного сховища даних, витягуючи, перетворюючи й
інтегруючи дані безпосередньо в процесі виконання запиту.
Переваги:
– можливість аналізу даних у OLTP-системі відразу
після їх надходження без очікування завантаження у СД;
– мінімізація обсягу необхідної дискової і оперативної
пам'яті;
– дозволяє аналітику повністю абстрагуватися від
проблем, пов'язаних з процесом добування даних з
різноманітних джерел, і зосередитися на вирішенні завдань
аналізу даних.
52.
52Рис. 15 Віртуальне СД
53.
53Недоліки:
– Збільшується навантаження на OLTP-систему.
– Тимчасова недоступність хоча б одного з джерел може призвести
до неможливості виконання запиту або до спотворення представленої по
ньому інформації.
– Відсутні автоматична підтримка цілісності і несуперечності
даних.
– Помилки при обробці і спотворення інформації, із-за різних
форматів джерел.
– По одному і тому ж запиту в різні моменти часу можуть бути
отримані відмінні дані.
– Неможлива робота з історичними даними.
Тому якщо історичні дані відіграють важливу роль при аналізі, то
необхідно використовувати СД з фізичною консолідацією даних. А ВСД
слід застосовувати в системах, орієнтованих на аналіз оперативної
інформації, актуальної тільки протягом обмеженого періоду.
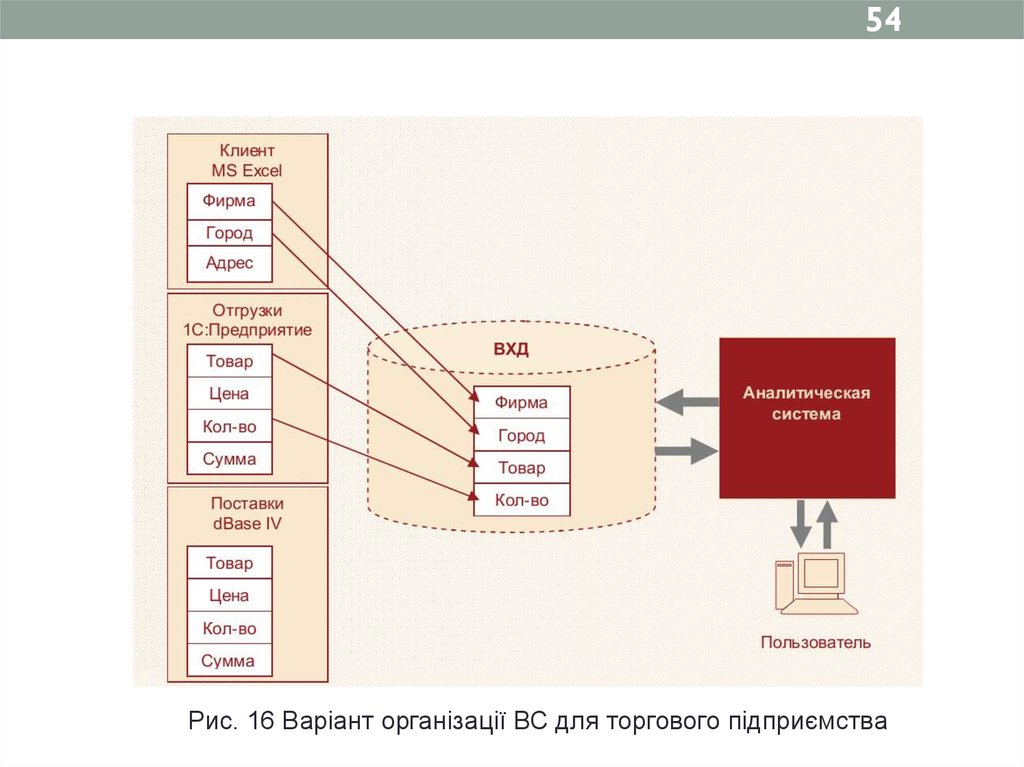
54.
54Рис. 16 Варіант організації ВС для торгового підприємства
55.
558 Введення в ETL
8.1 Основні цілі і задачі ETL
8.2 Вилучення даних у ETL
8.2 Вибір джерел даних, що використовуються
8.3 Особливості організації процесу вилучення даних
8.4 Особливості вилучення даних з різних типів джерел
56.
568 Введення в ETL
Витяг даних із різнотипних джерел і перенесення їх в
сховище даних з метою подальшої аналітичної обробки
пов'язані з низкою проблем, основними з яких є такі.
– Різноманітність типів і форматів, створених у
різних додатках, різні формати кодувань.
– Надмірна деталізація даних початкових джерел.
– «Забрудненість» початкових даних.
57.
57Визначення____________________________________
ETL – комплекс методів, що реалізують процес
переносу вихідних даних з різних джерел в аналітичний
додаток або у сховище даних, що його підтримує.
ETL (від англ. extraction, transformation, loading «витяг», «перетворення», «завантаження»). Сам процес
перенесення даних і пов'язані з ним дії називаються ETLпроцесом, а відповідні програмні засоби – ETLсистемами.
58.
