




















 database
databaseSimilar presentations:










Лекция №8 Основные этапы проектирования базы данных
1.
Основные этапыпроектирования
базы данных
Комплексный обзор классического процесса создания надежных и эффективных баз данных для
студентов колледжа
2.
Содержание презентации01
02
Сбор и анализ требований
Концептуальное проектирование
Фундамент успешного проекта
Создание ER-диаграмм и моделей
03
04
Логическое проектирование
Физическое проектирование
Преобразование в реляционную схему
Оптимизация производительности
3.
Зачем изучать проектирование БД?Основа
информационных
систем
Востребованные
навыки
Предотвращение
проблем
Умение проектировать
Правильное
Базы данных лежат в
эффективные БД высоко
проектирование на
основе практически всех
ценится работодателями в
начальных этапах
современных приложений -
сфере IT и является
экономит месяцы работы и
от мобильных приложений
основой карьеры
тысячи долларов на
до корпоративных систем
разработчика
исправлении ошибок в
управления
будущем
4.
Цена ошибок в проектированииИсследования показывают, что стоимость исправления ошибок экспоненциально возрастает с каждым этапом
разработки. Ошибка, обнаруженная на этапе сбора требований, стоит $1, на этапе проектирования - $10, при
кодировании - $100, а после внедрения - $1000.
В контексте баз данных это означает, что неправильно спроектированная структура может потребовать полного
переписывания приложения и миграции данных, что является крайне дорогостоящим процессом.
1X
Требования
Базовая стоимость
10X
Проектирование
Увеличение в 10 раз
100X
Кодирование
Увеличение в 100 раз
1000X
Эксплуатация
Максимальная стоимость
5.
Этап 1Сбор и анализа требований
Первый и критически важный этап, определяющий успех всего проекта базы данных
6.
Что включает сбор требований?Интервьюирование заинтересованных
сторон
Анализ существующих документов
Проведение детальных интервью с
процессов, форм и отчетов для выявления
пользователями, менеджерами и техническими
структуры данных и взаимосвязей
Изучение технической документации, бизнес-
специалистами для понимания бизнес-процессов и
потребностей системы
Наблюдение за рабочими процессами
Создание прототипов интерфейсов
Непосредственное изучение того, как
Разработка макетов экранов и форм для
пользователи работают с данными в реальных
уточнения требований к структуре и
условиях для выявления скрытых требований
представлению данных
7.
Типы требований к базе данныхФункциональные требования
Нефункциональные требования
• Какие данные должна хранить система
• Производительность системы (время
отклика, пропускная способность)
• Какие операции должны выполняться с
данными
• Как пользователи будут
взаимодействовать с системой
• Какие отчеты и запросы необходимы
• Требования к безопасности и
конфиденциальности
• Надежность и доступность системы
• Масштабируемость и возможности
расширения
8.
Результаты этапа сбора требованийТехническое задание
Модель предметной
области
Сценарии
использования
описанием всех
Словарь терминов и
Детальное описание того,
функциональных и
описание бизнес-правил,
как пользователи будут
нефункциональных
которые должна
взаимодействовать с
требований к системе
поддерживать база данных
системой в различных
Подробный документ с
ситуациях
9.
Этап 2Концептуальное проектирование
Создание абстрактной модели данных, независимой от конкретной СУБД
10.
Основы ER-моделированияЧто такое ER-диаграмма?
Entity-Relationship диаграмма - это графическое представление структуры
данных, показывающее сущности, их атрибуты и связи между ними. Это
универсальный язык для описания предметной области.
ER-модель была предложена Питером Ченом в 1976 году и стала стандартом в
Сущности
Объекты реального мира
области проектирования баз данных благодаря своей наглядности и
выразительности.
Атрибуты
Свойства сущностей
Связи
Отношения между сущностями
11.
