






 функций:")











 database
databaseSimilar presentations:










Технологии распределенных баз данных (тема 12)
1. Тема 12. Технологии распределенных баз данных
2. Основные условия и требования к распределенной обработке данных
1) прозрачность относительно расположения данных:СУБД должна представлять все данные так, как если бы они
были локальными;
2) гетерогенность системы - СУБД должна работать с
данными, которые хранятся в системах с различной
архитектурой и производительностью (независимость от СУБД);
3) прозрачность
относительно
сети:
СУБД
одинаково работать в условиях разнородных сетей;
4) поддержка
распределенных
должна
запросов:
пользователь должен иметь возможность объединять данные
из любых баз, даже если они размещены в разных системах;
3. Основные условия и требования к распределенной обработке данных
5) поддержкараспределенных
изменений:
пользователь должен иметь возможность изменять данные в
любых базах, на доступ к которым у него есть права, даже если
эти базы размещены в разных системах;
6) поддержка распределенных транзакций: СУБД
должна выполнять транзакции, выходящие за рамки одной
вычислительной системы,
и
поддерживать целостность
распределенной
БД даже при возникновении отказов как в
отдельных системах, так и в сети;
7) безопасность: СУБД должна обеспечивать защиту всей
распределенной БД от несанкционированного доступа;
8) универсальность доступа: СУБД должна обеспечивать
единую методику доступа ко всем данным.
4. Проблемы распределенной обработки данных
низкая и несбалансированная производительностьсетей передачи данных, что в распределенных транзакциях
сильно снижает общую производительность обработки;
обеспечение целостности данных в распределенных
транзакциях базируется на принципе «все или ничего»,
и требует специального протокола двухфазного завершения
транзакций, что приводит к длительной блокировке
изменяемых данных;
необходимо обеспечить совместимость данных
стандартного типа, для хранения которых в разных системах
используются разные физические форматы и кодировки;
5. Проблемы распределенной обработки данных
• выбор схемы размещения системных каталогов. Есликаталог будет храниться в одной системе, то удаленный доступ
будет замедлен. Если будет размножен — изменения придется
распространять и синхронизировать;
необходимо обеспечить совместимость СУБД разных
типов и поставщиков;
увеличение
потребностей
в
ресурсах
для
координации работы приложений с целью обнаружения и
устранения
транзакциях.
тупиковых
ситуаций
в
распределенных
6. Классфикация режимов работы с БД
В общем случае режимы работы склассифицировать по следующим признакам:
1.
Многозадачность:
однопользовательский;
многопользовательский;
2.
Правило обслуживания запросов:
последовательное;
параллельное;
3.
Схема размещения данных:
централизованная;
распределенная БД.
БД
можно
7. Классфикация режимов работы с БД
1.Системы
2.
Системы
распределенной
обработки
данных
отражают структуру и свойства многопользовательских
операционных систем с базой данных, размещенной на
большом центральном компьютере (мэйнфрейме). Клиентские
места - терминалы или мини-ЭВМ, обеспечивающие вводвывод данных и не имеющие собственных вычислительных
ресурсов для функционально-ориентированной обработки
получаемых данных.
распределенных
баз
данных
обеспечивают обработку распределенных запросов, когда при
обработке одного запроса используются ресурсы базы,
размещенные на различных ЭВМ сети. Состоит из узлов,
каждый из которых является СУБД, а узлы взаимодействуют
между собой так, что база данных любого узла будет доступна
пользователю, как если бы она была локальной.
8. Для «типового» приложения обработки данных можно выделить следующие группы (уровни) функций:
ввод и отображение данных: внешний (пользовательский)
уровень реализации целевой функциональной обработки и
представления (Presentation logic);
функциональная обработка, реализующая алгоритм
решения задач пользователя. Соответствующие «бизнес-правила»
реализуются обычно средствами
высокоуровневого языка
программирования или расширенного языка манипулирования
данными типа ADABAS Natural или 4-GL (Business logic);
манипулирование данными БД в рамках приложения,
которое обычно реализуется средствами SQL (Database logic);
управление данными и другими ресурсами БД,
реализуемое специализированными (внутренними) средствами
конкретной СУБД обычно в рамках файловой системы ОС;
управление процессами обработки: связывание и
синхронизация процессов обработки данных разного уровня.
