






SelfLens-Platforma-pro-osobni-zdravotni-analytiku-2-2
1.
SelfLens: Platforma pro osobní zdravotní analytikuSoukromí-orientovaná platforma pro Quantified Self analytiku, která přináší hloubkovou analýzu osobních zdravotních
dat s důrazem na ochranu soukromí a transparentní vysvětlování výsledků.
2.
ÚVODMotivace a výzva
Současná situace
Existující řešení pro osobní analytiku zdravotních dat nabízejí pouze fragmentované dashboardy s malou analytickou
hloubkou. Většina aplikací pracuje jako black-box – ukazují, co se stalo, ale nevysvětlují proč.
Cíl SelfLens
Posun od pouhé vizualizace ke skutečnému porozumění: Co spolu souvisí? Kde jsou anomálie? Měla moje intervence
skutečný efekt?
3.
CÍLE PRÁCEHlavní cíl a úkoly implementace
Navrhnout a implementovat webovou platformu pro agregaci osobních dat umožňující rigorózní analýzu v režimu n = 1 – kdy
pracujeme s jediným člověkem, málo událostmi, autokorelací a sezónností.
01
02
03
Ingest a normalizace dat
Pokročilá analytika
AI asistent
Import z Apple Health XML a vlastních
Analýza závislostí, detekce anomálií,
Vysvětlování výsledků při zachování
souborů s flexibilním mapováním
vyhodnocení experimentů a intervencí
soukromí uživatele
04
05
Interaktivní UI
Testování a optimalizace
Vizualizace časových řad, exporty a automatické reporty
Vyhodnocení trade-offů mezi výkonem, soukromím a užitečností
Kombinace robustní statistiky, časových řad a experimentálního designu zajišťuje spolehlivou interpretaci i při malých vzorcích dat.
4.
METODIKATeoretické základy n=1 analýzy
Hledání vztahů
Detekce anomálií
Vyhodnocení intervencí
Pearson, Spearman (lineární vs
Z-score, Rolling IQR, GESD
monotónní)
STL dekompozice
MIC pro nelineární závislosti
Isolation Forest, One-Class SVM
Effect size + 95% CI
Benjamini–Hochberg (FDR
Autoenkodér
korekce)
Severity skóre s CI-aware
Časové zpoždění (lag analýza)
Cohenovo d + confidence
intervaly
ITS: level_change, trend_change
SRM kontrola kvality
Varování na konfúze
hodnocením
Cílem není diagnóza, ale statisticky hygienická explorace dat. U n=1 je kritická pozornost k autokorelaci, trend
confounding a malým vzorkům.
5.
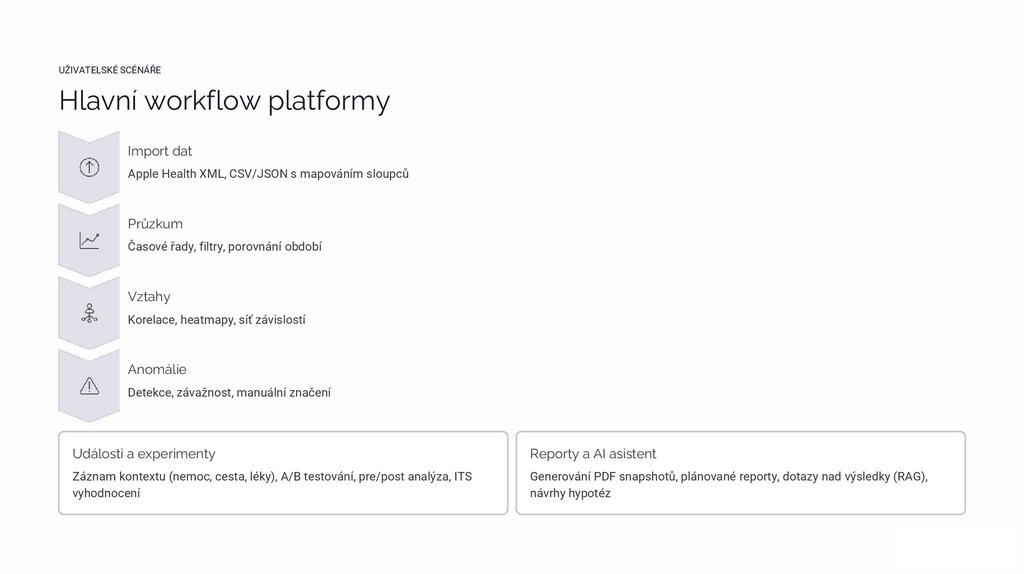
UŽIVATELSKÉ SCÉNÁŘEHlavní workflow platformy
Import dat
Apple Health XML, CSV/JSON s mapováním sloupců
Průzkum
Časové řady, filtry, porovnání období
Vztahy
Korelace, heatmapy, síť závislostí
Anomálie
Detekce, závažnost, manuální značení
Události a experimenty
Reporty a AI asistent
Záznam kontextu (nemoc, cesta, léky), A/B testování, pre/post analýza, ITS
vyhodnocení
Generování PDF snapshotů, plánované reporty, dotazy nad výsledky (RAG),
návrhy hypotéz
6.