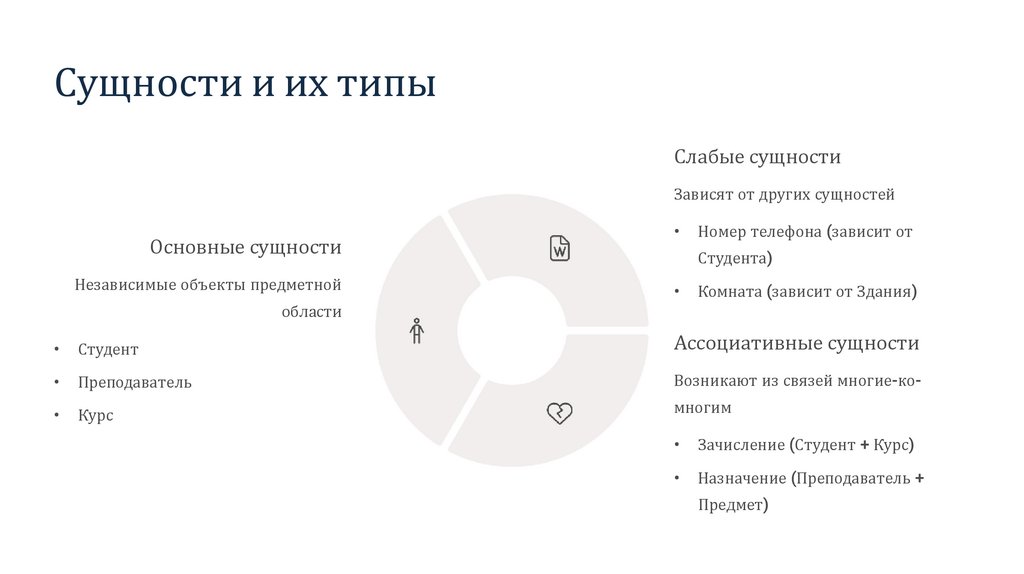
Сущности и их типыСлабые сущности
Зависят от других сущностей
Основные сущности
Независимые объекты предметной
области
Номер телефона (зависит от
Студента)
Комната (зависит от Здания)
Студент
Ассоциативные сущности
Преподаватель
Возникают из связей многие-ко-
Курс
многим
Зачисление (Студент + Курс)
Назначение (Преподаватель +
Предмет)
12.
Атрибуты и их классификацияКлючевые атрибуты
Простые атрибуты
Уникально идентифицируют экземпляр сущности.
Неделимые атрибуты, не состоящие из компонентов.
Подчеркиваются в ER-диаграмме.
Пример: Возраст, Пол, Рейтинг
Пример: Номер студенческого билета, ИНН
Составные атрибуты
Множественные атрибуты
Могут быть разделены на более простые компоненты.
Могут иметь несколько значений для одного экземпляра.
Пример: ФИО (Фамилия + Имя + Отчество)
Пример: Номера телефонов, Email-адреса
13.
Типы связей в ER-моделиОдин к одному (1:1)
Каждый экземпляр одной сущности связан максимум с одним экземпляром другой сущности
Пример: Студент ↔ Студенческий билет
Один ко многим (1:N)
Один экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности
Пример: Группа → Студенты
Многие ко многим (M:N)
Экземпляры обеих сущностей могут быть связаны с несколькими экземплярами другой сущности
Пример: Студенты ↔ Курсы
14.
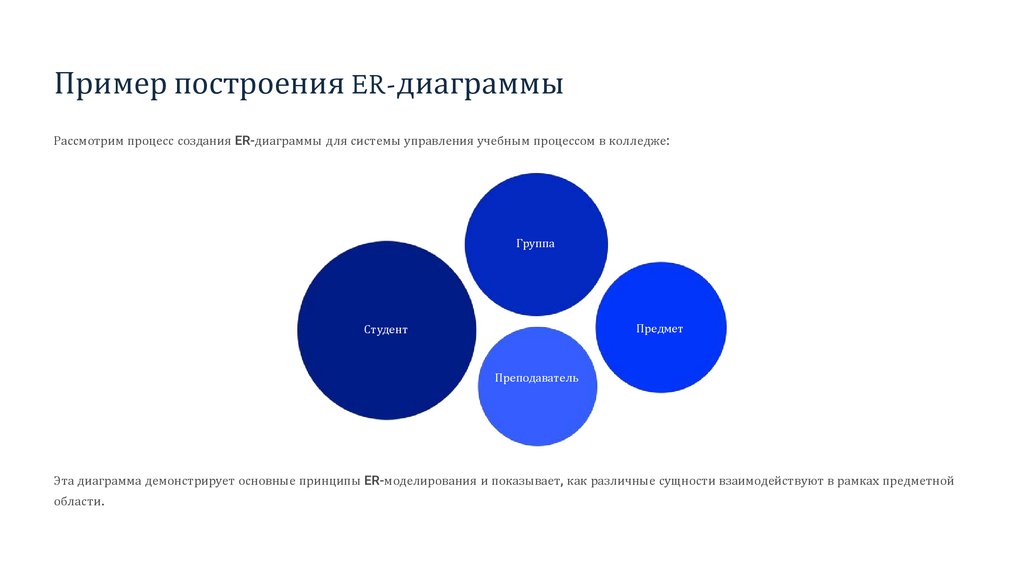
Пример построения ER-диаграммыРассмотрим процесс создания ER-диаграммы для системы управления учебным процессом в колледже:
Группа
Предмет
Студент
Преподаватель
Эта диаграмма демонстрирует основные принципы ER-моделирования и показывает, как различные сущности взаимодействуют в рамках предметной
области.