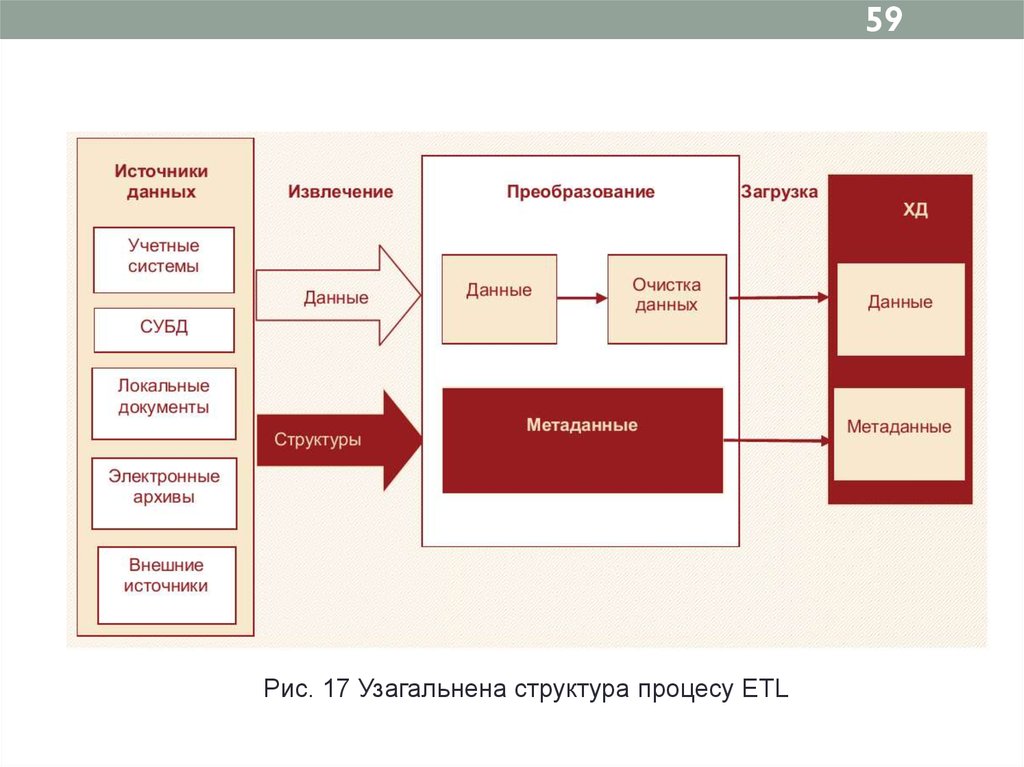
588.1 Основні цілі і задачі ETL
ETL-система повинна забезпечувати виконання трьох
основних етапів:
– Витяг даних і інформації, що описує їх структуру.
– Перетворення даних: перетворення форматів,
кодування даних, узагальнення та очищення.
– Завантаження даних – запис перетворених даних у
відповідну систему зберігання.
59.
59Рис. 17 Узагальнена структура процесу ETL
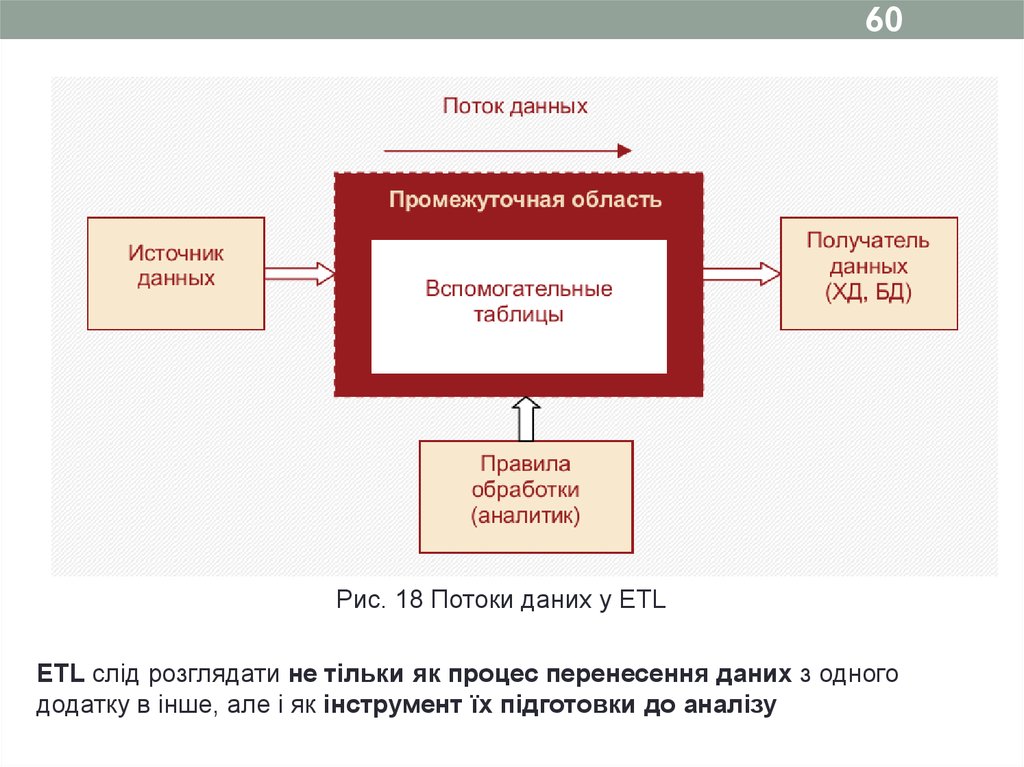
60.
60Рис. 18 Потоки даних у ETL
ETL слід розглядати не тільки як процес перенесення даних з одного
додатку в інше, але і як інструмент їх підготовки до аналізу
61.
618.2 Вилучення даних у ETL
Процедуру вилучення можна реалізувати двома основними способами.
Рис. 19 Витяг даних за допомогою спеціалізованих програмних засобів
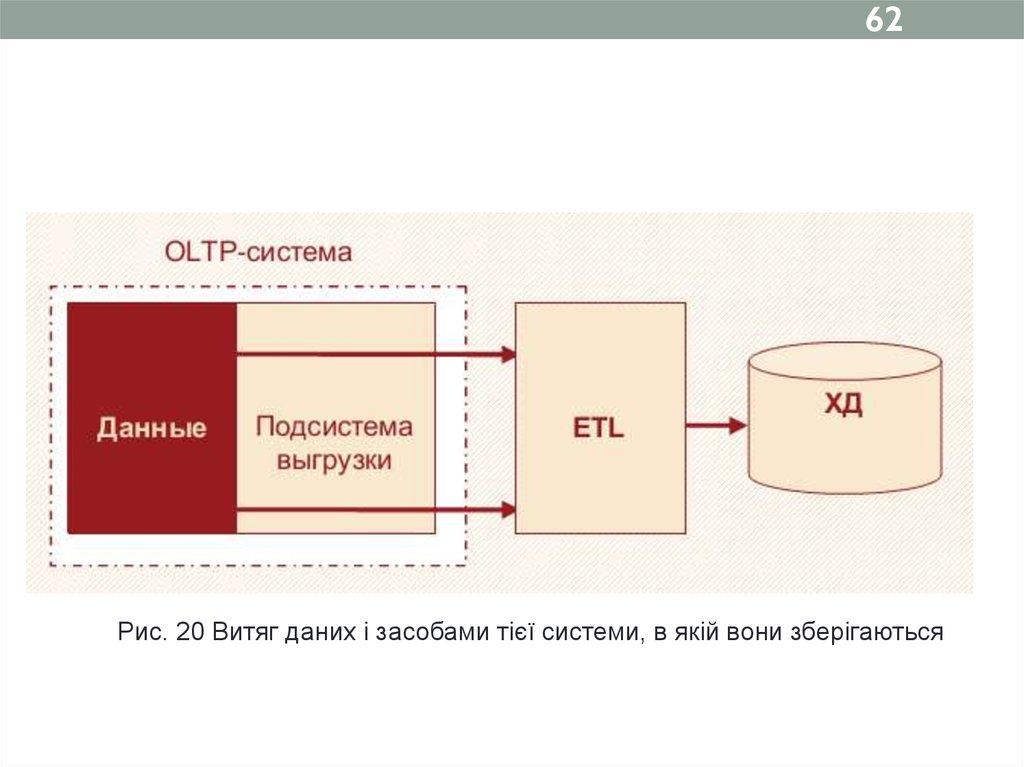
62.