9.
ОпределенияМодели
клиент-сервер
-
это
технология
взаимодействия
в
информационной сети.
Сервер обладает правом управления тем или иным ресурсом, а
клиент – пользования им. Каждый конкретный сервер определяется
видом того ресурса, которым он владеет.
10.
ОпределенияРазделение процесса выполнения запроса на «клиентскую» и
«серверную» компоненту позволяет:
различным прикладным (клиентским) программам
одновременно использовать общую базу данных;
• централизовать функции управления, такие, как
защита информации, обеспечение целостности данных,
управление совместным использованием ресурсов;
• обеспечивать параллельную обработку запроса в
случае распределенных БД;
• высвобождать ресурсы рабочих станций и сети;
• повышать эффективность управления данными за
счет использования ЭВМ, специально разработанных для
работы СУБД (серверы баз данных и машины баз данных).
11.
ОпределенияФункции стандартного интерактивного приложения :
•Функции ввода и отображения данных.
•Прикладные функции, характерные для данной предметной области.
хранения
и
управления
информационновычислительными ресурсами (базами данных, файловыми
•Функции
системами и т.д.).
•Служебные функции, осуществляющие связь между функциями
первых трех групп.
12.
ОпределенияЛогические компоненты приложения:
•компонент представления (presentation), реализующий функции
первой группы;
•прикладной компонент (business application), поддерживающий
функции второй группы;
•компонент доступа к информационным ресурсам (resource
manager), поддерживающий функции третьей группы, а также
вводятся и уточняются соглашения о способах их взаимодействия
(протокол взаимодействия).
13.
Модели распределенной обработки•модель файлового сервера (File Server - FS);
•модель доступа к удаленным данным (Remote Data Access - RDA);
•модель сервера баз данных (Data Base Server - DBS);
•модель сервера приложений (Application Server - AS).
14.
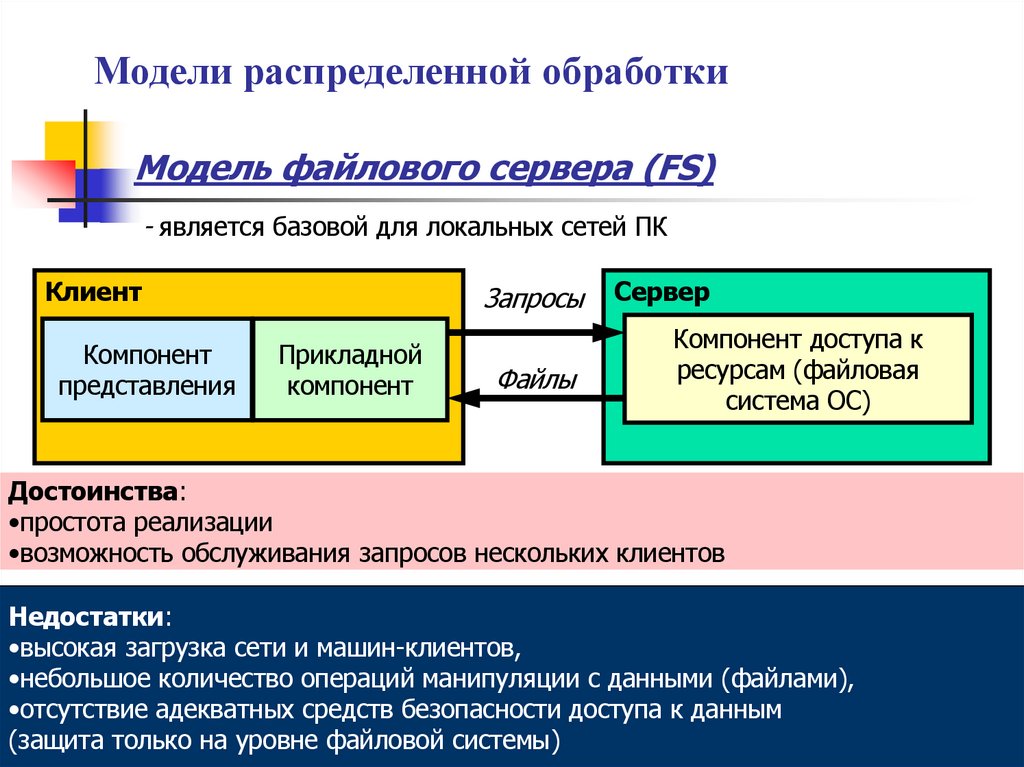
Модели распределенной обработкиМодель файлового сервера (FS)
- является базовой для локальных сетей ПК
Клиент
Компонент
представления
Запросы
Прикладной
компонент
Файлы
Сервер
Компонент доступа к
ресурсам (файловая
система ОС)
Достоинства:
•простота реализации
•возможность обслуживания запросов нескольких клиентов
Недостатки:
•высокая загрузка сети и машин-клиентов,
•небольшое количество операций манипуляции с данными (файлами),
•отсутствие адекватных средств безопасности доступа к данным
(защита только на уровне файловой системы)
15.