15.
Этап 3Логическое проектирование
Преобразование концептуальной ER-модели в реляционную схему базы данных
16.
Правила преобразования ER в реляционнуюмодель
01
02
03
Сильные сущности → Таблицы
Слабые сущности → Таблицы с
внешними ключами
Связи 1:1 → Внешние ключи
Каждая сильная сущность становится
Включается внешний ключ от
таблиц или создается отдельная
отдельной таблицей, атрибуты -
родительской сущности как часть
таблица связи
колонками
первичного ключа
Внешний ключ добавляется в одну из
04
05
Связи 1:N → Внешние ключи
Связи M:N → Таблицы связи
Внешний ключ добавляется в таблицу на стороне "многие"
Создается отдельная таблица с внешними ключами обеих
связанных таблиц
17.
Нормализация: устранение избыточностиЗачем нормализовать?
Устранение избыточности данных
Предотвращение аномалий обновления
Обеспечение целостности данных
Экономия дискового пространства
Первая нормальная форма (1NF)
Устранение повторяющихся групп и множественных значений в ячейках
Вторая нормальная форма (2NF)
Устранение частичных функциональных зависимостей от составного ключа
Третья нормальная форма (3NF)
Устранение транзитивных зависимостей от первичного ключа
18.
Пример нормализации таблицы студентовИсходная ненормализованная таблица:
ID_Студента
ФИО
Предметы
Оценки
Преподаватели
001
Иванов И.И.
Математика,
5, 4
Петров, Сидоров
Физика
После нормализации:
Создаются отдельные таблицы: Студенты, Предметы, Преподаватели, и связующая таблица Успеваемость с
внешними ключами. Это устраняет избыточность и обеспечивает целостность данных.
19.
Проектирование индексовПервичные ключи
Внешние ключи
Автоматически
Рекомендуется создавать
индексируются СУБД для
индексы для ускорения
Индексируются поля, часто
быстрого поиска и
операций JOIN между
появляющиеся в условиях
обеспечения уникальности
связанными таблицами
WHERE, ORDER BY и
записей
Часто используемые
поля
GROUP BY
20.
Этап 4Физическое проектирование
Реализация логической модели с учетом особенностей конкретной СУБД и требований к
производительности
21.
Выбор типов данныхЧисловые типы
Строковые типы
Дата и время
INT - для целых чисел (-2
млрд до +2 млрд)
длина, дополняется
BIGINT - для больших
пробелами
целых чисел
CHAR(n) - фиксированная
MM-DD)
VARCHAR(n) - переменная
длина, экономит место
DECIMAL(p,s) - для точных
TEXT - для больших
текстовых данных
FLOAT/DOUBLE - для
вычислений
DATETIME/TIMESTAMP дата и время
приближенных
TIME - только время
(HH:MM:SS)
десятичных вычислений
DATE - только дата (YYYY-
NVARCHAR - для Unicodeтекста
YEAR - только год
22.
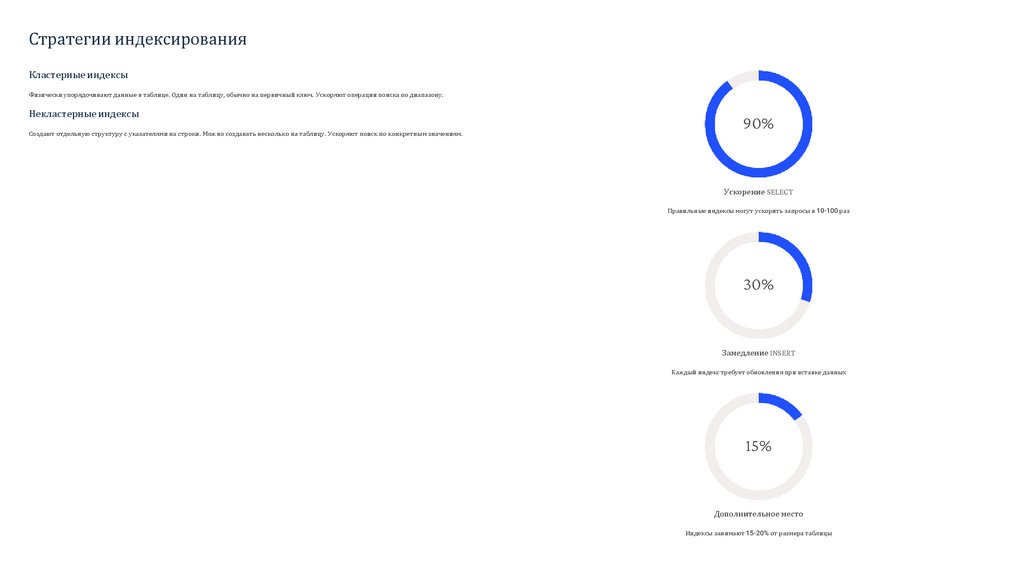
Стратегии индексированияКластерные индексы
Физически упорядочивают данные в таблице. Один на таблицу, обычно на первичный ключ. Ускоряют операции поиска по диапазону.