62Рис. 20 Витяг даних і засобами тієї системи, в якій вони зберігаються
63.
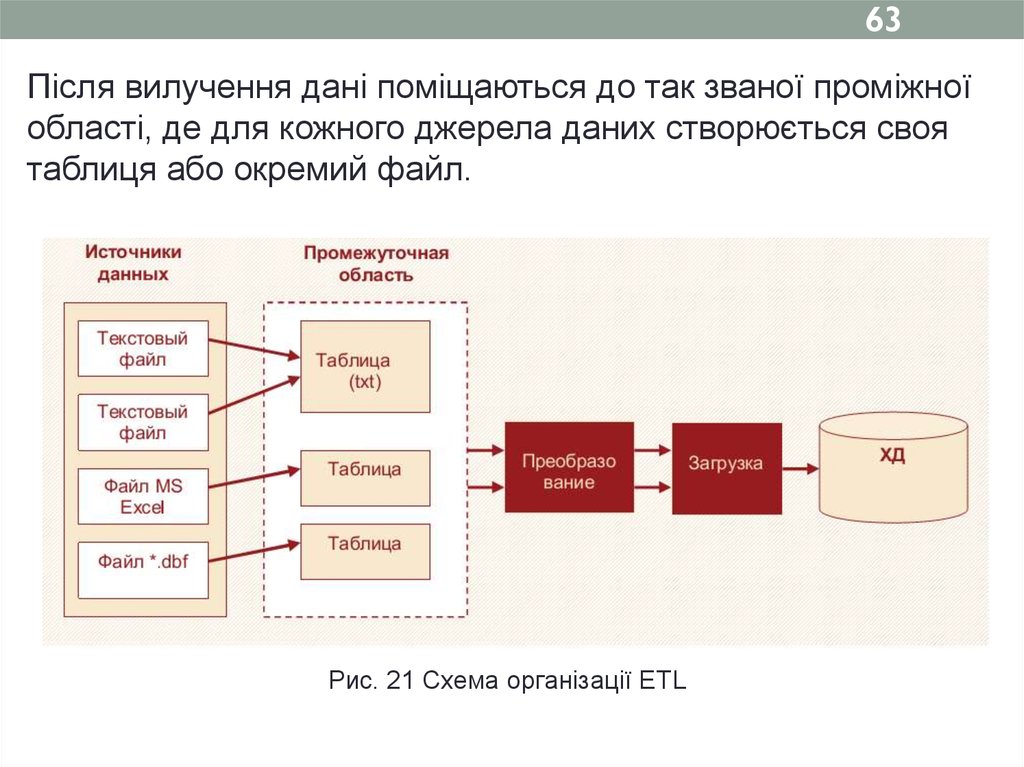
63Після вилучення дані поміщаються до так званої проміжної
області, де для кожного джерела даних створюється своя
таблиця або окремий файл.
Рис. 21 Схема організації ETL
64.
648.3 Вибір джерел даних, що використовуються
Всі джерела можна розділити на дві групи - розташовані
в корпоративних інформаційних системах та на
локальних комп'ютерах окремих користувачів
При виборі джерел даних для завантаження в СД
необхідно враховувати наступні фактори:
- значимість даних з точки зору аналізу;
- складність отримання даних із джерел;
- можливе порушення цілісності та достовірності
даних;
- обсяг даних у джерелі.
65.
658.4 Особливості організації процесу вилучення даних
Приклад_______________________________________________________
Легко уявити, що відвідувач супермаркету зайшов туди раптово: не для купівлі
товару, а щоб перечекати дощ, зустрітися з кимось, допомогти донести сумки і
т. ін. При цьому він купує коробку сірників, авторучку або іншу дрібницю, яку
міг купити і в звичайному вуличному лотку. Однак навіть для сірникової
коробки пробивається чек і створюється відповідний запис у системі
реєстрації. І запис про купівлю сірникової коробки за 50 коп. вимагає місця на
диску або в пам'яті не менше, ніж про продаж пляшки коньяку за 1000 руб. В
результаті після агрегування даних про продажі за день по відділу
з'ясовується, що зареєстровано 100 продажів, які дали в сумі 300 руб., і 10
продажів на загальну суму 15 000 руб. Виникає питання: чи потрібно витрачати
час на обробку та зберігання величезної кількості записів, внесок яких в
результат аналізу буде мізерний. Більш того, включення в аналіз інформації
щодо дрібних покупок, зроблених випадковими клієнтами, може тільки
перешкодити, наприклад, побудові моделі поведінки постійних клієнтів. Тому
аналітик може задати умову, що вилучатись повинні лише ті записи, у яких
значення поля «Сума» не менше 20 руб.
_______________________________________________________________
66.
66Інший важливий момент - визначення глибини
вивантаження даних по часу при первинному заповненні
сховища
8.5 Особливості вилучення даних з різних типів
джерел
Можна виділити три різновиди джерел даних, з
якими
найчастіше
стикаються
організатори
аналітичних проектів:
- Файли СУБД (SQL Server Oracle, Firebird, Accessі т. ін.)
67.
67- Структуровані файли різних форматів. До таких
джерел відносяться текстові файли з роздільниками,
файли електронних таблиць (наприклад, Excel, CSVфайли, HTML-документи і т. ін.
-
Неструктуровані джерела.
68.