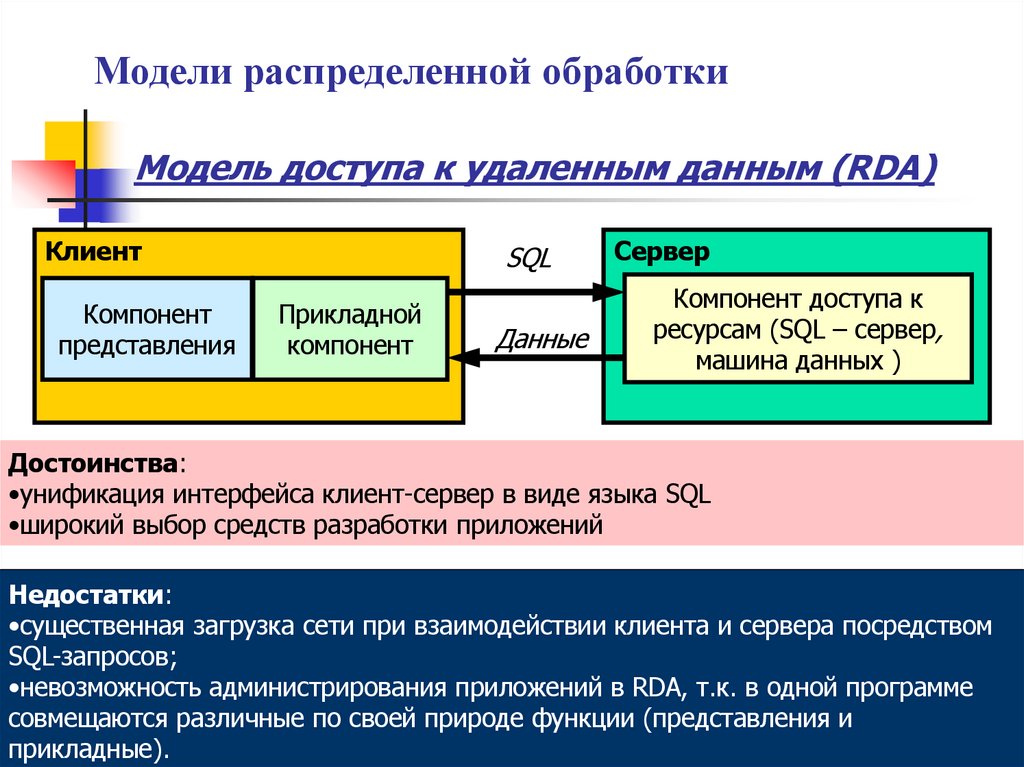
Модели распределенной обработкиМодель доступа к удаленным данным (RDA)
Клиент
Компонент
представления
SQL
Прикладной
компонент
Данные
Сервер
Компонент доступа к
ресурсам (SQL – сервер,
машина данных )
Достоинства:
•унификация интерфейса клиент-сервер в виде языка SQL
•широкий выбор средств разработки приложений
Недостатки:
•существенная загрузка сети при взаимодействии клиента и сервера посредством
SQL-запросов;
•невозможность администрирования приложений в RDA, т.к. в одной программе
совмещаются различные по своей природе функции (представления и
прикладные).