DEMOVideo ukázka platformy
7.
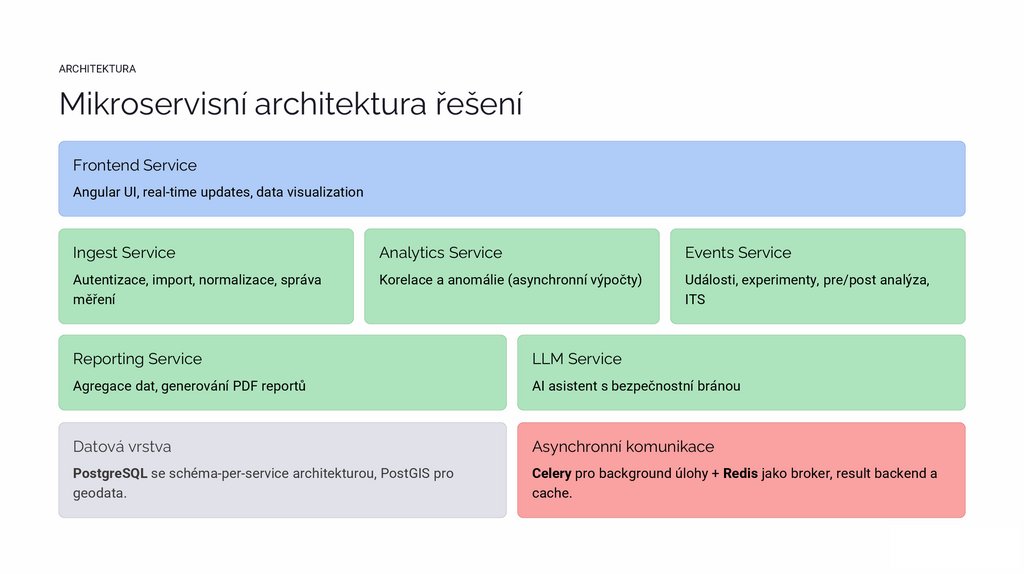
ARCHITEKTURAMikroservisní architektura řešení
Frontend Service
Angular UI, real-time updates, data visualization
Ingest Service
Analytics Service
Events Service
Autentizace, import, normalizace, správa
měření
Korelace a anomálie (asynchronní výpočty)
Události, experimenty, pre/post analýza,
ITS
Reporting Service
LLM Service
Agregace dat, generování PDF reportů
AI asistent s bezpečnostní bránou
Datová vrstva
Asynchronní komunikace
PostgreSQL se schéma-per-service architekturou, PostGIS pro
geodata.
Celery pro background úlohy + Redis jako broker, result backend a
cache.
8.