689 Очищення даних у ETL
9.1 Два рівня очищення даних
9.2 Критерії оцінки якості даних
9.3 Основні види проблем у даних, через які вони
потребують очищення
69.
699 Очищення даних у ETL
9.1 Два рівня очищення даних
Первинне очищення даних виконується на етапі ETL.
Його основне завдання – підготувати дані до
завантаження в сховище.
Вторинне очищення в аналітичній системі є
користувальницьким, воно спрямоване на підготовку
даних до вирішення конкретної аналітичної задачі.
70.
709.2 Критерії оцінки якості даних
Основний критерій - критичність помилок
Три категорії помилок:
– дані високої якості, що не потребують очищення;
– дані, що містять критичні помилки, через які вони
в принципі не можуть бути завантажені до СД;
– дані, що містять некритичні помилки, які не
заважають їх завантаженні в CД, але при цьому дані є
некоректними з точки зору їх аналізу (аномальні
значення, пропуски, дублікати, протиріччя і т. ін.).
71.
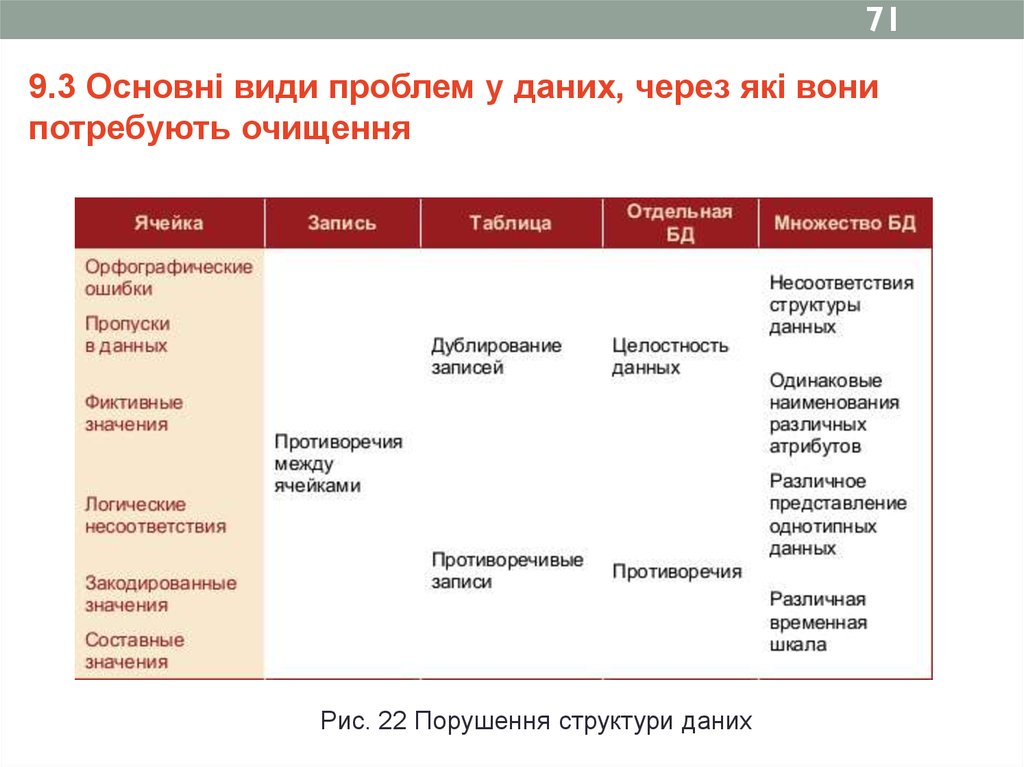
719.3 Основні види проблем у даних, через які вони
потребують очищення
Рис. 22 Порушення структури даних
72.
7210 Перетворення даних у ETL
10.1 Перетворення структури даних
10.2 Агрегування даних
10.3 Переклад значень
10.4 Створення нових даних
10.5 Очищення даних
10.6 Вибір місця для виконання перетворення даних
73.
7310 Перетворення даних у ETL
10.1 Перетворення структури даних
Мета перетворення даних – підготовка даних до
розміщення у СД і приведення їх до вигляду, найбільш
зручному для подальшого аналізу.
Рис. 23 Етапи процесу перетворення даних у ETL
74.
74У багатьох випадках витягнуті дані непридатні до
безпосереднього завантаження в СД через відмінності
їх структури від структури відповідних цільових таблиць
СД.
При цьому таблиці фактів найчастіше відповідають
вимогам СД, але таблиці вимірювань потребують
додаткової обробки і можуть бути об'єднанні.
Приклад. Додаткова обробка структури даних потрібна в
ситуації, коли один підрозділ фірми надає інформацію про
ціну і кількість проданих товарів, а інший – про
кількість товарів і загальну суму продажів. У такому
випадку потрібно навести інформацію щодо продажів,
отриману з обох джерел, до загального вигляду.
75.
7510.2 Агрегування даних
Для
достовірного
опису
предметної
області
використання
даних
з
максимальним
рівнем
деталізації не завжди доцільно, тому найбільший
інтерес для аналізу представляють дані, узагальнені по
деякому інтервалу часу, по групі клієнтів, товарів і т. ін.
Такі узагальнені дані називаються агрегованими (іноді,
агрегатами), а сам процес їх обчислення агрегуванням.
76.