16.
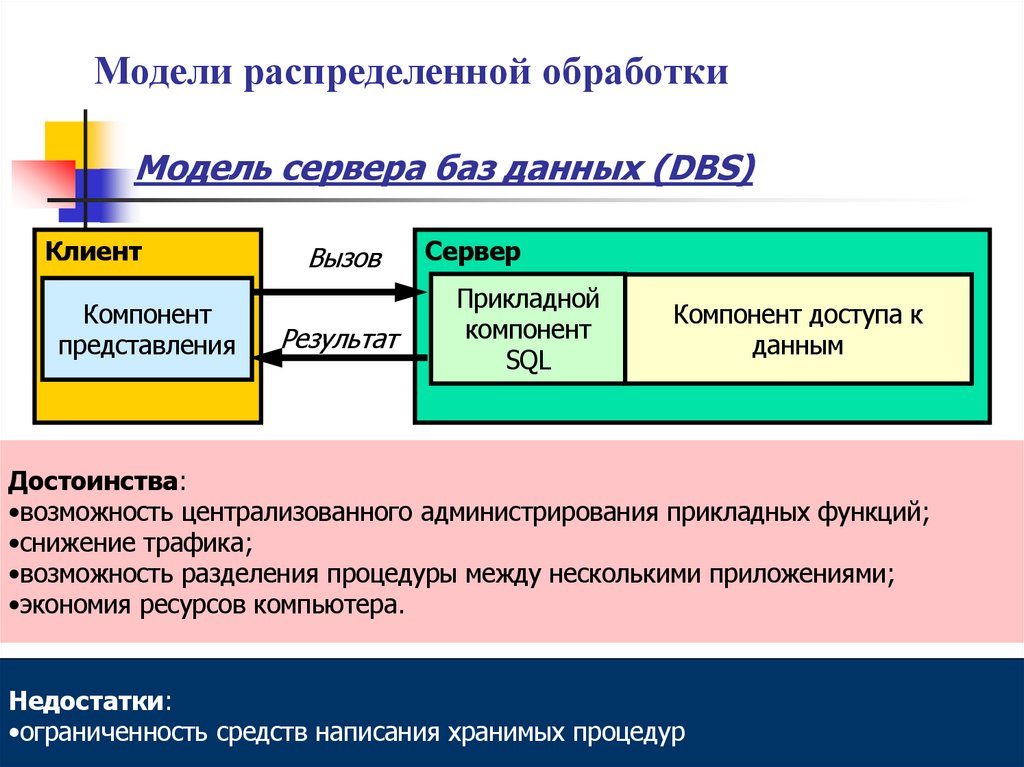
Модели распределенной обработкиМодель сервера баз данных (DBS)
Клиент
Компонент
представления
Вызов
Результат
Сервер
Прикладной
компонент
SQL
Компонент доступа к
данным
Достоинства:
•возможность централизованного администрирования прикладных функций;
•снижение трафика;
•возможность разделения процедуры между несколькими приложениями;
•экономия ресурсов компьютера.
Недостатки:
•ограниченность средств написания хранимых процедур
17.