TECHNOLOGIETechnologický stack a jeho zdůvodnění
Backend
Databáze
Async & Cache
Frontend
Python 3.11 + FastAPI pro async
výkon a Pydantic validaci
PostgreSQL 16 s JSONB, GIN indexy,
PostGIS
Celery + Redis pro background jobs a
caching
Angular + TypeScript + Material +
ECharts
Data Science
Machine Learning
Privacy & Reports
Pandas, SciPy, Statsmodels, Minepy pro
korelace a ITS analýzy
Scikit-learn, PyTorch pro Isolation Forest a
autoenkodéry
spaCy (lokální NER), WeasyPrint + Jinja2 pro PDF
Proč FastAPI?
Proč PostgreSQL?
Proč ECharts?
Nativní async, typová validace, automatická
OpenAPI dokumentace a generace klienta
Kombinuje relační konzistenci s JSONB pro
semi-strukturovaná metadata bez další
NoSQL databáze
Vysoký výkon pro vykreslování desítek tisíc
datových bodů v canvasu
9.
VÝSLEDKYZhodnocení výsledků a budoucí směry
✅ Co se podařilo
Kompletní pipeline
End-to-end: ingest → analytika → UI → reporty → AI vysvětlení
⚠ Limity a zlepšení
Výpočetní náročnost
MIC a autoenkodéry vyžadují selektivní spouštění
Mikroservisní architektura
Jednotný async pattern zajišťuje responsivní SPA
Optimalizace výkonu
Streaming XML parser s O(1) pamětí, bulk insert řádově
rychlejší
Privacy-aware AI
Minimalizace kontextu, sanitizace, cache odpovědí
Budoucí vylepšení
Agentnější asistent (spouštění výpočtů dle dotazu)
Více integrací (Fitbit, Garmin, Google Fit)
Keycloak pro SSO/MFA v self-hosted režimu
10.
Děkuji za pozornost11.
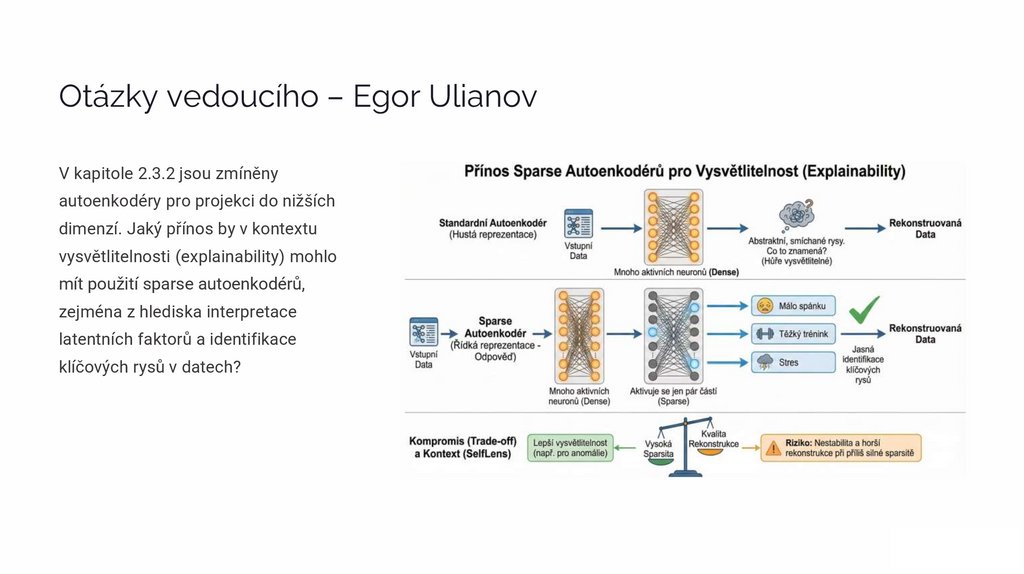
Otázky vedoucího – Egor UlianovV kapitole 2.3.2 jsou zmíněny
autoenkodéry pro projekci do nižších
dimenzí. Jaký přínos by v kontextu
vysvětlitelnosti (explainability) mohlo
mít použití sparse autoenkodérů,
zejména z hlediska interpretace
latentních faktorů a identifikace
klíčových rysů v datech?