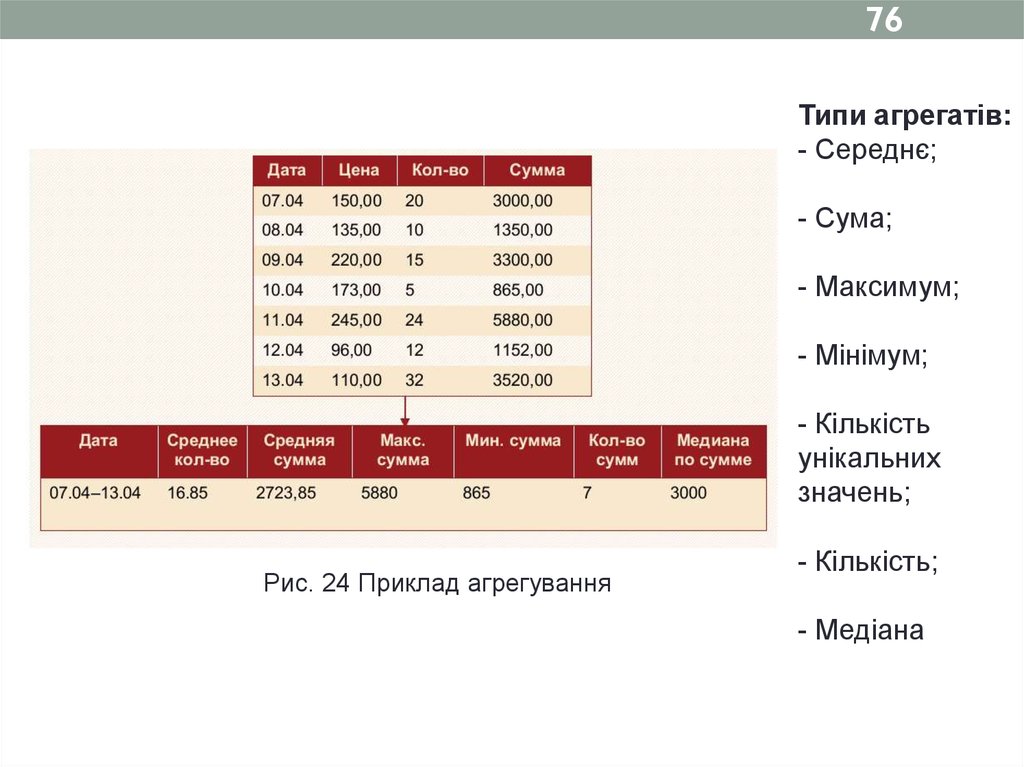
76Типи агрегатів:
- Середнє;
- Сума;
- Максимум;
- Мінімум;
- Кількість
унікальних
значень;
Рис. 24 Приклад агрегування
- Кількість;
- Медіана
77.
7710.3 Переклад значень
Приклад. Згідно заведеному в організації порядку
ідентифікаційний номер операції може бути закодований
у вигляді 06-04-12-62, де 06-04 - число і місяць, 12 - код
товару, 62 - код регіону. Таке подання дозволяє зберігати
дані дуже компактно. Однак для заповнення відповідних
вимірювань у багатовимірної моделі запис необхідно
декодувати.
Крім того, часто виникає необхідність конвертувати
числові дані, наприклад перетворити дійсні у цілі,
зменшити надлишкову точність представлення чисел,
використовувати експонентний формат і т. ін.
78.
7810.4 Створення нових даних
Приклад. OLTP-система містить інформацію тільки про
кількість і ціну проданого товару, а в цільовій таблиці
СД є поле “Сума”. Тоді в процесі перетворення необхідно
обчислити суму як добуток ціни на кількість проданих
одиниць товару. Таким чином, буде створено поле, що
містить нову інформацію.
79.
7910.5 Очищення даних
Очищення – процедура коригування даних, які в будьякому сенсі не задовольняють визначеним критеріям
якості, тобто містять порушення структури даних,
протиріччя, пропуски, дублікати, неправильні формати і т.
ін.
80.
8010.6 Вибір місця для виконання перетворення даних
Можливі варіанти:
- Перетворення в процесі вилучення даних. На даному етапі
найкраще
виконувати перетворення типів даних і здійснювати фільтрацію записів,
котрі представляють інтерес для СД. В ідеальному випадку повинні
відбиратися тільки ті записи, які змінювалися або створювалися після
минулого завантаження. Недолік - підвищення навантаження на OLTPсистему або БД.
- Перетворення в проміжній області перед завантаженням даних до
СД - найкращий варіант для інтеграції даних з багатьох джерел, оскільки
в процесі добування даних, очевидно, цього зробити не можна. У проміжній
області доцільно виконувати такі види перетворень, як сортування,
групування, обробка часових рядів і т. ін.
- Перетворення в процесі завантаження даних в СД. Окремі прості
перетворення, наприклад перетворення регістрів букв в текстових полях,
можуть бути виконані тільки після завантаження даних в сховище.
81.
8111 Завантаження даних у сховище
11.1 Організація процесу завантаження
11.2 Неповне завантаження даних
11.3 Багатопотокова організація процесу
завантаження даних
11.4 Операції після операції завантаження
82.
8211 Завантаження даних у сховище
Процес завантаження полягає в перенесенні даних з
проміжних таблиць до структури сховища даних
11.1 Організація процесу завантаження
Першими в процесі завантаження даних до СД зазвичай
завантажуються таблиці вимірювань, які містять
сурогатні ключі та іншу описову інформацію, необхідну
для таблиць фактів.
При завантаженні таблиць вимірів потрібно і додавати нові
записи, і змінювати існуючі.
83.
8311.2 Неповне завантаження даних
Не завжди дані завантажуються повністю: в завантаженні
деяких записів може бути відмовлено. Причини:
-На етапі перетворення даних не вдалося виправити всі
критичні помилки, які блокують завантаження записів у СД.
-Некоректний порядок завантаження даних. Наприклад,
робиться спроба завантажити факти для значення
вимірювання, яке ще не було завантажено. Причиною цього
є неправильна разработка ETL-процесу.
- Внутрішні проблеми СД, наприклад недолік місця в
ньому.
- Переривання процесу завантаження або зупинка його
користувачем.
84.