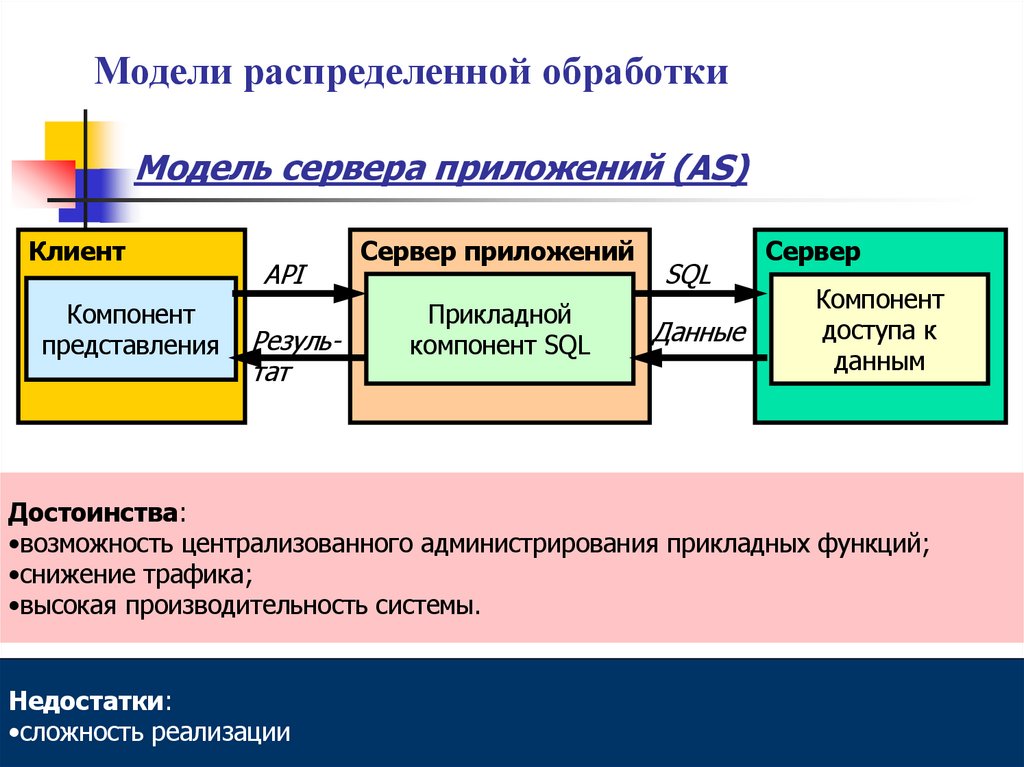
Модели распределенной обработкиМодель сервера приложений (AS)
Клиент
Компонент
представления
API
Результат
Сервер приложений
Прикладной
компонент SQL
SQL
Данные
Сервер
Компонент
доступа к
данным
Достоинства:
•возможность централизованного администрирования прикладных функций;
•снижение трафика;
•высокая производительность системы.
Недостатки:
•сложность реализации
18. Архитектура сервера баз данных
Методыповышения
эффективности
и
оперативности
обслуживания большого числа клиентских запросов:
• снижение суммарного расхода памяти и вычислительных
ресурсов за счет буферизации (кэширования) и
совместного использования (разделяемые ресурсы)
наиболее часто запрашиваемых данных и процедур;
• распараллеливание процесса обработки запроса —
использованием разных процессоров для параллельной
обработки
изолированных
подзапросов
и/или
для
одновременного обращения к частям базы данных,
размещенным на отдельных физических носителях.
19. 1. Архитектура сервера «один к одному»
Запрос 1Серверный
процесс 1
Процессор
Запрос N
Серверный
процесс 1
БД
20. 2. Многопотоковая односерверная архитектура
Серверный процессЗапрос 1
Поток 1
Процессор
Запрос N
Поток 2
БД
21. 3. Мультисерверная архитектура
Запрос 2Запрос N
Диспетчер
Запрос 1
Серверный
процесс
Серверный
процесс
Процессор
БД
Процессор
22. 4. Серверные архитектуры с параллельной обработкой запроса
Подхоык
повышению
оперативности
за
счет
распараллеливания процесса обработки отдельного запроса:
1. Модель
горизонтального параллелизма -
размещение
хранимых данных БД на нескольких физических носителях
(сегментирование базы). Для обработки запроса в этом случае
запускаются несколько серверных процессов (использующих обычно
отдельные процессоры), каждый из которых независимо от других
выполняет одинаковую последовательность действий, определяемую
существом запроса, но с данными, принадлежащими разным
сегментам
базы.
Полученные
таким
образом
результаты
объединяются и передаются клиенту.
2.
Модель
вертикального
параллелизма
запрос
обрабатывается по конвейерной технологии. Для этого запрос
разбивается на взаимосвязанные по результатам подзапросы,
каждый из которых может быть обслужен отдельным серверным
процессом независимо от обработки других подзапросов.
Получаемые результаты объединяются согласно схеме декомпозиции
запроса и передаются клиенту.
23. 4. Серверные архитектуры с параллельной обработкой запроса
Подзапрос 1Запрос 1
Серверный
процесс
Процессор
Сегмент
БД
Серверный
процесс
Процессор
Сегмент
БД
Подзапрос 2
Подзапрос N