Некластерные индексы
Создают отдельную структуру с указателями на строки. Можно создавать несколько на таблицу. Ускоряют поиск по конкретным значениям.
90%
Ускорение SELECT
Правильные индексы могут ускорить запросы в 10-100 раз
30%
Замедление INSERT
Каждый индекс требует обновления при вставке данных
15%
Дополнительное место
Индексы занимают 15-20% от размера таблицы
23.
Методы партиционированияГоризонтальное партиционирование
Функциональное партиционирование
Разделение строк таблицы между несколькими
Размещение связанных таблиц и данных на разных
физическими файлами по определенному критерию
физических устройствах для балансировки нагрузки
(например, по датам или регионам)
1
2
Вертикальное партиционирование
Разделение колонок таблицы между файлами. Часто
используемые колонки отделяются от редко
используемых
3
24.
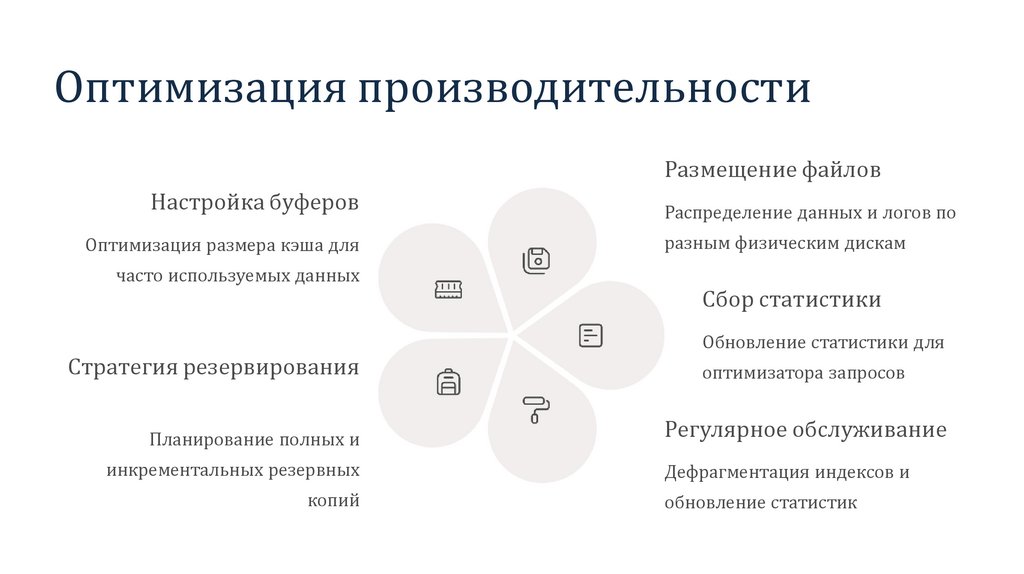
Оптимизация производительностиРазмещение файлов
Настройка буферов
Оптимизация размера кэша для
часто используемых данных
Стратегия резервирования
Планирование полных и
инкрементальных резервных
копий
Распределение данных и логов по
разным физическим дискам
Сбор статистики
Обновление статистики для
оптимизатора запросов
Регулярное обслуживание
Дефрагментация индексов и
обновление статистик
25.
Ключевые выводыКачество начинается с требований
Концептуальное моделирование - основа успеха
Тщательный сбор и анализ требований на начальном этапе
предотвращает дорогостоящие переделки в будущем.
ER-диаграммы помогают визуализировать структуру данных
Потратьте время на понимание предметной области.
и выявить проблемы до начала реализации. Инвестируйте
время в создание качественной модели.
Нормализация обеспечивает целостность
Физическая реализация критична
Правильная нормализация устраняет избыточность и
Выбор правильных типов данных, индексов и стратегий
аномалии. Однако иногда денормализация может быть
партиционирования напрямую влияет на
оправдана для производительности.
производительность системы в эксплуатации.
Помните: хорошо спроектированная база данных - это инвестиция в долгосрочный успех проекта. Каждый этап проектирования имеет
свою важность и вклад в итоговое качество системы.