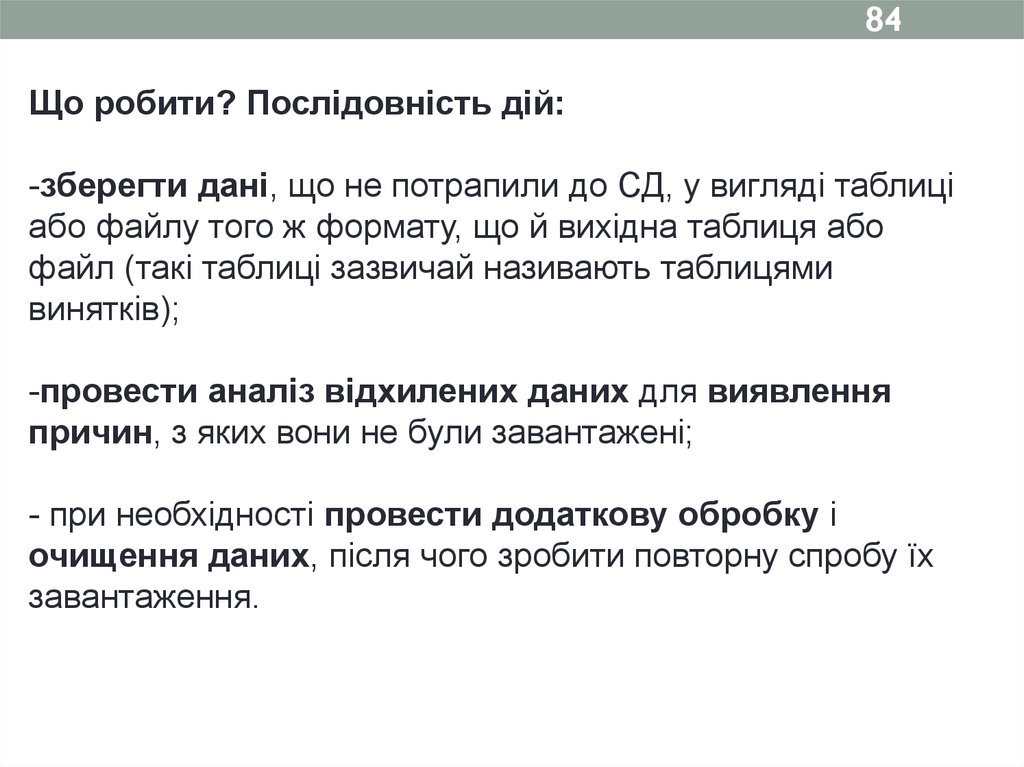
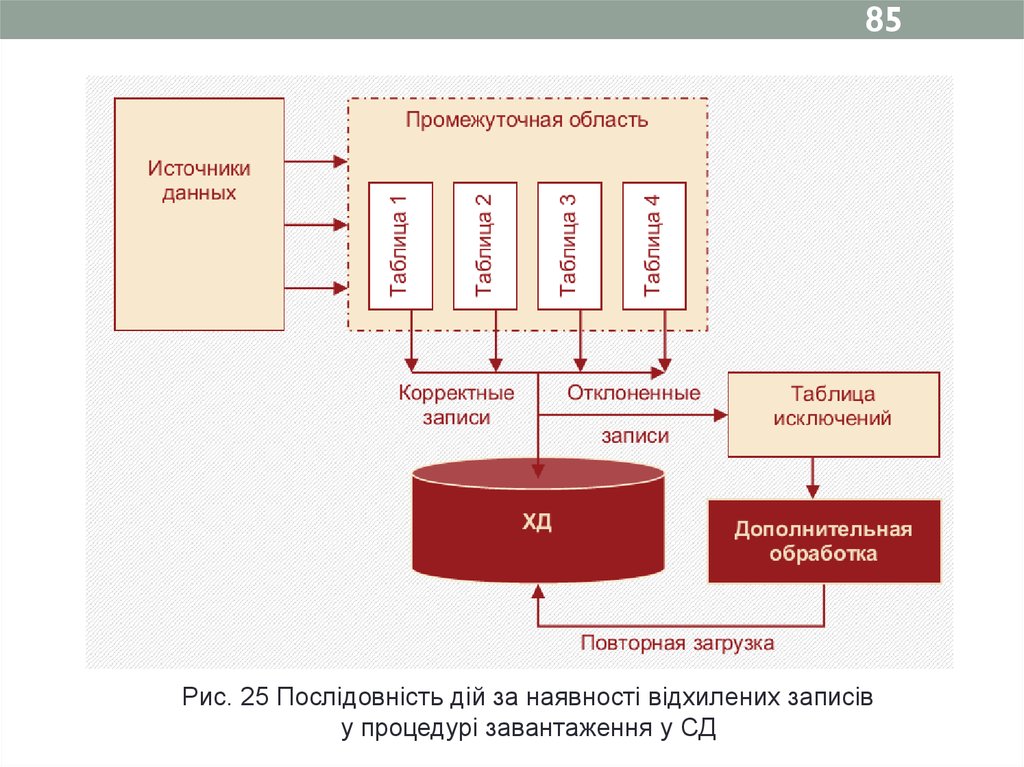
84Що робити? Послідовність дій:
-зберегти дані, що не потрапили до СД, у вигляді таблиці
або файлу того ж формату, що й вихідна таблиця або
файл (такі таблиці зазвичай називають таблицями
винятків);
-провести аналіз відхилених даних для виявлення
причин, з яких вони не були завантажені;
- при необхідності провести додаткову обробку і
очищення даних, після чого зробити повторну спробу їх
завантаження.
85.
85Рис. 25 Послідовність дій за наявності відхилених записів
у процедурі завантаження у СД
86.
86Що робити у разі повторної невдачі?
-відновити стан сховища, яким воно було до
завантаження (наприклад, за допомогою резервної копії);
- повністю очистити у СД таблиці з неповними даними,
щоб виключити некоректні результати їх аналізу;
- залишити все як є і повідомити користувача про
виниклі проблеми. У цьому випадку аналітик буде знати,
що завантажена інформація недостовірна і буде
використовувати її з певними обмеженнями.
87.
8711.3 Багатопотокова організація процесу завантаження
даних
При черговому завантаженні у СД переноситься не вся
інформація із OLTP-системи, а тільки та, яка була змінена
протягом проміжку часу, що пройшов з попередньою
завантаження.
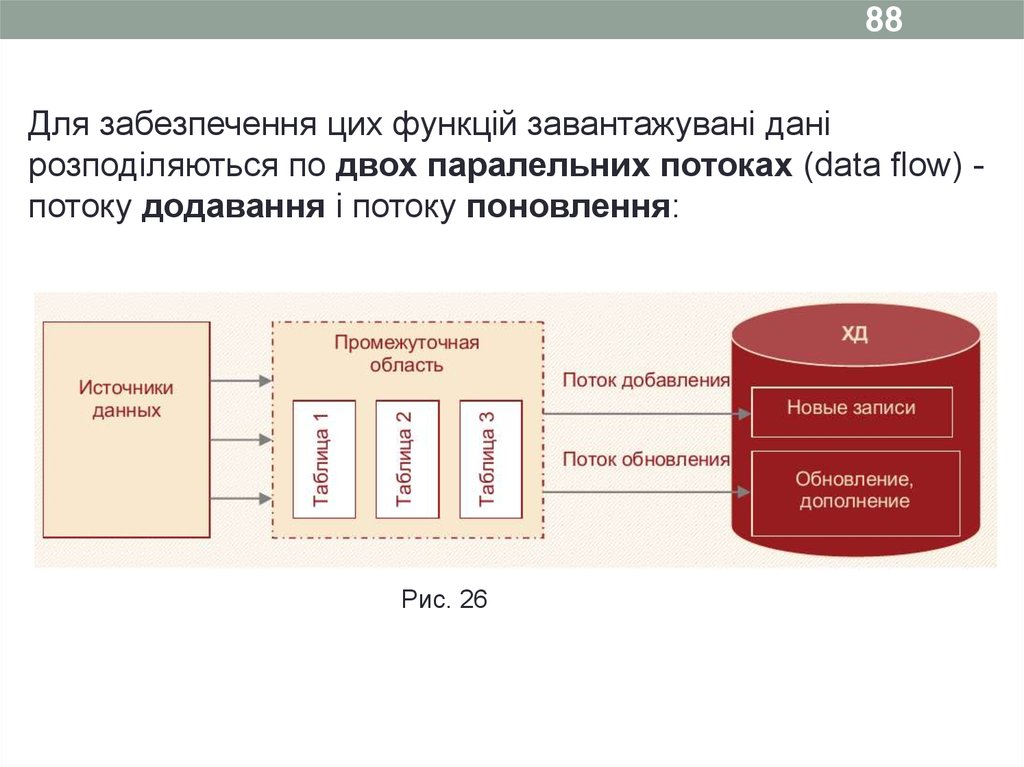
При цьому можна виділити два види змін - додавання й
оновлення (доповнення).
- Додавання - у СД передається нова інформація,
наприклад відомості про продажі, що відбулися з минулої
завантаження, про появу нового клієнта, товару і т. д.
- Оновлення (доповнення) - у СД передається інформація,
яка існувала раніше, але з якоїсь причини була змінена
або доповнена (наприклад, змінилось місто, в якому живе
клієнт).
88.
88Для забезпечення цих функцій завантажувані дані
розподіляються по двох паралельних потоках (data flow) потоку додавання і потоку поновлення:
Рис. 26
89.
8911.4 Операції після операції завантаження
З точки зору аналітика, найбільш важливим завданням є верифікація даних.
Перш ніж використовувати нові дані для аналізу, корисно переконатися в їх
надійності та достовірності. Комплекс верифікаційних тестів:
- при підсумовуванні продажів по одному вимірюванню результат повинен
співпадати з відповідною сумою, отриманою по іншому, пов'язаному з ним
вимірюванню, тобто сума продажів по всіх товарах за місяць повинна
відповідати сумі угод, укладених з усіма клієнтами за той же період;
- підсумковий показник за місяць повинен відповідати сумі щоденних або
щотижневих показників у цьому місяці;
- сумарна виручка по всіх регіонах за поточний місяць повинна відповідати сумі
продажів по всім регіональним дилерським центрам.
90.
90Крім того, може виявитися корисним порівнювати дані
не тільки в різних розрізах після їх завантаження у СД, але
і з джерелами даних.
Так, якщо значення будь-якого показника в джерелі і
сховище рівні, то все нормально, в іншому випадку дані,
можливо, є некоректними.
До аналізу нової інформації можна приступати тільки,
якщо дані у СД завантажені корректно.
91.
9112 Завантаження даних з локальних джерел
12.1 Переваги та недоліки відмови від сховищ даних
12.2 Проблеми, що виникають при прямому доступі до
джерел даних
12.3 Переваги використання безпосереднього доступу
до джерел даних
12.4 Особливості безпосереднього завантаження
даних з найбільш поширених типів джерел
92.
9212 Завантаження даних з локальних джерел
Це може знадобитися в разі, коли:
-організація відмовилася від використання СД або
- коли сховище мається, але дані з деяких джерел не
можуть бути в нього завантажені з технічних причин,
через невідповідність моделям і форматам даних,
використовуваним у СД.
93.
93Частина даних поступає в аналітичну систему через СД з
відповідною очісткою і підготовкою, а решта - безпосередньо
з джерел:
Рис. 27
94.
9412.1 Переваги та недоліки відмови від сховищ даних
Головна перевага використання СД в аналітичних
технологіях - підвищення ефективності та достовірності
аналізу даних, особливо для підтримки прийняття
стратегічних рішень.
95.
95Можливі причини відмови від використання СД:
1 Організація не має достатніх ресурсів (фінансових, технічних,
кадрових) для розробки, придбання та підтримки СД.
2 Успадкована система аналітичної обробки ефективно функціонує з
використанням звичайної реляційної СУБД, і керівництво не бачить
сенсу в дорогому і трудомісткому процесі впровадження СД.
3 Обсяг аналізованих даних невеликий, а застосовувані технології
аналізу даних нескладні. Зокрема, не потрібна підтримка хронології
даних, для аналізу використовуються тільки дані за певний період і т. ін.
4 Роль аналізу в діяльності організації невисока, адміністрація не
усвідомила його значимість в отриманні конкурентних переваг.
96.
9612.2 Проблеми, що виникають при прямому доступі
до джерел даних
- Необхідність самостійно визначати тип і формат джерела даних;
- Відсутність повноцінного семантичного шару того рівня, який є в СД;
- Відсутність жорсткої підтримки структури і форматів даних:
Рис. 28
97.
97-Відсутність автоматичних засобів підтримки цілісності,
несуперечності і унікальності даних (при роботі з локальними
файлами);
- Відсутність автоматичних засобів підтримки цілісності,
несуперечності і унікальності даних;
- Необходимость настройки механизмов доступа к источникам
данных.
(Для здійснення безпосереднього доступу до різних джерел даних
зазвичай використовуються стандартні механізми доступу - ODBC,
ADO іOLE DB. Щоб зазначені компоненти функціонували правильно,
вони повинні бути відповідним чином налаштовані, що також часто
лягає на плечі користувача або системного адміністратора.)
98.
9812.3 Переваги використання безпосереднього доступу
до джерел даних
- Відсутність ETL-процесу знімає проблему «вікна завантаження».
-Можливість внерегламентного використання джерел даних.
- Можливість отримувати для аналізу дані, які чомусь не потрапили в
сховище (наприклад, з технічних причин як не представляють цінності).
Крім того, у співробітників організацій часто накопичуються дані, зібрані ними для
власного використання.
- Користувач має можливість працювати з даними в їх «первозданному»
вигляді, що становить особливий інтерес, оскільки при завантаженні даних у СД в
них вносяться зміни, які в деяких випадках впливають на їх початковий зміст.
99.
9912.4 Особливості безпосереднього завантаження даних
з найбільш поширених типів джерел
Джерела, що найбільш часто зустрічаються, доступ до яких проводиться
безпосередньо:
-текстові файли з роздільниками (TXT, CSV);
-файли електронних таблиць Excel;
-файли плоских таблиць БД, наприклад dBase, FoxProі т.д. (DBF файли);
- реляційні СУБД настільного рівня, наприклад Access і т. ін.;
- корпоративні бази даних і облікові системи (Oracle, Informix, Sybase,
DB2 і т. ін.)
100.
10013 Збагачення даних
13.1 Дані і інформація
13.2 Необхідність збагачення даних
101.
10113 Збагачення даних
13.1 Дані і інформація
Інформація - це не будь-які дані, а тільки ті, які відповідним чином
представлені і впорядковані, тобто мають структурні закономірності, які,
крім усього іншого, повинні розпізнаватися і осмислюватися користувачем.
Дані - поняття об'єктивне. Вони або реально існують як зміни деякого
фізичного процесу, або ні. А інформація в більшості випадків суб'єктивна.
102.
102Приступаючи до аналізу даних з метою пошуку прихованих
закономірностей і вилучення знань, ми повинні задатися низкою
запитань:
-Чи мають ці дані взагалі якийсь сенс? Чи присутня в них будь-яка
інформація?
-Якщо так, то наскільки ця інформація надійна і достовірна?
- Чи достатньо цієї інформації для генерування надійних і
достовірних знань, на основі яких можна приймати відповідальні
управлінські рішення?
103.
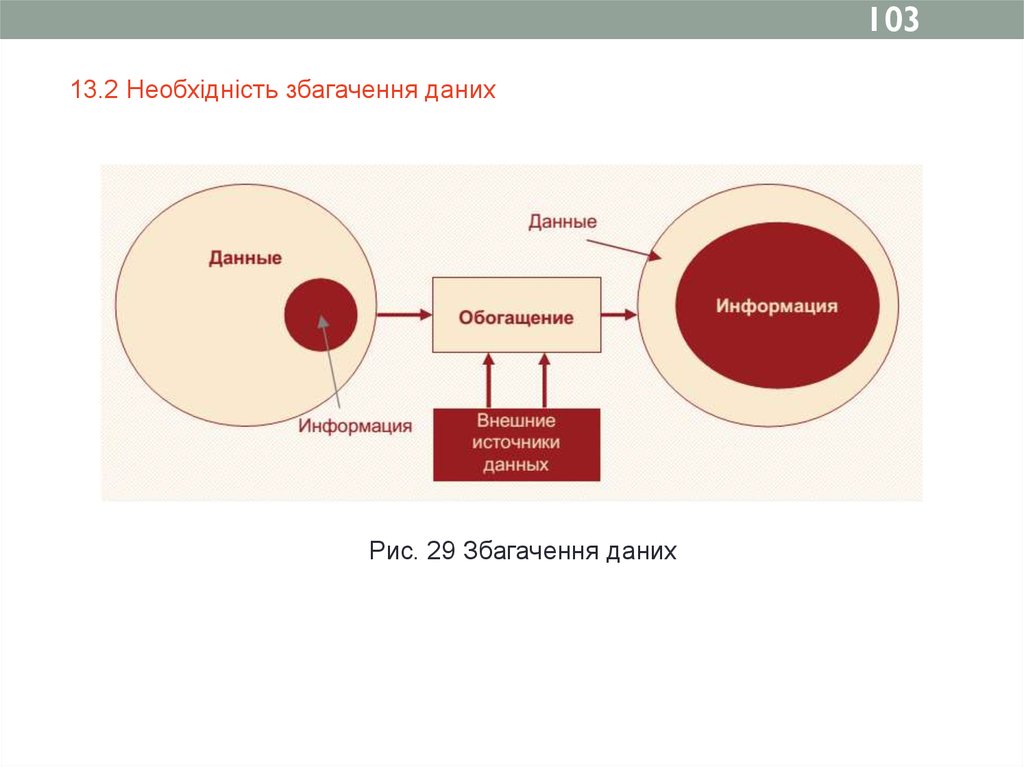
10313.2 Необхідність збагачення даних
Рис. 29 Збагачення даних
104.
104Визначення.
Збагачення даних - процес насичення даних новою інформацією, яка
дозволяє зробити їх більш цінними і значущими з точки зору
вирішення тієї чи іншої аналітичної задачі.
Можна виділити два основні методи збагачення даних
- зовнішнє і внутрішнє.
105.
105Зовнішнє збагачення припускає залучення додаткової інформації із
зовнішніх джерел, що дозволить підвищити цінність і значимість даних з точки
зору їх аналізу.
Під підвищенням значущості даних мається на увазі, що на основі їх аналізу
можна буде приймати управлінські рішення принципово нового рівня.
Зовнішніми джерелами можуть бути:
-Інші підприємства та організації, що працюють у цій же сфері діяльності або
в суміжних сферах, причому як партнери, так і конкуренти;
-Фінансово-кредитні установи, банки, страхові компанії;
-Державні податкові та статистичні служби;
-Органи державного та муніципального управління;
- Різні служби соціальної сфери: міграційна служба, органи праці та
зайнятості, система охорони здоров'я, пенсійні фонди і т. д.
106.
106Внутрішнє збагачення не припускає залучення зовнішньої
інформації. У цьому випадку підвищення інформативності й
значимості даних може бути досягнуто за рахунок зміни їх організації.
Внутрішнє збагачення зазвичай пов'язане з отриманням і
включенням в набір даних корисної інформації, яка відсутня в
явному вигляді, але може бути тим чи іншим способом отримана за
допомогою маніпуляцій з наявними даними. Потім ця інформація
вбудовується у вигляді нових полів або навіть таблиць в ХД і може
бути використана для подальшого аналізу. Для збагачення даних
також може використовуватися інформація, отримана в процесі їх
аналізу.
107. Дякую за увагу!
107Дякую за увагу!